| БрМЭЦМі: |
БОДЮЕФЗжЯэДѓИйЗжГЩ3ИіВПЗжЃЌЧАУцЯШНВЮвУЧдкNoSQLЩЯШЁЕУЕФГЩЙІЃЌШЛКѓНВШчКЮбнБфЕНNewSQLЃЌзюКѓНВетИібнНјЗНАИЕФШБЯнЃЌжИГіЮДРДЕФбнНјЗНЯђЁЃ
БОЮФРДздITPUBВЉПЭЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
ДѓМвЖМжЊЕРЃЌNewSQL ЪЧЖдИїжжаТаЭЪ§ОнПтЕФМђГЦЃЌетРрЪ§ОнПтВЛНіОпгаNoSQLЖдКЃСПЪ§ОнДІРэЕФИпРЉеЙФмСІКЭИпЭЬЭТФмСІЃЌЛЙОпгаДЋЭГЪ§ОнПтЕФЪТЮёФмСІКЭSQLФмСІЁЃ
ФЧУДдквЛЬзГЩЪьЕФNoSQLЯЕЭГЩЯЃЌЪЧЗёПЩвдЗѕЛЏГіNewSQLЯЕЭГРДФиЃПД№АИЪЧПЯЖЈЕФЁЃ
вђЮЊдкЕЮЕЮЃЌОЭгаетУДвЛИіГЩЪьЕФздбаЕФNoSQLЯЕЭГFusionЃЌЛљгкЫћжЎЩЯЮвУЧГЩЙІЗѕЛЏСЫNewSQLЯЕЭГЁЃ

НгЯТРДЃЌЯШПДБОДЮЗжЯэЕФДѓИйИХЪіЃЌШчЯТЁЃ

етПщЪЧЮвУЧЫљгаДцДЂВњЦЗЕФећЬхМмЙЙЪгЭМЃЌЮвУЧЕФВњЦЗЖМЪЧдкRocksDBв§ЧцВуЛљДЁжЎЩЯЙЙНЈЁЃЪзЯШдіМгСЫЭјТчВуЁЂМЏШКЙмРэВуЁЂНгШыВуЕФЙЄзїЃЌЙЙНЈСЫЮвУЧЕФNoSQLДцДЂЯЕЭГFusionЃЌШЛКѓдкFusionЕФЛљДЁжЎЩЯЃЌЮвУЧећКЯСЫЕЮЕЮЕФЕїЖШЯЕЭГКЭHadoopМЦЫуЦНЬЈЕФФмСІЃЌЙЙНЈСЫЮвУЧЕФDTSЗўЮёFastLoadЃЛЕк3ПщЪЧдкFusionЕФЛљДЁЩЯЃЌдіМгСЫschemaЙмРэЁЂЖўМЖЫїв§ЁЂЪТЮёЁЂbinlogЕШФмСІЃЌЙЙНЈСЫЮвУЧЕФNewSQLДцДЂdiseЃЛЕк4ПщЪЧУцЯђЮДРДЙцЛЎЕФЗжВМЪНЪ§ОнПтЁЃЮЇШЦетаЉКЫаФЗўЮёЃЌЮвУЧзіСЫвЛЬзЭъЩЦЕФжЧФмЙмПиЯЕЭГЃЌЫќЪЧвРЭагкsalt-stackЦНЬЈЃЌЪЕЯжСЫгУЛЇЯЕЭГКЭдЫЮЌЯЕЭГЃЌЗжБ№НтОіСЫгУЛЇНгШыЮЪЬтКЭздЖЏЛЏдЫЮЌЕФЮЪЬтЁЃ
НгЯТРДЃЌЮвУЧДгNoSQLНВЦ№ЁЃ
ЕквЛеТЃКГЩЪьЕФNoSQLДцДЂЯЕЭГFusion
етПщЪзЯШНВFusionЕФБГОАНщЩмЁЃПЩвдПДЕНFusionЪЧгУC++здбаЕФЗжВМЪНNoSQLЪ§ОнПтЃЌжЇГжRedisавщЃЌЪ§ОнЭЈЙ§RocksDBТфХЬЃЌЯждкЯпЩЯвЕЮёвбОНгШы400ЖрИівЕЮёЃЌИВИЧСЫШЋЙЋЫОЃЛЕБЧАЯпЩЯЙцФЃЪЧ300ЖрИіМЏШКЃЌШЋздЖЏЛЏдЫЮЌХмзХЃЌУЛгазЈУХЕФOPШЫдБВЮгыЃЌзмЪ§ОнСПДяЕН1500TBЃЌЗхжЕQPSГЌЙ§1400WЁЃ

НгЯТРДНВFusionЕФМмЙЙЃЌШчЯТЁЃНВМмЙЙжЎЧАЃЌЯШПДFusionЕФЕЎЩњБГОАЃЌЫћЕЎЩњГѕЦкжївЊНтОіСНИівЕЮёЕФЪ§ОнДцДЂЃКРњЪЗЖЉЕЅКЭЫОЛњааГЬЙьМЃЁЃДѓМвЖМжЊЕРЕЮЕЮЪЧИіУПЬьЖЉЕЅЧЇЭђМЖЕФвЕЮёЃЌФЧУДРњЪЗЖЉЕЅКмПьОЭЛсЭЛЦЦАйвкМЖЃЌЖјУПЬѕЖЉЕЅЖМЛсЖдгІвЛЬѕЫОЛњааГЬЙьМЃЃЌЖјЧвДђГЕОрРыдНГЄЃЌЕЅЬѕааГЬЙьМЃЪ§ОндНДѓЃЌетЪЧвЛИіБШРњЪЗЖЉЕЅЪ§ОнСПИќДѓЕФвЕЮёЁЃдкFusionЕЎЩњжЎЧАЃЌЕЮЕЮЕФДцДЂжївЊЪЧгУRedisКЭMySQLЃЌКмЯдШЛдкетжжЙцФЃЯТЕФЪ§ОнСПЃЌгУRedisКЭMySQLВЂВЛЪЧзюгХНтЁЃвђДЫЕЎЩњСЫFusionЁЃ
вђЮЊRedisЕФавщЪЕЯжКмМђЕЅЃЌЧвЪ§ОнНсЙЙЗЧГЃЗсИЛЃЌвђДЫЮвУЧдкДХХЬЩЯШЅЪЕЯжСЫRedisЕФДцДЂНсЙЙЃЌЛљгкетбљЕФКЫаФЫМЯыЃЌЮвУЧЪЕЯжСЫFusionЕФМЏШКМмЙЙЃЌДгЩЯЭљЯТЗжБ№ЪЧНгШыВуЁЂМЏШКЙмРэВуЁЂГжОУВуЁЂИпПЩгУВуЁЃ

НгЯТРДЃЌзмНсСЫ5ИіССЕуЃЌЬєЦфжа4ИіРДЫЕУїFusionЕФВњЦЗГЩЪьЖШЃЌШчЯТЃК

ССЕу1ЃКЪ§ОнСїЖЏ
ЕквЛИіЪЧЪ§ОнСїЖЏФмСІЁЃзіЮЊвЛИіздбаЕФДцДЂЯЕЭГЃЌЫћБиаыШкШыећИіЙЋЫОЕФПЊЗЂЩњЬЌЃЌОпБИгыЦфЫћДцДЂЯЕЭГЁЂжаМфМўЁЂРыЯпМЦЫуЁЂЪЕЪБМЦЫуЕШЦНЬЈДђЭЈЕФФмСІЃЌВХФмЭЦЙуПЊЁЃвђДЫЃЌЮвУЧдкетЗНУцзіСЫКмЖрЙЄзїЃЌЦфжаЬєhiveЕНFusionДђЭЈЃЌвдМАFusionгыFusionжЎМфДђЭЈЕФР§згРДеЙПЊНщЩмЁЃ

ЮЊСЫНтОіРыЯпhiveЕНFusionЕФЪ§ОнСїЖЏЃЌЮвУЧзіСЫвЛеОЪНDTSЦНЬЈFastLoadЃЌЦфМмЙЙЩшМЦШчЯТЃК
ЪзЯШЃЌЫћЕЎЩњГѕЦкЪЧЮЊСЫНтОіБъЧЉЦНЬЈКЭЬиеїЦНЬЈЕФвЕЮёЮЪЬтЁЃетСНИівЕЮёЕФЪ§ОнЪЧЭЈЙ§РыЯпМЦЫуВњЩњЃЌвђДЫЪ§ОнЪЧДцЗХдкhiveЩЯЃЌКмЯдШЛhiveЕФгХЪЦВЂВЛЪЧOLTPЁЃ
вђДЫЫћУЧЯЃЭћгаИіДцДЂЯЕЭГФмЙЛТњзуСНИіашЧѓЃК
1. жЇГХУПЬьЪ§АйвкДЮЕФИпЫйВщбЏЃЛ
2. жЇГжЫћУЧПьЫйЕФДгРыЯпИќаТTBМЖБ№ЕФЪ§ОнЕНдкЯпЁЃ
КмЯдШЛFusionКмШнвзТњзуЕквЛИіашЧѓЁЃФЧУДЕкЖўИіашЧѓШчКЮНтОіФиЃПвЕЮёКмШнвзЯыЕНЕФАьЗЈЪЧЃКБщРњЖСШЁhiveЕФЪ§ОнЃЌШЛКѓЙЙдьГЩвЛЬѕЬѕRedisавщжЇГжЕФKVЪ§ОнЃЌШЛКѓЕїгУRedisПЭЛЇЖЫаДЕНЮвУЧЕФVIP->proxy->FusionЁЃећИіЙ§ГЬСДТЗБШНЯГЄЃЌзмНсЯТга3ИіКЫаФЭДЕуЃК
РЫЗббаЗЂзЪдДЁЃЗВЪЧгаДгhiveЕНFusionЪ§ОнДђЭЈЕФвЕЮёЃЌЖМЕУЮЌЛЄвЛЬзЯрЭЌТпМЕФДњТыЁЃ
ФбвдБЃжЄЮШЖЈадЁЃРыЯпЦНЬЈвтЮЖзХИпЭЬЭТЁЂИпВЂЗЂЃЌгУЫќЭљдкЯпЪ§ОнПтЙрЪ§ОнЃЌЯдШЛЕУзЂвтСїПиКЭДэЗхЃЌвђДЫЮШЖЈадФбвдБЃжЄЁЃ
ЩњВњаЇТЪЕЭЁЃвЕЮёЪЙгУRedisавщЕФЗНЪНЙрПтЃЌКмЖрbatchКЭбЙЫѕФмСІЖМУЛЗЈгУЩЯЁЃ

ЛљгкЩЯЪіЕФвЕЮёашЧѓКЭКЫаФЭДЕуЃЌЮвУЧзіСЫFastLoadвЛеОЪНDTSЦНЬЈЁЃЫќжївЊИјRDЁЂВњЦЗОРэЕШгУЛЇЬсЙЉЗўЮёЃЌвђДЫЬсЙЉСЫСНжжНгШыЗНЪНЃКweb
consoleКЭopen APIЁЃгУЛЇЭЈЙ§етСНжжЗНЪНЃЌАбFastLoadШЮЮёЩЯДЋЕНЮвУЧЗўЮёЦїЃЌШЛКѓЗўЮёЦїЛсзЂВсвЛИіЕїЖШШЮЮёЃЌИУЕїЖШШЮЮёЭЈЙ§гУЛЇДЋШыВЮЪ§ЃЌХаЖЈЪ§ОндДЃЌШЛКѓДгЪ§ОндДРЬШЁФПБъЪ§ОнЃЌдйАбФПБъЪ§ОнЗжЦЌЭЈЙ§may/reduceзіХХађЃЌЙЙНЈSSTЮФМўЃЌШЛКѓЭЈЙ§TCPавщЕФЗНЪНЯТдиЕНFusionДцДЂНкЕуЃЌШЦЙ§proxyЃЌРћгУRocksDBЕФingestЙІФмЃЌМгдиЕНFusionЕБжаЃЌдйЭЈжЊгУЛЇЃЌгУЛЇОЭПЩвдЭЈЙ§RedisавщЖСЕНЕМШыЕФЪ§ОнСЫЁЃ
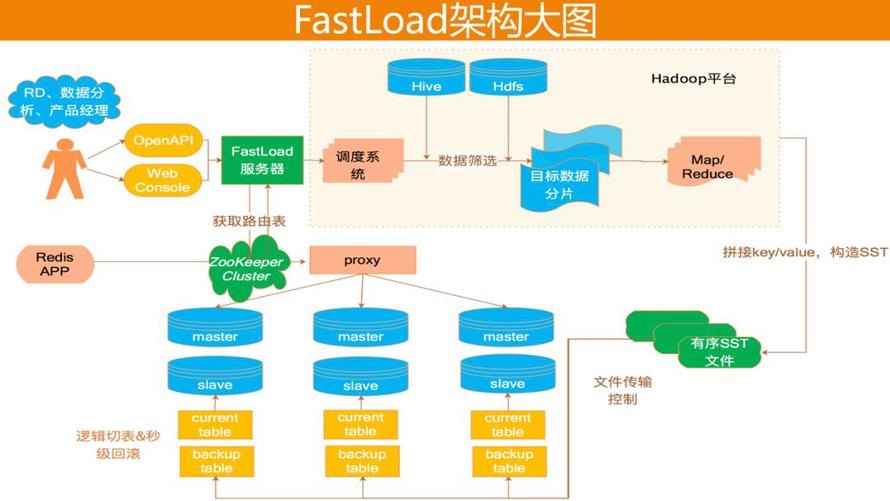
ЕкЖўИіСїЖЏФмСІЪЧМЏШКЧЈвЦЁЃ
ЫќЪЧжИвЛИіFusionМЏШКЕНСэвЛИіFusionМЏШКЕФЪ§ОндкЯпШШЧЈвЦЃЌАќРЈШЋСПКЭдіСПЃЌЧЈвЦЙ§ГЬЪЧдкЯпВЛЭЃЗўЕФЃЌЖдгУЛЇЮоИажЊЕФЃЌетИіЙІФмПЩвдгУгквЕЮёвЛНЈПЊГЧЁЂЛњЗПЧЈвЦЕШЁЃЫќЪЕЯжСЫСНИівьЙЙМЏШКМфНкЕуЕФЕуЖдЕуЪ§ОнЧЈвЦЁЃЧЈвЦЕФЙ§ГЬДѓИХЪЧЃКЪзЯШдДНкЕуБЃСєдіСПШежОЃЌЭЌЪБЙЙНЈШЋСППьееЃЌШЛКѓБщРњПьееЩњГЩСйЪБЕФSSTЃЌдйвдSSTЮФМўЕФЗНЪНЗЂЫЭЕНЖдЖЫmasterЃЌmasterЪеЕНКѓзЊЗЂЕНslaveЃЌД§ШЋСПЭЌВНЭъГЩЃЌдйДђПЊдіСПШежОЕФЭЌВНЃЌЦфЫћЯИНкШчЯТЁЃ

ССЕу2ЃКНЕМЖШндж
ЪзЯШFusionОпгажїПтНЕМЖФмСІЃЌЕБвЕЮёСїСПИпЗхЪБЃЌЕМжТжїПтЯьгІТ§ЃЌДЫЪБРЉШнвбОРДВЛМАЃЌвђДЫЮвУЧдкproxyЩЯЪЕЯжСЫЖСаДЗжРыФмСІЃЌМДЮўЩќвЛЖЈЕФвЛжТадЃЌАбвЛВПЗжЖССїСПТЗгЩЕНДгПтЃЌДяЕНБЃШЋжїПтЕФФПЕФЁЃ
ШЛКѓЪЧМЏШКШнджЁЃМДFusionЕзВуЪЕЯжСЫСНИіМЏШКМфЕФЪ§ОнздЖЏЭЌВНЁЃе§ГЃЧщПіЃЌгУЛЇЭЈЙ§VIP1ЗУЮЪМЏШК1ЕФЪ§ОнЃЌЕБМЏШК1ВЛПЩгУЪБЃЌЮвУЧЬсЙЉСНжжЧаСїЗНАИЃКЕквЛжжЪЧЃЌашвЊгУЛЇЧаЛЛЗУЮЪСДТЗЕНVIP2ЃЌетПЩФмашвЊгУЛЇжиЦєЃЛЕкЖўжжЪЧМйЩшVIPПЩгУЃЌЮвУЧПЩвдЭЈЙ§вЛМќЧаСїЦНЬЈЃЌАбVIP1жИЯђЕФReal
ServerИФЕНМЏШК2ЁЃ

НгЯТРДПДПДЪЧШчКЮЪЕЯжМЏШКМфЪ§ОнЭЌВНЕФЁЃ
ЮвУЧЪЕЯжСЫвьЙЙМЏШКМфНкЕуЕФЕуЖдЕуЪ§ОнДЋЪфЃЌВЛвРРЕШЮКЮжаМфМўЃЌУПИіНкЕуЛсИажЊЖдЖЫМЏШКЕФТЗгЩаХЯЂЃЌЧвФмЪЪгІСНЖЫМЏШКЕФзДЬЌБфЛЏЃЌБШШчЧажїЁЂРЉШнЕШЃЌЖМФмБЃжЄЪ§ОнгЩе§ШЗЕФНкЕуЗЂЦ№ЃЌШЛКѓЭЌВНЕНе§ШЗЕФНкЕуЁЃећИіЪ§ОнЕФПЩППадЪЧгЩЛЌЖЏДАПкРДБЃжЄЕФЃЌМДЮвУЧгУаДЕНFusionЕФkeyЕФЮЈвЛseqзіЛЌЖЏДАПкЕФдЊЫиЃЌЪЕЯжСЫвЛИіsend/ackЛњжЦЃЌБЃжЄСЫЫГађЗЂЫЭЁЂЫГађжиДЋЁЂПЩППДЋЫЭЁЃ
СэЭтЃЌИУЗНАИЛЙжЇГжЪ§ОнЕФздЖЏВЙГЅЁЃМДЕБМЏШК1ЙвЕєКѓЃЌгУЛЇАбСїСПЧаЕНМЏШК2ЃЌдкМЏШК1ЛжИДжЎЧАЕФетВПЗждіСПЪ§ОнЃЌЛсдкМЏШК1ЛжИДжЎКѓЃЌздЖЏЭЌВНЙ§ШЅЁЃ
зюКѓЃЌетИіЗНАИвВжЇГжЫЋаДЁЃЮвУЧРћгУRocksDBЕФmergeЙІФмЃЌзіСЫвЛИіЛљгкNTPЕФШЅжиЗНАИЁЃ

ССЕу3ЃКМЋжТаЇТЪ
етПщЪЧеыЖдRocksDBЕФвЛаЉЬиадзіаЉгХЛЏЁЃЕквЛИіЮвУЧЪЕЯжСЫkeyСЃЖШЧвОпгаШШЕудЄВтЙІФмЕФcacheЃЌНтОіRocksDBЫцЛњЖСЮЪЬтЃЌУќжаТЪФмДяЕНдЩњЕФ3БЖЃЛЕкЖўИіЪЧЪЕЯжСЫcompactЕФ24аЁЪБЕїЖШЃЌДХХЬФмНкдМ25%ЃЌбгГйКЭУЋДЬОљгаДѓЗљЖШНЕЕЭЃЛЕкШ§ИігХЛЏФкДцеМгУЃЌБШШчslaveЕФpage-cacheЪЧЮогУЕФЃЌашвЊGCЃЌblock-cacheдкЕЭЗхЪБЦкЪЧЮогУЕФЃЌвВашвЊGCЕШЁЃ

ССЕу4ЃКАВШЋБЃеЯ
ЕквЛИіЪЧЩ§МЖЪБЪ§ОнБИЗнЁЃГЃЙцЩ§МЖЪБЃЌЮвУЧЖМЛсБИЗнЖўНјжЦЮФМўКЭХфжУЮФМўЃЌЕЋЪЧЖдгкЪ§ОнВЂУЛгаБИЗнЁЃЮвУЧеыЖдRocksDBЕФSSTЮФМўЬиадЃЌМДжЛЛсБЛДДНЈКЭЩОГ§ЃЌЖјВЛЛсБЛаоИФЃЌзіСЫвЛИігВСДНгБИЗнЗНАИЃЌИУЗНАИЪЧаДЪБПНБДЃЌвђДЫБИЗнЫйЖШЗЧГЃПьЧвДХХЬПеМфеМгУЗЧГЃЩйЁЃИќЙиМќЕФЪЧЃЌетИіЗНАИЪЧЪЕЯждкжЧФмЙмПиЦНЬЈЕФЩ§МЖСїГЬРяУцЃЌВЛашвЊИФЗўЮёЖЫДњТыЃЌжЛашвЊаоИФЙмПиГЬађОЭПЩвдСЫЃЌвђДЫКмЗНБузіЕН100%ЯпЩЯИВИЧЃЌБЃжЄЪ§ОнАВШЋЁЃ
ЕкЖўИіЪЧЬсЙЉгУЛЇМЖБ№ПьееЃЌРћгУСЫRocksDBЕФcheckpointЃЌПЩвдзіЕНУыМЖПьееЁЃ
ЕкШ§ИіЪЧЪ§ОнЖрАцБОДцЗХЁЃМДдкFastLoadГЁОАРяУцЃЌЮвУЧЛсБЃСєЖрАцБОЪ§ОнЃЌгУгкгУЛЇЫцЪБЫцЕиЕФЧаЛЛЫћашвЊЕФЪ§ОнЃЌБШШчA/BtestЃЌЪ§ОнЛиЙіЕШЁЃ

ЕкЖўеТЃКЛљгкFusionЕФNewSQLЬНЫїЪЕМљ
НгЯТРДЬжТлNewSQLЬНЫїЪЕМљЕФЯИНкЁЃ
ЪзЯШЃЌашвЊЛиД№вЛИіЮЪЬтЃЌЮвУЧЮЊЪВУДвЊзіNewSQLбнНјЃПЮвЯыДѓМвЕФГіЗЂЕуЖМЪЧвЛбљЕФЃЌЖМЪЧЮЊСЫНтОідкДѓЪ§ОнСПДцДЂЯТЕФMySQLЕФМИИіКЫаФЮЪЬтЃЌМДЃКСщЛюЮЪЬтЁЂРЉеЙЮЪЬтЁЂГЩБОЮЪЬтЁЃФЧУДЖдгІЕФNewSQLЃЌЮвШЯЮЊОЭИУОпБИетбљМИИіФмСІЃКЧсЫЩМгзжЖЮЁЂДцДЂВЛЯоСПЁЂИќИпадМлБШЁЃ
ФЧвЊЪЕЯжетбљЕФФПБъЃЌУцСйФФаЉЬєеНФиЃП
ШчКЮдкKVЯЕЭГЩЯИажЊгУЛЇschemaЃП
ШчКЮдкKVЯЕЭГЩЯЭТГіМцШнMySQLЕФbinlogЃП
ШчКЮЪЕЯжЖўМЖЫїв§ЕФДцДЂКЭВщбЏЃП
ШчКЮЪЕЯжЪТЮёКЭЪТЮёЕФНЛЛЅЃП

НгЯТРДЃЌИјГіЮвУЧЕФNewSQLМмЙЙЭМЁЃЪзЯШЮвУЧАбгУЛЇЕФDDLВйзїЃЌЪеСВЕНПижЦЬЈЃЌВЛШУгУЛЇжБНгИјDBЗЂЦ№DDLВйзїЃЌгУЛЇЗЂЦ№ЕФDDLВйзїЃЌИФБфЕФschemaаХЯЂЃЌЛсБЃДцЕНХфжУжааФЃЌЭЌЪБЛсЭЦЫЭИјЮвУЧЕФproxyЃЌЫљгаproxyЭЦЫЭГЩЙІКѓЃЌЗЕЛиИјгУЛЇГЩЙІаХЯЂЁЃгУЛЇдкЭЈЙ§MySQLПЭЛЇЖЫЗУЮЪЮвУЧЕФproxyЃЌЮвУЧдкдРДRedisавщЕФproxyЩЯЃЌдіМгСЫSQL-parserЕШЙЄзїЃЌВЂНЋНгЪмЕНЕФгУЛЇSQLЧыЧѓЃЌзЊГЩKVЃЌдйаДЕНFusionЁЃFusionЗўЮёЖЫЛсЩњГЩMySQLИёЪНЕФbinlogЃЌдйЭТГіЕНMQЃЌЮвУЧЕФЫїв§ЗўЮёЦїЛсвьВНЯћЗбетВПЗжаХЯЂЃЌШЛКѓИљОнгУЛЇздЖЈвхЕФЫїв§keyЃЌАбЫћаДЕНЫїв§ДцДЂРяМДПЩЁЃ

schemaЙмРэ
етПщЕФКЫаФЫМТЗЃЌОЭЪЧАбDDLВйзїгыЪ§ОнСїЗжРыЃЌЭЈЙ§ХфжУжааФРДНтёюЁЃProxyетБпжиЕуашвЊНтЮіSQLЃЌзЊЛЛKVЕШЁЃФПЧАFusionжЇГжinsert/replace/delete/select/updateгяОфЃЌЫќЕФЖЈЮЛЪЧНтОіЕЅБэДѓБэЕФДцДЂЮЪЬтЃЌгыMySQLзівЛЖЈГЬЖШЕФЛЅВЙЃЌвђДЫдкМцШнMySQLЩЯзіСЫНЯДѓЕФЩсЦњЁЃ
етРяИјСЫвЛИіSQLЕНKVзЊЛЛЕФР§згЃЌзѓБпЪЧвЛИіstudentБэЃЌШ§ааЫФСаЃЌгвБпЪЧRedisЕФhashБрТыЃЌДѓkeyгаБэУћМгжїМќзщГЩЃЌfieldЪЧСаУћЃЌvalueЪЧааСажЕЁЃ

binlogМцШн
етПщЪЧНВШчКЮЭТГіbinlogЕФЃЌвђЮЊЕЮЕЮЕФЭЈгУbinlogЪЧашвЊджЕЕФЃЌЖјKVФЌШЯЕФlogЪЧжЛгаЕБЧАжЕЃЌвђДЫЮвУЧдкВњЩњlogЕФЪБКђЃЌЯШХаЖЯгУЛЇЕФВхШыРраЭЃЌШчЙћЪЧupdateОЭЯШШЁджЕЃЌдйвЛЦ№аДЕНlogРяЃЌШчЙћЪЧinsertдђВЛашвЊЁЃ
ЖўМЖЫїв§ЃЈЮЈвЛКЭЗЧЮЈвЛЃЉ
ЩЯЪіbinlogЭТГіЕНMQжЎКѓЃЌетРяЕФЫїв§ФЃПщЛсРДЯћЗбMQЃЌВЂвьВНЙЙНЈЫїв§ЃЈвђЮЊадФмПМТЧКЭВЛОпБИЗжВМЪНЪТЮёФмСІЃЌвђДЫУЛгазіЪЕЪБЫїв§ЃЉЁЃЫїв§keyЕФЦДНгЗНЪНШчЯТСНжжЃЌетРяашвЊзЂвтЕФЪЧЃЌПДЧАУцFusionЕФМмЙЙЭМЃЌЮвУЧжЊЕРFusionМЏШКЕФЪ§ОнЗжЦЌЪЧЭЈЙ§hashЪЕЯжЕФЃЌвђДЫЗжЦЌжЎМфЪЧВЛСЌајЕФЃЌЮоЗЈзіЕНПчНкЕуscanЃЌвђДЫЮвУЧЖдЭЌвЛИіСаЫїв§ЃЌдіМгСЫвЛИіЗжЧјНЁЃЌМДRedisавщЕФhash-tagЃЌРДБЃжЄЭЌвЛИіЫїв§ЃЌБиаыДцЕНЭЌвЛИіНкЕуЃЌЗНБуЮвУЧзіscanЁЃ

ЪТЮёЙІФм
ЪТЪЕЩЯЮвУЧВЛжЇГжЗжВМЪНЪТЮёЃЌЛЙЪЧЭЈЙ§redisЕФhash-tagЃЌЙцБмСЫЗжВМЪНЪТЮёЃЌМДИњгУЛЇдМЖЈЃЌШУгУЛЇАбЯЃЭћзіЪТЮёБЃжЄЕФааЕФжїМќЃЌДјЩЯhash-tagЃЌШУетаЉааЗХЕНЭЌвЛИіНкЕуЁЃЗжВМЪНЪТЮёОЭзЊГЩЕЅЛњЪТЮёСЫЁЃЖјЕЅЛњЪТЮёЃЌЮвУЧРћгУСЫRocksDBЕФЪТЮёв§ЧцЃЌвђЮЊRocksDBдйИјMyRocksЬсЙЉв§ЧцЪБЃЌжЇГжСЫЭъБИЕФЪТЮёФмСІЃЌвђДЫЮвУЧжБНгМгвдРћгУЁЃзюКѓвЊНтОіЕФЪЧЪТЮёНЛЛЅЮЪЬтЃЌетРяЮвУЧЭЈЙ§luaРДНтОіЁЃ

ЪТЮёНЛЛЅ
дЩњRedisЖдгкЪТЮёНЛЛЅДІРэжЇГжЕФВЂВЛКУЃЌБШШчВЛжЇГжЛиЙіЕШЃЌвђДЫЮвУЧЯывЊЭЈЙ§RedisРДЪЕЯжЪТЮёНЛЛЅЃЌОЭЕУдіМгвЛаЉНгПкЃЌЕЋетаЉНгПкЯдШЛВЛЪЧБъзМSDKЬсЙЉЕФЃЌОЭКмФбЭЦЙуЁЃКУдкRedisПЭЛЇЖЫЬсЙЉСЫluaЕФНХБОжЇГжЃЌФЧУДFusionвВЪЕЯжluaНтЪЭЦїЕФЙІФмЃЌОЭПЩвдШУгУЛЇЭЈЙ§luaНХБОДЋЕнШЮКЮНгПкЙ§РДЃЌетИіЬиадПЩвдКмКУЕФНтёюЁЃЭЌЪБгУЛЇПЩвддкluaНХБОРяЪЕЯжИїжжif/elseЕШТпМЁЃФЧУДЕБЮвУЧАбЪТЮёНЛЛЅЭЈЙ§luaЬсЙЉКѓЃЌгУЛЇИњFusionНЛЛЅЪБЃЌОЭПЩвдАбЯрЙиТпМЗХЕНFusionРДжДааЃЌећИіЙ§ГЬЪЧвЛНзЖЮЪТЮёЃЌВЛашвЊИДдгЕФbegin/commit/rollbackЕШЁЃЮвУЧЕФproxyвВВЛашвЊЮЌЛЄЪТЮёзДЬЌЃЌФкВПЕФЫјДІРэвВИќМђЕЅЃЌВЛашвЊЙиаФГЄЪТЮёЃЌИќВЛгУЙиаФЪТЮёРяЖрИіkeyЪЧЗёЗжВМдкВЛЭЌНкЕуЁЃ
ФЧдкMySQLавщетБпШчКЮЪЕЯжЪТЮёФиЃПЮвУЧЪЧНЈвщгУЛЇАбluaНХБОаДЕНMySQLЕФcommentРяЃЌЭЈЙ§НгЯТcommentЕФluaЃЌРДжДааЪТЮёЁЃ

змНс
зюКѓЃЌЖдЮвУЧЕФNewSQLЗНАИзіИіаЁНсЁЃЫћЕФгХЕуКмУїЯдЃЌжБНгдкЯжгаNoSQLМмЙЙЩЯМгвдЕќДњМДПЩПьЫйЩЯЯпЃЌИДгУГЬЖШИпЃЌЮШЖЈадИпЃЛЭЌЪБдкВЛашвЊЪТЮёЕФГЁОАЯТЃЌШЗЪЕКмКУЕФНтОіСЫРЉеЙЮЪЬтЁЂСщЛюЮЪЬтЃЛСэЭтЃЌдкЧАУцЬсЕНЕФhiveЕНFusionЕФДђЭЈжаЃЌШУгУЛЇЪЙгУИќздШЛЃЌвђЮЊдЯШЕФFastLoadЪЧАбSQLНсЙЙЛЏЕФЪ§ОнзЊГЩЗЧSQLНсЙЙЕФKVЕФЃЌЯждкгаСЫNewSQLжЎКѓЃЌгУЛЇОЭПЩвдДгSQLЕНSQLЁЃ
етИіЗНАИЩЯЯпвЛФъЃЌЕБЧАДцШыЪ§ОнГЌЙ§СЫ400TBЃЌзмQPSГЌЙ§СЫ200WЃЛНгШыЕФвЕЮёГЌЙ§СЫ58ИіЃЌЦНОљУПИівЕЮёДцДЂ8TBвдЩЯЪ§ОнЃЌПЩвдПДЕНетИіЪ§ОнСПЪЧMySQLВЛЬЋШнвзНтОіЕФвЛИіСПМЖЁЃ

ЕкШ§еТЃКЗжВМЪНЪ§ОнПтЩшМЦ
ЧАУцжЛЬсЕНСЫNewSQLЗНАИЕФгХЕуЃЌЪЕМЪЩЯЃЌЫќЛЙЪЧгаКмЖрВЛзуЕФЕиЗНЃЌзюКЫаФЕФЮЪЬтЪЧЃЌЫћЪЧвЛИіЁБЮБЗжВМЪНЁАЗНАИЃЌЫфШЛЪ§ОнзіЕНСЫЮоЯоРЉеЙЃЌЕЋЪЧЃК
жЛЪЕЯжСЫЕЅЛњЪТЮёЁЃ
жЛЪЕЯжСЫЕЅЛњЫїв§ЁЃвђЮЊМЏШКАДhashЗжЦЌЃЌЮоЗЈПчЛњscanЁЃ
жЛгавьВНЫїв§ФмСІЁЃвђЮЊУЛгаЗжВМЪНЪТЮёБЃжЄЃЌЮвУЧжЛЪЕЯжСЫвьВНЫїв§ЁЃ
JoinИќЪЧВЛжЇГжЕФЁЃ
ЮоЕЏадРЉШнФмСІscale outЁЃ
КмЯдШЛЃЌдкЯжгаЕФNoSQLМмЙЙЩЯЃЌвбОЮоЗЈМђЕЅЕФНтОіетаЉашЧѓЃЌашвЊГЙЕзДѓИФЁЃвђДЫЃЌЮвУЧгаСЫСэЦ№ТЏдюЕФЯюФПЁЊЁЊЗжВМЪНЪ§ОнПтЁЃЫќЪзвЊНтОіЕФМИИіЮЪЬтЪЧЃК
ЗжВМЪНЪТЮёЁЃ
Ъ§ОнКЭЫїв§ЕФеце§ЮоЯоРЉеЙЁЃ
ЪЕЪБЫїв§ЁЃ
ЕЏадРЉШнЁЃ
ЖрИББОЧПвЛжТЁЂИпПЩгУЁЃ
SQLМцШнЕШЁЃ

МмЙЙЩшМЦ
МмЙЙЩшМЦШчЯТЃЌЪТЪЕЩЯЃЌетвВЪЧЗжВМЪНДцДЂЕФОЕфМмЙЙЃЌКмЖрЕФЯЕЭГЖМГЄдкРрЫЦМмЙЙЩЯУцЃЌЫќЪЕЯжСЫrangeЗжЧјЁЂЧПвЛжТЁЂЕЏадРЉШнЁЂШЋОжscanЕШФмСІЁЃЯИНкОЭВЛЖрзіеЙПЊСЫЁЃ

ЕБЧАзДПі
ЮвУЧдкетЬзМмЙЙЩЯЃЌЪЕЯжСЫвЛИіОпБИraftЧПвЛжТЁЂШЋОжscanЁЂздЖЏЗжСбЕШФмСІЕФЗжВМЪНKVЯЕЭГЃЌЯТвЛВНЪЧзіЗжВМЪНЪТЮёЁЃМДЯШЪЕЯжвЛИіЙІФмЧПДѓЕФKVЯЕЭГЃЌШЛКѓдкетЛљДЁЩЯМЬајзіSQLЕФжЇГжЁЃ
змНсШ§ВПЧњ
зюКѓЪЧЖдећИібнНјЙ§ГЬзівЛИізмНсЁЃ
ЪзЯШЮвУЧбаЗЂСЫNoSQLЯЕЭГFusionЃЌЖЭСЖСЫЮвУЧЕФЛљДЁФмСІЃКЗжВМЪНЁЂГжОУЛЏЁЂИпПЩгУЁЂЪ§ОнСїЖЏЕШЁЃ
ЕкЖўВНЪЧЮвУЧЕФNewSQLЬНЫїЃЌЮвУЧзіСЫвЛИіПьЫйНтОівЕЮёЮЪЬтЕФЗНАИЃЌетИіЗНАИгаГЩЙІЕФЕиЗНЃЌвђЮЊЫќНтОіСЫ50ЖрИівЕЮёЕФашЧѓЃЌвВгаЪЇАмЕФЕиЗНЃЌЮвУЧЮоЗЈдкетЬзЯЕЭГЩЯзпЕУИќдЖЃЌЕЋетЬсЩ§СЫЮвУЧЕФЯЕЭГШЯжЊЃЌетКмживЊЁЃ
ЕкШ§ВНЪЧЮДРДбнНјЃЌЯывЊдкКЃСПЪ§ОнOLTPетЬѕТЗзпЕФИќдЖЃЌБиаыГЙЕзИяУќЃЌвђДЫзюКѓЕФбнНјЪЧХзЦњСЫЯжгаЯЕЭГМмЙЙЃЌДгЭЗЩшМЦЮвУЧЕФЗжВМЪНЪ§ОнПтЁЃетИіЯюФПвВЪЧЗжЦкЕФЃЌвЛЦкЮвУЧЯШзівЛИіЙІФмЧПДѓЕФKVЯЕЭГЃЌШЛКѓЖўЦкдкЫћЕФЛљДЁЩЯдіМгSQL-parserЃЌШЁДњЮвУЧЯжгаЕФNewSQLЗНАИЃЈЙІФмБШНЯМђЕЅЃЌКмШнвзТфЕиЃЉЃЌШЛКѓШ§ЦкВХЪЧИпЖШЕФSQLМцШнЁЃ
ећИібнНјЙ§ГЬзёбСЫСНИіддђЃКБмУтЙ§ЖШЩшМЦКЭДѓдОНјЁЃМДдкЯжгаЮШЖЈЕФМмЙЙЩЯЛЈзюаЁЕФДњМлЃЌНтОізюЖЬАхЮЪЬтЁЃећИіЙ§ГЬзіЕНСЫВњЦЗЕФГжајНЛИЖЃЌМШПьЫйЯьгІвЕЮёашЧѓЃЌгжВЛЖЯЗсИЛздМКЕФШЯжЊЃЌзюжеГЏзХвЛИіГЩБОПЩПиЁЂЮШЖЈЕќДњЕФФПБъЧАНјЁЃ
| 







