| БрМЭЦМі: |
| БОЮФРДздгкinfoq,ЮФжаНЋДгЗжВМЪНМЦЫуЗНЯђЫМПМЃЌДгВЂЗЂЕФНЧЖШНщЩмЪБађЪ§ОнПтШчКЮНЕЕЭЪ§ОнВщбЏЕФбгЪБЁЃ |
|
ЮяСЊЭјСьгђНќЦкШчЛ№ШчнБЃЌЛЅСЊЭјКЭДЋЭГЙЋЫОељЯрВМОжЮяСЊЭјЁЃзїЮЊЮяСЊЭјСьгђЪ§ОнДцДЂЕФЪзбЁЃЌЪБађЪ§ОнПтвВдНРДдНЖрНјШыШЫУЧЕФЪгвАЃЌЖјдчдк2016Фъ7дТЃЌАйЖШдЦдкЦфЬьЙЄЮяСЊЭјЦНЬЈЩЯЗЂВМСЫЙњФкЪзИіЖрзтЛЇЕФЗжВМЪНЪБађЪ§ОнПтВњЦЗTSDBЃЌГЩЮЊжЇГжЦфЗЂеЙжЦдьЃЌНЛЭЈЃЌФмдДЃЌжЧЛлГЧЪаЕШВњвЕСьгђЕФКЫаФВњЦЗЃЌЭЌЪБвВГЩЮЊАйЖШеНТдЗЂеЙВњвЕЮяСЊЭјЕФБъжОадЪТМўЁЃ
ЧАЮФЬсЕНЪ§ОнВщбЏЬиБ№ЪЧДѓЪ§ОнСПЕФОлКЯЗжЮіВщбЏЪЧЪБађЪ§ОнПташвЊНтОіЕФвЛИіжївЊЮЪЬтЃЌжЎЧАЕФЮФеТНщЩмСЫЭЈЙ§дЄДІРэЪ§ОнЕФЗНЗЈЃЌгУПеМфЛЛЪБМфЕФЫМТЗЃЌНЕЕЭСЫДѓЪ§ОнСПОлКЯЗжЮіЕФбгЪБЁЃ
1. ЕЅЛњЪБађЪ§ОнЕФОлКЯМЦЫу
ЮвУЧЯШРДПДПДЕЅЛњЪЧШчКЮжЇГжЕЅОлКЯКЏЪ§ЕФМЦЫуЁЃЕЅЛњОлКЯМЦЫуЗЧГЃМђЕЅЃЌгУЛЇВщбЏЪ§ОнЪБЃЌМЦЫуНкЕуВщбЏЛёШЁЪБМфЗЖЮЇФкЕФЫљгаЪБађЪ§ОнЃЌНкЕуАДееЪБађЪЙгУОлКЯКЏЪ§ЖдЪ§ОнНјааМЦЫуЃЌЩњГЩМЦЫуНсЙћЁЃ
ЗжЮіВщбЏвВОГЃЛсЪЙгУЧЖЬзОлКЯЃЌЧЖЬзОлКЯКЏЪ§ЪЙгУВЛЭЌЕФЪБМфДАПкЃЌФкВПКЏЪ§ЭЈГЃЪЙгУаЁЪБМфДАПкЃЌЭтВПЪЙгУИќДѓЕФЪБМфДАПкЁЃФЧЧЖЬзОлКЯВщбЏдкЕЅЛњШчКЮМЦЫуФиЃПКЭЕЅвЛОлКЯКЏЪ§РрЫЦЃЌЧЖЬзОлКЯКЏЪ§ЕФМЦЫуЪЧдкФкВПОлКЯКЏЪ§МЦЫуЕФНсЙћжЎЩЯЃЌИљОнЪБМфдйДЮМЦЫуЃЌЛёШЁНсЙћЁЃШчЯТЭМВщбЏдТЦНОљЦјЮТзюЕЭЕФвЛжмвдМАЦНОљЦјЮТЁЃзмЬхРДЫЕЃЌЕЅЛњЪБађЪ§ОнЕФЧЖЬзКЭЗЧЧЖЬзОлКЯКЏЪ§ЕФЪЕЯжЙ§ГЬМђЕЅжБНгЃЌКмШнвзРэНтЁЃ
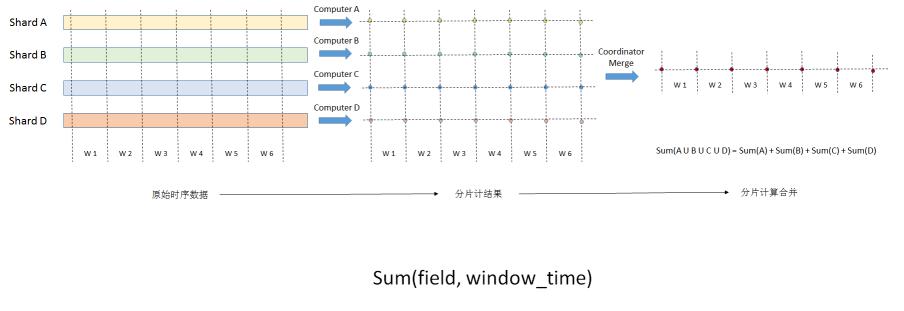
ЕЅЛњМЦЫугаЪВУДЬиеїФиЃПДгЕЅЛњЕФМЦЫуЙ§ГЬЃЌЮвУЧПЩвдПДЕНЕЅЛњашвЊВщбЏЛёШЁЫљгадЪМЪБађЪ§ОнЃЌдЪМЪ§ОнВщбЏЕФIOГЩБОКЭМЦЫуГЩБОЗЧГЃИпЃЌећИіВщбЏЕФбгЪБЛсКмИпЃЌЕЋЪЧОлКЯдЫЫуКѓЕФНсЙћЭљЭљЪ§ОнСПКмЩйЁЃ
2. ЗжВМЪНОлКЯМЦЫу
ЗжВМЪНМЦЫуЪЧвЛжжМЦЫуЗНЗЈЃЌгыжЎЯрЖдЕФЪЧМЏжаЪНМЦЫуЃЌЪЧЭЈЙ§ЪЙгУЖрИіМЦЫузЪдДдкЗжВМЪНЕФЛЗОГжаВЂЗЂжДааМЦЫуЕФЗНЗЈЁЃдкЪБађЪ§ОнПтСьгђЃЌЫцзХЪ§ОнЕФдіГЄЃЌЪБађЪ§ОнЛсдНРДдНЖрЃЌЕЅЛњЕФДцДЂЁЂВщбЏКЭОлКЯЗжЮіIOЪБМфГЩБОЗЧГЃИпЃЌЫфШЛЪЙгУИќМгИпаЇЕФгВМўвВФмЙЛЛКНтЃЌЕЋЪЧгаДІРэЩЯЯоЃЌЛљгкГЩБОЕШвђЫиЕФПМТЧЃЌЗжВМЪНОлКЯВщбЏШдШЛЪЧЪБађЪ§ОнПтздШЛЖјШЛЕФбЁдёЁЃ
ЕБЪБађЪ§ОнПтДцДЂЕФЪ§ОндНРДдНЖрЪБЃЌОлКЯВщбЏВЛПЩБмУтЃЌетвВЪЧOLAPЗжЮіВщбЏжазюГЃМћВйзїжЎвЛЃЌЪЙгУдЄДІРэПЩвдЬсИпВщбЏадФмЃЌЕЋЪЧВЛЙЛСщЛюЁЃЗжВМЪНОлКЯМЦЫудђЪЧФмЙЛЪЙгУЗжВМЪНЕФЬиадЃЌЭЈЙ§ЖрИіМЦЫузЪдДВЂааМЦЫуЃЌдйЖдНсЙћНјааКЯВЂЗЕЛиЃЌЭЈЙ§ВЂЗЂЬсИпОлКЯВщбЏадФмЁЃ
3. ЗжВМЪНЪБађЪ§ОнОлКЯМЦЫу
ЪБађЪ§ОнЕФЗжВМЪНОлКЯМЦЫуашвЊЖрИіНкЕуВЂааМЦЫуЃЌТпМЩЯвВЪЧвЛИіMap/ReduceЕФЙ§ГЬЃЌMapЙ§ГЬашвЊЖддЪМЪБађЪ§ОнНјааЗжЦЌЃЌЗжБ№ОлКЯМЦЫуЁЃReduceЙ§ГЬдђЪЧЖдЖрИіЗжЦЌМЦЫуНсЙћЕФКЯВЂЁЃЭљЭљОлКЯдЫЫуЕФНсЙћКЭдЪМЪ§ОнгазХУїЯдЪ§ОнСПЕФВюОрЃЌЦфДЮЗжВМЪНМЦЫуПЩвдИќЖрЕФПМТЧЪ§ОнЕФБОЕиЛЏЃЌвђДЫЪЙгУЗжВМЪНОлКЯМЦЫуЯдШЛФмЙЛгааЇЬсИпВщбЏадФмЁЃ
ЪБађЪ§ОнвЊНјааЗжВМЪНМЦЫуашвЊНтОіСНИіЛљБОЮЪЬтЃКЪБађЪ§ОнМЦЫуЗжЦЌвдМАМЦЫуНсЙћЕФКЯВЂЁЃ
3.1 ЪБађЪ§ОнМЦЫуЗжЦЌ
ЪБађЪ§ОнОлКЯМЦЫуЕФЗжЦЌПЩвдЗжЮЊМИИіЮЌЖШПМТЧЃКДцДЂЗжЦЌЁЂОлКЯКЏЪ§ЪБМфДАПквдМАВщбЏЬѕМўЁЃ
ЪзЯШЃЌЪБађЪ§ОнОлКЯВщбЏАќКЌЖржжЬѕМўЃЌЖдЪБађЪ§ОнНјааЗжзщОлКЯВщбЏвВЪЧвЛжжГЃгУВщбЏЃЌВЛЭЌЕФЗжзщдЪМЪБађЪ§ОнВЛЭЌЃЌвђДЫПЩвдЭЈЙ§ВщбЏЗжзщЖдЪБађЪ§ОнМЦЫуНјааЗжЦЌЃЌВЛЭЌЕФЗжзщЪЙгУВЛЭЌНкЕуВЂЗЂМЦЫуЁЃ
ЦфДЮЃЌЪБађЪ§ОнОлКЯВщбЏКЏЪ§ЭЈГЃЖМАќКЌЪБМфДАПкЃЌЯрЭЌЪБМфДАПкЕФдЪМЪ§ОнОлКЯМЦЫуЮЊвЛИіЪ§ОнЕуЃЌВЛЭЌЕФЪБМфДАПкгУгкМЦЫуЕФЪБађдЪМЪ§ОнВЛЭЌЃЌвђДЫвВЭЌбљПЩвдЭЈЙ§ЪБМфДАПкЖдЪБађЪ§ОнМЦЫуНјааЪБМфЮЌЖШЕФЗжЦЌЃЌВЛЭЌЕФНкЕуМЦЫуВЛЭЌЪБМфДАПкЕФЪ§ОнЁЃ
ЕкШ§ЃЌАДееДцДЂЗжЦЌНјааМЦЫуЁЃЮвУЧЯШРДЛивфвЛЯТЧАЮФЫЕУшЪіЕФЪБађЪ§ОнЕФДцДЂЃЌЪБађЪ§ОнгЩгкДцДЂЕФЪ§ОнСПКмДѓЃЌЕЅЛњВЂВЛФмТњзуашЧѓЃЌвђДЫашвЊЖдЪБађЪ§ОнНјааЗжЦЌДцДЂЃЌЗжЦЌ(shard)ЭЈГЃЪЙгУmetric+tagsЕФЗНЪННјааЃЌВЛЭЌЕФЗжЦЌДцДЂдкВЛЭЌЕФДцДЂНкЕуЃЌЗжЦЌДцДЂзХдЪМЪБађЪ§ОнЃЌЪЙгУДцДЂЗжЦЌНјааЗжЦЌМЦЫуЃЌвВЪЧвЛжжздШЛЖјШЛЕФбЁдёЁЃШчЯТЭМЯШЖдshardНјааЗжЦЌМЦЫуВщбЏЃЌзюКѓЖдНсЙћНјааКЯВЂЁЃ
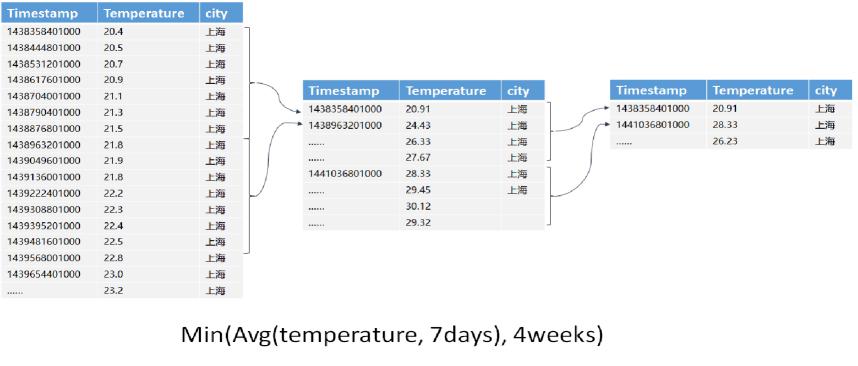
ЪЙгУДцДЂЗжЦЌРДЗжЦЌМЦЫугазХЪВУДгХЪЦФиЃПЯдШЛЃЌЪ§ОнВщбЏКЭМЦЫудкДцДЂЗжЦЌЕФНкЕуЩЯНјааЃЌФмЙЛзюДѓЕФБЃжЄЪ§ОнБОЕиЛЏЃЌФмЙЛгааЇМѕЩйЭјТчЭЈбЖДјРДЕФбгЪБЃЌЪЙЕУБОЕиЪ§ОнМЦЫуИќМгИпаЇЁЃ
ЗжВМЪНОлКЯВщбЏдкЪЕЯжЪБЃЌЭљЭљЖржжМЦЫуЗжЦЌЗНЪНЭЌЪБЪЙгУЃЌОлКЯМЦЫуОЁСПБЃжЄБОЕиЛЏЁЂ ОЁСПЖрЕФВЂЗЂжДааЁЃ
3.2 ЪБађЪ§ОнМЦЫуНсЙћЕФКЯВЂ
ЪБађЪ§ОнОлКЯМЦЫуНсЙћЕФКЯВЂКЭМЦЫуЗжЦЌЕФЗНЪНгаЯрЙиадЃЌВЛЭЌЗжЦЌЗНЪННсЙћЕФКЯВЂЗНЪНвВВЛЭЌЁЃ
ЪзЯШЃЌЖдгкЗжзщОлКЯВщбЏНсЙћЕФКЯВЂРДЫЕЃЌВЛЭЌЕФЗжзщВщбЏНсЙћЪєгкВЛЭЌЕФЗжзщЃЌАДееЗжзщОлКЯВщбЏЬѕМўКЯВЂНсЙћЃЌОЭФмаЮГЩМЦЫуНсЙћЁЃ
ЦфДЮЃЌЖдгкОлКЯКЏЪ§ЪБМфДАПкЗжЦЌВщбЏЕФКЯВЂРДЫЕЃЌВЛЭЌЕФЪБМфДАПкЕФМЦЫуНсЙћЫфШЛЪєгкЭЌвЛИіЗжзщЃЌЕЋЪЧНсЙћдкЪБМфЪЧЩЯгаађЕФЃЌвђДЫжЛашвЊЖдЗжЦЌМЦЫуНсЙћАДееЪБађХХађКЯВЂЃЌОЭФмЛёШЁзюжеМЦЫуНсЙћЁЃ
ЕкШ§ЃЌЖдгкДцДЂЗжЦЌНјааЗжЦЌМЦЫуНсЙћЕФКЯВЂРДЫЕЃЌКЯВЂЯрЖдИДдгЃЌвђЮЊдкЭЌвЛИіЪБМфДАПкФкЃЌПЩФмЛсАќКЌЖрИіЗжЦЌЃЌЖрИіЗжЦЌЩЯЭЌвЛЪБМфДАПкашвЊОлКЯдЫЫуЮЊвЛИіЪ§ОнЕуЁЃОлКЯдЫЫуНсЙћЕФКЯВЂОЭашвЊЗжЮіОлКЯКЏЪ§ЕФЬиадРДНјааЃЌР§ШчдкAКЭBСНИіДцДЂЗжЦЌЕФЭЌвЛЪБМфДАПкФкSUMОлКЯКЏЪ§ЃЌЯдШЛМЦЫуНсЙћПЩвджБНгРлМгSUM(A
U B) = SUM(A) + SUM(B)ЃЌЕЋЪЧВЂВЛЪЧЫљгаЕФОлКЯКЏЪ§ЖМТњзуетвЛЬиадЃЌашвЊИљОнОлКЯКЏЪ§ЕФЬиадзівЛвЛЕФЗжРрЁЃ
ЕБЪЙгУЖржжЗжЦЌЗНЪННјааОлКЯВщбЏЪБЃЌЯргІНсЙћЕФКЯВЂвВЭЌбљИќЮЊИДдгЁЃ
3.3 ЪБађЪ§ОнЧЖЬзОлКЯдЫЫу
ЧЖЬзОлКЯВщбЏвВЪЧЪ§ОнЗжЮіЕФГЃгУЗНЪНЃЌЧЖЬзОлКЯдЫЫуЭљЭљЖрИіОлКЯКЏЪ§ЧЖЬзЖјГЩЃЌУПИіОлКЯКЏЪ§ЕФМЦЫуЪєадВЂВЛЭъШЋЯрЭЌЁЃдкПМТЧМЦЫуЗжЦЌЪБЃЌПЩвдПМТЧНЋЭтВПЧЖЬзКЏЪ§КЭФкВПЧЖЬзКЏЪ§ЗжПЊМЦЫуЃЌбЁдёИќМггаРћЕФЗжЦЌЗНЪНЁЃР§ШчПМТЧ
DIFF(SUM(A, 1day)) ЧЖЬзОлКЯКЏЪ§ЃЈDIFFОлКЯКЏЪ§ЪЧМЦЫуЧАКѓЪБМфађСаНсЙћЕФВюжЕЃЉЃЌМШПЩвдЪЙгУАДееЪБМфДАПкЕФЗНЪНЗжЦЌМЦЫуЃЌвВЭЌбљПЩвдПМТЧНЋ
DIFFЕФМЦЫуКЭSUMЕФМЦЫуВ№ЗжПЊРДЃЌЯШЪЙгУДцДЂЗжЦЌЕФЗНЪНОлКЯМЦЫуSUM(A, 1day)ЕФНсЙћЃЌНсЙћКЯВЂЪБМЦЫуDIFFЧЖЬзОлКЯКЏЪ§ЕФНсЙћЃЌДцДЂЗжЦЌЕФЗжВМЪНМЦЫуФмЙЛГфЗжРћгУЪ§ОнБОЕиЛЏЕФЬиадЃЌвђДЫЪЙгУКѓепЯдШЛИќМгИпаЇЁЃЧЖЬзОлКЯКЏЪ§ЕФЪ§ОнШчКЮЗжЦЌМЦЫуЃЌашвЊИљОнОлКЯКЏЪ§ЬиадвдМАГЁОАОпЬхЗжЮіЃЌетШдШЛЪЧвЛИіашвЊЩюШыПМТЧЕФЮЪЬтЁЃ
3.4 МЦЫуШЮЮёЕФЕїЖШКЭгХЛЏ
ЪБађЪ§ОнЗжВМЪНМЦЫуГ§СЫМЦЫуЗжЦЌКЭЪ§ОнКЯВЂЮЪЬтвдЭтЃЌЭЌбљашвЊДІРэШЮЮёЕїЖШКЭSQLВщбЏгХЛЏЕФЮЪЬтЃЌЯжгаЕФКмЖрПЊдДПђМмSparkЁЂPrestoЁЂMongodbЁЂHiveЖМгаЯргІЕФНтОіЗНАИЃЌетРяОЭВЛзіЩюШыЬжТлСЫЁЃ
4. ЪБађЪ§ОнОлКЯВщбЏЕФФбЬт
ЪБађЪ§ОнЗжВМЪНОлКЯМЦЫуШдШЛгаКмЖрФбЬтЃЌР§ШчCOUNT(DISTINCT FIELD)ЃЌетРрОлКЯКЏЪ§ЕФЬиЕуЪЧдкМЦЫуНсЙћЪБФкВПашвЊБЃДцДѓСПЕФжаМфЪ§ОнгУгкМЦЫу,ашвЊЯћКФДѓСПМЦЫуКЭДцДЂзЪдДЁЃЫфШЛКмЖрДѓЪ§ОнСьгђЗжВМЪНВщбЏв§ЧцЕШЭЈЙ§ЫуЗЈЖМГЂЪдзіСЫВПЗжгХЛЏЃЌЕЋЪЧШдШЛЮДФмЭъШЋНтОіЫљгаЮЪЬтЁЃ
5. змНс
дкЪБађЪ§ОнПтДѓЪ§ОнСПОлКЯЗжЮіВщбЏжаЃЌОлКЯдЫЫужБНггАЯьзХВщбЏадФмЃЌЪЙгУЗжВМЪНМЦЫуЕФЗНЗЈЃЌФмЙЛгааЇЕФЬсИпВщбЏадФм,ЯрБШНЯгкдЄДІРэВщбЏИќМгЕФСщЛюЁЃБОЮФжївЊДгЗжЦЌвдМАШчКЮВЂЗЂЕФНЧЖШзіСЫЬжТлЃЌЕЋЪЧвЛаЉЬиЪтЧЖЬзОлКЯГЁОАЕФгХЛЏШдОЩЪЧашвЊЩюШыЫМПМПЮЬтЁЃ |








