| БрМЭЦМі: |
БОДЮНВЪіСЫМђвЊНщЩмЕЅБэгХЛЏЃЛ
зжЖЮЃЛ Ыїв§ЃЌВщбЏSQLЃЌв§ЧцЃЌInnoDBЃЌЯЕЭГЕїгХВЮЪ§ЃЌЩ§МЖгВМўЃЌЖСаДЗжРыЃЌЯЃЭћЖдФњгаЫљАяжњ,
БОЮФРДздcsdnЃЌгЩЛ№СњЙћШэМўDeloresБрМЁЂЭЦМіЁЃ |
|
вЛ. TiDBЕФКЫаФЬиад
ИпЖШМцШн MySQL
ДѓЖрЪ§ЧщПіЯТЃЌЮоашаоИФДњТыМДПЩДг MySQL ЧсЫЩЧЈвЦжС TiDBЃЌЗжПтЗжБэКѓЕФ MySQL МЏШКврПЩЭЈЙ§ TiDB ЙЄОпНјааЪЕЪБЧЈвЦЁЃ
ЫЎЦНЕЏадРЉеЙ
ЭЈЙ§МђЕЅЕидіМгаТНкЕуМДПЩЪЕЯж TiDB ЕФЫЎЦНРЉеЙЃЌАДашРЉеЙЭЬЭТЛђДцДЂЃЌЧсЫЩгІЖдИпВЂЗЂЁЂКЃСПЪ§ОнГЁОАЁЃ
ЗжВМЪНЪТЮё
TiDB 100% жЇГжБъзМЕФ ACID ЪТЮёЁЃ
ИпПЩгУ
ЯрБШгкДЋЭГжїДг (M-S) ИДжЦЗНАИЃЌЛљгк Raft ЕФЖрЪ§ХЩбЁОйавщПЩвдЬсЙЉН№ШкМЖЕФ 100% Ъ§ОнЧПвЛжТадБЃжЄЃЌЧвдкВЛЖЊЪЇДѓЖрЪ§ИББОЕФЧАЬсЯТЃЌПЩвдЪЕЯжЙЪеЯЕФздЖЏЛжИД (auto-failover)ЃЌЮоашШЫЙЄНщШыЁЃ
вЛеОЪН HTAP НтОіЗНАИ
TiDB зїЮЊЕфаЭЕФ OLTP ааДцЪ§ОнПтЃЌЭЌЪБМцОпЧПДѓЕФ OLAP адФмЃЌХфКЯ TiSparkЃЌПЩЬсЙЉвЛеОЪН HTAP НтОіЗНАИЃЌвЛЗнДцДЂЭЌЪБДІРэ OLTP & OLAPЃЌЮоашДЋЭГЗБЫіЕФ ETL Й§ГЬЁЃ
дЦдЩњ SQL Ъ§ОнПт
TiDB ЪЧЮЊдЦЖјЩшМЦЕФЪ§ОнПтЃЌЭЌ Kubernetes ЩюЖШёюКЯЃЌжЇГжЙЋгадЦЁЂЫНгадЦКЭЛьКЯдЦЃЌЪЙВПЪ№ЁЂХфжУКЭЮЌЛЄБфЕУЪЎЗжМђЕЅЁЃ
Жў.TiDB ећЬхМмЙЙ
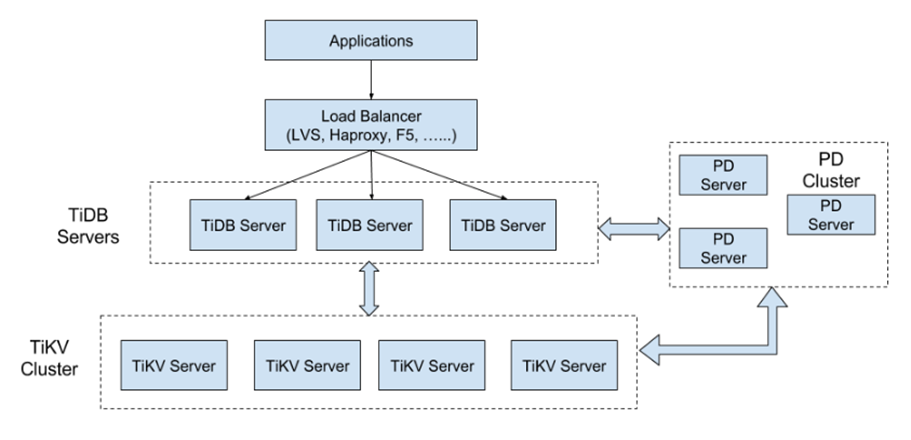
TiDB Server
TiDB Server ИКд№НгЪеSQLЧыЧѓЃЌДІРэSQLЯрЙиЕФТпМЃЌВЂЭЈЙ§PDевЕНДцДЂМЦЫуЫљашЪ§ОнЕФTiKVЕижЗЃЌгыTiKVНЛЛЅЛёШЁЪ§ОнЃЌзюжеЗЕЛиНсЙћЁЃTiDB Server ЪЧЮозДЬЌЕФЃЌЦфБОЩэВЂВЛДцДЂЪ§ОнЃЌжЛИКд№МЦЫуЃЌПЩвдЮоЯоЫЎЦНРЉеЙЃЌПЩвдЭЈЙ§ИКдиОљКтзщМўЃЈLVSЁЂHAProxyЛђF5ЃЉЖдЭтЬсЙЉЭГвЛЕФНгШыЕижЗЁЃ
PD Server
Placement DriverЃЈМђГЦPDЃЉЪЧећИіМЏШКЕФЙмРэФЃПщЃЌЦфжївЊЙЄзїгаШ§ИіЃКвЛЪЧДцДЂМЏШКЕФдЊаХЯЂЃЈФГИіKeyДцДЂдкФЧИіTiKVНкЕуЃЉЃЛЖўЪЧЖдTiKVМЏШКНјааЕїЖШКЭИКдиОљКтЃЈШчЪ§ОнЕФЧЈвЦЁЂRaft group leaderЕФЧЈвЦЕШЃЉЃЛШ§ЪЧЗжХфШЋОжЮЈвЛЧвЕндіЕФЪТЮёIDЁЃ
PD ЪЧвЛИіМЏШКЃЌашвЊВПЪ№ЦцЪ§ИіНкЕуЃЌвЛАуЯпЩЯЭЦМіжСЩйВПЪ№3ИіНкЕуЁЃPDдкбЁОйЕФЙ§ГЬжаЮоЗЈЖдЭтЬсЙЉЗўЮёЃЌетИіЪБМфДѓдМЪЧ3УыЁЃ
TiKV Server
TiKV Server ИКд№ДцДЂЪ§ОнЃЌДгЭтВППДTiKVЪЧвЛИіЗжВМЪНЕФЬсЙЉЪТЮёЕФKey-ValueДцДЂв§ЧцЁЃДцДЂЪ§ОнЕФЛљБОЕЅЮЛЪЧRegionЃЌУПИіRegionИКд№ДцДЂвЛИіKey RangeЃЈДгStartKeyЕНEndKeyЕФзѓБегвПЊЧјМфЃЉЕФЪ§ОнЃЌУПИіTiKVНкЕуЛсИКд№ЖрИіRegionЁЃTiKVЪЙгУRaftавщзіИДжЦЃЌБЃГжЪ§ОнЕФвЛжТадКЭШнджЁЃИББОвдRegionЮЊЕЅЮЛНјааЙмРэЃЌВЛЭЌНкЕуЩЯЕФЖрИіRegionЙЙГЩвЛИіRaft GroupЃЌЛЅЮЊИББОЁЃЪ§ОндкЖрИіTiKVжЎМфЕФИКдиОљКтгЩPDЕїЖШЃЌетРявВОЭЪЧвдRegionЮЊЕЅЮЛНјааЕїЖШ
Ш§. ДцДЂНсЙЙ
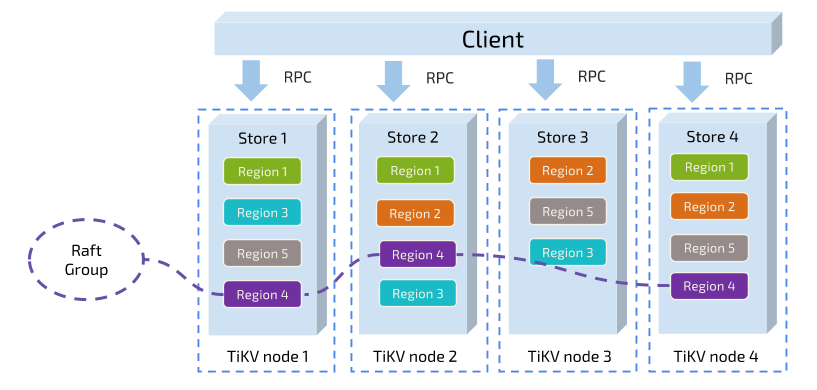
вЛИі Region ЕФЖрИі Replica ЛсБЃДцдкВЛЭЌЕФНкЕуЩЯЃЌЙЙГЩвЛИі Raft GroupЁЃЦфжавЛИі Replica ЛсзїЮЊетИі Group ЕФ LeaderЃЌЦфЫћЕФ Replica зїЮЊ FollowerЁЃЫљгаЕФЖСКЭаДЖМЪЧЭЈЙ§ Leader НјааЃЌдйгЩ Leader ИДжЦИј FollowerЁЃ
Key-Value ФЃаЭ
TiDBЖдУПИіБэЗжХфвЛИіTableIDЃЌУПвЛИіЫїв§ЖМЛсЗжХфвЛИіIndexIDЃЌУПвЛааЗжХфвЛИіRowID(ШчЙћБэгаећаЮЕФPrimary KeyЃЌФЧУДЛсгУPrimary KeyЕФжЕЕБзіRowID)ЃЌЦфжаTableIDдкећИіМЏШКФкЮЈвЛЃЌIndexID/RowID дкБэФкЮЈвЛЃЌетаЉIDЖМЪЧint64РраЭЁЃУПааЪ§ОнАДееШчЯТЙцдђНјааБрТыГЩKey-Value pairЃК
KeyЃК tablePrefix_rowPrefix_tableID_rowID
Value: [col1, col2, col3, col4]
ЦфжаKeyЕФtablePrefix/rowPrefixЖМЪЧЬиЖЈЕФзжЗћДЎГЃСПЃЌгУгкдкKVПеМфФкЧјЗжЦфЫћЪ§ОнЁЃЖдгкIndexЪ§ОнЃЌЛсАДееШчЯТЙцдђБрТыГЩKey-Value pair
Key: tablePrefix_idxPrefix_tableID_
indexID_indexColumnsValue
Value: rowID
Index Ъ§ОнЛЙашвЊПМТЧUnique Index КЭ ЗЧ Unique IndexСНжжЧщПіЃЌЖдгкUnique Index,ПЩвдАДееЩЯЪіБрТыЙцдђЁЃЕЋЪЧЖдгкЗЧUnique IndexЃЌЭЈГЃетжжБрТыВЂВЛФмЙЙдьГіЮЈвЛЕФKeyЃЌвђЮЊЭЌвЛИіIndexЕФtablePrefix_idxPrefix_tableID_indexID_ЖМвЛбљЃЌПЩФмгаЖрааЪ§ОнЕФColumnsValueЖМЪЧвЛбљЕФЃЌЫљвдЖдгкЗЧUnique IndexЕФБрТызіСЫвЛЕуЕїећЃК
Key: tablePrefix_idxPrefix_tableID_
indexID_ColumnsValue_rowID
ValueЃКnull
етбљФмЙЛЖдЫїв§жаЕФУПааЪ§ОнЙЙдьГіЮЈвЛЕФKeyЁЃзЂвтЩЯЪіБрТыЙцдђжаЕФKeyРяУцЕФИїжжxxPrefixЖМЪЧзжЗћДЎГЃСПЃЌзїгУЖМЪЧгУРДЧјЗжУќУћПеМфЃЌвдУтВЛЭЌРраЭЕФЪ§ОнжЎМфЛЅЯрГхЭЛЃЌЖЈвхШчЯТЃК
var(
tablePrefix = []byte{'t'}
recordPrefixSep = []byte("_r")
indexPrefixSep = []byte("_i")
)
ОйИіМђЕЅЕФР§згЃЌМйЩшБэжага3ааЪ§ОнЃК
1,ЁАTiDBЁБ, ЁАSQL LayerЁБ, 10
2,ЁАTiKVЁБ, ЁАKV EngineЁБ, 20
3,ЁАPDЁБ, ЁАManagerЁБ, 30
ФЧУДЪзЯШУПааЪ§ОнЖМЛсгГЩфЮЊвЛИіKey-Value pairЃЌзЂвтЃЌетИіБэгавЛИіIntРраЭЕФPrimary KeyЃЌЫљвдRowIDЕФжЕМДЮЊетИіPrimary KeyЕФжЕЁЃМйЩшетИіБэЕФTable ID ЮЊ10ЃЌЦфжаRowЕФЪ§ОнЮЊЃК
t_r_10_1 --> ["TiDB", "SQL Layer", 10]
t_r_10_2 --> ["TiKV", "KV Engine", 20]
t_r_10_3 --> ["PD", "Manager", 30]
Г§СЫPrimary KeyжЎЭтЃЌетИіБэЛЙгавЛИіIndexЃЌМйЩшетИіIndexЕФIDЮЊ1ЃЌЦфЪ§ОнЮЊЃК
t_i_10_1_10_1 --> null
t_i_10_1_20_2 --> null
t_i_10_1_30_3 --> null
Database/Table ЖМгадЊаХЯЂЃЌвВОЭЪЧЦфЖЈвхвдМАИїЯюЪєадЃЌетаЉаХЯЂвВашвЊГжОУЛЏЃЌЮвУЧвВНЋетаЉаХЯЂДцДЂдкTiKVжаЁЃУПИіDatabase/TableЖМБЛЗжХфСЫвЛИіЮЈвЛЕФIDЃЌетИіIDзїЮЊЮЈвЛБъЪЖЃЌВЂЧвдкБрТыЮЊKey-ValueЪБЃЌетИіIDЖМЛсБрТыЕНKeyжаЃЌдйМгЩЯm_ЧАзКЁЃетбљПЩвдЙЙдьГівЛИіKeyЃЌValueжаДцДЂЕФЪЧађСаЛЏКѓЕФдЊЪ§ОнЁЃГ§ДЫжЎЭтЃЌЛЙгавЛИізЈУХЕФKey-ValueДцДЂЕБЧАSchemaаХЯЂЕФАцБОЁЃTiDBЪЙгУGoogle F1ЕФOnline SchemaБфИќЫуЗЈЃЌгавЛИіКѓЬЈЯпГЬдкВЛЖЯЕФМьВщTiKVЩЯУцДцДЂЕФSchemaАцБОЪЧЗёЗЂЩњБфЛЏЃЌВЂЧвБЃжЄдквЛЖЈЪБМфФквЛЖЈФмЙЛЛёШЁАцБОЕФБфЛЏЃЈШчЙћШЗЪЕЗЂЩњСЫБфЛЏЃЉЁЃ
ЫФ. SQL дЫЫу
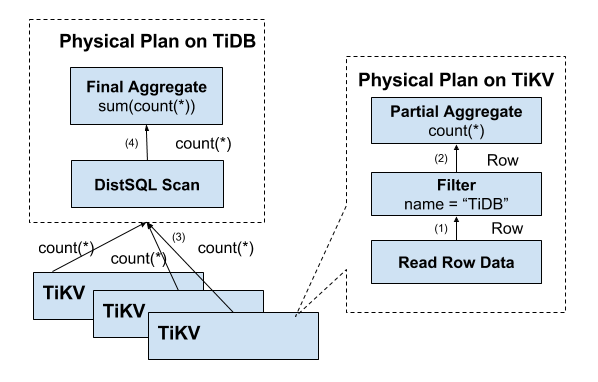
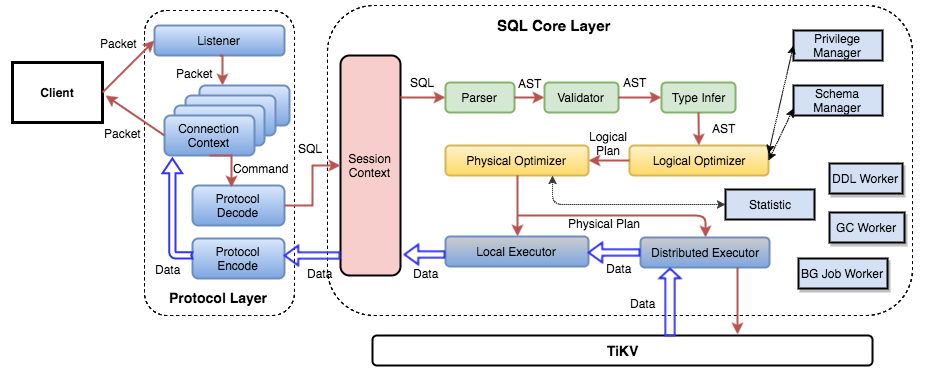
гУЛЇЕФ SQL ЧыЧѓЛсжБНгЛђепЭЈЙ§ Load Balancer ЗЂЫЭЕН tidb-serverЃЌtidb-server ЛсНтЮі MySQL Protocol PacketЃЌЛёШЁЧыЧѓФкШнЃЌШЛКѓзігяЗЈНтЮіЁЂВщбЏМЦЛЎжЦЖЈКЭгХЛЏЁЂжДааВщбЏМЦЛЎЛёШЁКЭДІРэЪ§ОнЁЃЪ§ОнШЋВПДцДЂдк TiKV МЏШКжаЃЌЫљвддкетИіЙ§ГЬжа tidb-server ашвЊКЭ tikv-server НЛЛЅЃЌЛёШЁЪ§ОнЁЃзюКѓ tidb-server ашвЊНЋВщбЏНсЙћЗЕЛиИјгУЛЇЁЃ
Юх. Еї ЖШ
ЕїЖШЕФСїГЬ
PD ВЛЖЯЕФЭЈЙ§ Store Лђеп Leader ЕФаФЬјАќЪеМЏаХЯЂЃЌЛёЕУећИіМЏШКЕФЯъЯИЪ§ОнЃЌВЂЧвИљОнетаЉаХЯЂвдМАЕїЖШВпТдЩњГЩЕїЖШВйзїађСаЃЌУПДЮЪеЕН Region Leader ЗЂРДЕФаФЬјАќЪБЃЌPD ЖМЛсМьВщЪЧЗёгаЖдетИі Region Д§НјааЕФВйзїЃЌЭЈЙ§аФЬјАќЕФЛиИДЯћЯЂЃЌНЋашвЊНјааЕФВйзїЗЕЛиИј Region LeaderЃЌВЂдкКѓУцЕФаФЬјАќжаМрВтжДааНсЙћЁЃ
зЂвтетРяЕФВйзїжЛЪЧИј Region Leader ЕФНЈвщЃЌВЂВЛБЃжЄвЛЖЈФмЕУЕНжДааЃЌОпЬхЪЧЗёЛсжДаавдМАЪВУДЪБКђжДааЃЌгЩ Region Leader здМКИљОнЕБЧАздЩэзДЬЌРДЖЈЁЃ
аХЯЂЪеМЏ
ЕїЖШвРРЕгкећИіМЏШКаХЯЂЕФЪеМЏЃЌашвЊжЊЕРУПИіTiKVНкЕуЕФзДЬЌвдМАУПИіRegionЕФзДЬЌЁЃTiKVМЏШКЛсЯђPDЛуБЈСНРраХЯЂЃК
ЃЈ1ЃЉУПИіTiKVНкЕуЛсЖЈЦкЯђPDЛуБЈНкЕуЕФећЬхаХЯЂЁЃ
TiKVНкЕуЃЈStoreЃЉгыPDжЎМфДцдкаФЬјАќЃЌвЛЗНУцPDЭЈЙ§аФЬјАќМьВтУПИіStoreЪЧЗёДцЛюЃЌвдМАЪЧЗёгааТМгШыЕФStoreЃЛСэвЛЗНУцЃЌаФЬјАќжавВЛсаЏДјетИіStoreЕФзДЬЌаХЯЂЃЌжївЊАќРЈЃК
a) змДХХЬШнСП
b) ПЩгУДХХЬШнСП
c) ГадиЕФRegionЪ§СП
d) Ъ§ОнаДШыЫйЖШ
e) ЗЂЫЭ/НгЪмЕФSnapshotЪ§СПЃЈReplicaжЎМфПЩФмЛсЭЈЙ§SnapshotЭЌВНЪ§ОнЃЉ
f) ЪЧЗёЙ§ди
g) БъЧЉаХЯЂЃЈБъЧЉЪЧЗёОпБИВуМЖЙиЯЕЕФвЛЯЕСаTagЃЉ
ЃЈ2ЃЉУПИі Raft Group ЕФ Leader ЛсЖЈЦкЯђ PD ЛуБЈRegionаХЯЂ
УПИіRaft Group ЕФ Leader КЭ PD жЎМфДцдкаФЬјАќЃЌгУгкЛуБЈетИіRegionЕФзДЬЌЃЌжївЊАќРЈЯТУцМИЕуаХЯЂЃК
a) LeaderЕФЮЛжУ
b) FollowersЕФЮЛжУ
c) ЕєЯпReplicaЕФИіЪ§
d) Ъ§ОнаДШы/ЖСШЁЕФЫйЖШ
PD ВЛЖЯЕФЭЈЙ§етСНРраФЬјЯћЯЂЪеМЏећИіМЏШКЕФаХЯЂЃЌдйвдетаЉаХЯЂзїЮЊОіВпЕФвРОнЁЃ
Г§ДЫжЎЭтЃЌPD ЛЙПЩвдЭЈЙ§ЙмРэНгПкНгЪмЖюЭтЕФаХЯЂЃЌгУРДзіИќзМШЗЕФОіВпЁЃБШШчЕБФГИі Store ЕФаФЬјАќжаЖЯЕФЪБКђЃЌPD ВЂВЛФмХаЖЯетИіНкЕуЪЧСйЪБЪЇаЇЛЙЪЧгРОУЪЇаЇЃЌжЛФмОЙ§вЛЖЮЪБМфЕФЕШД§ЃЈФЌШЯЪЧ 30 ЗжжгЃЉЃЌШчЙћвЛжБУЛгааФЬјАќЃЌОЭШЯЮЊЪЧ Store вбОЯТЯпЃЌдйОіЖЈашвЊНЋетИі Store ЩЯУцЕФ Region ЖМЕїЖШзпЁЃЕЋЪЧгаЕФЪБКђЃЌЪЧдЫЮЌШЫдБжїЖЏНЋФГЬЈЛњЦїЯТЯпЃЌетИіЪБКђЃЌПЩвдЭЈЙ§ PD ЕФЙмРэНгПкЭЈжЊ PD ИУ Store ВЛПЩгУЃЌPD ОЭПЩвдТэЩЯХаЖЯашвЊНЋетИі Store ЩЯУцЕФ Region ЖМЕїЖШзпЁЃ
ЕїЖШВпТд
PD ЪеМЏвдЩЯаХЯЂКѓЃЌЛЙашвЊвЛаЉВпТдРДжЦЖЈОпЬхЕФЕїЖШМЦЛЎЁЃ
вЛИіRegionЕФReplicaЪ§СПе§ШЗ
ЕБPDЭЈЙ§ФГИіRegion LeaderЕФаФЬјАќЗЂЯжетИіRegionЕФReplicaЕФЪ§СПВЛТњзувЊЧѓЪБЃЌашвЊЭЈЙ§Add/Remove ReplicaВйзїЕїећReplicaЪ§СПЁЃГіЯжетжжЧщПіЕФПЩФмдвђЪЧЃК
A.ФГИіНкЕуЕєЯпЃЌЩЯУцЕФЪ§ОнШЋВПЖЊЪЇЃЌЕМжТвЛаЉRegionЕФReplicaЪ§СПВЛзу
B.ФГИіЕєЯпНкЕугжЛжИДЗўЮёЃЌздЖЏНгШыМЏШКЃЌетбљжЎЧАвбОУжВЙСЫReplicaЕФRegionЕФReplicaЪ§СПЙ§ЖрЃЌашвЊЩОГ§ФГИіReplica
C.ЙмРэдБЕїећСЫИББОВпТдЃЌаоИФСЫmax-replicasЕФХфжУ
ЗУЮЪШШЕуЪ§СПдк Store жЎМфОљдШЗжХф
УПИіStoreвдМАRegion Leader дкЩЯБЈаХЯЂЪБаЏДјСЫЕБЧАЗУЮЪИКдиЕФаХЯЂЃЌБШШчKeyЕФЖСШЁ/аДШыЫйЖШЁЃPDЛсМьВтГіЗУЮЪШШЕуЃЌЧвНЋЦфдкНкЕужЎМфЗжЩЂПЊЁЃ
ИїИі Store ЕФДцДЂПеМфеМгУДѓжТЯрЕШ
УПИі Store ЦєЖЏЕФЪБКђЖМЛсжИЖЈвЛИі Capacity ВЮЪ§ЃЌБэУїетИі Store ЕФДцДЂПеМфЩЯЯоЃЌPD дкзіЕїЖШЕФЪБКђЃЌЛсПМТЧНкЕуЕФДцДЂПеМфЪЃгрСПЁЃ
ПижЦЕїЖШЫйЖШЃЌБмУтгАЯьдкЯпЗўЮё
ЕїЖШВйзїашвЊКФЗб CPUЁЂФкДцЁЂДХХЬ IO вдМАЭјТчДјПэЃЌЮвУЧашвЊБмУтЖдЯпЩЯЗўЮёдьГЩЬЋДѓгАЯьЁЃPD ЛсЖдЕБЧАе§дкНјааЕФВйзїЪ§СПНјааПижЦЃЌФЌШЯЕФЫйЖШПижЦЪЧБШНЯБЃЪиЕФЃЌШчЙћЯЃЭћМгПьЕїЖШ(БШШчвбОЭЃЗўЮёЩ§МЖЃЌдіМгаТНкЕуЃЌЯЃЭћОЁПьЕїЖШ)ЃЌФЧУДПЩвдЭЈЙ§ pd-ctl ЪжЖЏМгПьЕїЖШЫйЖШЁЃ
жЇГжЪжЖЏЯТЯпНкЕу
ЕБЭЈЙ§ pd-ctl ЪжЖЏЯТЯпНкЕуКѓЃЌPD ЛсдквЛЖЈЕФЫйТЪПижЦЯТЃЌНЋНкЕуЩЯЕФЪ§ОнЕїЖШзпЁЃЕБЕїЖШЭъГЩКѓЃЌОЭЛсНЋетИіНкЕужУЮЊЯТЯпзДЬЌЁЃ
вЛИі Raft Group жаЕФЖрИі Replica ВЛдкЭЌвЛИіЮЛжУ
| 







