|
��MySQL������¼������ʱ����ɾ�IJ����ܶ��ἱ���½������Բο����²������Ż���
�����Ż�
���ǵ�������δ����һֱ�������ǣ�����Ҫһ��ʼ�Ϳ��Dz�֣���ֻ��������������ά�ĸ��ָ��Ӷȣ�һ��������ֵΪ���ı���ǧ�����£��ַ���Ϊ���ı��������������û��̫������ġ�����ʵ�Ϻܶ�ʱ��MySQL������������Ȼ�в����Ż��ռ䣬����������֧��ǧ�����ϵ���������
�ֶ�
����ʹ��TINYINT��SMALLINT��MEDIUM_INT��Ϊ�������Ͷ���INT������Ǹ������UNSIGNED
VARCHAR�ij���ֻ����������Ҫ�Ŀռ�
ʹ��ö�ٻ����������ַ�������
����ʹ��TIMESTAMP����DATETIME��
������Ҫ��̫���ֶΣ�������20����
����ʹ��NULL�ֶΣ����Ѳ�ѯ�Ż���ռ�ö��������ռ�
����������IP
����
����������Խ��Խ�ã�Ҫ���ݲ�ѯ������ԵĴ�����������WHERE��ORDER BY�������漰���н����������ɸ���EXPLAIN���鿴�Ƿ�������������ȫ��ɨ��
Ӧ����������WHERE�Ӿ��ж��ֶν���NULLֵ�жϣ��������������ʹ������������ȫ��ɨ��
ֵ�ֲ���ϡ�ٵ��ֶβ��ʺϽ����������硱�Ա�����ֻ��������ֵ���ֶ�
�ַ��ֶ�ֻ��ǰ����
�ַ��ֶ���ò�Ҫ������
����������ɳ���֤Լ��
��������UNIQUE���ɳ���֤Լ��
ʹ�ö�������ʱ����˳��Ͳ�ѯ��������һ�£�ͬʱɾ������Ҫ�ĵ�������
��ѯSQL
��ͨ����������ѯ��־���ҳ�������SQL
���������㣺SELECT id WHERE age + 1 = 10���κζ��еIJ����������±�ɨ�裬���������ݿ�̳̺������������ʽ�ȵȣ���ѯʱҪ�����ܽ����������Ⱥ��ұ�
sql��価���ܼ�һ��sqlֻ����һ��cpu���㣻������С��䣬������ʱ�䣻һ����sql���Զ���������
����SELECT *
OR��д��IN��OR��Ч����n����IN��Ч����log(n)����in�ĸ������������200����
���ú����ʹ���������Ӧ�ó���ʵ��
����%xxxʽ��ѯ
����JOIN
ʹ��ͬ���ͽ��бȽϣ�������'123'��'123'�ȣ�123��123��
����������WHERE�Ӿ���ʹ��!=��<>�������������������ʹ������������ȫ��ɨ��
����������ֵ��ʹ��BETWEEN����IN��SELECT id FROM t WHERE num BETWEEN 1 AND 5
�б����ݲ�Ҫ��ȫ����Ҫʹ��LIMIT����ҳ��ÿҳ����Ҳ��Ҫ̫��
����
Ŀǰ�㷺ʹ�õ���MyISAM��InnoDB�������棺
MyISAM
MyISAM������MySQL 5.1��֮ǰ�汾��Ĭ�����棬�����ص��ǣ�
��֧����������ȡʱ����Ҫ���������б�������д��ʱ��Ա���������
��֧������
��֧�����
��֧�ֱ�����İ�ȫ�ָ�
�ڱ��ж�ȡ��ѯ��ͬʱ��֧�������в����¼�¼
֧��BLOB��TEXT��ǰ500���ַ�������֧��ȫ������
֧���ӳٸ�����������������д������
���ڲ�������ĵı���֧��ѹ������������ٴ��̿ռ�ռ��
InnoDB
InnoDB��MySQL 5.5���ΪĬ�������������ص��ǣ�
֧������������MVCC��֧�ָ߲���
֧������
֧�����
֧�ֱ�����İ�ȫ�ָ�
��֧��ȫ������
����������MyISAM�ʺ�SELECT�ܼ��͵ı�����InnoDB�ʺ�INSERT��UPDATE�ܼ��͵ı�
ϵͳ���Ų���
����ʹ�����漸���������������ԣ�
sysbench��һ��ģ�黯����ƽ̨�Լ����̵߳����ܲ��Թ���
iibench-mysql������ Java �� MySQL/Percona/MariaDB �������в������ܲ��Թ���
tpcc-mysql��Percona������TPC-C���Թ���
����ĵ��Ų������ݽ϶࣬����ɲο��ٷ��ĵ����������һЩ�Ƚ���Ҫ�IJ�����
back_log��back_logֵָ����MySQL��ʱֹͣ�ش�������֮ǰ�Ķ�ʱ���ڶ��ٸ�������Ա����ڶ�ջ�С�Ҳ����˵�����MySql���������ݴﵽmax_connectionsʱ�����������ᱻ���ڶ�ջ�У��Եȴ�ijһ�����ͷ���Դ���ö�ջ��������back_log������ȴ����ӵ���������back_log������������������Դ�����Դ�Ĭ�ϵ�50����500
wait_timeout�����ݿ���������ʱ�䣬�������ӻ�ռ���ڴ���Դ�����Դ�Ĭ�ϵ�8Сʱ������Сʱ
max_user_connection: �����������Ĭ��Ϊ0�����ޣ������һ����������
thread_concurrency�������߳�������ΪCPU����������
skip_name_resolve����ֹ���ⲿ���ӽ���DNS����������DNS����ʱ�䣬����Ҫ����Զ��������IP����
key_buffer_size��������Ļ����С�����ӻ��������������ٶȣ���MyISAM������Ӱ��������ڴ�4G���ң�����Ϊ256M��384M��ͨ����ѯshow status like 'key_read%'����֤key_reads / key_read_requests��0.1%�������
innodb_buffer_pool_size���������ݿ�������飬��InnoDB������Ӱ�����
ͨ����ѯshow status like 'Innodb_buffer_pool_read%'����֤ (Innodb_buffer_pool_read_requests �C Innodb_buffer_pool_reads) /Innodb_buffer_pool_read_requestsԽ��Խ��
innodb_additional_mem_pool_size��InnoDB�洢����������������ֵ���Ϣ�Լ�һЩ�ڲ����ݽṹ���ڴ�ռ��С�������ݿ����dz����ʱ���ʵ������ò����Ĵ�С��ȷ���������ݶ��ܴ�����ڴ�����߷���Ч�ʣ�����С��ʱ��MySQL���¼Warning��Ϣ�����ݿ�Ĵ�����־�У���ʱ����Ҫ�õ������������С
innodb_log_buffer_size��InnoDB�洢�����������־��ʹ�õĻ�������һ����˵�����鳬��32MB
query_cache_size������MySQL�е�ResultSet��Ҳ����һ��SQL���ִ�еĽ���������Խ���ֻ�����select��䡣��ij�������������κ��κα仯�����ᵼ�����������˸ñ���select�����Query Cache�еĻ�������ʧЧ�����ԣ������ǵ����ݱ仯�dz�Ƶ��������£�ʹ��Query Cache���ܻ�ò���ʧ������������(Qcache_hits/(Qcache_hits+Qcache_inserts)*100))���е�����һ�㲻����̫��256MB�����Ѿ�����ˣ����͵������;�̬���ݿ��ʵ�����.
����ͨ������show status like 'Qcache_%'�鿴ĿǰϵͳQuery catchʹ�ô�С
read_buffer_size��MySql���뻺������С���Ա�����˳��ɨ���������һ�����뻺������MySql��Ϊ������һ���ڴ滺����������Ա���˳��ɨ������dz�Ƶ��������ͨ�����Ӹñ���ֵ�Լ��ڴ滺������С���������
sort_buffer_size��MySqlִ������ʹ�õĻ����С�������Ҫ����ORDER BY���ٶȣ����ȿ��Ƿ������MySQLʹ�����������Ƕ��������Ρ�������ܣ����Գ�������sort_buffer_size�����Ĵ�С
read_rnd_buffer_size��MySql���������������С����������˳���ȡ��ʱ(���磬��������˳��)��������һ������������������������ѯʱ��MySql������ɨ��һ��û��壬�Ա��������������߲�ѯ�ٶȣ������Ҫ����������ݣ����ʵ����߸�ֵ����MySql��Ϊÿ���ͻ����ӷ��Ÿû���ռ䣬����Ӧ�����ʵ����ø�ֵ���Ա����ڴ濪������
record_buffer��ÿ������һ��˳��ɨ����߳�Ϊ��ɨ���ÿ�ű����������С��һ������������������ܶ�˳��ɨ�裬������Ҫ���Ӹ�ֵ
thread_cache_size�����浱ǰû�������ӹ���������Ϊ�����µ����ӷ�����̣߳����Կ�����Ӧ���ӵ��߳���������贴���µ�
table_cache��������thread_cache_size��������������ļ�����InnoDBЧ��������Ҫ����MyISAM
����Ӳ��
Scale up���������˵�ˣ�����MySQL��CPU�ܼ��ͻ���I/O�ܼ��ͣ�ͨ������CPU���ڴ桢ʹ��SSD��������������MySQL����
�����
Ҳ��Ŀǰ���õ��Ż����ӿ������д��һ�㲻Ҫ����˫�����������ܶิ���ԣ������������е�����������������ܡ�ͬʱĿǰ�ܶ��ֵĽ������ͬʱҲ��˿����˶�д����
����
������Է�������Щ��Σ�
MySQL�ڲ�����ϵͳ���Ų����������������
���ݷ��ʲ㣺����MyBatis���SQL��������棬��Hibernate���Ծ�ȷ��������¼�����ﻺ��Ķ�����Ҫ�dz־û�����Persistence Object
Ӧ�÷���㣺�������ͨ������ֶζԻ������������Ŀ��ƺ����ʵ�ֲ��ԣ����ﻺ��Ķ��������ݴ������Data Transfer Object
Web�㣺���webҳ��������
������ͻ��ˣ��û��˵Ļ���
���Ը���ʵ�������һ����λ�����ν�ϼ��뻺�档�����ص�����·����Ļ���ʵ�֣�Ŀǰ��Ҫ�����ַ�ʽ��
ֱдʽ��Write Through����������д�����ݿ��ͬʱ���»��棬ά�����ݿ��뻺���һ���ԡ���Ҳ�ǵ�ǰ�����Ӧ�û�������Spring Cache�Ĺ�����ʽ������ʵ�ַdz���ͬ���ã���Ч��һ�㡣
��дʽ��Write Back������������Ҫд�����ݿ�ʱ��ֻ����»��棬Ȼ���첽�����Ľ���������ͬ�������ݿ��ϡ�����ʵ�ֱȽϸ��ӣ���Ҫ�϶��Ӧ������ͬʱ���ܻ�������ݿ��뻺��IJ�ͬ������Ч�ʷdz��ߡ�
������
MySQL��5.1������ķ�����һ�ּ�ˮƽ��֣��û���Ҫ�ڽ�����ʱ����Ϸ�����������Ӧ�������������Ĵ���
���û���˵����������һ�����������������ǵײ��ɶ�������ӱ���ɣ�ʵ�ַ����Ĵ���ʵ������ͨ����һ��ײ���Ķ����װ������SQL����˵��һ����ȫ��װ�ײ�ĺں��ӡ�MySQLʵ�ַ����ķ�ʽҲ��ζ������Ҳ�ǰ��շ������ӱ����壬û��ȫ������

�û���SQL�������Ҫ��Է��������Ż���SQL������Ҫ���Ϸ����������У��Ӷ�ʹ��ѯ��λ�������ķ����ϣ�����ͻ�ɨ��ȫ������������ͨ��EXPLAIN PARTITIONS���鿴ij��SQL����������Щ�����ϣ��Ӷ�����SQL�Ż�������ͼ5����¼�������������ϣ�

�����ĺô��ǣ�
�����õ����洢���������
�����������ݸ�����ά��������ͨ�����������������ɾ���������ݣ�Ҳ���������µķ�����֧���²�������ݡ����⣬�����Զ�һ���������������Ż�����顢���Ȳ���
���ֲ�ѯ�ܹ��Ӳ�ѯ����ȷ��ֻ�������������ϣ��ٶȻ�ܿ�
�����������ݻ����Էֲ��ڲ�ͬ�������豸�ϣ��Ӷ���Ц���ö��Ӳ���豸
����ʹ�÷�����������ijЩ����ƿ��������InnoDB���������Ļ�����ʡ�ext3�ļ�ϵͳ��inode������
���Ա��ݺͻָ���������
���������ƺ�ȱ�㣺
һ�������ֻ����1024������
��������ֶ�������������Ψһ�������У���ô���������к�Ψһ�����ж������������
��������ʹ�����Լ��
NULLֵ��ʹ����������Ч
���з�������ʹ����ͬ�Ĵ洢����
���������ͣ�
RANGE��������������һ�����������������ֵ���Ѷ��з��������
LIST�����������ڰ�RANGE��������������LIST�����ǻ�����ֵƥ��һ����ɢֵ�����е�ij��ֵ������ѡ��
HASH�����������û�����ı���ʽ�ķ���ֵ������ѡ��ķ������ñ���ʽʹ�ý�Ҫ���뵽���е���Щ�е���ֵ���м��㡣�������������MySQL����Ч�ġ������Ǹ�����ֵ���κα���ʽ
KEY�����������ڰ�HASH��������������KEY����ֻ֧�ּ���һ�л���У���MySQL�������ṩ�������Ĺ�ϣ������������һ�л���а�������ֵ
�����ʺϵij����У�
���ʺϵij������ݵ�ʱ�������ԱȽ�ǿ�������ʱ����������������ʾ��

��ѯʱ����ʱ�䷶Χ����Ч�ʻ�dz��ߣ�ͬʱ���ڲ���Ҫ����ʷ�����ܺ��ݵ�����ɾ����
������������Ե��ȵ㣬���ҳ����ⲿ�����ݣ��������ݺ��ٱ����ʵ�����ô���Խ��ȵ����ݵ�������һ������������������������ܹ��л��ᶼ�������ڴ��У���ѯʱֻ����һ����С�ķ��������ܹ���Чʹ�������ͻ���
����MySQL��һ�����ڵļķ���ʵ�� �C �ϲ�����merge table�������ƽ϶���ȱ���Ż���������ʹ�ã�Ӧ�����µķ������������
��ֱ���
��ֱ�ֿ��Ǹ������ݿ���������ݱ�������Խ��в�֣����磺һ�����ݿ�����ȴ����û����ݣ��ִ��ڶ������ݣ���ô��ֱ��ֿ����û����ݷŵ��û��⡢�Ѷ������ݷŵ������⡣��ֱ�ֱ��Ƕ����ݱ����д�ֱ��ֵ�һ�ַ�ʽ���������ǰ�һ�����ֶεĴ���������ֶκͷdz����ֶν��в�֣�ÿ������������ݼ�¼��һ�����������ͬ�ģ�ֻ���ֶβ�һ����ʹ����������
����ԭʼ���û����ǣ�

��ֱ��ֺ��ǣ�

��ֱ��ֵ��ŵ��ǣ�
����ʹ�������ݱ�С��һ�����ݿ�(Block)���ܴ�Ÿ�������ݣ��ڲ�ѯʱ�ͻ����I/O����(ÿ�β�ѯʱ��ȡ��Block ����)
���Դﵽ�������Cache��Ŀ�ģ������ڴ�ֱ��ֵ�ʱ����Խ���������ֶη�һ�𣬽������ı�ķ�һ��
��������
ȱ���ǣ�
�����������࣬��Ҫ����������
�����������JOIN����������CPU����������ͨ����ҵ��������Ͻ���join���������ݿ�ѹ��
��Ȼ���ڵ�����������������⣨��Ҫˮƽ��֣�
����������
ˮƽ���
����
ˮƽ�����ͨ��ij�ֲ��Խ����ݷ�Ƭ���洢���ֿ��ڷֱ��ͷֿ������֣�ÿƬ���ݻ��ɢ����ͬ��MySQL����⣬�ﵽ�ֲ�ʽ��Ч�����ܹ�֧�ַdz������������ǰ��ı�����������Ҳ��һ������Ŀ��ڷֱ�
���ڷֱ��������ǵ����Ľ���˵�һ�����ݹ�������⣬����û�аѱ������ݷֲ�����ͬ�Ļ����ϣ���˶��ڼ���MySQL��������ѹ����˵����û��̫������ã���һ��Ǿ���ͬһ���������ϵ�IO��CPU�����磬�����Ҫͨ���ֿ������
ǰ�洹ֱ��ֵ��û����������ˮƽ��֣�����ǣ�

ʵ��������������Ǵ�ֱ��ֺ�ˮƽ��ֵĽ�ϣ�����Users_A_M��Users_N_Z�ٲ��Users��UserExtras������һ�����ű�
ˮƽ��ֵ��ŵ���:
�����ڵ�������ݺ߲���������ƿ��
Ӧ�ö˸������
�����ϵͳ���ȶ��Ժ�������
ȱ���ǣ�
��Ƭ����һ�������Խ��
��ڵ�Join���ܲ������
���ݶ����չ�Ѷȸ�ά��������
��Ƭԭ��
�ܲ��־Ͳ��֣��ο������Ż�
��Ƭ���������٣���Ƭ�������ȷֲ��ڶ�����ݽ���ϣ���Ϊһ����ѯSQL���ƬԽ�࣬����������Խ���ȻҪ��������������һ����Ƭ�Ľ����ֻ�ڱ�Ҫ��ʱ��������ݣ����ӷ�Ƭ����
��Ƭ������Ҫ����ѡ��������ǰ�滮����Ƭ�����ѡ����Ҫ�������ݵ�����ģʽ�����ݵķ���ģʽ����Ƭ���������⣬�Լ���Ƭ�������⣬����ķ�Ƭ����Ϊ��Χ��Ƭ��ö�ٷ�Ƭ��һ����Hash��Ƭ���⼸�ַ�Ƭ������������
������Ҫ��һ�������е�SQL��Խ�����Ƭ���ֲ�ʽ����һֱ�Ǹ����ô���������
��ѯ���������Ż�����������Select * �ķ�ʽ���������ݽ�����£������Ĵ���������CPU��Դ����ѯ�������ⷵ�ش�������������Ҿ���ΪƵ��ʹ�õIJ�ѯ��佨��������
ͨ����������ͱ����������Ϳ��Join�Ŀ���
�����ر�ǿ��һ�·�Ƭ�����ѡ�����⣬���ij���������������Ե�ʱ�����������綩��������¼�ȣ�������ͨ���ȽϺ�����ʱ�䷶Χ��Ƭ����Ϊ����ʱЧ�Ե����ݣ�����������ע����ڵ����ݣ���ѯ��������������ʱ���ֶν��й��ˣ��ȽϺõķ����ǣ���ǰ��Ծ�����ݣ����ÿ�ȱȽ϶̵�ʱ��ν��з�Ƭ������ʷ�Ե����ݣ�����ñȽϳ��Ŀ�ȴ洢��
��������˵����Ƭ��ѡ����ȡ������Ƶ���IJ�ѯSQL����������Ϊ�����κ�Where���IJ�ѯSQL����������еķ�Ƭ������������������SQLԽ�࣬��ϵͳ��Ӱ��Խ����������Ҫ������������SQL�IJ�����
�������
����ˮƽ���ǣ������Ƚϸ��ӣ���ǰҲ���˲��ٱȽϳ���Ľ����������Щ������Ϊ�����ࣺ�ͻ��˼ܹ��ʹ����ܹ���
�ͻ��˼ܹ�
ͨ�������ݷ��ʲ㣬��JDBC��Data Source��MyBatis��ͨ�������������������Դ��ֱ�����ݿ⣬����ģ����������ݵķ�Ƭ���ϣ�һ����Jar���ķ�ʽ����
����һ���ͻ��˼ܹ������ӣ�

���Կ�����Ƭ��ʵ���Ǻ�Ӧ�÷�������һ��ģ�ͨ����Spring JDBC����ʵ��
�ͻ��˼ܹ����ŵ��ǣ�
Ӧ��ֱ�����ݿ⣬������Χϵͳ������������崻�����
���ɳɱ��ͣ����������ά�����
ȱ���ǣ�
����ֻ�������ݿ���ʲ��������£���չ��һ�㣬���ڱȽϸ��ӵ�ϵͳ���ܻ���������
����Ƭ����ѹ������Ӧ�÷������ϣ���ɶ������
�����ܹ�
ͨ���������м����ͳһ������������Դ�����ݷ�Ƭ���ϣ�������ݿ⼯Ⱥ��ǰ��Ӧ�ó���������Ҫ�����������ά�������
����һ�������ܹ������ӣ�
�������Ϊ�˷����ͷ�ֹ���㣬һ���Լ�Ⱥ��ʽ���ڣ�ͬʱ������ҪZookeeper֮��ķ������������
�����ܹ����ŵ��ǣ�
�ܹ������dz����ӵ����������ݿ���ʲ�ԭ��ʵ�ֵ����ƣ���չ��ǿ
����Ӧ�÷���������û�������κζ��⸺��
ȱ���ǣ�
�貿�����ά�����Ĵ����м�����ɱ���
Ӧ���辭���������������ݿ⣬�����϶���һ������������ʧ���ж������
�������Ƚ�


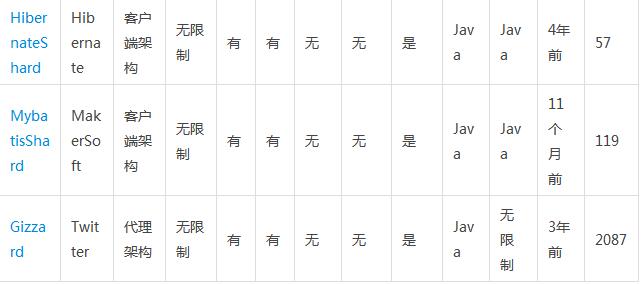
��˶�ķ�������ν���ѡ��������˼·�����ǣ�
ȷ����ʹ�ô����ܹ����ǿͻ��˼ܹ�����С��ģ���DZȽϼij���������ѡ��ͻ��˼ܹ������ӳ�������ģϵͳ����ѡ������ܹ�
���幦���Ƿ����㣬������Ҫ��ڵ�ORDER BY����ô֧�ָù��ܵ����ȿ���
������һ����û�и��µIJ�Ʒ��˵������ͣ�ͣ���������ά���ͼ���֧��
��ð���˾->����->С��˾->���������ij�Ʒ��˳����ѡ��
ѡ��ڱ��Ϻõģ�����github������ʹ��������������ʹ���߷���
��Դ�����ȣ�������Ŀ���������������Ҫ�Ķ�Դ����
��������˼·���Ƽ�����ѡ��
�ͻ��˼ܹ���
�����ܹ�
����MySQL�ҿ�ˮƽ��չ�����ݿ�
ĿǰҲ��һЩ��Դ���ݿ����MySQLЭ�飬�磺
TiDB
Cubrid
���乤ҵƷ�ʺ�MySQL���в�࣬����Ҫ�ϴ����άͶ�룬����뽫ԭʼ��MySQLǨ�Ƶ���ˮƽ��չ�������ݿ��У����Կ���һЩ�����ݿ⣺
������PetaData
������OceanBase
��Ѷ��DCDB
NoSQL
��MySQL����Sharding��һ�ִ������������裬��ʵ�Ϻܶ���������MySQL����RDBMS����������Ҫ��ACID�����Կ��ǽ���Щ��Ǩ�Ƶ�NoSQL�������ˮƽ��չ���⣬���磺
��־�ࡢ����ࡢͳ��������
�ǽṹ�������ṹ������
������Ҫ��ǿ������̫��������������� |






