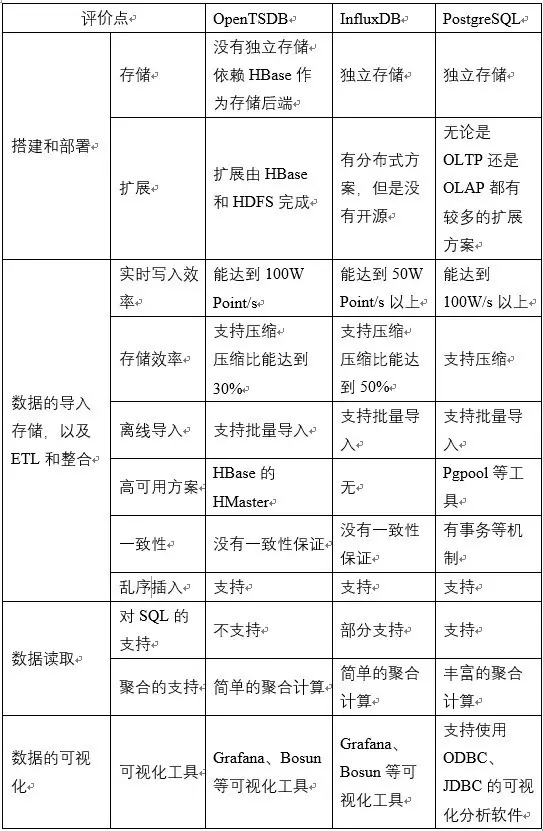
| БрМЭЦМі: |
ЮФеТжївЊНщЩмСЫЪЕЪБДІРэКЭеыЖдЪБађЪ§ОнгХЛЏДцДЂЕФOpenTSDBзщГЩЕФЙЄвЕЪ§ОнЦНЬЈЕФЯъЯИЗНАИЁЃ
БОЮФРДздгкЮЂаХЙЋжкКХIluvatarCoreXЃЌгЩЛ№СњЙћШэМўЮЂЮЂБрМЁЂЭЦМіЁЃ |
|
зюНќЃЌЪБМфађСаЪ§ОнПтЕФИХФюдНРДдНЛ№ЃЌЫќЪЧвЛжжУцЯђДјгаЪБМфађСааХЯЂЪ§ОнЕФгХЛЏДцДЂЗНАИЁЃН№ШкЙЩЦБЁЂIoTЁЂЛЅСЊЭјЁЂITЯЕЭГдЫЮЌЕШаавЕСьгђЕФКЃСПЪ§ОнВњЩњЪБОЭДјгаЪБМфађСаЬиеїЃЌвђДЫЫќУЧЗЧГЃЪЪКЯзїЮЊЪБађЪ§ОнПтЕФгІгУГЁОАЁЃ
дкеыЖдIoTаавЕПЭЛЇЩшМЦЪ§ОнДцДЂЗНАИЕФашЧѓЯТЃЌгЩгкЙЄвЕЪ§ОнЕФЬиЪтадЃЌЮвУЧЧуЯђЙизЂбЙЫѕБШЁЂЪЕЪБЖСаДЁЂРЉеЙет3ИіЦНЬЈФмСІЁЃ
ЁЄзЗЧѓИпбЙЫѕБШ
жЧФмжЦдьСьгђЕФЙЄвЕЪ§ОнжаЃЌДѓВПЗжГЁОАЪЧДІРэДЋИаЦїЕФЪЕЪБЪ§ОнЃЌЪ§ОнвдУыЩѕжСКСУыЕФЦЕЖШЪЕЪБВњЩњЁЃвЛИіДЋИаЦїУПУыЕФЪ§ОнАДее1ByteЕФВњЩњЃЌУПЬЈга1000ИіДѓаЭЩшБИЃЌУПУыОЭЪЧ1KзѓгвЕФЪ§ОнСПЃЌШчЙћга1000ЬЈЃЌФЧУДУПУыОЭЪЧ1MЃЌвЛЬьЕФЪ§ОнСПОЭНгНќ100GЁЃвђДЫЃЌЪ§ОнХђеЭДјРДЕФДцДЂбЙСІЃЌЪЧIoTаХЯЂЛЏКЭЪ§зжЛЏЗЂеЙЕФжївЊЭДЕуЁЃ
ЁЄЪЕЪБЖСаДаЇТЪ
ЙЄвЕЪ§ОнБОЩэДјгаЪЕЪБадЕФЬиЕуЃЌЭЌЪБвЕЮёвВЪЧЦЋЪЕЪБЕФЃЌБШШчЙЪеЯдЄВтЁЂЩшБИНЁПЕзДПіМрПиЕШЃЌвРРЕЪ§ОнЕФЪБаЇадЁЃЪЕЪБЖСаДЪЧТњзувЕЮёЕФЛљДЁЁЃ
ЁЄЦНЬЈЕФРЉеЙФмСІ
ЩшБИЕФИќаТЛЛДњвдМАвЕЮёЗЖЮЇЕФРЉДѓЃЌвЕЮёЪ§ОнСППЩФмдкЖЬЦкФкОЭгаЪ§БЖЕФдіГЄЃЌЖдДцДЂКЭМЦЫуЕФРЉеЙашЧѓвВЪЧИеадЕФЃЌЫљвдЮёБиГфЗжПМТЧЯЕЭГЕФРЉеЙадЁЃ
ГігквдЩЯПМТЧЃЌЪБађЪ§ОнПтгЩгкЦфЖдЪБМфађСаЪ§ОнЕФбЙЫѕЁЂЖдИпВЂЗЂЖСаДЕФжЇГжЃЌГЩЮЊЮвУЧдкЙЄвЕЪ§ОнДцДЂСьгђЕФЪзбЁЗНАИЁЃ
1.Ъ§ОнПтЕФбЁаЭ
ДгЪ§ОнПтбЁаЭБОЩэЃЌЮвУЧдкOpenTSDBЁЂInfluxDBЁЂPostgreSQL 3епжЎМфзіСЫБШНЯЁЃ
ПМТЧЕНOpenTSDBЕФЕзВуРЉеЙФмСІЃЌЮвУЧзюжебЁдёСЫOpenTSDBЁЃ
2.ЙигкOpenTSDB
OpenTSDBЪЧвЛИіjavaгябдПЊЗЂЕФПЊдДЪБађЪ§ОнПтЃЌЕзВуДцДЂвРРЕHBaseЁЃ
ШчOpenTSDBЙйЭјНщЩмЃЌга3ИіжївЊЕФЬиадЁЃ
ЁЄДјгаЪБМфаХЯЂЕФДцДЂ
ЁЄПЩРЉеЙЕФДцДЂКЭВЂЗЂаДФмСІ
ЁЄЬсЙЉHTTPНгПкКЭПЩЪгЛЏзщМў
OpenTSDBЬсЙЉREST APIзїЮЊЪ§ОнаДШыЕФНгПкЃЌЪЧвЛИіНщгкHBaseСаЪНДцДЂКЭвЕЮёЪ§ОнжЎМфЕФДцДЂжаМфМўЁЃЭЌЪБЃЌOpenTSDBвВЪЧвЛИігХауЕФHBaseПЭЛЇЖЫЃЌПЩвдИљОнздМКЕФбЙЫѕВпТдАбЪБађЪ§ОнГжОУЛЏЕНHBaseЁЃOpenTSDBЕФгІгУМмЙЙШчЯТЃК

ЭМ1ЃК OpenTSDBЕФМмЙЙ
ЖдOpenTSDBРДЫЕОЭЪЧ3ВуМмЙЙЃК
1ЁЂЪ§ОндДЃКРДздгкЛњЦїЁЂwebвГУцЕШЃЌЪЧЪ§ОнВЩМЏЕФЙ§ГЬ
2ЁЂTSDНјГЬЃКOpenTSDBЦєЖЏКѓЕФЪиЛЄНјГЬЁЃЭЈЙ§REST APIНгПкЛђепCLIНгПкЃЌOpenTSDBЕФTSDНјГЬЯьгІЗЂИјOpenTSDBЕФЪ§ОнЧыЧѓЁЃШЛКѓTSDНјГЬЭЈЙ§HBaseЕФREST
APIНгПкЯђHBaseаДШыЪ§ОнЛђепЖСШЁЪ§Он
3ЁЂHBaseЃКHBaseЯьгІTSDЗЂЦ№ЕФЧыЧѓЁЃ
ЪТЪЕЩЯЃЌOpenTSDBФкВПЗтзАСЫвЛИіHBaseПЭЛЇЖЫasynchbaseЁЃasynchbaseжЇГжвьВНЧыЧѓЃЌOpenTSDBЕУвдЮЌЛЄвЛИіrpc
queueЃЌХњСПЕФАбpointЗЂЫЭИјHBaseЃЌasynchbaseБЃжЄСЫOpenTSDBИпВЂЗЂЪЕЪБаДШыЪ§ОнЕФашЧѓЁЃ
вд1аЁЪБЕФЪ§ОнЮЊР§ЃЌдкЪЕМЪДцДЂЩЯЃЌOpenTSDBАб1аЁЪБЕФЪ§ОнећКЯГЩ1Иіkey-valueЖдЃЌДцЕНHBaseжаЁЃЮвУЧЖМжЊЕРHBaseЪЙгУЕФЙиМќОЭЪЧRowkeyЕФЩшМЦЃЌHBaseздМКАягУЛЇЩшМЦКУRowkeyвдМАДцДЂБэЁЃ
OpenTSDBЩњГЩЕФrowkey
[salt]<metric_uid><timestamp><tagk1><tagv1>[...<tagkN><tagvN>]
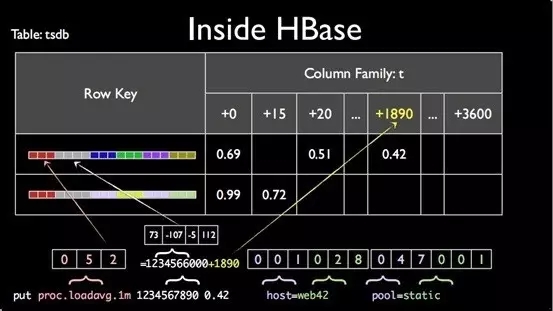
ЭМ2ЃКOpenTSDBдкHBaseжаЕФДцДЂНсЙЙ
ЭЌвЛИіmetricжаtagжЕЯрЭЌЕФЪ§Онвд1аЁЪБЮЊСЃЖШЪЙгУвЛИіЙВЭЌЕФrowkeyЃЌ3600ИіУыМЖЕФЪ§ОндђКЯВЂЕНвЛЦ№ЪЧзїЮЊ1ИіvalueЃЌOpenTSDBЕФбЙЫѕаЇЙћзюжївЊвђЮЊетИіЙ§ГЬЁЃ
ОпЬхЕФДцДЂбљР§ШчЯТЃК

3.ЛљгкOpenTSDBЕФЪЕЪБДцДЂМмЙЙ
дкЮвУЧЕФУцЯђЙЄвЕЪ§ОнЕФНтОіЗНАИжаЃЌOpenTSDBИпВЂЗЂаДЕФФмСІТњзуСЫЪЕЪБСїДІРэМмЙЙЖдЕзВуДцДЂЕФЪЕЪБаДвЊЧѓЁЃШчЯТЭМеЙЪОЕФећЬхММЪѕПђМмжаЃЌАќРЈСЫШежОВЩМЏЁЂШежОДІРэЁЂЪ§ОнДцДЂвдМАЪ§ОнЕМГігыеЙЪОЕШФЃПщЁЃ
Ъ§ОнЕФВЩМЏгыЗжЗЂЃКвЕЮёШэМўВњЩњЕФШежОЭЈЙ§Apache flume+KafkaЪеМЏКЭЗжЗЂ
Ъ§ОнСїДІРэЃКSparkStreamingЪЕЪБЕФДгKafkaжаЛёШЁЪ§ОнКЭМЦЫу
Ъ§ОнДцДЂЃКOpenTSDB+HBase+HDFSдкЯьгІ10W+вдЩЯЕФВЂЗЂаДЕФЭЌЪБЃЌРэТлЩЯФмЮоЯоЕФРЉеЙ
Ъ§ОнгІгУЃКдЄВтЁЂМрВтгыЗжЮі
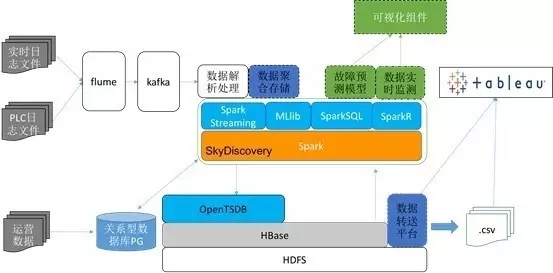
ЭМ3ЃКЛљгкOpenTSDBЕФЪЕЪБЙЄвЕЪ§ОнЦНЬЈ
Г§СЫгУOpenTSDBРДБЃДцЙЄвЕЪБађЪ§ОнЭтЃЌЙиЯЕаЭЪ§ОнПтзїЮЊвЕЮёЪ§ОнКЭЯЕЭГдЫааЪ§ОнЕФГжОУЛЏДцДЂЁЃНЋРДзїЮЊРЉеЙЃЌвВПЩвдЪЙгУЗжВМЪНЕФЙиЯЕаЭДцДЂЃЌзщГЩШкКЯЕФДцДЂЗНАИЁЃ
4.МмЙЙЯъЯИ
4.1 FlumeЪ§ОнЪеМЏ
Flume+KafkaЖМЪЧИпЭЬЭТЕФЪ§ОнЭЈЕРЃЌЕЅИіFlume ДњРэЕФЪеМЏФмСІФмДяЕН10MB/sЃЌ6ИіНкЕуЕФKafkaЭЬЭТФмДяЕН100MB/sвдЩЯЁЃ
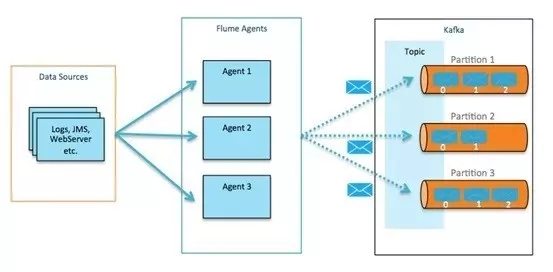
ЭМ4ЃКApache Flume+Kafak
ВЛЙмЪЧЗжВМЪНЕФЖрFlume ДњРэЛЙЪЧЖрВуДЮЕФFlume ДњРэНсЙЙЃЌЖМФмГжајРЉеЙЪ§ОнЪеМЏФмСІЁЃ
4.2 OpenTSDBЕФВЂЗЂДІРэФмСІ
KafkaКЭSparkЖМОпБИЗжВМЪНЕФРЉеЙФмСІЃЌOpenTSDBЫфШЛУЛгаИпПЩгУКЭМЏШКЗНАИЃЌЕЋЪЧвђЮЊУПИіНјГЬЖМПЩвдзїЮЊЖРСЂЕФЙЄзїНкЕуЃЌЫљвдПЩвддкИїИіSpark
WorkerЫљЪєЕФМЏШКЦєЖЏЖрOpenTSDBЪЕР§ЃЌДяЕНИКдиОљКтЕФаЇЙћЁЃ

ЭМ5ЃКOpenTSDBЕФЖрНкЕу
4.3 HBaseЕФRegionServer
гЩгкRegionServerМАЦфжаЕФregionПЩвдЗжЩЂаДЧыЧѓЃЌЫљвдHBaseФмЙЛИпВЂЗЂаДЁЃвђЮЊгаФкДцЛКДцЛњжЦЃЌдкШШЪ§ОнБЛflushЕНHDFSжаЪБЛсВњЩњНЯИпЕФIOЧыЧѓЃЌЫљвдКЯРэПижЦflushЕФНкзрЪЧЮЌГжHBaseадФмЮШЖЈадЕФЙиМќЁЃ
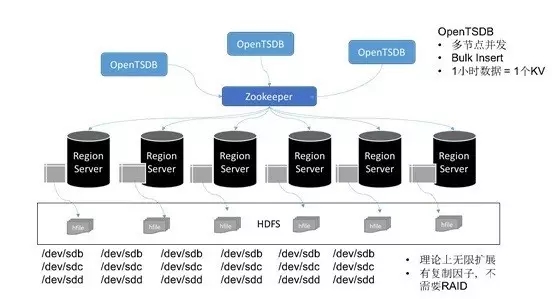
ЭМ6ЃКOpenTSDBЕФЕзВуДцДЂЗўЮё
4.4 OpenTSDBЕФЪ§ОнВщбЏ
зїЮЊвЛИіСаЪНДцДЂЕФNoSQLЪ§ОнПтЃЌOpenTSDBЪЙгУHBaseзїЮЊДцДЂЗНАИЃЌФмТњзуаДЕФЭЌЪБЃЌУцЖдРрЫЦПэБэЕФВщбЏГЁОАЃЌашвЊАбИїИіСаЪ§ОнКЯВЂГЩБэЃЌвђДЫвВДјРДСЫвЛаЉМЦЫуЯћКФЁЃ
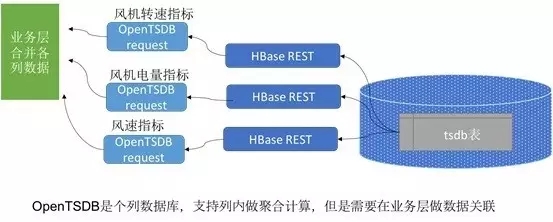
ЭМ7 OpenTSDBжаДцДЂЪ§ОнЕФЕМГі
ЮвУЧдкЪЕМЪгІгУжаЃЌУЛгаЪЕЯжJOINЃЌЖјЪЧШЁЧЩгкгаађЕФЪБМфЬиеїЃЌЪЙгУappendЕФЗНЪНАбЖрСаЪ§ОнЦДНгГЩвЛИіЖрСаЕФБэЁЃ
5ЃЎЕїгХгыадФм
ЮвУЧЪЙгУ6ИіНкЕуМЏШКЃЌОЙ§ИїЯюЕїгХКѓЃЌИїИізщМўЕФадФмЪ§ОнШчЯТЃК

6.змНс
БОЮФжаНщЩмЕФгЩЪЕЪБДІРэКЭеыЖдЪБађЪ§ОнгХЛЏДцДЂЕФOpenTSDBзщГЩЕФЙЄвЕЪ§ОнЦНЬЈЗНАИЃЌжЇГжИпВЂЗЂаДКЭЮоЯоЕФКсЯђРЉеЙЁЃЙЄвЕЪ§ОнЪЙгУЪБађЪ§ОнзїЮЊЭГвЛЕФЪ§ОнДцДЂБъзМЃЌОпБИЭЈгУадЁЃЗНАИжаЛЙгазХадФмЬсЩ§ЕФПеМфЃЛдкЪ§ОнЦНЬЈЛљДЁЩЯЃЌдіМгИќЖрЕФЪЕЪБЕФЪ§ОнЗўЮёЃЌВЂЧвЬсЙЉИпаЇЕФЪ§ОнВщбЏзщМўЃЌЪЧЮвУЧвдКѓЕФХЌСІЗНЯђЁЃ
| 







