| 旧版
API 的 Partitioner 解析
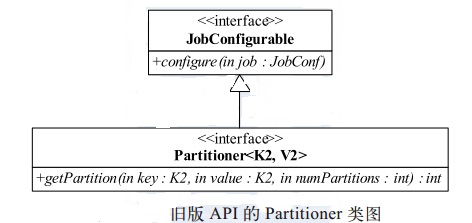
Partitioner 的作用是对 Mapper 产生的中间结果进行分片,以便将同一分组的数据交给同一个
Reducer 处理,它直接影响 Reduce 阶段的负载均衡。旧版 API 中 Partitioner
的类图如图所示。它继承了JobConfigurable,可通过 configure 方法初始化。它本身只包含一个待实现的方法
getPartition。 该方法包含三个参数, 均由框架自动传入,前面两个参数是key/value,第三个参数
numPartitions 表示每个 Mapper 的分片数,也就是 Reducer 的个数。
MapReduce 提供了两个Partitioner 实 现:HashPartitioner和TotalOrderPartitioner。其中
HashPartitioner 是默认实现,它实现了一种基于哈希值的分片方法,代码如下:
public int getPartition(K2 key, V2 value, int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
} |
TotalOrderPartitioner 提供了一种基于区间的分片方法,通常用在数据全排序中。在MapReduce
环境中,容易想到的全排序方案是归并排序,即在 Map 阶段,每个 Map Task进行局部排序;在 Reduce
阶段,启动一个 Reduce Task 进行全局排序。由于作业只能有一个 Reduce Task,因而
Reduce 阶段会成为作业的瓶颈。为了提高全局排序的性能和扩展性,MapReduce 提供了 TotalOrderPartitioner。它能够按照大小将数据分成若干个区间(分片),并保证后一个区间的所有数据均大于前一个区间数据,这使得全排序的步骤如下:
步骤1:数据采样。在 Client 端通过采样获取分片的分割点。Hadoop
自带了几个采样算法,如 IntercalSampler、 RandomSampler、 SplitSampler
等(具体见org.apache.hadoop.mapred.lib 包中的 InputSampler 类)。
下面举例说明。
采样数据为: b, abc, abd, bcd, abcd, efg,
hii, afd, rrr, mnk
经排序后得到: abc, abcd, abd, afd, b, bcd,
efg, hii, mnk, rrr
如果 Reduce Task 个数为 4,则采样数据的四等分点为 abd、
bcd、 mnk,将这 3 个字符串作为分割点。
步骤2:Map 阶段。本阶段涉及两个组件,分别是 Mapper 和 Partitioner。其中,Mapper
可采用 IdentityMapper,直接将输入数据输出,但 Partitioner 必须选用TotalOrderPartitioner,它将步骤
1 中获取的分割点保存到 trie 树中以便快速定位任意一个记录所在的区间,这样,每个 Map Task
产生 R(Reduce Task 个数)个区间,且区间之间有序。TotalOrderPartitioner
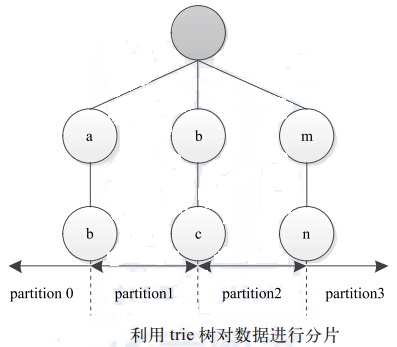
通过 trie 树查找每条记录所对应的 Reduce Task 编号。 如图所示, 我们将分割点 保存在深度为
2 的 trie 树中, 假设输入数据中 有两个字符串“ abg”和“ mnz”, 则字符串“ abg”
对应 partition1, 即第 2 个 Reduce Task, 字符串“ mnz” 对应partition3,
即第 4 个 Reduce Task。
步骤 3:Reduce 阶段。每个 Reducer 对分配到的区间数据进行局部排序,最终得到全排序数据。从以上步骤可以看出,基于
TotalOrderPartitioner 全排序的效率跟 key 分布规律和采样算法有直接关系;key
值分布越均匀且采样越具有代表性,则 Reduce Task 负载越均衡,全排序效率越高。TotalOrderPartitioner
有两个典型的应用实例: TeraSort 和 HBase 批量数据导入。 其中,TeraSort 是 Hadoop
自 带的一个应用程序实例。 它曾在 TB 级数据排序基准评估中 赢得第一名,而 TotalOrderPartitioner正是从该实例中提炼出来的。HBase
是一个构建在 Hadoop之上的 NoSQL 数据仓库。它以 Region为单位划分数据,Region
内部数据有序(按 key 排序),Region 之间也有序。很明显,一个 MapReduce 全排序作业的
R 个输出文件正好可对应 HBase 的 R 个 Region。
新版 API 的 Partitioner 解析
新版 API 中的Partitioner类图如图所示。它不再实现JobConfigurable
接口。当用户需要让 Partitioner通过某个JobConf 对象初始化时,可自行实现Configurable
接口,如:
public class TotalOrderPartitioner<K, V> extends Partitioner<K,V> implements Configurable |

Partition所处的位置
Partition主要作用就是将map的结果发送到相应的reduce。这就对partition有两个要求:
1)均衡负载,尽量的将工作均匀的分配给不同的reduce。
2)效率,分配速度一定要快。
Mapreduce提供的Partitioner
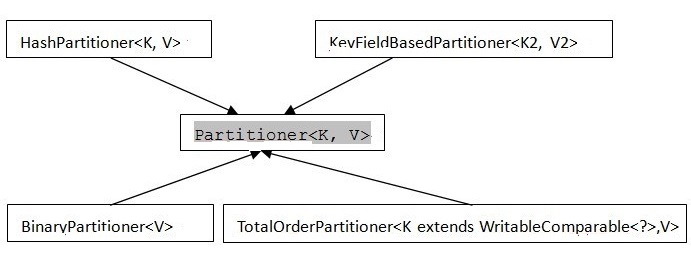
patition类结构
1. Partitioner<k,v>是partitioner的基类,如果需要定制partitioner也需要继承该类。源代码如下:
package org.apache.hadoop.mapred;
/**
* Partitions the key space.
*
* <p class="artcon"><code>Partitioner</code> controls the partitioning of the keys of the
* intermediate map-outputs. The key (or a subset of the key) is used to derive
* the partition, typically by a hash function. The total number of partitions
* is the same as the number of reduce tasks for the job. Hence this controls
* which of the <code>m</code> reduce tasks the intermediate key (and hence the
* record) is sent for reduction.</p>
*
* @see Reducer
* @deprecated Use {@link org.apache.hadoop.mapreduce.Partitioner} instead.
*/
@Deprecated
public interface Partitioner<K2, V2> extends JobConfigurable {
/**
* Get the paritition number for a given key (hence record) given the total
* number of partitions i.e. number of reduce-tasks for the job.
*
* <p class="artcon">Typically a hash function on a all or a subset of the key.</p>
*
* @param key the key to be paritioned.
* @param value the entry value.
* @param numPartitions the total number of partitions.
* @return the partition number for the <code>key</code>.
*/
int getPartition(K2 key, V2 value, int numPartitions);
} |
2. HashPartitioner<k,v>是mapreduce的默认partitioner。源代码如下:
package org.apache.hadoop.mapreduce.lib.partition;
import org.apache.hadoop.mapreduce.Partitioner;
/** Partition keys by their {@link Object#hashCode()}. */
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
} |
3. BinaryPatitioner继承于Partitioner<BinaryComparable
,V>,是Partitioner<k,v>的偏特化子类。该类提供leftOffset和rightOffset,在计算which
reducer时仅对键值K的[rightOffset,leftOffset]这个区间取hash。
reducer=(hash & Integer.MAX_VALUE) % numReduceTasks |
4. KeyFieldBasedPartitioner<k2, v2="">也是基于hash的个partitioner。和BinaryPatitioner不同,它提供了多个区间用于计算hash。当区间数为0时KeyFieldBasedPartitioner退化成HashPartitioner。
源代码如下:
package org.apache.hadoop.mapred.lib;
import java.io.UnsupportedEncodingException;
import java.util.List;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.Partitioner;
import org.apache.hadoop.mapred.lib.KeyFieldHelper.KeyDescription;
/**
* Defines a way to partition keys based on certain key fields (also see
* {@link KeyFieldBasedComparator}.
* The key specification supported is of the form -k pos1[,pos2], where,
* pos is of the form f[.c][opts], where f is the number
* of the key field to use, and c is the number of the first character from
* the beginning of the field. Fields and character posns are numbered
* starting with 1; a character position of zero in pos2 indicates the
* field's last character. If '.c' is omitted from pos1, it defaults to 1
* (the beginning of the field); if omitted from pos2, it defaults to 0
* (the end of the field).
*
*/
public class KeyFieldBasedPartitioner<K2, V2> implements Partitioner<K2, V2> {
private static final Log LOG = LogFactory.getLog(KeyFieldBasedPartitioner.class.getName());
private int numOfPartitionFields;
private KeyFieldHelper keyFieldHelper = new KeyFieldHelper();
public void configure(JobConf job) {
String keyFieldSeparator = job.get("map.output.key.field.separator", "\t");
keyFieldHelper.setKeyFieldSeparator(keyFieldSeparator);
if (job.get("num.key.fields.for.partition") != null) {
LOG.warn("Using deprecated num.key.fields.for.partition. " +
"Use mapred.text.key.partitioner.options instead");
this.numOfPartitionFields = job.getInt("num.key.fields.for.partition",0);
keyFieldHelper.setKeyFieldSpec(1,numOfPartitionFields);
} else {
String option = job.getKeyFieldPartitionerOption();
keyFieldHelper.parseOption(option);
}
}
public int getPartition(K2 key, V2 value,
int numReduceTasks) {
byte[] keyBytes;
List allKeySpecs = keyFieldHelper.keySpecs();
if (allKeySpecs.size() == 0) {
return getPartition(key.toString().hashCode(), numReduceTasks);
}
try {
keyBytes = key.toString().getBytes("UTF-8");
} catch (UnsupportedEncodingException e) {
throw new RuntimeException("The current system does not " +
"support UTF-8 encoding!", e);
}
// return 0 if the key is empty
if (keyBytes.length == 0) {
return 0;
}
int []lengthIndicesFirst = keyFieldHelper.getWordLengths(keyBytes, 0,
keyBytes.length);
int currentHash = 0;
for (KeyDescription keySpec : allKeySpecs) {
int startChar = keyFieldHelper.getStartOffset(keyBytes, 0, keyBytes.length,
lengthIndicesFirst, keySpec);
// no key found! continue
if (startChar < 0) {
continue;
}
int endChar = keyFieldHelper.getEndOffset(keyBytes, 0, keyBytes.length,
lengthIndicesFirst, keySpec);
currentHash = hashCode(keyBytes, startChar, endChar,
currentHash);
}
return getPartition(currentHash, numReduceTasks);
}
protected int hashCode(byte[] b, int start, int end, int currentHash) {
for (int i = start; i <= end; i++) {
currentHash = 31*currentHash + b[i];
}
return currentHash;
}
protected int getPartition(int hash, int numReduceTasks) {
return (hash & Integer.MAX_VALUE) % numReduceTasks;
}
} |
5. TotalOrderPartitioner这个类可以实现输出的全排序。不同于以上3个partitioner,这个类并不是基于hash的。下面详细的介绍TotalOrderPartitioner
TotalOrderPartitioner 类
每一个reducer的输出在默认的情况下都是有顺序的,但是reducer之间在输入是无序的情况下也是无序的。如果要实现输出是全排序的那就会用到TotalOrderPartitioner。
要使用TotalOrderPartitioner,得给TotalOrderPartitioner提供一个partition
file。这个文件要求Key(这些key就是所谓的划分)的数量和当前reducer的数量-1相同并且是从小到大排列。对于为什么要用到这样一个文件,以及这个文件的具体细节待会还会提到。
TotalOrderPartitioner对不同Key的数据类型提供了两种方案:
1) 对于非BinaryComparable 类型的Key,TotalOrderPartitioner采用二分发查找当前的K所在的index。
例如:reducer的数量为5,partition file 提供的4个划分为【2,4,6,8】。如果当前的一个key/value
是<4,”good”>,利用二分法查找到index=1,index+1=2那么这个key/value
将会发送到第二个reducer。如果一个key/value为<4.5, “good”>。那么二分法查找将返回-3,同样对-3加1然后取反就是这个key/value将要去的reducer。
对于一些数值型的数据来说,利用二分法查找复杂度是O(log(reducer count)),速度比较快。
2) 对于BinaryComparable类型的Key(也可以直接理解为字符串)。字符串按照字典顺序也是可以进行排序的。
这样的话也可以给定一些划分,让不同的字符串key分配到不同的reducer里。这里的处理和数值类型的比较相近。
例如:reducer的数量为5,partition file 提供了4个划分为【“abc”, “bce”,
“eaa”, ”fhc”】那么“ab”这个字符串将会被分配到第一个reducer里,因为它小于第一个划分“abc”。
但是不同于数值型的数据,字符串的查找和比较不能按照数值型数据的比较方法。mapreducer采用的Tire
tree(关于Tire tree可以参考《字典树(Trie Tree)》)的字符串查找方法。查找的时间复杂度o(m),m为树的深度,空间复杂度o(255^m-1)。是一个典型的空间换时间的案例。
Tire tree的构建
假设树的最大深度为3,划分为【aaad ,aaaf, aaaeh,abbx】

Mapreduce里的Tire tree主要有两种节点组成:
1) Innertirenode
Innertirenode在mapreduce中是包含了255个字符的一个比较长的串。上图中的例子只包含了26个英文字母。
2) 叶子节点{unslipttirenode, singesplittirenode,
leaftirenode}
Unslipttirenode 是不包含划分的叶子节点。
Singlesplittirenode 是只包含了一个划分点的叶子节点。
Leafnode是包含了多个划分点的叶子节点。(这种情况比较少见,达到树的最大深度才出现这种情况。在实际操作过程中比较少见)
Tire tree的搜索过程
接上面的例子:
1)假如当前 key value pair <aad, 10="">这时会找到图中的leafnode,在leafnode内部使用二分法继续查找找到返回
aad在划分数组中的索引。找不到会返回一个和它最接近的划分的索引。
2)假如找到singlenode,如果和singlenode的划分相同或小返回他的索引,比singlenode的划分大则返回索引+1。
3)假如找到nosplitnode则返回前面的索引。如<zaa,
20="">将会返回abbx的在划分数组中的索引。
TotalOrderPartitioner的疑问
上面介绍了partitioner有两个要求,一个是速度,另外一个是均衡负载。使用tire tree提高了搜素的速度,但是我们怎么才能找到这样的partition
file 呢?让所有的划分刚好就能实现均衡负载。
InputSampler
输入采样类,可以对输入目录下的数据进行采样。提供了3种采样方法。
采样类结构图
采样方式对比表:

writePartitionFile这个方法很关键,这个方法就是根据采样类提供的样本,首先进行排序,然后选定(随机的方法)和reducer数目-1的样本写入到partition
file。这样经过采样的数据生成的划分,在每个划分区间里的key/value就近似相同了,这样就能完成均衡负载的作用。
SplitSampler类的源代码如下:
/**
* Samples the first n records from s splits.
* Inexpensive way to sample random data.
*/
public static class SplitSampler<K,V> implements Sampler<K,V> {
private final int numSamples;
private final int maxSplitsSampled;
/**
* Create a SplitSampler sampling all splits.
* Takes the first numSamples / numSplits records from each split.
* @param numSamples Total number of samples to obtain from all selected
* splits.
*/
public SplitSampler(int numSamples) {
this(numSamples, Integer.MAX_VALUE);
}
/**
* Create a new SplitSampler.
* @param numSamples Total number of samples to obtain from all selected
* splits.
* @param maxSplitsSampled The maximum number of splits to examine.
*/
public SplitSampler(int numSamples, int maxSplitsSampled) {
this.numSamples = numSamples;
this.maxSplitsSampled = maxSplitsSampled;
}
/**
* From each split sampled, take the first numSamples / numSplits records.
*/
@SuppressWarnings("unchecked") // ArrayList::toArray doesn't preserve type
public K[] getSample(InputFormat<K,V> inf, JobConf job) throws IOException {
InputSplit[] splits = inf.getSplits(job, job.getNumMapTasks());
ArrayList samples = new ArrayList(numSamples);
int splitsToSample = Math.min(maxSplitsSampled, splits.length);
int splitStep = splits.length / splitsToSample;
int samplesPerSplit = numSamples / splitsToSample;
long records = 0;
for (int i = 0; i < splitsToSample; ++i) {
RecordReader<K,V> reader = inf.getRecordReader(splits[i * splitStep],
job, Reporter.NULL);
K key = reader.createKey();
V value = reader.createValue();
while (reader.next(key, value)) {
samples.add(key);
key = reader.createKey();
++records;
if ((i+1) * samplesPerSplit <= records) {
break;
}
}
reader.close();
}
return (K[])samples.toArray();
}
} |
RandomSampler类的源代码如下:
/**
* Sample from random points in the input.
* General-purpose sampler. Takes numSamples / maxSplitsSampled inputs from
* each split.
*/
public static class RandomSampler<K,V> implements Sampler<K,V> {
private double freq;
private final int numSamples;
private final int maxSplitsSampled;
/**
* Create a new RandomSampler sampling all splits.
* This will read every split at the client, which is very expensive.
* @param freq Probability with which a key will be chosen.
* @param numSamples Total number of samples to obtain from all selected
* splits.
*/
public RandomSampler(double freq, int numSamples) {
this(freq, numSamples, Integer.MAX_VALUE);
}
/**
* Create a new RandomSampler.
* @param freq Probability with which a key will be chosen.
* @param numSamples Total number of samples to obtain from all selected
* splits.
* @param maxSplitsSampled The maximum number of splits to examine.
*/
public RandomSampler(double freq, int numSamples, int maxSplitsSampled) {
this.freq = freq;
this.numSamples = numSamples;
this.maxSplitsSampled = maxSplitsSampled;
}
/**
* Randomize the split order, then take the specified number of keys from
* each split sampled, where each key is selected with the specified
* probability and possibly replaced by a subsequently selected key when
* the quota of keys from that split is satisfied.
*/
@SuppressWarnings("unchecked") // ArrayList::toArray doesn't preserve type
public K[] getSample(InputFormat<K,V> inf, JobConf job) throws IOException {
InputSplit[] splits = inf.getSplits(job, job.getNumMapTasks());
ArrayList samples = new ArrayList(numSamples);
int splitsToSample = Math.min(maxSplitsSampled, splits.length);
Random r = new Random();
long seed = r.nextLong();
r.setSeed(seed);
LOG.debug("seed: " + seed);
// shuffle splits
for (int i = 0; i < splits.length; ++i) {
InputSplit tmp = splits[i];
int j = r.nextInt(splits.length);
splits[i] = splits[j];
splits[j] = tmp;
}
// our target rate is in terms of the maximum number of sample splits,
// but we accept the possibility of sampling additional splits to hit
// the target sample keyset
for (int i = 0; i < splitsToSample ||
(i < splits.length && samples.size() < numSamples); ++i) {
RecordReader<K,V> reader = inf.getRecordReader(splits[i], job,
Reporter.NULL);
K key = reader.createKey();
V value = reader.createValue();
while (reader.next(key, value)) {
if (r.nextDouble() <= freq) {
if (samples.size() < numSamples) {
samples.add(key);
} else {
// When exceeding the maximum number of samples, replace a
// random element with this one, then adjust the frequency
// to reflect the possibility of existing elements being
// pushed out
int ind = r.nextInt(numSamples);
if (ind != numSamples) {
samples.set(ind, key);
}
freq *= (numSamples - 1) / (double) numSamples;
}
key = reader.createKey();
}
}
reader.close();
}
return (K[])samples.toArray();
}
} |
IntervalSampler类的源代码为:
/**
* Sample from s splits at regular intervals.
* Useful for sorted data.
*/
public static class IntervalSampler<K,V> implements Sampler<K,V> {
private final double freq;
private final int maxSplitsSampled;
/**
* Create a new IntervalSampler sampling all splits.
* @param freq The frequency with which records will be emitted.
*/
public IntervalSampler(double freq) {
this(freq, Integer.MAX_VALUE);
}
/**
* Create a new IntervalSampler.
* @param freq The frequency with which records will be emitted.
* @param maxSplitsSampled The maximum number of splits to examine.
* @see #getSample
*/
public IntervalSampler(double freq, int maxSplitsSampled) {
this.freq = freq;
this.maxSplitsSampled = maxSplitsSampled;
}
/**
* For each split sampled, emit when the ratio of the number of records
* retained to the total record count is less than the specified
* frequency.
*/
@SuppressWarnings("unchecked") // ArrayList::toArray doesn't preserve type
public K[] getSample(InputFormat<K,V> inf, JobConf job) throws IOException {
InputSplit[] splits = inf.getSplits(job, job.getNumMapTasks());
ArrayList samples = new ArrayList();
int splitsToSample = Math.min(maxSplitsSampled, splits.length);
int splitStep = splits.length / splitsToSample;
long records = 0;
long kept = 0;
for (int i = 0; i < splitsToSample; ++i) {
RecordReader<K,V> reader = inf.getRecordReader(splits[i * splitStep],
job, Reporter.NULL);
K key = reader.createKey();
V value = reader.createValue();
while (reader.next(key, value)) {
++records;
if ((double) kept / records < freq) {
++kept;
samples.add(key);
key = reader.createKey();
}
}
reader.close();
}
return (K[])samples.toArray();
}
} |
TotalOrderPartitioner实例
public class SortByTemperatureUsingTotalOrderPartitioner extends Configured
implements Tool
{
@Override
public int run(String[] args) throws Exception
{
JobConf conf = JobBuilder.parseInputAndOutput(this, getConf(), args);
if (conf == null) {
return -1;
}
conf.setInputFormat(SequenceFileInputFormat.class);
conf.setOutputKeyClass(IntWritable.class);
conf.setOutputFormat(SequenceFileOutputFormat.class);
SequenceFileOutputFormat.setCompressOutput(conf, true);
SequenceFileOutputFormat
.setOutputCompressorClass(conf, GzipCodec.class);
SequenceFileOutputFormat.setOutputCompressionType(conf,
CompressionType.BLOCK);
conf.setPartitionerClass(TotalOrderPartitioner.class);
InputSampler.Sampler<IntWritable, Text> sampler = new InputSampler.RandomSampler<IntWritable, Text>(
0.1, 10000, 10);
Path input = FileInputFormat.getInputPaths(conf)[0];
input = input.makeQualified(input.getFileSystem(conf));
Path partitionFile = new Path(input, "_partitions");
TotalOrderPartitioner.setPartitionFile(conf, partitionFile);
InputSampler.writePartitionFile(conf, sampler);
// Add to DistributedCache
URI partitionUri = new URI(partitionFile.toString() + "#_partitions");
DistributedCache.addCacheFile(partitionUri, conf);
DistributedCache.createSymlink(conf);
JobClient.runJob(conf);
return 0;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(
new SortByTemperatureUsingTotalOrderPartitioner(), args);
System.exit(exitCode);
}
} |
|





