| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫЭМЪ§ОнПтЯрЙижЊЪЖКЭЪєадЃЌЯЃЭћЖдФњгаЫљАяжњЁЃ
БОЮФРДздВЉПЭдАЃЌгЩЛ№СњЙћШэМўСѕшЁБрМЭЦМі
|
|
ЫцзХЩчНЛЁЂЕчЩЬЁЂН№ШкЁЂСуЪлЁЂЮяСЊЭјЕШаавЕЕФПьЫйЗЂеЙЃЌЯжЪЕЩчЛсжЏЦ№СЫСЫвЛеХХгДѓЖјИДдгЕФЙиЯЕЭјЃЌДЋЭГЪ§ОнПтКмФбДІРэЙиЯЕдЫЫуЁЃДѓЪ§ОнаавЕашвЊДІРэЕФЪ§ОнжЎМфЕФЙиЯЕЫцЪ§ОнСПГЪМИКЮМЖЪ§діГЄЃЌиНашвЛжжжЇГжКЃСПИДдгЪ§ОнЙиЯЕдЫЫуЕФЪ§ОнПтЃЌЭМЪ§ОнПтгІдЫЖјЩњЁЃ
ЪРНчЩЯКмЖржјУћЕФЙЋЫОЖМдкЪЙгУЭМЪ§ОнПтЁЃБШШчЃК
ЩчНЛСьгђЃКFacebook, TwitterЃЌLinkedinгУЫќРДЙмРэЩчНЛЙиЯЕЃЌЪЕЯжКУгбЭЦМі
СуЪлСьгђЃКeBayЃЌЮжЖћТъЪЙгУЫќЪЕЯжЩЬЦЗЪЕЪБЭЦМіЃЌИјТђМвИќКУЕФЙКЮяЬхбщ
Н№ШкСьгђЃКФІИљДѓЭЈЃЌЛЈЦьКЭШ№вјЕШвјаадкгУЭМЪ§ОнПтзіЗчПиДІРэ
ЦћГЕжЦдьСьгђЃКЮжЖћЮжЃЌДїФЗРеКЭЗсЬяЕШЖЅМЖЦћГЕжЦдьЩЬвРППЭМЪ§ОнПтЭЦЖЏДДаТжЦдьНтОіЗНАИ
ЕчаХСьгђЃКVerizon, OrangeКЭAT&T ЕШЕчаХЙЋЫОвРППЭМЪ§ОнПтРДЙмРэЭјТчЃЌПижЦЗУЮЪВЂжЇГжПЭЛЇ360
ОЦЕъСьгђЃКЭђКРКЭбХИпОЦЕъЕШЖЅМЖОЦЕъЙЋЫОвРЪЙгУЭМЪ§ОнПтРДЙмРэИДдгЧвПьЫйБфЛЏЕФПтДц
МШШЛЭМЪ§ОнПтгІгУетУДЙуЗКЃЌдНРДдНЖрЕФЦѓвЕКЭПЊЗЂепПЊЪМЪЙгУЫќЃЌФЧЫќОПОЙЪВУДЙ§ШЫжЎДІФиЃЌЯТУцЮвУЧРДНвПЊЫќЕФЩёУиУцЩДЁЃ
1. Why Graph DB?
бЇЙ§Ъ§ОнНсЙЙетУДПЮГЬЕФЭЌбЇФдКЃжагІИУЛђЖрЛђЩйгаЭМЕФИХФюЁЃ
1.1 ЪВУДЪЧЭМЃП
ЭМгЩСНИідЊЫизщГЩЃКНкЕуКЭЙиЯЕЁЃ
УПИіНкЕуДњБэвЛИіЪЕЬхЃЈШЫЃЌЕиЃЌЪТЮяЃЌРрБ№ЛђЦфЫћЪ§ОнЃЉЃЌУПИіЙиЯЕДњБэСНИіНкЕуЕФЙиСЊЗНЪНЁЃетжжЭЈгУНсЙЙПЩвдЖдИїжжГЁОАНјааНЈФЃ - ДгЕРТЗЯЕЭГЕНЩшБИЭјТчЃЌЕНШЫПкЕФВЁЪЗЛђгЩЙиЯЕЖЈвхЕФШЮКЮЦфЫћЪТЮяЁЃ
1.2 ЪВУДЪЧЭМЪ§ОнПтЃП
ЭМЪ§ОнПт(Graph database)ВЂЗЧжИДцДЂЭМЦЌЕФЪ§ОнПтЃЌЖјЪЧвдЭМетжжЪ§ОнНсЙЙДцДЂКЭВщбЏЪ§ОнЁЃ
ЭМаЮЪ§ОнПтЪЧвЛжждкЯпЪ§ОнПтЙмРэЯЕЭГЃЌОпгаДІРэЭМаЮЪ§ОнФЃаЭЕФДДНЈЃЌЖСШЁЃЌИќаТКЭЩОГ§ЃЈCRUDЃЉВйзїЁЃ
гыЦфЫћЪ§ОнПтВЛЭЌЃЌЙиЯЕдкЭМЪ§ОнПтжаеМЪзвЊЕиЮЛЁЃетвтЮЖзХгІгУГЬађВЛБиЪЙгУЭтМќЛђДјЭтДІРэЃЈШчMapReduceЃЉРДЭЦЖЯЪ§ОнСЌНгЁЃ
гыЙиЯЕЪ§ОнПтЛђЦфЫћNoSQLЪ§ОнПтЯрБШЃЌЭМЪ§ОнПтЕФЪ§ОнФЃаЭвВИќМгМђЕЅЃЌИќОпБэЯжСІЁЃ
ЭМаЮЪ§ОнПтЪЧЮЊгыЪТЮёЃЈOLTPЃЉЯЕЭГвЛЦ№ЪЙгУЖјЙЙНЈЕФЃЌВЂЧвдкЩшМЦЪБПМТЧСЫЪТЮёЭъећадКЭВйзїПЩгУадЁЃ
1.3 СНИіживЊЪєад
ИљОнДцДЂКЭДІРэФЃаЭВЛЭЌЃЌЪаУцЩЯЭМЪ§ОнПтвВгавЛаЉЧјЗжЁЃ
БШШчЃК
Neo4JОЭЪЧЪєгкдЩњЭМЪ§ОнПтЃЌЫќЪЙгУЕФКѓЖЫДцДЂЪЧзЈУХЮЊNeo4JетжжЭМЪ§ОнПтЖЈжЦКЭгХЛЏЕФЃЌРэТлЩЯЫЕФмИќгаРћгкЗЂЛгЭМЪ§ОнПтЕФадФмЁЃ
ЖјJanusGraphВЛЪЧдЩњЭМЪ§ОнПтЃЌЖјНЋЪ§ОнДцДЂдкЦфЫћЯЕЭГЩЯЃЌБШШчHbaseЁЃ
Ђй ЭМДцДЂ
вЛаЉЭМЪ§ОнПтЪЙгУдЩњЭМДцДЂЃЌетРрДцДЂЪЧОЙ§гХЛЏЕФЃЌВЂЧвЪЧзЈУХЮЊСЫДцДЂКЭЙмРэЭМЖјЩшМЦЕФЁЃВЂВЛЪЧЫљгаЭМЪ§ОнПтЖМЪЧЪЙгУдЩњЭМДцДЂЃЌвВгавЛаЉЭМЪ§ОнПтНЋЭМЪ§ОнађСаЛЏЃЌШЛКѓБЃДцЕНЙиЯЕаЭЪ§ОнПтЛђепУцЯђЖдЯѓЪ§ОнПтЃЌЛђЦфЫћЭЈгУЪ§ОнДцДЂжаЁЃ
Ђк ЭМДІРэв§Чц
дЩњЭМДІРэЃЈвВГЦЮЊЮоЫїв§СкНгЃЉЪЧДІРэЭМЪ§ОнЕФзюгааЇЗНЗЈЃЌвђЮЊСЌНгЕФНкЕудкЪ§ОнПтжаЮяРэЕижИЯђБЫДЫЁЃЗЧБОЛњЭМДІРэЪЙгУЦфЫћЗНЗЈРДДІРэCRUDВйзїЁЃ
2. ЖдБШ
2.1 гыNoSQLЪ§ОнПтЖдБШ
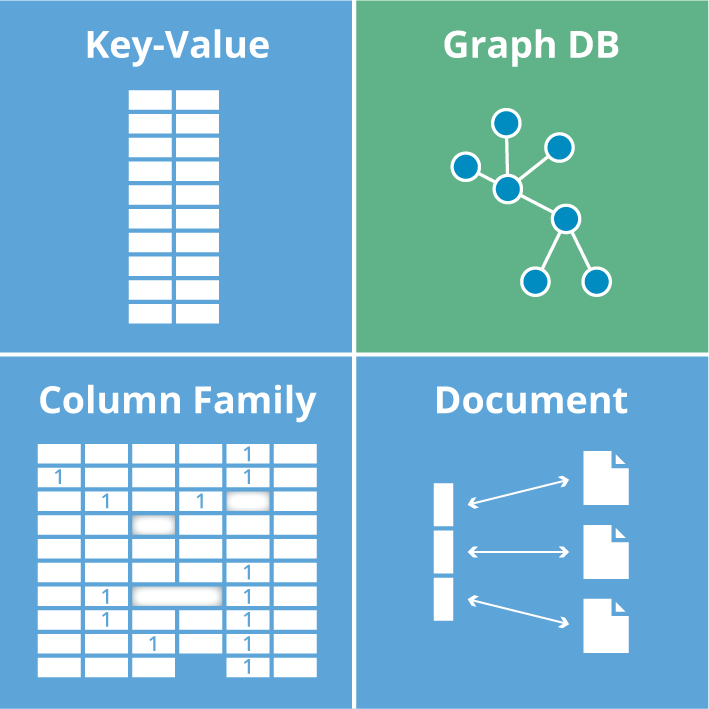
NoSQLЪ§ОнПтДѓжТПЩвдЗжЮЊЫФРрЃК
МќжЕ(key/value)Ъ§ОнПт
СаДцДЂЪ§ОнПт
ЮФЕЕаЭЪ§ОнПт
ЭМЪ§ОнПт
2.2 гыЙиЯЕаЭЪ§ОнПтЖдБШ
ЙиЯЕаЭЪ§ОнПтЪЕМЪЩЯЪЧВЛЩУГЄДІРэЙиЯЕЕФЁЃКмЖрГЁОАЯТЃЌФуЕФвЕЮёашЧѓЭъШЋГЌГіСЫЕБЧАЕФЪ§ОнПтМмЙЙЁЃ
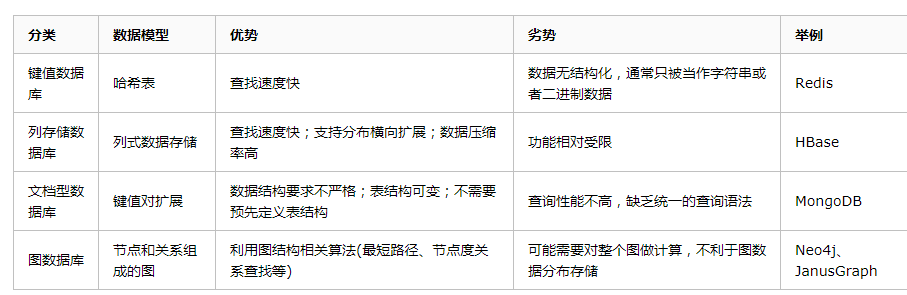
ОйИіРѕзгЃКМйЩшФГЙиЯЕаЭЪ§ОнПтжагаетУДМИеХгУЛЇЁЂЖЉЕЅЁЂЩЬЦЗБэЃК
ЕБЮвУЧвЊВщбЏЃКЁАгУЛЇЙКТђСЫФЧаЉЩЬЦЗЃПЁБ Лђеп ЁАИУЩЬЦЗгаФФаЉПЭЛЇЙКТђЙ§ЃПЁБ ашвЊПЊЗЂШЫдБJOINМИеХБэЃЌаЇТЪЗЧГЃЕЭЯТЁЃ
ЖјЁАЙКТђИУВњЦЗЕФПЭЛЇЛЙЙКТђСЫФФаЉЩЬЦЗЃПЁБРрЫЦЕФВщбЏМИКѕВЛПЩФмЪЕЯжЁЃ
ЙиЯЕВщбЏадФмЖдБШ
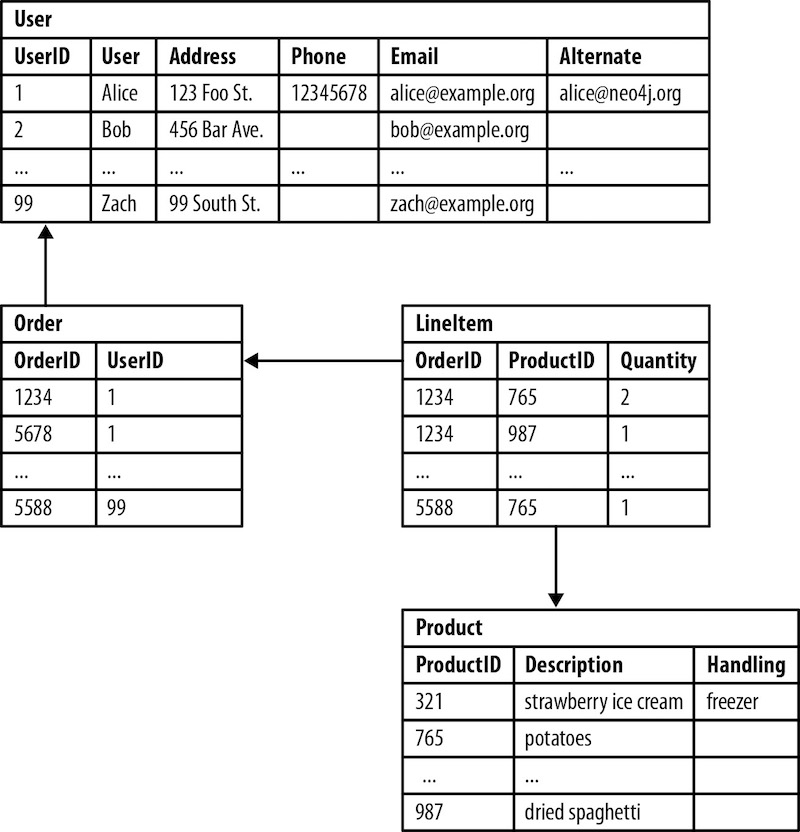
дкЪ§ОнЙиЯЕжааФЃЌЭМаЮЪ§ОнПтдкВщбЏЫйЖШЗНУцЗЧГЃИпаЇЃЌМДЪЙЖдгкЩюЖШКЭИДдгЕФВщбЏвВЪЧШчДЫЁЃдкЁЖNeo4j in ActionЁЗетБОЪщжаЃЌзїепдкЙиЯЕаЭЪ§ОнПт
КЭЭМЪ§ОнПт(Neo4j)жЎМфНјааСЫЪЕбщЁЃ
ЫћУЧЕФЪЕбщЪдЭМдквЛИіЩчНЛЭјТчРяевЕНзюДѓЩюЖШЮЊ5ЕФХѓгбЕФХѓгбЁЃЫћУЧЕФЪ§ОнМЏАќРЈ100ЭђШЫЃЌУПШЫдМга50ИіХѓгбЁЃЪЕбщНсЙћШчЯТЃК
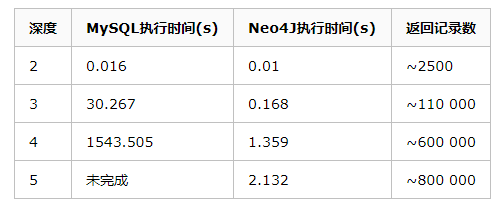
дкЩюЖШЮЊ2ЪБЃЈМДХѓгбЕФХѓгбЃЉЃЌСНжжЪ§ОнПтадФмЯрВюВЛЪЧКмУїЯдЃЛЩюЖШЮЊ3ЪБ(МДХѓгбЕФХѓгбЕФХѓгб)ЃЌКмУїЯдЃЌЙиЯЕаЭЪ§ОнПтЕФЯьгІЪБМф30sЃЌвбОБфЕУВЛПЩНгЪмСЫЃЛЩюЖШЕН4ЪБЃЌЙиЯЕЪ§ОнПташвЊНќАыИіаЁЪБВХФмЗЕЛиНсЙћЃЌЪЙЦфЮоЗЈгІгУгкдкЯпЯЕЭГЃЛЩюЖШЕН5ЪБЃЌЙиЯЕаЭЪ§ОнПтвбОЮоЗЈЭъГЩВщбЏЁЃЖјЖдгкЭМЪ§ОнПтNeo4JЃЌЩюЖШДг3ЕН5ЃЌЦфЯьгІЪБМфОљдк3УывдФкЁЃ
ПЩвдПДГіЃЌЖдгкЭМЪ§ОнПтРДЫЕЃЌЪ§ОнСПдНДѓЃЌдНИДдгЕФЙиСЊВщбЏЃЌдМгаРћгкЬхЯжЦфгХЪЦЁЃДгЩюЖШЮЊ4/5ЕФВщбЏНсЙћЮвУЧПЩвдПДГіЃЌЭМЪ§ОнПтЗЕЛиСЫећИіЩчНЛЭјТчвЛАывдЩЯЕФШЫЪ§ЁЃ
3. Neo4J КЭ JanuasGraph
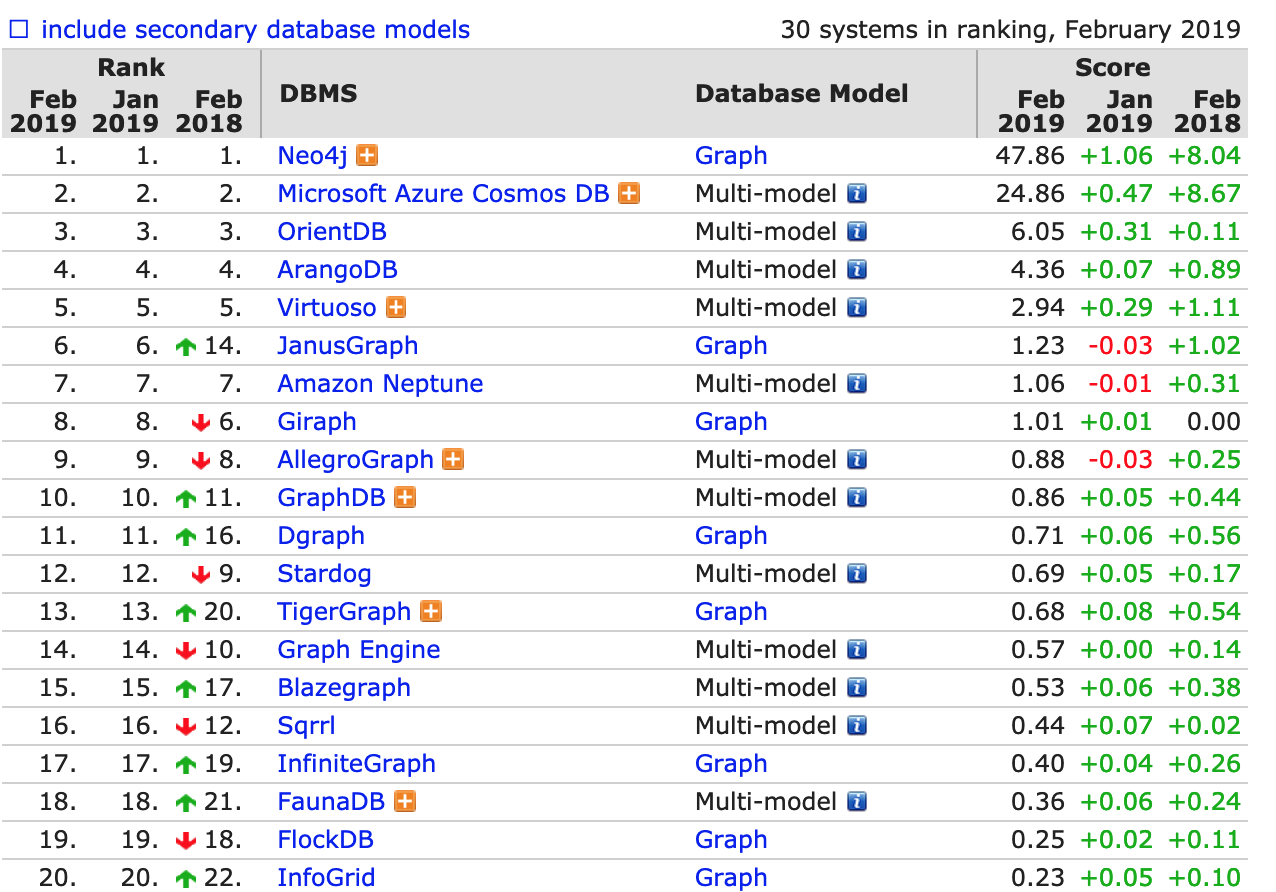
ИљОнDB-EnginesзюаТЗЂВМЕФЭМЪ§ОнПтХХУћЃЌNeo4JШдШЛДѓЗљСьЯШХХдкЕквЛЮЛЃК
Neo4J
Neo4JЪЧгЩJavaЪЕЯжЕФПЊдДЭМЪ§ОнПтЁЃзд2003ФъПЊЪМПЊЗЂЃЌжБЕН2007Фъе§ЪНЗЂВМЕквЛАцЃЌВЂЭаЙмгкGitHubЩЯЁЃ
Neo4JжЇГжACIDЃЌМЏШКЁЂБИЗнКЭЙЪеЯзЊвЦЁЃФПЧАNeo4JзюаТАцБОЮЊ3.5ЃЌЗжЮЊЩчЧјАцКЭЦѓвЕАцЃЌЩчЧјАцжЛжЇГжЕЅЛњВПЪ№ЃЌЙІФмЪмЯоЁЃЦѓвЕАцжЇГжжїДгИДжЦКЭЖСаДЗжРыЃЌАќКЌПЩЪгЛЏЙмРэЙЄОпЁЃ
JanusGraph
JanusGraphЪЧвЛИіLinuxЛљН№ЛсЯТЕФПЊдДЗжВМЪНЭМЪ§ОнПт ЁЃJanusGraphЬсЙЉApache2.0ШэМўаэПЩжЄЁЃИУЯюФПгЩIBMЁЂGoogleЁЂHortonworksжЇГжЁЃJanusGraphЪЧгЩTitanDB ЭМЪ§ОнПтаоИФЖјРДЃЌTitanDBДг2012ФъПЊЪМПЊЗЂЁЃФПЧАзюаТАцБОЮЊ0.3.1ЁЃ
JanusGraphжЇГжЖржжДЂДцКѓЖЫЃЈАќРЈApache CassandraЁЂApache HBaseЁЂBigtableЁЂBerkeley DBЃЉЁЃJanusGraphЕФПЩРЉеЙадШЁОігкгыJanusGraphвЛЦ№ЪЙгУЕФЛљДЁММЪѕЁЃР§ШчЃЌЭЈЙ§ЪЙгУApache CassandraзїЮЊДцДЂКѓЖЫЃЌПЩвдНЋJanusGraphМђЕЅЕиРЉеЙЕНЖрИіЪ§ОнжааФЁЃ
JanusGraphЭЈЙ§гыДѓЪ§ОнЦНЬЈЃЈApache SparkЃЌApache GiraphЃЌApache HadoopЃЉМЏГЩЃЌжЇГжШЋОжЭМЪ§ОнЕФЗжЮіЁЂБЈИцКЭETLЁЃ
JanusGraphЭЈЙ§ЭтВПЫїв§ДцДЂЃЈElasticsearchЃЌSolrЃЌLuceneЃЉжЇГжЕиРэЁЂЪ§зжЗЖЮЇКЭШЋЮФЫбЫїЁЃ
3.1 БъМЧЪєадЭМФЃаЭ
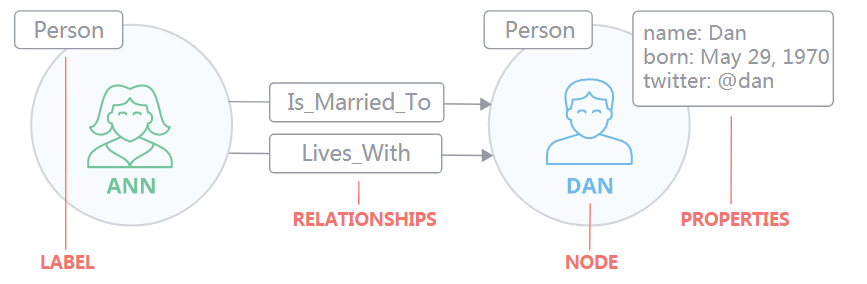
ЃЈ1ЃЉНкЕу
НкЕуЪЧжївЊЕФЪ§ОндЊЫи
НкЕуЭЈЙ§ЙиЯЕСЌНгЕНЦфЫћНкЕу
НкЕуПЩвдОпгавЛИіЛђЖрИіЪєадЃЈМДЃЌДцДЂЮЊМќ/жЕЖдЕФЪєадЃЉ
НкЕугавЛИіЛђЖрИіБъЧЉЃЌгУгкУшЪіЦфдкЭМБэжаЕФзїгУ
ЪОР§ЃКШЫдБНкЕугыCarНкЕу
ЃЈ2ЃЉЙиЯЕ
ЙиЯЕСЌНгСНИіНкЕу
ЙиЯЕЪЧЗНЯђадЕФ
НкЕуПЩвдгаЖрИіЩѕжСЕнЙщЕФЙиЯЕ
ЙиЯЕПЩвдгавЛИіЛђЖрИіЪєадЃЈМДДцДЂЮЊМќ/жЕЖдЕФЪєадЃЉ
ЃЈ3ЃЉЪєад
ЪєадЪЧУќУћжЕЃЌЦфжаУћГЦЃЈЛђМќЃЉЪЧзжЗћДЎ
ЪєадПЩвдБЛЫїв§КЭдМЪј
ПЩвдДгЖрИіЪєадДДНЈИДКЯЫїв§
ЃЈ4ЃЉБъЧЉ
БъЧЉгУгкНЋНкЕуЗжзщ
вЛИіНкЕуПЩвдОпгаЖрИіБъЧЉ
ЖдБъЧЉНјааЫїв§вдМгЫйдкЭМжаВщевНкЕу
БОЛњБъЧЉЫїв§еыЖдЫйЖШНјааСЫгХЛЏ
4. CypherЭМВщбЏгябд
CypherЪЧNeo4jЕФЭМаЮВщбЏгябдЃЌдЪаэгУЛЇДцДЂКЭМьЫїЭМаЮЪ§ОнПтжаЕФЪ§ОнЁЃ
ОйР§ЃЌЮвУЧвЊВщевJoeЕФЫљвдЖўЖШКУгбЃК
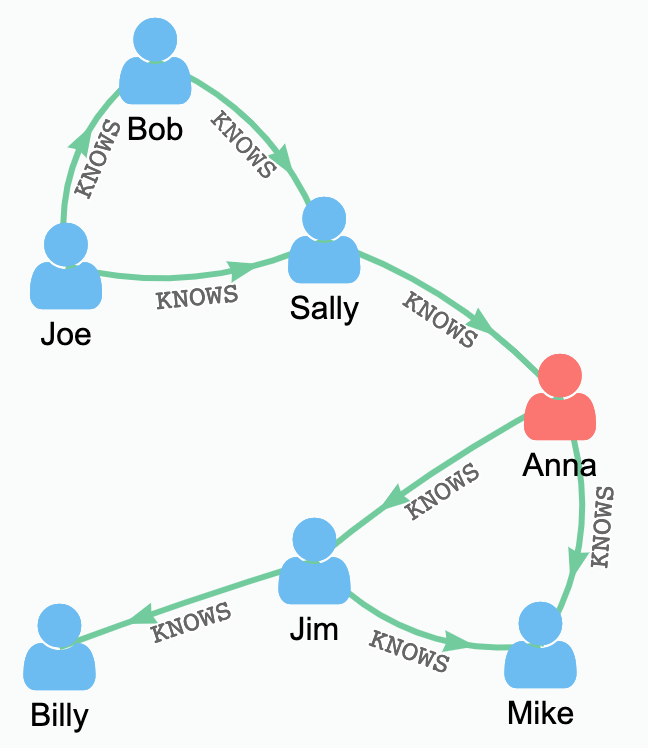
ВщбЏгяОфШчЯТЃК
MATCH
(person:Person)-[:KNOWS]-(friend:Person)-[:KNOWS]-
(foaf:Person)
WHERE
person.name = "Joe"
AND NOT (person)-[:KNOWS]-(foaf)
RETURN
foaf |
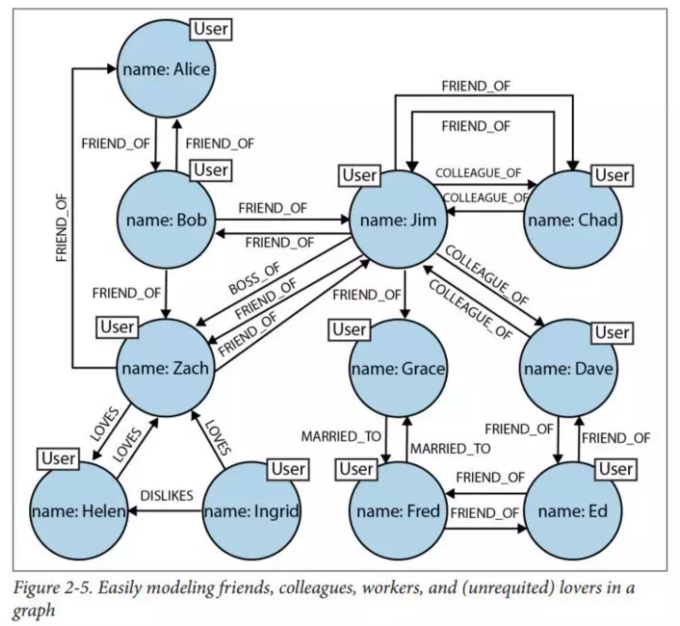
JoeШЯЪЖSallyЃЌSallyШЯЪЖAnnaЁЃ BobБЛХХГ§дкНсЙћжЎЭтЃЌвђЮЊГ§СЫЭЈЙ§SallyГЩЮЊЖўМЖХѓгбжЎЭтЃЌЫћЛЙЪЧвЛМЖХѓгбЁЃ
5. аЁНс
ЭМЪ§ОнПтгІЖдЕФЪЧЕБНёвЛИіКъЙлЕФЩЬвЕЪРНчЕФДѓЧїЪЦЃКЦОНшИпЖШЙиСЊЁЂИДдгЕФЖЏЬЌЪ§ОнЃЌЛёЕУЖДВьСІКЭОКељгХЪЦЁЃЙњФкдНРДдНЖрЕФЙЋЫОПЊЪМНјШыЭМЪ§ОнПтСьгђЃЌбаЗЂздМКЕФЭМЪ§ОнПтЯЕЭГЁЃЖдгкШЮКЮДяЕНвЛЖЈЙцФЃЛђМлжЕЕФЪ§ОнЃЌЭМЪ§ОнПтЖМЪЧГЪЯжКЭВщбЏетаЉЙиЯЕЪ§ОнЕФзюКУЗНЪНЁЃЖјРэНтКЭЗжЮіетаЉЭМЕФФмСІНЋГЩЮЊЦѓвЕЮДРДзюКЫаФЕФОКељСІЁЃ
| 







