дНРДдНЖрЕФЙЋЫОВЩгУСїДІРэЃЌВЂНЋЯжгаЕФХњДІРэгІгУЧЈвЦЕНСїДІРэЃЌЛђепЖдаТЕФгУР§ВЩгУСїДІРэЪЕЯжЕФНтОіЗНАИЁЃЦфжааэЖргІгУМЏжадкСїЪ§ОнЗжЮіЩЯЃЌЗжЮіЕФЪ§ОнСїРДздИїжждДЃЌР§ШчЪ§ОнПтЪТЮёЁЂЕуЛїЁЂДЋИаЦїВтСПЛђIoT ЩшБИЁЃ
Apache Flink ЗЧГЃЪЪгУгкСїЗжЮігІгУГЬађЃЌвђЮЊЫќжЇГжЪТМўЪБМфгявхЃЌШЗБЃжЛДІРэвЛДЮЃЌвдМАЭЌЪБЪЕЯжСЫИпЭЬЭТСПКЭЕЭбгГйЁЃвђЮЊетаЉЬиадЃЌFlink ФмЙЛНќЪЕЪБЖдДѓСПЕФЪфШыЪ§ОнМЦЫуГівЛИіШЗЖЈКЭОЋШЗЕФНсЙћЃЌВЂЧвдкЗЂЩњЙЪеЯЕФЪБКђЬсЙЉвЛДЮадгявхЁЃ
Flink ЕФКЫаФСїДІРэAPIЃЌDataStream APIЃЌЗЧГЃОпгаБэЯжСІЃЌВЂЧвЮЊаэЖрГЃМћВйзїЬсЙЉСЫдгяЁЃдкЦфЫћЬиаджаЃЌЫќЬсЙЉСЫИпЖШПЩЖЈжЦЕФДАПкТпМЃЌВЛЭЌБэЯжЬиеїЯТЕФВЛЭЌзДЬЌдгяЃЌзЂВсКЭЯьгІЖЈЪБЦїЕФЙГзгЃЌвдМАИпаЇЕФвьВНЧыЧѓЭтВПЯЕЭГЕФЙЄОпЁЃСэвЛЗНУцЃЌаэЖрСїЗжЮігІгУзёбЯрЫЦЕФФЃЪНЃЌВЂВЛашвЊDataStream API ЬсЙЉЕФБэЯжСІМЖБ№ЁЃЫћУЧПЩвдЪЙгУСьгђЬиЖЈЕФгябдРДЪЙгУИќздШЛКЭМђНрЕФЗНЪНБэДяЁЃзмЫљжмжЊЃЌSQL ЪЧЪ§ОнЗжЮіЕФЪТЪЕБъзМЁЃЖдгкСїЗжЮіЃЌSQL ПЩвдШУИќЖрЕФШЫдкЪ§ОнСїЕФЬиЖЈгІгУжаЛЈЗбИќЩйЕФЪБМфЁЃШЛЖјЃЌФПЧАЛЙУЛгаПЊдДЕФСїДІРэЦїЬсЙЉСюШЫТњвтЕФSQL жЇГжЁЃ
ЮЊЪВУДСїжаЕФSQL КмживЊ
SQL ЪЧЪ§ОнЗжЮіЪЙгУзюЙуЗКЕФгябдЃЌгаКмЖрдвђЃК
- SQL ЪЧЩљУїЪНЕФЃКФужИЖЈФуЯывЊЕФЖЋЮїЃЌЖјВЛЪЧШчКЮШЅМЦЫуЃЛ
- SQL ПЩвдНјаагааЇЕФгХЛЏЃКгХЛЏЦїМЦЙРЫугааЇЕФМЦЛЎРДМЦЫуНсЙћЃЛ
- SQL ПЩвдНјаагааЇЕФЦРЙРЃКДІРэв§ЧцзМШЗЕФжЊЕРМЦЫуФкШнЃЌвдМАШчКЮгааЇЕФжДааЃЛ
- зюКѓЃЌЫљгаШЫЖМжЊЕРЕФЃЌаэЖрЙЄОпЖМРэНтSQLЁЃ
вђДЫЃЌЪЙгУSQL ДІРэКЭЗжЮіЪ§ОнСїЃЌПЩвдЮЊИќЖрШЫЬсЙЉСїДІРэММЪѕЁЃДЫЭтЃЌвђЮЊSQL ЕФЩљУїаджЪКЭЧБдкЕФздЖЏгХЛЏЃЌЫќПЩвдДѓДѓМѕЩйЖЈвхИпаЇСїЗжЮігІгУЕФЪБМфКЭОЋСІЁЃ
ЕЋЪЧЃЌSQLЃЈвдМАЙиЯЕЪ§ОнФЃаЭКЭДњЪ§ЃЉВЂВЛЪЧЮЊСїЪ§ОнЩшМЦЕФЁЃЙиЯЕЪЧЃЈЖрЃЉМЏКЯЖјВЛЪЧЮоЯоађСаЕФдЊзщЁЃЕБжДааSQL ВщбЏЪБЃЌДЋЭГЪ§ОнПтЯЕЭГКЭВщбЏв§ЧцЖСШЁКЭДІРэЭъећЕФПЩгУЪ§ОнМЏЃЌВЂВњЩњЙЬЖЈДѓаЁЕФНсЙћЁЃЯрБШжЎЯТЃЌЪ§ОнСїГжајЬсЙЉаТЕФМЧТМЃЌЪЙЪ§ОнЫцзХЪБМфЕНДяЁЃвђДЫЃЌСїВщбЏашвЊВЛЖЯЕФДІРэЕНДяЕФЪ§ОнЃЌДгРДЖМВЛЪЧЁАЭъећЕФЁБЁЃ
ЛАЫфШчДЫЃЌЪЙгУSQL ДІРэСїВЂВЛЪЧВЛПЩФмЕФЁЃвЛаЉЙиЯЕаЭЪ§ОнПтЯЕЭГЮЌЛЄСЫЮяЛЏЪгЭМЃЌРрЫЦгкдкСїЪ§ОнжаЦРЙРSQL ВщбЏЁЃЮяЛЏЪгЭМБЛЖЈвхЮЊвЛИіSQL ВщбЏЃЌОЭЯёГЃЙцЃЈащФтЃЉЪгЭМвЛбљЁЃЕЋЪЧЃЌВщбЏЕФНсЙћЪЕМЪЩЯБЛБЃДцЃЈЛђепЪЧЮяЛЏЃЉдкФкДцЛђгВХЬжаЃЌетбљЪгЭМдкВщбЏЪБВЛашвЊЪЕЪБМЦЫуЁЃЮЊСЫЗРжЙЮяЛЏЪгЭМЕФЪ§ОнЙ§ЪБЃЌЪ§ОнПтЯЕЭГашвЊдкЦфЛљДЁЙиЯЕЃЈЖЈвхЕФSQL ВщбЏв§гУЕФБэЃЉБЛаоИФЪБИќаТИќаТЪгЭМЁЃШчЙћЮвУЧНЋЪгЭМЕФЛљДЁЙиЯЕаоИФЪгзїаоИФСїЃЈЛђепЪЧИќИФШежОСїЃЉЃЌЮяЛЏЪгЭМЕФЮЌЛЄКЭСїжаЕФSQL ЕФЙиЯЕОЭБфЕУКмУїШЗСЫЁЃ
Flink ЕФЙиЯЕAPIЃКTable API КЭSQL
Дг1.1.0АцБОЃЈ2016Фъ8дТЗЂВМЃЉвдРДЃЌFlink ЬсЙЉСЫСНИігявхЯрЕБЕФЙиЯЕAPIЃЌгябдФкЧЖЕФTable APIЃЈгУгкJava КЭScalaЃЉвдМАБъзМSQLЁЃетСНжжAPI БЛЩшМЦгУгкдкЯпСїКЭвХСєЕФХњДІРэЪ§ОнAPI ЕФЭГвЛЃЌетвтЮЖзХЮоТлЪфШыЪЧОВЬЌХњДІРэЪ§ОнЛЙЪЧСїЪ§ОнЃЌВщбЏВњЩњЭъШЋЯрЭЌЕФНсЙћЁЃ
ЭГвЛСїКЭХњДІРэЕФAPI ЗЧГЃживЊЁЃЪзЯШЃЌгУЛЇжЛашвЊбЇЯАвЛИіAPI РДДІРэОВЬЌКЭСїЪ§ОнЁЃДЫЭтЃЌПЩвдЪЙгУЭЌбљЕФВщбЏРДЗжЮіХњДІРэКЭСїЪ§ОнЃЌетбљПЩвддкЭЌвЛИіВщбЏРяУцЭЌЪБЗжЮіРњЪЗКЭдкЯпЪ§ОнЁЃдкФПЧАЕФзДПіЯТЃЌЮвУЧЩаЮДЭъШЋЪЕЯжХњДІРэКЭСїЪНгявхЕФЭГвЛЃЌЕЋЩчЧјдкетИіФПБъЩЯШЁЕУСЫКмДѓЕФНјеЙЁЃ
ЯТУцЕФДњТыЦЌЖЮеЙЪОСЫСНИіЕШаЇЕФTable API КЭSQL ВщбЏЃЌгУРДдкЮТЖШДЋИаЦїВтСПЪ§ОнСїжаМЦЫувЛИіМђЕЅЕФДАПкОлКЯЁЃSQL ВщбЏЕФгяЗЈЛљгкApache Calcite ЕФЗжзщДАПкКЏЪ§бљЪНЃЌВЂНЋдкFlink 1.3.0АцБОжаЕУЕНжЇГжЁЃ
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val tEnv = TableEnvironment.getTableEnvironment(env)
// define a table source to read sensor data (sensorId, time, room, temp)
val sensorTable = ??? // can be a CSV file, Kafka topic, database, or ...
// register the table source
tEnv.registerTableSource("sensors", sensorTable)
// Table API
val tapiResult: Table = tEnv.scan("sensors") // scan sensors table
.window(Tumble over 1.hour on 'rowtime as 'w) // define 1-hour window
.groupBy('w, 'room) // group by window and room
.select('room, 'w.end, 'temp.avg as 'avgTemp) // compute average temperature
// SQL
val sqlResult: Table = tEnv.sql("""
|SELECT room, TUMBLE_END(rowtime, INTERVAL '1' HOUR), AVG(temp) AS avgTemp
|FROM sensors
|GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR), room
|""".stripMargin) |
ОЭЯёФуПДЕНЕФЃЌСНжжAPI вдМАFlink жївЊЕФЕФDataStream КЭDataSet API ЪЧНєУмНсКЯЕФЁЃTable ПЩвдКЭDataSet ЛђDataStream ЯрЛЅзЊЛЛЁЃвђДЫЃЌПЩвдКмМђЕЅЕФШЅЩЈУшвЛИіЭтВПЕФБэЃЌР§ШчЪ§ОнПтЛђепЪЧParquet ЮФМўЃЌЪЙгУTable API ВщбЏзівЛаЉдЄДІРэЃЌНЋНсЙћзЊЛЛЮЊDataSetЃЌВЂЖдЦфдЫааGelly ЭМаЮЫуЗЈЁЃЩЯЪіЪОР§жаЖЈвхЕФВщбЏвВПЩвдЭЈЙ§ИќИФжДааЛЗОГРДДІРэХњСПЪ§ОнЁЃ
дкФкВПЃЌСНжжAPI ЖМБЛзЊЛЛГЩЯрЭЌЕФТпМБэЪОЃЌгЩApache Calcite НјаагХЛЏЃЌВЂБЛБрвыГЩDataStream ЛђЪЧDataSet ГЬађЁЃЪЕМЪЩЯЃЌгХЛЏКЭзЊЛЛГЬађВЂВЛжЊЕРВщбЏЪЧЭЈЙ§Table API ЛЙЪЧSQL РДЖЈвхЕФЁЃШчЙћФуЖдгХЛЏЙ§ГЬЕФЯИНкИааЫШЄЃЌПЩвдПДПДЮвУЧШЅФъЗЂВМЕФвЛЦЊВЉПЭЮФеТЁЃгЩгкTable API КЭSQL дкгявхЗНУцЕШЭЌЃЌжЛЪЧдкбљЪНЩЯгааЉЧјБ№ЃЌдкетЦЊЮФеТжаЕБЮвУЧЬИТлSQL ЪБЮвУЧЭЈГЃв§гУетСНжжAPIЁЃ
дкЕБЧАЕФ1.2.0АцБОжаЃЌFlink ЕФЙиЯЕAPI дкЪ§ОнСїжаЃЌжЇГжгаЯоЕФЙиЯЕВйзїЃЌАќРЈЭЖгАЁЂЙ§ТЫКЭДАПкОлКЯЁЃЫљгажЇГжЕФВйзїгавЛИіЙВЭЌЕуЃЌОЭЪЧЫќУЧгРдЖВЛЛсИќаТвбОВњЩњЕФНсЙћМЧТМЁЃетЖдгкЪБМфМЧТМВйзїЃЌР§ШчЭЖгАКЭЙ§ТЫЯдШЛВЛЪЧЮЪЬтЁЃЕЋЪЧЃЌЫќЛсгАЯьЪеМЏКЭДІРэЖрЬѕМЧТМЕФВйзїЃЌР§ШчДАПкОлКЯЁЃгЩгкВњЩњЕФНсЙћВЛФмБЛИќаТЃЌдкFlink 1.2.0жаЃЌЪфШыЕФМЧТМдкВњЩњНсЙћжЎКѓВЛЕУВЛБЛЖЊЦњЁЃ
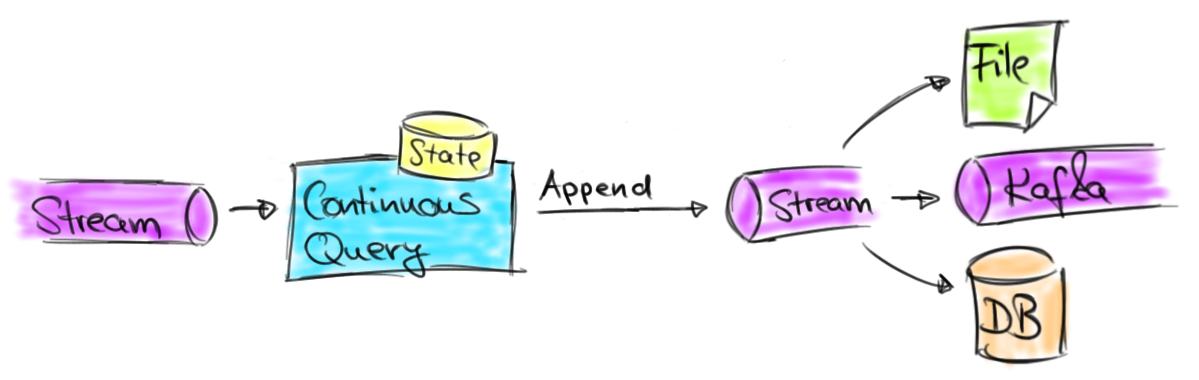
ЕБЧААцБОЕФЯожЦЖдгкНЋВњЩњЕФЪ§ОнЗЂЭљKafka жїЬтЁЂЯћЯЂЖгСаЛђепЪЧЮФМўетаЉДцДЂЯЕЭГЕФгІгУЪЧПЩвдБЛНгЪмЕФЃЌвђЮЊЫќУЧжЛжЇГжзЗМгВйзїЃЌУЛгаИќаТКЭЩОГ§ЁЃзёбетжжФЃЪНЕФГЃМћгУР§ЪЧГжајЕФETL КЭСїДцЕЕгІгУЃЌНЋСїНјааГжОУЛЏДцЕЕЃЌЛђепЪЧзМБИЪ§ОнгУгкНјвЛВНЕФдкЯпЃЈСїЃЉЛђепЪЧРыЯпЗжЮіЁЃгЩгкВЛПЩФмИќаТжЎЧАВњЩњЕФНсЙћЃЌетвЛРргІгУБиаыШЗБЃВњЩњЕФНсЙћЪЧе§ШЗЕФЃЌВЂЧвНЋРДВЛашвЊИќе§ЁЃЯТЭМЫЕУїСЫетбљЕФгІгУЁЃ
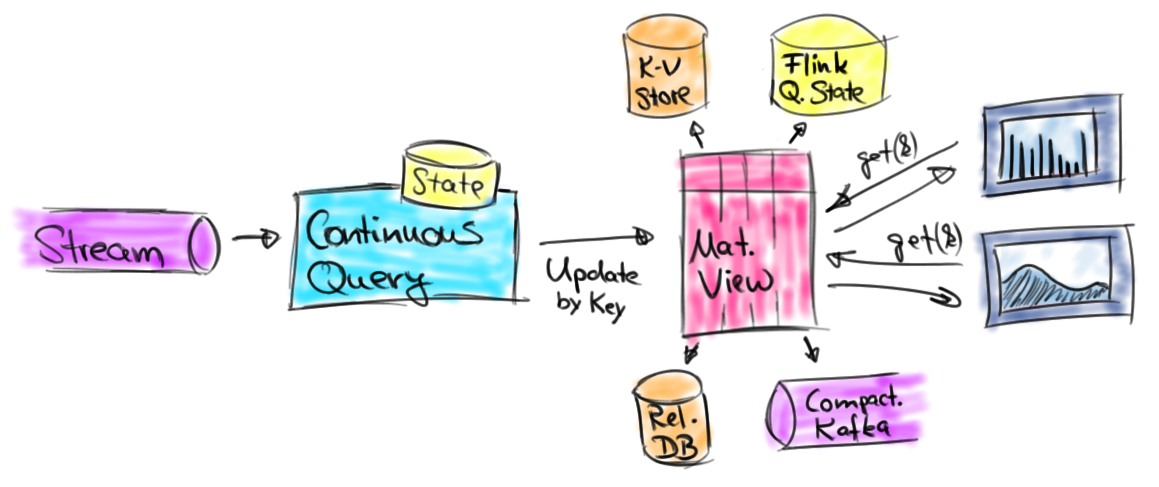
ЫфШЛжЛжЇГжзЗМгВщбЏЖдгааЉРраЭЕФгІгУКЭДцДЂЯЕЭГгагУЃЌЕЋЪЧЛЙЪЧгавЛаЉСїЗжЮіЕФгУР§ашвЊИќаТНсЙћЁЃетаЉСїгІгУАќРЈВЛФмЖЊЦњбгГйЕНДяЕФМЧТМЃЌашвЊдчЦкЕФНсЙћгУгкЃЈГЄЦкдЫааЃЉДАПкОлКЯЃЌЛђепЪЧашвЊЗЧДАПкЕФОлКЯЁЃдкУПжжЧщПіЯТЃЌжЎЧАВњЩњЕФНсЙћМЧТМЖМашвЊБЛИќаТЁЃНсЙћИќаТВщбЏЭЈГЃНЋЦфНсЙћБЃДцдкЭтВПЪ§ОнПтЛђепЪЧМќжЕДцДЂЃЌЪЙЦфПЩвдШУЭтВПгІгУЗУЮЪЛђепЪЧВщбЏЁЃЪЕЯжетжжФЃЪНЕФгІгУгавЧБэАхЁЂБЈИцгІгУЛђепЪЧЦфЫћЕФгІгУЃЌЫќУЧашвЊМАЪБЕФЗУЮЪГжајИќаТЕФНсЙћЁЃЯТЭМЫЕУїСЫетвЛРргІгУЁЃ
ЖЏЬЌБэЕФГжајВщбЏ
жЇГжВщбЏИќаТжЎЧАВњЩњЕФНсЙћЪЧFlink ЕФЙиЯЕAPI ЕФЯТвЛИіживЊВНжшЁЃетИіЙІФмЗЧГЃживЊЃЌвђЮЊЫќДѓДѓдіМгСЫAPI жЇГжЕФгУР§ЕФЗЖЮЇКЭжжРрЁЃДЫЭтЃЌвЛаЉаТЕФгУР§ПЩвдВЩгУDataStream API РДЪЕЯжЁЃ
вђДЫЃЌЕБЬэМгЖдНсЙћИќаТВщбЏЕФжЇГжЪБЃЌЮвУЧБиаыБЃСєжЎЧАЕФСїКЭХњДІРэЪфШыЕФгявхЁЃЮвУЧЭЈЙ§ЖЏЬЌБэЕФИХФюРДЪЕЯжЁЃЖЏЬЌБэЪЧГжајИќаТЃЌВЂЧвФмЙЛЯёГЃЙцЕФОВЬЌБэвЛбљВщбЏЕФБэЁЃЕЋЪЧЃЌгыХњДІРэБэВщбЏжежЙКѓЗЕЛивЛИіОВЬЌБэзїЮЊНсЙћВЛЭЌЕФЪЧЃЌЖЏЬЌБэжаЕФВщбЏЛсГжајдЫааЃЌВЂИљОнЪфШыБэЕФаоИФВњЩњвЛИіГжајИќаТЕФБэЁЃвђДЫЃЌНсЙћБэвВЪЧЖЏЬЌЕФЁЃетИіИХФюЗЧГЃРрЫЦЮвУЧжЎЧАЬжТлЕФЮяЛЏЪгЭМЕФЮЌЛЄЁЃ
МйЩшЮвУЧПЩвддкЖЏЬЌБэжадЫааВщбЏВЂВњЩњвЛИіаТЕФЖЏЬЌБэЃЌФЧЛсДјРДвЛИіЮЪЬтЃЌСїКЭЖЏЬЌБэШчКЮЯрЛЅЙиСЊЃПД№АИЪЧСїКЭЖЏЬЌБэПЩвдЯрЛЅзЊЛЛЁЃЯТЭМеЙЪОСЫдкСїжаДІРэЙиЯЕВщбЏЕФИХФюФЃаЭЁЃ

ЪзЯШЃЌСїБЛзЊЛЛЮЊЖЏЬЌБэЃЌЖЏЬЌБэЪЙгУвЛИіГжајВщбЏНјааВщбЏЃЌВњЩњвЛИіаТЕФЖЏЬЌБэЁЃзюКѓЃЌНсЙћБэБЛзЊЛЛГЩСїЁЃвЊзЂвтЃЌетИіжЛЪЧТпМФЃаЭЃЌВЂВЛвтЮЖзХВщбЏЪЧШчКЮЪЕМЪжДааЕФЁЃЪЕМЪЩЯЃЌГжајВщбЏдкФкВПБЛзЊЛЛГЩДЋЭГЕФDataStream ГЬађЁЃ
ЫцКѓЃЌЮвУЧУшЪіСЫетИіФЃаЭЕФВЛЭЌВНжшЃК
- дкСїжаЖЈвхЖЏЬЌБэ
- ВщбЏЖЏЬЌБэ
- ЩњГЩЖЏЬЌБэ
дкСїжаЖЈвхЖЏЬЌБэ
ЦРЙРЖЏЬЌБэЩЯЕФSQL ВщбЏЕФЕквЛВНЪЧдкСїжаЖЈвхвЛИіЖЏЬЌБэЁЃетвтЮЖзХЮвУЧБиаыжИЖЈСїжаЕФМЧТМШчКЮаоИФЖЏЬЌБэЁЃСїаЏДјЕФМЧТМБиаыОпгагГЩфЕНБэЕФЙиЯЕФЃЪНЕФФЃЪНЁЃдкСїжаЖЈвхЖЏЬЌБэгаСНжжФЃЪНЃКИНМгФЃЪНКЭИќаТФЃЪНЁЃ
дкИНМгФЃЪНжаЃЌСїжаЕФУПЬѕМЧТМЪЧЖдЖЏЬЌБэЕФВхШыаоИФЁЃвђДЫЃЌСїжаЕФЫљгаМЧТМЖМИНМгЕНЖЏЬЌБэжаЃЌЪЙЕУЫќЕФДѓаЁВЛЖЯдіГЄВЂЧвЮоЯоДѓЁЃЯТЭМЫЕУїСЫИНМгФЃЪНЁЃ
дкИќаТФЃЪНжаЃЌСїжаЕФМЧТМПЩвдзїЮЊЖЏЬЌБэЕФВхШыЁЂИќаТЛђепЩОГ§аоИФЃЈИНМгФЃЪНЪЕМЪЩЯЪЧвЛжжЬиЪтЕФИќаТФЃЪНЃЉЁЃЕБдкСїжаЭЈЙ§ИќаТФЃЪНЖЈвхвЛИіЖЏЬЌБэЪБЃЌЮвУЧПЩвддкБэжажИЖЈвЛИіЮЈвЛЕФМќЪєадЁЃдкетжжЧщПіЯТЃЌИќаТКЭЩОГ§ВйзїЛсДјзХМќЪєадвЛЦ№жДааЁЃИќаТФЃЪНШчЯТЭМЫљЪОЁЃ

ВщбЏЖЏЬЌБэ
вЛЕЉЮвУЧЖЈвхСЫЖЏЬЌБэЃЌЮвУЧПЩвддкЩЯУцдЫааВщбЏЁЃгЩгкЖЏЬЌБэЫцзХЪБМфНјааИФБфЃЌЮвУЧБиаыЖЈвхВщбЏЖЏЬЌБэЕФвтвхЁЃМйЖЈЮвУЧгавЛИіЬиЖЈЪБМфЕФЖЏЬЌБэЕФПьееЃЌетИіПьееПЩвдзїЮЊвЛИіБъзМЕФОВЬЌХњДІРэБэЁЃЮвУЧНЋЖЏЬЌБэA дкЕуt ЕФПьееБэЪОЮЊA[t]ЃЌПЩвдЪЙгУШЫвтЕФSQL ВщбЏРДВщбЏПьееЃЌИУВщбЏВњЩњСЫвЛИіБъзМЕФОВЬЌБэзїЮЊНсЙћЃЌЮвУЧАбдкЪБМфt ЖдЖЏЬЌБэA зіЕФВщбЏq ЕФНсЙћБэЪОЮЊq(A[t])ЁЃШчЙћЮвУЧЗДИДдкЖЏЬЌБэЕФПьееЩЯМЦЫуВщбЏНсЙћЃЌвдЛёШЁНјЖШЪБМфЕуЃЌЮвУЧНЋЛёЕУаэЖрОВЬЌНсЙћБэЃЌЫќУЧЫцзХЪБМфЕФЭЦвЦЖјИФБфЃЌВЂЧвгааЇЕФЙЙГЩвЛИіЖЏЬЌБэЁЃЮвУЧдкЖЏЬЌБэЕФВщбЏжаЖЈвхШчЯТгявхЁЃ
ВщбЏq дкЖЏЬЌБэA ЩЯВњЩњСЫвЛИіЖЏЬЌБэRЃЌЫќдкУПИіЪБМфЕуt ЕШМлгкдкA[t]ЩЯжДааq ЕФНсЙћЃЌМДR[t]=q(A[t])ЁЃИУЖЈвхвтЮЖзХдкХњДІРэБэКЭСїБэЩЯжДааЯрЭЌЕФВщбЏq ЛсВњЩњЯрЭЌЕФНсЙћЁЃдкЯТУцЕФР§згжаЃЌЮвУЧИјГіСЫСНИіР§згРДЫЕУїЖЏЬЌБэВщбЏЕФгявхЁЃ
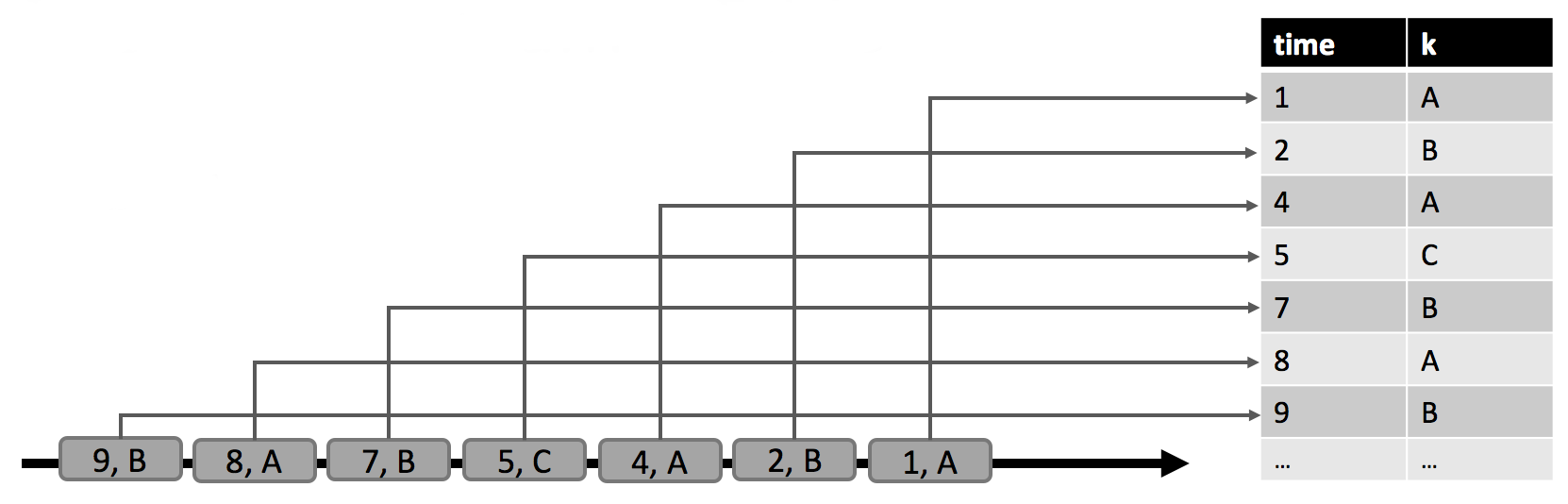
дкЯТЭМжаЃЌЮвУЧПДЕНзѓВрЕФЖЏЬЌЪфШыБэAЃЌЖЈвхГЩзЗМгФЃЪНЁЃдкЪБМфt=8ЪБЃЌA гЩ6ааЃЈБъМЧГЩРЖЩЋЃЉзщГЩЁЃдкЪБМфt=9 КЭt=12 ЪБЃЌгавЛаазЗМгЕНAЃЈЗжБ№гУТЬЩЋКЭГШЩЋБъМЧЃЉЁЃЮвУЧдкБэA ЩЯдЫаавЛИіШчЭМжаМфЫљЪОЕФМђЕЅВщбЏЃЌетИіВщбЏИљОнЪєадk ЗжзщЃЌВЂЭГМЦУПзщЕФМЧТМЪ§ЁЃдкгвВрЮвУЧПДЕНСЫt=8ЃЈРЖЩЋЃЉЃЌt=9ЃЈТЬЩЋЃЉКЭt=12ЃЈГШЩЋЃЉЪБВщбЏq ЕФНсЙћЁЃдкУПИіЪБМфЕуtЃЌНсЙћБэЕШМлгкдкЪБМфt ЪБдйЖЏЬЌБэA ЩЯжДааХњВщбЏЁЃ
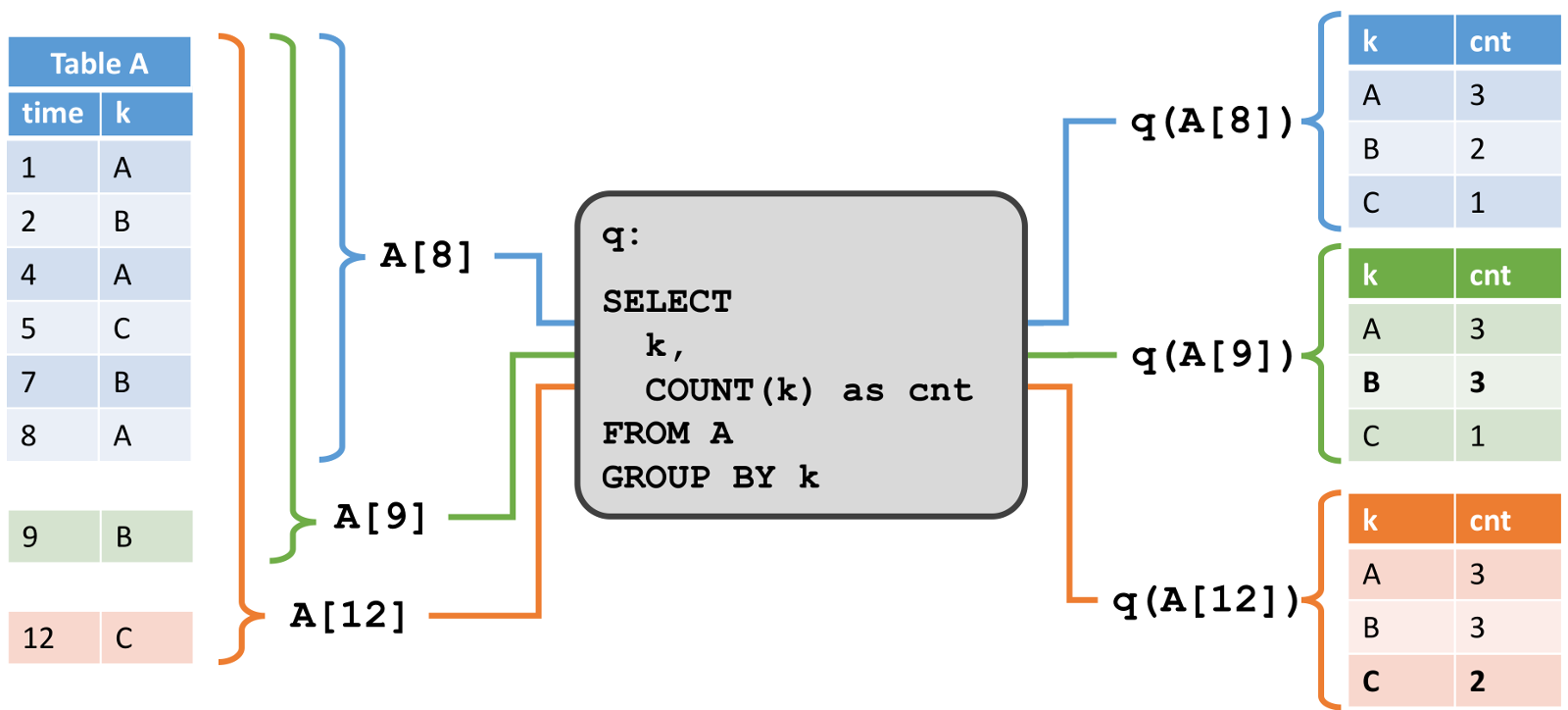
етИіР§згжаЕФВщбЏЪЧвЛИіМђЕЅЕФЗжзщЃЈЕЋЪЧУЛгаДАПкЃЉОлКЯВщбЏЁЃвђДЫЃЌНсЙћБэЕФДѓаЁвРРЕгкЪфШыБэЕФЗжзщМќЕФЪ§СПЁЃДЫЭтЃЌжЕЕУзЂвтЕФЪЧЃЌетИіВщбЏЛсГжајИќаТжЎЧАВњЩњЕФНсЙћааЃЌЖјВЛжЛЪЧЬэМгаТааЁЃ
ЕкЖўИіР§згеЙЪОСЫвЛИіРрЫЦЕФВщбЏЃЌЕЋЪЧгавЛИіКмживЊЕФВювьЁЃГ§СЫЖдЪєадk ЗжзщвдЭтЃЌВщбЏЛЙНЋМЧТМУП5УыжгЗжзщЮЊвЛИіЙіЖЏДАПкЃЌетвтЮЖзХЫќУП5УыжгМЦЫувЛДЮk ЕФзмЪ§ЁЃдйвЛДЮЕФЃЌЮвУЧЪЙгУCalcite ЕФЗжзщДАПкКЏЪ§РДжИЖЈетИіВщбЏЁЃдкЭМЕФзѓВрЃЌЮвУЧПДЕНЪфШыБэA ЃЌвдМАЫќдкИНМгФЃЪНЯТЫцзХЪБМфЖјИФБфЁЃдкгвВрЃЌЮвУЧПДЕННсЙћБэЃЌвдМАЫќЫцзХЪБМфбнБфЁЃ
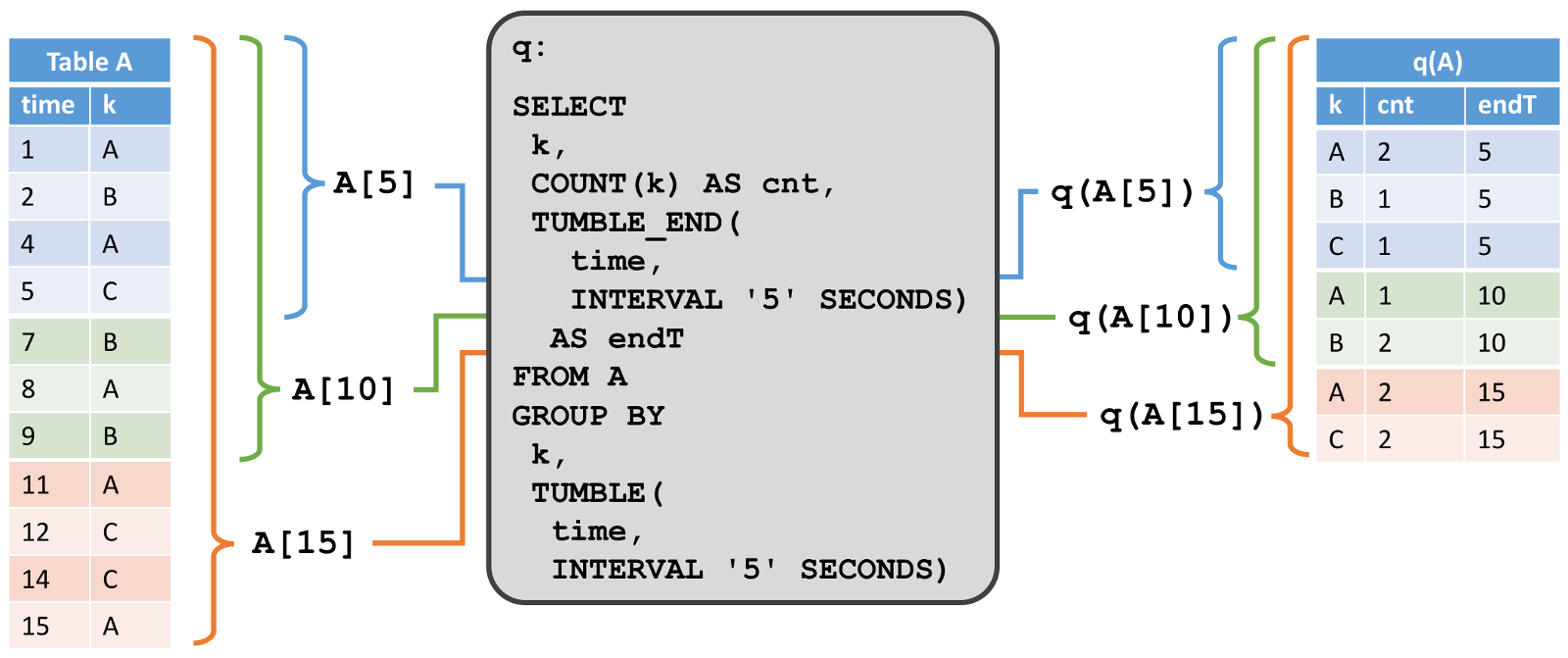
гыЕквЛИіР§згЕФНсЙћВЛЭЌЕФЪЧЃЌетИіНсЙћБэЫцзХЪБМфдіГЄЃЌР§ШчУП5УыжгМЦЫуГіаТЕФНсЙћааЃЈПМТЧЕНЪфШыБэдкЙ§ШЅ5УыЪеЕНИќЖрЕФМЧТМЃЉЁЃЫфШЛЗЧДАПкВщбЏЃЈжївЊЪЧЃЉИќаТНсЙћБэЕФааЃЌЕЋЪЧДАПкОлКЯВщбЏжЛзЗМгаТааЕННсЙћБэжаЁЃ
ЫфШЛетЦЊВЉПЭзЈзЂгкЖЏЬЌБэЕФSQL ВщбЏЕФгявхЃЌЖјВЛЪЧШчКЮгааЇЕФДІРэетбљЕФВщбЏЃЌЕЋЪЧЮвУЧвЊжИГіЕФЪЧЃЌЮоТлЪфШыБэЪВУДЪБКђИќаТЃЌЖМВЛПЩФмМЦЫуВщбЏЕФЭъећНсЙћЁЃЯрЗДЃЌВщбЏБрвыГЩСїгІгУЃЌИљОнЪфШыЕФБфЛЏГжајИќаТЫќЕФНсЙћЁЃетвтЮЖзХВЛЪЧЫљгаЕФгааЇSQL ЖМжЇГжЃЌжЛгаФЧаЉГжајадЕФЁЂЕндіЕФКЭИпаЇМЦЫуЕФБЛжЇГжЁЃЮвУЧМЦЛЎдкКѓајЕФВЉПЭЮФеТжаЬжТлЙигкЦРЙРЖЏЬЌБэЕФSQL ВщбЏЕФЯъЯИФкШнЁЃ
ЩњГЩЖЏЬЌБэ
ВщбЏЖЏЬЌБэЩњГЩЕФЖЏЬЌБэЃЌЦфЯрЕБгкВщбЏНсЙћЁЃИљОнВщбЏКЭЫќЕФЪфШыБэЃЌНсЙћБэЛсЭЈЙ§ВхШыЁЂИќаТКЭЩОГ§ГжајИќИФЃЌОЭЯёЦеЭЈЕФЪ§ОнБэвЛбљЁЃЫќПЩФмЪЧвЛИіВЛЖЯБЛИќаТЕФЕЅааБэЃЌвЛИіжЛВхШыВЛИќаТЕФБэЃЌЛђепНщгкСНепжЎМфЁЃ
ДЋЭГЕФЪ§ОнПтЯЕЭГдкЙЪеЯКЭИДжЦЕФЪБКђЃЌЭЈЙ§ШежОжиНЈБэЁЃгавЛаЉВЛЭЌЕФШежОММЪѕЃЌБШШчUNDOЁЂREDOКЭUNDO/REDOШежОЁЃМђЖјбджЎЃЌUNDO ШежОМЧТМБЛаоИФдЊЫижЎЧАЕФжЕРДЛиЙіВЛЭъећЕФЪТЮёЃЌREDO ШежОМЧТМдЊЫиаоИФЕФаТжЕРДжизівбЭъГЩЪТЮёЖЊЪЇЕФИФБфЃЌUNDO/REDO ШежОЭЌЪБМЧТМСЫБЛаоИФдЊЫиЕФОЩжЕКЭаТжЕРДГЗЯњЮДЭъГЩЕФЪТЮёЃЌВЂжизівбЭъГЩЪТЮёЖЊЪЇЕФИФБфЁЃЛљгкетаЉШежОММЪѕЕФдРэЃЌЖЏЬЌБэПЩвдзЊЛЛГЩСНРрИќИФШежОСїЃКREDO СїКЭREDO+UNDO СїЁЃ
ЭЈЙ§НЋБэжаЕФаоИФзЊЛЛЮЊСїЯћЯЂЃЌЖЏЬЌБэБЛзЊЛЛЮЊredo+undo СїЁЃВхШыаоИФЩњГЩвЛЬѕаТааЕФВхШыЯћЯЂЃЌЩОГ§аоИФЩњГЩвЛЬѕОЩааЕФЩОГ§ЯћЯЂЃЌИќаТаоИФЩњГЩвЛЬѕОЩааЕФЩОГ§ЯћЯЂвдМАвЛЬѕаТааЕФВхШыЯћЯЂЁЃааЮЊШчЯТЭМЫљЪОЁЃ
зѓВрЯдЪОСЫвЛИіЮЌЛЄдкИНМгФЃЪНЯТЕФЖЏЬЌБэЃЌзїЮЊжаМфВщбЏЕФЪфШыЁЃВщбЏЕФНсЙћзЊЛЛЮЊЯдЪОдкЕзВПЕФredo+undo СїЁЃЪфШыБэЕФЕквЛЬѕМЧТМ(1,A)зїЮЊНсЙћБэЕФвЛЬѕаТМЭТМЃЌвђДЫВхШыСЫвЛЬѕЯћЯЂ+(A,1)ЕНСїжаЁЃЕкЖўЬѕЪфШыМЧТМk=ЁЎAЁЏ(4,A)ЕМжТСЫНсЙћБэжа (A,1)МЧТМЕФИќаТЃЌДгЖјВњЩњСЫвЛЬѕЩОГ§ЯћЯЂ-(A,1)КЭвЛЬѕВхШыЯћЯЂ+(A,2)ЁЃЫљгаЕФЯТгЮВйзїЛђЪ§ОнЛузмЖМашвЊФмЙЛе§ШЗДІРэетСНжжРраЭЕФЯћЯЂЁЃ
дкСНжжЧщПіЯТЃЌЖЏЬЌБэЛсзЊЛЛГЩredo СїЃКвЊУДЫќжЛЪЧвЛИіИНМгБэЃЈМДжЛгаВхШыаоИФЃЉЃЌвЊУДЫќгавЛИіЮЈвЛЕФМќЪєадЁЃЖЏЬЌБэЩЯЕФУПвЛИіВхШыаоИФЛсВњЩњвЛЬѕаТааЕФВхШыЯћЯЂЕНredo СїЁЃгЩгкredo СїЕФЯожЦЃЌжЛгаДјгаЮЈвЛМќЕФБэФмЙЛНјааИќаТКЭЩОГ§аоИФЁЃШчЙћвЛИіМќДгЖЏЬЌБэжаЩОГ§ЃЌвЊУДЪЧвђЮЊааБЛЩОГ§ЃЌвЊУДЪЧвђЮЊааЕФМќЪєаджЕБЛаоИФСЫЃЌЫљвдвЛЬѕДјгаБЛвЦГ§МќЕФЩОГ§ЯћЯЂЗЂЫЭЕНredo СїЁЃИќаТаоИФЩњГЩДјгаИќаТЕФИќаТЯћЯЂЃЌБШШчаТааЁЃгЩгкЩОГ§КЭИќаТаоИФИљОнЮЈвЛМќРДЖЈвхЃЌЯТгЮВйзїашвЊФмЙЛИљОнМќРДЗУЮЪжЎЧАЕФжЕЁЃЯТЭМеЙЪОСЫШчКЮНЋЩЯЪіЯрЭЌВщбЏЕФНсЙћБэзЊЛЛЮЊredo СїЁЃ
ВхШыЕНЖЏЬЌБэЕФ(1,A)ВњЩњСЫ+(A,1)ВхШыЯћЯЂЁЃВњЩњИќаТЕФ(4,A)ЩњГЩСЫ*(A,2)ЕФИќаТЯћЯЂЁЃ
Redo СїЕФЭЈГЃзіЗЈЪЧНЋВщбЏНсЙћаДЕННіИНМгЕФДцДЂЯЕЭГЃЌБШШчЙіЖЏЮФМўЛђепKafka жїЬтЃЌЛђепЪЧЛљгкМќЗУЮЪЕФЪ§ОнДцДЂЃЌБШШчCassandraЁЂЙиЯЕаЭDBMSвдМАбЙЫѕЕФKafka жїЬтЁЃЛЙПЩвдЪЕЯжНЋЖЏЬЌБэзїЮЊСїгІгУЕФЙиМќЕФФкЧЖВПЗжЃЌРДЦРМлГжајВщбЏКЭЖдЭтВПЯЕЭГЕФВщбЏФмСІЃЌР§ШчвЛИівЧБэХЬгІгУЁЃ
ЧаЛЛЕНЖЏЬЌБэЗЂЩњЕФИФБф
дк1.2АцБОжаЃЌFlink ЙиЯЕAPI ЕФЫљгаСїВйзїЃЌР§ШчЙ§ТЫКЭЗжзщДАПкОлКЯЃЌжЛЛсВњЩњаТааЃЌВЂЧвВЛФмИќаТЯШЧАЗЂВМЕФНсЙћЁЃ ЯрБШжЎЯТЃЌЖЏЬЌБэФмЙЛДІРэИќаТКЭЩОГ§аоИФЁЃ ЯждкФуПЩФмЛсЮЪздМКЃЌЕБЧААцБОЕФДІРэФЃЪНШчКЮгыаТЕФЖЏЬЌБэФЃаЭЯрЙиЃП API ЕФгявхЛсЭъШЋИФБфЃЌЮвУЧашвЊДгЭЗПЊЪМжиаТЪЕЯжAPIЃЌвдДяЕНЫљашЕФгявхЃП
ЫљгаетаЉЮЪЬтЕФД№АИКмМђЕЅЁЃЕБЧАЕФДІРэФЃаЭЪЧЖЏЬЌБэФЃаЭЕФвЛИізгМЏЁЃ ЪЙгУЮвУЧдкетЦЊЮФеТжаНщЩмЕФЪѕгяЃЌЕБЧАЕФФЃаЭЭЈЙ§ИНМгФЃЪННЋСїзЊЛЛЮЊЖЏЬЌБэЃЌМДвЛИіЮоЯодіГЄЕФБэЁЃ гЩгкЫљгаВйзїНіНгЪмВхШыИќИФВЂдкЦфНсЙћБэЩЯЩњГЩВхШыИќИФЃЈМДЃЌВњЩњаТааЃЉЃЌвђДЫЫљгадкЖЏЬЌИНМгБэЩЯвбОжЇГжЕФВщбЏЃЌНЋЪЙгУжизіФЃаЭзЊЛЛЛиDataStreamsЃЌНігУгкИНМгБэЁЃ вђДЫЃЌЕБЧАФЃаЭЕФгявхБЛаТЕФЖЏЬЌБэФЃаЭЭъШЋИВИЧКЭБЃСєЁЃ
НсТлгыеЙЭћ
Flink ЕФЙиЯЕAPI дкШЮКЮЪБКђЖМЗЧГЃЪЪКЯгУгкСїЗжЮігІгУЃЌВЂдкВЛЭЌЕФЩњВњЛЗОГжаЪЙгУЁЃдкетЦЊВЉЮФжаЃЌЮвУЧЬжТлСЫTable API КЭSQL ЕФЮДРДЁЃ етвЛХЌСІНЋЪЙFlink КЭСїДІРэИќвзгкЗУЮЪЁЃ ДЫЭтЃЌгУгкВщбЏРњЪЗКЭЪЕЪБЪ§ОнЕФЭГвЛгявхвдМАВщбЏКЭЮЌЛЄЖЏЬЌБэЕФИХФюЃЌНЋФмЙЛЯдзХМђЛЏаэЖрСюШЫаЫЗмЕФгУР§КЭгІгУГЬађЕФЪЕЯжЁЃ гЩгкетЦЊЮФеТзЈзЂгкСїКЭЖЏЬЌБэЕФЙиЯЕВщбЏЕФгявхЃЌЮвУЧУЛгаЬжТлВщбЏжДааЕФЯИНкЃЌАќРЈФкВПжДааГЗЯњЃЌДІРэКѓЦкЪТМўЃЌжЇГжНсЙћдЄРРЃЌвдМАБпНчПеМфвЊЧѓЁЃ ЮвУЧМЦЛЎдкЩдКѓЕФЪБМфЕуЗЂВМгаЙиДЫжїЬтЕФКѓајВЉПЭЮФеТЁЃ
НќМИИідТРДЃЌFlink ЩчЧјЕФаэЖрГЩдБвЛжБдкЬжТлКЭЙБЯзЙиЯЕAPIЁЃ ЕНФПЧАЮЊжЙЃЌЮвУЧШЁЕУСЫКмДѓЕФНјВНЁЃ ЫфШЛДѓЖрЪ§ЙЄзїЖМзЈзЂгквдИНМгФЃЪНДІРэСїЃЌЕЋЪЧШеГЬЩЯЕФЯТвЛВНЪЧДІРэЖЏЬЌБэвджЇГжИќаТЦфНсЙћЕФВщбЏЁЃ ШчЙћФњЖдЪЙгУSQLДІРэСїГЬЕФЯыЗЈИаЕНаЫЗмЃЌВЂЯЃЭћЮЊДЫзіГіЙБЯзЃЌЧыЬсЙЉЗДРЁЃЌМгШыгЪМўСаБэжаЕФЬжТлЛђЛёШЁJIRA ЮЪЬтЁЃ |








