| ����
MapReduce �㷨
һ����Ȥ������
��������һ�������ж����ź��ҡ�ֱ�۷�ʽ��һ��һ�ż�鲢�������ж������Ǻ��ң�

MapReduce�������ǣ�
������������������������
��ÿ��������Լ����е����м����Ǻ��ң�Ȼ��������Ŀ�㱨����
���������Ҹ���������ּ��������õ����Ľ���
���
MapReduce�ϲ������־��亯����
ӳ�䣨Mapping���Լ������ÿ��Ŀ��Ӧ��ͬһ�������������������ѱ�����ÿ����Ԫ����Զ�����ô���������������Ӧ����ÿ����Ԫ���ϵIJ���������mapping��
����Reducing �����������е�Ԫ��������һ���ۺϵĽ�����������������һ�����ֵĺ������������reducing��
�����������������
������������ԭ���Ǹ���ɢֽ�Ƶ����ӣ�������MapReduce���ݷ����Ļ���������������ʾ���ⲻ�Ǹ��Ͻ������ӡ������������˴������������Ϊ����ͬʱ���������������Ǹ���Ⱥ���ڴ����ʵ��Ӧ���У����Ǽ��������Ѿ���ÿ̨���������
�C Ҳ����˵���Ʒַ���ȥ������MapReduce��һ��������ʵ�ϣ��ڼ������Ⱥ����δ洢�ļ���Hadoop���������ġ���
ͨ�����Ʒָ������Ҳ��������Ǹ�������������ڲ���ִ�����㣬��Ϊÿ����Ҷ���ͬʱ��������ͬʱ�����������˷ֲ�ʽ�ģ���Ϊ�����ͬ�����ڽ��ͬһ������Ĺ����в�����Ҫ֪�����ǵ��ھ��ڸ�ʲô��
ͨ������ÿ����ȥ���������һ����ÿ���Ƶ����������ӳ�䡣 �㲻�������ǰѺ����Ƶݸ��㣬���������ǰ�����Ҫ�Ķ�������Ϊһ�����֡�
����һ������˼��������Ʒ�����ж���ȡ�MapReduce����������ϴ���ģ�shuffled��- ������к��Ҷ��ֵ���һ�������ϣ��������ƵĹ��̿��ܱ�������Ҫ���ܶࡣ
������㹻���˵Ļ�����һЩ����Ȥ��������൱���� - ���硰һ���Ƶ�ƽ��ֵ����ʮһ���㷨����ʲô���������ͨ���ϲ��������Ƶ�ֵ�ĺ���ʲô�����������ж������ơ��������������õ��𰸡�������ͳ����Ƶ������͵õ���ƽ��ֵ��
MapReduce�㷨�Ļ���ҪԶ���⸴�ӵö࣬��������˼����һ�µ� �C
ͨ����ɢ�����������������ݡ�������Facebook��NASA������С��ҵ��˾��MapReduce����Ŀǰ�����������������ݵ�����������
Hadoop�е�MapReduce
���ģ���ݴ���ʱ��MapReduce�����������ϵĻ�����˼
1����ζԸ������ݴ������ֶ���֮
����䲻���м���������ϵ�Ĵ����ݣ�ʵ�ֲ�������Ȼ�İ취���Dz�ȡ�ֶ���֮�IJ���
2������������ģ�ͣ�Mapper��Reducer
MPI�Ȳ��м��㷽��ȱ�ٸ߲㲢�б��ģ�ͣ�Ϊ�˿˷���һȱ�ݣ�MapReduce�����Lisp����ʽ�����е�˼�룬��Map��Reduce���������ṩ�˸߲�IJ��б�̳���ģ��
3�����������ܣ�ͳһ���ܣ�Ϊ����Ա����ϵͳ��ϸ��
MPI�Ȳ��м��㷽��ȱ��ͳһ�ļ�����֧�֣�����Ա��Ҫ�������ݴ洢�����֡��ַ�������ռ�������ָ������ϸ�ڣ�Ϊ�ˣ�MapReduce��Ʋ��ṩ��ͳһ�ļ����ܣ�Ϊ����Ա�����˾������ϵͳ����Ĵ���ϸ��
1.�Ը������ݴ���-�ֶ���֮
ʲô���ļ�������ɽ��в��л����㣿
���м���ĵ�һ����Ҫ��������λ��ּ�����������������Ա�Ի��ֵ�����������ݿ�ͬʱ���м��㡣��һЩ��������ǡǡ�����������Ļ��֣�
Nine women cannot have a baby in one month!
���磺Fibonacci����: Fk+2 = Fk + Fk+1
ǰ��������֮����ں�ǿ��������ϵ��ֻ�ܴ��м��㣡
���ۣ����ɷֲ�ļ�������������������ϵ�����������в��м��㣡
�����ݵIJ��л�����
һ�������������Է�Ϊ����ͬ��������̵����ݿ飬������Щ���ݿ�֮�䲻��������������ϵ������ߴ����ٶȵ���ð취���Dz��м���
���磺������һ�����2ά������Ҫ����(������ÿ��Ԫ�صĿ�����)�����ж�ÿ��Ԫ�صĴ�������ͬ��,��������Ԫ�ؼ䲻��������������ϵ,���Կ��Dz�ͬ�Ļ��ַ������仮��Ϊ������,��һ�鴦�������д���



2.��������ģ��-Map��Reduce
�������ʽ�������Lisp�����˼��
?����ʽ�������(functional programming)����Lisp��һ���б����� ����(List
processing)����һ��Ӧ�����˹����ܴ����ķ���ʽ���ԣ���MIT���˹�����ר�ҡ�ͼ�齱�����John
McCarthy��1958����Ʒ�����
?Lisp�����˿ɶ��б�Ԫ�ؽ������崦���ĸ��ֲ������磺
�磺(add #(1 2 3 4) #(4 3 2 1)) ����������� #(5 5 5 5)
?Lisp��Ҳ�ṩ��������Map��Reduce�IJ���
��: (map ��vector #+ #(1 2 3 4 5) #(10 11 12 13 14))
ͨ������ӷ�map���㽫2��������Ӳ������#(11 13 15 17 19)
(reduce #��+ #(11 13 15 17 19)) ͨ���ӷ��鲢�����ۼӽ��75
Map: ��һ������Ԫ�ؽ���ij���ظ�ʽ�Ĵ���
Reduce: ��Map���м�������ij�ֽ�һ���Ľ����

�ؼ�˼�룺Ϊ�����ݴ��������е�������Ҫ���������ṩһ�ֳ������
MapReduce�е�Map��Reduce�����ij�������
MapReduce����˺���ʽ�����������Lisp�е�˼�룬���������µ�Map��Reduce��������ı�̽ӿڣ����û�ȥ���ʵ��:
map: (k1; v1) �� [(k2; v2)]
���룺��ֵ��(k1; v1)��ʾ������
�������ĵ����ݼ�¼(���ı��ļ��е��У������ݱ����е���)���ԡ���ֵ�ԡ���ʽ����map������map������������Щ��ֵ�ԣ�������һ�ּ�ֵ����ʽ���������һ���ֵ���м���������[(k2;
v2)]
�������ֵ��[(k2; v2)]��ʾ��һ���м�����
reduce: (k2; [v2]) �� [(k3; v3)]
���룺 ��map�����һ���ֵ��[(k2; v2)] �������кϲ�������ͬ�������µIJ�ͬ��ֵ�ϲ���һ���б�[v2]�У���reduce������Ϊ(k2;
[v2])
�������Դ�����м����б����ݽ���ij���������һ���Ĵ���,���������յ�ij����ʽ�Ľ�����[(k3; v3)]
��
���������������[(k3; v3)]
Map��ReduceΪ����Ա�ṩ��һ�������IJ����ӿڳ�������

����map�����������ֵ����ݲ��д������Ӳ�ͬ���������ݲ�����ͬ���м������
����reduceҲ���Բ��м��㣬���Ը�������ͬ���м������ݼ���?����reduce����֮ǰ,����ȵ����е�map�������꣬���,�ڽ���reduceǰ��Ҫ��һ��ͬ����(barrier);�����Ҳ�����map���м������ݽ����ռ�����(aggregation
& shuffle)����,�Ա�reduce����Ч�ؼ������ս��?���ջ�������reduce�����������ɻ�����ս��
����MapReduce�Ĵ�������ʾ���C�ĵ���Ƶͳ�ƣ�WordCount
����4��ԭʼ�ı����ݣ�
Text 1: the weather is good Text 2: today is good
Text 3: good weather is good Text 4: today has good
weather
��ͳ�Ĵ��д�����ʽ(Java)��
String[] text = new String[] { ��hello world��, ��hello every one��, ��say hello to everyone in the world�� ��;
HashTable ht = new HashTable();
for(i = 0; i < 3; ++i) {
StringTokenizer st = new StringTokenizer(text[i]);
while (st.hasMoreTokens()) {
String word = st.nextToken();
if(!ht.containsKey(word)) {
ht.put(word, new Integer(1));
} else {
int wc = ((Integer)ht.get(word)).intValue() +1;
// ������1
ht.put(word, new Integer(wc));
}
}
}
for (Iterator itr=ht.KeySet().iterator(); itr.hasNext(); ) {
String word = (String)itr.next();
System.out.print(word+ ��: ��+ (Integer)ht.get(word)+��; ��); |
�����good: 5; has: 1; is: 3; the: 1; today: 2; weather:
3
����MapReduce�Ĵ�������ʾ���C�ĵ���Ƶͳ�ƣ�WordCount
MapReduce������ʽ
ʹ��4��map�ڵ㣺
map�ڵ�1:
���룺(text1, ��the weather is good��)
�����(the, 1), (weather, 1), (is, 1), (good, 1)
map�ڵ�2:
���룺(text2, ��today is good��)
�����(today, 1), (is, 1), (good, 1)
map�ڵ�3:
���룺(text3, ��good weather is good��)
�����(good, 1), (weather, 1), (is, 1), (good, 1)
map�ڵ�4:
���룺(text3, ��today has good weather��)
�����(today, 1), (has, 1), (good, 1), (weather, 1)
ʹ��3��reduce�ڵ㣺
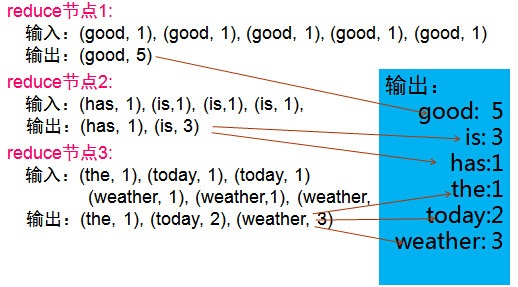
MapReduce������ʽ
MapReduceα����(ʵ��Map��Reduce��������)��

Class Mapper method map(String input_key, String input_value):
// input_key: text document name
// input_value: document contents
for each word w in input_value:
EmitIntermediate(w, "1");
Class Reducer method reduce(String output_key, Iterator intermediate_values):
// output_key: a word
// output_values: a list of counts
int result = 0;
for each v in intermediate_values:
result += ParseInt(v);
Emit(output_key�� result); |
3.����������-�Զ����л������صͲ�ϸ��
����ṩͳһ�ļ�����
MapReduce�ṩһ��ͳһ�ļ����ܣ�����ɣ�
��������Ļ��ֺ͵���
���ݵķֲ��洢�ͻ���
������������������ͬ��
������ݵ��ռ�����(sorting, combining, partitioning,��)
ϵͳͨ�š�����ƽ�⡢���������Ż�����
����ϵͳ�ڵ��������ʧЧ�ָ�
MapReduce��������
ͨ������ģ�ͺͼ����ܰ���Ҫ��ʲô(what need to do)�������ô��(how
to do)�ֿ��ˣ�Ϊ����Ա�ṩһ������߲�ı�̽ӿںͿ��
����Ա����Ҫ������Ӧ�ò�ľ���������⣬�����д�����Ĵ���Ӧ�ñ�����������ij������
��ξ������������м�����������ص����ϵͳ��ϸ�ڱ���������,����������ȥ�������ӷֲ������ִ�У�������ǧС�������ڵ㼯Ⱥ���Զ�����ʹ��
MapReduce�ṩ����Ҫ����
?������ȣ��ύ��һ��������ҵ(job)��������Ϊ�ܶ����������(tasks), ������ȹ�����Ҫ����Ϊ��Щ���ֺ�ļ����������͵��ȼ���ڵ�(map�ڵ��reducer�ڵ�);
ͬʱ��������Щ�ڵ��ִ��״̬, ������map�ڵ�ִ�е�ͬ������(barrier); Ҳ�������һЩ���������Ż�����,
��������ļ���������ö౸��ִ�С�ѡ����������Ϊ���
?����/���뻥��λ��Ϊ�˼�������ͨ�ţ�һ������ԭ���DZ��ػ����ݴ���(locality)����һ������ڵ㾡���ܴ����䱾�ش��������ֲ��洢�����ݣ���ʵ���˴��������ݵ�Ǩ�ƣ������������ֱ��ػ����ݴ���ʱ����Ѱ���������ýڵ㲢�����ݴ������ϴ����ýڵ�(���������Ǩ��)�����������ܴ��������ڵı��ػ�����Ѱ�ҿ��ýڵ��Լ���ͨ���ӳ�
?�����������ԵͶ����÷��������ɵĴ��ģMapReduce���㼯Ⱥ��,�ڵ�Ӳ��(���������̡��ڴ��)������������bug�dz�̬�����,MapReducer��Ҫ�ܼ�Ⲣ��������ڵ㣬�����ȷ����µĽڵ�ӹܳ����ڵ�ļ�������
�ֲ�ʽ���ݴ洢���ļ��������������ݴ�����Ҫһ�����õķֲ����ݴ洢���ļ�����ϵͳ֧��,���ļ�ϵͳ�ܹ��Ѻ������ݷֲ��洢�ڸ����ڵ�ı��ش�����,�������������������ϳ�Ϊһ�������������ļ���Ϊ���ṩ���ݴ洢�ݴ�����,���ļ�ϵͳ��Ҫ�ṩ���ݿ�Ķ౸�ݴ洢��������
Combiner��Partitioner:Ϊ�˼�������ͨ�ſ���,�м������ݽ���reduce�ڵ�ǰ��Ҫ���кϲ�(combine)����,�Ѿ���ͬ�����������ݺϲ���һ������ظ�����;
һ��reducer�ڵ������������ݿ��ܻ����Զ��map�ڵ�, ���, map�ڵ�������м�����ʹ��һ���IJ��Խ����ʵ��Ļ���(partitioner)��������֤������ݷ��͵�ͬһ��reducer�ڵ�
����Map��Reduce�IJ��м���ģ��
4.MapReduce����Ҫ���˼�������
1�����⡱������չ���������ϡ�������չ��Scale ��out��, not ��up����
��MapReduce��Ⱥ�Ĺ���ѡ�ü۸���ˡ�������չ�Ĵ����Ͷ����÷����������Ǽ۸�����չ�ĸ߶˷�������SMP��?�Ͷ˷������г��������Desktop
PC���ص����г�����ˣ��������۸�ľ������ɻ����IJ�������ģ����ЧӦ��ʹ�õͶ˷��������ֽϵ͵ļ۸�?����TPC-C��2007��������������,һ���Ͷ˷�����ƽ̨��߶˵Ĺ����洢���ṹ�ķ�����ƽ̨���,���Լ۱ȴ�ԼҪ��4��;��������۸����,�Ͷ˷������Լ۱ȴ�Լ���12��?���ڴ��ģ���ݴ����������д������ݴ洢��Ҫ���Զ��������ڵͶ˷������ļ�ȺԶ�Ȼ��ڸ߶˷������ļ�Ⱥ��Խ�������ΪʲôMapReduce���м��㼯Ⱥ����ڵͶ˷�����ʵ��
2��ʧЧ����Ϊ�dz�̬��Assume failures are common��
MapReduce��Ⱥ��ʹ�ô����ĵͶ˷�����(GoogleĿǰ��ȫ��ʹ�ð���̨���ϵķ������ڵ�),��ˣ��ڵ�Ӳ��ʧЧ�����������dz�̬�������
һ��������ơ������ݴ��ԵIJ��м���ϵͳ������Ϊ�ڵ�ʧЧ��Ӱ����������������κνڵ�ʧЧ����Ӧ�����½���IJ�һ�»�ȷ���ԣ��κ�һ���ڵ�ʧЧʱ�������ڵ�Ҫ�ܹ���ӹ�ʧЧ�ڵ�ļ�������ʧЧ�ڵ�ָ���Ӧ���Զ�����뼯Ⱥ��������Ҫ����Ա�˹�����ϵͳ����
MapReduce���м����������ʹ���˶�����Ч�Ļ��ƣ���ڵ��Զ�����������ʹ��Ⱥ�ͼ����ܾ��жԸ��ڵ�ʧЧ�Ľ�׳�ԣ�����Ч����ʧЧ�ڵ�ļ��ͻָ���
3���Ѵ���������Ǩ�ƣ�Moving processing to the data��
��ͳ�����ܼ���ϵͳͨ���кܶദ�����ڵ���һЩ��洢���ڵ���������������洢����(SAN,Storage
Area Network)���ӵĴ������У���ˣ����ģ���ݴ���ʱ����ļ�����I/O���ʻ��Ϊһ����Լϵͳ���ܵ�ƿ����?Ϊ�˼��ٴ��ģ���ݲ��м���ϵͳ�е�����ͨ�ſ�������֮�����ݴ��͵������ڵ�(���������������Ǩ��)��Ӧ�����ǽ����������ݿ�£��Ǩ�ơ�?MapReduce����������/���뻥��λ�ļ�������������ڵ㽫���Ƚ�������������䱾�ش洢������,�Է������ݱ��ػ��ص�(locality),�����ڵ���������������ʱ���ٲ��þͽ�ԭ��Ѱ���������ü���ڵ㣬�������ݴ��͵��ÿ��ü���ڵ㡣
4��˳�������ݡ���������������ݣ�Process data sequentially
and avoid random access��
���ģ���ݴ������ص�����˴��������ݼ�¼�����ܴ�����ڴ桢��ֻ���ܷ�������н��д�����?���̵�˳����ʺ��漴�������������о�IJ���
����100��(1010)�����ݼ�¼(ÿ��¼100B,����1TB)�����ݿ�
����1%�ļ�¼(һ�����������)��Ҫ1����ʱ�䣻��˳����ʲ���д�������ݼ�¼����1��ʱ�䣡
MapReduce���Ϊ��������ݼ��������IJ��м���ϵͳ�����м��㶼����֯�ɺܳ�����ʽ�������Ա������÷ֲ��ڼ�Ⱥ�д����ڵ��ϴ��̼��ϵĸߴ��������
5��ΪӦ�ÿ���������ϵͳ��ϸ�ڣ�Hide system-level details
from the application developer��
��������ʵ��ָ���У�רҵ����Ա��Ϊ֮����д�������ѣ�����Ϊ����Ա��Ҫ��ס̫��ı��ϸ��(�ӱ������������㷨�ı߽��������)����Դ��Լ�����һ�������֪����,��Ҫ�߶ȼ���ע����?�����г����д�и������ѣ�����Ҫ���Ƕ��߳�������ͬ���ȸ��ӷ�����ϸ�ڣ����ڲ���ִ���еIJ���Ԥ���ԣ�����ĵ��Բ��Ҳʮ�����ѣ����ģ���ݴ���ʱ����Ա��Ҫ�����������ݷֲ��洢���������ݷַ�������ͨ�ź�ͬ�����������ռ������ϸ������?MapReduce�ṩ��һ�ֳ�����ƽ�����Ա��ϵͳ��ϸ�ڸ��뿪��������Ա����������Ҫ����ʲô(what
to compute), ��������ôȥ��(how to compute)�ͽ���ϵͳ��ִ�п�ܴ�������������Ա�ɴ�ϵͳ��ϸ���н�ų���������������Ӧ�ñ�������������㷨���
6��ƽ����Ŀ���չ�ԣ�Seamless scalability��
��Ҫ�������������ϵ���չ�ԣ�������չ��ϵͳ��ģ��չ��?����������㷨Ӧ�����������ݹ�ģ����������ֳ���������Ч�ԣ������ϵ��½��̶�Ӧ�����ݹ�ģ����ı����൱?�ڼ�Ⱥ��ģ�ϣ�Ҫ���㷨�ļ�������Ӧ�����Žڵ��������ӱ��ֽӽ����Գ̶ȵ�����?����������еĵ����㷨���ﲻ�����������Ҫ���м�������ά�����ڴ��еĵ����㷨�ڴ��ģ���ݴ���ʱ�ܿ�ʧЧ���ӵ��������ڴ��ģ��Ⱥ�IJ��м���Ӹ�������Ҫ��ȫ��ͬ���㷨���?������ǣ�MapReduce������ʵ�������������չ��������
�����о����ֻ���MapReduce�ļ������ܿ���ڵ���Ŀ�������ֽ��������Ե�������
|





