| 编辑推荐: |
本文的主要目的还是以介绍为主,带你认识新技术,而更多的使用以及各种图形数据库之间的对比,优点缺点,希望对您有所帮助
本文来自于csdn,由火龙果软件琪琪编辑推荐 |
|
一、关系型数据库的不适性
在众多不同的数据模型里,关系数据模型自20世纪80年代就处于统治地位,而且出现了不少巨头,如Oracle、MySQL,它们也被称为:关系数据库管理系统(RDBMS)。然而,随着关系数据库使用范围的不断扩大,也暴露出一些它始终无法解决问题,其中最主要的是数据建模中的一些缺陷和问题,以及在大数据量和多服务器之上进行水平伸缩的限制。同时,互联网发展也产生了一些新的趋势变化:
用户、系统和传感器产生的数据量呈指数增长,数据量不断增加,大数据的存储和处理;
新时代互联网形势下的问题急迫性,这一问题因互联网+、社交网络,智能推荐等的大规模兴起和繁荣而变得越加紧迫。
而在应对这些趋势时,关系数据库产生了更多的不适应性,从而导致大量解决这些问题中某些特定方面的不同技术出现,它们可以与现有RDBMS相互配合或代替它们。过去的几年间,出现了大量新型数据库,它们被统称为NoSQL数据库。
二、NoSQL数据库的数据模型
NoSQL(Not Only SQL,不限于SQL)是一类范围非常广泛的持久化解决方案,它们不遵循关系数据库模型,也不使用SQL作为查询语言。其数据存储可以不需要固定的表格模式,也经常会避免使用SQL的JOIN操作,一般有水平可扩展的特征。
简言之,NoSQL数据库可以按照它们的数据模型分成4类:
键-值存储库(Key-Value-stores);
BigTable实现(BigTable-implementations);
文档库(Document-stores);
图形数据库(Graph Database);
在NoSQL四种分类中,图数据库从最近十年的表现来看已经成为关注度最高,也是发展趋势最明显的数据库类型。下图就是db-engines.com对最近三年来所有数据库种类发展趋势的分析结果:
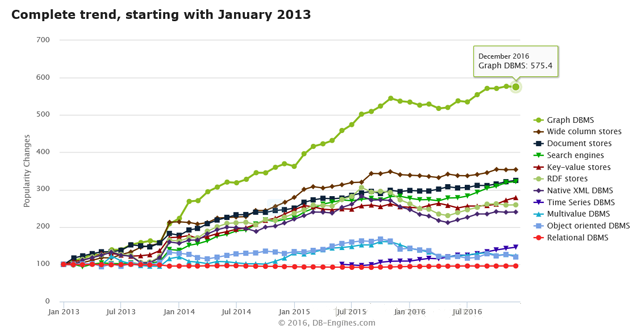
看到这里如果以前没有对图数据库有所了解的话可能还是一头雾水,图数据库到底是什么东西!下边我们首先通过一个小案例说一下使用图数据的紧迫性!
三、新时期互联网下什么最重要?
新时期的互联网下,对于一个公司什么最重要?当然是流量!一个初创公司只要有流量,就可以轻轻松松拿到投资,一个大型互联网只要有流量,就可以轻轻松松躺着赚钱!为了流量企业也是和移动运营商"相互勾结",推出了诸如:大王卡、大牛卡、宝卡、日租卡、平台应用免流卡等等,各种各样的手机SIM卡,唯一的目的不过就是圈人头!
为了圈人头各大公司也是绞尽脑汁,按照增长黑客的指导思想,病毒式的营销方案!利用各种高深算法像你推荐各种东西,例如:脉脉,职场中会向你推荐同一所高校毕业的同事,同一个家乡的同事等等,这些都属于二度人脉的推广!
如果把你的微信好友作为一度人脉的话,那么你微信好友的好友就属于你的二度人脉,而你微信好友的好友的好友就是你的三度人脉,画个图简单看一下(图A):
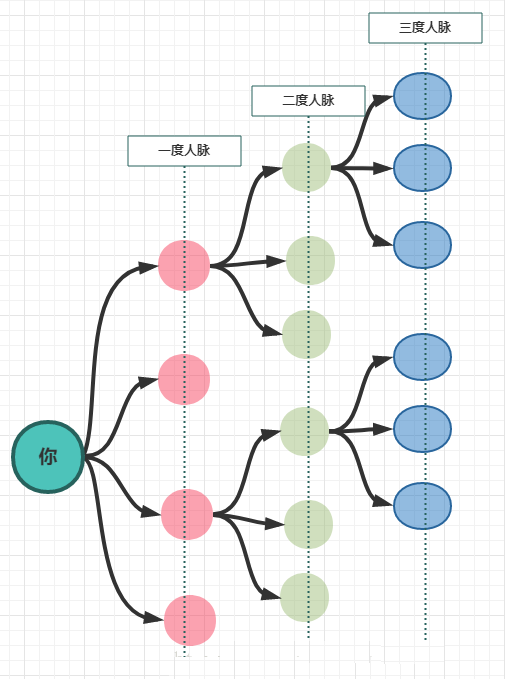
通常情况下我们所指的二度人脉基本都是一个泛指,泛指除了一度人脉之外的所有关联的人脉关系,如:三度、四度、五度甚至六度人脉等!
那么问题来了,如果让你实现推荐二度人脉这个功能,你会如何实现哪?
四、二度人脉推荐实现及对比
相信有一定基础的小伙伴都可以很轻松的实现一个推荐二度人脉的数据库表设计和代码实现。数据库首先有一个用户表user,用于表示用户的基本信息,然后一个有一个好友表user_friends,用于表示好友之间的关系。查找你的一度人脉就是直接根据你的用户ID到user_friends表中查找好友的ID;查找你的二度人脉是先根据你的用户ID去user_friends表中先查出来你的一度人脉,然后得到所有一度人脉的用户ID,然后根据这些所有一度人脉的用户ID再去user_friends中查找他的好友!那么如果让你查找三度、四度、五度人脉哪?哇!想都不敢想!一个复杂的人脉关系网例如图B:
如果你确实厉害,对于上述查找三度、四度、五度人脉都是小意思!那么帮忙查一个五度范围内和我是同一个家乡的好友!注意:这里加了一个附加属性“同一个家乡”!可能此时你还认为这是一件简单的事,也不过是先把所有的五度范围内的人脉找出来,然后在搜索一下和我是同一个家乡的而已!
厉害了!可能此时你的代码已经完成,然后准备测试!但是,此时的结果可能会让你失望!查询的效率可能会极低极低!完全是一个无法接受的范围!(后边会有测试看结果!)
有想法的小伙伴可能已经注意了,利用自己所学的知识,图B不就是一张我们数据结构中的有向图吗?而搜索二度人脉、三度人脉等不就相当于图的一个节点到达另一个节点的路径为2、为3的搜索吗?而图的搜索常用的算法不就是深度优先算法、广度优先算法、迪克拉斯算法吗?
看到这里,感觉到你已经领略到图数据库的精髓了!图数据库可以很轻松的实现上述二度人脉、三度人脉等的查询。
有一个很有意思的测试,一种是通过关系型数据实现上述功能,一种是通过图数据库实现上述功能,测试的案例是:我们希望在一个社交网络里找到最大深度为5的朋友的朋友。假设随机选择两个人,是否存在一条路径,使得关联他们的关系长度最多为5?对于一个包含100万人,每人约有50个朋友的社交网络, 图数据库与关系型数据库执行时间对比:
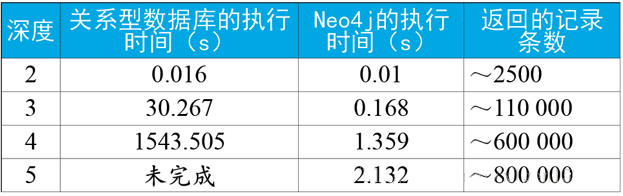
在深度为2时(即朋友的朋友),假设在一个在线系统中使用,无论关系型数据库还是图数据库,在执行时间方面都表现得足够好。虽然Neo4j的查询时间为关系数据库的2/3,但终端用户很难注意到两者间毫秒级的时间差异。当深度为3时(即朋友的朋友的朋友),很明显关系型数据库无法在合理的时间内实现查询:一个在线系统无法接受30s的查询时间。相比之下,Neo4j的响应时间则保持相对平坦:执行查询仅需要不到1s,这对在线系统来说足够快了。
在深度为4时,关系型数据库表现出很严重的延迟,使其无法应用于在线系统。Neo4j所花时间也有所增加,但其时延在在线系统的可接受范围内。最后,在深度为5时,关系型数据库所花时间过长以至于没有完成查询。相比之下,Neo4j则在2 s左右的时间就返回了结果。在深度为5时,事实证明几乎整个网络都是我们的朋友,因此在很多实际用例中,我们可能需要修剪结果,并进行时间控制。
将社交网络替换为任何其他领域时,你会发现图数据库在性能、建模和维护方面都能获得类似的好处。无论是音乐还是数据中心管理,无论是生物信息还是足球统计,无论是网络传感器还是时序交易,图都能对这些数据提供强有力而深入的理解。
而关系型数据库对于超出合理规模的集合操作普遍表现得不太好。当我们试图从图中挖掘路径信息时,操作慢了下来。我们并非想要贬低关系型数据库,它在所擅长的方面有很好的技术能力,但在管理关联数据时却无能为力。任何超出寻找直接朋友或是寻找朋友的朋友这样的浅遍历查询,都将因为涉及的索引数量而使查找变得缓慢。而图数据库由于使用的是图遍历技术,所需要计算的数据量远小于关系型数据库,所以非常迅速。
此时,我们还没有真正的了解到底什么是图数据库,但是我们已经可以领略到图数据库的威力了!
五、揭开图数据库的面纱
图数据库源起欧拉和图理论,也可称为面向/基于图的数据库,对应的英文是Graph Database。图数据库的基本含义是以“图”这种数据结构存储和查询数据,而不是存储图片的数据库。它的数据模型主要是以节点和关系(边)来体现,也可处理键值对。它的优点是快速解决复杂的关系问题。
图具有如下特征:
包含节点和边;
节点上有属性(键值对);
边有名字和方向,并总是有一个开始节点和一个结束节点;
边也可以有属性。
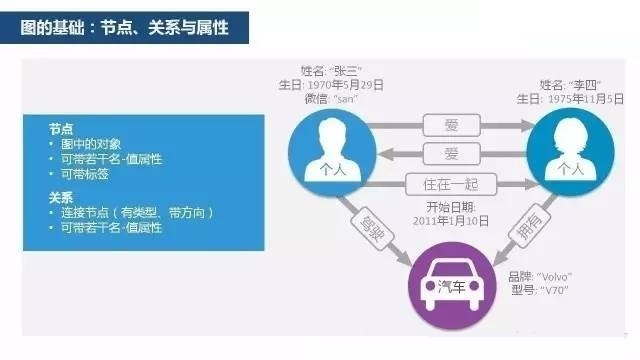
说得正式一些,图可以说是顶点和边的集合,或者说更简单一点儿,图就是一些节点和关联这些节点的联系(relationship)的集合。
通常,在图计算中,基本的数据结构表达就是:
G=(V, E)
V=vertex(节点)
E=edge(边) |
如下图所示:
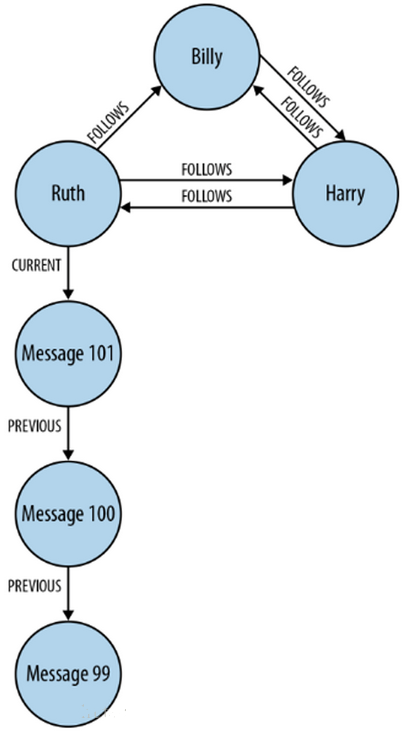
图数据库名字的由来其实与其在底层的存储方式有关,Neo4j底层会以图的方式把用户定义的节点以及关系存储起来,通过这种方式,可以高效的实现从某个节点开始,通过节点与节点间关系,找出两个节点间的联系。
从这段描述中可以猜得到,在Neo4j中最重要的两个元素就是节点和关系。说到节点和关系,就必须引出一个非常重要的概念,属性图模型(Property Graph Model)。如下所示:
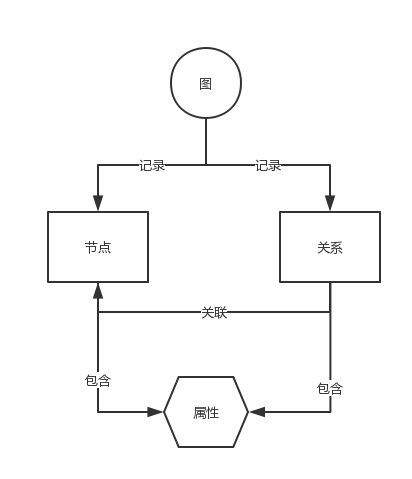
一个图中会记录节点和关系;
关系可以用来关联两个节点 ;
节点和关系都可以拥有自己的属性;
可以赋予节点多个标签(类别);
六、图数据库的代表Neo4j
目前市面上有很多图数据库,例如:Neo4J、ArangoDB、OrientDB、FlockDB、GraphDB、InfiniteGraph、Titan、Cayley等,但目前较为活跃可以称之为代表的当属Neo4j。
Neo4j官方地址:https://neo4j.com/
Neo4j的安装使用很简单,如果是Window平台的话直接安装就可以,然后配置一下环境变量即可使用!这里不再介绍,下边看一下简单使用。
1,Neo4j浏览器:
Neo4j服务器具有一个集成的浏览器,在一个运行的服务器实例上访问 “http://localhost:7474/”,打开浏览器,显示启动页面:

默认的host是bolt://localhost:7687,默认的用户是neo4j,其默认的密码是:neo4j,第一次成功登陆到Neo4j服务器之后,需要重置密码。访问Graph Database需要输入身份验证,Host是Bolt协议标识的主机。
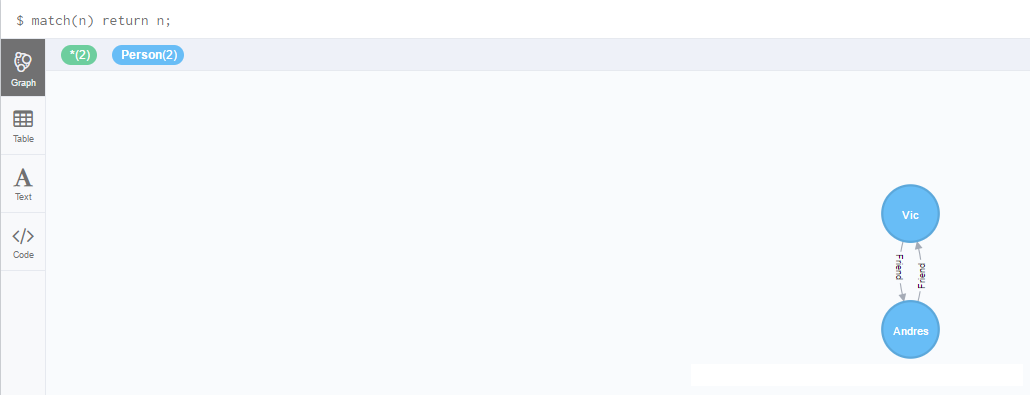
2,在Neo4j浏览器中创建节点和关系:
示例,编写Cypher命令,创建两个节点和两个关系:
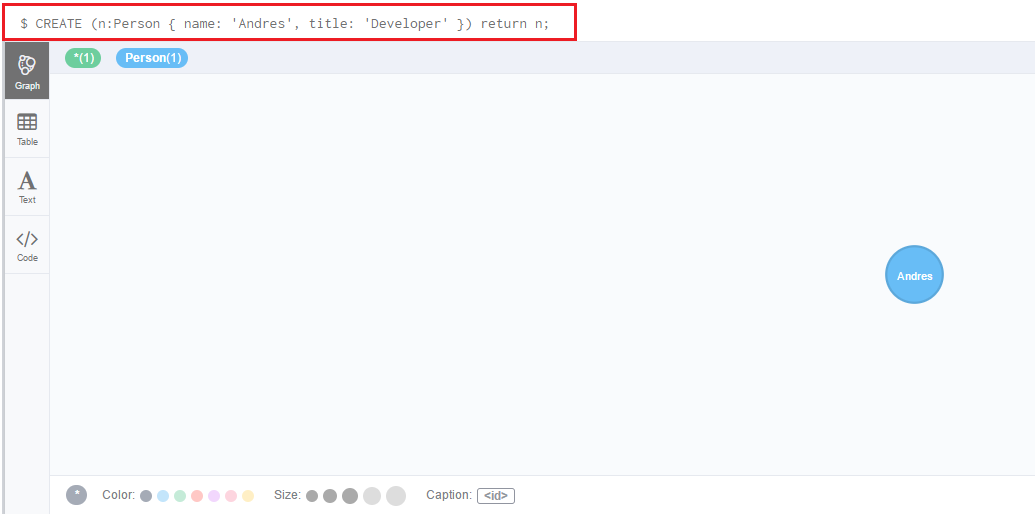
CREATE (n:Person
{ name: 'Andres', title: 'Developer' }) return
n;
CREATE (n:Person { name: 'Vic', title: 'Developer'
}) return n;
match(n:Person{name:"Vic"}),(m:Person{name:"Andres"})
create (n)-[r:Friend]->(m) return r;
match(n:Person{name:"Vic"}),(m:Person{name:"Andres"})
create (n)<-[r:Friend]-(m) return r; |
在$ 命令行中,编写Cypher脚本代码,点击Play按钮,点击创建第一个节点:

3、在第一个节点创建之后,在Graph模式下,能够看到创建的图形,继续编写Cypher脚本,创建其他节点和关系:
4、在创建完两个节点和关系之后,查看数据库中的图形:
七、总结
图数据库它善于处理大量的、复杂的、互联的、多变的网状数据,其效率远远高于传统的关系型数据库的百倍、千倍甚至万倍。图数据库特别适用于社交网络、实时推荐、银行交易环路、金融征信系统等广泛的领域。领英、沃尔玛、CISCO、HP、eBay等全球知名企业都在使用图数据库Neo4j,中国企业也在逐步开始用图数据库来构建自己的应用。
| 







