| БрМЭЦМі: |
| БОЮФРДздгкinfoqЃЌНщЩмСЫЪЙгУAppache
ArrowНјааЯђСПЛЏЖгСаДІРэЃЌDremioЯЕЭГжаЕФArrowВщбЏДІРэЕШЁЃ |
|
вЊЕу
СаЪНЪ§ОнПтгажњгкМѕЩйСЊЛњЗжЮіДІРэ(OLAP)ЕФИКдиЃЌвђЮЊВщбЏЛсЩцМАЕНСаЕФвЛИізгМЏЃЌЕЋетаЉСаЖМгаДѓСПЕФааЪ§ЁЃ
СаЪНДцДЂИёЪНЪЙЮвУЧПЩвдВЩгУвЛаЉЛљгкУПСаЕФЧсСПМЖбЙЫѕЫуЗЈЃЈlightweight compression
algorithmsЃЉ ЁЃ
ЯђСПЛЏЕФЪ§ОнДІРэЭЈЙ§гааЇЪЙгУCPUЛКГхЛњжЦЕФЗНЗЈЃЌРДПЊЗЂИќПьЫйЕФЗжЮіВщбЏв§ЧцЁЃ
ArrowЕФСаЪНЪ§ОнНсЙЙдЪаэЪЙгУЧсСПМЖЗНАИЃЌШчзжЕфБрТыЃЈdictionary encodingЃЉЁЂЮЛбЙЫѕЃЈbit
packing ЃЉЃЌЛђЪЧдЫааГЄЖШБрТыЃЈrun lengthЃЉЃЌетбљдкбЙЫѕБШР§вЛЖЈЪБЃЌПЩвдЬсИпВщбЏадФмЁЃ
СаЪНЪ§ОнПтзщжЏДХХЬЛђФкДцжаИјЖЈЕФСЌајСаЪ§ОнЁЃЛљгкСаЕФДцДЂЗНЪНЃЌгажњгкМѕЩйСЊЛњЗжЮіДІРэ(OLAP)ЕФИКдиЃЌвђЮЊВщбЏЛсЩцМАЕНСаЕФвЛИізгМЏЃЌЕЋетаЉСаЖМгаДѓСПЕФааЪ§ЁЃЖдгкетРрВщбЏЃЌЪЙгУСаЪ§ОнИёЪНПЩвдДѓДѓМѕЩйДгДХХЬЕНФкДцКЭДгФкДцЕНМФДцЦїЕФЪ§ОнзЊЛЛЁЃетбљПЩвдгааЇЕиЬсИпећИіДцДЂЬхЯЕЕФЭЬЭТСПЁЃЖјЧвЃЌСаЪНИёЪНШУЮвУЧПЩвдЪЙгУвЛаЉЛљгкУПСаЕФЧсСПМЖбЙЫѕЫуЗЈЁЃетжжЧщПіЯТЃЌбЙЫѕЫуЗЈадФмЛсИќКУЃЌвђЮЊбЙЫѕв§ЧцЕФЪфШыЪ§ОнЪЧЭЌвЛРраЭЪ§ОнЃЌФмЙЛбЙЫѕЕФИќКУИќПьЁЃ
ЯђСПЛЏДІРэздMonerDB-X100ЃЈVectorwiseЃЉЯЕЭГПЊЪМСїааЃЌЯждквбГЩЮЊдкЯжДњгВМўЬѕМўЯТЙЙНЈИпаЇЗжЮіВщбЏв§ЧцЃЌНјЖјМгЫйЪ§ОнДІРэЕФБъзМЁЃетжжФЃЪНашвЊАДСаБэЪОЕФЪ§ОнРДБраДИпаЇгХЛЏЕФВщбЏДІРэЫуЗЈЁЃЯђСПЛЏЕФЙ§ГЬКЭДЋЭГЕФЛљгкдЊзщЕФВщбЏЙ§ГЬФЃЪНгазХЯджјЧјБ№ЁЃ
СНжжЗНЗЈзюжївЊЕФВЛЭЌЪЧЃЌЧАепЪЧЛљгкСаЖјВЛЪЧЛљгкаа/дЊзщРДжиаДВщбЏДІРэЫуЗЈЁЃСЌајДцДЂЕФвЛСаЪ§ОнЃЌдкФкДцжаПЩвдБэЪОЮЊвЛИіЯђСПЃЌетИіЯђСПАќКЌСЫИУСажаЙЬЖЈЪ§ФПЕФвЛаЉжЕЁЃ
ЯђСПФЃЪНКЭДЋЭГФЃЪНЕФЕкЖўИіВЛЭЌЪЧЃЌЮвУЧПЩвдЬэМгвЛИіПщЃЌЖјВЛЪЧдкВщбЏМЦЛЎЪїЖЅВПвЛДЮЬэМгвЛИідЊзщЁЃвЛИіПщгЩЙЬЖЈЕФвЛзщдЊзщЃЈМЧТМЃЉзщГЩЃЌЫќДњБэвЛзщЯђСПЃЌетаЉЯђСПКЭСа/зжЖЮгавЛвЛЖдгІЕФЙиЯЕЁЃЯђСППщЪЧЪ§ОнЕФЛљБОЕЅдЊЃЌЫќОгЩжДааМЦЛЎЪїЃЌДгвЛИіВйзїЗћСїЯђСэвЛИіВйзїЗћЁЃ
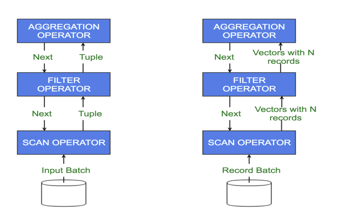
ЭМ1ЃКДЋЭГЕФвЛДЮЬэМгвЛИідЊзщЕФДІРэКЭЯђСПЛЏДІРэБШНЯ
дкЭМ1жаЃЌзѓВрЭМЮЊДЋЭГЕФвЛДЮВйзївЛИідЊзщЕФДІРэСїГЬЁЃЩЈУшдЫЫуЗћПЊЪМЛёШЁЪфШыЪ§ОнЃЌВЂЭЈЙ§Й§ТЫдЫЫуЗћПЊЪМЭЦЖЏдЊзщЕФДІРэЁЃНгЯТРДЃЌЙ§ТЫдЫЫуЗћДЋЕнЗћКЯЬѕМўЕФдЊзщЕНОлКЯдЫЫуЗћЁЃдЫЫуЗћВЛЭЃЕїгУВщбЏМЦЛЎЪїЯТВуЕФЯТвЛИідЫЫуЗћЁЃЦфНсЙћОЭЪЧЮЛгкЪїЯТВуЕФдЫЫуЗћАбдЊзщЭЦЯђЮЛгкЪїЖЅЕФдЫЫуЗћЁЃетОЭЪЧВщбЏЕФжДааЙ§ГЬЁЃ
ЯждкЃЌгЩгкгаДѓСПЕФКЏЪ§ЕїгУЃЌЧвУПДЮКЏЪ§ЕїгУЪБДгвЛИідЫЫуЗћЕНСэвЛИідЫЫуЗћашвЊДІРэЛђДЋЪфЕФЪ§ОнВЛЖрЃЌдкетИіжДааЙ§ГЬжаЃЌадФмПЊЯњКмДѓЁЃЦфДЮЃЌЕБНіашвЊДІРэдЊзщРяСаЕФвЛИізгМЏЪБЃЌашвЊДЋЕнећИідЊзщЁЃ
гвВрЕФЮЊвЛИіЯђСПФЃаЭЃЌЭљИУФЃаЭжаЬэМгвЛИіЯђСППщЃЌУПИіЯђСПгавЛзщМЧТМЛђСажЕЁЃдкетИіЪ§ОнМЏКЯжаЃЌгаЖрЩйСаЃЌОЭгаЖрЩйЯђСПЁЃВЛЖЯЭљВщбЏМЦЛЎЪїЩЯУцбЙШывЛХњЯђСПЃЌЫќУЧОЭЪЧВщбЏМЦЛЎжаВЛЭЌВйзїЗћЕФЪфШыгыЪфГіЁЃетжжЗНЗЈдЖБШЦфЫќЗНЗЈгааЇЃЌвђЮЊетжжЗНЗЈдкВЛЭЌЕФВйзїЗћМфЦНЬЏСЫКЏЪ§ЕїгУЕФПЊЯњЃЌЦфДЮЃЌВйзїЛљгкСаЖјВЛдйЛљгкааЛђдЊзщЁЃ
ЯђСПЛЏЕФДњТыПЩвдГфЗжРћгУCPUЕФЛКДцЁЃР§ШчЃЌга10СаЕФвЛааЪ§ОнКЭжЛашВйзївЛСаЕФВщбЏМЦЛЎЁЃдкЛљгкааЕФВщбЏДІРэФЃЪНжаЃЌ9СаЪ§ОнЛсВЛБивЊЕФеМгУЛКДцЃЌЯожЦСЫПЩвдНјШыЛКДцЕФЪ§ОнЪ§СПЁЃдкЛљгкСаЕФДІРэжаЃЌжЛЛсЖСШыИааЫШЄЕФСаЪ§ОнЃЌетбљПЩвдвЛЦ№ДІРэИќЖрЕФжЕЃЌЭЌЪБгааЇЪЙгУСЫCPUЕФФкДцДјПэЁЃ
ЯђСПДІРэБГКѓЕФжївЊЫМЯыЪЧЃЌАДСаЃЈЛђСаЪНЪ§ОнЪ§ОнЃЉЙЄзїЃЌВЂАбДгЖрСаЕНдЊзщЃЈааЃЉЕФЪЕМЪзЊЛЏЭЦГйЕНВщбЏМЦЛЎЕФКмППКѓЕФЮЛжУНјааДІРэЃЌДѓВПЗжЧщПіЪЧашвЊеЙЪОНсЙћИјгУЛЇЪБЁЃете§ЪЧЮЊЪВУДВщбЏжДааЫуЗЈЭЈГЃЛсжиаДЃЌРДзіЛљгкСаЕФДІРэЁЃШчЙћЮвУЧвдСаЪНЗНЪНДцДЂЪ§ОнЃЌЕЋЪЧДІРэДњТыЪЧЛљгкааДІРэБраДЕФЃЌФЧУДЕБЖСЕНСаЪБЃЌОЭВЛЕУВЛзщКЯКмЖрСаЕФЪ§ОнРДЙЙГЩвЛИідЊзщЃЌВЂНЋИУдЊзщДЋЕнИјВщбЏВйзїЗћРДНјааДЋЭГЕФж№ааДІРэЁЃжДааЙ§ГЬжаЕФдЊзщЙЙНЈГйдчЛсгАЯьЖдСаЪНЪ§ОнНјааИпЖШгХЛЏЕФВщбЏДІРэЁЃ
ЯжДњДІРэЦїгаРЉеЙЕФжИСюМЏЃЌдкЕЅЖРЕФвЛИіжИСюжаЃЌИУжИСюМЏПЩвдРЉеЙЯђСПжДааИХФюЕНЖрСаЕФжЕЁЃЕЅжИСюЖрЪ§ОнСїЃЈSIMDЃЉжИСюдк20ЪРМЭ90ФъДњГЩЮЊзРУцдЫЫужїСїЃЌЬсИпСЫЖрУНЬхгІгУШчгЮЯЗЕФадФмЁЃ
ЖдЖрИіжЕзіЯрЭЌИФБфЃЌБШШчЕїећвЛИіЭМЯёЕФССЖШЪБЃЌSIMDгШЦфгагУЁЃУПИіЯёЫиЕуЕФССЖШгЩКьЩЋЃЈRЃЉЃЌТЬЩЋЃЈGЃЉКЭРЖЩЋЃЈBЃЉЕФжЕШЗЖЈЁЃИФБфССЖШЃЌвЊДгФкДцЖСШЁRЃЌGКЭBЕФжЕЃЌВЂНјааЕїећЃЌЕїећКѓЕФжЕвЊжиаДЛиФкДцЁЃВЛЪЙгУSIMDЃЌЯёЫиЕФRGBжЕЛсвРДЮЕЅИіЖСШыФкДцЁЃЪЙгУSIMDЃЌЯёЫиЕФRGBЪ§ОнПщПЩвддквЛИіжИСюжавЛЦ№НјааДІРэЁЃетбљОЭМЋДѓЕиЬсИпСЫгааЇадЁЃ
етаЉИХФюдкЗжЮібЇЕФЪ§ОнДІРэжаЗЧГЃЪЪгУЁЃSIMDВЩгУКЭВЂЗЂЮоЙиЕФЪ§ОнМЖВЂааЁЃSIMDжИСюдЪаэдкЭЌвЛЪБжгжмЦкФкЃЌЖдВЛЭЌЕФСаЪ§ОнжДааЯрЭЌЕФжИСю,
ЪЕМЪЩЯжДааЭЬЭТСПЃЈthroughput of executionЃЉПЩвдЬсИп4БЖЛђИќЖрЁЃСаЪНЪ§ОнПЩвдзёбSIMDДІРэЃЌетбљПЩвдДцДЂСажЕЕНФкДцжаЕФгаађХХСаЧвзжНкЖдЦыЕФУмМЏЪ§зщжаЃЌетаЉЪ§ОнЛсдиШыЕНЙЬЖЈПэЖШЕФSIMDМФДцЦїжаЁЃЯждкЕФIntelБрвыЦїХфжУСЫAVX-512ЃЈИпМЖЪИСПРЉеЙЃЉжИСюМЏЃЌИУжИСюМЏдіМгSIMDМФДцЦїЕФПэЖШЕН512БШЬиЁЃЛЛЖјбджЎЃЌПЩвдВЂаадЫЫу16Иі4зжНкЕФећЪ§СажЕЁЃЦфЫќЕФSIMDжИСюМЏЛЙгаSSEЃЌSSE2ЃЌAVXЃЌAVX2.
вЊЪЙгУЯђСПДІРэКЭSIMDЃЌКмживЊЕФвЛЕуЪЧе§ШЗзщжЏЪ§ОнвдзюДѓЛЏЪевцЁЃЯждкгавЛжжФкДцДІРэЕФПЊдДПђМмНаApache
ArrowЁЃArrowШЗБЃФкДцжаЕФЪ§ОнЪЧе§ШЗЖдЦыЕФЃЌетбљФмзюДѓЯоЖШЕиРћгУЯђСПЛЏКЭSIMDжИСюЕФгХЪЦЁЃ
Apache Arrow
ArrowЯюФПЪЧApacheШэМўЛљН№ЛсЖЅМЖЕФПЊдДЯюФПЁЃArrowЖЈвхСЫБъзМЕФЗНЪНРДБэЪОПЩгааЇДІРэЕФФкДцЪ§ОнЃЌЭЌЪБжЇГжЖржжСїааЕФБрГЬгябджаЃЌАќРЈJavaЃЌC++КЭPythonЁЃ
ArrowЯюФПСНФъЗЂЗЂВМЃЌШЁЕУСЫПьЫйЕФЗЂеЙЁЃздЗЂВМКѓЃЌЪЎЖрИіжївЊЕФПЊдДЯюФПжаЕФПЊЗЂепЖМЮЊArrowЩчЧјзіГіСЫЙБЯзЁЃArrowЪЙКмЖрВЛЭЌРраЭЕФЯюФПЖМФмЪмвцЃЌВЂМђЛЏСЫЙ§ГЬжЎМфЕФЪ§ОнНЛЛЛЁЃЪЙгУArrowЕФКУДІЗЧГЃЯджјЁЃ
ЪЙгУAppache ArrowНјааЯђСПЛЏЖгСаДІРэ
ArrowЕФжївЊЙизЂЕудкCPUКЭGPUЕФаЇТЪЩЯЁЃArrowЖдСаЪНЪ§ОнЃЈБтЦНЕФЛђЧЖЬзЕФЃЉЬсЙЉгыгябдЮоЙиЕФБъзМИёЪНКЭЯргІЕФПтЃЌетбљПЩвддкЯШНјЕФгВМўЩЯгааЇЕФдЫааЗжЮіШЮЮёЁЃ
Ъ§ОнВжПтЙЄзїКЭЗжЮіВщбЏДгСаЪНЪ§ОнжаЛёвцЗЫЧГЃЌвђЮЊВщбЏЭЈГЃЩцМАЕНСаЕФзгМЏЃЌдкетаЉСаМфЃЌЛсЩцМАЕНДѓСПЕФааЁЃЗжЮіЙЄзїЕФВщбЏАќРЈДѓСПЕФЛиЙщЃЌЩЈУшКЭИДдгЕФСЌНгЁЃ
ПЩвдгУСаЪНЪ§ОнИёЪНРДБраДМђЕЅЖјгааЇЕФВщбЏЙ§ГЬДњТыЃЌвдМгПьЗжЮіВйзїЁЃНєДеЕФforбЛЗДњТыФмПьЫйдЫаадкСажЕЩЯЃЌВЂжДааБиашЕФВйзїЃЌШчFILTERЃЌCOUNT,
SUMКЭMINЕШЕШЁЃетжжЗНЗЈЖдCPUгбКУЃЌвђЮЊCache lineжаЬюГфЕФЮЊЯрЙиЪ§ОнЃЌМДвЛЯЕСаДгСаЛёШЁЕФжЕЃЌЫќУЧЖМашвЊНјааДІРэЁЃРрЫЦЕФЃЌЮвУЧДгДХХЬНЋЫљашСаЪНЪ§ОнЖСШыФкДцЪБЃЌжЛашвЊЖСШЁЫљашСаМДПЩЁЃвђДЫЃЌдкДХХЬI/OКЭCPUФкДцДјПэеМгУЗНУцЃЌЛљгкСаЪНИёЪНЪ§ОнБраДЕФВщбЏЫуЗЈЃЌаЇТЪдЖБШЛљгкааЕФЦфЫќЫуЗЈИпЁЃ
ЖјЧвЃЌдкБрвыжаЃЌШчЙћгагХЛЏЛњЛсЃЌБрМЦїЛсНЋНєДебЛЗДњТыздЖЏзЊЛЛЮЊЯђСПжИСюЁЃЕББраДЛљгкааЪ§ОнЕФВщбЏДІРэЫуЗЈЪБЃЌетжжгХЛЏЛњЛсЪЧУЛгаЕФЁЃ
ArrowСаЪНЪ§ОнЕФФкДцИёЪНЪЕМЪЩЯШУCPUЪЙгУТЪбЙЫѕЩшМЦЃЈCPU-efficient compression
schemesЃЉЃЌетжжЩшМЦЪЧЧсСПМЖЕФЃЌИќЙизЂЪЕМЪЕФВщбЏЙ§ГЬадФмЖјВЛЪЧЪЕМЪЕФбЙЫѕТЪЃЌКѓепЛсбЯжигАЯьCPUаЇТЪЁЃ
DremioЯЕЭГжаЕФArrowВщбЏДІРэ
DremioЪЧздЗўЮёЪ§ОнЕФПЊдДЦНЬЈЁЃКЫаФЕФв§ЧцУћЮЊSabotЃЌЫќЭъШЋЛљгкArrowПтЕФЖЅВуНјааЙЙНЈЁЃ
ЪзЯШРДЬжТлDremioРяArrowЯрЙиЕФФкДцЙмРэЁЃArrowЪЕМЪАќКЌвЛИіЛљгкChunkЙмРэЕФЗжХфЦїЃЌИУЗжХфЦїЭъШЋЙЙНЈдкNettyЕФJEMalllocЕФЖЅВуЪЕЯжжаЁЃжївЊЕФФкДцЙмРэФЃЪНЛђЗжХфФЃЪНЪЧвЛжжЛљгкЪїЕФФЃЪНЃЌДгИљЗжХфЦїПЊЪМНјааЗжХфЁЃетбљЃЌПЩвддкИљЗжХфЦїЯТДДНЈЖрИізгЗжХфЦїЁЃУПИіЗжХфЦїгавЛИіГѕЪМдЄСєЃЈДДНЈЗжХфЦїЪБДЅЗЂЃЉКЭзюДѓЕФЗжХфЯоЖюЁЃдЄСєВЛЪЧжИдЄЯШЗжХфЃЌЫќвтЮЖзХдкЗжХфЦїећИіЩњУќжмЦкжаЃЌПЩгУгкЗжХфВйзїЗћЖдЕФдЄСєЕФФкДцЪ§СПЁЃ
ЭМ2: ЪїзДЗжХфЯЕЭГ
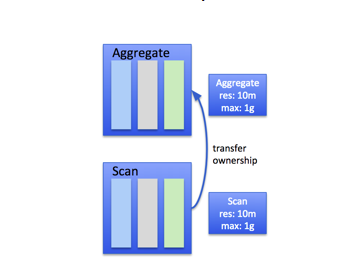
дкдЫаав§ЧцжаЃЌПЩвдНЋЖбЭтФкДцЛКГхгУзіФкДцСаЪНЪ§ОнНсЙЙЕФЕзВуФкДцЃЈunderlying memoryЃЉЁЃдкJavaЕФРЌЛјЛиЪежаЃЌгІБмУтЪЙгУJVMЖбЃЌвдМѕЩйПЊЯњЁЃ
ЯждкЃЌРДЬжТлдѕбљЪЙгУЪїзДЗжХфФЃЪНЃЌвдМАDremioжаЕФГѕЪМдЄСєКЭФкДцЯожЦСНИіИХФюЁЃВщбЏМЦЛЎЪїЕФУПИідЫЫуЗћЕУЕНЫќздМКЕФЗжХфЦїЃЈИИЗжХфЦїЃЉЁЃетбљЃЌУПИідЫЫуЗћЛсЮЊЦфжаЕФУПИіЖРСЂШЮЮёДДНЈвЛИіЛђЖрИіЗжХфЦїЃЈДјГѕЪМдЄСєКЭФкДцЯожЦЃЉЁЃ
вдЭтВПsortдЫЫуЗћЮЊР§ЁЃетИідЫЫуЗћИКд№дкФкДцВЛзуЪБЃЌКмКУЕФДІРэХХађВщбЏЁЃдкШЮКЮЕЭФкДцЕФЧщПіЯТЃЌЫќЖМПЩвдвчГіЪ§ОнЁЃ 
ЭМ3ЃКЖдЭтВПsortдЫЫуЗћНјааЛљгкЪїЕФЗжХф
дкдЫЫуЗћЕФЖЅВуЃЌгавЛИіИУдЫЫуЗћЕФИљЗжХфЦїЁЃВщбЏПЊЪМдЫааЧАЃЌЛсЯШНЈСЂИУдЫЫуЗћздМКЕФЗжХфЦїЁЃХХађдЫЫуЗћгаСНИіжївЊЕФзгЙЙМўЁЃвЛИіЪЧдЫааФкДцЃЌСэвЛИіЪЧдЫааДХХЬЃЌУПИізгЙЙМўДДНЈЖРСЂгкдЫЫуЗћЗжХфЦїЕФзгЗжХфЦїЁЃ
НјШыдЫЫуЗћЕФХњСПЪ§ОнЃЌгЩдЫааФкДцИКд№ЦфЛёШЁКЭХХађЁЃЕБЫљгаЕФЪфШыЖМБЛДІРэКѓЃЌЫљвдЕФЪ§ОнЖМвбХХађЃЌдЫЫуЗћПЩвдПЊЪМДгдЫааФкДцЕФзгЙЙМўжаЪфГіЪ§ОнЁЃ
ДХХЬдЫааИКд№ЙмРэвчГіЁЃШчЙћФкДцВЛзуЃЌашвЊвчГіЃЈвЛДЮЛђЖрДЮЃЉФкДцжавбХХађЕФЪ§ОнЁЃвЛЕЉЪ§ОнвчГіЃЌашвЊжиаТЖдвЛаЉДІРэНјааХХађЃЌДгДХХЬЭљФкДцжаМгдиЖрИівбХХађЕФЪ§ОнСїЃЌдкФкДцжаНјааЦфКЯВЂРДЭъГЩДІРэЃЌШЛКѓНЋЪ§ОнДгдЫЫуЗћГщШЁГіРДЁЃДІРэвчГіЪ§ОнЕФДњТыашвЊБЃжЄгазуЙЛЕФПеМфЃЌПЩвдМгди2зщЛђЖрзщЃЈЛђХњЃЉвчГіМЧТМЕНФкДцРяЃЌРДМЬајФкДцжаЕФКЯВЂДІРэЁЃДХХЬдЫааВПМўЛсвЛжБМрВтЖрИівьГЃжмЦкЃЈЛђбЛЗЃЉКЭУПИіжмЦкФкзюДѓвчГіХњДЮЕФДѓаЁЁЃзгЗжХфЦїдЄСєзуЙЛЕФФкДцПеМфЃЌПЩвдМгдиУПДЮвчГібЛЗВњЩњЕФвчГіХњДЮЁЃ
дкDremioжаЃЌЪ§ОнзїЮЊвЛзщЯђСПЃЌЭЈЙ§ЙмЕРДгвЛИідЫЫуЗћСїЯђСэвЛИідЫЫуЗћЁЃетНазіМЧТМХњДЮЁЃвЛИіМЧТМХњДЮгЩЙЬЖЈИіЪ§ЕФСаЯђСПЃЈСаЪНУшЪіЕФааЪ§ОнНсЙЙЃЉзщГЩЁЃМЧТМХњДЮЪЧDremioдЫаав§ЧцЕФШЮЮёЕЅЮЛЁЃ
ЭМ4: ДгвЛИіВщбЏдЫЫуЗћЕНСэвЛИіЕФЙмЕРЪ§ОнСїЃЈВЛашОЙ§ПНБДЃЉ
дкетИіР§згжаЃЌгаСНИідЫЫуЗћЃКscanКЭaggregationЁЃЪ§ОнгаШ§СаЃЌУПИіСагаИіArrowЯђСПЃЌзмЙВгаШ§ИіЯђСПЁЃЩЯЭМБэЪОscanдЫЫуЗћЕФЪфГіЃЈМЧТМЯђСПЃЉе§КУзїЮЊaggregationдЫЫуЗћЕФЪфШыЁЃ
дкФГаЉдЫЫужаЃЌБШШчгааЉРраЭЕФjoinКЭaggregationЃЌПЩФмашвЊАбЛљгкСаЕФЪ§ОнзЊЛЛЮЊЛљгкааЕФЪ§ОнЁЃЭЈЙ§адФмЪЕбщЃЌПЩвдЗЂЯжСаЪНЪ§ОнЖдгкhashБэЕФВхШыЃЌhash
joinКЭhash aggregationЫуЗЈжаЕФlookupВЛЙЛгааЇЁЃЖдaggregationКЭjoinЃЌдкМгШыЕНhashБэжЎЧАЃЌашвЊАбжївЊЕФСаДгЪфШыМЧТМХњДЮзЊЛЛЕНЕНЯргІЕФааБэЪОЪ§ОнРяЃЌвђДЫетаЉЫуЗЈЪЕЯжВПЗжЃЈгШЦфhashБэЕФДњТыЃЉдЫааЛљгкааЪНБэДяЁЃ
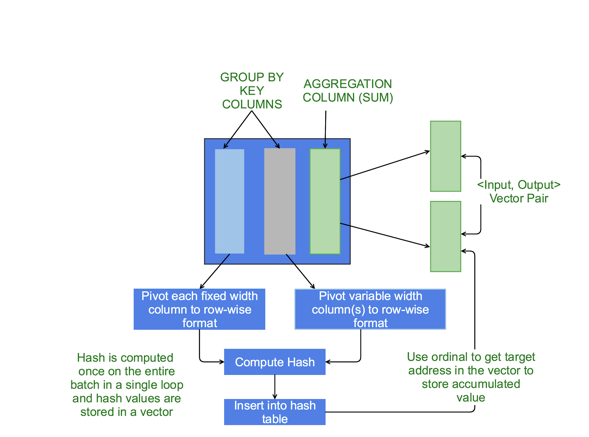
ЭМ5ЃКЯђСПЛЏЕФHash AggregationЃЌМАЦфжївЊСаЪ§ОнЕФааЪНБэДя
ЯТУцЪЧЯђСПЛЏДњТыЕФИХЪіЃЌгУРДжДааДгСаЪНЪ§ОнЕНааЪНЪ§ОнЕФзЊЛЏЃК
БраДвЛЖЮДњТыНЋЯђСПСаЪНЪ§ОнзЊЛЛЮЊааЪНБэДяЃЌПЩвддкhashБэжагааЇЕФНјааinsertion/lookupЕФВйзїЃЈЯђСПЛЏЕФhash
aggregationКЭjoinвВЛсгУЕНИУБэЃЉЁЃЖдгкhash aggregationКЭhash joinЃЌПЩвдЭЈЙ§ЖджївЊЕФСаНјааGROUP
BYЛђjoinРДЪЕЯжЁЃ
static void
pivot4Bytes(
VectorPivotDef def ,
FixedBlockVector fixedBlock,
final int count) {
/* source column vector to pivot */
final FieldVector field =def.getIncomingVector();
/* source column vector buffers */
final List <ArrowBuf> buffers = field.getFieldBuffers();
final int blockLength = fixedBlock.getBlockWidth();
final int bitOffset = def.getNullBitOffset();
/* validity buffer of source vector */
long srcBitsAddr = buffers.get(0).memoryAddress();
/* data buffer of source vector */
long srcDataAddr = buffers.get(1).memoryAddress();
/* target memory region to store pivoted (row-wise)
representation */
long targetAddr = fixedBlock.getMemoryAddress();
/* determine number of null values to work
through a word at a time */
final int remainCount = count % WORD_BITS;
final int wordCount = (count - remainCount)
/ WORD_BITS;
final long finalWordAddr = srcDataAddr + (wordCount
* WORD_BITS * FOUR_BYTE);
long bitTargetAddr = targetAddr + def. getNullByte
Offset ();
long valueTargetAddr = targetAddr + def.getOffset();
// decode word at a time -- 64 column values
while (srcDataAddr < finalWordAddr) {
final long bitValues = PlatformDependent .getLong
(srcBitsAddr);
if (bitValues == NONE_SET) {
// noop (all nulls).
bitTargetAddr += (WORD_BITS * blockLength);
valueTargetAddr += (WORD_BITS * blockLength);
srcDataAddr += (WORD_BITS * FOUR_BYTE);
} else if (bitValues == ALL_SET) {
// all set, set the bit values using a constant
AND.
// Independently set the data values without
transformation.
final int bitVal = 1 << bitOffset;
for (int i = 0; i < WORD_BITS; i++, bitTargetAddr
+= blockLength ) {
PlatformDependent.putInt(bitTargetAddr,
PlatformDependent.getInt(bitTargetAddr) | bitVal);
}
for (int i = 0; i < WORD_BITS; i++, valueTargetAddr
+= blockLength , srcDataAddr += FOUR_BYTE) {
PlatformDependent .putInt(valueTargetAddr, PlatformDependent
.getInt(srcDataAddr));
}
} else {
// some nulls, some not, update each value to
zero or the value, depending on the null bit.
for (int i = 0; i < WORD_BITS; i++, bitTargetAddr
+= blockLength , valueTargetAddr += blockLength,
srcDataAddr += FOUR_BYTE) {
final int bitVal = ((int) (bitValues >>>
i)) & 1;
PlatformDependent.putInt (bitTargetAddr,
PlatformDependent.getInt (bitTargetAddr) | (bitVal
<< bitOffset ));
PlatformDependent.putInt(valueTargetAddr, PlatformDependent
.getInt(srcDataAddr) * bitVal);
}
}
srcBitsAddr += WORD_BYTES;
}
if(remainCount > 0) {
// do the remaining bits..
} |
ДњТыЪЕР§ЃКДгвЛСаЯђСПЃЈдДЃЉЕНСэвЛСаЯђСПЃЈФПБъЃЉзіЯђСППНБДЃЌЪЙгУ2зжНкбЁдёЯђСПЁЃИпаЇC/C++ЗчИёЕФНєДебађДњТыЃЌжБНгзїгУгкunderlying
memoryЃЈЪЕР§ЪЪКЯЙЬЖЈПэЖШЮЊ4зжНкЕФСаЃЉЃК
гУР§ЃКSELECT C1 from FOO where C2 > 1000;
ЪзЯШЃЌдкНєДеforбЛЗЯђСПДњТыжаЃЌЖдC2зігааЇЕФЙ§ТЫДІРэЃЌЙЙНЈбЁдёЯђСПЃЌДцДЂЭЈЙ§ИУЙ§ТЫЦїЕФСажЕЦЋвЦЁЃЯждкПЊЪМдЫааСэвЛИібЛЗЃЌЪЙгУетаЉЦЋвЦСПРДЫїв§ДгC1ДЋЕнГіРДЕФжЕЁЃ
static class
FourByteCopier extends FieldBufferCopier {
private static final int SIZE = 4;
private final FieldVector source;
private final FieldVector target;
private final FixedWidthVector targetAlt;
public FourByteCopier(FieldVector source,
FieldVector target) {
this.source = source;
this.target = target;
this.targetAlt = (FixedWidthVector) target;
}
@Override
public void copy(long offsetAddr, int count)
{
targetAlt.allocateNew(count);
final long max = offsetAddr + count * 2;
final long srcAddr = source.getDataBufferAddress();
long dstAddr = target.getDataBufferAddress();
for(long addr = offsetAddr; addr < max; addr
+= STEP _ SIZE, dstAddr += SIZE){
PlatformDependent.putInt(dstAddr,
PlatformDependent.getInt(srcAddr + ((char)PlatformDependent.getShort(addr))
* SIZE));
}
} |
ШЗЖЈЯђСПЕФХњДЮДѓаЁ
ЯждкРДЬжТлЪЕМЪдѕУДШЗЖЈЯђСПДѓаЁЁЃDremioжаЕФШЮЮёЕЅдЊНаМЧТМХњДЮЛђЪ§ОнХњДЮЛђМЏЃЌгЩArrowФкДцЯђСПзщГЩЁЃУПИіЯђСПДњБэСЫЪ§ОнМЏжаЕФвЛИігђЛђвЛИіСаЃЌгЩЙЬЖЈЪ§СПЕФМЧТМЙЙГЩЁЃ
ЭМ6ЃКдкВщбЏдЫЫуЗћжаДЋЕнЕФМЧТМХњДЮ
МйЩшгавЛИіАйЭђЕФМЧТМЪ§ОнМЏКЯЁЃдкЭЌвЛЪБМфашвЊДІРэЕФЪЧдМ4800ИіМЧТМЕФМЧТМХњДЮЁЃМЧТМХњДЮЪЧдкдЫЫуЗћжЎМфЙмЕРжаСїЖЏЕФЪ§ОнЕЅдЊЁЃЯждкЃЌЙигкШчКЮЙЬЖЈвЛИіЪ§ОнХњДЮЕФМЧТМзмЪ§ЃЌгаКмЖрВЛЭЌЕФЗНАИЃЌИУЪ§ПЩФмЖрДя64,000ЁЃ
ПЩвдПДЕНЃЌДѓЕФХњДЮШнСПШч8000Лђ16,000ЪЕМЪЩЯПЩвдЬсЩ§аЇТЪЃЌвђЮЊЕЅЮЛШЮЮёдіМгСЫЃЌашвЊжиИДжДаавЛИіЙ§ГЬЕФДЮЪ§ОЭЛсНЕЕЭЁЃЕЋЪЧЃЌДѓЕФХњДЮвВЛсв§Ц№ЙмЕРЮЪЬтЃЌвђЮЊдЫЫуЗћжЎМфЪЕМЪДЋЕнЕФЪ§ОнСПвВдіМгСЫЁЃШЛЖјЪЙгУаЁЕФХњДЮДѓаЁЃЌШч128Лђ256ЃЌЫфШЛЕЅИіХњДЮЕФДІРэЛсБфПьЃЌдЫЫуЗћжЎМфДЋЕнЕФЪ§ОнЛсТ§КмЖрЃЌЕЋвђЮЊДІРэЙ§ГЬжиИДЕФОјЖдДЮЪ§КЭвЊДДНЈЕФЖдЯѓШнСПДѓЃЌЛсКмПьЕНДяВщбЏЕФЖбЖЅЁЃетвВЪЧЮЊЪВУДдкDremioжаЃЌЪЙгУЕНЕФБъзММЧТМХњДЮДѓаЁЪЧПЩХфжУЕФЃЌДѓЖрЪ§ЧщПіЯТЃЌетИіДѓаЁЮЊ4096ИіМЧТМЁЃ
ЭЈЙ§ХњДЮДѓаЁЃЌПЩвдЪЕМЪПижЦЮЊЯђСПЗжХфЕФФкДцЪ§СПЁЃдкexternal sortЃЌaggregationКЭjoinЕШдЫЫужаЃЌвЛЖЈвЊвтЪЖЕНдЫЫуЗћашвЊЙЄзїЕФФкДцЪ§СПЃЌЪЕМЪЩЯВЛФмвРРЕArrow
APIЬсЙЉЕФИјЯђСПЗжХфЕФШБЪЁФкДцЁЃ
дкФкДцЪмЯоЕФЧщПіЯТЃЌзаЯИХфжУЯђСПЕФХњДЮДѓаЁЃЌНјЖје§ШЗЕиИјетаЉМЧТМЗжХфФкДцЃЌетбљПЩвдаДГіФмКмКУЙЄзїЕФНЁзГЫуЗЈЁЃ
ЭЈГЃДЋЭГвтвхЕФбЙЫѕдкЪ§ОнПтКЭЦфЫќЯЕЭГШчLZOЃЌZLIBЕШжаЕФЪЙгУЪЧжиСПМЖЕФЃЌЖјбЙЫѕСаЪНИёЪНПЩвдЦНКтЪЙгУЩЯЕФЧсСПМЖКЭCPUгааЇбЙЫѕЗНАИЁЃДЋЭГбЙЫѕЫуЗЈЬсЙЉИќКУЕФбЙЫѕБШР§ЃЌЕЋЛсгАЯьCPUаЇТЪЃЌвђЮЊбЙЫѕКЭНтбЙЫѕдіМгСЫВщбЏЕФзмЪБМфЯћКФЁЃ
ArrowЕФзнСаИёЪНШУЮвУЧПЩвдЪЙгУЧсСПМЖЗНАИЃЌШчзжЕфБрТыЃЈdictionary encodingЃЉЁЂЮЛбЙЫѕЃЈbit
packingЃЉЃЌЛђЪЧГЄЖШБрТыЃЌКѓепПЩИљОнбЙЫѕБШР§ЕїећВщбЏадФмЁЃЦфДЮЃЌПЩвджБНгВйзїбЙЫѕКѓЕФСаЪНЪ§ОнЃЌетбљдкПЊЪМДІРэжЎЧАЃЌВЛашвЊЖдЫљгаЕФСаЪНЪ§ОнНјааНтбЙЫщЃЌВщбЏадФмОЭПЩвдЬсИпвЛИіЪ§СПМЖЁЃ
ЯТУцОйР§ЫЕУїдѕУДЖдПЩБфПэЖШСажЕНјааЪЙгУзжЕфБрТыЁЃ
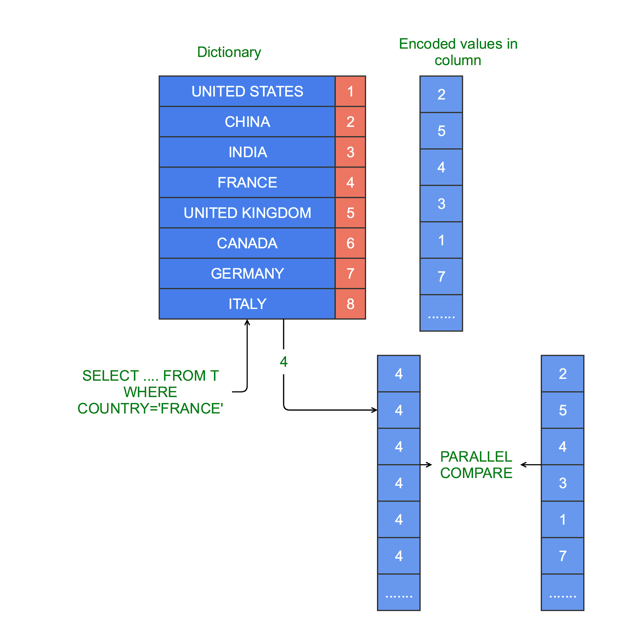
ЭМ7: ЪЙгУДјSIMDЕФзжЕфБрТыРДгааЇЖЯбдStringsЕФЙРжЕ
СаCOUNTRYгаUnited StatesЃЌChinaЃЌIndiaЃЌFranceКЭUnited
KingdomЕШЙњМвЃЌЦфГЄЖШЪЧПЩБфЕФЃЌашвЊБраДвЛИіЛљгкCOUNTRYЕФЙ§ТЫЕФВщбЏЁЃЖдИУСаНјаазжЕфБрТыЃЌЯёЙЬЖЈПэЖШЕФзжЕфБрТыжЕЕФЙ§ТЫЦївЛбљЃЌжиаДПЩБфГЄЖШзжЗћДЎЕФЙ§ТЫЦїЃЌетбљПЩвдгааЇЕФНјааЙ§ТЫДІРэЁЃ
SELECT C1, C2 FROM FOO WHERE COUNTRY=ЁЏFRANCEЁЏ
ЪзЯШВщдФзжЕфЃЌЕУЕНЁАFRANCEЁБЕФзжЕфБрТыжЕЮЊ4ЁЃМгдизжЕфжЕ4ЕНSIMFМФДцЦїЃЌШЛКѓМгдиЕФЫљгавбБрТыжЕЃЌЭЌЪББШНЯБрТыКѓЕФжЕКЭ4ЃЌДгЖјевГіИУЕЅдЊЯрЖдгкCOUNTRYСажЕЮЊЁАFRANCEЁБЕЅдЊЕФЮЛжУЃЈЛђЫїв§ЃЉЁЃ
етОЭЪЧзжЕфБрТыЕФЧПгаСІЕФЕиЗНЁЃЪЕМЪЩЯЃЌПЩвдбЙЫѕПЩБфГЄЖШСаПэЕФжЕЕНЙЬЖЈГЄЖШЕФзжЕфжЕЪ§зщжаЃЌШЛКѓДгаДВщбЏДІРэЫуЗЈЃЌИУЫуЗЈПЩвдЗЧГЃгааЇЕФдкетаЉбЙЫѕКѓЕФСажЕМфвРДЮЭЈЙ§ЁЃ
Ъ§ОнЗДЩф
ЮЊМгПьВщбЏЫйЖШЃЌDremioЪЙгУУћЮЊЪ§ОнЗДЩфЃЈData ReflectionЃЉЕФЬиадРДНјааЪ§ОнгХЛЏЁЃЪ§ОнЗДЩфдкДХХЬжаДцДЂЃЌЫќЪЙгУСаЪНЪ§ОнИёЪНЃЌВЩгУСЫParquetСаЪНДцДЂИёЪНЃЈApache
ParquetЃЉЁЃЕБДгЪ§ОнЗДЩфжаЖСШЁЪ§ОнЪБЃЌЛсДгParquetАбЪ§ОнМгдиЮЊЯргІЕФСаИёЪНЕНArrowЕФФкДцЃЌвдБудкжДаав§ЧцжаНјааДІРэЁЃ
Ъ§ОнЗДЩфЕФзюГѕЖСШЁЪЕМЪЪЧЛљгкааИёЪНЕФЁЃЫќЛљБОЪЧааЕМЯђЕФЖСШЁЃЌЭъШЋУЛгаРћгУдДЃЈДХХЬЃЉКЭФПБъЃЈФкДцЃЉЪ§ОнИёЪНЖМЪЧСаЪНЕФЧщПіЁЃ
вђДЫЮвУЧжиаДЖСШЁЮЊЭъШЋЕФЯђСПЛЏЖСШЁЃЌИУЙ§ГЬжаЃЌЮЊЛљгкСаЕФДІРэЁЃетЬсИпСЫСНЗНУцЕФДњТыаЇТЪЃЌМДДгДХХЬЖСШЁParquetвГЃЈбЙЫѕЙ§ЛђУЛгабЙЫѕЙ§ЕФЃЉКЭжиЙЙArrowСаЯђСПЁЃ
ЮвУЧвВЬсЙЉжЇГжParquetЩЈУшЕФЙ§ТЫЦїбЙШыЁЃдкВщбЏжаЕФЖЯбдФмжБНгбЙШыЕНParquetЩЈУшДњТыжаЃЌвђДЫдкжиЙЙArrowФкДцЯђСПЪБЃЌжЛашМгдиФкДцжаашвЊЕФСаЪ§ОнЁЃ
змНс
DremioЪЧЛљгкApache ArrowЕФПЊдДЪ§ОнДІРэПђМмЃЌОпгаЯђСПЛЏЬиадЁЃдкБОЮФжаЃЌдЮФзїепЬжТлСЫетаЉЬиадЕФжївЊЗНУцЃЌЯИНкЕФММЪѕЬжТлдкНёФъSan
JoseЕФStrata ConferenceжавбИјГіЁЃдкDrmioжаЃЌРЉеЙСЫArrowдкећИіФкДцдЫаав§ЧцЕФЪЙгУЁЃзюНќЃЌдЮФзїепЫљдкЭХЖгжиаДСЫArrowжаЕФДѓВПЗжJavaЪЕЯжЃЌЬсИпЦфадФмКЭЖбЪЙгУЁЃвЛаЉTPCHВщбЏЯдЪОбгГйНЕЕЭСЫ60%ЁЃЫћУЧМЦЛЎзіИќЖрЕФИФНјЃЌАќРЈБОЕиSIMDМгЫйПтЃЌВЂШЯЮЊЫќдкДІРэаЇТЪЩЯПЩвдгаМЋДѓЕФИФНјЁЃ | 







