| MongoDB��˾ԭ��10gen��������2007�꣬��2013���յ�һ��2.31����Ԫ�����ʺ�˾��ֵ����������10����Ԫ��������߶���֪����Դ��˾Red
Hat(������1993��)20��ķܶ��ɹ���
�����ܡ�����չһֱ��MongoDB������֮����ͬʱ�淶���ĵ��ͽӿڸ����������û�ϲ������һ��ӷ���DB-Engines�ĵ÷ֽ�����ѿ�����������1��ʱ�䣬MongoDB������˵�7�������������������÷־ʹ�124��������214�֣�����ֵ�ǵ�����PotgreSQL��������ͬʱ������PostgreSQL�ĵ÷�Ҳֻ���16�ֲ�����
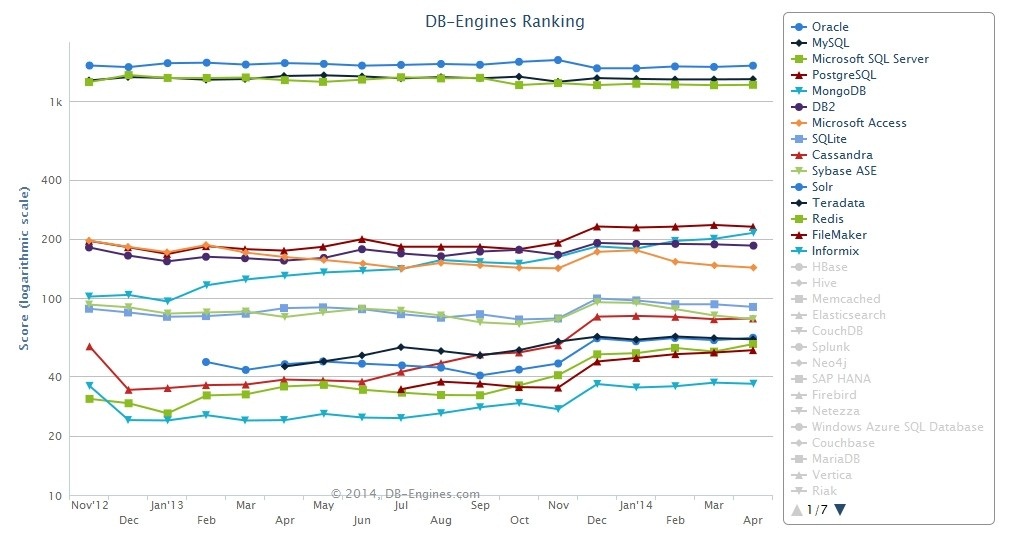
MongoDB��������ٶȷ�չ���ܴ�̶��Ϲ�������ഫͳ��ϵ���ݿ�����Ӧ�Ե������ݴ�������չ��������Ȼ���Ǿþ����飬���߱����������ܼ��ȶ��ԡ�Ȼ��������������ʹ�÷���������NoSQL�������Լ������ƣ��Ӷ�Ҳ�����������ѵ����⡣��������Ϊ��ҷ���
�����IJ��ġ�����δ��Ч��MongoDB��Ⱥ��
����Ϊ���ģ�
���븱�����ڲ�����
��ϵ�����µĵ�һ���ֽ����˸����������ã�������ֽ������о�һ�¸��������ڲ����ơ����Ǵ��Ÿ�����������������!
����������ת�ƣ����ڵ������ѡ�ٵ�?�ܷ��ֶ������¼�ijһ̨���ڵ㡣
�ٷ�˵���������������������Ϊʲô?
MongDB�����������ͬ����?���ͬ������ʱ�����ʲô���?�����ֲ�һ����?
MongDB�Ĺ���ת�ƻ�����Զ�����?ʲô�����ᴥ��?Ƶ���������ܻ����ϵͳ���ؼ���?
Bully�㷨
MongDB����������ת�ƹ��ܵ���������ѡ�ٻ��ơ�ѡ�ٻ��Ʋ�����Bully�㷨�����Ժܷ���ӷֲ�ʽ�ڵ���ѡ�����ڵ㡣һ���ֲ�ʽ��Ⱥ�ܹ���һ�㶼��һ����ν�����ڵ㣬�����кܶ���;�����绺������ڵ�Ԫ���ݣ���Ϊ��Ⱥ�ķ�����ڵȵȡ����ڵ��о��аɣ����Ǹ���ҪʲôBully�㷨?Ҫ������������ȿ��������ּܹ���
ָ�����ڵ�ļܹ������ּܹ�һ�㶼������һ���ڵ�Ϊ���ڵ㣬�����ڵ㶼�Ǵӽڵ㣬�����dz��õ�MySQL�������������������ܹ������ڵ�һ��˵��������Ⱥ������ڵ�ҵ��˾͵��ֹ��������ϼ�һ���µ����ڵ���ߴӴӽڵ�ָ����ݣ���̫��
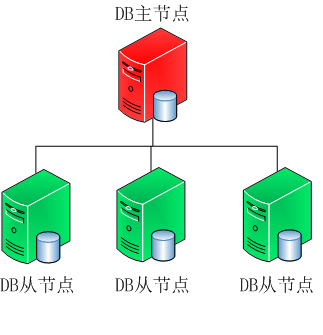
��ָ�����ڵ㣬��Ⱥ�е�����ڵ㶼���Գ�Ϊ���ڵ㡣MongoDBҲ���Dz������ּܹ���һ�����ڵ���������ӽڵ��Զ����������ڵ㡣����ͼ��
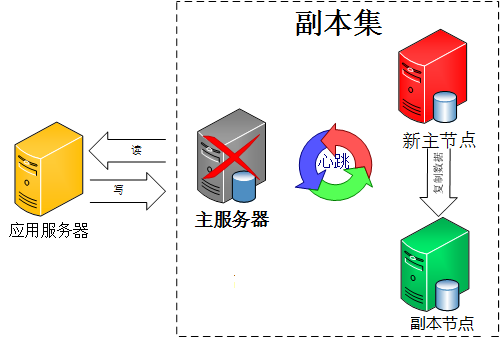
���ˣ������������ط�����Ȼ���нڵ㶼��һ����һ�����ڵ���ˣ���ôȷ����һ�����ڵ�?�����Bully�㷨��������⡣
��ʲô��Bully�㷨��Bully�㷨��һ��Э����(���ڵ�)��ѡ�㷨����Ҫ˼���Ǽ�Ⱥ��ÿ����Ա�����������������ڵ㲢֪ͨ�����ڵ㡣��Ľڵ����ѡ�����������ƻ��Ǿܾ����������ڵ㾺�������������нڵ���ܵĽڵ���ܳ�Ϊ���ڵ㡣�ڵ㰴��һЩ�������ж�˭Ӧ��ʤ����������Կ�����һ����̬ID��Ҳ�����Ǹ��µĶ��������һ������ID(���µĽڵ��ʤ��)��������ο�
NoSQL���ݿ�ֲ�ʽ�㷨��Э���߾�ѡ���� ά���ٿƵĽ��͡�
ѡ��
��ô��MongDB��������ѡ�ٵ���?�ٷ���ô������
We use a consensus protocol to pick a primary. Exact details will be spared here but that basic process is:
����get maxLocalOpOrdinal from each server.
����if a majority of servers are not up (from this server��s POV), remain in Secondary mode and stop.
����if the last op time seems very old, stop and await human intervention.
����else, using a consensus protocol, pick the server with the highest maxLocalOpOrdinal as the Primary. |
���·������Ϊʹ��һ��Э��ѡ�����ڵ㡣��������Ϊ��
�õ�ÿ���������ڵ��������ʱ�����ÿ��MongDB����oplog���Ƽ�¼��������������������������жԱ������Ƿ�ͬ�����������ڴ���ָ���
�����Ⱥ�дַ�����down���ˣ��������ŵĽڵ㶼Ϊsecondary״̬��ֹͣ����ѡ���ˡ�
�����Ⱥ��ѡ�ٳ��������ڵ�������дӽڵ����һ��ͬ��ʱ�俴�����ܾɣ�ֹͣѡ�ٵȴ�����������
������涼û�������ѡ��������ʱ�������(��֤���������µ�)�ķ������ڵ���Ϊ���ڵ㡣
�����ᵽ��һ��һ��Э��(��ʵ����bully�㷨)����������ݿ��һ����Э�黹����Щ����һ��Э����Ҫǿ������ͨ��һЩ���Ʊ�֤��Ҵ�ɹ�ʶ;��һ����Э��ǿ�����Dz�����˳��һ���ԣ�����ͬʱ��дһ�����ݻ����������ݡ�һ��Э���ڷֲ�ʽ����һ��������㷨�С�Paxos�㷨���������ٽ��ܡ�
�����и����⣬�������дӽڵ��������ʱ�䶼��һ����ô��?����˭�ȳ�Ϊ���ڵ��ʱ������ѡ˭��
ѡ�ٴ�������
ѡ�ٲ���ʲôʱ�̶��ᱻ�����ģ�������������Դ�����
��ʼ��һ��������ʱ��
�����������ڵ�Ͽ����ӣ��������������⡣
���ڵ�ҵ���
ѡ�ٻ��и�ǰ������������ѡ�ٵĽڵ�����������ڸ������ܽڵ�������һ�룬����Ѿ�С��һ�������нڵ㱣��ֻ��״̬����־������֣�
can't see a majority of the set, relinquishing primary |
1. ���ڵ�ҵ��ܷ���Ϊ��Ԥ?���ǿ϶��ġ�
����ͨ��replSetStepDown�����¼����ڵ㡣���������Ե�¼���ڵ�ʹ��
db.adminCommand({replSetStepDown : 1}) |
���ɱ��������ʹ��ǿ�ƿ���
db.adminCommand({replSetStepDown : 1, force : true}) |
����ʹ�� rs.stepDown(120)Ҳ���Դﵽͬ����Ч�����м������ָ������ֹͣ�������ʱ���Ϊ���ڵ㣬��λΪ�롣
2. ����һ���ӽڵ��б����ڵ��и��ߵ����ȼ���
�Ȳ鿴��ǰ��Ⱥ�����ȼ���ͨ��rs.conf()���Ĭ�����ȼ�Ϊ1�Dz���ʾ�ģ������ʾ����
[java] view plaincopyrs.conf();
����[java] view plaincopy{
����"_id" : "rs0",
����"version" : 9,
����"members" : [
����{
����"_id" : 0,
����"host" : "192.168.1.136:27017" },
����{
����"_id" : 1,
����"host" : "192.168.1.137:27017" },
����{
����"_id" : 2,
����"host" : "192.168.1.138:27017" }
����]
����} |
���������һ���ӽڵ��Ϊ���ڵ������ô����?
ʹ��rs.freeze(120)����ָ������������ѡ�ٳ�Ϊ���ڵ㡣
������һƪ���ýڵ�ΪNon-Voting���͡�
�����ڵ㲻�ܺʹִӽڵ�ͨѶ���������ڵ����߰ε����ٺ٣�)
���ȼ���������ô�ã�������Dz�������ʲôhidden�ڵ㣬����secondary������Ϊ���ݽڵ�Ҳ����������Ϊ���ڵ���ô��?����ͼ���������ڵ�ֲ��������������ģ���������2�Ľڵ��������ȼ�Ϊ0���ܳ�Ϊ���ڵ㣬���ǿ��Բ���ѡ�١����ݸ��ơ��ܹ����Ǻ�����!
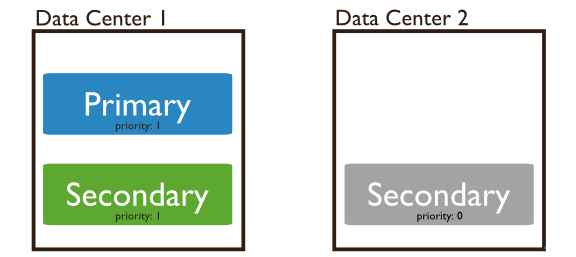
����
�ٷ��Ƽ��������ij�Ա����Ϊ���������12���������ڵ㣬���7���ڵ����ѡ�١����12���������ڵ�����Ϊû��Ҫһ�����ݸ�����ô��ݣ�����̫�෴�����������縺�غ������˼�Ⱥ����;�����7���ڵ����ѡ������Ϊ�ڲ�ѡ�ٻ��ƽڵ�����̫��ͻᵼ��1�����ڻ�ѡ�������ڵ㣬����ֻҪ�ʵ��ͺá������12������7�����ֻ��ã�ͨ�����ǹٷ��������ܲ��Զ�������������⡣���廹����Щ���Ʋο��ٷ��ĵ�
�� MongoDB Limits and Thresholds ���� ��������һֱû�㶮������ȺΪʲôҪ������ͨ�����Լ�Ⱥ������Ϊż��Ҳ�ǿ������еģ��ο��������http://www.itpub.net/thread-1740982-1-1.html������ͻȻ����һƪ
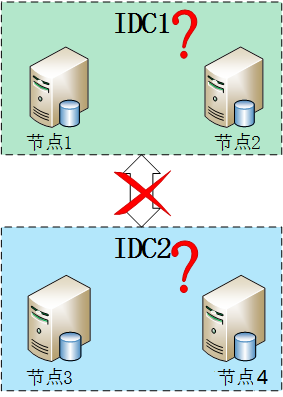
stackoverflow���������ڶ����ˣ�mongodb������Ƶľ���һ�����Կ�IDC�ķֲ�ʽ���ݿ⣬��������Ӧ�ð����ŵ���Ļ���������
�����ĸ��ڵ㱻�ֳ�����IDC��ÿ��IDC����̨����������ͼ���������ͳ����˸����⣬�������IDC����ϵ������ڹ������Ϻ����׳��ֵ����⣬������ѡ�����ᵽֻҪ���ڵ�ͼ�Ⱥ�дֽڵ�Ͽ����ӾͻῪʼһ���µ�ѡ�ٲ���������MongoDB���������߶�ֻ�������ڵ㣬����ѡ��Ҫ�����Ľڵ������������һ�룬�������м�Ⱥ�ڵ㶼û�취����ѡ�٣�ֻ�ᴦ��ֻ��״̬����������������ڵ�Ͳ������������⣬����3���ڵ㣬ֻҪ��2���ڵ���žͿ���ѡ�٣�5���е�3����7���е�4������
����
����������������Ⱥ��Ҫ����һ����ͨ�Ų���֪����Щ�ڵ������Щ�ڵ�ҵ���MongoDB�ڵ�������е������ڵ�ÿ����ͻᷢ��һ��pings������������ڵ���10����֮��û�з��ؾͱ�ʾΪ���ܷ��ʡ�ÿ���ڵ��ڲ�����ά��һ��״̬ӳ�����������ǰÿ���ڵ���ʲô��ɫ����־ʱ����ȹؼ���Ϣ����������ڵ㣬����ά��ӳ������Ҫ����Լ��ܷ�ͼ�Ⱥ���ڴֽڵ�ͨѶ�������������Լ�����Ϊsecondaryֻ���ڵ㡣
ͬ��
������ͬ����Ϊ��ʼ��ͬ����keep���ơ���ʼ��ͬ��ָȫ�������ڵ�ͬ�����ݣ�������ڵ��������Ƚϴ�ͬ��ʱ���Ƚϳ�����keep����ָ��ʼ��ͬ�����ڵ�֮���ʵʱͬ��һ��������ͬ������ʼ��ͬ����ֻ���ڵ�һ�βŻᱻ��������������������ᴥ����
1.secondary��һ�μ��룬����ǿ϶��ġ�
2.secondary����������������oplog�Ĵ�С������Ҳ�ᱻȫ�����ơ�
��ʲô��oplog�Ĵ�С?ǰ��˵��oplog���������ݵIJ�����¼��secondary����oplog��������IJ�����secondaryִ��һ�顣����oplogҲ��mongodb��һ�����ϣ�������local.oplog.rs��;Ȼ�����oplog��һ��capped
collection��Ҳ���ǹ̶���С�ļ��ϣ������ݼ��볬�����ϵĴ�С�Ḳ�ǣ�����������Ҫע�⣬��IDC�ĸ���Ҫ���ú��ʵ�oplogSize������������������������ȫ�����ơ�oplogSize
����ͨ���CoplogSize���ô�С������Linux ��Windows 64λ��oplog sizeĬ��Ϊʣ����̿ռ��5%��
ͬ��Ҳ����ֻ�ܴ����ڵ�ͬ�������輯Ⱥ��3���ڵ㣬�ڵ�1�����ڵ���IDC1���ڵ�2���ڵ�3��IDC2����ʼ���ڵ�2���ڵ�3��ӽڵ�1ͬ�����ݡ�����ڵ�2���ڵ�3��ʹ�þͽ�ԭ��ӵ�ǰIDC�ĸ������н��и��ƣ�ֻҪ��һ���ڵ��IDC1�Ľڵ�1�������ݡ�
����ͬ����Ҫע�����¼��㣺
secondary�����delayed��hidden��Ա�ϸ������ݡ�
ֻҪ����Ҫͬ����������Ա��buildindexes����Ҫ��ͬ�����Ƿ���true��false��buildindexes��Ҫ���������Ƿ�����ڵ���������ڲ�ѯ��Ĭ��Ϊtrue��
���ͬ������30�붼û�з�Ӧ���������ѡ��һ���ڵ����ͬ����
���ˣ�����ǰ���ᵽ������ȫ������ˣ����ò�˵MongoDB����ƻ�����ǿ��!
�������������һ���⼸�����⣺
���ڵ�����ܷ��Զ��л�����?Ŀǰ��Ҫ�ֹ��л���
���ڵ�Ķ�дѹ��������ν��?
��ϵͳ���ڣ���������С��ʱ������̫������⣬���������������������࣬������������һ̨����Ӳ��ƿ������ġ���MongoDB����ľ��Ǻ������ݼܹ��������ܽ������������ô��!����Ƭ��������������������⡣
��ͳ���ݿ���ô���������ݶ�д?��ʵһ�仰�������ֶ���֮����ͼ����������ˣ�����TaoBao����ǿ�ᵽ�ļܹ�ͼ��
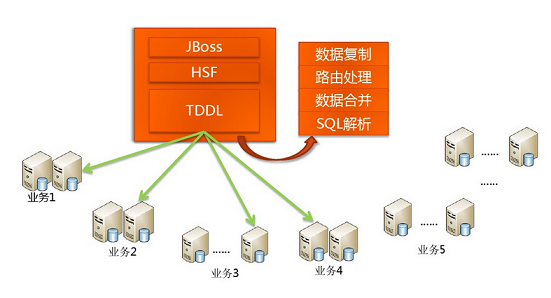
��ͼ���и�TDDL����TaoBao��һ�����ݷ��ʲ����������Ҫ��������SQL������·�ɴ���������Ӧ�õ�����Ĺ��ܽ�����ǰ���ʵ�sql�ж������ĸ�ҵ�����ݿ⡢�ĸ������ʲ�ѯ���������ݽ����������ͼ��
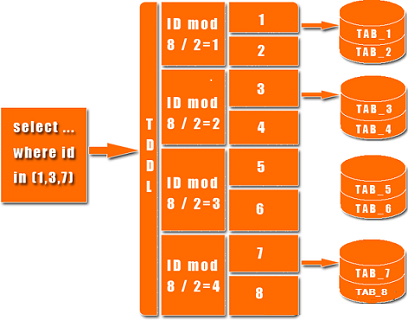
˵����ô�ഫͳ���ݿ�ļܹ�����NoSQL��ôȥ��������Щ��?MySQLҪ�����Զ���չ��Ҫ��һ�����ݷ��ʲ��ó���ȥ��չ�����ݿ�����ӡ�ɾ�������ݻ���Ҫ����ȥ���ơ�һ�����ݿ�Ľڵ�һ�࣬Ҫά������Ҳ�Ƿdz�ͷ�۵ġ�����MongoDB���е���һ��ͨ�����Լ����ڲ����ƾͿ��Ը㶨!������ͼ����MongoDBͨ����Щ����ʵ��·�ɡ���Ƭ��
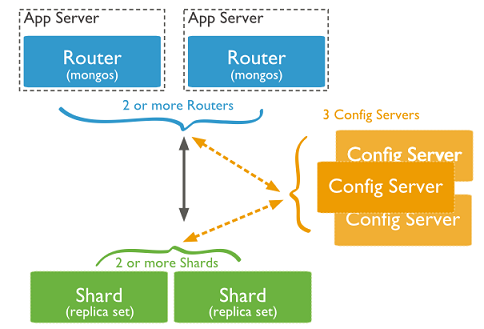
��ͼ�п��Կ������ĸ������mongos��config server��shard��replica set��
mongos�����ݿ⼯Ⱥ�������ڣ����е�����ͨ��mongos����Э��������Ҫ��Ӧ�ó�������һ��·��ѡ������mongos�Լ�����һ������ַ����ģ�������Ѷ�Ӧ��������������ת������Ӧ��shard�������ϡ�����������ͨ���ж�mongos��Ϊ�������ڣ���ֹ����һ���ҵ����е�mongodb����û�а취������
config server������˼��Ϊ���÷��������洢�������ݿ�Ԫ��Ϣ(·�ɡ���Ƭ)�����á�mongos����û�������洢��Ƭ������������·����Ϣ��ֻ�ǻ������ڴ�����÷�������ʵ�ʴ洢��Щ���ݡ�mongos��һ���������߹ص������ͻ��
config server ����������Ϣ���Ժ�������÷�������Ϣ�仯��֪ͨ�����е� mongos �����Լ���״̬������
mongos ���ܼ���ȷ·�ɡ�����������ͨ���ж�� config server ���÷���������Ϊ���洢�˷�Ƭ·�ɵ�Ԫ���ݣ�����ɲ��ܶ�ʧ!����ҵ�����һ̨��ֻҪ���д����
mongodb��Ⱥ�Ͳ���ҵ���
shard������Ǵ�˵�еķ�Ƭ�ˡ������ᵽһ���������������ٴ�Ҳ���컨�壬������Ӵ���һ����һ������������ѪƿҲƴ�����Է���һ��ʦ����˵������Ƥ����������������ʱ���Ŷӵ��������Գ����ˡ��ڻ�����Ҳ��������һ̨��ͨ�Ļ��������˵Ķ�̨��������������ͼ��
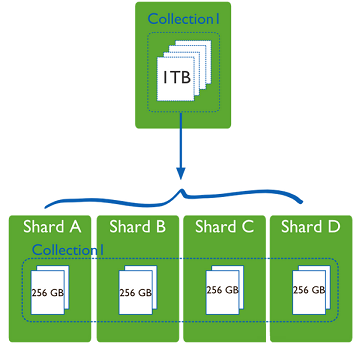
һ̨������һ�����ݱ� Collection1 �洢�� 1T ���ݣ�ѹ��̫����!�ڷָ�4��������ÿ����������256G�����̯�˼�����һ̨������ѹ����Ҳ��������һ̨����Ӳ�̼Ӵ�һ�㲻�Ϳ����ˣ�ΪʲôҪ�ָ���̨������?��Ҫ���뵽�洢�ռ䣬ʵ�����е����ݿ��Ӳ�̵Ķ�д�������IO��CPU���ڴ��ƿ������mongodb��ȺֻҪ���ú��˷�Ƭ����ͨ��mongos�������ݿ�����Զ��Ѷ�Ӧ�����ݲ�������ת������Ӧ�ķ�Ƭ�����ϡ������������з�Ƭ��Ƭ����Ҫ�ú����ã����Ӱ�쵽����ô�����ݾ��ȷֵ������Ƭ�����ϣ���Ҫ��������һ̨��������1T����������û�зֵ�����������������粻��Ƭ!
replica set���������Ѿ���ϸ�����������������ô��������������!��ʵ��ͼ4����Ƭ���û��
replica set �Ǹ��������ܹ����������е�һ����Ƭ�ҵ����ķ�֮һ�����ݾͶ�ʧ�ˣ������ڸ߿����Եķ�Ƭ�ܹ�����Ҫ����ÿһ����Ƭ����
replica set ��������֤��Ƭ�Ŀɿ��ԡ���������ͨ���� 2������ + 1���ٲá�
˵����ô�࣬������ʵսһ����δ�߿��õ�mongodb��Ⱥ��
����ȷ�����������������mongos 3���� config server
3�������ݷ�3Ƭ shard server 3����ÿ��shard ��һ������һ���ٲ�Ҳ���� 3 * 2
= 6 �����ܹ���Ҫ����15��ʵ������Щʵ�����Բ����ڶ�������Ҳ���Բ�����һ̨�������������������Դ���ޣ�ֻ����
3̨��������ͬһ̨����ֻҪ�˿ڲ�ͬ�Ϳ��ԣ���һ����������ͼ��
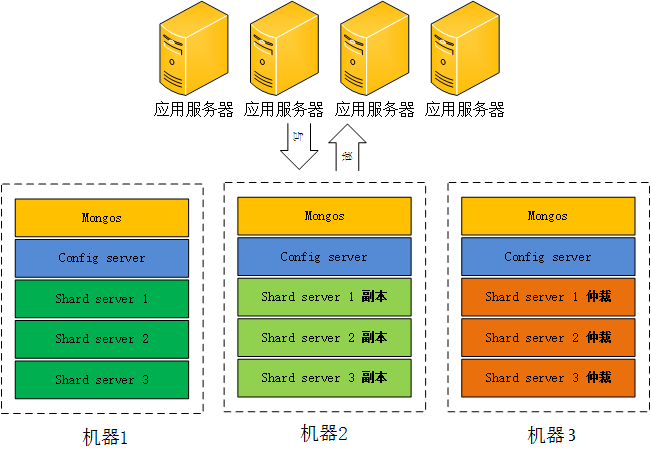
�ܹ�����ˣ���װ����!
1. ��������IP�ֱ�����Ϊ�� 192.168.0.136��192.168.0.137��192.168.0.138��
2. �ֱ���ÿ̨�����Ͻ���mongodb��Ƭ��Ӧ�����ļ��С�
#���mongodb�����ļ�
����mkdir -p /data/mongodbtest
����#����mongodb�ļ���
����cd /data/mongodbtest |
3. ����mongodb�İ�װ�����
wget http://fastdl.mongodb.org/linux/mongodb-linux-x86_64-2.4.8.tgz
����#��ѹ���ص�ѹ����
����tar xvzf mongodb-linux-x86_64-2.4.8.tgz |
4. �ֱ���ÿ̨��������mongos ��config �� shard1 ��shard2��shard3
���Ŀ¼��
��Ϊmongos���洢���ݣ�ֻ��Ҫ������־�ļ�Ŀ¼���ɡ�
#����mongosĿ¼
����mkdir -p /data/mongodbtest/mongos/log
����#����config server �����ļ����Ŀ¼
����mkdir -p /data/mongodbtest/config/data
����#����config server ��־�ļ����Ŀ¼
����mkdir -p /data/mongodbtest/config/log
����#����config server ��־�ļ����Ŀ¼
����mkdir -p /data/mongodbtest/mongos/log
����#����shard1 �����ļ����Ŀ¼
����mkdir -p /data/mongodbtest/shard1/data
����#����shard1 ��־�ļ����Ŀ¼
����mkdir -p /data/mongodbtest/shard1/log
����#����shard2 �����ļ����Ŀ¼
����mkdir -p /data/mongodbtest/shard2/data
����#����shard2 ��־�ļ����Ŀ¼
����mkdir -p /data/mongodbtest/shard2/log
����#����shard3 �����ļ����Ŀ¼
����mkdir -p /data/mongodbtest/shard3/data
����#����shard3 ��־�ļ����Ŀ¼
����mkdir -p /data/mongodbtest/shard3/log |
5. �滮5�������Ӧ�Ķ˿ںţ�����һ��������Ҫͬʱ���� mongos��config server ��shard1��shard2��shard3��������Ҫ�ö˿ڽ������֡�
����˿ڿ������ɶ��壬�ڱ��� mongosΪ 20000�� config server Ϊ 21000��
shard1Ϊ 22001 �� shard2Ϊ22002�� shard3Ϊ22003.
6. ��ÿһ̨�������ֱ��������÷�������
/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongod
--configsvr --dbpath /data/mongodbtest/config/data --port 21000
--logpath /data/mongodbtest/config/log/config.log --fork |
7. ��ÿһ̨�������ֱ�����mongos��������
/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongos --configdb
192.168.0.136:21000,192.168.0.137:21000,192.168.0.138:21000 --port
20000 --logpath /data/mongodbtest/mongos/log/mongos.log --fork |
8. ���ø�����Ƭ�ĸ�������
#��ÿ��������ֱ����÷�Ƭ1��������������shard1
/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongod
--shardsvr --replSet shard1 --port 22001 --dbpath /data/mongodbtest/shard1/data
--logpath /data/mongodbtest/shard1/log/shard1.log --fork --nojournal --oplogSize 10 |
Ϊ�˿�����������Լ���Ի����洢�ռ䣬������� nojournal ��Ϊ�˹ر���־��Ϣ�������ǵIJ��Ի�������Ҫ��ʼ����ô���redo��־��ͬ������
oplogsize��Ϊ�˽��� local �ļ��Ĵ�С��oplog��һ���̶����ȵ� capped collection,�������ڡ�local�����ݿ���,���ڼ�¼Replica
Sets������־��ע�⣬�����������Ϊ�˲���!
#��ÿ��������ֱ����÷�Ƭ2��������������shard2
/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongod
--shardsvr --replSet shard2 --port 22002 --dbpath /data/mongodbtest/shard2/data
--logpath /data/mongodbtest/shard2/log/shard2.log --fork --nojournal --oplogSize 10
#��ÿ��������ֱ����÷�Ƭ3��������������shard3
/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongod --shardsvr
--replSet shard3 --port 22003 --dbpath /data/mongodbtest/shard3/data
--logpath /data/mongodbtest/shard3/log/shard3.log --fork --nojournal --oplogSize 10 |
�ֱ��ÿ����Ƭ���ø������������˽⸱�����ο���ϵ��ǰ��ƪ���¡�
�����½һ�������������½192.168.0.136������MongoDB
#���õ�һ����Ƭ������
����/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongo 127.0.0.1:22001
����#ʹ��admin���ݿ�
����use admin
����#���帱��������
����config = { _id:"shard1", members:[
����{_id:0,host:"192.168.0.136:22001"},
����{_id:1,host:"192.168.0.137:22001"},
����{_id:2,host:"192.168.0.138:22001",arbiterOnly:true}
����]
����}
����#��ʼ������������
����rs.initiate(config);
����#���õڶ�����Ƭ������
����/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongo 127.0.0.1:22002
����#ʹ��admin���ݿ�
����use admin
����#���帱��������
����config = { _id:"shard2", members:[
����{_id:0,host:"192.168.0.136:22002"},
����{_id:1,host:"192.168.0.137:22002"},
����{_id:2,host:"192.168.0.138:22002",arbiterOnly:true}
����]
����}
����#��ʼ������������
����rs.initiate(config);
����#���õ�������Ƭ������
����/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongo 127.0.0.1:22003
����#ʹ��admin���ݿ�
����use admin
����#���帱��������
����config = { _id:"shard3", members:[
����{_id:0,host:"192.168.0.136:22003"},
����{_id:1,host:"192.168.0.137:22003"},
����{_id:2,host:"192.168.0.138:22003",arbiterOnly:true}
����]
����}
����#��ʼ������������
����rs.initiate(config); |
9. Ŀǰ���mongodb���÷�������·�ɷ�������������Ƭ������������Ӧ�ó������ӵ�
mongos ·�ɷ�����������ʹ�÷�Ƭ���ƣ�����Ҫ�ڳ��������÷�Ƭ���ã��÷�Ƭ��Ч��
#���ӵ�mongos /data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongo 127.0.0.1:20000
����#ʹ��admin���ݿ� user admin
����#����·�ɷ���������丱����1
����db.runCommand( { addshard : "shard1/192.168.0.136:22001,192.168.0.137:22001,192.168.0.138:22001"}); |
����shard�ǵ�̨���������� db.runCommand( { addshard : �� [: ]��
} )������������룬���shard�Ǹ���������db.runCommand( { addshard :
��replicaSetName/ [:port][,serverhostname2[:port],��]��
});�����ĸ�ʽ��ʾ ��
#����·�ɷ���������丱����2
����db.runCommand( { addshard : "shard2/192.168.0.136:22002,192.168.0.137:22002,192.168.0.138:22002"});
����#����·�ɷ���������丱����3
����db.runCommand( { addshard : "shard3/192.168.0.136:22003,192.168.0.137:22003,192.168.0.138:22003"});
����#�鿴��Ƭ������������
����db.runCommand( { listshards : 1 } );
����#�������
����[plain] view plaincopy{
����"shards" : [
����{
����"_id" : "shard1",
����"host" : "shard1/192.168.0.136:22001,192.168.0.137:22001"
����},
����{
����"_id" : "shard2",
����"host" : "shard2/192.168.0.136:22002,192.168.0.137:22002"
����},
����{
����"_id" : "shard3",
����"host" : "shard3/192.168.0.136:22003,192.168.0.137:22003"
����}
����],
����"ok" : 1
����} |
��Ϊ192.168.0.138��ÿ����Ƭ���������ٲýڵ㣬������������û���г�����
10. Ŀǰ���÷���·�ɷ���Ƭ�������������Ѿ����������ˣ������ǵ�Ŀ����ϣ���������ݣ������ܹ��Զ���Ƭ���Ͳ���ôһ��㣬һ��㡣����
������mongos�ϣ�����ָ�������ݿ⡢ָ���ļ��Ϸ�Ƭ��Ч��
#ָ��testdb��Ƭ��Ч
����db.runCommand( { enablesharding :"testdb"});
����#ָ�����ݿ�����Ҫ��Ƭ�ļ��Ϻ�Ƭ��
����db.runCommand( { shardcollection : "testdb.table1",key : {id: 1} } ) |
��������testdb�� table1 ����Ҫ��Ƭ������ id �Զ���Ƭ�� shard1 ��shard2��shard3
����ȥ��Ҫ������������Ϊ��������mongodb �����ݿ�ͱ� ����Ҫ��Ƭ!
11. ���Է�Ƭ���ý����
#����mongos������
����/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongo 127.0.0.1:20000
����#ʹ��testdb use testdb;
����#�����������
����for (var i = 1; i <= 100000; i++)
����db.table1.save({id:i,"test1":"testval1"});
����#�鿴��Ƭ������£���������Ϣʡ����
����db.table1.stats();
����[java] view plaincopy{
����"sharded" : true,
����"ns" : "testdb.table1",
����"count" : 100000,
����"numExtents" : 13,
����"size" : 5600000,
����"storageSize" : 22372352,
����"totalIndexSize" : 6213760,
����"indexSizes" : {
����"_id_" : 3335808,
����"id_1" : 2877952
����},
����"avgObjSize" : 56,
����"nindexes" : 2,
����"nchunks" : 3,
����"shards" : {
����"shard1" : {
����"ns" : "testdb.table1",
����"count" : 42183,
����"size" : 0,
����...
����"ok" : 1
����},
����"shard2" : {
����"ns" : "testdb.table1",
����"count" : 38937,
����"size" : 2180472,
����...
����"ok" : 1
����},
����"shard3" : {
����"ns" : "testdb.table1",
����"count" :18880,
����"size" : 3419528,
����...
����"ok" : 1
����}
����},
����"ok" : 1
����} |
���Կ������ݷֵ�3����Ƭ�����Է�Ƭ����Ϊ�� shard1 ��count�� : 42183��shard2
��count���� 38937��shard3 ��count�� : 18880���Ѿ��ɹ���!�����ֵĺ����Ǻܾ��ȣ����������Ƭ���Ǻ��н����ģ��������������ۡ�
12. Java������÷�Ƭ��Ⱥ����Ϊ��������������mongos��Ϊ��ڣ����������ĸ���ڹҵ��˶�û��ϵ��ʹ�ü�Ⱥ�ͻ��˳������£�
[java] view plaincopypublic class TestMongoDBShards { public static void main(String[] args)
����{ try { List addresses = new ArrayList();
����ServerAddress address1 = new ServerAddress("192.168.0.136" , 20000); ServerAddress
����address2 = new ServerAddress("192.168.0.137" , 20000); ServerAddress address3
����= new ServerAddress("192.168.0.138" , 20000); addresses.add(address1);
����addresses.add(address2); addresses.add(address3); MongoClient client =
����new MongoClient(addresses); DB db = client.getDB( "testdb" ); DBCollection
����coll = db.getCollection( "table1" ); BasicDBObject object = new BasicDBObject();
����object.append( "id" , 1); DBObject dbObject = coll.findOne(object); System.
����out .println(dbObject); } catch (Exception e) { e.printStackTrace(); }
����} } |
������Ƭ��Ⱥ����ˣ�˼��һ����������ܹ��Dz����㹻����?��ʵ���кܶ�ط���Ҫ�Ż����������ǰ����е��ٲýڵ����һ̨������������̨�����е���ȫ����д������������Ϊ�ٲõ�192.168.0.138�൱���С��û���3
192.168.0.138��ֵ������ΰ�!�ܹ����������������ѻ����ĸ��طֵĸ��Ӿ���һ�㣬ÿ�������ȿ�����Ϊ���ڵ㡢�����ڵ㡢�ٲýڵ㣬����ѹ���ͻ����ܶ��ˣ���ͼ��
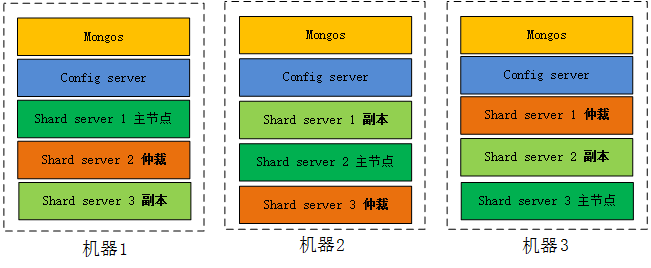
��Ȼ��������������ԶԶ���ڵ�ǰ�IJ������ݣ����ģ����Ӧ����������Dz����ܰ�ȫ���Ľڵ�����������Ӳ��ƿ����Ӳ�ˣ�ֻ����չ������Ҫ�ú�mongodb���кܶ������Ҫ����������ͨ������������ǿ��Կ���ʵ�ָ߿����ԡ�����չ�ԣ�����������һ���dz�������Nosql�����
�ٿ�������ʹ�õ�mongodb java �����ͻ��� MongoClient(addresses)��������Դ�����mongos
�ĵ�ַ��Ϊmongodb��Ⱥ����ڣ����ҿ���ʵ���Զ�����ת�ƣ����Ǹ��ؾ������ĺò�����?��Դ����鿴��

���Ļ�����ѡ��һ��ping ���Ļ�������Ϊ�����������ڣ������̨�����ҵ���ʹ����һ̨���������������������϶��Dz��е�!��һ����˫ʮһ������������������з��͵���һ̨��������̨�������п��ܹҵ���һ���ҵ��ˣ��������Ļ��ƻ�ת��������̨�������������ѹ����������û�м��ٰ�!��һ̨���ǿ��ܱ�������������ܹ�����©��!��������ƪ����������������
|





