| NoSQL֮��MongoDB��ѧϰ��һ������װ˵��
���:
MongoDB ���Ϻ������Ѿ��㹻���ˣ��Ͳ���˵���ˣ��������������������˵��Ubuntu�µİ�װ��
��װ��
һ��apt��װ��Mongodb�İ�װ���Ѿ����ɵ���Ubuntu��apt���棬����ֱ��apt��װ��
1�� �Ȳ鿴�����Ƿ��а�װ��
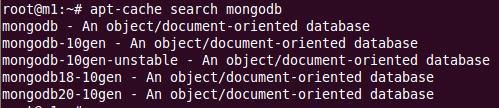
2�� Ҫ��û�еĻ���Ҫ�Լ�����Դ��10.04����������Ҫ��װ���µİ汾��
û��aptԴ������һ��
�� ��/etc/apt/sources.list �����ӣ�
deb http://downloads-distro.mongodb.org/repo/ubuntu-upstart dist 10gen |
�� ��ִ�У�
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv 7F0CEB10 |
�� ����ٸ���������Դ��
�� ��װ:
sudo apt-get install mongodb |
�� ��������������ϵͳ:���빫��GPG��Կ��:
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv 7F0CEB10 |
�� ����һ��10gen.list�ļ���
echo 'deb http://downloads-distro.mongodb.org/repo/ubuntu-upstart dist 10gen' | sudo tee /etc/apt/sources.list.d/10gen.list |
�� ���¼��أ�
�� ��װ��
sudo apt-get install mongodb-10gen |
sudo apt-get install mongodb-10gen
apt-get install mongodb-10gen=2.4.3 |
3�� Ҫ���а��Ļ���12.04������ֱ�Ӱ�װ����2���Ͳ���Ҫ�����ˡ�

4�� ����
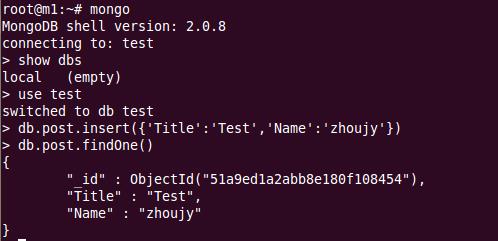
����ubuntu �����ư�װʹ��
1�� ���أ��� http://www.mongodb.org/downloads �����ʺ��Լ��İ汾��Mongodb
�����ҵ�ϵͳ��32λ��
�鿴�汾��lsb_release -a
�鿴λ����file /sbin/init
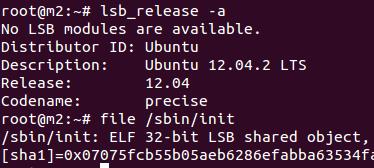
32λ�����أ�
wget http://fastdl.mongodb.org/linux/mongodb-linux-i686-2.4.3.tgz |
64λ�����أ�
wget http://fastdl.mongodb.org/linux/mongodb-linux-x86_64-2.4.3.tgz |

2�� ��ѹ:tar zxvf package

����Щ�ļ����������ӵ�/usr/bin Ŀ¼�£�
ln -s /home/zhoujy/mongodb/mongodb-linux-i686-2.4.3/bin/mongo /usr/bin/mongo
|
3�� �����ļ�Ŀ¼�Լ��ʺ�
useradd mongodb
mkdir -p /var/lib/mongodb
mkdir -p /var/log/mongodb
chown -R mongodb:mongodb /var/lib/mongodb/
chown -R mongodb:mongodb /var/log/mongodb/ |

4�� ����mongodb��һ��:ָ������
mongod --dbpath /var/lib/mongodb/ --logpath=/var/log/mongodb/mongodb.log & |

5�� ��Ϊ�����ư���װ��mongodb��û�������ļ��ģ���Ҫ�Լ��ֶ���һ������д���ļ�֮��ŵ�/etc/mongodb.conf

6�� ���� mongodb��������ָ�������ļ�(-f)
mongod -f /etc/mongodb.conf |

7�� ����

NoSQL֮��MongoDB��ѧϰ��������DML�Ͳ�ѯ����˵��ժҪ��
����MongoDB�ķ�����ϵ�����ݿ���ܴ����ڶ����ǽ���˵�������ڻ������ơ�
##��ͷ��ʾMySQL
** ��ͷ��ʾMongoDB
������
Mongodb���ĵ����ݿ⣬�ó���ǽṹ�����ݣ�����Ҫ���ȹ涨���ĵ��������Ķ��塣
##create table Test(����)
**db.createCollection('Test')
##drop table Test
**db.Test.drop()
##drop database test
**db.dropDatabase() |
���������ϣ�
����������
##rename table Test to Test_A;
**db.Test.renameCollection('Test_A');
##create table Test_A select * from Test;
** db.Test.copyTo('Test_A') #����û�и��Ƶ�yyy����
**�����ȱ��ݣ��ٻ�ԭ�� Test --> ddd
mongodump --host=127.0.0.1 --port=27017 -ubackup
-p --db=abc --collection=Test -o backup/
mongorestore --db=abc --collection=Test_A backup/abc/stu.bson
|
���������ݿ⣺
** db.copyDatabase('test','test_bak') #��һ�����ƣ���Ҫ��ԭ��ɾ����
{ "ok" : 1 }
Զ�̸������ݿ⣺
db.copyDatabase(fromdb, todb, fromhost, username,
password) |
���룺
MongoDB��������ʱ�����Ȱ�����ת����BSON��ʽ�������ݿ⣬
�ٽ���BSON�������Ƿ������_id�����ĵ�������4M��С�����������ݿ�
##insert into Test(name) values(����)
**db.Test.insert({"name":"zhoujy"})
--����Ҫ���ȹ涨��name�У�����
������ֵ��
##insert into Test() values(),(),()����
**db.Test.insert([{"a":1,"b":2},{"a":2,"b":3},{"a":3,"b":4}]) |
ɾ����
ɾ��ָ����¼
##delete from Test where name ='zhoujy'
**db.Test.remove({"name":"zhoujy"})
ɾ�����м�¼
##delete from Test
**db.Test.remove() |
���£�
4����������һ���������������ڶ�����������������������upsert���о��£�û����(add
column)�������ĸ�Ϊ�Ƿ���¶��У�Ĭ���ǵ�һ�С�
$inc ����int���͵�key���У��Ӽ�������Ҫ��ָ����Ҫ���µ�key�����ڣ����������key���У���
##update Test set pv=pv+1 where name ='a'��alter table Test add column,
**db.Test.update({"name":"a"},{"$inc":{"pv":1}})
--ֻ���µ�һ�����ֵļ�¼��+1
**db.Test.update({"name":"a"},{"$inc":{"pv":1}},false,true)
--�������з��������ļ�¼��+1;����4��������true��
**db.Test.update({"name":"a"},{"$inc":{"pv":-1}},false,true)
--�������з��������ļ�¼��-1
**db.Test.update({"name":"a"},{"$inc":{"pv":-1}},true,true)
--Ҫ�Ǹ��������Ҳ�����¼��Ĭ���Dz�ִ�У�Ҫ�ǵ�3��������true��
�������һ����¼����������key�ͱ����µ�key��
$set ���ڸ���ָ��key���У���Ҫ��ָ����Ҫ���µ�key�����ڣ����������key���У���
##update Test set name ='A' where pv_bak = -1��alter
table Test add column,
**db.Test.update({"pv_bak":-1},{"$set":{"name":"A"}})
--ֻ���µ�һ�����ֵļ�¼
**db.Test.update({"pv_bak":-1},{"$set":{"name":"A"}},false,true)
--�������з��������ļ�¼����4��������true��
**db.Test.update({"pv_bak":-11},{"$set":{"Sname":"BB"}},true,true)
--Ҫ�Ǹ��������Ҳ�����¼��Ĭ���Dz�ִ�У�Ҫ�ǵ�3��������true���������һ����¼����������key�ͱ����µ�key��
��λ����������Ƕ�ĵ����õ㣨.������ʾ��Ƕ�ĵ��ڵ�key���磺
**db.pv.update({"hit.a":1111},{"$set":{"hit.a":1}})
$unset ����ɾ��ָ��key���У�
##alter table Test drop column ����
**db.Test.update({"Sname":"BB"},{"$unset":{"pv_bak":1}})
--ɾ����һ�����ֵļ�¼��key(��)<pv_bak>
**db.Test.update({"Sname":"BB"},{"$unset":{"pv_bak":1}},true,true)
--ɾ�����������ļ�¼��key(��)<pv_bak>����3������û������
**db.Test.update({},{"$unset":{"name":1}},false,true)
--ɾ���ĵ�������������name��key���У�
$rename ����������key����
##alter table Test change column ����
**db.Test.update({"name":"A"},{"$rename":{"nl":"age"}})
--��������һ�����ֵļ�¼��key(��)< nl����>age >
**db.Test.update({"name":"A"},{"$rename":{"nl":"age"}},true,true)
--���������������ļ�¼��key(��)< nl����>age >
**db.Test.update({},{"$rename":{"name":"Sname"}},true,true)
--���������еļ�¼��key(��)< name����>Sname >
�������������$push,$ne,$addToSet,$each,$pop,$pull
$push ��ָ��key���У�����������������ݣ�Ҫ��ָ����key�����ڣ����������key���У���
**db.Test.update({"Sname":"A"},{"$push":{"cc":1}})
--�Է��������ĵ�һ���������ݵ�����cc������һ��ֵ1(����key)������������cc��������ֵ1(������key)
**db.Test.update({"Sname":"A"},{"$push":{"cc":1}},false,true)
--�Է������������ݵ�����cc������һ��ֵ1(����key)������������cc��������ֵ1(������key)
**db.Test.update({},{"$push":{"dd":"a"}},false,true)
--�������ĵ�(��)������cc������һ��ֵ1(����key)������������cc��������ֵ1(������key)
$ne �ж��Ƿ���ڣ�������ظ������������һ����һ����ֵҲ�ܲ��룺
**db.Test.update({"ee":{"$ne":"A"}},{"$push":{"ee":"A"}})
--��һ�������Ƿ��������ee��A��Ԫ�أ�ֵ�����������ӣ�push��A��ee������������key���У�
**db.Test.update({"ee":{"$ne":"B"}},{"$push":{"ee":"A"}})
--��һ�������Ƿ��������ee��B��Ԫ�أ�ֵ�����������ӣ�push��
A��ee������������key���У���������һ������eeԪ����2��AԪ�أ������ظ�Ԫ��
**db.Test.update({"ee":{"$ne":"B"}},{"$push":{"ee":"A"}},true,true)
--���������ݣ���4����������3��������Ч�����Ƿ��������ee��A��Ԫ�أ�
ֵ�����������ӣ�push��A��ee������������key���У�
$addToSet �ж��Ƿ���ڣ���������ظ������
**db.Test.update({"name":"a"},{"$addToSet":{"email":"asd"}})
**db.Test.update({"age":"13"},{"$addToSet":{"email":"asd"}})
--����2��������Ӧͬһ����¼������ͬ����ֵд������ֻ�ܼ�¼һ�Σ������ظ�
**db.Test.update({"app":"13"},{"$addToSet":{"email":"asd"}},true)
--���������������������Ҳ����ļ�¼�õ�����һ��key���У�
**db.Test.update({"name":"a"},{"$addToSet":{"email":"asd"}},true,true)
--���ĸ���������ƥ�䵽�ļ�¼���õ�����
**db.Test.update({},{"$addToSet":{"email":"asd"}},true,true)
--�������м�¼
$addToSet + $each Ϊ�������Ӷ��Ԫ�أ�
**db.Test.update({"name":"a"},{"$addToSet":{"xyz":{"$each":["a","b","c"]}}})
--���¸��������ĵ�һ������
**db.Test.update({},{"$addToSet":{"add":{"$each":["a","b","c"]}}},true,true)
--�������м�¼
$pop��$pull ɾ�������е�Ԫ�أ�
λ�ã�
**db.Test.update({"name":"a"},{"$pop":{"cc":1}})
--��һ������ɾ������cc�����һ��Ԫ��
**db.Test.update({"name":"a"},{"$pop":{"cc":-1}})
--��һ������ɾ������cc�ĵ�һ��Ԫ��
**db.Test.update({"name":"a"},{"$pop":{"cc":-1}},false,true)
--����������ȫ������ɾ������cc�ĵ�һ��Ԫ��
**db.Test.update({},{"$pop":{"cc":-1}},false,true)
--ȫ������ɾ������cc�ĵ�һ��Ԫ��
ָ����
**db.Test.update({"name":"b"},{"$pull":{"cc":4}})
--��һ������ɾ������cc��ָ����Ԫ��4
**db.Test.update({"name":"a"},{"$pull":{"cc":4}},false,true)
--����������ȫ������ɾ������cc��ָ��Ԫ��4
**db.Test.update({},{"$pull":{"cc":4}},false,true)
--ȫ������ɾ������cc��ָ��Ԫ��4
��� $
�õ㣨.��+ λ�ã����֣�����ʾ�����ڲ���key���磺
**db.Test.update({"age":14},{"$inc":{"ddd.0.a":10}})
--��������ddd�ĵ�һ��Ԫ�أ�0����a����ֵ����Ҫ֪��a�����У�������ĵڼ���Ԫ����
**db.Test.update({"ddd.a":1},{"$set":{"ddd.$.d":20}})
--��������������ddd��a=1����������ȥ�������ȳ��ֵķ���Ҫ��������d����
����Ҫ֪�������µ�key�ڵڼ���λ��
�����͵��IJ���Ч��������һ�� |
��ͨ��ѯ��
##select * from stu
**db.stu.find()
������ѯ��
##select * from stu where sno = 8
**db.stu.find({"sno":8})
**db.stu.find({"sno":{"$in":[8]}})
##select * from stu where sno = 1 and sname ='ABC'
**db.stu.find({"sno":1,"sname":"ABC"})
in��ѯ��
##select * from stu where sno in (1,3,5,8)
**db.stu.find({"sno":{"$in":[1,3,5,8]}})
not in ��ѯ:
##select * from stu where sno not in (1,3,5,8)
**db.stu.find({"sno":{"$nin":[1,3,5,8]}})
or ��ѯ��
##select * from stu where sno = 5 or sname ='zhoujy'
**db.stu.find({"$or":[{"sno":5},{"sname":"zhoujy"}]})
##select * from stu where sno in (1,2,3) or sname
='zhoujy'
**db.stu.find({"$or":[{"sno":{"$in":[1,2,3]}},{"sname":"zhoujy"}]})
##select * from stu where sno = 4 and sname ='zhoujy'
or sno = 1
**db.stu.find({"$or":[{"sno":4,"sname":"zhoujy"},{"sno":1}]})
##select sno,sname from stu where sno =2
**db.stu.find({"sno":2},{"sno":1,"sname":1,"_id":0})
##select count(*) from stu where sno=1
**db.stu.find({"sno":1}).count()
����������ѯ��
$lt(<);$lte(<=);$gt(>);$gte(>=);$ne(<>)
##select * from stu where sno > 1 and sno
<=5
**db.stu.find({"sno":{"$gt":1,"$lte":5}})
##select * from stu where sno > 1 and sno
<=5 and sno <> 3
**db.stu.find({"sno":{"$gt":1,"$lte":5,"$ne":3}})
##select * from stu where sno > 1 and sno
<=5 and sname <> 'zhoujy'
**db.stu.find({"sno":{"$gt":1,"$lte":5},"sname":{"$ne":"zhoujy"}})
ȡ�ࣺ
##select sno,sname from stu where sno%5 = 1
**db.stu.find({"sno":{"$mod":[5,1]}},{"sno":1,"sname":1,"_id":0})
##select sno,sname from stu where sno%5 != 1
**db.stu.find({"sno":{"$not":{"$mod":[5,1]}}},{"sname":1,"sno":1,"_id":0})
ƥ���ѯ:
##select sno,sname from stu where sname like '%j%'
**db.stu.find({"sname":/j/},{"sno":1,"sname":1,"_id":0})
--���ִ�Сд
**db.stu.find({"sname":/j/i},{"sno":1,"sname":1,"_id":0})
--�����ִ�Сд
##select sno,sname from stu where sname like
'j%'
**db.stu.find({"sname":/^j/},{"sno":1,"sname":1,"_id":0})
--���ִ�Сд
**db.stu.find({"sname":/^j/i},{"sno":1,"sname":1,"_id":0})
--�����ִ�Сд
##select sno,sname from stu where sname like
'%j'
**db.stu.find({"sname":/j$/},{"sno":1,"sname":1,"_id":0})
--���ִ�Сд
**db.stu.find({"sname":/j$/i},{"sno":1,"sname":1,"_id":0})
--�����ִ�Сд
���Ʋ�ѯ��
##select sno,sname from stu limit 3
**db.stu.find({},{"sno":1,"sname":1,"_id":0}).limit(3)
##select sno,sname from stu where sno > 3
limit 3
**db.stu.find({"sno":{"$gt":3}},{"sno":1,"sname":1,"_id":0}).limit(3)
##select sno,sname from stu where sno=102 limit
3
**db.stu.find({"sno":102},{"sno":1,"sname":1,"_id":0}).limit(3)
�����ѯ��
##select sno,sname from stu order by sno
**db.stu.find({},{"sno":1,"sname":1,"_id":0}).sort({"sno":1})
##select sno,sname from stu order by sno,sname
**db.stu.find({},{"sno":1,"sname":1,"_id":0}).sort({"sno":1,"sname":1})
##select sno,sname from stu order by sno,sname
desc
**db.stu.find({},{"sno":1,"sname":1,"_id":0}).sort({"sno":1,"sname":-1})
##select sno,sname from stu order by sno desc
**db.stu.find({},{"sno":1,"sname":1,"_id":0}).sort({"sno":-1})
##select sno,sname from stu where sno <=3
order by sno desc
**db.stu.find({"sno":{"$lte":3}},{"sno":1,"sname":1,"_id":0}).sort({"sno":-1})
##select sno,sname from stu where sno <=10
order by sno desc limit 4
**db.stu.find({"sno":{"$lte":10}},{"sno":1,"sname":1,"_id":0}).sort({"sno":-1}).limit(4)
--limit �� sort û���Ⱥ�˳��ǰ�ź���һ��
�ض�λ��ѯ��
##select sno,sname from stu limit 4,�����
**db.stu.find({},{"sno":1,"sname":1,"_id":0}).skip(4)
--�ӵ�5�п�ʼ�����
##select sno,sname from stu where sno <=10
limit 4,3
**db.stu.find({"sno":{"$lte":10}},{"sno":1,"sname":1,"_id":0}).skip(4).limit(3)
--�ӵ�5�п�ʼ��ȡ3��
##select sno,sname from stu where sno <=10
order by sno desc limit 4,3
**db.stu.find({"sno":{"$lte":10}},{"sno":1,"sname":1,
"_id":0}).limit(3).sort({"sno":-1}).skip(4)
--sort,skip,limit ��3������û��˳�����ﶼһ��
ȥ�ز�ѯ��
##select distinct a from Test
**db.Test.distinct("a")
##select distinct a from Test where a>2
**db.Test.distinct("a",{"a":{"$gt":1}})
���ѡȡ��
##select sno,sname from stu order by rand() limit
10
**ͨ��skip(random)��ȡ�������
> total = db.stu.count()
21
> total
21
> total = db.stu.count()
21
> random = Math.floor(Math.random()*total)
16
> random = Math.floor(Math.random()*total)
1
> random = Math.floor(Math.random()*total)
7
db.stu.find({"sno":{"$lte":10}},{"sno":1,"sname":1,"_id":0}).limit(10).sort({"sno":-1}).skip(random)
|
Mongodb ����
nullֵ��ѯ��
null���г�Z�����У���NULL�������г�������Z�����У��ļ�¼
db.stu.find({"Z":null})
�г�����Z�����У�������Z�����У���NULL�ļ�¼
db.stu.find({"Z":{"$in":[null],"$exists":true}})
�����ѯ��
����һ��Ԫ��
db.food.find({"fruit":"a"})
<==> db.food.find({"fruit":{"$all":["a"]}})
--����fruit���������a�ļ�¼
���Ԫ�ز��ң�$all
db.food.find({"fruit":{"$all":["a","b"]}})
--����fruit���������a,b�ļ�¼,˳��Ӱ��
ָ���������λ��
db.food.find({"fruit.2":"c"})
--����fruit�������3��λ����c�ļ�¼
ָ������ij���
db.food.find({"fruit":{"$size":5}})
--����fruit���鳤����5�ļ�¼
ȡ�����ǰ/��3���Ӽ�
db.food.find({"fruit":"X"},{"fruit":{"$slice":3}})
--����fruit���������X��¼�������������ǰ3λ
db.food.find({"fruit":"X"},{"fruit":{"$slice":-3}})
--����fruit���������X��¼������������ĺ�3λ
db.food.find({"fruit":"X"},{"fruit":{"$slice":[3,2]}})
--����fruit���������X��¼�������ش�����λ��3��ʼ�ĺ�2λ
db.food.find({},{"fruit":{"$slice":3}})
--����fruit���飬�����ش������ǰ3λ
db.food.find({"fruit":{"$exists":true}},{"fruit":{"$slice":-1}})
--����fruit������ڣ���������������һλ
�ĵ���ѯ��
ָ����Ƕ�ĵ���ļ���������
db.post.find({"xx.age":12}) --������Ƕ�ĵ�xx���ҳ�age��12�ļ�¼
db.post.find({"xx.age":12,"xx.add":"hz","xx.sex":1})
--������Ƕ�ĵ�xx���ҳ�age��12��add��hz��sex��1�ļ�¼
db.post.find({"xx.add":"hz","xx.age":{"$gt":12}})
--������Ƕ�ĵ�xx���ҳ�add��hz��age > 12 �ļ�¼,$elemMatch
�г�ȫ�����ݣ���������ӣ���˳��һ������鲻����
db.post.find({"xx":{"sex":1,"add":"hz","age":12}})
--������Ƕ�ĵ�xx����ȫƥ��
$where ��ѯ:
��ͨ�У�
##ע���ʽ�����ҳ�2������ֵ��ȵ��ĵ�:{"D" : 4, "E"
: 4, "F" : 5 }��D��E���
db.foo.find({"$where":function(){ ##�̶���ʽ
for (var numA in this){ ##��ֵ���ĵ���key��һ��������this
��ʾ���ĵ�
for (var numB in this){ ##��ֵ���ĵ���key��һ������
if (numA != numB && this[numA] == this[numB])
##�жϣ�key����ȵ����ǵ�ֵ��ȣ���D��D���ܱ�
return true; ##����
}
}
}
})
##ע���ʽ,���ҳ�����2��ֵ����5���ĵ�
db.foo.find({"$where":function(){ ##�̶���ʽ
var cnt = 0; ##��������
for (var num in this){ ##��ֵ���ĵ���key��һ��������this ��ʾ���ĵ�
if (this[num] >=5) ##�жϣ����ֵ����5����...
cnt++;
}
return cnt >=2; ##��cnt>=2������
}
})
��Ƕ�ĵ���
##ע���ʽ�����ҳ�����2��ֵ����90���ĵ�
db.stu.find({"$where":function(){
var cnt = 0;
for (var num in this.course){
if( this.course[num] > 90)
cnt++;
}
return cnt >=2;
}
})
##ע���ʽ�����ҳ�2������ֵ��ȵ��ĵ�
db.stu.find({"$where":function(){
for (var t1 in this.course){
for (var t2 in this.course){
if(t1 != t2 && this.course[t1]==this.course[t2])
return true;
}
}
}
})
�����Ѿ����µ��ĵ�:getLastError��findAndModify
> db.runCommand({getLastError:1}) --����
{
"updatedExisting" : true,
"n" : 1, --�ĵ�����
"connectionId" : 1,
"err" : null,
"ok" : 1
}
##ֻ���ر��Ķ��ļ�¼
> db.Test.findAndModify({
... "query":{"name":"b"},
--����
... "update":{"name":"BB"},
--����
... "new":true --����������
... })
> db.Test.findAndModify({
... "query":{"name":"b"},
... "update":{"name":"BB"},
... "new":false --������ǰ������
... })
|
�ۺϺ���������{count,sum,max,min,avg}����ͨ����group��mapreduce��aggregate��ɡ����ǵľ���ʹ�÷���Ϊ������˵������
group��
db.collection.group(
key,
reduce,
initial,
keyf,
cond,
finalize)
mapReduce:
db.collection.mapReduce(
<mapfunction>,
<reducefunction>,
{
out: <collection>,
query: <document>,
sort: <document>,
limit: <number>,
finalize: <function>,
scope: <document>,
jsMode: <boolean>,
verbose: <boolean>
}
)
aggregate:
ʹ�÷�������http://blog.nosqlfan.com/html/3648.html
{ aggregate: "[collection]", pipeline:
[pipeline] }
Pipeline ����IJ�����:
$match �C query predicate as a filter.
$project �C use a sample document todetermine the
shape of the result.
$unwind �C hands out array elements oneat a time.
$group �C aggregates items into bucketsdefined
by a key.
$sort �C sort document.
$limit �C allow the specified number ofdocuments
to pass
$skip �C skip over the specified numberof documents.
|
�������ݣ�
##select dept,count(*) from test_gh group by dept
**db.test_gh.group({
'key':{"dept":1}, /* group by dept */
'reduce':function(obj,prev){
prev.ccount ++ /* count(*) */
},
'initial':{"ccount":0} /*��ʼ������*/
})
[ { "dept" : 111, "ccount"
: 4 }, { "dept" : 222, "ccount"
: 2 } ]
##select dept,sum(age) from test_gh group by
dept
**db.test_gh.group({
"key":{"dept":1},
"reduce":function(obj,prev){
prev.ssum += obj.age /*obj��ʾ���ϣ���������ĵ����У�*/
},
"initial":{"ssum":0}
})
[ { "dept" : 111, "ssum" :
54 }, { "dept" : 222, "ssum"
: 27 } ]
##select dept,max(age) from test_gh group by
dept;
**db.test_gh.group({
"key":{"dept":1},
"reduce":function(obj,prev){
if (obj.age > prev.age){ /*��������ֵ*/
prev.age = obj.age
}
},
"initial":{"age":0} /*��ʼ��һ������*/
})
[ { "dept" : 111, "age" :
16 }, { "dept" : 222, "age"
: 14 } ]
##select dept,min(age) from test_gh group by
dept
**db.test_gh.group({
"key":{"dept":1},
"reduce":function(obj,prev){
if(obj.age < prev.age){ /*�������Сֵ*/
prev.age=obj.age}
},
"initial":{"age":9999999}
/*��ʼ��һ������,����һ������������*/
})
[ { "dept" : 111, "age" :
11 }, { "dept" : 222, "age"
: 13 } ]
mapreduce����Ҳ����ʵ��,2.1֮�����һ���µľۺ��õĺ�����aggregate
ʹ��aggregate������˵����:http://my.oschina.net/GivingOnenessDestiny/blog/88006
��ƽ��
##select avg(age) from test_gh
**db.test_gh.aggregate({"$group":{_id:null,Avg:{"$avg":"$age"}}}).result[0].
Avg /*_id��һ����Ҫ��group��key��null��ʾû��group������Ķ���
���硱��*/
13.5
����ƽ��
##select avg(age) from test_gh group by dept
**db.test_gh.aggregate({"$group":{_id:"$dept",Avg:{"$avg":"$age"}}})
.result/*_id��һ����Ҫ��group��key��$dept��ʾû��group dept������Ķ���
���硱��*/
[ { "_id" : 222, "Avg" : 13.5
}, { "_id" : 111, "Avg" :
13.5 } ]
##select dept,avg(age) from test_gh where name
<'e' group by dept
$match �൱��һ��query����
**db.test_gh.aggregate({"$match":{"name":{"$lt":"e"}}},{"$group":{_id:"$dept",Avg:{"$avg":"$age"}}})
���ŵ�ƽ��age�����ܵ�ƽ��age
db.test_gh.aggregate([
{$group :{_id:"$dept",Avg:{"$avg":"$age"}}},
/*���ŵ�ƽ��*/
{$match :{Avg:{"$gt": /*�Ƚ�*/
db.test_gh.aggregate({
$group :{_id:null,totalAvg:{"$avg":"$age"}}}).result[0].totalAvg
/*�ܵ�ƽ��,һ��aggregate*/
}}}
]).result
[ { "_id" : 111, "Avg" : 13.8
} ]
aggregate ʵ�������ľۺϣ�
�����������
> db.test_gh.aggregate({$group:{_id:"$dept",Avg:{"$min":"$age"}}}).result
[ { "_id" : 222, "Avg" : 13
}, { "_id" : 111, "Avg" :
11 } ]
> db.test_gh.aggregate({$group:{_id:"$dept",Avg:{"$max":"$age"}}}).result
[ { "_id" : 222, "Avg" : 14
}, { "_id" : 111, "Avg" :
16 } ]
|
|





