| 传统互联网正在迈向一个全新的时代――社交服务网(Social
Networking Service)时代,从“人与机器”的时代迈向“人与人”的时代。互联网社交服务网站的发展验证了“六度分隔理论”(Six
Degrees of Separation),即“人际关系脉络方面你必然可以通过不超出六位中间人间接与世上任意先生女士相识”。个体的社交圈会不断地扩大和重叠并最终形成大的社交网络。无论是国外的Facebook、MySpace、Twitter,还是国内的开心网、人人网等都一头扎进社交网,因为他们认定社交网必然掀起新一轮的互联网革命。
社交网的一个显著特点是支持巨大用户数,例如Facebook支持超过3亿的用户,其数据中心运行着超过万台的服务器,为遍布全球的用户提供信息通讯服务。另外,任何两个社交网用户都可能交互,也就是必须支持任何两个数据库用户的数据关联操作。这对于服务端的数据库管理提出了极大的挑战。
关系数据库与 NoSQL 数据库
关系数据库使用者遵循一些数据库范式,这些范式是数据库设计中的一系列原理和技术,目的是为了减少数据库中数据冗余和增进数据的一致性。结构化查询语言SQL大量使用多表连接操作,SQL的通用性可以为使用者带来很多方便。
随着越来越多大规模工作负荷应用的发行,对可伸缩性的需求,可能会变得非常迅速和无比庞大。
关系数据库的确能伸缩自如,但通常只能在单台服务器节点上进行。例如采用表分区技术,一个表格可以由多个物理文件组成,虽然表格的容量增大了,但该表格仍然只能由一数据库引擎管理;另外增加一物理文件时,表格Schema得做改动,也就是还不能支持动态扩容。
一旦单节点的能力抵达上限,就得通过多服务器节点来扩展来分发负载。这时关系数据库的复杂性就开始影响其潜在的扩展规模了。RDBMS支持分区视图(Partition
View) 技术,也就是支持联合数据库(Federated Database)(如图1)。一个分区视图可以由多个分布在不同数据库节点服务器上的表格组合而成,数据库用户看到的只是该视图,不必关心物理表格。通过数据水平分割技术,分区视图把负载分担到多个数据库节点服务器上。扩容时,该方法除了需改动视图定义外,分区视图成为分布式数据库系统的中心,存在单点故障问题。另外,跨数据库节点之间多表格间连接操作的支持出现极大困难。

图1 IBM联邦数据库的体系结构
当试图扩展数据库系统到成百上千个节点时,将导致不堪复杂性之重负,这一特点使得RDBMS在大型分布式系统平台市场里的生存能力被大幅削减。
为了能向客户提供一个伸缩自如的空间存放应用数据,供应商实际上只有一种真正的选择――实现一种新型的专注于可扩展性的数据库系统,而牺牲掉关系数据库所带来的其他好处。NoSQL是非关系型数据存储的广义定义,它打破了长久以来关系型数据库与ACID理论大一统的局面。NoSQL数据存储不需要固定的表结构,通常也不存在连接操作,在超大型数据存取上具备关系型数据库无法比拟的性能优势。该术语在2009
年初得到了广泛认同,其中Key-Value数据模型是解决大型数据库系统扩充问题的一种可行的解决方案。
Berkeley DB Key-Value数据模型
Berkeley DB是一种支持Key-Value数据模型的嵌入式数据库存储引擎。它不支持Client/Server网络访问方式,程序通过进程内的API访问数据库,不支持SQL或者其他数据库查询语言,不支持表结构和数据列。访问数据库的程序自主决定数据如何储存在记录里,一条记录由一个称为键(Key)的数据块和一个称为值(Value)的数据块组成。Berkeley
DB不对记录里的数据进行任何包装。应用程序可通过回调函数来定义不同键之间的大小关系,记录和它的键都可以达到4GB的长度。尽管架构简单,Berkeley
DB却支持很多高级的数据库特性,比如ACID 数据库事务处理、细粒度锁、 XA接口、热备份以及同步复制。Berkley
DB为不同用户提供多种功能集(Feature Set):支持单个写线程的数据存储(Data Store);支持多并发写线程的并发数据存储(Concurrent
Data Store);支持ACID和灾难恢复的事务数据存储(Transactional Data Store);通过复制支持容错的高可靠数据存储(High
Availability)。
关系数据库系统由存储引擎和关系引擎两个独立部分组成。存储引擎负责记录存储、索引和事务处理,关系引擎负责基于存储引擎提供的服务,分析SQL、制定查询执行计划等。Berkeley
DB是一种存储引擎。例如MySQL数据库可采用MyISAM、InnoDB、Berkeley DB等存储引擎,如图2所示。
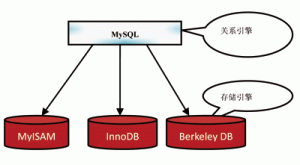
图2 MySQL使用的不同的存储引擎
Berkeley DB支持平衡树(BTree)、哈希(Hash)、队列(Queue)和记录(Record)等数据集存储和索引方式,还支持根据Key-Value中的Key创建集群索引(Clustered
Index)。这样记录集的物理次序就根据Key值大小来排列。如果要查询结果记录集的键值为给定的一个范围,该特性对于支持这种类型的快速查询起了很大作用。Berkeley
DB的一个Key-Value记录集称为一个数据库,会存储在一个单独文件中。Berkeley DB通过创建辅助数据库(Secondary
Database),允许对记录集建立非集群索引(Non-Clustered Index)。非集群索引适用于快速查询结果为一条记录,该记录的键值为给定的一个值。例如社交网用户数据集:
User <UID, First_Name, Last_Name, Icon, E-mail>
如果以UID作为主数据库的键,其他字段作为主数据库的值,可再创建一个辅助数据库,以E-mail作为辅助数据库的键,辅助数据库的值为E-mail所对应的UID,也就是指向主数据库记录的指针。若在一个Key-Value数据库查询,一般可根据查询条件创建成一个键值,引擎返回一个游标(Cursor),该游标指向等于或大于该键值的结果数据集。
不难看出Berkeley DB使用的索引技术与SQL Server、Oracle等高端数据库系统是一样的。RDBMS中经常使用的表格连接操作,在Berkeley
DB中不再支持,需要应用程序去实现两个数据集的连接操作。这是Key-Value数据模型与关系数据模型典型的区别。
Berkeley DB除了作为MySQL的存储引擎之外,还应用在OpenLDAP、MemCached等知名软件。
与Berkeley DB类似的数据库引擎还有Tokyo Cabinet/ Tyrant等。
社交网数据库系统Cassandra
以Facebook用户数据集为例,不可能把3亿条数据集存放在同一个表格、文件或由同一台计算机处理,这要求系统能支持数据分区,把数据集分割在多台节点计算机中,每台计算机分担一部分负载,当用户增加到一定程度时,系统能允许加入新的节点计算机,并且尽可能地减少数据迁移。
2007年10月30日,Amazon的CTO Werner Vogels发表了一篇文章,讨论了一种基于Key-Value数据模型的存储系统Dynamo。该系统支撑了不少Amazon的面向电子商务等关键性应用,它采用的存储引擎是
Berkeley DB 事务数据存储(Transactional Data Store)。Dynamo系统主要为存储1M左右甚至更小的内容,如购物车、推荐列表等。Dynamo设计上有下面一些特点。
1.通过数据分区复制来支持高可靠性与高可伸缩性。
2.始终可写。
3.一致性与写入速度的折中,不要求同步写入所有副本。
4.对称,完全去中心化,人工管理工作很小。
Cassandra DB最初由Facebook开发,后来转变成为开源项目。它是一个为网络社交云计算设计的数据库,主要特点是它不再是一个数据库,而是由一堆数据库节点共同构成的一个分布式网络服务,对Cassandra的一个写操作会被复制到其他节点上去,对Cassandra的读操作也会被路由到某个节点上面去读取。对于Cassandra群集来说,扩展性能是比较简单的事情,只管在群集里面添加节点就可以了。
Cassandra的用户包括Facebook、Twitter和Digg等。Digg工程副总裁John
Quinn说:“Cassandra采用完全分散的模式,每个节点都一样,不会出现单点故障。它的容错率也非常高,数据可以被复制到数据中心的多个节点中。它还非常具有弹性,随着新设备的加入,其读写吞吐量将呈线性增加。”
Cassandra以Amazon专有的完全分布式的Dynamo为基础,结合了Google BigTable基于列族(Column
Family)的数据模型。P2P去中心化的存储。很多方面都可以称之为Dynamo 2.0。
图3为Cassandra、Dynamo、Key-Value之间的关系及在社交网上的应用。箭头表示依赖关系。
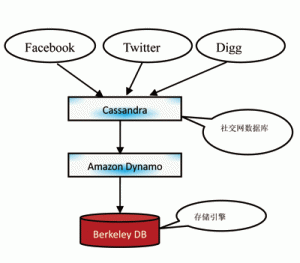
图3 Cassandra、Dynamo、Key-Value关系图
分布式存储系统Dynamo
Dynamo采用Consistent Hashing算法来实现数据分区。
Consistent Hashing基本原理是:首先求出服务器节点的哈希值,并将其配置到0~2^32的圆上。然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。再从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过2^32仍然找不到服务器,就会保存到第一台服务器上。如图4所示。
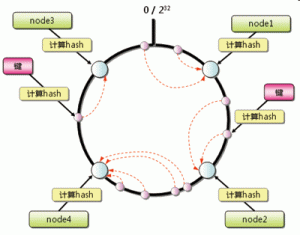
图4 数据分割到4个节点数据库
如果添加一台服务器。只有在圆上,增加服务器的地点逆时针方向的第一台服务器上的部分数据需要迁移到新的节点数据库。如图5所示。
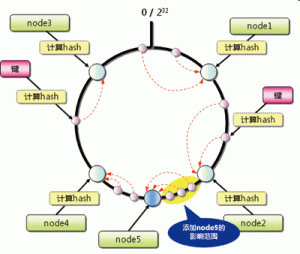
图5 添加Node5后需要迁移的数据
数据分区后,数据块被复制到N个节点上。复制时因为更新产生的一致性问题的维护采取类似拜占庭容错Quorum协议(Byzantine
Fault-tolerance Quorum)的机制以及去中心化的复制同步协议。当一个存储节点被认为是拜占庭节点时,它的行为可能任意偏移,表现在:拒绝响应请求、发送错误消息、存储错误信息。Quorum协议中除了N之外还有两个关键参数:R与W。R代表一次成功的读取操作中最小参与节点数量,W代表一次成功的写操作中最小参与节点数量。R和W直接影响性能、一致性。R
和 W 值过小则影响一致性,过大则影响效率,这两个值要平衡。如果W设置为1,则一个实例中只要有一个节点可写就写成功,不会影响写效率;如果R设置为1,只要有一个节点可读,就读成功,不会影响读效率。
Facebook数据库查询语言:FQL
Facebook为开发者提供一套和SQL风格一致的数据库查询语言,称为Facebook Query
Language (FQL)。FQL是一种基于列的数据查询语言。提供丰富的条件查询,甚至包括子查询。
例如,以下FQL查询已安装Facebook应用程序的用户$app_user的好友ID集合:
SELECT uid FROM user WHERE is_app_user = 1 AND
uid IN (SELECT uid2 FROM friend WHERE uid1 = $app_user) |
与SQL重要区别是FQL不支持:
多表连接:JOIN操作
分组: GROUP BY操作
排序:ORDER BY操作
随着技术发展,一部分基于列结构的NoSQL数据库开始支持分租、排序等复杂数据统计分析功能。
举例:查询好友信息
Facebook应用程序从以下两个数据集中查找一用户的好友数据集信息:
User <UID,First_Name, Last_Name, Icon>
Friend_List <UID, Friend_UID>
注Friend_UID是一指向User(UID)的外键。RDBMS应用程序可使用数据集连接操作实现:
SELECT f.UID, u.Friend_UID, u.First_Name, u.Last_Name, u.Icon
FROM Friend_List f, User u
WHERE f.Friend_UID = u.UID AND
f.UID=@Input_UID |
在社交网数据库系统中,由于User数据分布在多台服务器中,其连接操作和外键约束实际上不能支持。
在Facebook中查找一用户的好友信息,得分A、B两步操作实现:
A步
SELECT Friend_UID
INTO @Out_Record_Set
FROM Friend_List f
WHERE f.UID=@Input_UID |
B步
FOR EACH (Friend_UID in @Out_Record_Set)
SELECT u.Friend_UID, u.First_Name, u.Last_Name, u.Icon
FROM User u
WHERE u.UID = Friend_UID |
No-SQL: Not Only SQL
对于那些关系复杂的数据处理和分析统计,SQL值得花钱。但当数据库结构非常简单时,SQL可能没有太大用处。如果能用普通文件存储代替数据库系统的话,优选普通文件存储。
对于社交网,能够不受限制的扩展比更丰富的功能更加重要。建立大规模社交网成本的压力让很多社交网开发人员努力去寻找更高性价比的解决方案。研究表明基于普通廉价硬件的分布式存储解决方案比现在的高端数据库更加可靠。支持SQL的RDBMS不能解决所有问题的时候,NoSQL不是简单的No
SQL,其本质是Non-Relational,这时候NoSQL也就成为Not Only SQL。 |





