| 1.编程模型
我们知道hadoop有mapreduce编程模型,那么与之对应的storm的编程模型是什么那,下面我们详细介绍一下。
在storm的编程模型中,主要有三个组件,一个是Topology,这个Topology是一个由多个计算节点构成的拓扑图。结算节点分为两种,一种是Spout,一种是Blot。这些Spout和Bolt构成下图所示的一个多节点的有向图。(数据从左向右流动)。整个图是一个Topology,其中有2个Spout和4个Bolot组成。
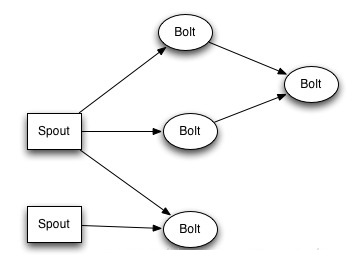
Spout是Storm的Topoloy的入口,数据流都是从Spout进入topology来进行处理。他负责从外部接收数据,处理,然后发射出去。每个Topology至少要有一个Spout
Bolt是数据处理单元,他可以从一个或者多个其他的计算节点接收数据,处理并发射出去。他可以从Spout接收数据,也可以从其他的Bolt接收数据。Bolt数量可以为0。
Spout的数据发射给谁,Bolt从谁接收数据这些将不会再Spout和Bolt类中声明,在组装Topology的时候说明。
2.编程步骤
我们要编写一个完整的storm的程序,需要经过四步
编写一个或者多个Spout
编写一个或者多个Bolt
编写一个带Main函数的然后将其组装成为一个Topology
最后提交给storm集群运行
3.详细实现
略
4.需求
假设我们会不断的将一些移动用户上网日志记录文件存储到HDFS的某个目录下,要求我们能够快速的将新到达的文件解析成我们需要的结构,存储到HBase数据库的上网日志表中,并且对每个用户上网记录的次数做统计,超出门限值后存储到Hbase的超门限信息表中。
4.1具体实现
通过分析,我们采用storm来实现该需求,首先我们设计出我们的处理架构图如下所示
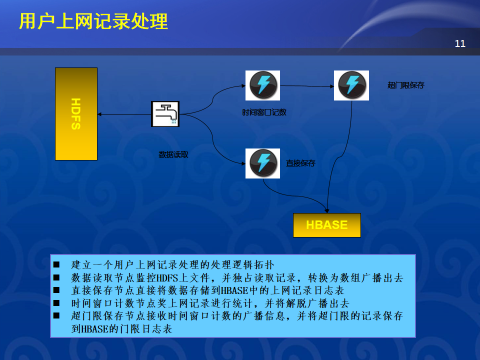
由以上设计,我们需要实现一个Spout类(com.ygc.mobilenet.MobileNetLogAnalyseSpout)负责从HDFS读取数据,初步处理然后发射(emit)出去。我们要实现三个Bolt类,一个Bolt类(com.ygc.mobilenet.MobileNetLogSaveBolt)负责获取每条记录,并存储到HBase数据库中。一个Bolt类(com.inspur.mobilenet.MobileNetLogStatisticsBolt)负责按手机号在时间窗口内统计上网记录数。一个Bolt类(com.inspur.mobilenet.MobileNetLogThresholdBolt)负责检查每个手机号时间窗口内上网记录数是否超门限,如果超门限则保存到Hbase数据库中。
在实现之前,我们要导入依赖包。我是用maven来管理依赖包的。所以我的maven依赖配置如下所示
<dependencies>
<dependency>
<groupId>storm</groupId>
<artifactId>storm</artifactId>
<version>0.8.1</version>
</dependency>
<dependency>
<groupId>com.ygc.hadoop</groupId>
<artifactId>hadoop2client</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies> |
我对HBase和HDFS的访问都封装到hadoop2client这个jar包中了,而这个jar包依赖的hadoop和hbase的包在他自己的pom.xml文件中声明,不需要我们自己显式的声明。这是maven的好处,只用声明直接依赖即可。
当然,我们一定要导入storm本身的包才行
以下章节分别描述每个部分具体的实现。
4.2.1Spout实现
4.2.1.1com.ygc.mobilenet.MobileNetLogVal
类
这个是一个辅助类,用来描述读取的数据文件结构的,不需要解释
package com.ygc.mobilenet;
import backtype.storm.tuple.Fields;
/**
* 用来描述要解析的日志内容的辅助类
*/
public class MobileNetLogVal {
//上网开始时间
public static String START_TIME_FIELD = "START_TIME";
//上网响应时间
public static String RESPONSE_TIME_FIELD = "RESPONSE_TIME";
//响应结束时间
public static String END_TIME_FIELD = "END_TIME";
//源设备IP
public static String SOURCE_DEV_IP_FIELD = "SOURCE_DEV_IP";
//源用户IP
public static String SOURCE_USER_IP_FIELD = "SOURCE_USER_IP";
//源端口
public static String SOURCE_PORT_FIELD = "SOURCE_PORT";
//目标设备IP
public static String DEST_DEV_IP_FIELD = "DEST_DEV_IP";
//目标用户IP
public static String DEST_USER_IP_FIELD = "DEST_USER_IP";
//目标端口
public static String DEST_PORT_FIELD = "DEST_PORT";
//IMSI标识设备
public static String IMSI_FIELD = "IMSI";
//MSISDN标识手机号码
public static String MSISDN_FIELD = "MSISDN";
//移动上网接入点
public static String APN_FIELD = "APN";
//用户操作系统。一般是浏览器型号或者程序名
public static String USER_AGENT_FIELD = "USER_AGENT";
//目标URL
public static String URL_FIELD = "URL";
//目标主机,包含在URL中
public static String HOST_FIELD = "HOST";
/**
* 创建一个Spout要发射的数据结构。
*
* @return 返回Spout要发射的数据结构。
*/
public Fields createFields() {
return new Fields(
START_TIME_FIELD,
RESPONSE_TIME_FIELD,
END_TIME_FIELD,
SOURCE_DEV_IP_FIELD,
SOURCE_USER_IP_FIELD,
SOURCE_PORT_FIELD,
DEST_DEV_IP_FIELD,
DEST_USER_IP_FIELD,
DEST_PORT_FIELD,
IMSI_FIELD,
MSISDN_FIELD,
APN_FIELD,
USER_AGENT_FIELD,
URL_FIELD,
HOST_FIELD);
}
}
|
4.2.1.2com.ygc.mobilenet.MobileNetLogAnalyseSpout类
package com.ygc.mobilenet;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
import com.ygc.hadoop.hdfs.HDFSClient;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import java.io.BufferedReader;
import java.io.File;
import java.util.Map;
/**
* @author inspur research
* @since 2014-01-09
* 接收移动用户上网记录并发射
*/
public class MobileNetLogAnalyseSpout implements
IRichSpout {
private SpoutOutputCollector outputCollector;
private HDFSClient hdfsClient;
private Log log = LogFactory.getLog(MobileNetLogAnalyseSpout.class);
//要监控的HDFS文件目录
private String MONITOR_PATH = "/storm/mobilelog";
@Override
public void declareOutputFields(OutputFieldsDeclarer
outputFieldsDeclarer) {
//每个Spout或者Blot要emit数据,必须指定数据的结构。
outputFieldsDeclarer.declare(new MobileNetLogVal().createFields());
}
/**
* 解析一行数据,转换为后续要处理的数据结构,这里从数据中读取了15列数据
* @param line 从数据源接收的一行数据
* @return 格式化好的Values对象。
*/
public Values createValues(String line) {
String[] cols = line.split("[|]");
return new Values(
cols[0],
cols[1],
cols[2],
cols[4],
cols[6],
cols[12],
cols[5],
cols[7],
cols[13],
cols[28],
cols[29],
cols[32],
cols[33],
cols[30],
cols[31]
);
}
@Override
public Map<String, Object> getComponentConfiguration()
{
return null;
}
@Override
public void open(Map map, TopologyContext topologyContext,
SpoutOutputCollector spoutOutputCollector) {
//需要通过SpoutOutputCollector对象来emit数据流和
this.outputCollector = spoutOutputCollector;
try {
//读取HDFS文件的客户端,自己实现
hdfsClient = new HDFSClient();
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void close() {
}
@Override
public void activate() {
}
@Override
public void deactivate() {
}
@Override
public void nextTuple() {
Utils.sleep(10000);
try {
//该方法从指定的目录中中读取符合条件的文件列表,并随机从中选择一个将其独占并返回文件名
String lockFileName = hdfsClient.lockFileName(MONITOR_PATH,
".TXT");
if (lockFileName != null) {
//从HDFS中打开已经被独占的文本文件
BufferedReader read = hdfsClient.getBufferedReader(lockFileName);
String line;
int count = 0;
while ((line = read.readLine()) != null) {
if (line.trim().length() > 0) {
count++;
this.outputCollector.emit(createValues(line));
}
}
log.info("deal file " + lockFileName
+ " " + count + " rows!");
}
} catch (Exception e) {
log.error(e);
}
}
@Override
public void ack(Object o) {
}
@Override
public void fail(Object o) {
}
}
|
4.2.1.3重点解释
要实现一个Spout类,一般的做法是实现backtype.storm.topology.IRichSpout接口,重点的是要实现下面的几个接口4.2.1.3.1public
void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer)
接口在这个接口里,我们要声明本Spout要发射(emit)的数据的结构,及一个backtype.storm.tuple.Fields对象。这个对象和public
void nextTuple()接口中emit的backtype.storm.tuple.Values共同组成了一个元组对象(backtype.storm.tuple.Tuple)供后面接收该数据的Blot使用
4.2.1.3.2public void open(Map map, TopologyContext
topologyContext, SpoutOutputCollector spoutOutputCollector)接口
该接口是初始化接口。在这里要将SpoutOutputCollector spoutOutputCollector对象保存下来,供后面的public
void nextTuple()接口使用,还可以执行一些其他的操作。例如这里将HDFSClient对象初始化了。
4.2.1.3.3public void nextTuple() 接口该接口实现具体的读取数据源的方法。本例中是从HDFS中读取一个数据文件,并逐行解析,将获取的数据emit出去。emit的对象是通过public
Values createValues(String line)方法生成的backtype.storm.tuple.Values对象。该方法从数据源的一行数据中,选取的15个目标值组成一个backtype.storm.tuple.Values对象。这个对象中可以存储不同类型的对象,例如你可以同时将String对象,Long对象存取在一个backtype.storm.tuple.Values中emit出去。实际上只要实现了Storm要求的序列化接口的对象都可以存储在里面。emit该值得时候需要注意,他的内容要和declareOutputFields中声明的backtype.storm.tuple.ields对象相匹配,必须一一对应。他们被共同组成一个backtype.storm.tuple.Tuple元组对象,被后面接收该数据流的对象使用。
4.2.2Bolt实现
4.2.2.1com.ygc.mobilenet.MobileNetLogSaveBolt类
package com.ygc.mobilenet;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
import com.inspur.hadoop.hbase.HTableClient;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import java.util.Map;
/**
* 负责将所有上网记录保存到HBase数据库中
*/
public class MobileNetLogSaveBolt implements IRichBolt
{
private OutputCollector outputCollector;
private HTableClient tableClient;
private Log log = LogFactory.getLog(MobileNetLogSaveBolt.class);
@Override
public void prepare(Map map, TopologyContext topologyContext,
OutputCollector outputCollector) {
this.outputCollector = outputCollector;
try {
//初始化HBase数据库
tableClient = new HTableClient("192.168.1.230");
} catch (Exception e) {
log.error(e);
}
}
@Override
public void execute(Tuple tuple) {
try {
log.info("access tuple " + tuple.getValues()+"files
info = " +tuple.getFields().toString());
saveTupleToHBase(tuple);
this.outputCollector.emit(tuple, tuple.getValues());
} catch (Exception e) {
log.error(e);
} finally {
outputCollector.ack(tuple);
}
}
/**
* 将接收的元组保存到数据库
* @param tuple 从其他计算节点接收的数据流,这里是从com.ygc.mobilenet.MobileNetLogAnalyseSpout中接收的数据流。注意和该类中声明的backtype.storm.tuple.Fields对象和emit的backtype.storm.tuple.Values对象对应
* @return
*/
private boolean saveTupleToHBase(Tuple tuple)
{
try {
String rowKey = createRowKeyByeTuple(tuple);
long ts = System.currentTimeMillis();
tableClient.insertRow("t_mobilenet_log",
rowKey, "TIME",
MobileNetLogVal.START_TIME_FIELD, ts, tuple.getStringByField(MobileNetLogVal.START_TIME_FIELD));
tableClient.insertRow("t_mobilenet_log",
rowKey, "TIME",
MobileNetLogVal.RESPONSE_TIME_FIELD, ts, tuple.getStringByField(MobileNetLogVal.RESPONSE_TIME_FIELD));
tableClient.insertRow("t_mobilenet_log",
rowKey, "TIME",
MobileNetLogVal.END_TIME_FIELD, ts, tuple.getStringByField(MobileNetLogVal.END_TIME_FIELD));
tableClient.insertRow("t_mobilenet_log",
rowKey, "SOURCE_INFO",
MobileNetLogVal.SOURCE_DEV_IP_FIELD, ts, tuple.getStringByField(MobileNetLogVal.SOURCE_DEV_IP_FIELD));
tableClient.insertRow("t_mobilenet_log",
rowKey, "SOURCE_INFO",
MobileNetLogVal.SOURCE_USER_IP_FIELD, ts, tuple.getStringByField(MobileNetLogVal.SOURCE_USER_IP_FIELD));
tableClient.insertRow("t_mobilenet_log",
rowKey, "SOURCE_INFO",
MobileNetLogVal.SOURCE_PORT_FIELD, ts, tuple.getStringByField(MobileNetLogVal.SOURCE_PORT_FIELD));
tableClient.insertRow("t_mobilenet_log",
rowKey, "DEST_INFO",
MobileNetLogVal.DEST_DEV_IP_FIELD, ts, tuple.getStringByField(MobileNetLogVal.DEST_DEV_IP_FIELD));
tableClient.insertRow("t_mobilenet_log",
rowKey, "DEST_INFO",
MobileNetLogVal.DEST_USER_IP_FIELD, ts, tuple.getStringByField(MobileNetLogVal.DEST_USER_IP_FIELD));
tableClient.insertRow("t_mobilenet_log",
rowKey, "DEST_INFO",
MobileNetLogVal.DEST_PORT_FIELD, ts, tuple.getStringByField(MobileNetLogVal.DEST_PORT_FIELD));
tableClient.insertRow("t_mobilenet_log",
rowKey, "BASIC_INFO",
MobileNetLogVal.APN_FIELD, ts, tuple.getStringByField(MobileNetLogVal.APN_FIELD));
tableClient.insertRow("t_mobilenet_log",
rowKey, "BASIC_INFO",
MobileNetLogVal.IMSI_FIELD, ts, tuple.getStringByField(MobileNetLogVal.IMSI_FIELD));
tableClient.insertRow("t_mobilenet_log",
rowKey, "BASIC_INFO",
MobileNetLogVal.MSISDN_FIELD, ts, tuple.getStringByField(MobileNetLogVal.MSISDN_FIELD));
tableClient.insertRow("t_mobilenet_log",
rowKey, "BASIC_INFO",
MobileNetLogVal.URL_FIELD, ts, tuple.getStringByField(MobileNetLogVal.URL_FIELD));
tableClient.insertRow("t_mobilenet_log",
rowKey, "BASIC_INFO",
MobileNetLogVal.HOST_FIELD, ts, tuple.getStringByField(MobileNetLogVal.HOST_FIELD));
} catch (Exception e) {
log.error(e);
return false;
}
return true;
}
private String createRowKeyByeTuple(Tuple tuple)
{
return tuple.getStringByField(MobileNetLogVal.MSISDN_FIELD)
+ tuple.getStringByField(MobileNetLogVal.START_TIME_FIELD);
}
@Override
public void cleanup() {
}
@Override
public void declareOutputFields(OutputFieldsDeclarer
outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new MobileNetLogVal().createFields());
}
@Override
public Map<String, Object> getComponentConfiguration()
{
return null;
}
} |
需要注意几个方面:
因为这个Bolt处理完了后,将数据原样发射出去。所以这里的public
void declareOutputFields方法和com.ygc.mobilenet.MobileNetLogAnalyseSpout中的方法一样。
而在private boolean saveTupleToHBase(Tuple
tuple)方法中处理backtype.storm.tuple.Tuple对象的时候主要该对象的内容和前面计算单元(com.ygc.mobilenet.MobileNetLogAnalyseSpout)声明的backtype.storm.tuple.Fields对象和emit的backtype.storm.tuple.Values对象对应。
4.2.2.2com.ygc.mobilenet.MobileNetLogStatisticsBolt
package com.ygc.mobilenet;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import java.util.HashMap;
import java.util.Map;
/**
* 统计时间窗口内上网记录数。这里没有实现时间窗口。
*/
public class MobileNetLogStatisticsBolt implements
IRichBolt {
private OutputCollector outputCollector;
private Map<String, Integer> requestStatistic
= new HashMap<String, Integer>();
@Override
public void prepare(Map map, TopologyContext topologyContext,
OutputCollector outputCollector) {
this.outputCollector = outputCollector;
}
@Override
public void execute(Tuple tuple) {
String msisdn = tuple.getStringByField(MobileNetLogVal.MSISDN_FIELD);
Integer count = 1;
if (requestStatistic.containsKey(msisdn)) {
count = requestStatistic.get(msisdn) + 1;
}
requestStatistic.put(msisdn, count);
this.outputCollector.emit(tuple, new Values(msisdn,
count));
this.outputCollector.ack(tuple);
}
@Override
public void cleanup() {
}
@Override
public void declareOutputFields(OutputFieldsDeclarer
outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields(MobileNetLogVal.MSISDN_FIELD,"count"));
}
@Override
public Map<String, Object> getComponentConfiguration()
{
return null;
}
} |
重点注意:
这里声明的backtype.storm.tuple.Fields包含两个字段MobileNetLogVal.MSISDN_FIELD,"count";
这里emit的backtype.storm.tuple.Values同样对应两个字段,而且一个是String类型一个是Integer类型
这里emit时,第一个字段为原始的acktype.storm.tuple.Tuple,第二个字段才是要emit的backtype.storm.tuple.Values。这里是为了建立源消息和派生消息直接的树形结构,让storm框架能够自动跟踪该消息是否被完整的处理。这是保证storm中的数据可靠性的一个机制。这里先不讨论。你也可以不要第一个参数。那么backtype.storm.tuple.Values被发射出去后,是否被成功处理storm就不管了。
4.2.2.3com.ygc.mobilenet.MobileNetLogThresholdBolt
package com.ygc.mobilenet;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
import com.inspur.hadoop.hbase.HTableClient;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import java.util.Map;
/**
* 负责检查用户上网次数是否门限,如果超门限则保存到HBase数据库中
*/
public class MobileNetLogThresholdBolt implements
IRichBolt {
private OutputCollector outputCollector;
//操作HBase数据库的客户端
private HTableClient tableClient;
private Log log = LogFactory.getLog(MobileNetLogThresholdBolt.class);
@Override
public void prepare(Map map, TopologyContext topologyContext,
OutputCollector outputCollector) {
this.outputCollector = outputCollector;
try {
tableClient = new HTableClient("192.168.1.230");
} catch (Exception e) {
log.error(e);
}
}
@Override
public void execute(Tuple tuple) {
log.info("deal data " + tuple.getString(0)
+ "=" + tuple.getInteger(1));
if (tuple.getInteger(1) > 2) {
try {
tableClient.insertRow("t_mobilenet_threshold",
tuple.getString(0), "STAT_INFO", "COUNT",
String.valueOf(tuple.getInteger(1)));
} catch (Exception e) {
log.error(e);
}
}
this.outputCollector.emit(tuple, tuple.getValues());
this.outputCollector.ack(tuple);
}
@Override
public void cleanup() {
}
@Override
public void declareOutputFields(OutputFieldsDeclarer
outputFieldsDeclarer) {
}
@Override
public Map<String, Object> getComponentConfiguration()
{
return null;
}
} |
重点解释:
只要注意在从元组中取数的时候,tuple.getString(0)和tuple.getInteger(1)分别对应了com.inspur.mobilenet.MobileNetLogStatisticsBolt对象中发射的MobileNetLogVal.MSISDN_FIELD,"count"字段对应即可。在com.inspur.mobilenet.MobileNetLogStatisticsBolt中我们取元组数据的时候是通过Field的名字来取的,这里是通过序号来取的。
4.2.3组装实现
现在,我们开发的组件需要组装成Topology了这个是在一个带Main函数的类里面实现的。从上面的设计图看,结构应该是com.ygc.mobilenet.MobileNetLogAnalyseSpout作为该Topology读取数据的源,他发射的数据分别被com.ygc.mobilenet.MobileNetLogSaveBolt、com.ygc.mobilenet.MobileNetLogStatisticsBolt对象接收。而com.ygc.mobilenet.MobileNetLogStatisticsBolt对象发射的数据流被com.ygc.mobilenet.MobileNetLogThresholdBolt对象接收。所以组装Topology的代码如下所示
package com.ygc.mobilenet;
import backtype.storm.Config;
import backtype.storm.StormSubmitter;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
/**
* 组装storm的Topology的代码
*/
public class MobileNetLogTopology {
public static void main(String[] args) {
if (args.length > 0) {
int worknum = Integer.parseInt(args[0]);
int execunum = Integer.parseInt(args[1]);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("analyseMobileNetlog",
new MobileNetLogAnalyseSpout(), execunum);
builder.setBolt("saveMobileNetlog",
new MobileNetLogSaveBolt(), execunum).shuffleGrouping("analyseMobileNetlog");
builder.setBolt("countMobileNetlog",
new MobileNetLogStatisticsBolt(), execunum).fieldsGrouping("analyseMobileNetlog",
new Fields(MobileNetLogVal.MSISDN_FIELD));
builder.setBolt("thresholdMobileNetlog",
new MobileNetLogThresholdBolt(), execunum).shuffleGrouping("countMobileNetlog");
Config conf = new Config();
conf.setNumWorkers(worknum);
conf.setMaxSpoutPending(5000);
try {
StormSubmitter.submitTopology("mobilenetlogtopology",
conf, builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
|
builder.setSpout("analyseMobileNetlog",
new MobileNetLogAnalyseSpout(), execunum);设置Topology的Spout是谁。可以设置多个,其中第一个参数是该计算节点的名称,在同一个Topology中必须保持唯一性。第三个参数是设置该计算单元执行者数量的参数,即有多少个线程来执行该计算逻辑。
builder.setBolt("saveMobileNetlog",
new MobileNetLogSaveBolt(), execunum).shuffleGrouping("analyseMobileNetlog");设置一个Bolt。第一个参数还是该计算节点的名称。必须保持唯一性。第三个节点同样是设置该计算单元执行数量的参数
shuffleGrouping("analyseMobileNetlog")方法,表示该Bolt计算单元要随机从ID为"analyseMobileNetlog"的计算节点,即前面设置的Spout对象中接收数据。
builder.setBolt("countMobileNetlog",
new MobileNetLogStatisticsBolt(), execunum).fieldsGrouping("analyseMobileNetlog",
new Fields(MobileNetLogVal.MSISDN_FIELD));设置第二个Bolt。因为是在内存中对手机号码做上网记录的统计,所以相同手机号的数据需要发送到同一个MobileNetLogStatisticsBolt的线程来处理,所以这里使用了一个fieldsGrouping("analyseMobileNetlog",
new Fields(MobileNetLogVal.MSISDN_FIELD))的方式来分发数据。
builder.setBolt("thresholdMobileNetlog",
new MobileNetLogThresholdBolt(),execunum).shuffleGrouping("countMobileNetlog");这个没有新鲜内容。
在组装Topology的过程中涉及到一个Stream Grouping的概念,这个概念就是Topology的各个计算单元之间数据流分发的一个策略。不同的策略应用在不同的场景下。例如上面第三节,要求某个字段(手机号)相同的数据必须发送到后续计算节点同一个任务中。Stream
Grouping默认提供如下的类别
shuffleGrouping:是前一个计算单元随机的将数据流发送给后一个计算单元的Task
fieldsGrouping:是通过某个字段来识别,将该字段值一样的数据流发送给后一个计算单元的同一个Task。即如果以手机号为fieldsGrouping的依据,前一次将手机号为138111111111的数据发送Task1,则下一次的138111111111的数据不会发给其他的Task来处理。
All grouping:将数据流发送给所有后一个计算节点的Task,即如果后一个计算节点有5个Task,这5个Task都将接收到所有的数据。我现在想不到这个用在什么场景下。
Global grouping:这个意思是说数据流将被消费他的Bolt的任务号最小的任务接收。
None grouping:这个意思是你不关系数据如何被分发,实际上,他等同于shuffleGrouping。
Direct grouping:这个是说让生成元组的对象自己决定消费这个元组的计算单元的哪个任务来接收这个元组。他在发射的时候必须用emitDirect方法来发射,并指明taskId。
4.2.4提交执行
提交这个storm的Topology任务之前,要将以上代码需要的相关jar中和storm0.8.1无关的其他jar包全部打到一个jar中,例如上述相关的就有自己实现的HDFSClient、HTableClient以及他们相关的Hadoop、Hbase依赖包都打包到同一个stormdemo-1.0-SNAPSHOT-jar-with-dependencies.jar文件中。这里可以使用maven的装配插件来完成这个打包的工作
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
</build> |
这个组装插件可以将你的项目依赖的所有jar包解压和你的class一起打包到你的jar文件中。当然,里面也会有一些坑。例如多个jar包中有同一个配置文件互相覆盖导致的问题我就遇到过。
打包好了后,将该jar文件上传到storm的nimbus进程所在的服务器上,执行如下的命令
storm jar stormdemo-1.0-SNAPSHOT-jar-with-dependencies.jar
com.ygc.mobilenet.MobileNetLogTopology 16 4
其中16、4是com.ygc.mobilenet.MobileNetLogTopology对象要读取的的命令行参数。分别用户用来设置执行该Topology的worker的数量和executors的数量。这两个数量分别设置了这个Topoploy要执行的进程数和每个计算单元执行的线程数。
如果成功,会显示如下的信息
0 [main] INFO backtype.storm.StormSubmitter - Jar not uploaded to master yet. Submitting jar...
10 [main] INFO backtype.storm.StormSubmitter -
Uploading topology jar stormdemo-1.0-SNAPSHOT-jar-with-dependencies.
jar to assigned location: /home/storm/stormlocale/nimbus/inbox/stormjar-a3bdefb1-6ec5-40ab-8153-6baab889b043.jar
593 [main] INFO backtype.storm.StormSubmitter - Successfully uploaded topology
jar to assigned location: /home/storm/stormlocale/nimbus/inbox/stormjar-a3bdefb1-6ec5-40ab-8153-6baab889b043.jar
593 [main] INFO backtype.storm.StormSubmitter - Submitting topology
mobilenetlogtopology in distributed mode with conf {"topology.workers":16,"topology.max.spout.pending":5000}
719 [main] INFO backtype.storm.StormSubmitter - Finished submitting topology: mobilenetlogtopology |
在Storm UI界面上将看到如下的界面
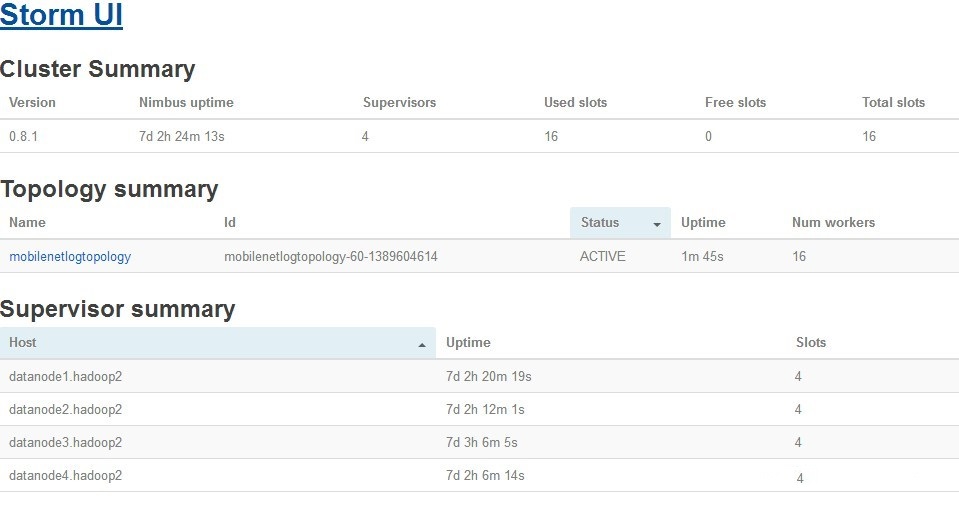
4.2.5执行效果4.2.5.1查看Storm UI效果
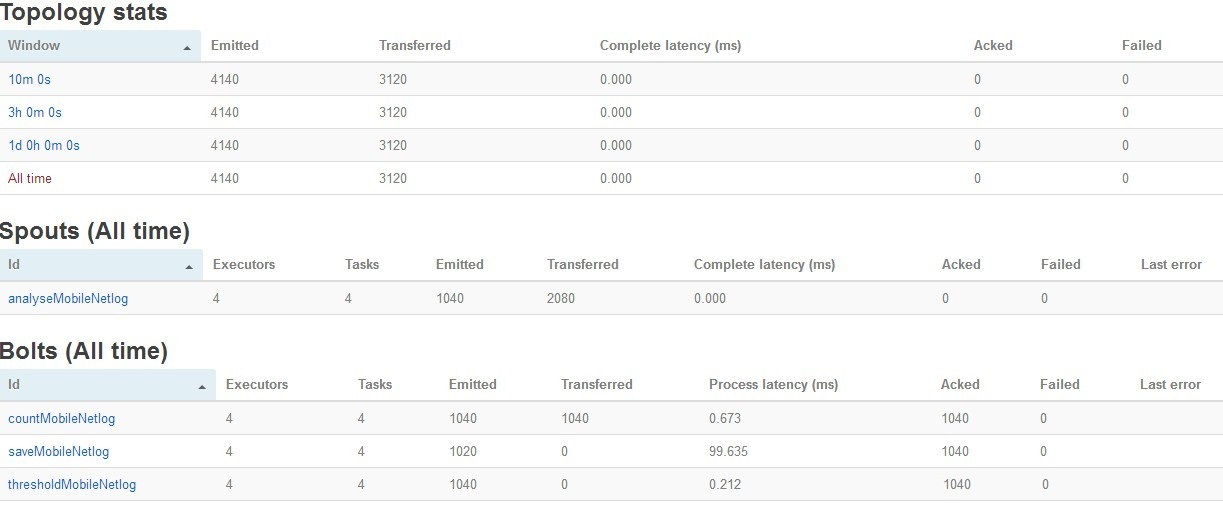
现在我们将几个要处理的上网日志文件上传到HDFS的/storm/mobilelist文件夹中。等一会刷新storm
UI界面,点击上图中的mobilenetlogtopology链接,可以看到如下的画面。里面是该Topology运行的详情
4.2.5.2查看HBase数据在HBase的HMaster上执行
hbase shell
进入HBase交互界面,执行如下的命令
scan 't_mobilenet_log'
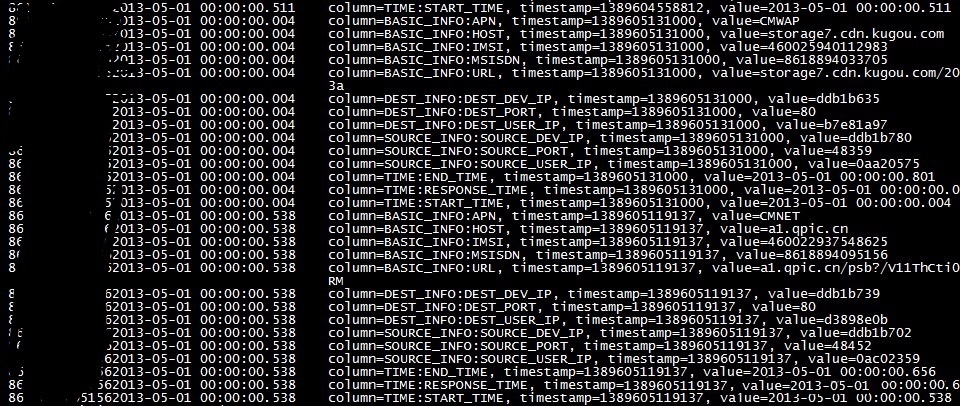
另一个表的数据就不看了。到这里一个完整的Storm的流计算应用就算是完成了,希望对大家有用。如果有不对的地方也请指正。我也是刚刚接触。理解不到位的地方还有不少。希望一起讨论。
|





