| БрМЭЦМі: |
| БОЮФРДздгкЮЂаХЃЌНщЩмСЫВЩМЏМрПиЪ§ОнЃЌЕїгХММЧЩЃКЕїЖШЦїЃЌraftstoreНјГЬгыapplyНјГЬЃЌRocksDBЃЌХњСПВхШыЁЃ |
|
дкЗжВМЪНЯЕЭГжаНјааЕїгХВЛЪЧПЊЭцаІЕФЪТЧщЁЃЗжВМЪНЯЕЭГжаЕїгХБШЕЅНкЕуЗўЮёЦїЕїгХИДдгЕУЖрЃЌЫќЕФЦПОБПЩФмГіЯждкШЮКЮЕиЗНЃЌЕЅИіНкЕуЩЯЕФЯЕЭГзЪдДЃЌзгзщМўЃЌЛђепНкЕуМфЕФазїЃЌЩѕжСЭјТчДјПэетаЉЖМПЩФмГЩЮЊЦПОБЁЃ
адФмЕїгХОЭЪЧЗЂЯжВЂНтОіетаЉЦПОБЕФЪЕМљЃЌжБЕНЯЕЭГДяЕНзюМбадФмЫЎЦНЁЃЮвЛсдкБОЮФжаЗжЯэШчКЮЖд TiDB ЕФЁАаДШыЁБВйзїНјааЕїгХЃЌЪЙЦфДяЕНзюМбадФмЕФЪЕМљЁЃ
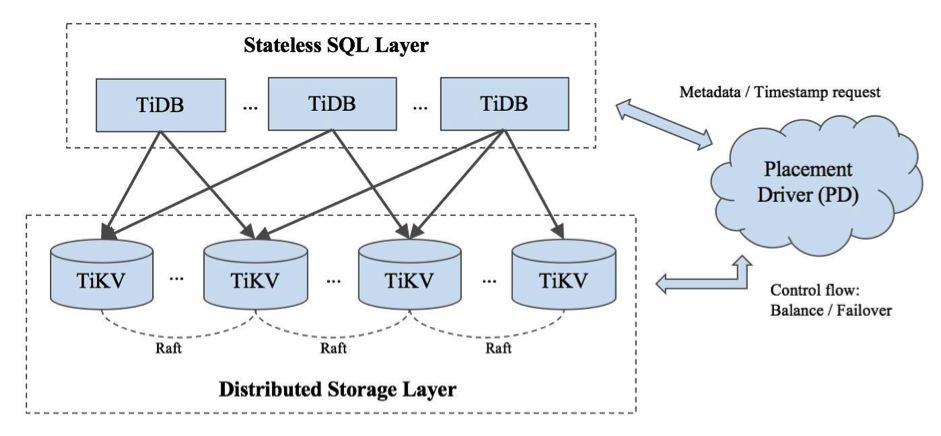
TiDB ЪЧПЊдДЕФЛьКЯЪТЮёДІРэ/ЗжЮіДІРэЃЈHTAPЃЉЕФ NewSQL Ъ§ОнПтЁЃвЛИі TiDB МЏШКгЕгаМИИі
TiDB ЗўЮёЁЂМИИі TiKV ЗўЮёКЭвЛзщ Placement DeiverЃЈPDЃЉЃЈЭЈГЃ 3-5
ИіНкЕуЃЉЁЃ
TiDB ЗўЮёЪЧЮозДЬЌ SQL ВуЃЌTiKV ЗўЮёЪЧМќжЕЖдДцДЂВуЃЌPD дђЪЧЙмРэзщМўЃЌДгЖЅВуЪгНЧИКд№ДцДЂдЊЪ§ОнвдМАИКдиОљКтЁЃЯТУцЪЧвЛИі
TiDB МЏШКЕФМмЙЙЃЌФуПЩвддк TiDB ЙйЗНЮФЕЕжаевЕНУПИізщГЩВПЗжЕФЯъЯИУшЪіЁЃ
ВЩМЏМрПиЪ§Он
Prometheus ЪЧвЛИіПЊдДЕФЯЕЭГМрВтЕФНтОіЗНАИЃЌВЩМЏУПИіФкВПзщМўЕФМрПиЪ§ОнЃЌВЂЖЈЦкЗЂИј Prometheus
ЁЃНшжњПЊдДЕФЪБађЗжЮіЦНЬЈ Grafana ЃЌЮвУЧПЩвдЧсвзЙлВтЕНетаЉЪ§ОнЕФБэЯжЁЃЪЙгУ Ansible
ВПЪ№ TiDB ЪБЃЌPrometheus КЭ Grafana ЪЧФЌШЯАВзАбЁЯюЁЃЭЈЙ§ЙлВьетаЉЪ§ОнЕФБфЛЏЃЌЮвУЧПЩвдПДЕНУПИізщМўЪЧЗёДІгкдЫаазДЬЌЃЌПЩвдЖЈЮЛЦПОБЫљдкЃЌПЩвдЕїећВЮЪ§РДНтОіЮЪЬтЁЃ
ВхШы SQL гяОфЕФаДШыСїЃЈWriteflowЃЉ
МйЩшЮвУЧЪЙгУШчЯТ SQL РДВхШывЛЬѕЪ§ОнЕНБэ t

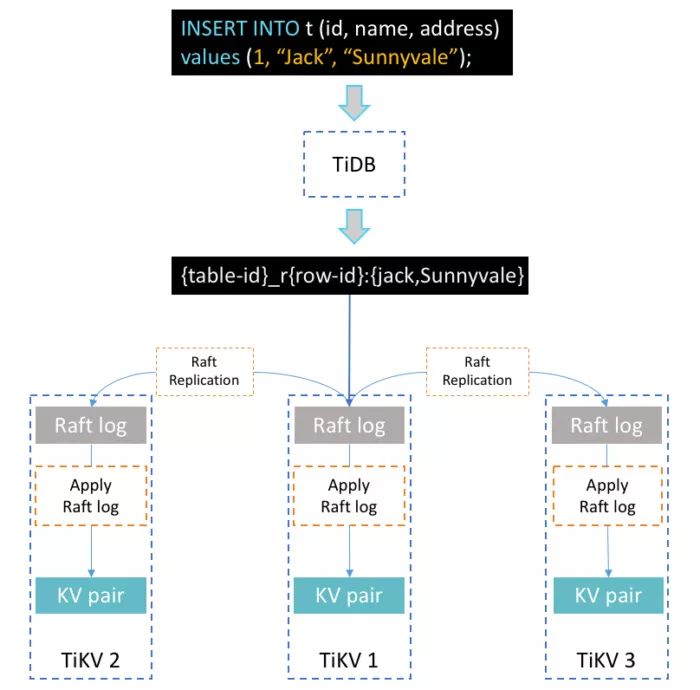
ЩЯУцЪЧвЛИіМђЕЅЖјжБЙлЕФМђЪіЃЌНщЩмСЫ TiDB ШчКЮДІРэ SQL гяОфЁЃTiDB ЗўЮёЦїЪеЕН SQL
гяОфКѓЃЌИљОнЫїв§ЕФБрКХНЋгяОфзЊЛЛЮЊвЛИіЛђЖрИіМќжЕЖд(KV)ЃЌетаЉМќжЕЖдБЛЗЂЫЭЕНЯрЙиСЊЕФ TiKV ЗўЮёЦїЃЌетаЉЗўЮёЦївд
Raft ШежОЕФаЮЪНИДжЦБЃДцЁЃзюКѓЃЌRaf ШежОБЛЬсНЛЃЌетаЉМќжЕЖдЛсБЛаДШыжИЖЈЕФДцДЂв§ЧцЁЃ
дкДЫЙ§ГЬжаЃЌга 3 РрЙиМќЕФЙ§ГЬвЊДІРэЃКзЊЛЛ SQL ЮЊЖрИіМќжЕЖдЁЂRegion ИДжЦКЭЖўНзЖЮЬсНЛЁЃНгЯТРДШУЮвУЧЩюШыЬНЬжИїЯИНкЁЃ
Дг SQL зЊЛЛЮЊМќжЕЖд
гыЦфЫћЪ§ОнПтЯЕЭГВЛЭЌЃЌTiDB жЛДцДЂМќжЕЖдЃЌвдЬсЙЉЮоЯоЕФЫЎЦНПЩЩьЫѕадвдМАЧПДѓЕФвЛжТадЁЃФЧУДвЊШчКЮЪЕЯжжюШчЪ§ОнПтЁЂБэКЭЫїв§ЕШИпВуИХФюФиЃПдк
TiDB жаЃЌУПИіБэЖМгавЛИіЙиСЊЕФШЋОжЮЈвЛБрКХЃЌБЛГЦЮЊ ЁАtable-idЁБЁЃЬиЖЈБэжаЕФЫљгаЪ§ОнЃЈАќРЈМЧТМКЭЫїв§ЃЉЕФМќЖМЪЧвд
8 зжНкЕФ table-id ПЊЭЗЕФЁЃУПИіЫїв§ЖМгавЛИіУћЮЊ ЁАindex-idЁБ ЕФБэЗЖЮЇЕФЮЈвЛБрКХЁЃЯТУцеЙЪОСЫМЧТММќКЭЫїв§МќЕФБрТыЙцдђЁЃ

RegionЃЈЧјгђЃЉЕФИХФю
дк TiDB жаЃЌRegion БэЪОвЛИіСЌајЕФЁЂзѓБегвПЊЕФМќжЕЗЖЮЇ [start_keyЃЌend_keyЃЉЁЃУПИі
Region гаЖрИіИББОЃЌВЂЧвУПИіИББОГЦЮЊвЛИі peer ЁЃУПИі Region вВЙщЪєгкЕЅЖРЕФ Raft
зщЃЌвдШЗБЃЫљга peer жЎМфЕФЪ§ОнвЛжТадЁЃЃЈгаЙиШчКЮдк TiKV жаЪЕЯж Raft вЛжТадЫуЗЈЕФИќЖраХЯЂЃЌЧыВЮдФ
PingCAP НмГіЙЄГЬЪІЬЦСѕЕФЯрЙиВЉЮФЁЃЃЉгЩгкЮвжЎЧАЬсЕНЕФБрТыЙцдђЕФдвђЃЌЭЌвЛБэЕФСйНќМЧТМКмПЩФмЮЛгкЭЌвЛ
Region жаЁЃ
ЕБМЏШКЕквЛДЮГѕЪМЛЏЪБЃЌжЛДцдквЛИі Region ЁЃЕБ Region ДяЕНЬиЖЈДѓаЁЃЈЕБЧАФЌШЯжЕЮЊ96MBЃЉЪБЃЌ
Region НЋЖЏЬЌЗжИюЮЊСНИіСкНќЕФ Region ЃЌВЂздЖЏНЋЪ§ОнЗжВМЕНЯЕЭГжавдЬсЙЉЫЎЦНРЉеЙЁЃ
ЖўНзЖЮЬсНЛ
ЮвУЧЕФЪТЮёДІРэФЃаЭЩшМЦСщИаРДдДгк PercolatorЃЌВЂдкДЫЛљДЁЩЯНјааСЫвЛаЉгХЛЏЁЃМђЕЅЕиЫЕЃЌетЪЧвЛИіЖўНзЖЮЬсНЛавщЃЌМДдЄаДШыКЭЬсНЛЁЃ
УПИізщМўжаЖМгаИќЖрЕФФкШнЃЌЕЋДгКъЙлВуДЮРДРэНтзувдЮЊадФмЕїгХЩшжУГЁОАЁЃЯждкЮвУЧРДЩюШыбаОПЫФжжЕїгХММЪѕЁЃ
ЕїгХММЧЩ #1: ЕїЖШЦї
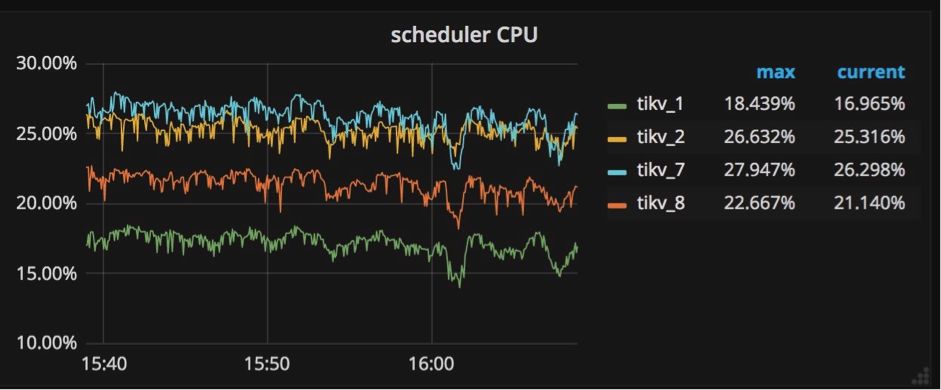
ЫљгааДШыУќСюЖМБЛЗЂЫЭЕНЕїЖШЦїФЃаЭЃЌШЛКѓБЛИДжЦЁЃЕїЖШЦїФЃаЭгЩвЛИіЕїЖШЯпГЬКЭМИИіЙЄзїЯпГЬзщГЩЁЃЮЊЪВУДашвЊЕїЖШЦїФЃаЭЃПдкЯђЪ§ОнПтаДШыЪ§ОнжЎЧАЃЌашвЊМьВщЪЧЗёдЪаэетаЉаДУќСюЃЌвдМАетаЉаДУќСюЪЧЗёТњзуЪТЮёдМЪјЁЃЫљгаетаЉМьВщЙЄзїЖМашвЊДгЕзВуДцДЂв§ЧцЖСШЁаХЯЂЃЌЫќУЧЭЈЙ§ЕїЖШгЩЙЄзїЯпГЬРДНјааДІРэЁЃ
ШчЙћПДЕНЫљгаЙЄзїЯпГЬЕФ CPU ЪЙгУСПзмКЭГЌЙ§ scheduler-worker-pool-size
* 80% ЪБЃЌОЭашвЊЭЈЙ§діМгЕїЖШЙЄзїЯпГЬЕФЪ§РэРДЬсИпадФмЁЃ
ПЩвдЭЈЙ§аоИФХфжУЮФМўжа ЁЎstorageЁЏ НкЕФ ЁЎscheduler-worker-pool-sizeЁЏ
РДИФБфЕїЖШЙЄзїЯпГЬЕФЪ§СПЁЃЖдгк CPU КЫаФЪ§ФПаЁгк 16 ЕФЛњЦїЃЌФЌШЯЧщПіЯТХфжУСЫ 4 ИіЕїЖШЙЄзїЯпГЬЃЌЦфЫќЧщПіЯТФЌШЯжЕЪЧ
8ЁЃВЮдФЯрЙиДњТыВПЗжЃКscheduler-worker-pool-size = 4
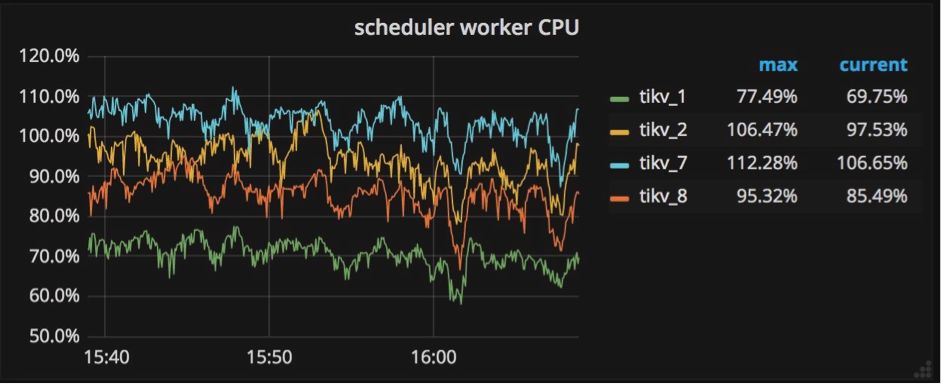
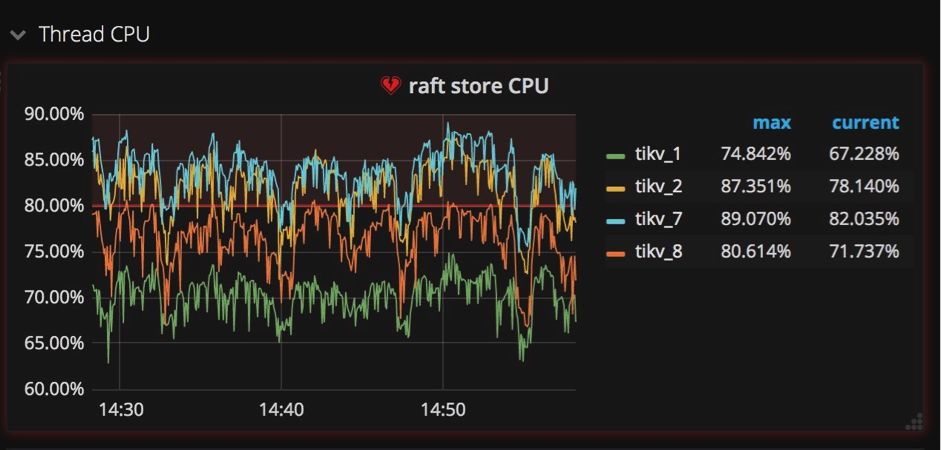
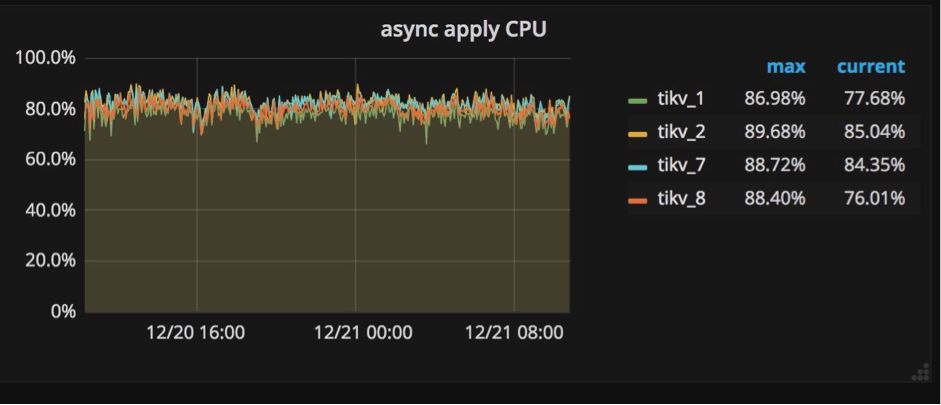
ЕїгХММЧЩ #2ЃКraftstoreНјГЬгыapplyНјГЬ
ЯёЮвЧАБпЬсЕНЕФЃЌЮвУЧдкЖрНкЕужЎМфЪЙгУRaftЪЕЯжЧПвЛжТадЁЃдкНЋвЛИіМќжЕЖдаДШыЪ§ОнПтжЎЧАЃЌетИіМќжЕЖдЪзЯШвЊБЛИДжЦГЩRaft
logИёЪНЃЌЭЌЪБЛЙвЊБЛаДШыИїИіНкЕугВХЬжаБЃДцЁЃдкRaft logБЛЬсНЛКѓЃЌЯрЙиЕФМќжЕЖдВХФмБЛаДШыЪ§ОнПтЁЃ
етбљОЭВњЩњСНжжаДШыВйзїЃКвЛИіЪЧаДRaft logЃЌвЛИіЪЧАбМќжЕЖдаДШыЪ§ОнПтЁЃЮЊСЫдкTiKVжаЖРСЂЕижДааетСНжжВйзїЃЌЮвУЧДДНЈвЛИіraftstoreНјГЬЃЌЫќЕФЙЄзїЪЧРЙНиЫљгаRaftаХЯЂЃЌВЂаДRaft
logЕНгВХЬжаЃЛЭЌЪБЮвУЧДДНЈСэвЛИіНјГЬapply workerЃЌЫќЕФжАд№ЪЧАбМќжЕЖдаДЕНЪ§ОнПтжаЁЃдкGrafanaжаЃЌетСНИіНјГЬЯдЪОдкTiKVУцАхЕФзгУцАхThread
CPUжаЃЈШчЯТЭМЫљЪОЃЉЁЃЫќУЧЖМЪЧМЋЦфживЊЕФаДВйзїИКдиЃЌдкGrafanaжаЮвУЧКмШнвзОЭФмЗЂЯжЫќУЧЯрЕБЗБУІЁЃ
ЮЊЪВУДашвЊЬиБ№ЙизЂетСНИіНјГЬЃПЕБвЛаЉTiKVЗўЮёЦїЕФapplyЛђепraftstoreНјГЬКмЗБУІЃЌЖјСэвЛаЉЛњЦїШДКмПеЯаЕФЪБКђЃЌвВОЭЪЧЫЕаДВйзїИКдиВЛОљКтЕФЪБКђЃЌетаЉБШНЯЗБУІЕФЗўЮёЦїОЭГЩСЫМЏШКжаЕФЦПОБЁЃдьГЩетжжЧщПіЕФвЛжждвђЪЧЪЙгУСЫЕЅЕїЕндіЕФСаЃЌБШШчЪЙгУAUTOINCREMENTжИЖЈжїМќЃЌЛђепдкжЕВЛЖЯдіМгЕФСаЩЯДДНЈЫїв§ЃЌР§ШчзюКѓвЛДЮЗУЮЪЕФЪБМфДСЁЃ
вЊгХЛЏетбљЕФГЁОАВЂЯћГ§ЦПОБЃЌБиаыБмУтдкЕЅЕїдіМгЕФСаЩЯЩшМЦжїМќКЭЫїв§ЁЃ
дкДЋЭГЕЅНкЕуЪ§ОнПтЯЕЭГЩЯЃЌЪЙгУAUTOINCREMENTЙиМќзжПЩвдЮЊЫГађаДШыДјРДМЋДѓКУДІЃЌЕЋЪЧдкЗжВМЪНЪ§ОнПтЯЕЭГжаЃЌЪЙЫљгазщМўЕФИКдиОљКтВХЪЧзюживЊЕФЁЃ
ЕїгХММЧЩЃЃ3ЃКRocksDB
RocksDB ЪЧвЛИіИпадФмЃЌгаДѓСПЬиадЕФгРОУад KV ДцДЂЁЃ TiKV ЪЙгУ RocksDB зїЮЊЕзВуДцДЂв§ЧцЃЌКЭЦфЫћжюЖрЙІФмЃЌБШШчСазхЁЂЗЖЮЇЩОГ§ЁЂЧАзКЫїв§ЁЂmemtable
ЧАзКВМТЁЙ§ТЫЦїЃЌsst гУЛЇЖЈвхЪєадЕШЕШЁЃ RocksDB ЬсЙЉЯъЯИЕФадФмЕїгХЮФЕЕЁЃ
УПИі TiKV ЗўЮёЦїЯТУцЖМгаСНИі RocksDB ЪЕР§ЃКвЛИіДцДЂЪ§ОнЃЌЮвУЧГЦжЎЮЊ kv-engine
ЃЌСэвЛИіДцДЂ Raft ШежОЃЌЮвУЧГЦжЎЮЊ raft-engine ЁЃkv-engine га4ИіСазхЃКЁАdefaultЁБ
ЁЂЁАlockЁБЁЂ ЁАwriteЁБ КЭ ЁАraftЁБ ЁЃДѓЖрЪ§МЧТМДцДЂдк ЁАdefaultЁБ СазхжаЃЌЫљгаЫїв§ЖМДцДЂдк
ЁАwriteЁБ СазхжаЁЃ
ФуПЩвдЭЈЙ§аоИФХфжУЮФМўЙиСЊВПЗжжаЕФ block-cache-size жЕРДЕїећетСНИі RocksDB
ЪЕР§ЃЌвдЪЕЯжзюМбадФмЁЃЯрЙиВПЗжЪЧЃК [rocksdb.defaultcf] block-cache-size
= ЁА1GBЁБ КЭ [rocksdb.writecf] block-cache-size = ЁА1GBЁБ
ЮвУЧЕїећ block-cache-size ЕФдвђЪЧвђЮЊ TiKV ЗўЮёЦїЦЕЗБЕиДгЁАwriteЁБ СазхжаЖСШЁЪ§ОнвдМьВщВхШыЪБЪЧЗёТњзуЪТЮёдМЪјЃЌЫљвдЮЊ
ЁАwriteЁБ СазхЕФПщЛКДцЩшжУКЯЪЪЕФДѓаЁЗЧГЃживЊЁЃЕБ ЁАwriteЁБ СазхЕФ block-cache
УќжаТЪЕЭгк 90ЃЅ ЪБЃЌгІИУдіМг ЁАwriteЁБ СазхЕФ block-cache-size ДѓаЁЁЃ
ЁАwriteЁБСазхЕФ block-cache-size ЕФФЌШЯжЕЮЊзмФкДцЕФ 15ЃЅ ЃЌЖј ЁАdefaultЁБ
СазхЕФФЌШЯжЕЮЊ 25ЃЅ ЁЃР§ШчЃЌШчЙћЮвУЧдк 32GB ФкДцЕФЛњЦїЩЯВПЪ№ TiKV НкЕуЃЌФЧУДЖдгк ЁАdefaultЁБ
СазхЃЌ ЁАwriteЁБ СазхЕФ block-cache-size ЕФжЕдМЮЊ 4.8GB ЕН 8GB
ЁЃ
дкЗБжиЕФаДШыЙЄзїСПжаЃЌ ЁАdefaultЁБ СазхжаЕФЪ§ОнКмЩйБЛЗУЮЪЃЌЫљвдЕБЮвУЧШЗЖЈ ЁАwriteЁБ
СазхЕФЛКДцУќжаТЪЕЭгк 90ЃЅЃЈР§Шч50ЃЅЃЉЪБЃЌЮвУЧжЊЕР ЁАwriteЁБ СазхДѓдМЪЧФЌШЯ 4.8 GBЕФСНБЖЁЃ
ЮЊСЫЕїгХвдЛёЕУИќКУЕФадФмЃЌЮвУЧПЩвдУїШЗЕиНЋ ЁАwriteЁБ СазхЕФ block-cache-size
ЩшжУЮЊ 9GB ЁЃЕЋЪЧЃЌЮвУЧЛЙашвЊНЋ ЁАdefaultЁБ СазхЕФ block-cache-size
ДѓаЁМѕЩйЕН 4GB ЃЌвдБмУт OOMЃЈФкДцВЛзуЃЉЗчЯеЁЃФуПЩвддк Grafana ЕФ ЁАRocksDB-kvЁБ
УцАхжаевЕН RocksDB ЕФЯъЯИЭГМЦаХЯЂЃЌвдАяжњНјааЕїгХЁЃ
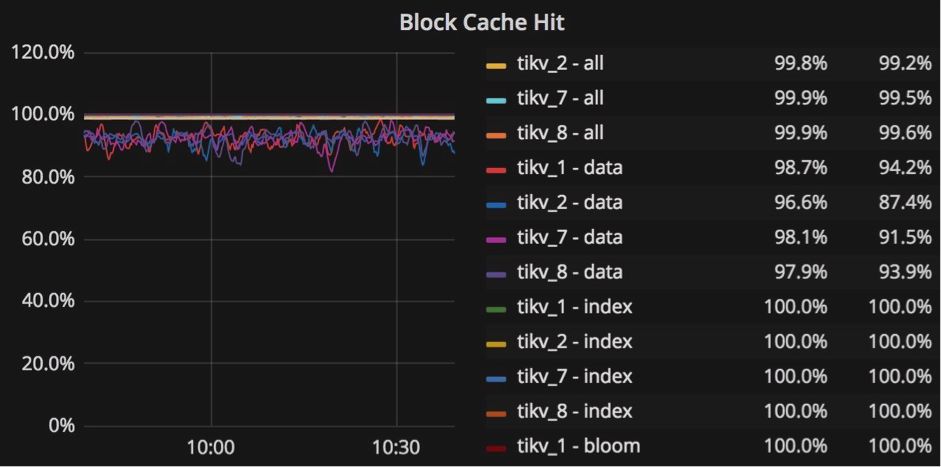
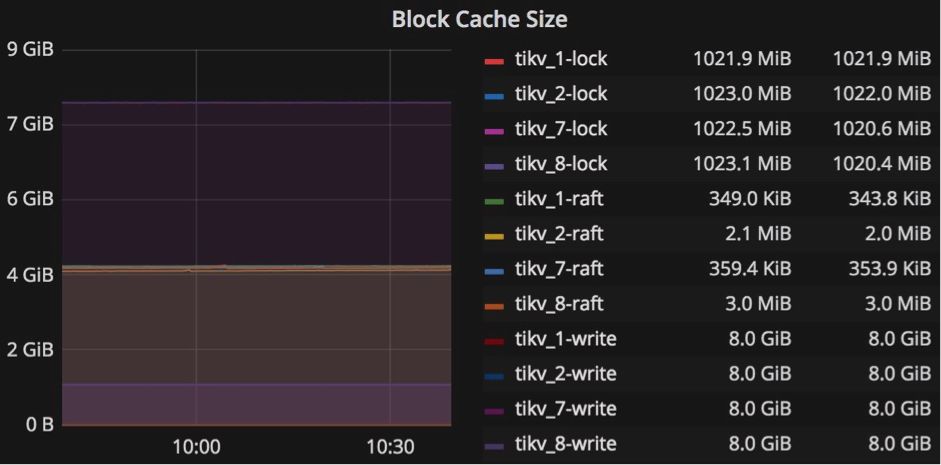
RocksDB-kv УцАх
ЕїгХММЧЩ#4: ХњСПВхШы
ЪЙгУХњСПВхШыПЩвдЪЕЯжИќКУЕФаДШыадФмЁЃДг TiDB ЗўЮёЦїЕФНЧЖШРДПДЃЌХњСПВхШыВЛНіПЩвдМѕЩйПЭЛЇЖЫгы
TiDB ЗўЮёЦїжЎМфЕФ RPC бгГйЃЌЛЙПЩвдМѕЩй SQL НтЮіЪБМфЁЃдк TiKV ФкВПЃЌХњСПВхШыПЩвдЭЈЙ§НЋЖрИіМЧТМКЯВЂЕНвЛИі
Raft ШежОЬѕФПжаРДМѕЩй Raft аХЯЂЕФзмЪ§СПЁЃ
ИљОнЮвУЧЕФОбщЃЌНЈвщНЋХњСПДѓаЁБЃГждк 50?100 аажЎФкЁЃЕБвЛИіБэжагаГЌЙ§ 10 ИіЫїв§ЪБЃЌгІМѕЩйХњСПДІРэЕФДѓаЁЃЌвђЮЊАДееЩЯЪіБрТыЙцдђЃЌВхШывЛааРрЫЦЪ§ОнНЋДДНЈГЌЙ§
10 ИіМќжЕЖдЁЃ
змНс
ЮвЯЃЭћБОЮФФмЙЛдкЪЙгУ TiDB ЪБАяжњФуСЫНтвЛаЉГЃМћЕФЦПОБзДПіЃЌвдМАШчКЮЕїгХетаЉЮЪЬтЃЌвдБудкЁАаДШыЁБЙ§ГЬжаЪЕЯжзюгХадФмЁЃзлЩЯЫљЪіЃК
1.ВЛвЊШУвЛаЉ TiKV НкЕуДІРэДѓВПЗжЁАаДШыЁБЙЄзїИКдиЃЌБмУтдкЕЅЕїдіМгЕФСаЩЯЩшМЦжїМќКЭЫїв§ЁЃ
2.ЕБ TiKV ЕїЖШФЃаЭжаЕФЕїЖШЦїЕФзм CPU ЪЙгУТЪГЌЙ§ scheduler-worker-pool-size*80ЃЅ
ЪБЃЌЧыдіМг scheduler-worker-pool-size ЕФжЕЁЃ
3.ЕБаДШыШЮЮёЦЕЗБЖСШЁ'write'СазхВЂЧвПщЛКДцУќжаТЪЕЭгк 90ЃЅ
ЪБЃЌдк RocksDB жадіМг block-cache-size ЕФжЕЁЃ
4.ЪЙгУХњСПВхШыРДЬсИпЁАаДШыЁБВйзїЕФадФмЁЃ | 







