|

导论
Uber的早期架构由一个单体后端应用程序构成,该应用由Python编写,Python使用Postgres以实现数据持久化。自那时起,Uber架构已发生巨变,逐步转化为微服务模式和新的数据平台。特别是在之前一些使用Postgres的案例中,现在则改用Schemaless(一个基于MySQL的全新数据库分片)。本文将探索Postgres的缺陷,解释迁移到MySQL的基础上构建Schemaless和其它后端服务的原因。
Postgres的架构
Postgres有很多局限性:
写入架构低效
数据复制低效
表损坏的问题
糟糕的从库MVCC支持
新版本更新难度升级
下文将分析Postgres的表表示法和磁盘上的索引数据,重点对比MySQL通过其InnoDB存储引擎呈现相同数据的方法,以探索上述缺陷。注意:本文涉及的分析主要基于旧版Postgres
9.2系列。 众所周知,本文论述的内部架构在新发布的Postgres中没有太大变更。事实上,至少自Postgres
8.3的发布开始(距今近十年),Postgres 9.2中磁盘上表示法的基础设计就一直没有做出显著调整。
磁盘上的数据格式
关系数据库必须执行下列关键任务:
支持插入/更新/删除功能
支持schema变更功能
实现一个多版本并发控制(MVCC)机制,促使不同的连接对其所处理的数据生成一致性的事务视图
思考其所有特性如何协同运作是设计数据库在磁盘上呈现数据的基础。
Postgres的一项核心设计是行数据固定。该固定行在Postgres用语中又名“元组(tuple)”。在Postgres中,元组又通过ctid获得唯一标识。从概念上讲,ctid代表元组在磁盘上的位置(例如物理磁盘偏移)。多个ctid可能能够描述一个单行(例如多个行版本为了MVCC的目的而存在时,或是旧版本行未经autovacuum进程回收时)。一组元组的组织集合构成表,表本身包含索引,索引经组合构成数据结构(通常是B-tree结构),从而将索引字段映射到ctid的有效载荷。
通常情况下,这些ctid是面向用户透明的,但了解其运行方式有助于理解Postgres表在磁盘上的表架构。若要查看行的当前ctid,则可向WHERE子句中的栏目列表中添加“ctid”:
uber@[local] uber=> SELECT ctid, * FROM my_table LIMIT 1;
-[ RECORD 1 ]--------+------------------------------
ctid | (0,1)
...other fields here... |
为求布局细节,先以一个简单的用户表为例。Uber针对每个用户设置了自动递增的用户ID主键、用户姓名和出生年份。同时Uber还设置了一个基于用户全名(包括名和姓)的复合二级索引,和另一个基于用户出生年份的二级索引。用以创建该表的DDL如下:
CREATE TABLE users (
id SERIAL,
first TEXT,
last TEXT,
birth_year INTEGER,
PRIMARY KEY (id)
);
CREATE INDEX ix_users_first_last ON users (first,
last);
CREATE INDEX ix_users_birth_year ON users (birth_year); |
注意该定义中的三个索引:主键索引和两个二级索引。
为求例证,将以下面的表格数据展开论述,表中数据均由历史上颇具影响力的数学家构成:

如前所述,表中每一行隐含一个唯一且不公开的ctid。因此,表的内部表示如下:

设置主键索引(映射ID到ctid):

B-tree结构的设置基于id字段,且其每个节点都保存ctid值。在这个案例中需要注意的是,由于使用自动递增id,B-tree中的字段顺序有时会和表中顺序相同,但是也不一定如此。
二级索引彼此都很相似;主要差异在于字段存储顺序,而字段在B-tree中必须以字典顺序排布。(first,last)索引从名开始按字母表顺序自上而下排列。

同样,birth_year(出生年份)聚集索引以升序排列:

综上所述,不同于自动递增主键的案例,在上面的情境下,各个二级索引中的ctid字段都不是按字母表顺序升序排布的。
假设需要更新一条表记录,比如将al-Khwārizmī的出生年份字段更新为另一个预估值770CE。如前所述,行元组是固定的,因此,为了更新记录,需要向表中添加一个新元组。该新元组有一个新的非公开ctid,称之为I。Postgres需要能够区分I上的新元组和D上的旧元组。在内部,Postgres将一个版本字段和指向前一个元组(如果有的话)的指针存于各个元组。据此,表的新结构如下:

只要al-Khwārizmī存在两个行版本,则索引必须包含这两个行的条目。为求简洁,Uber此处删除了主键索引,只显示二级索引:
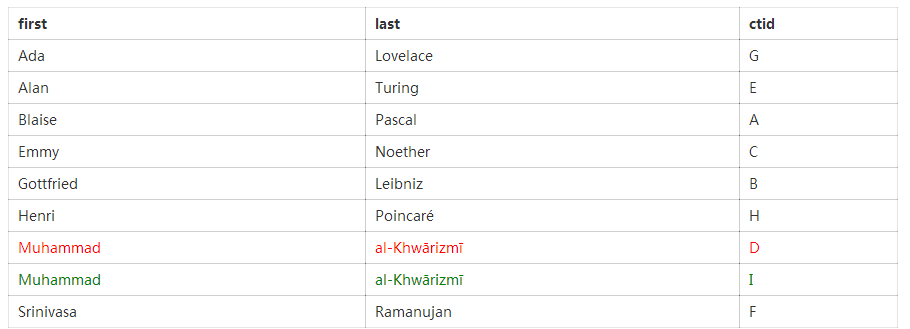

此处将旧版显示为红色,新版为绿色。在内部,Postgre通过另一个字段保存行版本,以判定哪一个是最新元组。该新增字段帮助数据库决定让哪一个行元组服务于一个事务,该事务可能不被允许查看最新行版本。

Postgres下,主索引和二级索引都直指磁盘上的元组偏移。若一个元组的位置发生改变,则必须更新全部索引。
复制
在表中插入新行时,若支持流复制,Postgres则需对其进行复制。为求故障修复,数据库已启用一个预写式日志(WAL),以实现两阶段提交。即使不支持流复制,数据库也必须启用WAL,因为WALL支持ACID中的原子性和持久性两方面。
若数据库发生突发异常(比如突然断电),可通过考虑发生的事情来理解WAL。数据库计划对表和索引在磁盘上的内容做出更改,而WAL表示这些更改的分类汇总。Postgres的后台程序初次启动时,进程将该分类汇总内的数据和磁盘上的实际数据进行对比。若汇总中包含磁盘上未反应的数据,则数据库修正元组或索引数据,以反应WAL预写的数据。随后滚回部分数据,这些数据出现于WAL,但来自部分应用事务(指未提交事务)。
Postgres将主数据库上的WAL发送至从库,以实现流复制。每一个从库都在以故障修复的方式高效运行,以应对故障后启动的方式,不断实施WAL更新。流复制和实际故障修复之间的唯一不同在于:执行流WAL时,处于“热备份”模式的从库支持读取查询;而实际处于故障修复模式的Postgres数据库往往不支持查询,直到数据库实例完成崩溃恢复进程。
由于WAL是专为崩溃恢复而设计的,故包含磁盘上更新的底层信息。而WAL的内容位于行元组和其磁盘偏移(例如行ctid)在磁盘上的实际表示层。若在从库完全同步时暂停Postgres的主数据库和从库,则从库磁盘上的实际内容恰好和主数据库上的内容完全匹配。因此,若与主数据库连接超时,rsync这类工具能够修复损坏副本。
Postgres设计的坑
在Uber的应用过程中,Postgres的设计导致低效问题的同时,还给Uber数据造成障碍。
写入放大
在其它情况下Postgres设计的首要问题是写入放大。写入放大通常代指数据写入SSD磁盘的问题:一个小的逻辑更新(写入几个字节(byte))被放大了,从而增加了更新转入物理层的代价。Postgres也出现了相同的问题。在前面的例子中,若对al-Khwārizmī的出生年份进行小的逻辑更新,则至少需要展开四项物理更新:
向表空间写入新的行元组;
更新主键索引以向新元组中加入一条记录;
更新(first,last)索引以向新元组中加入一条记录;
更新birth_year索引以向新元组中加入一条记录。
实际上,这四项更新仅反映了主要表空间的写入;其中每一项写入都需要反映于WAL,因此磁盘上的总写入量更大了。
此处值得注意的是第二和第三项更新。更新al-Khwārizmī的出生年份时,实际上并非更改主键,也不是改变其名和姓。然而,这些索引仍要依据数据库中行记录新创建的行元组进行更新。针对拥有大量二级索引的表,这些多余的步骤将导致低效。例如,现有一表,其上定义了十二条索引,则其更新至一个仅涵盖一条索引的字段也必须要转至全部十二条索引以反应新行的ctid。
复制
此处的写入放大问题自然转至复制层,因为复制发生在磁盘上的更改层级。不复制小的逻辑记录(如“将ctid
D距今的出生年份更改为770”),数据库转而写出上述四项操作的WAL记录,该记录通过网络同步。因此,写入扩大问题也转化为复制扩大问题,且Postgres复制数据流迅速变得极为繁琐,从而可能会大量占用频宽。
若Postgres复制仅在一个数据中心内发生,则复制频宽可能不会构成问题。现代网络设备和交换器可支持大量频宽,且很多主机提供商提供免费或廉价的内部数据中心频宽。然而,若复制必须发生于两个数据中心之间,问题则会迅速扩大。例如,Uber最初使用西海岸主机托管空间的物理服务器。出于崩溃恢复的目的,向二级东海岸主机托管空间添加服务器。在该设计中,西部数据中心有一个主数据库Postgres实例(和从数据库),东部数据中心有一个副本集。
级联复制将内部数据中心频宽需求限制在主数据库和单一副本间的所需的量,即使二级数据中心有很多副本。然而,Postgres副本协议冗余仍然会导致使用大量索引的数据库产生巨量数据。购买高频宽跨国连接话费很高,而且即使资金不是问题,也很难获得一个和本地内部连接一样的跨国网络连接。同时频宽问题也带来了WAL档案问题。除了要将所有WAL更新从西海岸发送到东海岸,还要将所有WAL存入一个文件存储器web服务,这不仅是为故障发生后的数据库恢复提供额外保障,同时存储WAL也从数据库快照中提取新副本。在早期通信高峰阶段,存储web服务的频宽速度不够快,以至于不足以赶上WAL被写入的速度。
数据损坏
在一次常规主数据库扩容过程中,Uber遭遇了Postgres 9.2的bug。从库按时间顺序切换出错,导致部分WAL记录误用。由于这个bug,部分应被版本控制机制标记为非活跃的记录,实际上未被标记为非活跃。
下面的查询阐释了该bug是如何影响用户表的:
SELECT * FROM users WHERE id = 4;
该查询返回两条记录:初始al-Khwārizmī行的780 CE出生年份,加上新al-Khwārizmī行的770
CE出生年份。若想向WHERE列表中添加ctid,则两个返回记录将具有不同的ctid值,会产生两个截然不同的行元组。
受一些原因影响,这个问题极为棘手。首先,很难确认有多少行会受到影响;数据库返回的重复结果导致大量应用逻辑出错。Uber最终添加防御性编程语句以检测有这类问题的表的情境。因为该bug影响所有服务器,因此从库实例不同则崩溃行不同,也就是说在同一个副本上X行可能是坏的,而Y行又是好的,但另一个副本的X行可能是好的,而Y行却是坏的。实际上,并不能确定包含崩溃数据的副本数,以及该问题是否影响到了主数据库。
综上所述,该问题仅体现在每个数据库中的几个行上,但是却颇令人忧虑,因为复制发生在物理层,所以最终可能导致数据库索引完全崩溃。B-tree的一个重要方面就是必须定期对其进行重新平衡,且该操作会彻底改变tree的结构,sub-trees被移往新的磁盘位置。若错误数据被转移,可能会导致tree的大部分完全失效。
最终,Uber能够追捕实际bug,并用它来确定新升级的主数据库不包含任何受损行。通过重新同步全部主数据库的新快照,以解决副本崩溃问题,这个进程很困难;Uber一次只能从负载均衡池中提取有限量的副本。
遭遇的问题仅影响了Postgres 9.2的特定发布,并且已经被解决很长时间了。但仍然会担心这类bug会再次发生。一旦发现这种性质的bug,一个新版的Postgres可以随时发布,而且由于复制的工作方式,该问题可能会同步至复制层的所有数据库。
从库MVCC
Postgres没有真正的复制MVCC支持。从库运用WAL更新这一点导致其具有一个磁盘上数据的副本,在任何给定的时间点都和主数据库相同。
Postgres需要保持MVCC旧行版本的副本。若流复制包含一个开放事务,则在影响到通过该事务保持开放的行时,数据库更新会被锁定。在这种情境下,Postgres中止WAL应用线程,直到事务终止。由于从库较之主数据库可能会严重滞后,所以若事务耗时过长则会产生问题。因此,Postgres在这类情景下设置超时:若一项事务锁定WAL应用一段时间,则Postgres将kill该事务。
这个设计意味着从库正常会比主数据库延迟几秒,因此很容易编写代码,从而导致杀死事务。一些应用开发者编写的代码中,事务的起始点较为模糊,对于他们而言,这个问题的可能不那么明显。例如,假设一个开发者有一些代码,而这些代码必须向用户邮件发送收据。基于其编写方式,该代码暗含一个数据库事务,这一事务保持开放状态,直至邮件发送完成。虽然执行无关阻塞I/O时,代码包含开放式数据库事务并不妥当,但事实是大多数工程师都不是数据库专家,所以往往可能不能理解这个问题,特别是在使用ORM的时候,类似于开放事务,它会模糊底层细节。
Postgres更新
因为复制记录在物理层执行,所以不可能复制Postgres不同通用版本间的数据。一个运行Postgres
9.3的主数据库,无法复制一个运行Postgres 9.2的从库;(反之亦然)一个运行Postgres
9.2的主数据库也无法复制一个运行Postgres 9.3的从库。
在从一个Postgres GA更新到另一个的过程中,遵循以下步骤:
关闭主数据库;
在主数据库上运行’pg_upgrade’指令,它将在适当位置更新主数据库数据。这对于一个大型数据库而言,往往要花好多个小时,且在该进程进行的过程中,不支持任何通信;
再次启动主数据库;
创建主数据库新快照。该步骤完全复制主数据库内的所有数据,因此一个大型数据库在此也要花费数个小时;
清理每个从库,修复主数据库到从库的新快照;
恢复每个从库至复制层,与此同时,等待从库完全获取主数据库的全部更新。
Uber团队从Postgres 9.1开始,成功实现了更新至Postgres 9.2的进程。然而,该进程耗时过长,因而无法支持再次执行。Postgres
9.3推出后,Uber的发展促使其数据集大幅增,因此更新过程将耗时更久。出于这个原因,之前遗留的Postgres实例直至今日仍在运行Postgres
9.2,尽管目前Postgres GA已经发布到9.5版本了。
若运行Postgres 9.4或是更新的版本,则可以运用pglogical这样的功能,该功能实现了Postgres的一个逻辑复制层。运用pglogical,则可复制不同Postgres版本间的数据,这意味着可以在无需遭遇重大故障的前提下,进行更新操作(如将Postgres
9.4更新到9.5版本)。同时,该性能也仍然存在问题,因为它并未集成到Postgres的主干树,且pglogical本身也仍非运行旧版Postgres的选项。
MySQL的架构
除了介绍Postgres的限制,还要阐述一下对于近期的Uber Engineering存储项目(如Schemaless)而言,以MySQL为工具的重要意义。会发现在很多情况下,MySQL更为适用。为了了解其中的差异,Uber团队检测了MySQL的架构以及其与Postgres架构间的差别。团队特别分析了MySQL是如何与InnoDB的存储引擎相合作的。针对Uber,其团队不仅使用到了InnoDB,但它可能是最受欢迎的MySQL存储引擎。
InnoDB磁盘上的表示法
类似于Postgres,InnoDB支持高级功能,如MVCC和可变数据。关于InnoDB在磁盘上格式的详尽讨论,不属于本文的范畴;本文将着眼于其与Postgres二者间的核心差异。
其中最重要的架构区别在于:Postgres直接将索引记录映射到磁盘上的位置,而InnoDB则保有一个二级结构。InnoDB二级索引记录指针指向主键值,而不是像Postgres中ctid的操作,指针指向磁盘上行的位置。如此,MySQL中的二级索引连接索引键和主键。

若要基于(first,last)索引执行一项索引查找,实际上需要完成两项查找。第一项搜索表并找出一条记录的主键。一旦找到主键,第二项查询启动,开始搜索主键索引以找出磁盘上行的位置。
该设计表明在执行第二项键查找的时候,对Postgres造成轻微的负面影响,因为InnoDB要进行两次索引查找,而Postgres仅需一次。然而,由于是标准化数据,行更新仅需更新那些真正因为行更新而产生变更的索引记录。此外,InnoDB往往在适当的位置进行行更新。若旧事务需要引用一个行以实现MVCC,则MySQL将旧行复制到一个名为回滚段的特殊区域。
下面继续跟进更新al-Khwārizmī出生年份时发生的情况。若有空间,id为4的行中的出生年份字段在适当位置更新(实际上,该更新总是在适当位置发生,因为出生年份时一个占据定额空间的Integer)。出生年份索引也在适当位置更新,以反映新数据。旧行数据被复制到回滚段。主键索引无需更新,(名,姓)索引也无需更新。若表上包含大量索引,也只需要更新检索涉及birth_year字段的那部分索引。因此,假设现有涉及类似于signup_date、last_login_time等字段的索引,则无需对其进行更新,反之,在Postgres中则必须对其更新。
同时,该设计还能提高数据扫除(vacuuming)和压缩操作的效率。所有按需待扫除的行都可直接在回滚段中获取。相较而言,Postgres的autovacuum(自动扫除)进程则必须要进行全表扫描来确认删除行。

MySQL启用一个额外的间接层:二级索引记录指向主键记录,且主键本身保存磁盘上的行位置。若行偏移发生变更,只需更新主索引。
复制
MySQL支持多种复制模式:
基于语句(statement)的复制:复制逻辑SQL语句(例如,按字面复制语句文字如:UPDATE users
SET birth_year=770 WHERE id = 4);
基于行的复制:复制变更的行记录;
混合复制模式:混合上述两种模式。
对于这些模式还有多种权衡。基于语句的复制往往最为简洁,但可能会需要从库运用高价的语句来更新少量数据。此外,基于行的复制,类似于Postgres
WAL复制,相对繁琐,但其结果预见性更强,且有助于从库高效更新。
在MySQL中,只有主索引具有指针指向磁盘上的行偏移。这在涉及复制时,产生了一个重要结果。MySQL复制流只需要包含逻辑更新到行的信息。复制更新属于这一类“将行的时间戳从T_1改到T_2”。这些语句的结果为从库自动推断需要变更的索引。
对比之下,Postgres复制流包含物理变更,例如“磁盘上偏移8,382,491,写入字节XYZ”。Postgres下,磁盘的每一次物理变更都需纳入WAL流。小的逻辑变化(如更新一个时间戳)需要多个磁盘上的变更:Postgres必须插入新元组并更新所有指向该元组的索引。如此,WAL流中将输入大量变更。该设计差异表明MySQL复制的二进制日志比Postgres
WAL流要简洁很多。
每个复制流的运行方式对于MVCC和从库的合作方式也有着重要意义。由于MySQL复制流有逻辑更新,从库可具有真正的MVCC语义;因此读取从库查询不会锁定复制流。相较而言,Postgres
WAL流包含磁盘上的物理变更,因此Postgres从库不能运用与读取查询相冲突的复制更新,故而无法实现MVCC。
MySQL的复制架构表明,若bugs确实导致了表崩溃,则该问题不太可能导致灾难性的故障。复制发生在逻辑层,因此再平衡B-tree这类操作不可能引发索引崩溃。一个典型的MySQL复制问题往往是语句被跳过(或缺少次数、运行两次)的情况。这可能会导致数据缺失或失效,但不会导致数据库宕机。
最终,MySQL的复制架构简化了不同MySQL版本间的复制。若复制格式变化,则MySQL仅增加其版本,这对MySQL而言并不常见。MySQL的逻辑复制格式也表明存储引擎层内磁盘上的变更不会影响复制格式。执行MySQL更新的常用方式是一次更新一个从库,且一但更新所有从库,则其中一个从库将变为新的主数据库。这可以在零故障下完成,同时也简化了保持MySQL最新状态的操作。
其它MySQL设计优势
So far, we’ve focused on the on-disk architecture for
Postgres and MySQL. Some other important aspects of
MySQL’s architecture cause it to perform significantly
better than Postgres, as well.
截止目前,本文主要关注Postgres和MySQL磁盘上的架构。而MySQL架构还有一部分要点使之在运行上优于Postgres。
缓冲池
首先,缓存在这两个数据库中的运行方式不同。Postgres为内部高速缓存配置内存,但较之机器总内存量,这些高速缓存往往较小。为了提升性能,Postgres支持内核通过页面缓存自动存储最近访问磁盘的数据。例如,Uber最大的Postgres从库具有768
GB可用内存,但实际上其中只有约25 GB被Postgres的RSS内存占用。这给Linux页面缓存遗留了超过700
GB的空闲内存。
该设计的问题在于,事实上,较之访问RSS内存,通过页面缓存访问数据耗资更高。针对磁盘中的数据查询,Postgres发布了lseek(2)和read(2)系统调用以定位数据。此二者都会引发上下文切换(context
switch),这比访问主内存数据的花费还要更高。实际上,在这一点上,Postgres甚至还没有完全优化:其未使用pread(2)系统调用,pread(2)将seek
+ read操作合并到一个系统调用之中。
通过比较,InnoDB存储引擎实现了自身InnoDB缓冲池中的LRU。这在逻辑上和Linux页面缓存相似,但它实现于用户空间。虽然比Postgres的设计更复杂,但InnoDB缓冲池设计也拥有一些能突出的优势:
可实现一个用户LRU设计。例如,能够检测出有损LRU的恶意访问模式,并阻止其造成更进一步的危害;
几乎不会导致上下文切换。通过InnoDB缓冲池访问到的数据不要求任何用户/内核的上下文切换。最糟糕的情况莫过于发生TLB
miss(TLB失败),这相对而言也较为便宜,且可通过大内存页使损失最小化。
连接管理
通过对每个连接生成一个线程(thread-per-connection),MySQL实现并发连接。这种连接占用相对较低;每个线程都占用栈空间内存,加上部分配置到堆内存连接特定(connection-specific)缓冲区的。将MySQL扩展到10,000或是这样的并行连接是很常见的,实际上,如今Uber的MySQL实例更接近这个连接数。
但Postgres采用一个每个连接一个进程(process-per-connection)设计。出与多方面的原因,该设计耗资比一个thread-per-connection设计高出很多。较之生成一个新线程,派生一个新进程会占据更多内存。此外,进程间的IPC比线程间的IPC耗资更多。Postgres
9.2使用System V IPC为IPC的原语,而不是使用线程时的轻量级futexes。因为通常在 futex无竞争的情况下,无需上下文切换,所以futexes比System
V IPC速度更快。
Postgres设计的内存和IPC占用之外,Postgres似乎在支持高连接数量方面的处理能力较差,即使是在可用内存充足的情况下。而在扩展Postgres至数百个活跃连接的过程中,Uber团队遭遇了重大问题。虽然该官方文档未给出明确原因,但的确给出了强烈的建议:选用进程外连接池机制以扩展Postgres连接数量。相应地,在运用pgbouncer合并连接和Postgres方面,Uber团队总体上获得了成功。然而,偶尔后端服务还是会出现应用bug,从而导致开启多于应有服务的活跃连接(往往是“idle
in transaction”连接),这些bugs又会导致故障扩张。
结论
在Uber早期,Postgres适应发展需求,但是随着Postgres的扩展和Uber的发展,Uber团队逐渐开始遭遇一些棘手的问题。如今,Uber还保有一些遗留Postgres实例,但大量数据库是基于MySQL(往往用到Schemaless层)构建,或是(在某些情况下)基于NoSQL数据库,比如Cassandra。Uber团队如今对MySQL较为满意,未来将会更新更多博文,以解释其针对Uber的更多先进应用。
|






