|
本文根据王晶昱(花名沈询)老师在“高可用架构”微信群所做的《NoSQL VS SQL》分享整理而成,转发请注明来自微信公众号ArchNotes。

王晶昱,花名沈询,阿里资深技术专家,专注分布式数据库七年。毕业加入淘宝,在淘宝分布式数据层干了七年,参与了大部分的淘宝数据库业务架构设计工作。目前关注于分布式数据库DRDS和分布式消息系统ONS的研发工作。
以下为分享内容实录:
前言
今天想介绍的东西是NoSQL到SQL。我之所以选择这个题目,其实就是因为看到了一张图:

(图1)
看完以后我真的噗嗤就笑了,黑的漂亮。
今天要分享的主题有如下几个方面:
- 1970:We have no SQL
-
1980:Know SQL
-
2005:Not only SQL
-
2013:No,SQL!
阿里的技术选择
对一个对数据库历史有点了解的人来说,这张图真的是反映了我们在数据库存储领域螺旋上升式发展历程的最佳代表。这哥们真的是天赋异禀啊!
为什么我会笑呢? 希望我做完了这次分享,大家也能跟我一样笑一下。
那么我们先来到第一章。
1970:We have no SQL
恩!我们没有SQL。
要介绍这个问题,我们就要先来看看什么叫数据库,以及数据库这个东西是怎么来的。
程序员一般都会碰到类似这样的需求:用计算机表示一辆车子。这辆车呢,它有一个外壳,四扇玻璃,四个轮子。
我应该如何用程序来表述它呢?首先能想到的一定是使用结构体(Java的话是Class)。
但当我们发现这个车子的项不够用了,比如我需要在车子上面装一对反光镜,怎么办呢?我们只能往里面增加一个新的属性来表示这个反光镜。如果这种需求越来越多,越来越多,我们就会发现,每次都改一下这个结构体、编译、发布,是个非常麻烦的事情。
于是,就有了这种非常纯粹的需求:有没有可能把它弄成动态的。这时候,我们最常用到的一个数据结构就是“映射”。
对Java程序员来说,映射就是一个Map<Object,Object>。一般来说Map有两类实现:一类是Hash,一类是有序树。有了这个随需应变的集合,我们就可以把事情变成这样:
- map.put("轮子",轮子对象);
-
map.put("镜子",镜子对象) ......
有些时候我们又会担心数据丢失,对不对?
所以还得想办法把这个对象以非常高效的方式持久化下来,放到磁盘上,这样就不容易丢失了。
map.put/get操作其实都会有一次寻找的过程的,这个寻找过程对于磁盘来说会转变为一次随机寻道过程。有很多种方式能够用磁盘结构来存储类似Map这样的概念。我今天只介绍一种,就是B-tree,不知道大家对这个词儿是不是熟悉,反正我面试基本都会问问。
需要先提的一件事是B树 == B-树。所谓B-树,并不是B减树的意思,希望大家不要跟我一样土鳖。

(图2)
这就是一个最简单的B树,观察一下就会发现,其实B树的出发点很简单:既然磁盘寻道时间很多,那就减少它,一次寻道能够从磁盘取更多数据就行了。所以,它是以“数组” 为单位存储数据的(数组其实就是一片连续并且有界的空间)。数组难以扩展,并且维护数组内元素有序也是有一定代价的。数组满了以后怎么办呢? 这就是B树会做的事儿,分裂。如果这里大家能够联想到另外一个东西,那就算学明白了,HBase其实就是棵巨大的、分布式的B树。其他容我最后吐槽~。
相信很多人都听过一个名词:层次数据库。这东西似乎就是在上古时代的神器,现在则不见了踪影。层次数据库到底是个什么玩意儿呢?我们来看一张图。

(图3)注:图片来自网络
抽象来看,层次模型其实就是这样的东西,我再用小汽车来表述一下:一个小车由四扇玻璃,四个轮子,两个反光镜组成。车有自己的属性,轮子有自己的属性,反光镜有自己的属性。
给大家两个例子相信大家应该立刻就能明白了,所谓的层次模型,如果用Java代码来写的话,就是Map套Map ,每个Map有一些固定的属性,比如这个Map的名字是什么,这个Map的属性是什么,而这就是我们最开始在使用的数据库了。非常简单,一个Map结构搞定所有需求。 看起来世界大同了。
1980:Know SQL
下面,我们就来到了1980年,Know SQL,知道SQL了。
为什么这么写?其实就是虽然关系数据库是上世纪70年代发明的,但是直到80年代,IBM发布了第一代全功能的关系数据库系统System R后,我们才正式进入到关系数据库模型。
相信很多人都觉得自己了解关系模型,似乎每个人提到它,都说“对对对”。绝对对,因为这是有数学支持的,不应该被怀疑。可惜的是,如果大家了解科学发现的历史就会发现,自从爱因斯坦把牛顿那由完美数学保证的自洽理论踢出了神坛,数学自洽就再也不是真理的标准了。哪个的用户最多哪个就是真理。为什么关系模型最终赢得了比赛,而层次模型死掉了呢?很简单,因为人类都是蠢蛋和傻瓜啊。哪个简单易用,哪个就赢了。
下面,我们就以一个例子来看看关系模型易用在哪里。还是以车子为例,如果我要做这样的一个查询:把厂里生产的所有汽车里面,左轮子供应商是DRDS的轮胎都找出来。采用层次模型的代码是:
遍历每一辆车,从车对象中找到左面的轮子,查看轮子的属性,如果是DRDS,留下,不是则丢弃。
如果是关系模型呢?
select * from 轮子表 where 轮子位置='左' and 轮子供应商='DRDS'
完成。
我看了都觉得是个世界性的创举,不知道您是什么感觉?下一步,我们来看看关系模型将会怎么处理这条SQL。
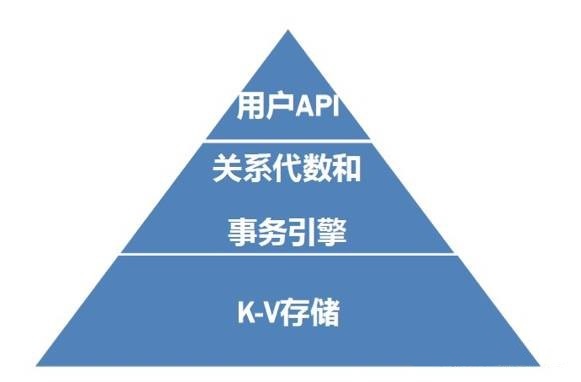
(图4)
其实用这一张图就可以表示一个最简单的关系模型了。基本上所有的数据库都是这个组织形式:最上面的用户API就是执行的SQL和事务命令、
中间的就是关系代数转换层和事务处理层、最后最底层是个KV存储。啊? KV这不是NoSQL的概念么,你凭什么盗用它?呵呵,谁盗用谁还不一定呢。
最底层的KV存储其实就是我们一开始说过的“映射”结构,对应内存可能有Hash和有序树结构,对应磁盘则主要是btree树系和LSM树系。因为每个数据结构都有自己好玩的属性,讲起来太多了,这里就不展开了,大家可以看我博客。我们直接来聊聊关系代数引擎,这是数据库最关键的部分之一,但从功能目标来说却并不是很复杂。
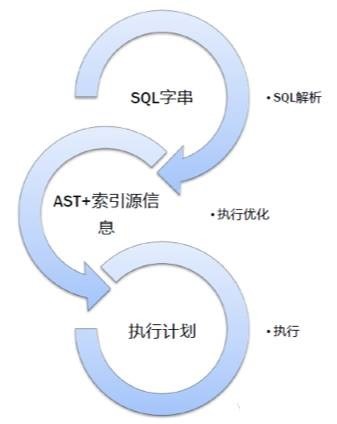
(图5)
这张图就是整个关系代数引擎所经过的步骤:
最原始的是SQL字符串,类似select * from tab where id = 1,它经过的过程叫SQL解析,会生成一个AST 抽象语法树。
如图6所示:
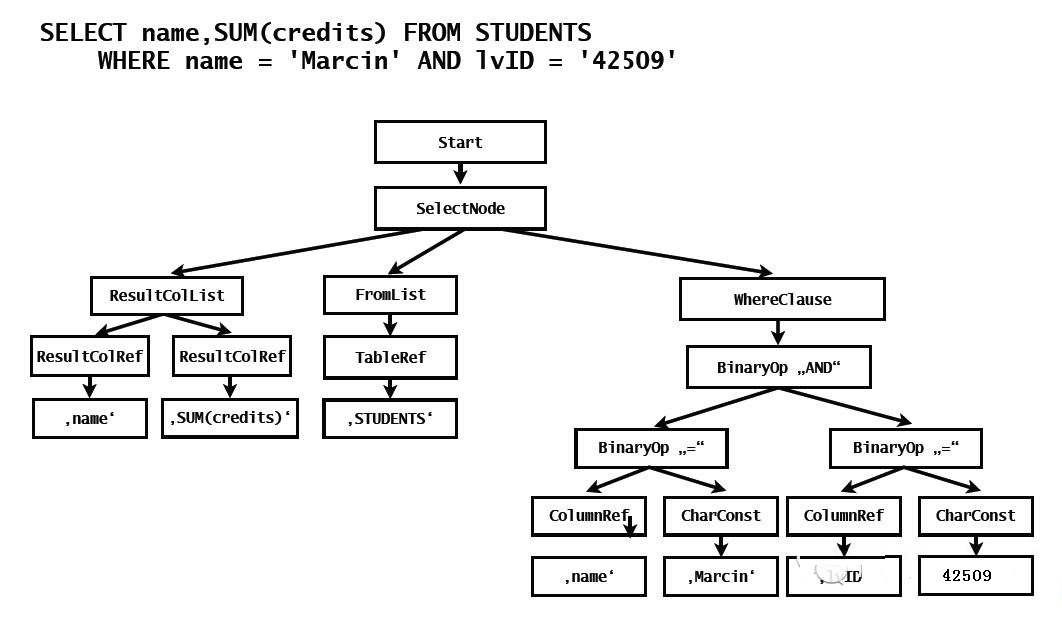
(图6)
select 被拆解为了fromList/WhereClause等细碎的字串。这个过程的主要作用是作为计算机编写代码而言,我们更容易识别这种结构化的数据,而文档属于非结构化数据;有了这棵树,下面就是执行优化,其入参是AST树+索引源信息。简单说来,AST使得你可以很容易地通过在树中来回的跳跃来寻找所需的关键字信息,比如where条件是什么,返回哪些列等。索引源信息又是个什么鬼?要讲明白这个,得先看看关系模型和Map是怎么对应起来的,我用几张PPT(很多人可能见过)来说明:

(图7)
第一个SQL是 select * from tab where id = ?,上面的那个则是一个表格,如果我们用Map来表示,可以表示成这样:
Map:key -> primaryKey, value -> [pk,user_id,Name]
也就是以PK值作为Map的key,以一个包含了pk, user_id, Name的值的结构作为Map的value(当然只包含[user_id,Name]也OK) 。有了这个Map,我们只需要从AST里面取出id = ? (假设id = 0),通过map.get(0)拿到对应的user_id数据和Name数据,加上输入的id=0这个数据,拼成对象返回就可以了。
再来看另一个需求。
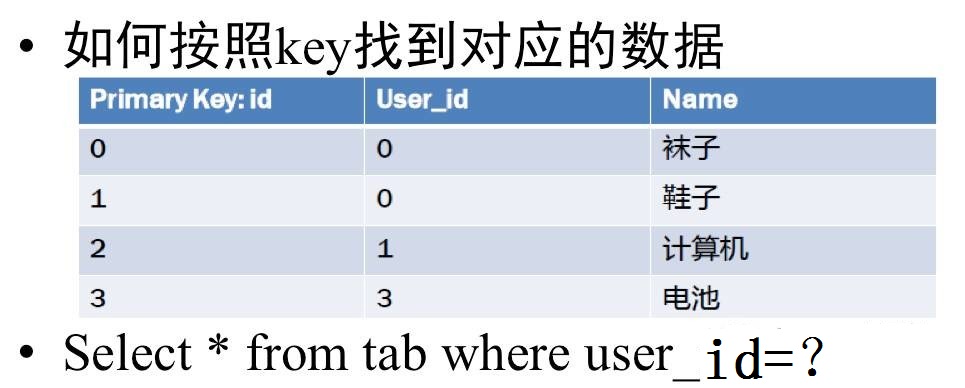
(图8)
我们来看看这个图,这里面我们的查询条件发生了变化,不是id了而是user_id。
我们刚才只有一个Map:
Map: key -> id , value -> [user_id,Name]
我应该如何利用这个Map去找到所有符合要求的结果呢?我能想到的第一种方式是遍历Map里面的每一个Entry,取出每一个Entry以后看看User_id是不是等于我要求的值,如果不等于就丢弃,等于的话返回即可。然而这种方式带来的问题是,如果我有1亿条记录,我就要做这件事1亿次。明显的 O(N)效率太慢了。怎么加快一下?有需求就有人响应。于是我们可以用个空间换时间的法子:
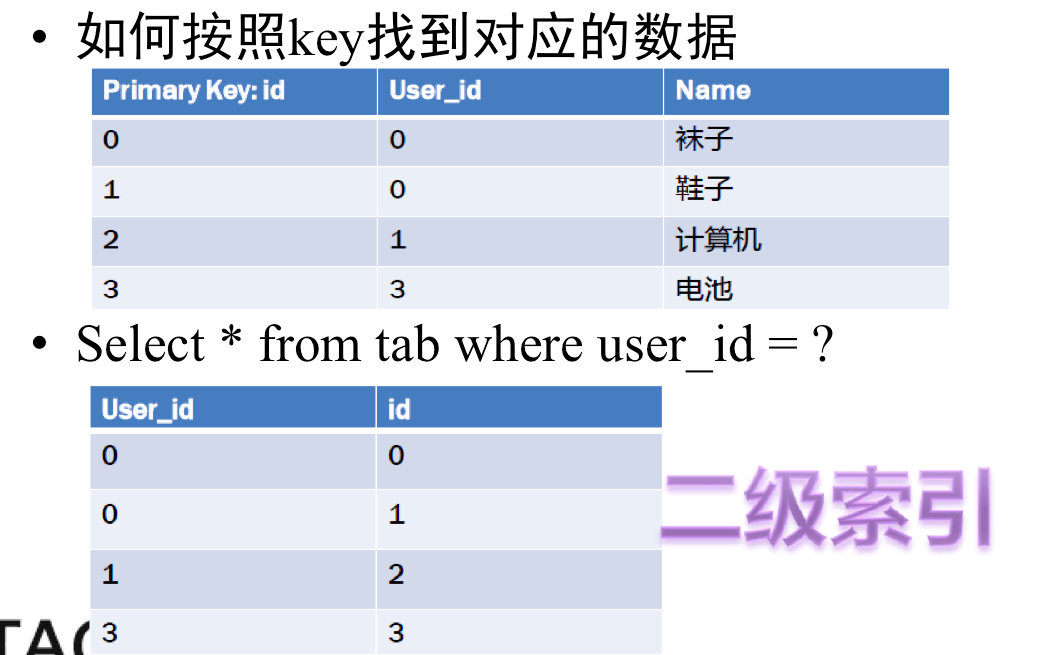
(图9)
看看上面的图,里面增加了一个新的Map:
Map: key -> user_id, value -> [id]
这个Map以user_id作为key,于是我们又可以愉快而高效地用第二个Map的get接口来获取所有符合要求的id列表,然后再根据这个符合要求的id列表,去查第一个Map,获得对应的数据了。刚才介绍的这块其实就是关系模型如何映射到Map(也就是KV模型)的关键方法了。当然,还会有很多扩展性的方式和方法,不过这就不是今天的主题咯。这个数据比较小,只有三列,一个索引。如果我有十几个甚至几十个索引的时候我们又会面对另一个问题。

(图10)
如果我有一个user_id的二级索引,又有一个Name的二级索引,我应该选择哪一个作为查询用的索引呢?是不是我需要有一种机制来选择那个最“便宜”的索引,这就是索引选择的过程。要进行索引选择就必然要知道每个索引的区分度高还是低(说白了就是一个key对应的pklist.size()少还是多),而索引的区分度高|低,就是所谓索引源信息的最简单模式。在真实的数据库中还有很多其他信息也是索引的源信息,不过为了方便大家理解简化了一下。有了索引源信息和AST树就可以生成执行计划了:

(图11)
这时候再尝试看看这个,相信大家就大概都能猜到这里的东西所表示的含义了。所以很多事儿呢不用去背,了解了背后的原理,优化就是信手拈来的事儿。这里我省略了事务步骤,这个更复杂,各位感兴趣可以看我的视频了解。
2000:No SQL!
No SQL! 豪言壮语,SQL数据库has gone,新时代来临了!似乎一夜之间,这世界就翻了天,Facebook开源了Cassandra,Hadoop Hbase横空出世,似乎这就是未来啊。
我们来看看知乎的问题:“互联网领域,传统的SQL很力不从心,一些更具有针对性的NoSQL会越来越火。以后会不会出来各种强力NoSQL?”,最雷我的一个问题大概是:“我们是一个新业务,想用NoSQL来提升开发效率,不知道Cassandra和HBase应该选哪个?”。
再见,看完以后我真的是觉得没办法好好做朋友了。
Digg采用Cassandra遭遇失败,工程副总裁离职,希望大家不是这个人。好啦,闲话扯完,回到正题。
No SQL是怎么来的?这还是得从事务说起,自从第一代产品化的数据库在上世纪80年代开发完成以后,我们的数据库主要演进模型里面只有几个有限的里程碑,我目前能记住的就这么几件事:
- mvcc 多版本并发控制;
-
存储过程;
-
各类OLAP的分析类引擎。
实际上大家心里都知道,有一件事一定会发生,只是不知道什么时候会发生。这就是分布式系统。分布式系统能够具备无限的扩展能力,按需伸缩,只要有钱我们的系统就不会down,不会死。这种能力其实在上世纪80年代就早已深入人心了。 还记得SUN公司提出的口号么?网络就是计算机。傻瓜都知道未来一定是分布式系统的天下,单机系统还有什么玩头?单机系统不就应该是那待宰的羔羊么?等着DRDS 异军突起不就好了么?但是等啊等啊,30年过去了,却没等到自己寿终正寝的那一天,反而似乎活的越来越好了,这是为什么?理由很简单,技术没突破。
如果一个分布式系统做的跟单机系统一样方便,又能扩展,性能又好,那这世界上早就没有单机系统了。而且,从上世纪80年代到21世纪的前几年,我们实际上都不需要分布式系统。大部分的系统都是诸如“图书馆管理系统”,“客户关系管理系统”等等企业内部管理系统,不需要很高的并发,只需要容易操作就行了,而单机的关系数据库系统自然地最容易操作啊,所以单机系统大行其道。
然而,云计算和互联网的时代到来了,我们服务的对象从顶天了几千人一下就变成了十几亿人,计算机要管理的数据量呈指数级别地飞速上涨,而我们却完全无法对用户数做出准确预估。这时候,扩展性、性能的要求就变得更为重要。不扩展的话业务就挂了,扩展的话开发难度少量上升,这两件事情做权衡,相信大家都能立刻知道哪个更重要。我们当然选扩展了!然而数据库却无法提供这样的扩展性,当年的淘宝也是用Oracle的,配置算不错的,也算是有小黑柜子。然而,今天不火的网站明天可能突然就火了,我们的用户数在一年内就会突破这个柜子的容量,折旧都来不及。很明显的,时代变了。
传统关系数据库,哪怕是RAC都不能满足我们对于数据库扩展性的追求了,这时候肯定有人在想:“这个有问题,我们就解决它啊”。这类技术就是Oracle RAC啊、MySQL Cluster啊这类玩具,它们希望能够不改变用户行为来实现扩展性,可是做了好多年,发现玩不转。为了支撑更大的访问量和数据量,我们必然需要分布式数据库系统,然而分布式系统又必然会面对强一致性所带来的延迟提高的问题,因为网络通信本身比单机内通信代价高很多,这种通信的代价就会直接增加系统单次提交的延迟,延迟提高会导致数据库锁持有时间变长,使得高冲突条件下分布式事务的性能不升反降(具体可了解下Amdahl定律),甚至性能距离单机数据库有明显差距。
说了这么多我们可以发现问题的关键并不是分布式事务做不出来,而是做出来了却因为性能太差而没有什么卵用。数据库领域的高手们努力了40年,但至今仍然没有人能够很好地解决这个问题,Google Spanner的开发负责人就经常在他的Blog上谈论延迟的问题,相信也是饱受这个问题的困扰。于是乎有一群人认为,既然强一致性不怎么靠谱,那彻底绕开这个问题是不是更好的选择?他们发现确实有那么一些场景是不需要强一致事务的,甚至连SQL都可以不要。最典型的就是日志流水的记录与分析这类场景。去掉了事务和SQL,接口简单了,性能就更容易得到提升,扩展性也更容易实现,这就是NoSQL系统的起源。
他们喊出了非常响亮的口号:No SQL! No SQL标志着他们时代的到来。
2005:Not only SQL . 不仅仅是SQL
经过5年的忽悠,有很多人愿意相信NoSQL似乎确有其事。于是有一批先行者就开始探索各种玩法:
http://www.lampchina.net/mod-news_do-show_id-8272.html
Digg采用Cassandra遭遇失败,工程副总裁离职:

(图12)
点个蜡。

玩着玩着,大家发现还是不靠谱。这不行啊,这东西不就是让我们每个业务都把关系数据库从新实现一把么?让我们退回到层次模型上去啊。对于人类这种懒惰而笨拙的动物,开历史的倒车明显是不受待见的。于是,有一批人站出来了,说No什么SQL,还是得有数据库。但NoSQL开发者们已经忽悠了那么多投资人的钱,总得有个交代啊,既然没办法颠覆,咱们就共存吧,什么NoSQL和SQL,大家一家人,各自发展就好了。这就是Not only SQL的来源。
NoSQL有哪些明确的场景呢?请注意前方高能。
比如HDFS比较火,于是就有人发现:“哎? 我们如果学Google ,也弄个分布式KV是不是也能火?” 呵呵,我想这就是某个base最大的价值。不过在这个平缓期还是能看到一些创新性的想法的,他们帮助数据库领域往前走了不大的一步。MongoDB 是个不错的思路(我个人觉得),json替代了臃肿的XML成为了一个小的标准,而在这个上面做很多索引,也是很聪明的做法,借鉴了数据库的核心思路,这也算是共存。其他的NoSQL也在往SQL上面努力,比如Cassandra的CQL 、HBase的各类SQL引擎,其实都是对关系数据模型的一种妥协。毕竟,NoSQL还没有好到能够颠覆整个生态。
2013:No,SQL!
不,我们还是要关系数据库,这就是现在我们的感觉咯。经过了10年的折腾,我们还是发现关系模型目前来说是最方便表达数据存取的语言,比其他都要方便的多,所以还是妥协吧。于是所有的NoSQL都在想办法尝试支持关系数据库。然而回到初始,我们不就是因为关系数据库不能满足用户要求,所以才要去做NoSQL的么。难道NoSQL 弄个关系代数引擎,就能做出魔法么?其实,也不行,该有的限制一个都没少,最终大家殊途同归,还是回到了如何能够让关系数据库更具有扩展性,性能更好这条路上来,条条大路通罗马嘛,和气生财。这就是NewSQL的来源。
DRDS 也是NewSQL的一员,其实说实话,我挺有感触的。作为这么多年来一直坚守在分布式数据库这个领域的人来说,能够坚持下来真的不容易,在外面有太多的诱惑,最火的时候,连DBA都去学了各种NoSQL的运维技术。然而,我们能够坚守,其实就是因为我们懂得历史也看得见现在。我们深刻地知道,科学就是承认自己并非无所不能,然后不断地往那无所不能的地方努力的一种精神。一直以来,我们都尽可能地协助用户保留关系数据库的方便性,然后想办法告知用户哪些地方目前还缺少技术突破,应该使用哪些工具来替代,所以也算是积累了非常多的经验和工具。
同时我们也在努力追求数据库领域的那个圣杯:更快的存取数据,可以按需扩缩以承载更大的访问量和更大的数据量,开发容易,硬件成本低。这是大家梦寐以求在追求的东西。也是我们在追求的。虽不能至,吾心向往之。
阿里的技术选择
最后,来聊聊阿里的技术选择。其实,所有大公司似乎都在释放各种信号,xxx在用什么系统了,xxx在用什么系统了。阿里可能不大一样,从内部来说,他也是个生态系统,用户选择什么实际上主要都是由用户自己决定的,所以阿里能够出现任何一种选择,只要能解决问题即可。TDDL DRDS这套体系,只能说是目前用的最广的一套,原因也很简单,改变行为习惯少。
双11 对DRDS这套体系来说其实没什么压力,我前几年的双十一虽然都在核心作战室,不过我一般的做法都是到了那里:“您辛苦了,您也是,大家辛苦了”,然后吃吃吃。因为确实没什么好担心的啊,没有不平稳的理由,DRDS的能力更多地体现在双11开始和双11结束,我们需要在那之前机器扩容,以及那之后要机器缩容,这些才是DRDS的核心能力。上上次我确实是很紧张,因为新接了一个消息系统。哎!这种用来消峰填谷的系统才是压力山大,其余的时候基本上就没啥了,更多地跟大家一样,也都是普通的功能开发而已。
好了,我的故事讲完了,谢谢大家收听。
Q&A
Q1:ADS是什么?它和DRDS的关系是?
沈询:ADS主打adhoc查询,目前不支持事务。DRDS则支持事务,这两个系统是互补的,一个针对离线,一个针对在线。
Q2:请问阿里的DRDS如何实现Join SQL语句来执行多表关联查询的?如何兼容单机存储的SQL?需要注意那些坑?
沈询:方案很多,其实如果大家
对Join有了解,也就那么几种,hash/index nest loop / sort merge ,没什么魔法。
http://coding-geek.com/how-databases-work/ ,这个不错,我比较推荐。
Q3:请问schema less/free你怎么看?
沈询:这俩似乎没见过拼一起哈,我分开。 但本质是同一个东西,我个人觉得有市场。不过能有多大,不知道。
技术债也一定是要还的。我清楚地记得当年我维护的一个CMS系统,所有数据都是map。结果最后有一些诡异的数据不知道什么时候被塞到里面。然后最后也没人知道是在哪里塞的。debug都很难找到。所以一般来说,结合会更好一些。 目前pg/mysql都开始支持json了。 这东西其实只是工作量问题。没什么技术上的难度。
Q4:最近很多声音说不要再用MongoDB,你怎么看?
沈询:这个就纯属个人意见了啊。我个人不喜欢MongoDB那帮人的嘴脸。MongoDB核心贡献者:不是MongoDB不行,而是你不懂!
http://www.cnblogs.com/shanyou/archive/2012/11/17/2774344.html
然而,为什么会这样,还不是某些人为了骗分,默认配置特别激进么。而开发者不会告诉你,如果改成安全配置,他们的性能没比SQL强哪里去。
一个存储,最少10年才能稳定。 前些天刚碰到一个游戏客户说某NoSQL数据文件损坏无法恢复,问我们有没有办法,我说,下次选择谨慎点,性能不是唯一,这次请节哀。
Q5:海量,低延时(豪秒级),高并发(十万以上),目前关系型数据库是否有并存的方案?
沈询:10w并发不算是很高。DRDS是你最好的选择 :)
Q6:非结构化数据,如文本,树图等,这些SQL无法处理的,是否使用NoSQL更合理?
沈询:非结构化数据也是一个重要的门类,一直都存在,以后也会存在,但NoSQL为了宣传,把所有的东西都拉到自己阵营,这其实与其初衷已经违背。
Twitter的图数据库其实也是依托MySQL做的。你给我钱给我人,给我时间,我能用汇编写任何东西。
Q7:能说一下DRDS和RDS的关系么?
沈询:一个偏重分布式,一个偏重单机
Q8:SQL模型已经那么多年了,数据库领域有其他可能更好使的语言模型方向么?
沈询:目前还没见到更好地抽象,所谓好使就是你发现他占据了更多江山。在历史上有很多次尝试,比如对象数据库等,但实际上也都是针对SQL问题的一些改善。不过目前还没有特别成功的。
Q9:分享中有提到,分布式数据库网路延迟方面的瓶颈一直是一个需要突破的点,你是否认为新型网路架构,或是网路设备的出现能够逐步弥补这一点呢?
沈询:能够做到一些改善,但完美解决不大可能。目前系统需要更大的理论突破。
Q10:能不能简单用一句来概括DRDS的强大?
沈询:SQL数据库里扩展性最好的,NoSQL数据库里最方便的。
Q11:WebScaleSQL与DRDS是什么关系?
沈询:没关系,当成竞争对手似乎也可以。
Q12:DRDS和NewSQL有何异同?
沈询:DRDS属于NewSQL。 |





