| ǰ�ԣ�
����ڴ�ͳ��ҵ����Է���ʱ��9x9x6����9x12x5����Ϊ���������������Լ���������Ϸ��ʵʱ�ԣ����Է���Ҫ��7*24Сʱ��ҵ��ܹ�������Ӧ�û������ݿ⣬����Ҫ���ֻ�������mysql����ϵ�У����ͨ�����ʼ�ε����ݿ�ܹ�����ʵ������ϵͳ�����������ҵ���۽ǶȲ�����mysql�ܹ��ķ������档
һ��MySQL�ܹ���ơ�ҵ�����
��1�������
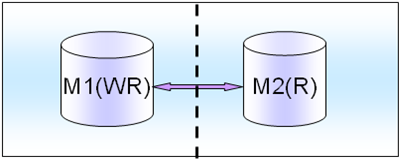
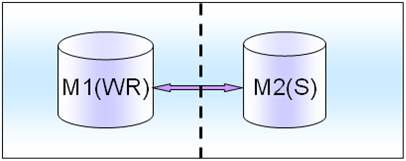
���߱�ʾ��������𣬱����������ϵͳ��һ��Master���ж�Ҳ��Щд���Զ�����һ������Ҫ�Ƚ���Ҫ�ģ���Ҫ����Master���档
M(R)������һ�����⣬ֻ��M(WR)����֮�Ż��л���M(R)�ϣ����ʱ��M(R)�ͱ���˶�д�⡣������Ϸϵͳ���кܶ�Salve����غ���һ��M(R)���档
��2�������MMS-����
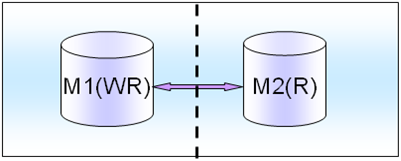
����ǵ����������͵ģ����ֶ���д�ٵģ�һ����1��master����4��6��slave������slave������һ��masterҲ�㹻�ˡ�
�л���ʱ��M1�Ķ�дҵ���л���M2���棬Ȼ�������M1�ϵ�slave�ҵ�M2����ȥ��������ʾ��
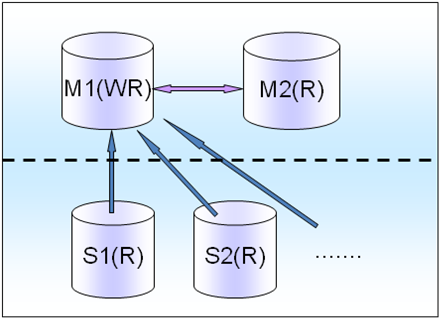
��3������д��MMSS-��Ϸ
�������Ϸ��ҵ�Ļ������dz��������Եģ������һ��1��Master�������10�����ϵ�Slave��������������ʱ����һ����Slave�����µ�M(R)���档���ٻ����һЩѹ�����������ٷ������ҵ���ʱ��������е�slave��Ӱ�죬����һ������M(R)�ϵ�slave�ڼ�������������е�slave�ܵ�Ӱ�죬��ͼ3��
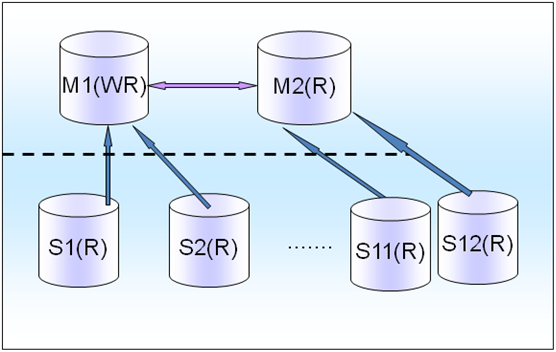
��4�������
��ζ�Ŷ�������Ӱ��д��Ч�ʣ����Զ�д�����Է���һ��M1(WR)��������һ�����ṩ��Ҳ���ṩд��ֻ�ṩstandby����������֡�
�����������Ƿdz���Ҫ�ģ���������ǵ����ģ����ߵ�ҵ����һidc���������ˣ�һ��ͻ�Ӱ������ҵ��ģ�����
���ҵ��2Сʱ��Ӧ�ã��������ߵ�����������˵��Ӱ��������ģ�����Ϊ������ȵı�֤7*24Сʱ������Ҫ����������֣�MMҪ��idc��������Ȼ����Դ��һЩҪ���Ƕ�HA��˵�Dz���ȱ�ٵģ�һ��Ҫ�����MM���ơ�
���л���ʱ�����еĶ�д��M1ֱ���л���M2�ϾͿ����ˡ�
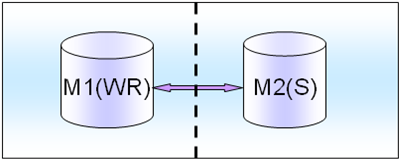
��5����дƽ����ɫ
����д��࣬���Ƕ�����Ӱ��д���������Ѷ�д����M1(WR)�ϣ�Ȼ���һ���ֶ�Ҳ����M2(R)���棬��ȻM1��M2Ҳ�ǿ���������
�л���ʱ��һ���ֶ���ȫ��д��M1�л���M2�ϾͿ����ˡ�
����MySQL�ܹ���ơ������ܹ�
��1��ǿһ����
�Զ�һ���Ե�Ȩ�⣬����ǶԶ�дʵʱ��Ҫ��dz��ߵĻ����ͽ���д������M1���棬M2ֻ����Ϊstandby�����Dz�ȡ�������һ��4���Ķ���д���һ���ļܹ�ģʽ��
���磬�����������̣���ô�Զ���Ҫǿһ���ԣ�ʵʱдʵʱ�������������漰���Ļ��߶�̬ʵʱ����ͳ�ƵĶ�Ҫ�������ּܹ�ģʽ
��2����һ����
�������һ���ԵĻ�������ͨ����M2����ֵ�һЩ��ѹ��������������һЩ�����Ķ�ȡ�Լ���̬�������ݵĶ�ȡģ�鶼���Էŵ�M2���档������ͳ�Ʊ�����������ҳ�Ƽ���Ʒҵ��ʵʱ��Ҫ���Ǻܸߣ���ȫ���Բ���������һ���Ե���Ƽܹ�ģʽ��
��3���м�һ����
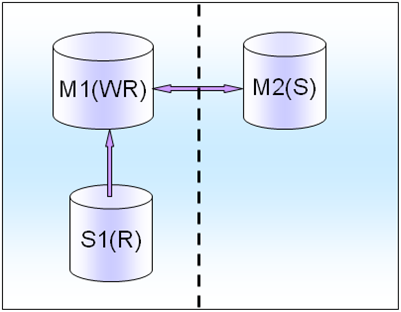
����Ȳ��Ǻ�ǿ��һ�����ֲ��Ǻ�����һ���ԣ���ô���ǾͲ�ȡ�м�IJ��ԣ�������ͬ�����ٲ���һ��S1(R)����Ϊ���⣬�ṩ��ȡ������M1(WR)��ѹ����������һ��idc������M2ֻ��standby���ַ�ʽ����;��
��Ȼ������õ�3̨���ݿ��������Ҳ�������Ӳɹ�ѹ�����������ǿ����ṩ���õĶ������ݷ����������;����ʵ���о���������ˡ�
��4��ͳ��ҵ��
����PV��UV������ҳ����ͳ�ơ�������ͳ�ơ����ݵĻ��ܵȵȣ������Ի���Ϊͳ�����͵�ҵ��
���ݿ��������ѯ��ͳ���Ƿdz�������Դ�ġ�ͳ�Ʒ�Ϊʵʱ��ͳ�ƺͷ�ʵʱ��ͳ�ƣ�����mysql��������sql��ģʽ�����Բ��ܴﵽ100%��ʵʱ�������onlineҪ�ϸ�ķdz�ʵʱ��ͳ�Ʊ������Ʊ�Լ�������ؽ���ȵ�ͳ�ƣ�mysql��鲻������ǿ���ֻ�в�ѯM1������ʵ���ˡ�
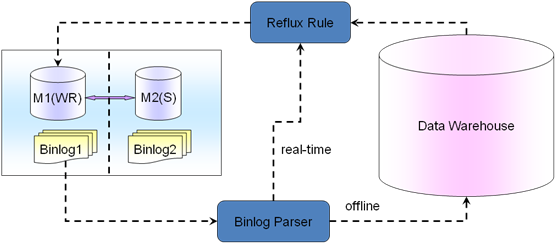
A�����Ƕ��ڲ����ϸ��ʵʱ�Ե�ͳ�ƣ�mysql�и��ܺõĻ�����binlog�����ǿ���ͨ��binlog���н���Parser����������д��ͳ�Ʊ�����ͳ�ƻ��߷���Ϣ��Ӧ�ö˳���������ͳ�ơ�������ʵʱ��ͳ�Ʋ�������һ���Ķ��ݵĿɽ��ܵ�ͳ���ӳ��������Ҫ100%ʵʱ��ͳ��ֻ�в�ѯM1�����ˡ�
ͨ��binlog�ķ�ʽʵ��ͳ�ƣ��ڻ�������ҵ�������ǵ��̺���Ϸ��飬�����Խ��90%���ϵ�ͳ��ҵ����ʱ������û����߿ͻ����Ҫʵʱread-time�ˣ���ҿ��Թ�ͨһ��Ϊʲô��Ҫʵʱ���˽�����ҵ������Щ������IJ���Ҫʵʱͳ�ƣ���Ҫ����Ȩ�⣬��Ҫ���û��Ϳͻ������Ч��ͨ�������Ƚ��ʺ�ҵ���ͳ�Ƽܹ�ģ�͡�
B������һ��offlineͳ��ҵ�����·ݱ����걨��ͳ�Ƶȣ�������ȫ�������ݷŵ����ݲֿ�������ߵ�����Nosql�������ͳ�ơ�
��5����ʷ����Ǩ��
��ʷ����Ǩ�ƣ���Ҫ������Ӱ���������ϵ�ҵ������Ӱ���������ϵIJ�ѯд�������ΪʲôҪ����ʷ����Ǩ�ƣ���Ϊ��Щҵ�����������ʱЧ�Եģ���������е��Ѿ���ɵ���ʷ�����ȣ��������и��²����ˣ�ֻ�кܼIJ�ѯ���������Ҳ�ѯҲ�����Ƶ������������һ�춼�����ѯһ�Ρ�
�����ʱ����ʷ���ݻ���online���������online�����棬��ô�ͻ�Ӱ��online�����ܣ����Զ������֣���������Ǩ�Ƶ��µ���ʷ���ݿ��ϣ������ʷ���ݿ������mysqlҲ������nosql��Ҳ���������ݲֿ�����hbase�����ݵȡ�
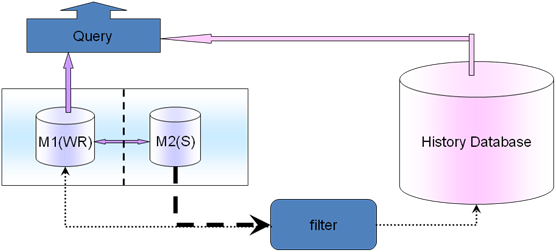
ʵ��;����ͨ��slave���ѯ�����е����ݣ�Ȼ�����ҵ��������ʱ�䡢ijһ��γ�ȵȹ���ɸѡ�����ݣ�������ʷ���ݿ�(History
Databases)���档Ǩ�����ˣ��ٻص�����M1�ϣ�ɾ������Щ��ʷ���ݡ�������ҵ����棬��ѯ��Ҫ�������ʵʱ���ݺ���ʷ���ݣ�������filter�������Ǩ�ƹ����online��ѯ��history��ѯ�Խ�����������˵һ����֮�ڵ���online���ѯһ����֮ǰ����history���ѯ����������������DB��Ǩ��filter���Ӧ�ò�ѯҵ��ģ��㡣������ԵĻ������������ø�ϸ����ͨ��Ӧ�ò�ѯҵ��ģ�����Ӱ��DB��Ǩ��filter�㣬������ǰ��ѯ��Ϊһ����Ϊ�������ڲ�ѯҵ��仯�ˣ���15��Ϊ������ôӦ�ò�ѯҵ��ģ���仯���Զ���DB��filter��Ҳ�仯��ʵ�ְ���Զ�������������һЩ��
��6��MySQL Sharding
��oracle���ֻ���rac���ڹ����洢�ķ�ʽ������Ҫshardingֻ��Ҫ����rac�洢����ʵ���ˡ��������ִ�����Ի�Ƚϸ�һЩ�������洢һ�㶼�ȽϹ�����ҵ�����չ���ݵı�ըʽ��������ͣ�ۼ���ijɱ��������ﵽһ���������֡�
Ŀǰ����share disk�ķ�ʽ������oracle��ҵ���������ķdz�����֮�������Ľ�������������Ǻ�������
Mysql��shardingҲ��������ԣ�sharding֮������ݲ�ѯ�����Լ�ͳ�ƶ����кܴ�����⣬mysql��sharding�ǽ��share
nothing�Ĵ洢��һ�ֲַ�ʽ�ķ����������Ϸ�Ϊ��ֱ��ֺ�ˮƽ��֡�
��6.1����ֱ���
���Ժ����֣����������֣����Ժ��������֣���������ҵ���֡�
6.1.1������
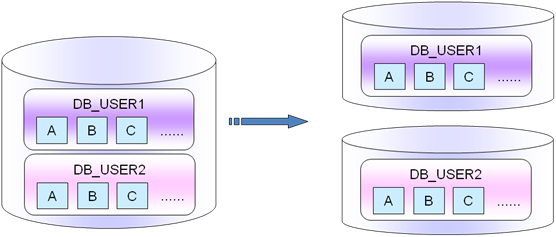
Mysql������ĺ�������ָ��ÿһ�����ݿ�ʵ�����涼�кܶ��db�⣬ÿһ��db�����涼��A��B��������db1����A��B����db2����Ҳ��A����B������ô���ǰ�db1��db2���A��B����ֳ�������һ����ֳ�2�����Ͳ�ֳ�db1��db2��db3��db4������db1���db2���A�����ݣ�db3���db4���B�������ݣ�db1��db2������ֻ��A�����ݣ�db3��db4������ֻ��B�������ݡ�
����ȷ�����Ϊ������˵��ÿ�������涼����־���Ͷ�����������A������־��log����B���Ƕ�����Order����һ��˵��д��־��д����û��ǿ�����ԣ����ǿ��Խ�A����־����B����������ֳ�������ô���ʱ�������һ�κ���IJ�ֹ�������A����־����B����������ֿ������ڲ�ͬ�Ŀ⣬��ȻA����B�����ڵ����ݿ���Ҳ���Ա���һ��(PS���ڲ�ͬ��ʵ������)������ͼ��ʾ��
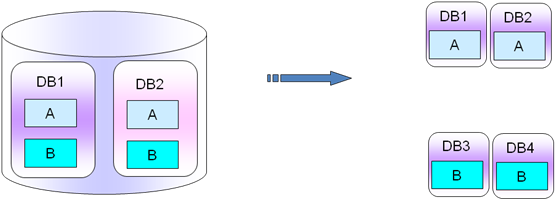
PS�����ֲ����Ҫ����ڲ�ͬ��ҵ��Ա���Ӱ�첻��֮���ҵ�����������������û��ҵ���������ֵĺô��Dz���ص����ݱ���ֵ���ͬ��ʵ�����棬�����ݿ��������չ��������ߵľ�����˵���������кô��ġ�
6.1.2������
��ͬһ��ʵ���ϵIJ�ͬ��db���ֳ��������뵥���IJ�ͬʵ���С����ֲ�ֵ���Ӧ������Ҫ����db1��db2��û�ж���ҵ����ϵ�ģ�����6.1.2�����A����B��������������õ��˿��ҵ��ͬʱʹ��db1��db2�Ļ������˽���Ҫ���¿�����ҵ�����������¾�����һ��ģ��ı�����һ�������棬��Ҫ��������
���ֿ����������棬�����Ŀ�db1����A�ͱ�B��ǿ�����ġ�����ͼ��ʾ��
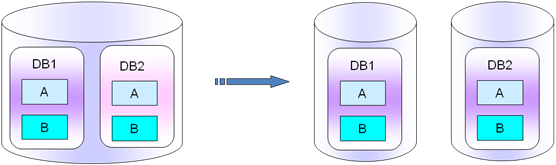
PS�������ܶ�ʹ��mysql���ˣ����ǰѺܶ�û��ҵ������Եı�����һ�������棬�������ǰѺܶ����db�����ͬһ��ʵ�����棬����ʹ��oracle������һ��instance�ĸ�����ѡ�Mysql��ʹ��һ��ԭ����Ǽ�������һ����ȥʹ��mysql����Ҫ�ϸ�ķֿ�����û�й�ϵ�ģ�Ҫ�ϸ��ֳɿ⡣�����Ļ���չ���ǵ�ҵ��ͷdz�������ˣ�ֻ��Ҫ��ҵ��ģ�����ڵ�db��ֳ����������µ����ݿ�������ϼ��ɡ�
6.1.3 ����������
��Щ���ģ���ʼΪ�˿��ٳ���Ʒ���Ͱ����ԵĿ����еı�������һ��ʵ���ϣ���ҵ��չ�����������ݲ�֣�����ͻ�Ѻ��������ֽ��������һ��ʵ�֣�����ͼ��ʾ��
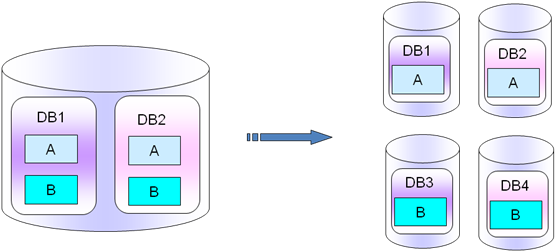
6.1.4 ҵ����
��ˮƽ����е����ƣ������в�ͬ�ĵط�������һ����Ӧ�̣�����������վ����10����Ӧ�̣�һ����վ����ÿһ����Ӧ�̶���һ�����������ҹ�Ӧ��֮�����������ģ�����Ĺ�ģ����ô���ʱ��Ϳ���ʹ�ù�Ӧ�̵�γ��������֡�
����usern���У�a��b��c������ǿ�����ģ�����������ҵ�������ڣ�����ֻ���û�����Ӧ�̣�γ����û�й����ģ������ʱ��Ϳ����������û���γ�������в�֡�
�����û�1���û�2���Զ���һ��������ҵ���������ұ˴�֮�䲻���������ԾͿ����û�1���û�2���ݲ�ֵ���ͬ�����ݿ�ʵ�����档Ŀǰ�ܶ������˾������Ϸ��˾�кܶ�ҵ�������û�γ�Ƚ��в�ֵģ�����qunaer��sohu
game��sina�ȡ�
��6.2�� ˮƽ���
ˮƽ������Ҫ��һЩ�������Ѷ�ƫ�ᵼ�·ֲ�ʽ������������ݵ�������������������Է�Ϊ������࣬1����ʷ���ݺ�ʵʱ���ݲ�֣�2�ǵ�������֣�3�Ƕ������֡�
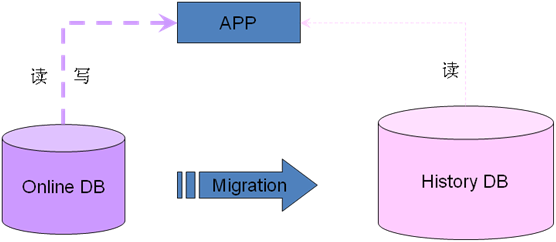
6.2.1 ʵʱ������ʷ���ݵIJ��
����ʷ����Ǩ����һ������������Ҫ��online�������Ǩ�Ƶ�listory�����ݿ����棬����ʵʱ�Ķ�д��˵�������Ƿ���online
db�����棬����ʱ���Զ��������˵���Ƿ�����ʷHistory DB��¼������ģ��������ʷ�������mysqlҲ�����DZ��nosql��ȡ�
6.2.2 ���������
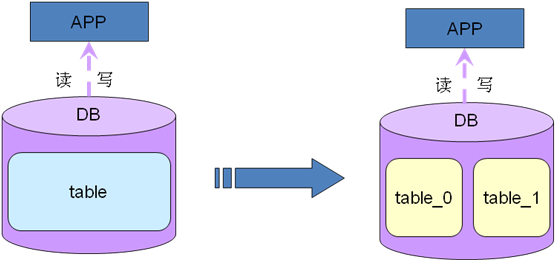
��Ҫ���ǽ���������⣬���ǽ�������������չ�ģ����뵱ǰʵ��ֻ��һ��DB����һ�������һ������Ͱ�����ʵ��ռ���ˣ����ʱ��Ͳ��ܲ��db�ˣ���Ϊֻ��һ�����������ʱ�����Ǿ�ֻ�ܲ���ˣ�����ķ�ʽ��Ҫ�ǽ���������⣬��Ϊ������Խ����mysql��˵�����������νṹ�������ݻ����ĸ������Դ����ʱ��һ���IJ�ѯ�Ϳ��ܻ���������db�ĺܶ�Ҷ�ӽڵ㶼Ҫ�䶯������insert��update��delete���������������нڵ�ı������ʱ��������dz�������ʱ���д���ܶ���ܵͣ����ʱ�����ǾͿ��Կ��ǰѴ����ֳɶ��С���������������ǰ���hashȡģ��ɢ��16��С����Ҳ�а���id����/50ȡģ��ɢ��50��С�����У���ͼʵ���Ǵ�ɢ��2��С����
6.2.3 ��������
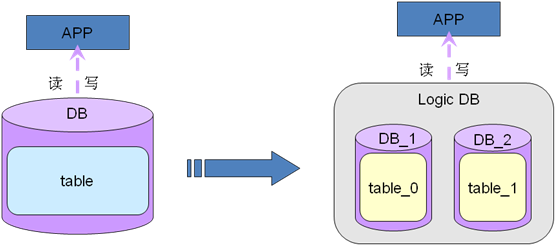
�ڵ������Ļ����ϣ��������ռ���Դ�Ѿ��������ṩҵ��֧�ŵĻ������Կ��Ƕ�����ķ�ʽ����������˿ռ�������������⣬��������һ��������ǿ���ѯ��������ѯ�ͻ�������IJ��ԣ�����˵��һ��logic
db����ʵ�ֿ���ʵ���Զ���ѯ��������ͼ��ʾ��
6.2.4ˮƽ���С��
ˮƽ���ԭ��
-- a. �������ȵIJ��ά�ȡ�
-- b. ��������������
-- c. �����������ѯ��
��ƣ�
--a���ݲ��ά�ȣ���mod�������ݱ���֣��ֶ���ȡģ�IJ�ֻ��ƣ�����hash��16ģԭ��ȡ�
--b���������������������ݿ���
���ݲ�����
--a������������ֲ�ʽ����ͨ��Ԥд��־�ķ�ʽ����ӵ�ʵ�֡�
--b����ѯ�����ݻ���or��Ϣ����
6.2.5 ����˵��
������
�C �����û�ά�Ƚ��в�ֳ�64���ֿ⣬1024���ֱ�
user_id%1024 ��ֵ�1024�ŷֱ���
ÿ���ֿ��д��1024/64�ŷֱ�
ȡģ��ʱ������id�����4λ���ݻ���3λ������ȡģ�Ϳ����ˡ�
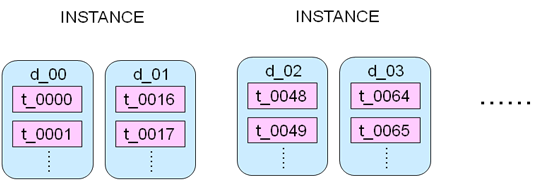
����1������Configure DB
�C ���֮��IJ�ѯ��������һ��Configure DB�����DB��ŵ�������ʵ���Ŀ����ӳ���ϵ������APP������һ�������ѯuser1�����ݣ���ô���user1�������Ǵ������ǧ��ʵ���е���һ������أ����������Ϣ����Configure
DB���棬APP��ȥConfigure DB����ȡ��user1�Ĺ���ϵ��Ϣ(�����Ǵ����d_01���ϵ�t_0016������)��Ȼ��APP���ݹ�����Ϣֱ��ȥ��ѯ��Ӧ��d_01ʵ����t_0016������ȡ�����ݡ�
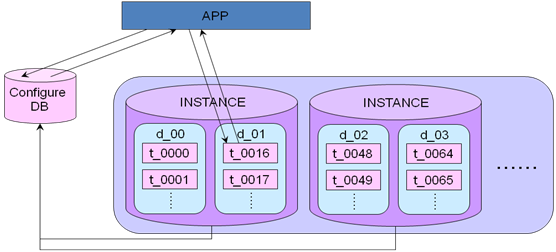
����2������Proxy
�C ���֮��IJ�ѯ��������һ��Proxy��APP����Proxy��Proxy���ݷ��ʹ���Ϳ���ֱ��·�ɵ������dbʵ���������µ�sqlȥ������Ӧ��dbʵ����Ȼ��ͨ��ProxyЭ����в����Ѳ���������ظ�APP��
�C ������Proxy��dbʵ������һ�����Σ�����Proxy��dbʵ���IJ�����ʱ���Ƿdz��̵ġ�
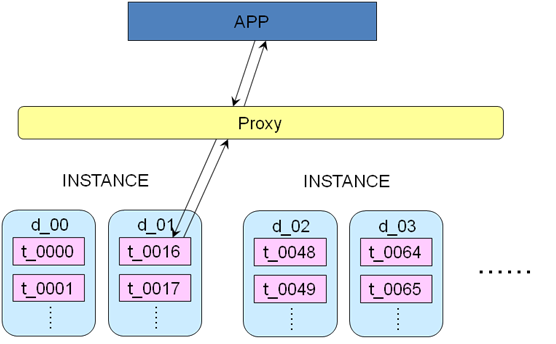
����3������Data Engine
�C ���֮��IJ�ѯ��������һ��Data Engine Service�����DES�����������������ݿ�ʵ����ӳ���ϵ����Ҫ��APPӦ�ö˰�װһ��Agent����ͬ��������JDBC��ʵ�֣�DES����ʵ�ֶ�д���룬ԭ�����Բο�TDDL��ʵ�֡�
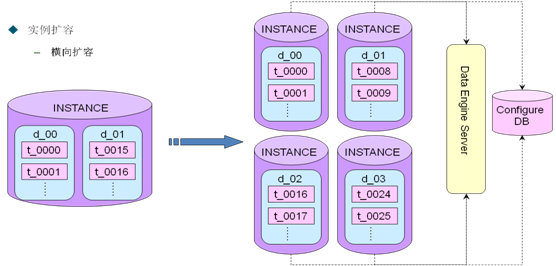
6.3 ��Ⱥ����
�������ݣ�һ��ʵ����ֳɶ��ʵ���������ֱȽϼ��ĵĶ����Ƚ��٣���ֵ�ʱ��Ҫ֪ͨ��Configure
DB����DES��������֮���ѯ�������ݻ�������¼�벻���µ�db���棬����ͼ��ʾ��
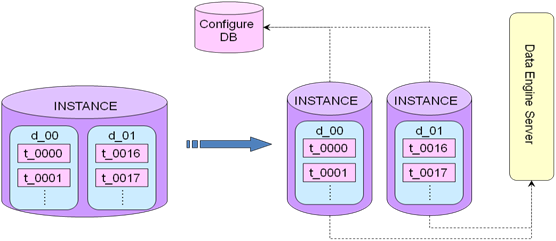
�������ݣ��Ƚϸ��ӣ����������ݳ�2����Ļ���֮�ϣ���һ�ζԿ�ı��������ݣ�������Ҫ��ʱ֪ͨConfigure
DB��DES��ϸ��ͱ���·��������Ϣ��
|





