|
�ڵڶ����Ϻ��������������ۻ��ϣ����� Intel�����ڵ����� Cloudera �Ĵ����ݹ���ʦ���ҷ���ʱ�´���������������ȵĻ��⡣
�����ף�Storm over Gearpump

Intel�����ݹ���ʦ������
�ݽ���ʼǰ��������ͨ�������Լ��Ĺ��������˶�streaming����Ȥ���������Ƽ��Լ��Ѽ���GitHub�ϵ�projects��ϣ���и�������Ȥ����һ������
Gearpump - Distributed Real-time Streaming Engine
Storm over Gearpump,����Gearpump���ṩһ��Storm�����ļ��ݲ㣬�û����Բ���һ�д��룬�������¶�������jar��,�Ϳ���Storm ���е�Gearpump�ϡ�Storm ��ҵ��ʹ����㷺�����������棬��Ҳ��¶���˲��پ����ԡ���Щ�������� Intel ���¿�Դ��������ϵͳ Gearpump �ж��õ������õĽ����Ϊ���ù�� Storm �û���ɱ������鵽 Gearpump ���������ԣ�Gearpump ʵ���˶� Storm �������ݣ����û������Ĵ��룬���±��룬�Ϳ���ֱ�ӽ������ư������� Gearpump �ϡ�
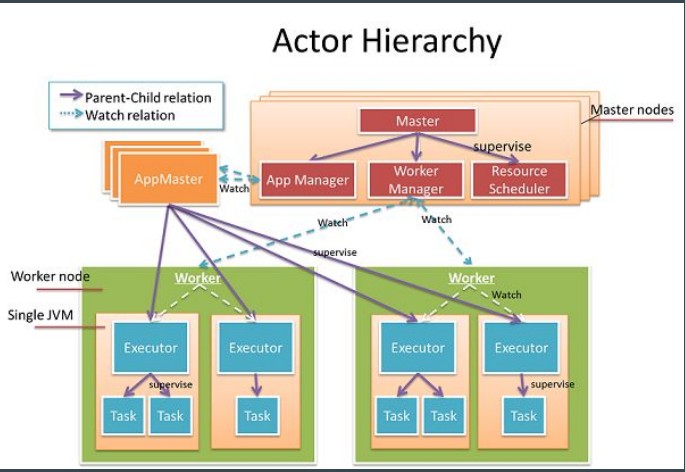
ͼ1����Akka/Actor ģ�͵�Gearpump�㼶ͼ
Gearpump ���� Akka �� Actor ģ������һ���߿ɿ������ܵ�ʵʱ������ϵͳ��ͼ1ΪGearpump��һ��cluster������һ��master�Ͷ��worker��ÿ��worker�����������Ⱥ�ϸ����ڵ����Դ���㼶���ĺô���ϵͳһ���ֳ�����ʱ����Ӱ�쵽�������֣���Gearpump�һ��master���Թ������worker,���Ӧ��֮���������ģ�ÿ��Ӧ�û���һ����Ӧ��appmaster��ÿ��appmaster��master������Դ�������worker�ϲ���executer,�൱��һ��JVM�������ִ�е�Ԫ��Task��һ��Task����һ��Actor��Gearpump��Dynamic DAG�ǿ��������ĵģ����Ҽ���죬��ʱ�͡�
Gearpump Updates
ͼ2����0.7.0�汾�IJ���
ΪʲôҪ��Gearpump��Storm�ϵļ������أ�
Storm����Ϊ�㷺��������ϵͳ����ʹ�ù�����Ҳ����������һЩ�����ԣ�Gearpump�����֮������Ϊ�˿˷�Storm�ľ����ԣ�ͬʱϣ������Storm�û��������۵����ܵ�Gearpump��Щ���������ԣ�����Ҫʵ����Gearpump���ܹ�����֧��Storm��Ӧ�á�
Storm over Gearpump �C Features
Gearpump����֧��0.9�汾��Storm��֧��multi-lang������Storm֧��һЩPython/Ruby/Node�Ľű���֧��Storm��DRPC�Ĺ��ܣ�Ҳ֧��KafkaSpout / KafkaBolt��Trident�ⲿ�ֵĹ���Ŀǰ���ڽ��е��С�
Similarities of Gearpump and Storm
����Gearpump��Storm���ǶԵ������ݵ�����Ϣ���д�����������ǵ��û��ӿڶ������Ƶģ�Storm��ͨ��Topolgy��Gearpump��ͨ��DAG������Task�ӿ�Ҳ�����Ƶġ�
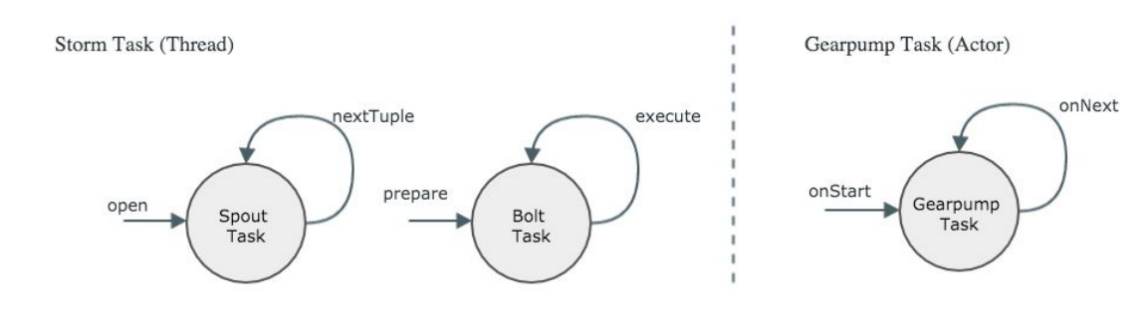
ͼ3 Strom��Gearpump��Task�ӿ�ͼ
ͼ3���ΪStorm��Task�ӿڣ�Storm���������ֽ�ɫ��Spout��Bolt������Spout���������ڻ���һ����ʼ��Open��ʽ��Ȼ��ͣ��ѭ������nextTouple�����η���Ϣ������Bolt��˵��ʼ����һ��prepare�Σ�ÿ�յ�һ����Ϣ�������execute���ұ���Gearpump��Task�ӿڣ�һ��ʼ����һ��onStart�Σ�ÿ�յ�һ����Ϣ�����onNext���������Ƿdz����Ƶģ�����Strom��Task��ռ�õ�һ���̣߳�Gearpump��Task��һ��Actor���DZ��̸߳�С��һ��ִ�е�Ԫ��
Storm over Gearpump �C Overview
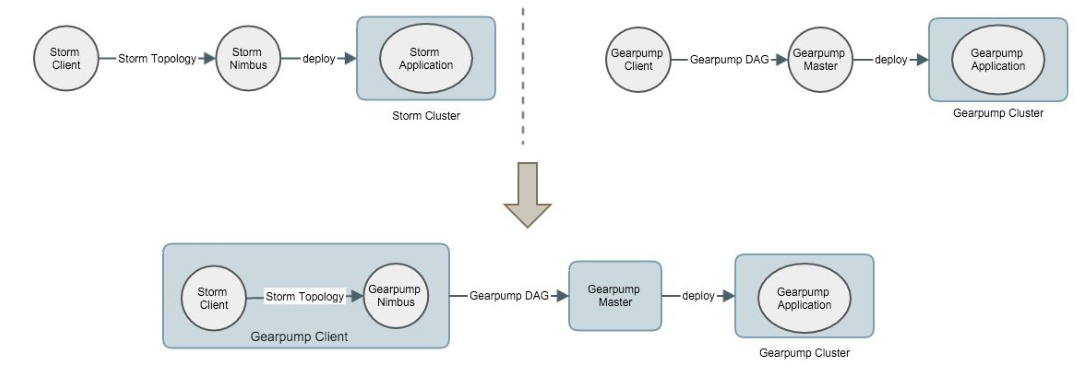
ͼ4ʵ�ָſ�ͼ
ͼ4�ϰ벿���������ߵ�ʵ�ֹ��̺����ơ�Storm Nimbus��Client��ͨ��Э����н����ģ����ǿ���������Gearpump��ʵ��Nimbus������Storm��Э�飬������������StormClient�ύ����ʱ�ڱ�����һ��Gearpump��Nimbus����Gearpump��Nimbus���Storm Topology�����Gearpump DAG���ٰ�Gearpump DAG�ύ��Gearpump master��������һ��StormӦ�þͿ���������Gearpump cluster�����ˡ�
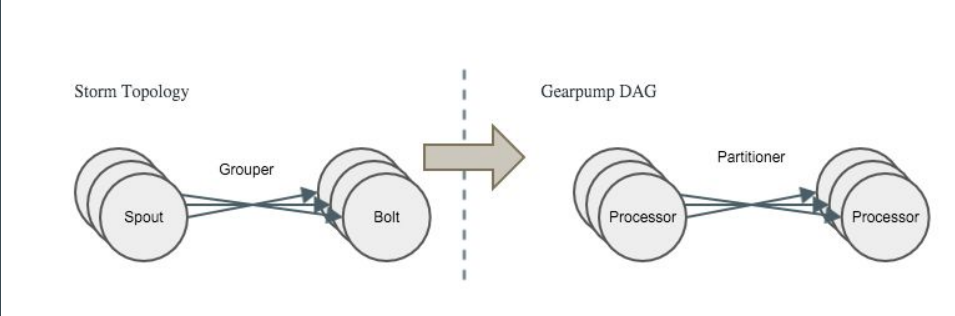
ͼ5 DAG�������
ͼ5�У�Spout�����Gearpump�����ڵ�Processor�����е�Grouperǣ����Gearpump���partitioner������ͼʵ����һһ��Ӧ�ġ�
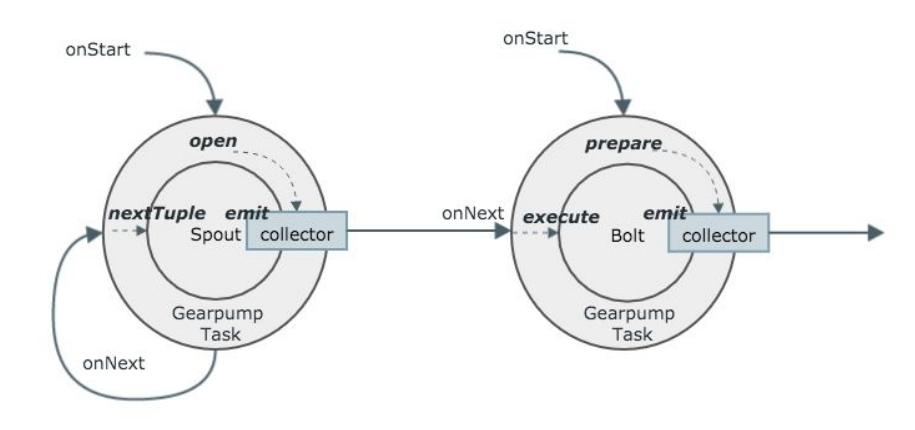
ͼ6 ����Taskִ��ͼ
ͼ6����Gearpump������Storm��Spout��Bolt�����ҰѶ��ߵ��������ڽ����һ�𡣴���Spout��ҪGearpump�Ĵ���㣬����ÿ�ε���onStartʱ�����Gearpump��collectorע�ᵽSpout�ͨ������ͨ�����Storm����Ϣ����Gearpump���档
Storm over Gearpump - Flow Control
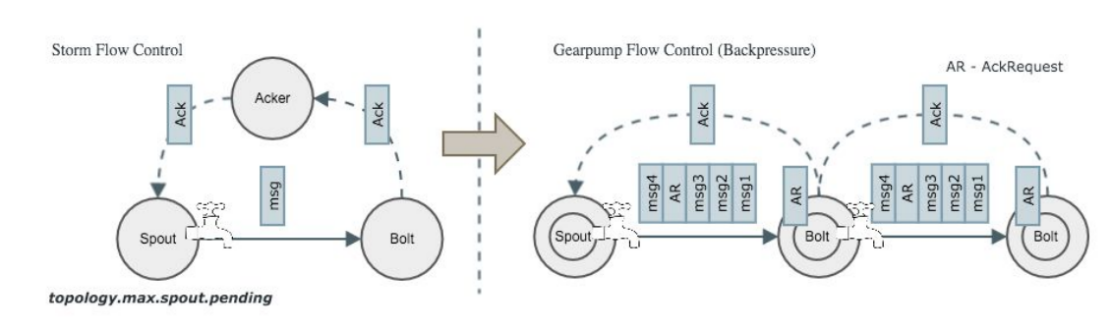
ͼ7 Strom��Gearpump��������
Storm��ͨ��Ackerʵ�������ƣ�����һ����������Ϣû�б�Ack��Storm��Spout�˾Ͳ��������η���Ϣ�ˣ���Gearpump���棬ÿ��һ������Ϣ��������Task��������Task��һ��AckRequest�������յ�AckRequest�������λ�һ��Ack����ʱ��һ��Task������ά����һ���������ĸ��ͨ������һ�ֻ��ƣ����ε�ѹ����һ���������δ�����ֱ������Spout��һ�㣬Spout��ֹͣ�����������η���Ϣ��
Storm over Gearpump - At Least Once
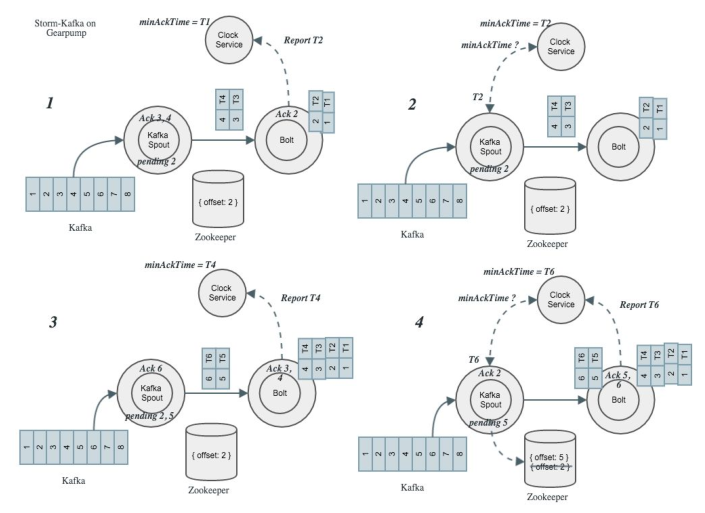
ͼ8 At least onceԭ��ͼ
Stormm���Kafka��Offset�浽Zookeeper�������������������´�Zookeeper���˽��Ϣ���������ˣ���Gearpump��Ҳ֧��Kafka��At least once�����⣬���Ǻ�Strom������һ����ͼ8�У�2�п�ʼ����Ϣʱ�Ǵ���pending��λ�ã�3��4����Ϣʱֱ��Ack������2��û��Ack����ʱStorm��Kafka��Offsetû�и��£���ʹ������ʱ��Ȼ������2��ʼ������Ϊ�˱���Storm��Spout���ۻ�������Ϣ��������Ϣ��Gearpump�϶������ϵͳ��ʱ��ӡ�ǣ������ε�Task�յ���Ϣ���㱨��Clock Service��Clock Service��ά��ȫ�ֵ���С��Ackʱ�䡣
����
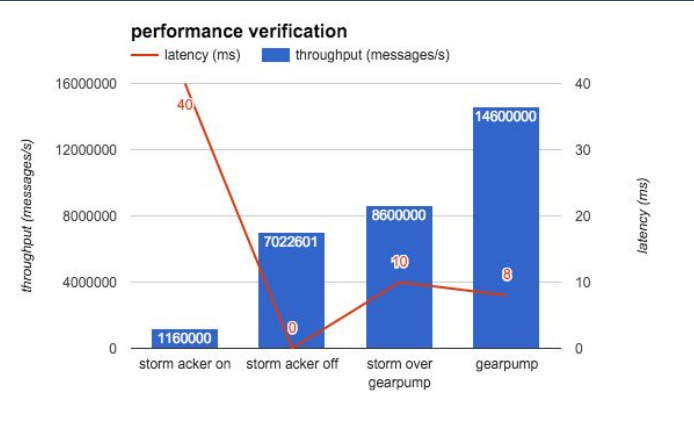
ͼ9����������ͼ
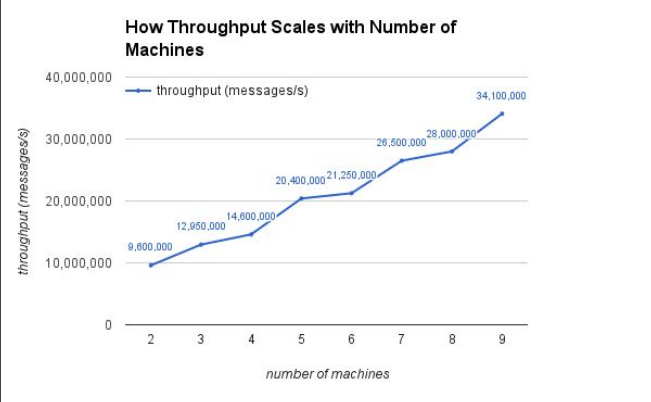
ʵ�������ļ��ݲ��������ô���أ��������ĸ��ڵ������˲��ԣ��õ��� storm-benchmark �е� SOL���������û���κ��û�����������Ե���ϵͳ��ܱ��������ܣ���48��Spouts��Bolts��16��workers��ͼ9�п��Կ���Gearpump���������á�
��һ������
�����ڽ�����ֱ���ύStorm Job������Storm 0.10��֧�֣�����At least once�Ը���Spouts��֧�֣�����Trident��֧�֡�
���´��� Storm ����ƽ̨�ڴ��ڵ�����ʵ��

���ڵ����������Ļ����ܹ���ܹ�ʦ���´�
������ʵʱӦ�ó���
������������ص� Dashboard������UV��ÿ������û�����������صĸ���ƽ̨����APP��Android/iPhone/iPad������APP���ܱ߿�顢PC��Mվ���¼����û������ֲ�η�Ʒ���ʵʱ���
���Ի��������Ƽ����û��ڵ�����ÿһ���м�ֵ�IJ��������������������������������ղصȣ�������ʵʱ�����ܵ�Ӱ���������Ӷ����������û��������顢����ת���ʡ�
���ĵ���ʣ����ķ����ס�ʵʱ�Ʒѣ��������淴����ҵ��ȫ��
������ʵʱƽ̨
�����ܹ�

ͼ1�����ܹ�
������ʵʱƽ̨�ܹ���Ҫ�ּ��飬����������Դ�����ݵ��������PC��APP�ϴ������ݣ����������ָ�û���������ݣ�Blackhole��Ҫ��֧����־��ģ�PUMA��Ҫ�ǻ�ȡMySQL�������ݿ�ģ�Swallow��Ҫ��MQϵͳ����ô��Storm�����õ���Щ�����أ��������е������ϲ��������ݶ������뼶���õ�����װ��Ӧ����������ԴSpout��ͨ��Blackhole֧����־��ʵʱ��ȡ�������־/ҵ��Log/Nginx��־�ȣ�����Puma Client��MySQL Binlog������һʱ���ȡ���ݿ����ݱ��������Swallow��MQ������ȡӦ����Ϣ����Pigeon��RPC ��ܣ���֧�ֵ��õ�����ҵ������ҵ����λ�ȡStorm�������������أ�ʵʱ����͵�����ҵ����ͨ��data-service�������ݿ������Redis/HBase/MySQL�ȴ洢�У�ͬ����������ҵ��ͨ��data-service����ȡStorm����ij־û����ݡ�

ͼ2 Blackhole�ܹ�
ÿ̨���ϵ�Ӧ�÷�����������Agent����ģ���Kafka��̫һ������Supervisor��������Ϣ�Ŀ��ƣ���������ʱͨ��Broker����Blackhole��һ����ʵʱ�������ѣ�������ȡ�����Ϻܶ�Ӧ����־ֱ�ӷŵ�HDFS�
��Ⱥ���
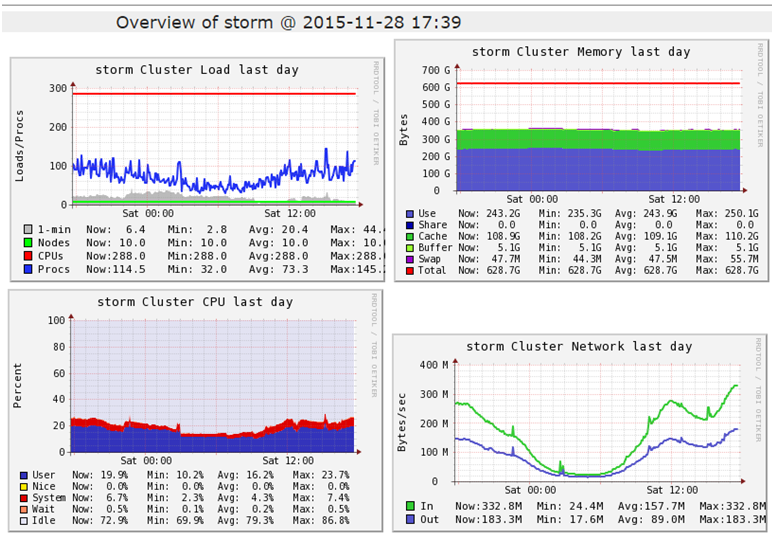
ͼ3ij����Ⱥ�Ļ���״̬
��ganglia�Ѽ�һЩ������ε����ݣ�Ҳ���Ǽ�Ⱥ�Ļ�����״̬������Load���ڴ桢cpu�����������������������Ų�����ʱ�Ϳ��Կ���������εĻ�����Ϣ��û���쳣��
ͼ4ij��worker������Ϣ
���嵽һ��workerʱ���ǰ�ͳһ����Ϣ�����ڲ��ļ��ϵͳCAT���棬�ܶ�Ӧ����ļ��Ҳ������CAT��
ҵ����
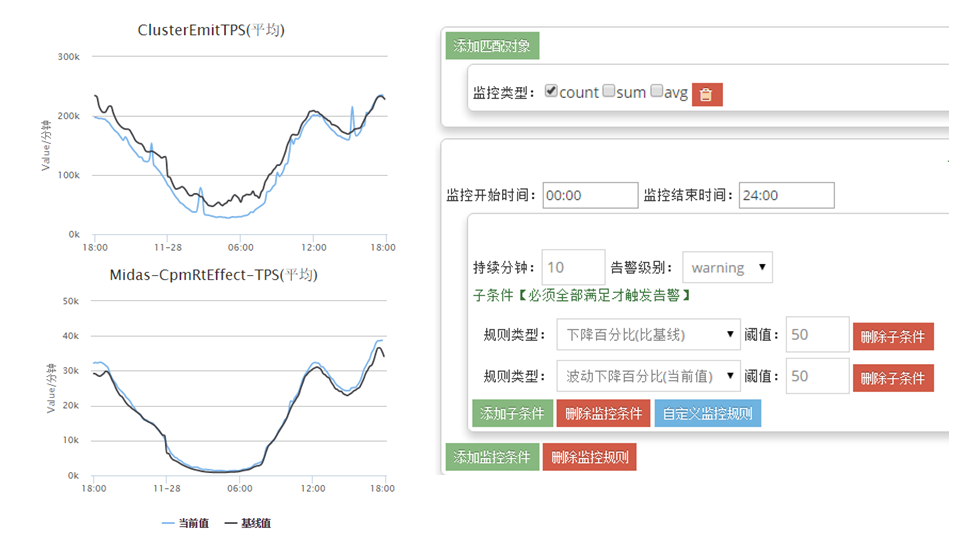
ͼ5�����Topologyά�ȵ���Ӧ����
�����е�Topologyͨ��Nimbus API��Metric API������ץ�����������������CAT���档���Զ�ÿ��ͼ�䱨��ֵ�����ĵ�ǰֵ�ͼ���ֵ���仯�ʣ����������ӵĵ�����٣���Сֵ���ֵ����Щ��������Ӧ�ı�����������ʱ�ͻ��յ����������š��ʼ������ŵȡ�

ͼ6ҵ���Լ������Ӧ����
���ǿ����Լ����ĵ�ҵ�����ݴ�CAT����ȥ����Spout��Blackhole���ѵ�Topic���ݣ�ʧ��������TPS�ȣ�����Ҳ��������һЩ��������
����ʹ�� Storm �����ľ����ѵ��������
1��ij��Worker�Ե��˼������е�CPU������TopologyҲ���꣺Topologyһ����2��Worker����Bolt�����Լ�������200���̣߳�����json��
���������CGroup���Ƶ���Worker����Դ��
2��Storm��Ȩ�������յ�һ�ѱ�����Owner��֪����˭��
3��Topology�ύ��Storm��ȴ������������Cause��free slot < worker num��
���������
import backtype.storm.nimbus.ITopologyValidator;
public class DPTopologyValidator implements ITopologyValidator {
//Topology Name�Ϸ���
//Worker��Executor����������
//free slot����������ڵ�Supervisor�ڵ���������֤��Ⱥ����ɿ���
} |
4��Zookeeper���̱�ˢ���ˣ�Casue��Storm��Ⱥ�ϵ�Topology Task����������Ϣ��zk��������־> 20G/H��
���������
����Zookeeper��־�����������
���Ƶ���Ⱥ��ģ��
task.heartbeat.frequency.secs Ĭ��3s���ʵ�����
5��Namenode��Topology DDoS��
Cause��
Hadoop��Ⱥ������Security��
������־����storm-hdfsдHDFS��ҵ���ع�����writeʧ�ܺ����ԣ�Namenode ��RPC ����8000QPS�����ع��ߣ���������Job���ܵ�Ӱ�졣
���������
�ṩͳһ��дHDFS�ķ���ֻ��Ҫ����Ҫд������ݷ���blackhole��
6������������Worker OOM��
Cause��StormĿǰ��backpress���ƣ�JStorm 2.1.0������
���������
����ACK��
����topology.max.spout.pending��
��������С����ǵļ������������� ����Щ�꣬����һ��ȹ��� Storm �Ӱ�����
���⣬����������һЩ Storm Topology �Ż���С���ɣ���ν�Ǹɻ�ʮ�㡣
�����滮
Worker��־ͳһ�ռ���չ�֣�doing��������log�鿴�Ƚϲ����㣬Topology��Worker��Package��Class��Level�ȶ�ά��ͳһչ�֡�
����ƽ̨���ɸ��������ݣ�֧��ϸ���ȵ�tracking��Storm/JStormͬʱ֧�֡�
Storm on Docker ����ǿ�����ԣ�Topology�������Զ�������
�̺ƣ�StreamingSQL on Spark

Intel �����ݹ���ʦ�̺�
�ݽ�ǰ���̺Ƽ�Ҫ�����������Ŷ��� Spark��Դ�����Ļ�Ծ�����ߣ����������� Intel ��Դ��Ŀ StreamingSQL �ĵ�һ�����ϡ�
Ϊʲô��ҪStreamingSQL��
���û�ʹ�õIJ����Ͻ������Ϊ�û��ṩһ���dz����ײ�����һ��װ���ô�Ҹ��õ�ȥ����Streaming�������ǵIJ�����StreamingSQL �ij���ʹ�ÿ����߿���ͨ�� SQL �켯�����������������������㣬����˿�����ά���ɱ����̺ƴ� Spark Streaming �� Spark SQL �Ļ���ԭ������SparkStreaming���ǰ�ָ����ʱ��Ƭ���ڵ�������������֯��һ�������Batches��Ȼ���װ��һ��RDD�����Զ�RDD���и���ת������������С�������ύ��Sparkִ������ȥִ�У�����һ�����ϵ���ǰ�ĵ����Ĺ��̡�
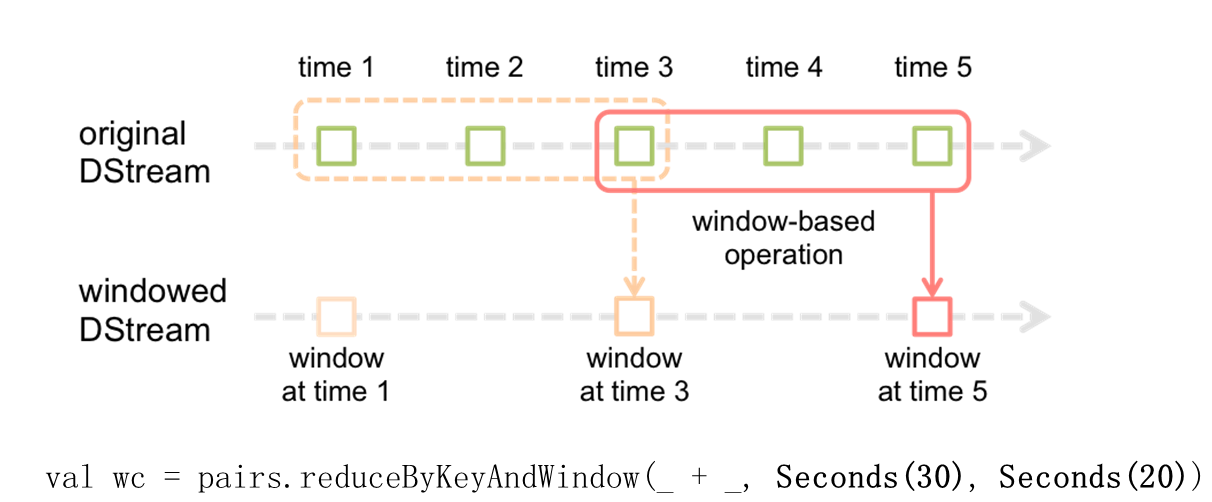
ͼ1Stream��window����
ÿ�Ѽ�һ����λʱ���ڵ����ݴ���һ��С���ӣ����ǿ��������ɸ���λʱ�����һ��window������ϣ����window�ڵ����ݽ��в�������������ʽ����������window���Բ�ͣ����ǰ�ƣ�ͼ1�ж���һ��window����30S��ÿ��20SҪִ��һ����صIJ�����
StreamingSQL �����˼��
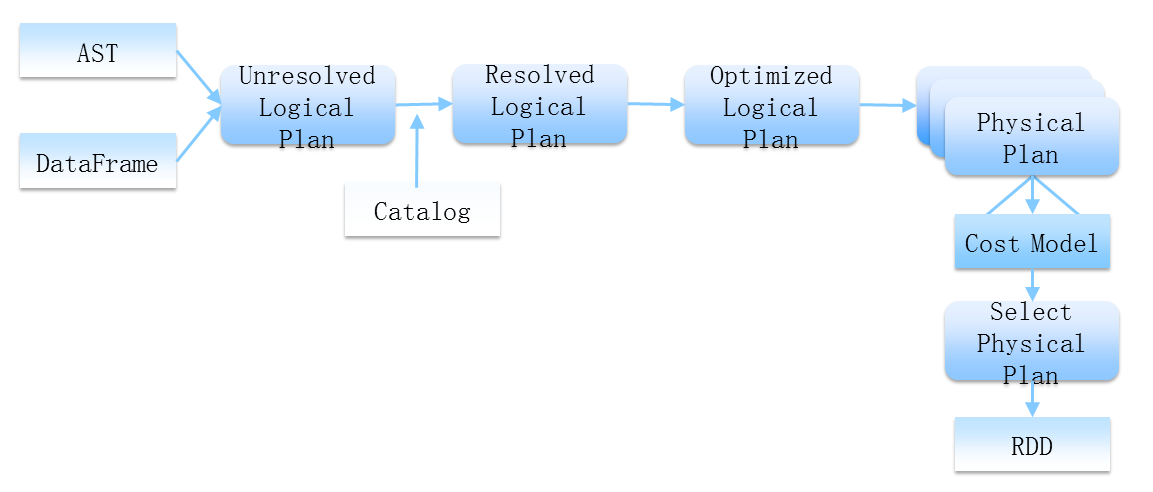
ͼ2 SparkSQL���Ż���execution pipeline��
ͼ2���ֳ�������˼����һ��AST��DataFrame��Ϊǰ�˵����룬ֻ�����������Ҫ��ʲô��������ôȥ���������Լ������飬����˵���������������������Ż�����һ��������͵ķ�ʽ������ȥ��ɡ��ڶ���Spark SQL����ִ���ǽ���Spark��Ⱥ�����ģ�������ִ���������������RDD��
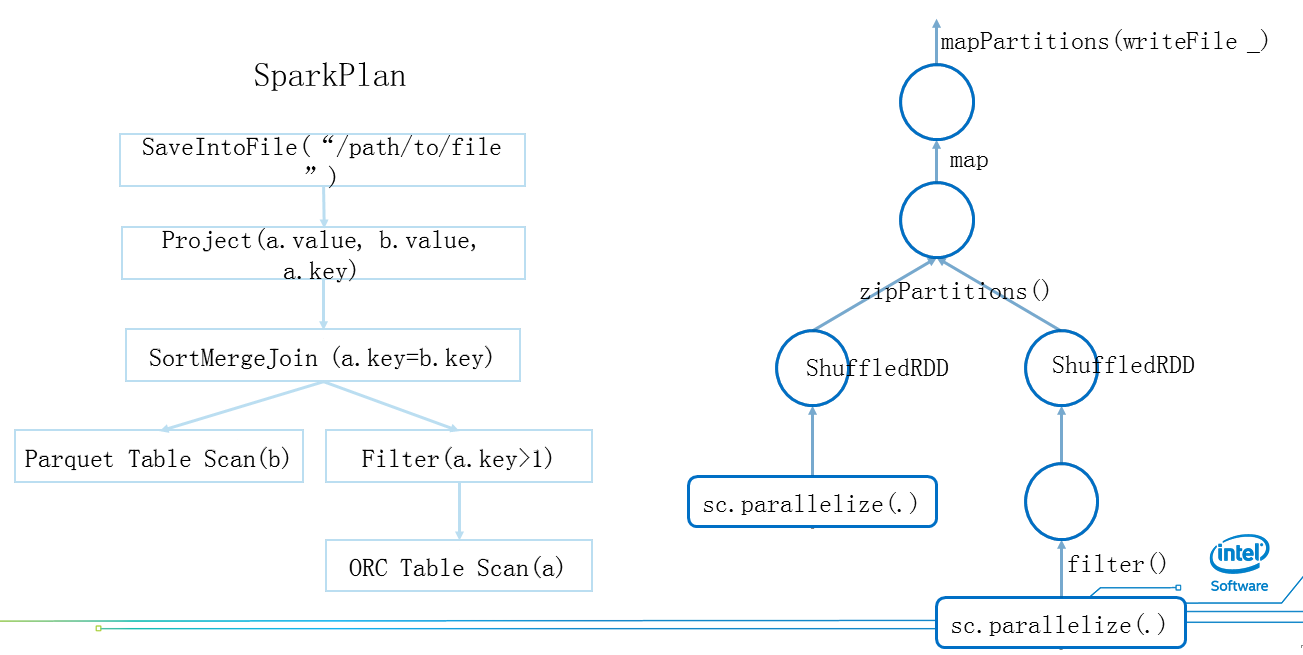
ͼ3 Spark SQL Spark Plan & RDD
ͼ3ΪSpark��һ�������ƻ��������״ͼ��������Ϊ���������ұ�ΪORC�����ΪParquet����ORC���й��˺������������ݽ���Join��Ȼ�����ͶӰ���ٰ�����д���ļ�����Ӧͼ���Sparkplan��RDD��ͼ�Ҳ࣬����һ���dz��Ķ�Ӧ��ϵ��
����ʵ��Spark Streaming SQL
��γ���Spark SQL��Steraming SQL���齨�������ʹ�����еĴ����Լ���μ̳����еĹ���

ͼ4 The Key Classes
ͼ4�е�һ��ΪWindowedPhysicalPlan������SparkPlan��һ�����࣬��windowDuration��slideDuration����������Window�ģ���Ͱ�Spark��Streaming�ĸ����������ˣ�execute�ķ������Ҫ����һ��RDD����������Planning Stage,������SQL���еĸ�������ĸ���������������ͨ��WindowPhysicalPlan��������������������ġ�Spark StreamingҪ��������DStream���ڶ���SchemaDStream��װ��һ��streamSQLContext��compute�ķ������ҲҪ����һ��RDD��
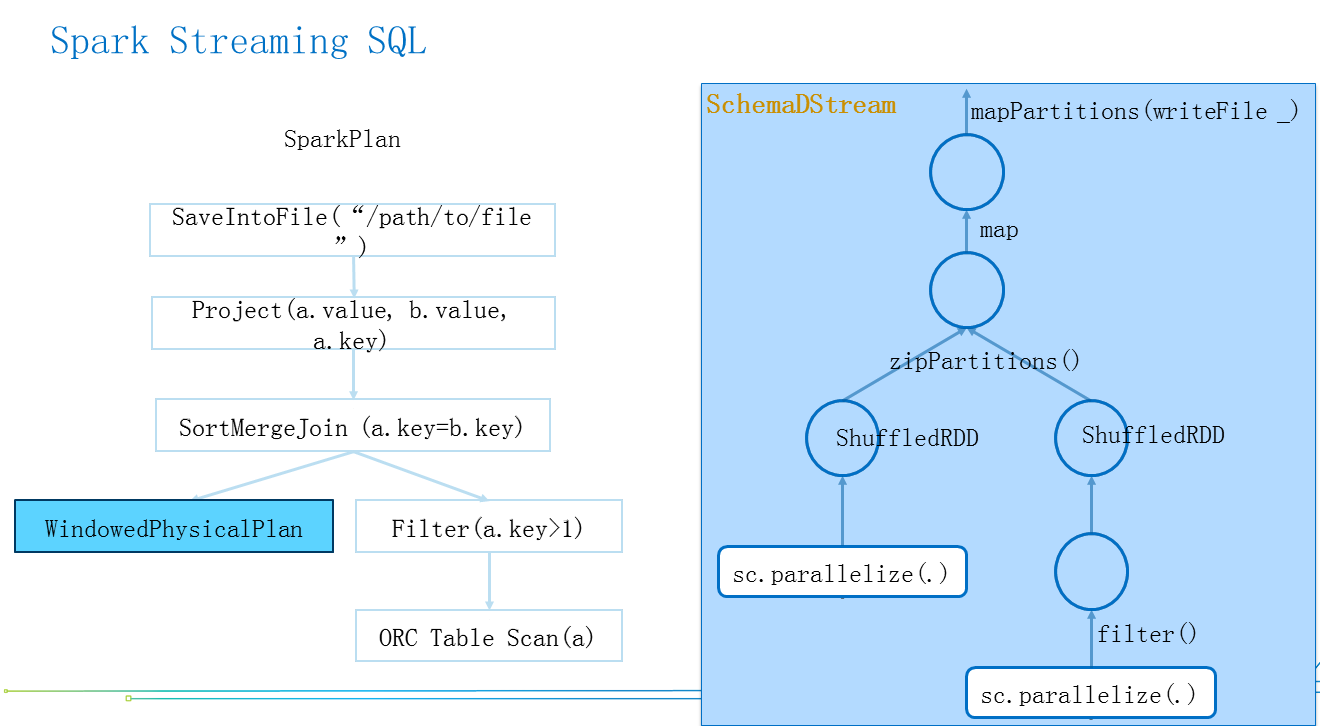
ͼ5 �滻���Spark SQL Spark Plan & RDD
����ͼ5����ߵı���Parquet�滻��Streaming��Datasource���������ƻ��Ľڵ㻻��WindowPhysicalPlan������һ��RDD���������ǰ�Streaming��SQL���������Ȼ����ұ����ɵ�RDD��DAG��װ��SchemaDStream����װ�������������Ǽȿ���ͨ����ߵķ�ʽ�ﵽSQL��ת�����һ��RDD��ͨ���ұߵķ�ʽ���õ���RDD���DStream�ύ��Spark Streamingȥ��������������Spark Streaming SQL�Ĺ��̡�
���ȥ����һ��������ʽ��Datasource��
Spark Streaming SQL��ȫ�ߵ���Spark SQL����Datasource�Ľӿ�ȥʵ�֣�ֻ����Ҫ�ر���һ��kafka��datasource��
�����SQL���Window
���Ƕ�SQL����һ�����չ������over������ʱ�����еĶ��塣ȥ��over����SQLһģһ����

ͼ6 Spark Streaming V.S. Streaming SQL
���߶Աȷ��֣�Spark Streaming�Ŀɶ��Խϲ��Streaming SQLһĿ��Ȼ��
����ô�
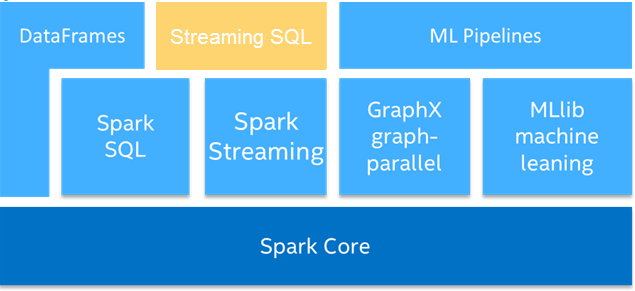
ͼ7 Spark Streaming SQL�ṹͼ
ͼ7�еײ�Spark Core�������DataFrames�Ա߲���Streaming SQL,���ǻ���Spark SQL��Spark Streaming������������齨����ȫ����Spark SQL,���SQL��Streaming��ʲô�Ľ�ʱ�����Զ������Щ�ô�������Ҫ��������ģ�������ʽ���ݿ��Ժ;�̬�����н��������������
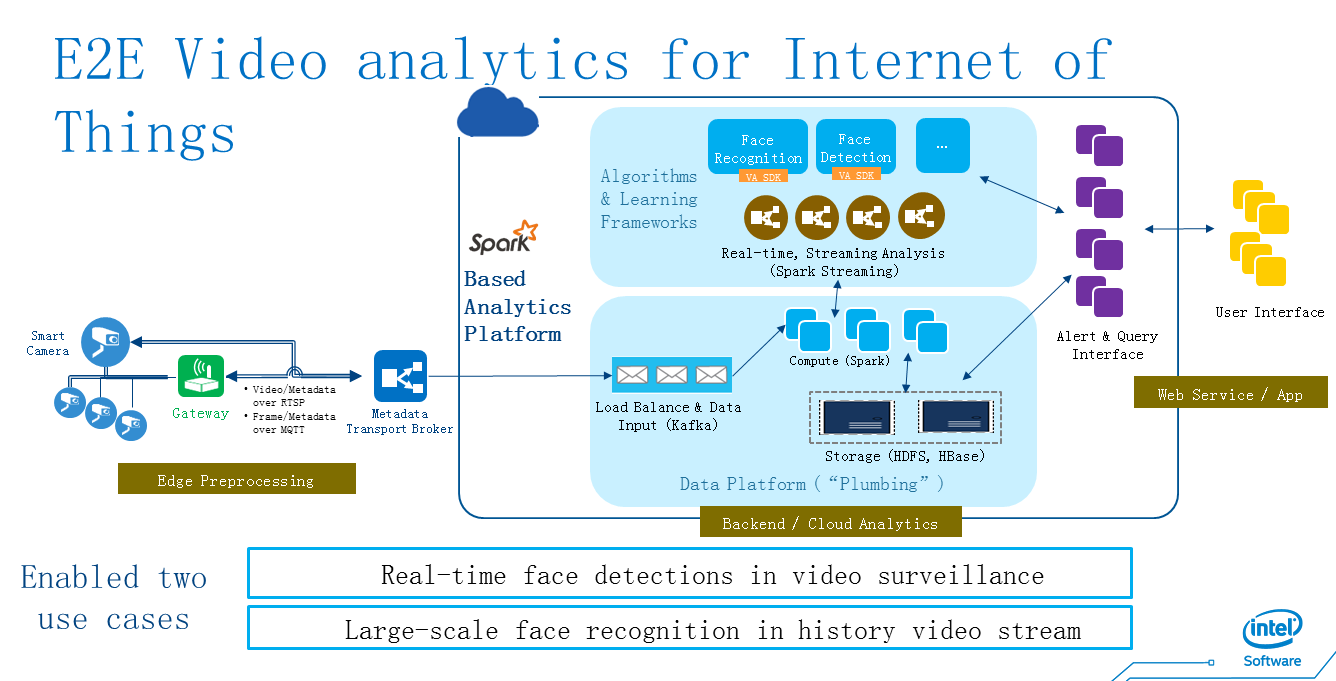
ͼ8 Spark Streaming SQLʹ�ð���
��������ʹ�� StreamingSQL ������ͷ������ʵʱ������Ԥ����������ʷ���ݺͷ������������ݽ���ƥ�䣬ץ�����ɷ���ʹ�ð�����StreamingSQL ��ǰ���� Spark 1.4.1 �汾���� Spark ���������ڴ�����һ���ں��������ݺ���ʽ���ݵķ����� Streaming DataFrames���̺���Ϊδ�� Spark �е����������������������㽫��϶�Ϊһ��
Todd Lipcon�� Fast Analytics on fast data

Cloudera���ǹ���ʦTodd Lipcon
Todd �� Hadoop ��������һ���Ĺ���ʦ��Hadoop �� HBase �� PMC �� Committer������highly-available metadata journaling (QJM) and automatic failover for HDFS�� ��2012���𣬿�ʼ��Cloudera�쵼Kudu��Ŀ��
��ǰ��Hadoop��̬ϵͳ
�ݽ��У�Todd ����ָ���˵��� Hadoop �洢ϵͳ�д��ڵ����⡣HDFS (Parquet) �ʺ����������ݵ����߷�����HBase �ʺ����������ݵ�������ʣ�û��һ��ϵͳ������ߵ����ơ����ų����ٳ��������ڴ��豸�ij��֣��洢ϵͳ��ƿ����ת�� CPU������ǰ�Ĵ洢ϵͳ�����֮����δ���ǵ� CPU ��Ч�ʡ�
Kudu���Ŀ��
��ɨ���ͨ�������ڷ��ʵĵ��ӳ٣������ݿ�����壬��ϵ����ģ�͵ȡ�Kudu ����Ϊ�˽����Щ����������ģ�����ͬʱ���� OLAP �� OLTP ����������ʹ���ϣ�Kudu �ı���ͳ���ݿ⣬�����������������������У�ͬʱ Kudu �ṩ�� NoSQL �����û��ӿڣ����⣬Kudu ʵ������ MapReduce��Spark �� Impala �ļ��ɡ��������ϣ�Kudu ������չ����ǧ���ڵ㣬�洢 PB �����ݣ�ÿ�봦������ζ�д��
Kudu ���ʺ���˳���д�������д��ϵ�Ӧ�ã���һ�� Todd ��С��ʹ�ó���Ϊ�������� Kudu�� С���˴����ݷ���ƽ̨��ԭ��������ͨ�������������ֱ�ӵ��� Kudu ���з�����ÿ���г��� 50 ������¼д�� Kudu����ʱ��Сʱ���죩���½����뼶��
Kudu��ʹ�ð���
Kudu�������ȡ��д��ͬʱ��ϡ�
ʱ������ʾ�������г�����;��թ����Ԥ��;���ռ�ء�
�������أ����룬���£�ɨ�裬���ҡ�
�������ݷ������磺������в��⡣
�������أ����룬ɨ�裬���ҡ�
���߱���ʾ����ODS��
�������أ����룬���£�ɨ�裬���ҡ�
ʲô��Kudu
Todd ��ϸ������ Kudu �ļܹ���ơ�Kudu �б���ˮƽ�ָ�Ϊ��� Tablets�����ݴ��ڷ������ı���Ӳ���ϡ�ÿ�� Tablet �ж�����ݣ�����֮��ͨ�� Raft Э�鱣��һ���ԡ�master �����������Ԫ���ݣ�Ϊ��������ܣ�Ԫ����ͬʱ�����ڿͻ��˵��ڴ��С�Kudu �������д洢�������ѹ����ʡ�ռ������������ͬʱ���ڸ�ѡ���Ե�����dz���Ч��
�� TPC-H �Ĵֲ����ϣ�Kudu ���� Parquet �и��õ����ܣ���Ҳ��С����ʵҵ������еõ���֤�����⣬Kudu ���ڳ�Ϊ Apache Incubator ��Ŀ��
|





