| 编辑推荐: |
| 本文来自于IBM,本文简单介绍了MySQL主从复制原理过程,实现的单向网络数据同步。 |
|
mysql主从复制的原理图
MySQL5.6开始主从复制有两种方式:基于日志(binlog)、基于GTID(全局事务标示符)。
binlog文件格式简介
根据《High-Level Binary Log Structure
and Contents》所述,不同版本的 Binlog 格式不一定一样,所以也没有一个定性。在我写这篇文章的时候,目前有三种版本的格式。
1. v1,用于 MySQL 3.2.3
2.v3,用于 MySQL 4.0.2 以及4.1.0
3.v4,用于 MySQL 5.0 以及更高版本
实际上还有一个 v2 版本,不过只在早期 4.0.x 的 MySQL
版本中使用过,但是 v2 已经过于陈旧并且不再被 MySQL 官方支持了。
通常我们现在用的 MySQL 都是在 5.0 以上的了,所以就略过 v1 ~ v3 版本的 Binlog,如果需要了解
v1 ~ v3 版本的 Binlog 可以自行前往上述的《High-level…》文章查看。
binlog格式分为statement,row以及mixed三种,mysql5.5默认的还是statement模式,当然我们在主从同步中一般是不建议用statement模式的,因为会有些语句不支持,比如语句中包含UUID函数,以及LOAD
DATA IN FILE语句等,一般推荐的是mixed格式。暂且不管这三种格式的区别,看看binlog的存储格式是什么样的。binlog是一个二进制文件集合,当然除了我们看到的mysql-bin.xxxxxx这些binlog文件外,还有个binlog索引文件mysql-bin.index。如官方文档中所写,binlog格式如下:
1.binlog文件以一个值为0Xfe62696e的魔数开头,这个魔数对应0xfe
'b''i''n'。
2.binlog由一系列的binlog event构成。每个binlog
event包含header和data两部分。
3.header部分提供的是event的公共的类型信息,包括event的创建时间,服务器等等。
4.data部分提供的是针对该event的具体信息,如具体数据的修改。
5.接下来的event就是按照上面的格式版本写入的event。
6.最后一个rotate event用于说明下一个binlog文件。
binlog索引文件是一个文本文件,其中内容为当前的binlog文件列表。比如下面就是一个mysql-bin.index文件的内容。
1./var/log/mysql/mysql-bin.000019
2./var/log/mysql/mysql-bin.000020
3./var/log/mysql/mysql-bin.000021
对照官方文档中的说明来看下format_descevent格式:
+=====================================+
| event | timestamp 0 : 4 |
| header +----------------------------+
| | type_code 4 : 1 | = FORMAT_DESCRIPTION_EVENT
= 15
| +----------------------------+
| | server_id 5 : 4 |
| +----------------------------+
| | event_length 9 : 4 | >= 91
| +----------------------------+
| | next_position 13 : 4 |
| +----------------------------+
| | flags 17 : 2 |
+=====================================+
| event | binlog_version 19 : 2 | = 4
| data +----------------------------+
| | server_version 21 : 50 |
| +----------------------------+
| | create_timestamp 71 :4 |
| +----------------------------+
| | header_length 75 : 1 |
| +----------------------------+
| | post-header 76 : n | = array of n bytes, one
byte per event
| | lengths for all | type that the server knows
about
| | event types |
+=====================================+
前面4个字节是固定的magic number,值为0x6e6962fe。接着是一个format_desc
event,先看下19个字节的header。这19个字节中前4个字节0x567fb2b8是时间戳,第5个字节0x0f是event
type,接着4个字节0x00000004是server_id,再接着4个字节0x00000067是长度103,然后的4个字节0x0000006b是下一个event的起始位置107,接着的2个字节的0x0001是flag(1为LOG_EVENT_BINLOG_IN_USE_F,标识binlog还没有关闭,binlog关闭后,flag会被设置为0),这样4+1+4+4+4+2=19个字节的公共头就完了(extra_headers暂时没有用到)。然后是这个event的data部分,event的data分为Fixeddata和Variable
data两部分,其中Fixeddata是event的固定长度和格式的数据,Variabledata则是长度变化的数据,比如format_desc
event的Fixed data长度是0x54=84个字节。下面看下这84=2+50+4+1+27个字节的分配:开始的2个字节0x0004为binlog的版本号4,接着的50个字节为mysql-server版本,如我的版本是5.5.46-0ubuntu0.14.04.2-log,与SELECTversion();查看的结果一致。接下来4个字节是binlog创建时间,这里是0;然后的1个字节0x13是指之后所有event的公共头长度,这里都是19;接着的27个字节中每个字节为mysql已知的event(共27个)的Fixed
data的长度;可以发现format_desc event自身的Variable data部分为空。
binlog格式
上面提到,binlog有三种格式,各有优缺点:
1.statement:基于SQL语句的模式,某些语句和函数如UUID,
LOAD DATA INFILE等在复制过程可能导致数据不一致甚至出错。
2.row:基于行的模式,记录的是行的变化,很安全。但是binlog会比其他两种模式大很多,在一些大表中清除大量数据时在binlog中会生成很多条语句,可能导致从库延迟变大。
3.mixed:混合模式,根据语句来选用是statement还是row模式。
Mysql binlog日志有ROW,Statement,MiXED三种格式;可通过my.cnf配置文件及
==set globalbinlog_format='ROW/STATEMENT/MIXED'==
进行修改,命令行 ==showvariables like 'binlog_format'== 命令查看binglog格式;。
1.Row level: 仅保存记录被修改细节,不记录sql语句上下文相关信息优点:能非常清晰的记录下每行数据的修改细节,不需要记录上下文相关信息,因此不会发生某些特定情况下的procedure、function、及trigger的调用触发无法被正确复制的问题,任何情况都可以被复制,且能加快从库重放日志的效率,保证从库数据的一致性
缺点:由于所有的执行的语句在日志中都将以每行记录的修改细节来记录,因此,可能会产生大量的日志内容,干扰内容也较多;比如一条update语句,如修改多条记录,则binlog中每一条修改都会有记录,这样造成binlog日志量会很大,特别是当执行alter
table之类的语句的时候,由于表结构修改,每条记录都发生改变,那么该表每一条记录都会记录到日志中,实际等于重建了表。
tip: - row模式生成的sql编码需要解码,不能用常规的办法去生成,需要加上相应的参数(--base64-output=decode-rows
-v)才能显示出sql语句; - 新版本binlog默认为ROW level,且5.6新增了一个参数:binlog_row_image;把binlog_row_image设置为minimal以后,binlog记录的就只是影响的列,大大减少了日志内容
2.Statement level: 每一条会修改数据的sql都会记录在binlog中优点:只需要记录执行语句的细节和上下文环境,避免了记录每一行的变化,在一些修改记录较多的情况下相比ROW
level能大大减少binlog日志量,节约IO,提高性能;还可以用于实时的还原;同时主从版本可以不一样,从服务器版本可以比主服务器版本高
缺点:为了保证sql语句能在slave上正确执行,必须记录上下文信息,以保证所有语句能在slave得到和在master端执行时候相同的结果;另外,主从复制时,存在部分函数(如sleep)及存储过程在slave上会出现与master结果不一致的情况,而相比Row
level记录每一行的变化细节,绝不会发生这种不一致的情况
3.Mixedlevel level: 以上两种level的混合使用经过前面的对比,可以发现ROW
level和statement level各有优势,如能根据sql语句取舍可能会有更好地性能和效果;Mixed
level便是以上两种leve的结合。不过,新版本的MySQL对row level模式也被做了优化,并不是所有的修改都会以row
level来记录,像遇到表结构变更的时候就会以statement模式来记录,如果sql语句确实就是update或者delete等修改数据的语句,那么还是会记录所有行的变更;因此,现在一般使用row
level即可。
4.选取规则如果是采用 INSERT,UPDATE,DELETE
直接操作表的情况,则日志格式根据 binlog_format 的设定而记录 如果是采用 GRANT,REVOKE,SET
PASSWORD 等管理语句来做的话,那么无论如何都采用statement模式记录
GTID(全局事务标示符)
GTID(Global Transaction ID)是对于一个已提交事务的编号,并且是一个全局唯一的编号。GTID实际上是由UUID+TID组成的。其中UUID是一个MySQL实例的唯一标识,保存在mysql数据目录下的auto.cnf文件里。TID代表了该实例上已经提交的事务数量,并且随着事务提交单调递增。下面是一个GTID的具体形式:3E11FA47-71CA-11E1-9E33-C80AA9429562:23。
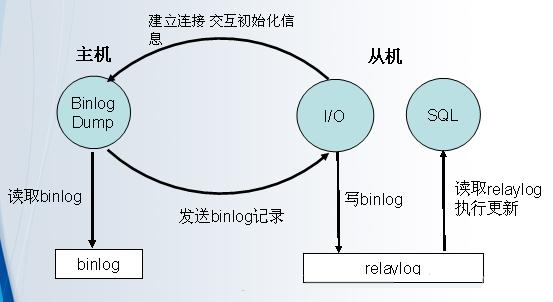
MySQL主从复制原理过程
以下简单描述下MySQL Replication的复制过程
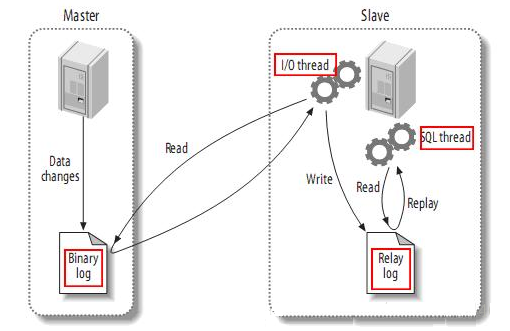
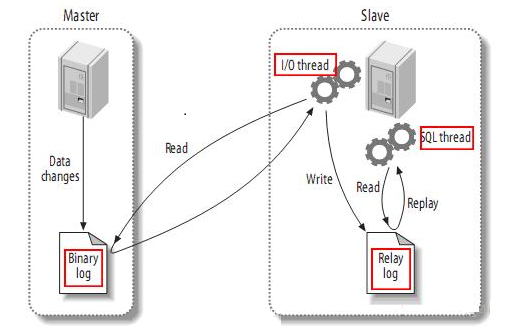
1. slave服务器上执行start slave命令,开启主从复制开关;
2. slave服务器的IO线程会通过 在Master上授权的复制用户权限请求连接Master服务器,并请求从指定binlog日志文件位置(日志文件名和位置在配置主从复制服务时执行changemaster
命令时指定)之后发送binlog日志内容;
3. master服务器接受来自slave服务器的IO线程的请求后,master服务器上负责复制的IO线程根据slave服务器的IO线程请求的信息读取指定binlog日志文件指定位置之后的binlog日志信息,然后返回给slave的IO线程,返回的信息中除了binlog日志内容外,还有本次返回日志内容后再master服务器端的新的binlog文件名称以及在binlog中的下一个指定更新位置;
4. 当slave服务器的IO线程获取到来自master服务器上IO线程发送日志内容以及日志文件以及位置点后,将binlog日志内容一次写入到slave端自身的relaylog(中继日志)文件(mysql-relay-bin.xxxxxx)的末尾,并将新的binlog文件名和位置记录到master-info文件中,以便下次读取master端新binlog日志时能够告诉master服务器需要从新binlog日志的哪个文件哪个位置开始请求新的binlog日志内容;
5. slave服务器的SQL线程会实时的检测本地relaylog中新增加的日志内容,然后及时的把log文件中的内容解析成在master端曾经执行的SQL语句的内容,并在自身的slave服务器上按语句的顺序执行应用这些SQL语句,应用完毕后清理用过的日志;
6. 经过上面的过程,就可以确保在master端和slave端执行了同样的SQL语句。当复制状态正常的情况下,master端和slave端的数据是完全一样的,MySQL的同步机制是有一些特殊的情况,具体请参考官方的说明,大多数情况下,我们不用担心。
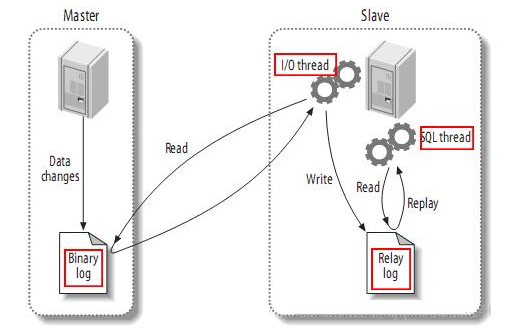
a.Master将数据改变记录到二进制日志(binary log)中
b.Slave上面的IO进程连接上Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容
c.Master接收到来自Slave的IO进程的请求后,负责复制的IO进程会根据请求信息读取日志指定位置之后的日志信息,返回给Slave的IO进程。
返回信息中除了日志所包含的信息之外,还包括本次返回的信息已经到Master端的bin-log文件的名称以及bin-log的位置
d.Slave的IO进程接收到信息后,将接收到的日志内容依次添加到Slave端的relay-log文件的最末端,并将读取到的Master端的
bin-log的 文件名和位置记录到master-info文件中,以便在下一次读取的时候能够清楚的告诉Master从某个bin-log的哪个位置开始往后的日志内容
e.Slave的Sql进程检测到relay-log中新增加了内容后,会马上解析relay-log的内容成为在Master端真实执行时候的那些可执行的内容,并在自身执行
基于mysql binlog日志实现的单向网络数据同步
binlog索引文件是一个文本文件 binlog.index,其中内容为当前的binlog文件列表.
索引文件的完整性保证了数据同步的完整性。
单向网络中,我们可以确保文本的传输的确切性:文本要么全部传过来,最好的结果,也是预期的结果;要么缺失一部分,文本内容不会出现错乱的现象,缺失的文本处理时做异常处理,等待下一次完整文本传输过来,可以成功解析。Binlog.index文件就是数据同步的基准(LIST
PLAN),清单计划上面的内容完成,就认为整个同步任务完成。网络的可靠性,内外网数据的一致性只能人工的排查,或者在网络可靠的情况下,外网收集数据清单,对内网进行比对,生成对比记录,辅助数据的一致性。
程序构成:
1.改动文件扫描程序:检测binlog文件的生成,筛选改动文件,增量发送到内网,利于程序的持久性传输。
2.内网Binlog文件校验解析程序:根据binlog.index索引文件校验文件数量的完整性,内网程序持久化记录上次处理binlog文件位置,包含binlog-file-name和binlog
的stop—position,xy两维数据定位binlog的位置。
3.解析binlog的程序采用 shyiko的mysql-binlog-connector-java;(项目地址:
https://github.com/shyiko/mysql-binlog-connector-java
)准确的解析binlog的日志格式。
4.Binlog文件恢复到指定数据库,采用mysqldbinlog命令行指定文件进行恢复,shell命令回传执行结果,打印执行日志,判断binlog文件恢复的情况,持久化本次的binlog恢复记录。 | 







