| 正式开始
连接方式和请求
如果你是一个开发者,并且你的程序使用SQLSERVER来做数据库的话
你会想知道当你用你的程序执行一个查询的时候实际发生了什么事情
我希望这篇文章能够帮你写出更好的数据库应用程序和帮你更深入了解遇到的数据库性能问题
SQLSERVER是一个C/S模型的平台。唯一和数据库交互的方式只有发送包含数据库命令的请求到数据库服务器端。
客户端和数据库通信的协议使用一种叫做TDS的协议(Tabular Data
Sream)
如果你用微软的Network Monitor工具来抓取SQL Server和客户端之间的网络包
你会看到使用的是TDS协议
在Description那一列
TDS:Response,Version=7.1......
TDS:SQLBatch,Version=7.1.......

那四个SSL连接是客户端登录SQLSERVER前做的加密连接(这里不管你有没有用SSL加密数据传输,SQLSERVER都会在登录前加密
用户发过来的用户名和密码,而登录了之后才使用您配置的SSL证书来加密客户端和SQLSERVER往来的数据)
SQLSERVER都会加密客户端发过来的用户名和密码(使用SQL验证不是使用Windows验证)
大家可以留意一下SQL ERRORLOG里在SQLSERVER启动的时候的日志
会看到一句:A self-generated certificate
was sccessfully loaded for encryption
默认情况下SQL Server会自动生成一个证书并使用这个证书来对客户端登录SQLSERVER的时候的连接做SSL加密
登录了SQLSERVER之后,就不会对连接/所传输的数据做加密了

而且SQL Server自动生成的证书。每次SQL Server启动时,它自动生成的证书都是不一样的
MSDN是这样描述的:Tabular Data Stream协议,应用程序能够使用下面的几种已经实现了TDS协议的驱动程序里的其中一种
驱动程序来连接数据库,包括:
the CLR managed SqlClient
OleDB
ODBC
JDBC
PHP Driver for SQL Server
开源的 FreeTDS 实现
当你的应用程序命令数据库如何去做的时候会通过TDS协议向数据库发送一个请求
发送的请求本身能携带下面几种格式的信息
(1)批处理请求
这种请求类型只会包含一个需要执行的批处理TSQL文本。这种类型的请求不能带有参数,不过,TSQL批处理脚本里
能包含本地变量的定义。这种类型的请求一般都是使用SQLCLIENT驱动程序发送的,
当你使用SqlCommand 对象调用下面语句的任何一个的时候,并且没有传入任何参数
SqlCommand.ExecuteReader()
SqlCommand.ExecuteNonQuery()
SqlCommand.ExecuteScalar()
SqlCommand.ExecuteXmlReader()
当你用SQL PROFILER监视你会看到一个:SQL:BatchStarting
事件类型
(2)远程过程调用请求
这个请求类型包含带有若干个参数的存储过程。
当你用SQL PROFILER监视你会看到一个:RPC:Starting
事件类型
(3) Bulk Load大容量装载请求
大容量装载请求是一种特别的使用bulk insert操作符的请求,
例如使用
BCP.EXE工具(我们常说的BCP命令)
bulk insert语句
IRowsetFastLoad OleDB 接口
C#里面的SqlBulkcopy类
大容量装载请求跟其他类型的请求是不同的,
因为请求通过TDS协议传送到SQLSERVER的时候,还未传送完毕,SQLSERVER就开始执行请求所要做的操作了
(一般来说,整个请求的数据包全部发送到SQLSERVER那里,SQLSERVER认为是完整的数据包才开始执行请求)
但是大容量装载请求不一样,数据包里包含有大量的数据,这些数据是附着在请求里的,如果要把整个请求传送完毕
SQLSERVER才开始执行请求,那不知道要等到何年何月了???
这样允许SQLSERVER开始执行请求,并且开始消费掉数据流中所插入的数据

下面是比较久以前的一张图片,大家可以参考一下,图片内容对于现在的SQLSERVER不一定正确

连接模块(模块化)

任务(Tasks)和工作者(Workers)
在一个完整的TDS请求到达SQLSERVER数据库引擎的时候,SQLSERVER会创建一个任务(task)去处理请求
想查询当前SQLSERVER里面的所有请求,可以使用sys.dm_exec_requests
这个DMV视图
任务(Tasks)
上面提到的任务会被创建用来处理请求,一直到请求处理完毕为止。
例如:如果请求是一个批处理请求类型的请求,任务(Tasks)会执行整个SQL批处理,不会只负责执行SQL批处理里的单独一条SQL语句
在SQL批处理里的单独的一条SQL语句不会创建一个新的任务(Tasks)。
当然,在SQL批处理里的单独的一条SQL语句有可能会并行执行(通常使用MAXDOP,或Degree
Of Parallelism)
在这种情况下,任务(Tasks)会再生新的子任务(sub-Tasks)去并行执行这个单独的SQL语句。
如果请求返回了批处理所要的完整的结果集,并且结果集已经被客户端从SQLSERVER的结果集缓存里取走
并且你在C#代码里dispose 了SqlDataReader,你会在sys.dm_os_tasks这个DMV视图里看到你的请求
所用的任务(Tasks)。
当一个新的请求到达SQLSERVER服务器端的时候,并且这时候任务(Tasks)已经被创建出来去处理这个请求了
如果这时候任务(Tasks)处于挂起(PENDING)状态,现阶段SQLSERVER还未知道这个请求的实际内容,
那么,被创建出来的任务必须首先去执行这个请求,并且数据库引擎也要分配一个工作者(Worker)去处理这个请求


工作者(Workers)
工作者(Workers)是SQLSERVER线程池里的一些线程,一些
工作者(Workers)/工作线程在SQLSERVER
初始化的时候就被创建出来,而另一些工作者(Workers)会根据需求而创建,当创建的数量达到max
worker threads
这个配置值的时候就不能再创建了,下图显示为0,他并不是说可以创建无限的工作者(Workers)
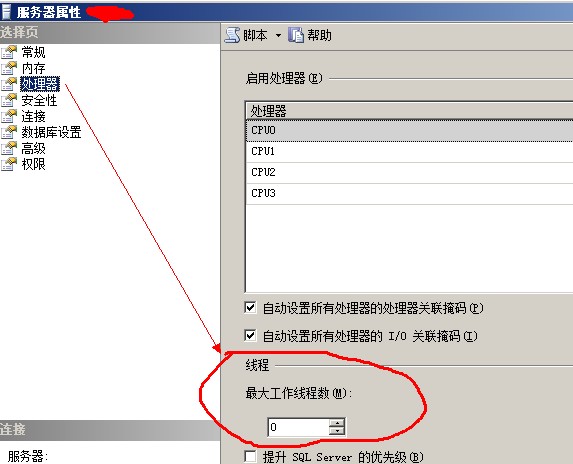

我的机器的配置是酷睿i3,双核四线程,那么,如果max worker
threads配置为0
最大的工作者(Workers)数目可以达到256个
实际上,只有工作者(Workers)才真正执行SQL代码。
工作者(Workers)每时每刻都等待那些已经传送进去SQLSERVER的请求的任务(Tasks)
从被挂起(PENDING)状态成为可以运行的状态,每个工作者(Workers)只会处理和执行一个任务(Tasks)
这时候,工作者(Workers)会一直处于工作状态,并一直被占用,直到他的工作完成为止(task
finishes)
如果当前没有可用的工作者(Workers)供给正在处于挂起状态的任务(Tasks)使用的话,那么这个任务(Tasks)
只能一直等待直到那些已经在执行/运行的任务(Tasks)执行完毕,另外,工作者(Workers)在处理完一个
任务(Tasks)之后也会继续处理下一个处于挂起状态的任务(Tasks)。
对于一个SQL批处理请求,工作者(Workers)会处理那个携带着那个SQL批处理的任务(Tasks)
并且会执行SQL批处理里面的每条SQL
有人就会问了:一个SQL批处理里的SQL语句不就是并行执行吗?
(=> 请求request =>任务 task =>工作者
worker),一个批处理请求进来,多个工作者去处理这个批处理请求里的每条SQL语句,
这显然就是SQLSERVER的并发处理SQL语句嘛
很多人都会有这个想法,实际上是错误的,实际上这些SQL语句也是串行执行的,这些SQL语句的执行只能由
一个单独的线程(工作者 worker)来执行,线程(工作者 worker)在执行完一个SQL语句之后才能执行下一个SQL语句,
当SQL批处理内部的SQL语句使用了并行提示MAXDOP>1来执行SQL语句
,这会造成创建子任务(sub-tasks),
每个子任务(sub-tasks)也是通过上面所说的那个循环去执行的:任务创建出来之后会处于挂起状态,
其他的(工作者 worker)必须去处理这个子任务(sub-tasks)
你会在sys.dm_os_workers这个DMV视图里看到SQLSERVER当前的工作者
worker列表和他们的当前状态


解释(Parsing)和编译(Compilation)
一旦一个任务(task)开始执行一个请求,第一件要做的事情就是:去理解请求里面的内容
在这一步,SQLSERVER的行为更像一个代码解释的虚拟机(类似于JVM):在请求(request)里面的TSQL代码将会被逐一解释
并且会生成一棵抽象语法树去处理这个请求。整个批处理请求会被解释和编译,如果在这一步发生错误,
SQLSERVER会给出编译/解释错误的提示,这个请求也会被终止不会执行,任务(task)和工作者(worker)都会被释放,
释放出来的工作者(worker)会继续处理下一个被挂起的任务(task)。
SQL语言和TSQL(SQLSERVER里叫TSQL,ORACLE里叫PLSQL)语言是一种高等的描述性语言
当一个SQL语句很复杂的时候,试想一下,一个SELECT 语句伴随着多个JOIN
1
USE [GPOSDB]
2 GO
3 SELECT * FROM [dbo].[CT_Append] AS a
4 INNER JOIN
5 [dbo].[CT_FuelingData] AS b
6 ON a.[VC_A_CardNO]=b.[VC_FD_Cardno]
7 INNER JOIN
8 [dbo].[CT_Dis_FuelingData] AS d
9 ON a.[VC_A_CardNO]=d.[VC_FD_Cardno]
10 INNER JOIN
11 [dbo].[CT_InhouseCard] AS e
12 ON e.[VC_IC_CardNO]=d.[VC_FD_Cardno]
13 INNER JOIN
14 [dbo].[CT_OuterCard] AS f
15 ON f.[VC_OC_CardNO]=a.[VC_A_CardNO] |
编译好的TSQL批处理不会产生可执行代码(executable code,类似可执行的二进制的exe文件),
这里更像本地CPU指令,甚至于类似C#的CLI指令或者JAVA的JVM
bytecode
不过,这里会产生用于访问表数据的执行计划(query plans),这些执行计划描述了如何去访问表和索引,
如何去搜索和定位表里面的行数据,如何根据SQL批处理里的SQL语句去做数据操作。
例如:一个执行计划会描述一种数据访问路径-》访问在t表上的索引idx1,定位到关键字为‘k’的那行记录,
最后返回a列和b列这两列数据。
另外:开发者通常都会犯一个普遍的错误
在一个TSQL语句里写很多的条件选择,通常这些条件选择都会用在带有OR
的where子句里
例如:cola=@parameter OR @parameter IS
NULL
对于开发者一定要避免这种情况。
这个时候,编译一定要得出一种通用的执行计划,无论任何参数代入到这个执行计划里都能得出最优的结果
在TSQL里的参数化(Dynamic Search Conditions)
例如下面SQL语句:
1
SET STATISTICS PROFILE ON
2 GO
3 INSERT INTO [dbo].[SystemPara] ( [ParaValue], [Name], [Description] )
4 VALUES ( '2', -- ParaValue - varchar(50)
5 '3', -- Name - varchar(50)
6 '4' -- Description - varchar(50)
7 ) |
当你打开SET STATISTICS PROFILE ON开关的时候,你会在Argument列和DefinedValues列看到


SQLSERVER会将输入的值2,3,4赋值到Expr1004,Expr1005,Expr1006这三个变量里

并做一些类型转换,Expr1004=CONVERT_IMPLICIT(VARCHAR(50),[@1],0)
2这个值会代入都@1变量里,然后通过类型转换赋值给Expr1004

recordno这一列也是,通过getidentity((277576027),(14),null)函数获得自增值
然后赋值给Expr1003

SQLSERVER会将输入的值2,3,4赋值到Expr1004,Expr1005,Expr1006这三个变量里
1
INSERT INTO [dbo].[SystemPara] ([RecordNo], [ParaValue],
[Name], [Description] )
2 VALUES(Expr1003,Expr1004,Expr1005,Expr1006) |
将实际的值先赋值给@1,@2,@3,@4 再通过类型转换赋值给Expr1003,Expr1004,Expr1005,Expr1006
Expr1003=类型转换(@1)
Expr1004=类型转换(@2)
Expr1005=类型转换(@3)
Expr1006=类型转换(@4)
为什麽SQLSERVER不直接使用下面的执行计划呢?
1
INSERT INTO [dbo].[SystemPara] ([RecordNo], [ParaValue],
[Name], [Description] )
2 VALUES(1,2,3,4) |
还要类型转换,参数代入这麽麻烦,SQLSERVER不是有病吗???
这里涉及到执行计划重用,如果使用上面的执行计划,编译的时间是很快,但是
如果我插入的值是:9,8,6,7
1
INSERT INTO [dbo].[SystemPara] ([RecordNo], [ParaValue],
[Name], [Description] )
2 VALUES(9,8,6,7) |
SQLSERVER不能重用上次的执行计划,又要重新生成执行计划,您说这样的效率。。。。。。。。

|








