| 1.����
��Hadoop2.x֮��İ汾������˽����������ķ�������HA��High Available �߿��ã�����ƪ���Ͳ�����δ�߿��õ�HDFS��YARN��
2.�
2.1����Hadoop�û�
useradd hadoop
passwd hadoop |
Ȼ�������ʾ���������롣�����Ҹ�hadoop�û�������������Ȩ�ޣ�Ҳ��������������Ȩ�ޡ�
chmod +w /etc/sudoers
hadoop ALL=(root)NOPASSWD:ALL
chmod -w /etc/sudoers |
2.2��װJDK
�����غõİ�װ����ѹ�� /usr/java/jdk1.7��Ȼ�����û����������������£�
Ȼ��༭���ã��������£�
export JAVA_HOME=/usr/java/jdk1.7
export PATH=$PATH:$JAVA_HOME/bin |
Ȼ��ʹ��������������Ч���������£�
Ȼ����֤JDK�Ƿ����óɹ����������£�
����ʾ��Ӧ�汾�ţ�����ʾJDK���óɹ�������������Ч��
2.3����hosts
��Ⱥ�����л�����hosts����ҪҪ��ͬ���Ƽ��������Ա��ⲻ��Ҫ���鷳��������ȡ��IP���������á�������Ϣ���£�
10.211.55.12 nna����# NameNode Active
10.211.55.13 nns����# NameNode Standby
10.211.55.14 dn1����# DataNode1
10.211.55.15 dn2����# DataNode2
10.211.55.16 dn3����# DataNode3 |
Ȼ����scp�����hosts���÷ַ��������ڵ㡣�������£�
�� ������NNS�ڵ�Ϊ����
scp /etc/hosts hadoop@nns:/etc/ |
2.4��װSSH
�����������
Ȼ��һ·���س���������ڽ�id_rsa.pubд��authorized_keys���������£�
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys |
��hadoop�û��£���Ҫ��authorized_keys����600��Ȩ�ޣ���Ȼ�������½��Ч���������ڵ�ֻ��Ҫʹ��
ssh-keygen �Ct rsa ���������Ӧ�Ĺ�Կ��Ȼ�����ڵ��id_rsa.pub�ӵ�nna�ڵ��authorized_keys�С����nna�ڵ��µ�authorized_keys�ļ�ͨ��scp����ַ��������ڵ��
~/.ssh/ Ŀ¼�¡�Ŀ¼���£�
# ������NNS�ڵ�Ϊ����
scp ~/.ssh/authorized_keys hadoop@nns:~/.ssh/ |
Ȼ��ʹ��ssh�������¼�����Ƿ�ʵ�����������¼����¼�������£�
# ������nns�ڵ�Ϊ����
ssh nns |
����¼������ľ����ʾ��Ҫ�������룬����ʾ�������óɹ���
2.5�رշ���ǽ
����hadoop�Ľڵ�֮����Ҫͨ�ţ�RPC���ƣ�������һ������Ҫ������Ӧ�Ķ˿ڣ������Ҿ�ֱ�ӽ�����ǽ�ر��ˣ��������£�
ע�������������������ֱ�ӹرշ���ǽ�Ǵ��ڰ�ȫ�����ģ����ǿ���ͨ�����÷���ǽ�Ĺ��˹�����hadoop��Ҫ��������Щ�˿����õ�����ǽ���ܹ����С����ڷ���ǽ�Ĺ������òμ���linux����ǽ���á�������֪ͨ��˾����άȥ��æ���ù�����
ͬʱ��Ҳ��Ҫ�ر�SELinux������ /etc/selinux/config �ļ��������е� SELINUX=enforcing
��Ϊ SELINUX=disabled���ɡ�
2.6��ʱ��
�����ڵ��ʱ�������ͬ��������������쳣��������ԭ�����ォʱ��ͳһ����ΪShanghaiʱ�����������£�
# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
cp: overwrite `/etc/localtime'? yes
��Ϊ�й��Ķ�����
# vi /etc/sysconfig/clock
ZONE="Asia/Shanghai"
UTC=false
ARC=false |
2.7ZK����װ����������֤��
2.7.1��װ
�����غõİ�װ������ѹ��ָ��λ�ã�����Ϊֱ�ӽ�ѹ����ǰλ�ã��������£�
tar -zxvf zk-{version}.tar.gz |
��zk���ã���zk��װĿ¼��conf/zoo_sample.cfg������zoo.cfg�������е����ݣ�
# The number of milliseconds of each tick
# ��������ͻ���֮�佻���Ļ���ʱ�䵥Ԫ��ms��
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
# zookeeper���ܽ��ܵĿͻ�������
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
# �������Ϳͻ���֮�������Ӧ��֮���ʱ����
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
# ����zookeeper���ݣ���־��·��
dataDir=/home/hadoop/data/zookeeper
# the port at which the clients will connect
# �ͻ�����zookeeper������Ķ˿�
clientPort=2181
server.1= dn1:2888:3888
server.2= dn2:2888:3888
server.3= dn3:2888:3888
#server.A=B:C:D ����A��һ�����֣��������ǵڼ��ŷ�������
B�Ƿ�������IP��ַ��C��ʾ��������Ⱥ���еġ��쵼�ߡ�������Ϣ�Ķ˿ڣ�
���쵼��ʧЧ��D��ʾ����ִ��ѡ��ʱ�������ͨ�ŵĶ˿ڡ� |
�������������õ�dataDirĿ¼�´���һ��myid�ļ�������д��һ��0-255֮���һ���������֣�ÿ��zk������ļ�������Ҫ�Dz�һ���ģ���Щ����Ӧ���Ǵ�1��ʼ������дÿ�����������ļ������Ҫ��dn�ڵ��µ�zk�������һֱ���磺server.1=dn1:2888:3888����ôdn1�ڵ��µ�myid�����ļ�Ӧ��д��1��
2.7.2����
�ֱ��ڸ���dn�ڵ�����zk���̣��������£�
Ȼ���ڸ����ڵ�����jps�����������½��̣�
2.7.3��֤
����˵������jps�������ʾ��Ӧ�Ľ��̣�����ʾ�����ɹ���ͬ������Ҳ��������zk��״̬����鿴���������£�
�����һ��leader������follower��
2.8HDFS��HA�Ľṹͼ
HDFS����HA�Ľṹͼ������ʾ��
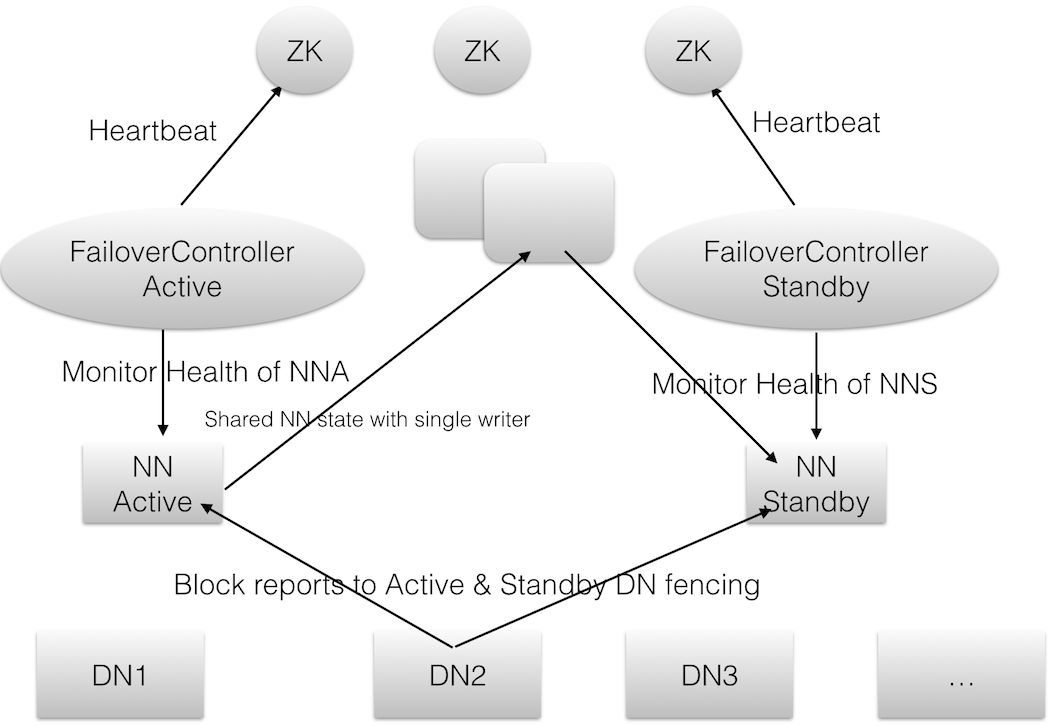
��ͼ���¼ܹ�������
1. ���ù����洢��������NN��ͬ��edits��Ϣ����ǰ��HDFS��share nothing but
NN������NN��share storage��������ʵ��ת���˵�����ϵ�λ�ã����и߶˵Ĵ洢�豸�ڲ����и���RAID�Լ�����Ӳ����������Դ�Լ������ȣ��ȷ������Ŀɿ��Ի���������ߡ�ͨ��NN�ڲ�ÿ��Ԫ���ݱ䶯���flush����������NFS��close-to-open�����ݵ�һ���Եõ��˱�֤��
2. DNͬʱ������NN�㱨����Ϣ��������Standby NN���ּ�Ⱥ������״̬�ı��벽�衣
3. ���ڼ��ӺͿ���NN���̵�FailoverController���̡���Ȼ�����Dz�����NN�����ڲ�������������Ϣͬ�������ԭ��һ��FullGC�Ϳ�����NN����ʮ�����ӣ����ԣ�����Ҫ��һ�������Ķ�С������watchdog��ר�Ÿ����ء���Ҳ��һ������ϵ���ƣ�������չ����ģ�Ŀǰ�汾������ZooKeeper�����ZK������ͬ���������û����Է���İ����Zookeeper
FailoverController�����ZKFC���滻Ϊ������HA������leaderѡ�ٷ�����
4. ���루Fencing������ֹ���ѣ����DZ�֤���κ�ʱ��ֻ��һ����NN�������������棺
�����洢fencing��ȷ��ֻ��һ��NN����д��edits��
�ͻ���fencing��ȷ��ֻ��һ��NN������Ӧ�ͻ��˵�����
DN fencing��ȷ��ֻ��һ��NN��DN�·����Ʃ��ɾ���飬���ƿ�ȵȡ�
2.9��ɫ����
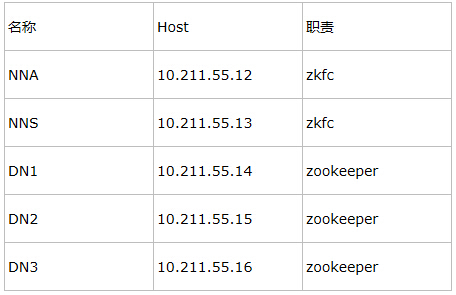
2.10������������
�����г������е����ã���������������������Բο���������á� ������ɺ����룺. /etc/profile����source
/etc/profile��ʹ֮������Ч����֤�����������óɹ�������룺echo $HADOOP_HOME���������Ӧ������·���������϶����óɹ���
ע��hadoop2.x�Ժ�İ汾conf�ļ��и�Ϊetc�ļ�����
��������������ʾ��
export JAVA_HOME=/usr/java/jdk1.7
export HADOOP_HOME=/home/hadoop/hadoop-2.6.0
export ZK_HOME=/home/hadoop/zookeeper-3.4.6
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOM |
2.11�����ļ�����
ע�������ر����ѣ������ļ��е�·����������Ⱥ֮ǰ���ô��ڣ��������ڣ������ȴ�����������Ϊ������ƪ������Ҫ������·���ű����������£�
mkdir -p /home/hadoop/tmp
mkdir -p /home/hadoop/data/tmp/journal
mkdir -p /home/hadoop/data/dfs/name
mkdir -p /home/hadoop/data/dfs/data
mkdir -p /home/hadoop/data/yarn/local
mkdir -p /home/hadoop/log/yarn |
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>dn1:2181,dn2:2181,dn3:2181</value>
</property>
</configuration>
|
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>dfs.nameservices</name>
<value>cluster1</value>
</property>
<property>
<name>dfs.ha.namenodes.cluster1</name>
<value>nna,nns</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster1.nna</name>
<value>nna:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster1.nns</name>
<value>nns:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster1.nna</name>
<value>nna:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster1.nns</name>
<value>nns:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://dn1:8485;dn2:8485;dn3:8485/cluster1</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/data/tmp/journal</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.journalnode.http-address</name>
<value>0.0.0.0:8480</value>
</property>
<property>
<name>dfs.journalnode.rpc-address</name>
<value>0.0.0.0:8485</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>dn1:2181,dn2:2181,dn3:2181</value>
</property>
</configuration>
|
map-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>nna:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>nna:19888</value>
</property>
</configuration> |
yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>dn1:2181,dn2:2181,dn3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>nna</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>nns</value>
</property>
<!--��namenode1������rm1,��namenode2������rm2,ע�⣺
һ�㶼ϲ�������úõ��ļ�Զ�̸��Ƶ����������ϣ�
�������YARN����һ��������һ��Ҫ�� -->
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
<!--�����Զ��ָ����� -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--������zookeeper�����ӵ�ַ -->
<property>
<name>yarn.resourcemanager.zk-state-store.address</name>
<value>dn1:2181,dn2:2181,dn3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>dn1:2181,dn2:2181,dn3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1-yarn</value>
</property>
<!--scheldulerʧ���ȴ�����ʱ�� -->
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<!--����rm1 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>nna:8132</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>nna:8130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>nna:8188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>nna:8131</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>nna:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>nna:23142</value>
</property>
<!--����rm2 -->
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>nns:8132</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>nns:8130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>nns:8188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>nns:8131</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>nns:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm2</name>
<value>nns:23142</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/home/hadoop/data/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/home/hadoop/log/yarn</value>
</property>
<property>
<name>mapreduce.shuffle.port</name>
<value>23080</value>
</property>
<!--���ϴ����� -->
<property>
<name>yarn.client.failover-proxy-provider</name>
<value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.zk-base-path</name>
<value>/yarn-leader-election</value>
</property>
</configuration> |
hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/usr/java/jdk1.7 |
yarn-env.sh
# some Java parameters
export JAVA_HOME=/usr/java/jdk1.7 |
2.12slave
��hadoop��װĿ¼�µ�slave�ļ���
2.13�������hdfs��yarn��������
��������������QJM������������Ҫ������QJM�ķ�������˳��������ʾ��
1.���뵽DN�ڵ㣬����zk�ķ���zkServer.sh start��֮���������zkServer.sh
status�鿴����״̬��������������������DN�ڵ㣬�����һ��leader������follower������jps������ʾ�������̣�QuorumPeerMain
2.��NN�ڵ��ϣ�ѡһ̨���ɣ�������ѡ�����һ̨ԤNNA�ڵ㣩��Ȼ������journalnode�����������£�hadoop-daemons.sh
start journalnode�����ߵ������뵽ÿ��DN�����������hadoop-daemon.sh
start journalnode������jps��ʾ�������̣�JournalNode��
3.�����������ú������״���������Ҫ��ʽ��HDFS���������£�hadoop
namenode �Cformat��
4.֮��������Ҫ��ʽ��ZK���������£�hdfs zkfc �CformatZK��
5.������������hdfs��yarn���������£�start-dfs.sh��start-yarn.sh��������nna����jps�鿴���̣���ʾ���£�DFSZKFailoverController��NameNode��ResourceManager��
6.����������NNS����jps�鿴������ֻ��DFSZKFailoverController���̣�����������Ҫ�ֶ�����NNS�ϵ�namenode��ResourceManager���̣��������£�hadoop-daemon.sh
start namenode��yarn-daemon.sh start resourcemanager����Ҫע����ǣ���NNS�ϵ�yarn-site.xml�У���Ҫ����ָ��NNS����������Ϊrm2����NNA�����õ���rm1��
7.���������Ҫͬ��NNA�ڵ��Ԫ���ݣ��������£�hdfs namenode
�CbootstrapStandby����ִ����������־�����ʾ������Ϣ��
15/02/21 10:30:59 INFO common.Storage:
Storage directory /home/hadoop/data/dfs/name has been successfully formatted.
15/02/21 10:30:59 WARN common.Util: Path /home/hadoop/data/dfs/name
should be specified as a URI in configuration files. Please update hdfs configuration.
15/02/21 10:30:59 WARN common.Util: Path /home/hadoop/data/dfs/name
should be specified as a URI in configuration files. Please update hdfs configuration.
15/02/21 10:31:00 INFO namenode.TransferFsImage: Opening connection to
http://nna:50070/imagetransfer?getimage=1&txid=0&storageInfo=-60:1079068934:0:
CID-1dd0c11e-b27e-4651-aad6-73bc7dd820bd
15/02/21 10:31:01 INFO namenode.TransferFsImage:
Image Transfer timeout configured to 60000 milliseconds
15/02/21 10:31:01 INFO namenode.TransferFsImage:
Transfer took 0.01s at 0.00 KB/s
15/02/21 10:31:01 INFO namenode.TransferFsImage:
Downloaded file fsimage.ckpt_0000000000000000000 size 353 bytes.
15/02/21 10:31:01 INFO util.ExitUtil: Exiting with status 0
15/02/21 10:31:01 INFO namenode.NameNode: SHUTDOWN_MSG:
/*** SHUTDOWN_MSG: Shutting down NameNode at nns/10.211.55.13 ***/ |
2.14HA���л�
���������õ����Զ��л�����NNA�ڵ�崵���NNS�ڵ��������standby״̬�л�Ϊactive״̬���������õ��ֶ�״̬����������������������˹��л���
hdfs haadmin -failover --forcefence --forceactive nna nns |
�����������˼�ǣ���nna���standby��nns���active�������ֶ�״̬����Ҫ��������
2.15Ч����ͼ
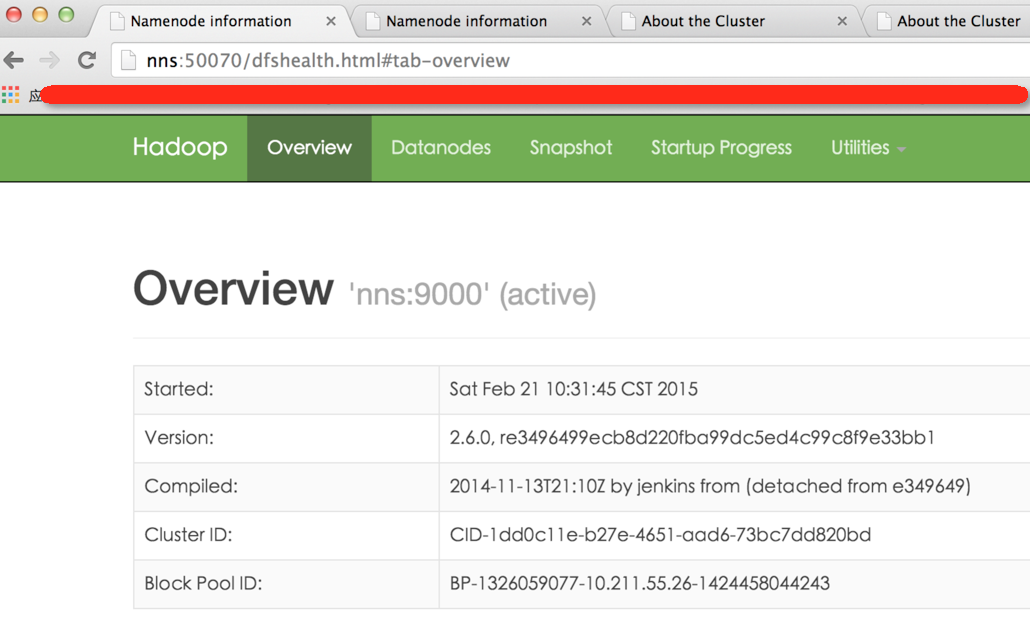
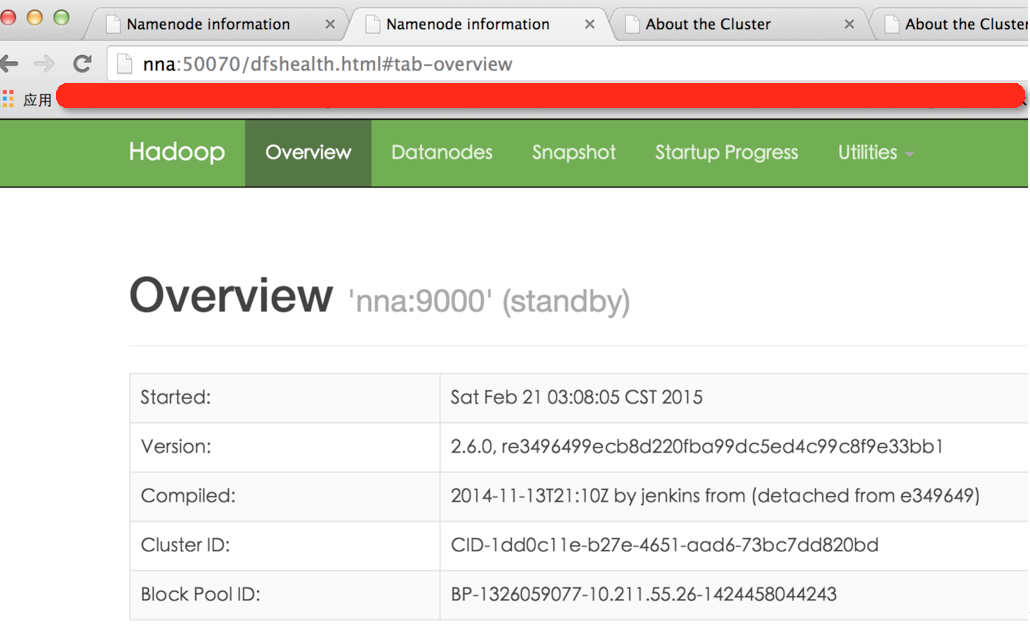
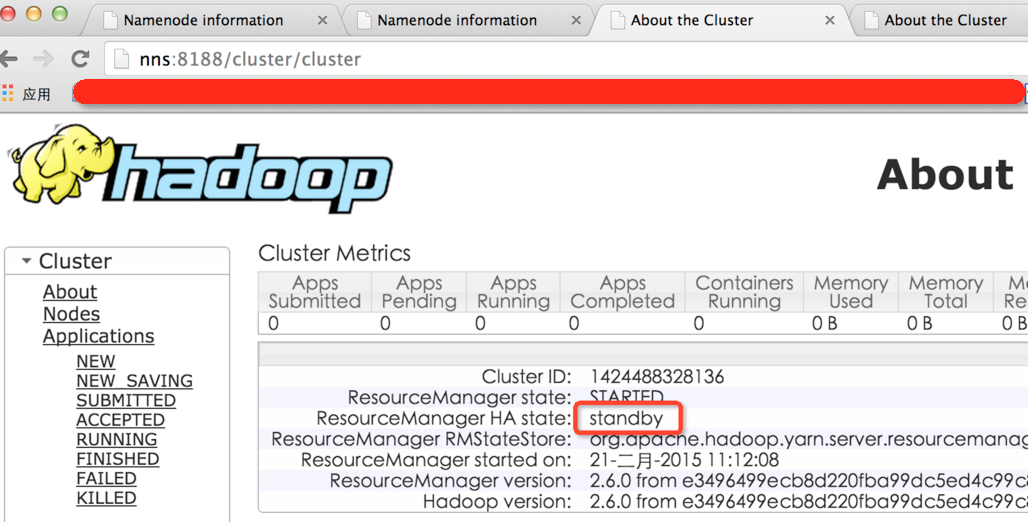
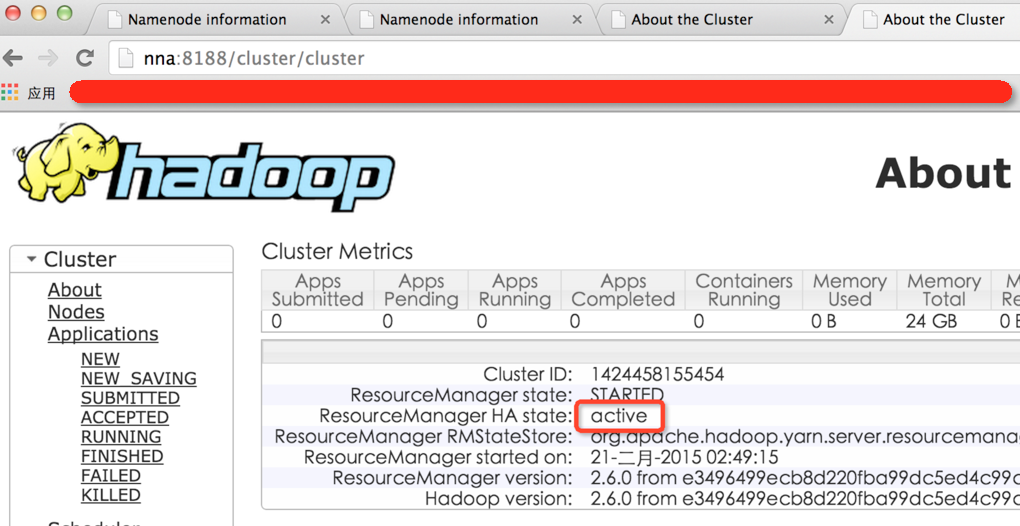
3.�ܽ�
��ƪ���¾���������������ù�������ʲô���ʻ����⣬���Լ���QQȺ���ۻ����ʼ����ң��һᾡ������Ϊ�����������㣡
|





