| БрМЭЦМі: |
БОДЮНВЪіСЫМђвЊНщЩмNewSQLЃЛ
ШчКЮНЈСЂвЛИіNewSQLЪ§ОнПтЃЛ
вдМАroadmapЃЌЯЃЭћЖдФњгаЫљАяжњ,
БОЮФРДздcsdnЃЌгЩЛ№СњЙћШэМўDeloresБрМЁЂЭЦМіЁЃ |
|
ЮЊЪВУДЮвУЧашвЊвЛИіаТЕФЪ§ОнПтЃП
дке§ЪНПЊЪМЧАЃЌЮвЯШЮЪвЛИіЮЪЬтЃКФуУЧЪьЯЄЪ§ОнПтТ№ЃП
СэЭтЃЌгаЫжЊЕРMySQLТ№ЃП
ФЧУДЃЌЯжгаЪ§ОнПтДцдкФФаЉЮЪЬтФиЃП
ЯёMySQLЁЂOracleЁЂPostgreSQLетбљЕФЙиЯЕЪ§ОнПтЃЌЫќУЧЕФЮЪЬтЪЧКмФбРЉеЙЁЃОЁЙмЮвУЧгаЗжЦЌММЪѕЃЌЛЙгаyoutube/vitessКЭMySQL proxyЕШ,ЕЋЫќУЧЖМВЛжЇГжЗжВМЪНЪТЮёвдМАcross-node joinСЌНгЁЃ
ЯёHBaseЁЂMongoDBвдМАRedisетбљЕФNoSQLЪ§ОнПтЃКЫќУЧПЩРЉеЙЃЌЕЋВЛжЇГжSQLЃЌЭЌЪБвВЩсЦњСЫЪТЮёЕФвЛжТадЁЃ
вђДЫЃЌаТвЛДњЪ§ОнПтНЋЛсЪЧдѕбљЕФЃПдкЮвПДРДЃЌЦфжївЊЬиеїгІИУЪЧЃК
жЇГжSQLЃЛ
ОпгаПЩРЉеЙадЃЛ
жЇГжЪТЮёжДааЫФвЊЫи/ACID TransactionЃЛ
ИпПЩгУЁЃ
ЪзЯШЃЌЫќБиаыжЇГжSQLЃЌвђЮЊетЪ§ЪЎФъРДЮвУЧвЛжБдкЪЙгУSQLЃЌЖјЧваэЖргІгУГЬађЖМЪЙгУSQLЃЌЙЪЖјВЛФмЧсвзНЋЦфЩсЦњЁЃ
ЕкЖўЃЌБиаыгаСМКУЕФРЉеЙадЃЌвВОЭЪЧЫЕжЛашЭЈЙ§НгШыИќЖрЕФЛњЦїОЭПЩвдРЉеЙЦфШнСПЛђЪЙжЎЪЕЯжИКдиОљКтЁЃ
ЕкШ§ЃЌБиаыжЇГжЪТЮёЕФACIDЪєадЃЌетвЛЕувВЧЁЧЁЪЧЙиЯЕЪ§ОнПтЕФжївЊЬиеїжЎвЛЁЃгаСЫЧПДѓЕФвЛжТадзїБЃеЯЃЌПЊЗЂепБуПЩвдгУНЯЖЬЕФДњТыБраДГіе§ШЗЕФГЬађЁЃ
зюКѓЃЌМДЪЙЪЧдкМЦЫуЛњЯнШыЙЪеЯЃЌЩѕжСЪЧећИіЪ§ОнжааФЬБЛОЕФЧщПіЯТЃЌЫќвВгІИУФмЙЛБЃГжЦфНЯИпЕФПЩгУадЁЃЭЌЪБЃЌЫќЛЙгІЕБПЩвдздЖЏаоИДЁЃ
змжЎЃЌаТвЛДњЪ§ОнПтгІИУМШгаКмКУЕФПЩРЉеЙадЃЌгжФмБЃСєЙиЯЕЪ§ОнПтЕФжївЊЬиеїЁЃ
NewSQLЪЧЪВУД?
ФуПЩФмЛсКУЦцЃЌетбљЕФЪ§ОнПтецЕФДцдкТ№ЃПЫќЬ§Ц№РДЫЦКѕЬЋЙ§ЭъУРКЭРэЯыЛЏСЫЁЃетИіЮЪЬтЕФД№АИЪЧПЯЖЈЕФЃЌетбљЕФЪ§ОнПтЕФШЗДцдкЃЌЫќОЭЪЧNewSQLЁЃФЧЪВУДЪЧNewSQLЪ§ОнПтЃПЯШРДПДвЛПДЮЌЛљАйПЦИјГіЕФНтЪЭЃК
NewSQLЪЧжИетбљвЛРраТЪНЕФЙиЯЕаЭЪ§ОнПтЙмРэЯЕЭГЃЌЫќеыЖдOLTPЪЕЯжЖС-аДЙЄзїИКдиЃЌзЗЧѓЬсЙЉКЭNoSQLЯЕЭГЯрЭЌЕФРЉеЙадФмЃЌЧвШдШЛБЃГжДЋЭГЪ§ОнПтжЇГжЕФACIDЬиадЁЃ
ДгЩЯЪіЖЈвхРДПДЃЌЮвУЧВЛФбЗЂЯжNewSQLЕФРЉеЙадгыNoSQLЯрЕБЃЌВЂЭЌЪББЃСєСЫACIDЬиадЁЃЖјетЧЁЧЁЪЧЮвУЧашвЊЕФЁЃ
НЈСЂвЛИіNewSQLЪ§ОнПт
НёЬьЮвНЋЯђДѓМвеЙЪОШчКЮНЈСЂвЛИіетбљЕФЪ§ОнПтЁЃЮвУЧЪмЕНШЋЧђзюДѓЪ§ОнПтGoogle Spanner КЭ F1 ЕФЦєЗЂЃЌНЋЦфЗжЮЊСНИіВуМЖЃК
KVВуЃКетвЛВуЪєгкЕзВуДцДЂЯЕЭГЃЌИКд№ЬсЙЉПчЪ§ОнжааФЕФЭЌВНвдМАЧПвЛжТадЪТЮёЁЃ
SQLВуЃКетвЛВуЪЙФмЙЛТњзуЮвУЧЖдДЋЭГSQLЪ§ОнПтПЩгУадвдМАЙІФмадЕФжЇГжЁЃ
НЈСЂNewSQLЪ§ОнПт
етОЭЪЧЮвУЧдкPingCAPЫљДгЪТЕФЙЄзїЃЌЕБШЛЪЧПЊдДЕФЁЃЦфжаЃЌЮвУЧЕФЪ§ОнПтЗжЮЊСНВуЃЌМДKVВуКЭSQLВуЁЃОЭKVВуРДПДЃЌЮвУЧгаTiKVЃЛЖдгкSQLВуЃЌдђгаTiDBЁЃЖјЮвНЋдкЩдКѓНщЩмЦфжаЕФЙиМќММЪѕЁЃетРяЕФTiЪЧTitaniumЃЈюбЃЉЕФЫѕаДЃЌЮвУЧЖМжЊЕРюбзїЮЊвЛжжПЙИЏЪДадЕФЛЏбЇдЊЫиЃЌБЛЙуЗКгІгУгкИпЖЫПЦММЕБжаЁЃ
TiKVЕФЬиад
вьЕиБИЗнЃКЮвУЧРћгУRaftРДжЇГжвьЕиБИЗнЁЃRaftЪЧвЛжжвЛжТадЫуЗЈЃЌЫќдкШнДэадКЭадФмЗНУцЯрЕБгкPaxosЫуЗЈЁЃЮвУЧЕФЪЕЯжВЮПМгІгУЙуЗКЕФetcdЃЌЫќвбОЭЈЙ§СЫЙуЗКВтЪдВЂОпгаНЯИпЕФЮШЖЈадЁЃ
ЫЎЦНРЉеЙадЃКгЩгкRaftжЇГж membership БфИќЃЌЮвУЧРћгУЦфетвЛЬиадРДЪЕЯжЫЎЦНРЉеЙЁЃ
вЛжТадЕФЗжВМЪНЪТЮёЃКетжжЪТЮёФЃаЭЕФДДНЈЪЧЪмЕНСЫ Google PercolatorЃЈРДздвЛЦЊ2006ЗЂБэЕФТлЮФЃЉЕФЦєЗЂЃЌжївЊЪЧвЛИігХЛЏЕФСННзЖЮЬсНЛавщЁЃИУФЃаЭНшжњвЛИіЪБМфДСЗжХфЦїРДИјИїЯюЪТЮёЗжХфЕЅЕїЕндіЕФЪБМфДСЃЌвђДЫПЩМьВтЕНГхЭЛЁЃ
аДІРэЦїжЇГжЃКгы HBase РрЫЦЃЌЮвУЧдЫгУаДІРэЦїМмЙЙжДааЗўЮёЦїДњТыРДНјааЗжВМЪНМЦЫуЁЃ
зЗЧѓИќИпЕФадФмКЭИќЕЭЕФбгГйЃЌгУБрГЬгябд Rust НјааСЫБраДЁЃФуУЧЕБжагаЫжЊЕР Rust Т№ЃПКмВЛДэЁЃФуУЧгІИУГЂЪдвЛЯТЃЌЫќецЕФЯрЕБгаШЄЁЃ
TiKVМмЙЙ
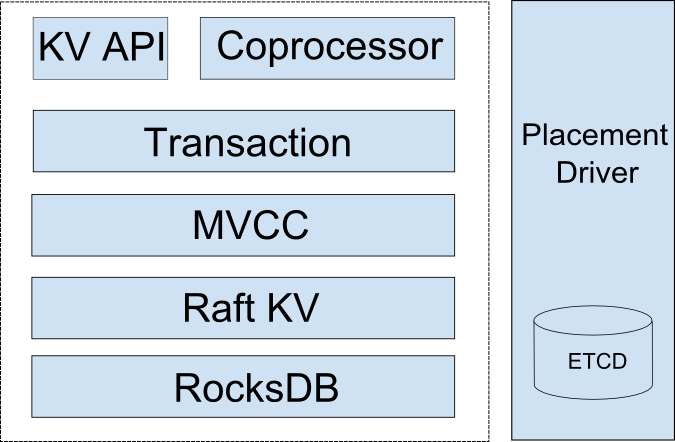
ДгЩЯЭМжаПЩвдПДГіЃЌЫќОЙ§СЫИпЖШЗжВуЁЃ
ДгЕзВуЭљЩЯПДЁЃЕзВуЪЧRocksDBЃЌЫќЪЧвЛИіГжОУЕФФкЧЖЪНKVДцДЂв§ЧцЁЃRocksDBЕФзюГѕЩшМЦжиЕудкгкЦфМЋИпЕФадФмЃЌПЩвдЧсЫЩЖдЖСЗХДѓЁЂаДЗХДѓвдМАПеМфЗХДѓНјаагХЛЏЁЃ
ЩЯУцвЛВуЪЧRaft KVЃЌетвЛВугУРДЪЕЯжЗжВМЪНЁЃ
дйЭљЩЯЪЧMVCCЃЌМДЖрАцБОВЂЗЂПижЦЃЈMulti-version concurrency controlЃЉЁЃЮвЯраХФуУЧЕБжаКмЖрШЫЖдДЫЖМКмЪьЯЄЁЃTiKVЪЧвЛИіЖрАцБОЪ§ОнПтЃЌЖјMVCCдђжЇГжЮвУЧЕФЮоЫјЖСвдМАЪТЮёЕФACIDЪєадЁЃ
НгЯТРДЕФЪТЮёЃЈTransactionЃЉВуЃЌЮвжЎЧАвбОНщЩмЙ§СЫЁЃ
ШЛКѓЪЧKV APIЃЌетЪЧвЛзщГЬађНгПкЃЌЫќдЪаэПЊЗЂепЖдЪ§ОнЕФЪфШыКЭЪфГіЁЃ
ЭЌбљЃЌаДІРэЦїЃЈCoprocesserЃЉдкЧАУцвВЬсЙ§СЫЁЃ
зюКѓЪЧPlacement DriverЃЌетЪЧвЛИігШЮЊживЊЕФВПЗжЃЌвђЮЊЫќПЩажњНјаавьЕиБИЗнЃЌЫЎЦНРЉеЙвдМАвЛжТадЕФЗжВМЪНЪТЮёЁЃЩдКѓЮвНЋЖдЦфЯИНкНјааНјвЛВНВЙГфЁЃ
TiKV ШэМўеЛ

ШУЮвУЧРДПДвЛЯТШэМўеЛЁЃЪзЯШЃЌЮвУЧЛсЗЂЯжПЭЛЇЖЫгыTiKVЯрСЌЁЃЭЌЪБЮвУЧЛЙФмПДМћМИИіNodeЁЃЖјдкУПИіNodeЕБжаЖМгаStoreЃЌУПвЛИіЮяРэДХХЬДцвЛИіstoreЁЃдкУПИі Store ЕБжаЃЌЮвУЧгжЛЎГіаэЖрRegionЁЃЖјRegionЪЧЪ§ОнЧЈвЦЕФЛљБОЕЅЮЛЃЌВЂЧвОгЩRaftБИЗнЁЃУПИіRegionЖМБЛЭЌВНЕНЖрИіНкЕуЁЃвЛИі Raft group гЩвЛИі Region ЕФЪ§ИіБИЗнзщГЩЁЃШчФуЫљМћЃЌУПИі Region дкШ§ИіВЛЭЌЕФНкЕуЩЯгаШ§ИіБИЗнЁЃ
Ч§ЖЏГЬађХфжУ
PDЃЌгжГЦ placement driverЃЌетвЛУћГЦРДдДздSpannerЕФдЮФЁЃЫќЪЧМЏШКЙмРэЦїЃЌЬсЙЉСЫИУМЏШКЕФЩЯЕлЪгНЧЁЃЫќгЩСНИіВПЗжЙЙГЩЃКrebalancerКЭtimestamp allocatorЁЃPDЖдRegionИББОНјаажмЦкадМьВтЃЌЦНКтИКдиЃЌВЂздЖЏДІРэЪ§ОнЧЈвЦЁЃЕБЫќМьВтЕНИКдиЙ§ИпЪБЃЌНЋЛсжиаТЦНКтЪ§ОнЁЃ
TiDB
вдTiKVЮЊЛљДЁЕФNewSQLЃКЫќНЋTiKVзЊБфГЩСЫвЛИіNewSQLЪ§ОнПтЁЃ
вьВНschemaИФБфЃКФуПЩвддкВЛЭЃжЙвВВЛгАЯье§дкНјааЕФВйзїЕФЧАЬсЯТЃЌЬэМгаТЕФСавдМАЫїв§ЁЃБОжЪЩЯПДЃЌЫќЪЧвЛИіЖрНзЖЮавщЁЃ
гыMySQLавщМцШнЃКTiDBЗўЮёЦїзёДгMySQLавщЃЌВЂЧвзёбЦфSQLгяЗЈЁЃЛЛОфЛАЫЕОЭЪЧдкДѓЖрЧщПіЯТЃЌФуФмЙЛдкВЛИќИФШЮКЮвЛааДњТыЕФЭЌЪБЃЌЭЈЙ§гУTiDBЬцЛЛMySQLРДдіЧПФуЕФгІгУЁЃTiDBЪЪгУгкMySQLгІгУКЭЙмРэЙЄОпЃЌБШphpMyAdminЁЂNavicatвдМАWordPressЁЃЭЌЪБЃЌКмЖрORMвВПЩвддкTiDBЩЯКмКУЕФЙЄзїЃЌР§ШчHibernateЁЂGORMЁЂActiveRecordЁЂSQLAlchemyЕШЁЃ
TiDBЕФМмЙЙ
ШУЮвУЧРДПДвЛЯТTiDBЕФМмЙЙЃК
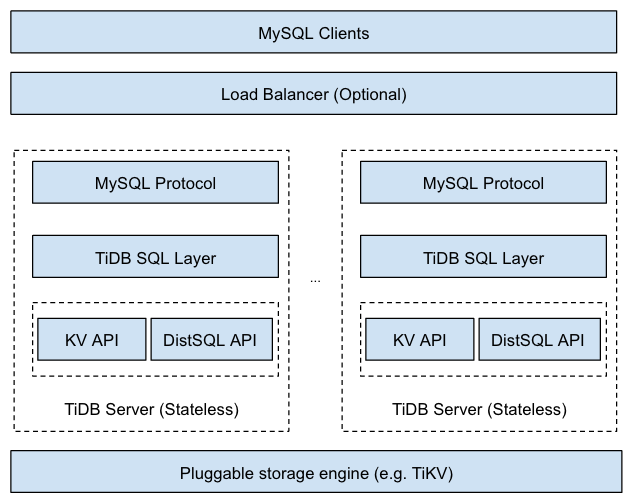
MySQLПЭЛЇЖЫЃКЖЅВуЪЧвЛзщMySQLПЭЛЇЖЫЃЌетаЉПЭЛЇЖЫЯђЯТвЛВуЗЂЫЭЧыЧѓЁЃдкетРяФуШдШЛПЩвдЪЙгУФуЫљЪьЯЄЕФMySQLЧ§ЖЏГЬађЁЃ
ИКдиЦНКтЦїЃКетвЛВуЪєгкПЩбЁВуЃЌР§ШчHAProxy вдМА LVSЁЃ
TiDBЗўЮёЦїЃКЫќЪЧЮозДЬЌЕФЃЌвЛИіПЭЛЇЖЫПЩвдЭЌШЮКЮвЛИіTiDBЗўЮёЦїЯрСЌНгЁЃдкTiDBЗўЮёЦїФкВПЃЌзюЖЅВуЬсЙЉMySQLавщжЇГжЃЛЯТвЛВуЪЧSQL PlanВуЃЌЭљЭљБЛгУвдНЋMySQLЧыЧѓзЊЛЛГЩTiDB SQL PlanЃЛЕзВудђЪЧKV APIвдМАЗжВМЪНSQL APIЁЃШчЙћНЯЕзВуЕФДцДЂв§ЧцжЇГжаДІРэЦїЃЌTiDB SQLВуНЋЛсЪЙгУБШKV APIИќЮЊИпаЇЕФDistSQL APIЁЃTiDBжЇГжВхМўЪНДцДЂв§ЧцЃЌдчЦкжЇГжHBaseЁЃЭЌЪБзїЮЊЪдбщадДцДЂв§ЧцЃЌЮвУЧЛЙжЇГжCockroachDBЁЃЕЋЮвУЧЭЦМіTiKVЮЊФЌШЯДцДЂв§ЧцЁЃ
TiDBШчКЮЪЙSQLгыKVЯрЦЅХф
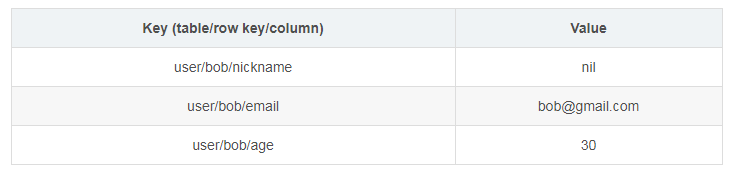
ШУЮвУЧгУвЛИіР§згРДеЙЪОвЛИіSQL БэЪЧШчКЮгГЩфГЩKVЖдЕФЁЃ
МйЩшЮвУЧЕФЪ§ОнПтРягавЛеХМђЕЅЕФгУЛЇБэЁЃЫќгавЛааШ§СаЃКnicknameЁЂemailКЭageЁЃДЫДІЕФnicknameРраЭЪЧзжЗћДЎЃЌЧвnicknameЪЧжїМќЁЃ

ШчЙћЮвУЧгГЩфетеХБэЕНKVЖдЃЌKeyОЭЗжГЩСЫШ§ИіВПЗжЃКtableЁЂrow keyЁЂcolumnЁЃЖјетЪБЕФKVЖдХХСаШчЯТЃК
| 







