| БрМЭЦМі: |
| БОЮФРДздгкcsdn,НщЩмСЫПтЗжБэЃЌЖЉЕЅIDЃЌзюжевЛжТадЃЌЪ§ОнПтИпПЩгУЃЌЪ§ОнЗжМЖЃЌДжЯИЙмЕРЕФжЊЪЖЁЃ |
|
вЛЁЂПтЗжБэ
дкredisЃЌmemcachedЕШЛКДцЯЕЭГЪЂааЕФЛЅСЊЭјЪБДњЃЌЙЙНЈвЛИіжЇГХУПУыЪЎЭђжЛЖСЕФЯЕЭГВЂВЛИДдгЃЌЮоЗЧЪЧЭЈЙ§вЛжТадЙўЯЃРЉеЙЛКДцНкЕуЃЌЫЎЦНРЉеЙwebЗўЮёЦїЕШЁЃжЇИЖЯЕЭГвЊДІРэУПУыЪЎЭђБЪЖЉЕЅЃЌашвЊЕФЪЧУПУыЪ§ЪЎЭђЕФЪ§ОнПтИќаТВйзїЃЈinsertМгupdateЃЉЃЌетдкШЮКЮвЛИіЖРСЂЪ§ОнПтЩЯЖМЪЧВЛПЩФмЭъГЩЕФШЮЮёЃЌЫљвдЮвУЧЪзЯШвЊзіЕФЪЧЖдЖЉЕЅБэЃЈМђГЦorderЃЉНјааЗжПтгыЗжБэЁЃ
дкНјааЪ§ОнПтВйзїЪБЃЌвЛАуЖМЛсгагУЛЇIDЃЈМђГЦuidЃЉзжЖЮЃЌЫљвдЮвУЧбЁдёвдuidНјааЗжПтЗжБэЁЃ
ЗжПтВпТдЮвУЧбЁдёСЫЁАЖўВцЪїЗжПтЁБЃЌЫљЮНЁАЖўВцЪїЗжПтЁБжИЕФЪЧЃКЮвУЧдкНјааЪ§ОнПтРЉШнЪБЃЌЖМЪЧвд2ЕФБЖЪ§НјааРЉШнЁЃБШШчЃК1ЬЈРЉШнЕН2ЬЈЃЌ2ЬЈРЉШнЕН4ЬЈЃЌ4ЬЈРЉШнЕН8ЬЈЃЌвдДЫРрЭЦЁЃетжжЗжПтЗНЪНЕФКУДІЪЧЃЌЮвУЧдкНјааРЉШнЪБЃЌжЛашDBAНјааБэМЖЕФЪ§ОнЭЌВНЃЌЖјВЛашвЊздМКаДНХБОНјааааМЖЪ§ОнЭЌВНЁЃ
ЙтЪЧгаЗжПтЪЧВЛЙЛЕФЃЌОЙ§ГжајбЙСІВтЪдЮвУЧЗЂЯжЃЌдкЭЌвЛЪ§ОнПтжаЃЌЖдЖрИіБэНјааВЂЗЂИќаТЕФаЇТЪвЊдЖдЖДѓгкЖдвЛИіБэНјааВЂЗЂИќаТЃЌЫљвдЮвУЧдкУПИіЗжПтжаЖМНЋorderБэВ№ЗжГЩ10ЗнЃКorder_0ЃЌorder_1ЃЌЁ.ЃЌorder_9ЁЃ
зюКѓЮвУЧАбorderБэЗХдкСЫ8ИіЗжПтжаЃЈБрКХ1ЕН8ЃЌЗжБ№ЖдгІDB1ЕНDB8ЃЉЃЌУПИіЗжПтжа10ИіЗжБэЃЈБрКХ0ЕН9ЃЌЗжБ№ЖдгІorder_0ЕНorder_9ЃЉЃЌВПЪ№НсЙЙШчЯТЭМЫљЪОЃК
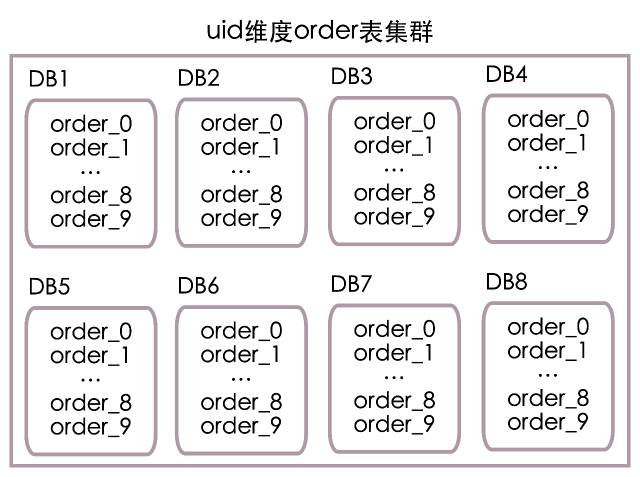
ИљОнuidМЦЫуЪ§ОнПтБрКХЃК
Ъ§ОнПтБрКХ = (uid / 10) % 8 + 1
ИљОнuidМЦЫуБэБрКХЃК
БэБрКХ = uid % 10
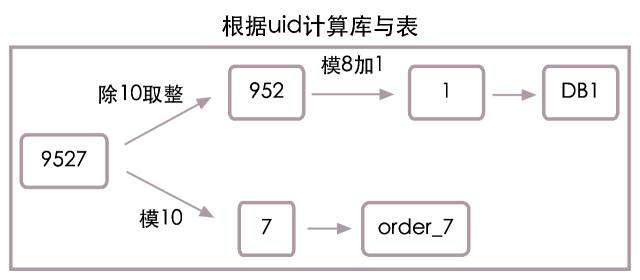
ЕБuid=9527ЪБЃЌИљОнЩЯУцЕФЫуЗЈЃЌЦфЪЕЪЧАбuidЗжГЩСЫСНВПЗж952КЭ7ЃЌЦфжа952ФЃ8Мг1ЕШгк1ЮЊЪ§ОнПтБрКХЃЌЖј7дђЮЊБэБрКХЁЃЫљвдuid=9527ЕФЖЉЕЅаХЯЂашвЊШЅDB1ПтжаЕФorder_7БэВщевЁЃОпЬхЫуЗЈСїГЬвВПЩВЮМћЯТЭМЃК
гаСЫЗжПтЗжБэЕФНсЙЙгыЫуЗЈзюКѓОЭЪЧбАевЗжПтЗжБэЕФЪЕЯжЙЄОпЃЌФПЧАЪаУцЩЯдМгаСНжжРраЭЕФЗжПтЗжБэЙЄОпЃК
1.ПЭЛЇЖЫЗжПтЗжБэЃЌдкПЭЛЇЖЫЭъГЩЗжПтЗжБэВйзїЃЌжБСЌЪ§ОнПт
2.ЪЙгУЗжПтЗжБэжаМфМўЃЌПЭЛЇЖЫСЌЗжПтЗжБэжаМфМўЃЌгЩжаМфМўЭъГЩЗжПтЗжБэВйзї
етСНжжРраЭЕФЙЄОпЪаУцЩЯЖМгаЃЌетРяВЛвЛвЛСаОйЃЌзмЕФРДПДетСНРрЙЄОпИїгаРћБзЁЃПЭЛЇЖЫЗжПтЗжБэгЩгкжБСЌЪ§ОнПтЃЌЫљвдадФмБШЪЙгУЗжПтЗжБэжаМфМўИп15%ЕН20%ЁЃЖјЪЙгУЗжПтЗжБэжаМфМўгЩгкНјааСЫЭГвЛЕФжаМфМўЙмРэЃЌНЋЗжПтЗжБэВйзїКЭПЭЛЇЖЫИєРыЃЌФЃПщЛЎЗжИќМгЧхЮњЃЌБугкDBAНјааЭГвЛЙмРэЁЃ
ЮвУЧбЁдёЕФЪЧдкПЭЛЇЖЫЗжПтЗжБэЃЌвђЮЊЮвУЧздМКПЊЗЂВЂПЊдДСЫвЛЬзЪ§ОнВуЗУЮЪПђМмЃЌЫќЕФДњКХНаЁАУЂЙћЁБЃЌУЂЙћПђМмдЩњжЇГжЗжПтЗжБэЙІФмЃЌВЂЧвХфжУЦ№РДЗЧГЃМђЕЅЁЃ
УЂЙћжївГЃКmango.jfaster.org
УЂЙћдДТыЃКgithub.com/jfaster/mango
ЖўЁЂЖЉЕЅID
ЖЉЕЅЯЕЭГЕФIDБиаыОпгаШЋОжЮЈвЛЕФЬиеїЃЌзюМђЕЅЕФЗНЪНЪЧРћгУЪ§ОнПтЕФађСаЃЌУПВйзївЛДЮОЭФмЛёЕУвЛИіШЋОжЮЈвЛЕФзддіIDЃЌШчЙћвЊжЇГжУПУыДІРэ10ЭђЖЉЕЅЃЌФЧУПУыНЋжСЩйашвЊЩњГЩ10ЭђИіЖЉЕЅIDЃЌЭЈЙ§Ъ§ОнПтЩњГЩзддіIDЯдШЛЮоЗЈЭъГЩЩЯЪівЊЧѓЁЃЫљвдЮвУЧжЛФмЭЈЙ§ФкДцМЦЫуЛёЕУШЋОжЮЈвЛЕФЖЉЕЅIDЁЃ
JAVAСьгђзюжјУћЕФЮЈвЛIDгІИУЫуЪЧUUIDСЫЃЌВЛЙ§UUIDЬЋГЄЖјЧвАќКЌзжФИЃЌВЛЪЪКЯзїЮЊЖЉЕЅIDЁЃЭЈЙ§ЗДИДБШНЯгыЩИбЁЃЌЮвУЧНшМјСЫTwitterЕФSnowflakeЫуЗЈЃЌЪЕЯжСЫШЋОжЮЈвЛIDЁЃЯТУцЪЧЖЉЕЅIDЕФМђЛЏНсЙЙЭМЃК

ЩЯЭМЗжЮЊ3ИіВПЗжЃК
ЪБМфДС
етРяЪБМфДСЕФСЃЖШЪЧКСУыМЖЃЌЩњГЩЖЉЕЅIDЪБЃЌЪЙгУSystem.currentTimeMillis()зїЮЊЪБМфДСЁЃ
ЛњЦїКХ
УПИіЖЉЕЅЗўЮёЦїЖМНЋБЛЗжХфвЛИіЮЈвЛЕФБрКХЃЌЩњГЩЖЉЕЅIDЪБЃЌжБНгЪЙгУИУЮЈвЛБрКХзїЮЊЛњЦїКХМДПЩЁЃ
зддіађКХ
ЕБдкЭЌвЛЗўЮёЦїЕФЭЌвЛКСУыжагаЖрИіЩњГЩЖЉЕЅIDЕФЧыЧѓЪБЃЌЛсдкЕБЧАКСУыЯТзддіДЫађКХЃЌЯТвЛИіКСУыДЫађКХМЬајДг0ПЊЪМЁЃБШШчдкЭЌвЛЗўЮёЦїЭЌвЛКСУыга3ИіЩњГЩЖЉЕЅIDЕФЧыЧѓЃЌет3ИіЖЉЕЅIDЕФзддіађКХВПЗжНЋЗжБ№ЪЧ0ЃЌ1ЃЌ2ЁЃ
ЩЯУц3ИіВПЗжзщКЯЃЌЮвУЧОЭФмПьЫйЩњГЩШЋОжЮЈвЛЕФЖЉЕЅIDЁЃВЛЙ§ЙтШЋОжЮЈвЛЛЙВЛЙЛЃЌКмЖрЪБКђЮвУЧЛсжЛИљОнЖЉЕЅIDжБНгВщбЏЖЉЕЅаХЯЂЃЌетЪБгЩгкУЛгаuidЃЌЮвУЧВЛжЊЕРШЅФФИіЗжПтЕФЗжБэжаВщбЏЃЌБщРњЫљгаЕФПтЕФЫљгаБэЃПетЯдШЛВЛааЁЃЫљвдЮвУЧашвЊНЋЗжПтЗжБэЕФаХЯЂЬэМгЕНЖЉЕЅIDЩЯЃЌЯТУцЪЧДјЗжПтЗжБэаХЯЂЕФЖЉЕЅIDМђЛЏНсЙЙЭМЃК
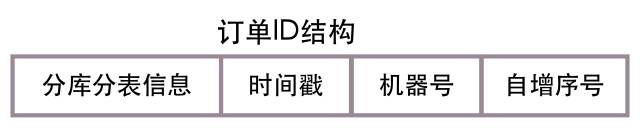
ЮвУЧдкЩњГЩЕФШЋОжЖЉЕЅIDЭЗВПЬэМгСЫЗжПтгыЗжБэЕФаХЯЂЃЌетбљжЛИљОнЖЉЕЅIDЃЌЮвУЧвВФмПьЫйЕФВщбЏЕНЖдгІЕФЖЉЕЅаХЯЂЁЃ
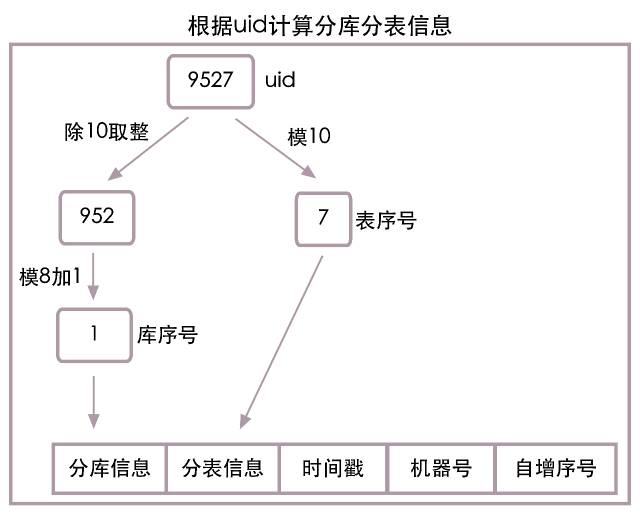
ЗжПтЗжБэаХЯЂОпЬхАќКЌФФаЉФкШнЃПЕквЛВПЗжгаЬжТлЕНЃЌЮвУЧНЋЖЉЕЅБэАДuidЮЌЖШВ№ЗжГЩСЫ8ИіЪ§ОнПтЃЌУПИіЪ§ОнПт10еХБэЃЌзюМђЕЅЕФЗжПтЗжБэаХЯЂжЛашвЛИіГЄЖШЮЊ2ЕФзжЗћДЎМДПЩДцДЂЃЌЕк1ЮЛДцЪ§ОнПтБрКХЃЌШЁжЕЗЖЮЇ1ЕН8ЃЌЕк2ЮЛДцБэБрКХЃЌШЁжЕЗЖЮЇ0ЕН9ЁЃ
ЛЙЪЧАДееЕквЛВПЗжИљОнuidМЦЫуЪ§ОнПтБрКХКЭБэБрКХЕФЫуЗЈЃЌЕБuidЃН9527ЪБЃЌЗжПтаХЯЂЃН1ЃЌЗжБэаХЯЂЃН7ЃЌНЋЫћУЧНјаазщКЯЃЌСНЮЛЕФЗжПтЗжБэаХЯЂМДЮЊЁБ17ЁБЁЃОпЬхЫуЗЈСїГЬВЮМћЯТЭМЃК
ЩЯЪіЪЙгУБэБрКХзїЮЊЗжБэаХЯЂУЛгаШЮКЮЮЪЬтЃЌЕЋЪЙгУЪ§ОнПтБрКХзїЮЊЗжПтаХЯЂШДДцдквўЛМЃЌПМТЧЮДРДЕФРЉШнашЧѓЃЌЮвУЧашвЊНЋ8ПтРЉШнЕН16ПтЃЌетЪБШЁжЕЗЖЮЇ1ЕН8ЕФЗжПтаХЯЂНЋЮоЗЈжЇГХ1ЕН16ЕФЗжПтГЁОАЃЌЗжПтТЗгЩНЋЮоЗЈе§ШЗЭъГЩЃЌЮвУЧНЋЩЯЫпЮЪЬтМђГЦЮЊЗжПтаХЯЂОЋЖШЖЊЪЇЁЃ
ЮЊНтОіЗжПтаХЯЂОЋЖШЖЊЪЇЮЪЬтЃЌЮвУЧашвЊЖдЗжПтаХЯЂОЋЖШНјааШпгрЃЌМДЮвУЧЯждкБЃДцЕФЗжПтаХЯЂвЊжЇГжвдКѓЕФРЉШнЁЃетРяЮвУЧМйЩшзюжеЮвУЧЛсРЉШнЕН64ЬЈЪ§ОнПтЃЌЫљвдаТЕФЗжПтаХЯЂЫуЗЈЮЊЃК
ЗжПтаХЯЂ = (uid / 10) % 64 + 1
ЕБuidЃН9527ЪБЃЌИљОнаТЕФЫуЗЈЃЌЗжПтаХЯЂ=57ЃЌетРяЕФ57ВЂВЛЪЧеце§Ъ§ОнПтЕФБрКХЃЌЫќШпгрСЫзюКѓРЉеЙЕН64ЬЈЪ§ОнПтЕФЗжПтаХЯЂОЋЖШЁЃЮвУЧЕБЧАжЛга8ЬЈЪ§ОнПтЃЌЪЕМЪЪ§ОнПтБрКХЛЙашИљОнЯТУцЕФЙЋЪННјааМЦЫуЃК
ЪЕМЪЪ§ОнПтБрКХ = (ЗжПтаХЯЂ - 1) % 8 + 1
ЕБuidЃН9527ЪБЃЌЗжПтаХЯЂЃН57ЃЌЪЕМЪЪ§ОнПтБрКХЃН1ЃЌЗжПтЗжБэаХЯЂ=ЁБ577ЁБЁЃ
гЩгкЮвУЧбЁдёФЃ64РДБЃДцОЋЖШШпгрКѓЕФЗжПтаХЯЂЃЌБЃДцЗжПтаХЯЂЕФГЄЖШгЩ1БфЮЊСЫ2ЃЌзюКѓЕФЗжПтЗжБэаХЯЂЕФГЄЖШЮЊ3ЁЃОпЬхЫуЗЈСїГЬвВПЩВЮМћЯТЭМЃК
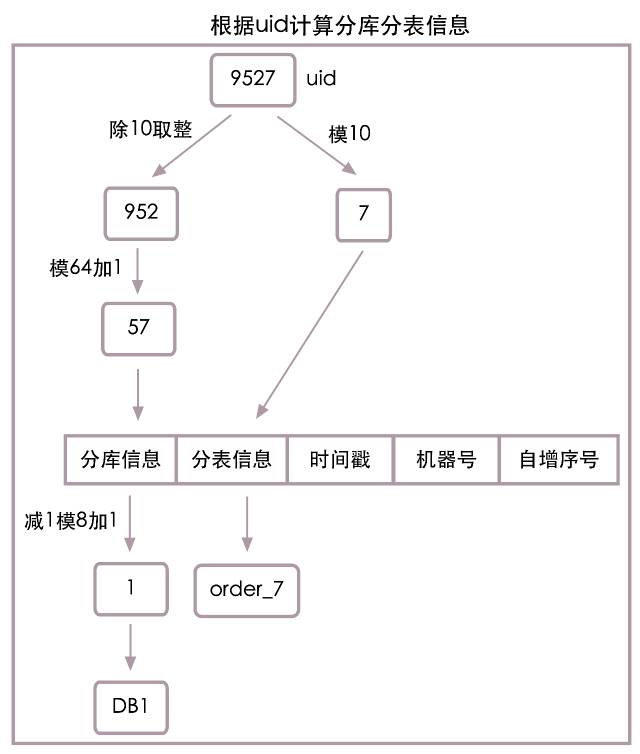
ШчЩЯЭМЫљЪОЃЌдкМЦЫуЗжПтаХЯЂЕФЪБКђВЩгУСЫФЃ64ЕФЗНЪНШпгрСЫЗжПтаХЯЂОЋЖШЃЌетбљЕБЮвУЧЕФЯЕЭГвдКѓашвЊРЉШнЕН16ПтЃЌ32ПтЃЌ64ПтЖМВЛЛсдйгаЮЪЬтЁЃ
ЩЯУцЕФЖЉЕЅIDНсЙЙвбОФмКмКУЕФТњзуЮвУЧЕБЧАгыжЎКѓЕФРЉШнашЧѓЃЌЕЋПМТЧЕНвЕЮёЕФВЛШЗЖЈадЃЌЮвУЧдкЖЉЕЅIDЕФзюЧАЗНМгСЫ1ЮЛгУгкБъЪЖЖЉЕЅIDЕФАцБОЃЌетИіАцБОКХЪєгкШпгрЪ§ОнЃЌФПЧАВЂУЛгагУЕНЁЃЯТУцЪЧзюжеЖЉЕЅIDМђЛЏНсЙЙЭМЃК

SnowflakeЫуЗЈЃКgithub.com/twitter/snowflake
Ш§ЁЂзюжевЛжТад
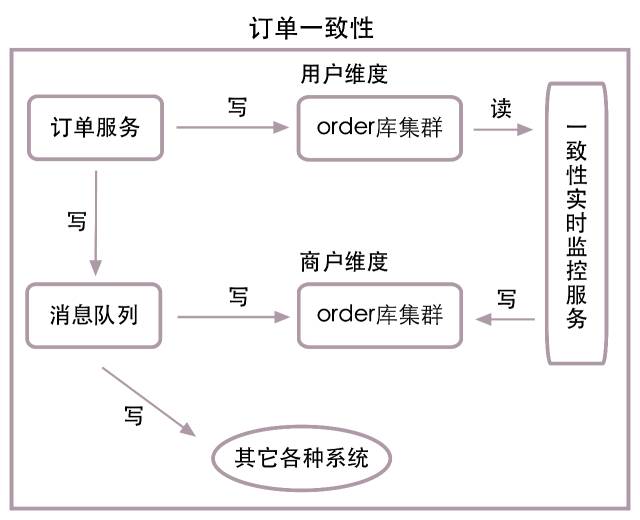
ЕНФПЧАЮЊжЙЃЌЮвУЧЭЈЙ§ЖдorderБэuidЮЌЖШЕФЗжПтЗжБэЃЌЪЕЯжСЫorderБэЕФГЌИпВЂЗЂаДШыгыИќаТЃЌВЂФмЭЈЙ§uidКЭЖЉЕЅIDВщбЏЖЉЕЅаХЯЂЁЃЕЋзїЮЊвЛИіПЊЗХЕФМЏЭХжЇИЖЯЕЭГЃЌЮвУЧЛЙашвЊЭЈЙ§вЕЮёЯпIDЃЈгжГЦЩЬЛЇIDЃЌМђГЦbidЃЉРДВщбЏЖЉЕЅаХЯЂЃЌЫљвдЮвУЧв§ШыСЫbidЮЌЖШЕФorderБэМЏШКЃЌНЋuidЮЌЖШЕФorderБэМЏШКШпгрвЛЗнЕНbidЮЌЖШЕФorderБэМЏШКжаЃЌвЊИљОнbidВщбЏЖЉЕЅаХЯЂЪБЃЌжЛашВщbidЮЌЖШЕФorderБэМЏШКМДПЩЁЃ
ЩЯУцЕФЗНАИЫфШЛМђЕЅЃЌЕЋБЃГжСНИіorderБэМЏШКЕФЪ§ОнвЛжТадЪЧвЛМўКмТщЗГЕФЪТЧщЁЃСНИіБэМЏШКЯдШЛЪЧдкВЛЭЌЕФЪ§ОнПтМЏШКжаЃЌШчЙћдкаДШыгыИќаТжав§ШыЧПвЛжТадЕФЗжВМЪНЪТЮёЃЌетЮовЩЛсДѓДѓНЕЕЭЯЕЭГаЇТЪЃЌдіГЄЗўЮёЯьгІЪБМфЃЌетЪЧЮвУЧЫљВЛФмНгЪмЕФЃЌЫљвдЮвУЧв§ШыСЫЯћЯЂЖгСаНјаавьВНЪ§ОнЭЌВНЃЌРДЪЕЯжЪ§ОнЕФзюжевЛжТадЁЃЕБШЛЯћЯЂЖгСаЕФИїжжвьГЃвВЛсдьГЩЪ§ОнВЛвЛжТЃЌЫљвдЮвУЧгжв§ШыСЫЪЕЪБМрПиЗўЮёЃЌЪЕЪБМЦЫуСНИіМЏШКЕФЪ§ОнВювьЃЌВЂНјаавЛжТадЭЌВНЁЃ
ЯТУцЪЧМђЛЏЕФвЛжТадЭЌВНЭМЃК
ЫФЁЂЪ§ОнПтИпПЩгУ
УЛгаШЮКЮЛњЦїЛђЗўЮёФмБЃжЄдкЯпЩЯЮШЖЈдЫааВЛГіЙЪеЯЁЃБШШчФГвЛЪБМфЃЌФГвЛЪ§ОнПтжїПтхДЛњЃЌетЪБЮвУЧНЋВЛФмЖдИУПтНјааЖСаДВйзїЃЌЯпЩЯЗўЮёНЋЪмЕНгАЯьЁЃ
ЫљЮНЪ§ОнПтИпПЩгУжИЕФЪЧЃКЕБЪ§ОнПтгЩгкИїжждвђГіЯжЮЪЬтЪБЃЌФмЪЕЪБЛђПьЫйЕФЛжИДЪ§ОнПтЗўЮёВЂаоВЙЪ§ОнЃЌДгећИіМЏШКЕФНЧЖШПДЃЌОЭЯёУЛгаГіШЮКЮЮЪЬтвЛбљЁЃашвЊзЂвтЕФЪЧЃЌетРяЕФЛжИДЪ§ОнПтЗўЮёВЂВЛвЛЖЈЪЧжИаоИДдгаЪ§ОнПтЃЌвВАќРЈНЋЗўЮёЧаЛЛЕНСэЭтБИгУЕФЪ§ОнПтЁЃ
Ъ§ОнПтИпПЩгУЕФжївЊЙЄзїЪЧЪ§ОнПтЛжИДгыЪ§ОнаоВЙЃЌвЛАуЮвУЧвдЭъГЩетСНЯюЙЄзїЕФЪБМфГЄЖЬЃЌзїЮЊКтСПИпПЩгУКУЛЕЕФБъзМЁЃетРягавЛИіЖёадбЛЗЕФЮЪЬтЃЌЪ§ОнПтЛжИДЕФЪБМфдНГЄЃЌВЛвЛжТЪ§ОндНЖрЃЌЪ§ОнаоВЙЕФЪБМфОЭЛсдНГЄЃЌећЬхаоИДЕФЪБМфОЭЛсБфЕУИќГЄЁЃЫљвдЪ§ОнПтЕФПьЫйЛжИДГЩСЫЪ§ОнПтИпПЩгУЕФжижажЎжиЃЌЪдЯывЛЯТШчЙћЮвУЧФмдкЪ§ОнПтГіЙЪеЯЕФ1УыжЎФкЭъГЩЪ§ОнПтЛжИДЃЌаоИДВЛвЛжТЕФЪ§ОнКЭГЩБОвВЛсДѓДѓНЕЕЭЁЃ
ЯТЭМЪЧвЛИізюОЕфЕФжїДгНсЙЙЃК

ЩЯЭМжага1ЬЈwebЗўЮёЦїКЭ3ЬЈЪ§ОнПтЃЌЦфжаDB1ЪЧжїПтЃЌDB2КЭDB3ЪЧДгПтЁЃЮвУЧдкетРяМйЩшwebЗўЮёЦїгЩЯюФПзщЮЌЛЄЃЌЖјЪ§ОнПтЗўЮёЦїгЩDBAЮЌЛЄЁЃ
ЕБДгПтDB2ГіЯжЮЪЬтЪБЃЌDBAЛсЭЈжЊЯюФПзщЃЌЯюФПзщНЋDB2ДгwebЗўЮёЕФХфжУСаБэжаЩОГ§ЃЌжиЦєwebЗўЮёЦїЃЌетбљГіДэЕФНкЕуDB2НЋВЛдйБЛЗУЮЪЃЌећИіЪ§ОнПтЗўЮёЕУЕНЛжИДЃЌЕШDBAаоИДDB2ЪБЃЌдйгЩЯюФПзщНЋDB2ЬэМгЕНwebЗўЮёЁЃ
ЕБжїПтDB1ГіЯжЮЪЬтЪБЃЌDBAЛсНЋDB2ЧаЛЛЮЊжїПтЃЌВЂЭЈжЊЯюФПзщЃЌЯюФПзщЪЙгУDB2ЬцЛЛдгаЕФжїПтDB1ЃЌжиЦєwebЗўЮёЦїЃЌетбљwebЗўЮёНЋЪЙгУаТЕФжїПтDB2ЃЌЖјDB1НЋВЛдйБЛЗУЮЪЃЌећИіЪ§ОнПтЗўЮёЕУЕНЛжИДЃЌЕШDBAаоИДDB1ЪБЃЌдйНЋDB1зїЮЊDB2ЕФДгПтМДПЩЁЃ
ЩЯУцЕФОЕфНсЙЙгаКмДѓЕФБзВЁЃКВЛЙмжїПтЛђДгПтГіЯжЮЪЬтЃЌЖМашвЊDBAКЭЯюФПзщаЭЌЭъГЩЪ§ОнПтЗўЮёЛжИДЃЌетКмФбзіЕНздЖЏЛЏЃЌЖјЧвЛжИДЙЄГЬвВЙ§гкЛКТ§ЁЃ
ЮвУЧШЯЮЊЃЌЪ§ОнПтдЫЮЌгІИУКЭЯюФПзщЗжПЊЃЌЕБЪ§ОнПтГіЯжЮЪЬтЪБЃЌгІгЩDBAЪЕЯжЭГвЛЛжИДЃЌВЛашвЊЯюФПзщВйзїЗўЮёЃЌетбљБугкзіЕНздЖЏЛЏЃЌЫѕЖЬЗўЮёЛжИДЪБМфЁЃ
ЯШРДПДДгПтИпПЩгУНсЙЙЭМЃК
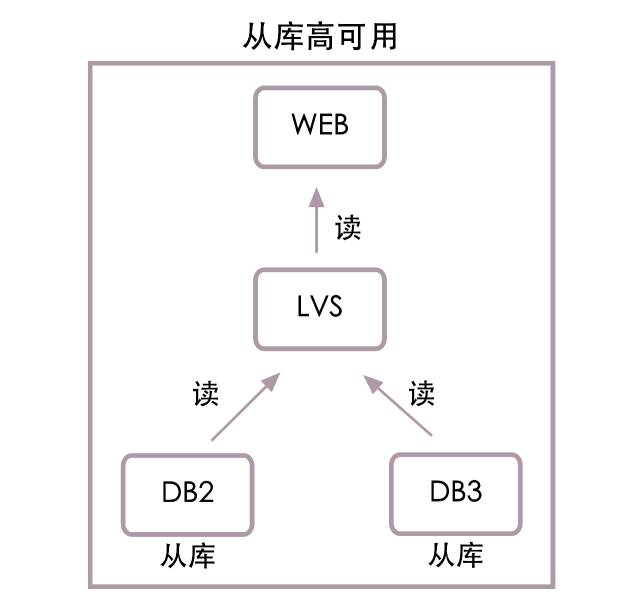
ШчЩЯЭМЫљЪОЃЌwebЗўЮёЦїНЋВЛдйжБНгСЌНгДгПтDB2КЭDB3ЃЌЖјЪЧСЌНгLVSИКдиОљКтЃЌгЩLVSСЌНгДгПтЁЃетбљзіЕФКУДІЪЧLVSФмздЖЏИажЊДгПтЪЧЗёПЩгУЃЌДгПтDB2хДЛњКѓЃЌLVSНЋВЛЛсАбЖСЪ§ОнЧыЧѓдйЗЂЯђDB2ЁЃЭЌЪБDBAашвЊдіМѕДгПтНкЕуЪБЃЌжЛашЖРСЂВйзїLVSМДПЩЃЌВЛдйашвЊЯюФПзщИќаТХфжУЮФМўЃЌжиЦєЗўЮёЦїРДХфКЯЁЃ
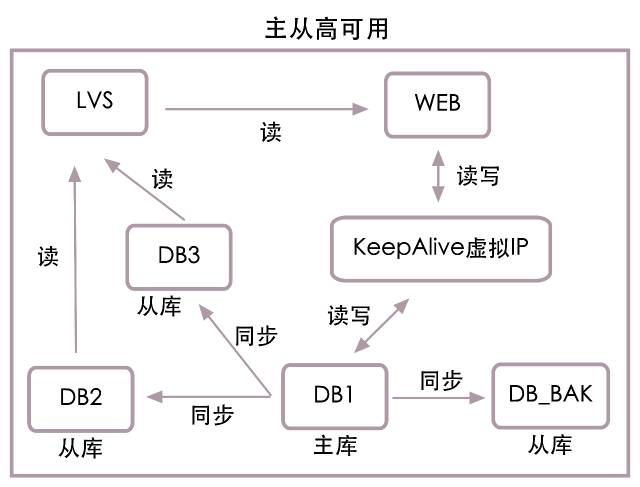
дйРДПДжїПтИпПЩгУНсЙЙЭМЃК

ШчЩЯЭМЫљЪОЃЌwebЗўЮёЦїНЋВЛдйжБНгСЌНгжїПтDB1ЃЌЖјЪЧСЌНгKeepAliveащФтГіЕФвЛИіащФтipЃЌдйНЋДЫащФтipгГЩфЕНжїПтDB1ЩЯЃЌЭЌЪБЬэМгDB_bakДгПтЃЌЪЕЪБЭЌВНDB1жаЕФЪ§ОнЁЃе§ГЃЧщПіЯТwebЛЙЪЧдкDB1жаЖСаДЪ§ОнЃЌЕБDB1хДЛњКѓЃЌНХБОЛсздЖЏНЋDB_bakЩшжУГЩжїПтЃЌВЂНЋащФтipгГЩфЕНDB_bakЩЯЃЌwebЗўЮёНЋЪЙгУНЁПЕЕФDB_bakзїЮЊжїПтНјааЖСаДЗУЮЪЁЃетбљжЛашМИУыЕФЪБМфЃЌОЭФмЭъГЩжїЪ§ОнПтЗўЮёЛжИДЁЃ
зщКЯЩЯУцЕФНсЙЙЃЌЕУЕНжїДгИпПЩгУНсЙЙЭМЃК
Ъ§ОнПтИпПЩгУЛЙАќКЌЪ§ОнаоВЙЃЌгЩгкЮвУЧдкВйзїКЫаФЪ§ОнЪБЃЌЖМЪЧЯШМЧТМШежОдйжДааИќаТЃЌМгЩЯЪЕЯжСЫНќКѕЪЕЪБЕФПьЫйЛжИДЪ§ОнПтЗўЮёЃЌЫљвдаоВЙЕФЪ§ОнСПЖМВЛДѓЃЌвЛИіМђЕЅЕФЛжИДНХБООЭФмПьЫйЭъГЩЪ§ОнаоИДЁЃ
ЮхЁЂЪ§ОнЗжМЖ
жЇИЖЯЕЭГГ§СЫзюКЫаФЕФжЇИЖЖЉЕЅБэгыжЇИЖСїЫЎБэЭтЃЌЛЙгавЛаЉХфжУаХЯЂБэКЭвЛаЉгУЛЇЯрЙиаХЯЂБэЁЃШчЙћЫљгаЕФЖСВйзїЖМдкЪ§ОнПтЩЯЭъГЩЃЌЯЕЭГадФмНЋДѓДђелПлЃЌЫљвдЮвУЧв§ШыСЫЪ§ОнЗжМЖЛњжЦЁЃ
ЮвУЧМђЕЅЕФНЋжЇИЖЯЕЭГЕФЪ§ОнЛЎЗжГЩСЫ3МЖЃК
Ек1МЖЃКЖЉЕЅЪ§ОнКЭжЇИЖСїЫЎЪ§ОнЃЛетСНПщЪ§ОнЖдЪЕЪБадКЭОЋШЗадвЊЧѓКмИпЃЌЫљвдВЛЬэМгШЮКЮЛКДцЃЌЖСаДВйзїНЋжБНгВйзїЪ§ОнПтЁЃ
Ек2МЖЃКгУЛЇЯрЙиЪ§ОнЃЛетаЉЪ§ОнКЭгУЛЇЯрЙиЃЌОпгаЖСЖраДЩйЕФЬиеїЃЌЫљвдЮвУЧЪЙгУredisНјааЛКДцЁЃ
Ек3МЖЃКжЇИЖХфжУаХЯЂЃЛетаЉЪ§ОнКЭгУЛЇЮоЙиЃЌОпгаЪ§ОнСПаЁЃЌЦЕЗБЖСЃЌМИКѕВЛаоИФЕФЬиеїЃЌЫљвдЮвУЧЪЙгУБОЕиФкДцНјааЛКДцЁЃ
ЪЙгУБОЕиФкДцЛКДцгавЛИіЪ§ОнЭЌВНЮЪЬтЃЌвђЮЊХфжУаХЯЂЛКДцдкФкДцжаЃЌЖјБОЕиФкДцЮоЗЈИажЊЕНХфжУаХЯЂдкЪ§ОнПтЕФаоИФЃЌетбљЛсдьГЩЪ§ОнПтжаЪ§ОнКЭБОЕиФкДцжаЪ§ОнВЛвЛжТЕФЮЪЬтЁЃ
ЮЊСЫНтОіДЫЮЪЬтЃЌЮвУЧПЊЗЂСЫвЛИіИпПЩгУЕФЯћЯЂЭЦЫЭЦНЬЈЃЌЕБХфжУаХЯЂБЛаоИФЪБЃЌЮвУЧПЩвдЪЙгУЭЦЫЭЦНЬЈЃЌИјжЇИЖЯЕЭГЫљгаЕФЗўЮёЦїЭЦЫЭХфжУЮФМўИќаТЯћЯЂЃЌЗўЮёЦїЪеЕНЯћЯЂЛсздЖЏИќаТХфжУаХЯЂЃЌВЂИјГіГЩЙІЗДРЁЁЃ
СљЁЂДжЯИЙмЕР
КкПЭЙЅЛїЃЌЧАЖЫжиЪдЕШвЛаЉдвђЛсдьГЩЧыЧѓСПЕФБЉеЧЃЌШчЙћЮвУЧЕФЗўЮёБЛМЄдіЕФЧыЧѓИјвЛВЈДђЫРЃЌЯывЊжиаТЛжИДЃЌОЭЪЧвЛМўЗЧГЃЭДПрКЭЗБЫіЕФЙ§ГЬЁЃ
ОйИіМђЕЅЕФР§згЃЌЮвУЧФПЧАЖЉЕЅЕФДІРэФмСІЪЧЦНОљ10ЭђЯТЕЅУПУыЃЌЗхжЕ14ЭђЯТЕЅУПУыЃЌШчЙћЭЌвЛУыжгга100ЭђИіЯТЕЅЧыЧѓНјШыжЇИЖЯЕЭГЃЌКСЮовЩЮЪЮвУЧЕФећИіжЇИЖЯЕЭГОЭЛсБРРЃЃЌКѓајдДдДВЛЖЯЕФЧыЧѓЛсШУЮвУЧЕФЗўЮёМЏШКИљБОЦєЖЏВЛЦ№РДЃЌЮЈвЛЕФАьЗЈжЛФмЪЧЧаЖЯЫљгаСїСПЃЌжиЦєећИіМЏШКЃЌдйТ§Т§ЕМШыСїСПЁЃ
ЮвУЧдкЖдЭтЕФwebЗўЮёЦїЩЯМгвЛВуЁАДжЯИЙмЕРЁБЃЌОЭФмКмКУЕФНтОіЩЯУцЕФЮЪЬтЁЃ
ЯТУцЪЧДжЯИЙмЕРМђЕЅЕФНсЙЙЭМЃК
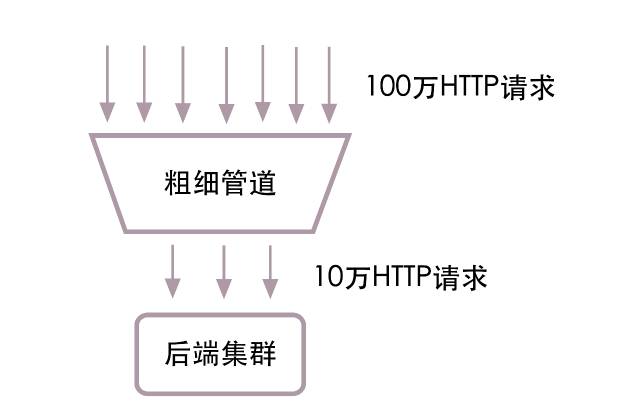
ЧыПДЩЯУцЕФНсЙЙЭМЃЌhttpЧыЧѓдкНјШыwebМЏШКЧАЃЌЛсЯШОЙ§вЛВуДжЯИЙмЕРЁЃШыПкЖЫЪЧДжПкЃЌЮвУЧЩшжУзюДѓФмжЇГж100ЭђЧыЧѓУПУыЃЌЖргрЕФЧыЧѓЛсБЛжБНгХзЦњЕєЁЃГіПкЖЫЪЧЯИПкЃЌЮвУЧЩшжУИјwebМЏШК10ЭђЧыЧѓУПУыЁЃЪЃгрЕФ90ЭђЧыЧѓЛсдкДжЯИЙмЕРжаХХЖгЃЌЕШД§webМЏШКДІРэЭъРЯЕФЧыЧѓКѓЃЌВХЛсгааТЕФЧыЧѓДгЙмЕРжаГіРДЃЌИјwebМЏШКДІРэЁЃетбљwebМЏШКДІРэЕФЧыЧѓЪ§УПУыгРдЖВЛЛсГЌЙ§10ЭђЃЌдкетИіИКдиЯТЃЌМЏШКжаЕФИїИіЗўЮёЖМЛсИпаЃдЫзЊЃЌећИіМЏШКвВВЛЛсвђЮЊБЉдіЕФЧыЧѓЖјЭЃжЙЗўЮёЁЃ | 







