| БрМЭЦМі: |
ЮФеТНВНтгХЛЏЩшМЦЗНАИ,Ъ§ОнБэЖдЯѓЃЌвЕЮёВугХЛЏВ№ЗжЃЌМмЙЙВугХЛЏЃЌЖСаДЗжРыММЪѕЃЌЯЃЭћЖдФњгаЫљАяжњ,
БОЮФРДздcsdnЃЌгЩЛ№СњЙћШэМўDeloresБрМЁЂЭЦМіЁЃ |
|
ЧЇЭђМЖДѓБэШчКЮгХЛЏЃЌетЪЧвЛИіКмгаММЪѕКЌСПЕФЮЪЬтЃЌЭЈГЃЮвУЧЕФжБОѕЫМЮЌЖМЛсЬјзЊЕНВ№ЗжЛђепЪ§ОнЗжЧјЃЌдкДЫЮвЯызівЛаЉВЙГфКЭЪсРэЃЌЯыКЭДѓМвзівЛаЉетЗНУцЕФОбщзмНсЃЌвВЛЖгДѓМвЬсГіНЈвщЁЃ
ДгвЛПЊЪМФдКЃРяПЊЪМвВЪЧЛ№ЙтЫФЯжЃЌЕНВЛЖЯЕФздЮвХњЦРЃЌКѓРДвВВЮПМСЫвЛаЉЭХЖгЕФОбщЃЌЮвећРэСЫЯТУцЕФДѓИйФкШнЁЃ

МШШЛвЊГдЭИетИіЮЪЬтЃЌЮвУЧЪЦБивЊЛиЕНБОдДЃЌЮвАбетИіЮЪЬтЗжЮЊШ§ВПЗж:
ЁАЧЇЭђМЖЁБЃЌЁАДѓБэЁБЃЌЁАгХЛЏЁБЃЌ
вВЗжБ№ЖдгІЮвУЧдкЭМжаБъЪЖЕФ
ЁАЪ§ОнСПЁБЃЌЁАЖдЯѓЁБКЭЁАФПБъЁБЁЃ
ЮвРДж№ВНеЙПЊЫЕУївЛЯТЃЌДгЖјИјГівЛЯЕСаЕФНтОіЗНАИЁЃ
1.Ъ§ОнСПЃКЧЇЭђМЖ
ЧЇЭђМЖЦфЪЕжЛЪЧвЛИіИаЙйЕФЪ§зжЃЌОЭЪЧЮвУЧгЁЯѓжаЕФЪ§ОнСПДѓЁЃ?етРяЮвУЧашвЊАбетИіИХФюЯИЛЏЃЌвђЮЊЫцзХвЕЮёКЭЪБМфЕФБфЛЏЃЌЪ§ОнСПвВЛсгаБфЛЏЃЌЮвУЧгІИУЪЧДјзХвЛжжЖЏЬЌЫМЮЌРДЩѓЪгетИіжИБъЃЌДгЖјЖдгкВЛЭЌЕФГЁОАЮвУЧгІИУгаВЛЭЌЕФДІРэВпТдЁЃ
1)Ъ§ОнСПЮЊЧЇЭђМЖЃЌПЩФмДяЕНвкМЖЛђепИќИп
ЭЈГЃЪЧвЛаЉЪ§ОнСїЫЎЃЌШежОМЧТМЕФвЕЮёЃЌРяУцЕФЪ§ОнЫцзХЪБМфЕФдіГЄЛсж№ВНдіЖрЃЌГЌЙ§ЧЇЭђУХМїЪЧКмШнвзЕФвЛМўЪТЧщЁЃ
2)Ъ§ОнСПЮЊЧЇЭђМЖЃЌЪЧвЛИіЯрЖдЮШЖЈЕФЪ§ОнСП
ШчЙћЪ§ОнСПЯрЖдЮШЖЈЃЌЭЈГЃЪЧдквЛаЉЦЋЯђгкзДЬЌЕФЪ§ОнЃЌБШШчга1000ЭђгУЛЇЃЌФЧУДетаЉгУЛЇЕФаХЯЂдкБэжаЖМгаЯргІЕФвЛааЪ§ОнМЧТМЃЌЫцзХвЕЮёЕФдіГЄЃЌетИіСПМЖЯрЖдЪЧБШНЯЮШЖЈЕФЁЃ
3)Ъ§ОнСПЮЊЧЇЭђМЖЃЌВЛгІИУгаетУДЖрЕФЪ§Он
етжжЧщПіЪЧЮвУЧБЛЖЏЗЂЯжЕФОгЖрЃЌЭЈГЃЗЂЯжЕФЪБКђвбОЭэСЫЃЌБШШчФуПДЕНвЛИіХфжУБэЃЌЪ§ОнСПЩЯЧЇЭђ;ЛђепЫЕвЛаЉБэРяЕФЪ§ОнвбОДцДЂСЫКмОУЃЌ99%ЕФЪ§ОнЖМЪєгкЙ§ЦкЪ§ОнЛђепРЌЛјЪ§ОнЁЃ
Ъ§ОнСПЪЧвЛИіећЬхЕФШЯЪЖЃЌЮвУЧашвЊЖдЪ§ОнзіИќНќвЛВуЕФРэНтЃЌетОЭПЩвдв§ГіЕкЖўИіВПЗжЕФФкШнЁЃ
2.ЖдЯѓЃКЪ§ОнБэ
Ъ§ОнВйзїЕФЙ§ГЬОЭКУБШЪ§ОнПтжаДцдкзХЖрЬѕЙмЕРЃЌетаЉЙмЕРжаЖМСїЬЪзХвЊДІРэЕФЪ§ОнЃЌетаЉЪ§ОнЕФгУДІКЭЙщЪєЪЧВЛвЛбљЕФЁЃ
вЛАуИљОнвЕЮёРраЭАбЪ§ОнЗжЮЊШ§жжЃК
ЃЈ1ЃЉСїЫЎаЭЪ§Он
СїЫЎаЭЪ§ОнЪЧЮозДЬЌЕФЃЌЖрБЪвЕЮёжЎМфУЛгаЙиСЊЃЌУПДЮвЕЮёЙ§РДЕФЪБКђЖМЛсВњЩњаТЕФЕЅОнЃЌБШШчНЛвзСїЫЎЁЂжЇИЖСїЫЎЃЌжЛвЊФмВхШыаТЕЅОнОЭФмЭъГЩвЕЮёЃЌЬиЕуЪЧКѓУцЕФЪ§ОнВЛвРРЕЧАУцЕФЪ§ОнЃЌЫљгаЕФЪ§ОнАДЪБМфСїЫЎНјШыЪ§ОнПтЁЃ
ЃЈ2ЃЉзДЬЌаЭЪ§Он
зДЬЌаЭЪ§ОнЪЧгазДЬЌЕФЃЌЖрБЪвЕЮёжЎМфвРРЕгкгазДЬЌЕФЪ§ОнЃЌЖјЧввЊБЃжЄИУЪ§ОнЕФзМШЗадЃЌБШШчГфжЕЪББиаывЊФУЕНдРДЕФгрЖюЃЌВХФмжЇИЖГЩЙІЁЃ
ЃЈ3ЃЉХфжУаЭЪ§Он
ДЫРраЭЪ§ОнЪ§ОнСПНЯаЁЃЌЖјЧвНсЙЙМђЕЅЃЌвЛАуЮЊОВЬЌЪ§ОнЃЌБфЛЏЦЕТЪКмЕЭЁЃ
жСДЫЃЌЮвУЧПЩвдЖдећЬхЕФБГОАгавЛИіШЯЪЖСЫЃЌШчЙћвЊзігХЛЏЃЌЦфЪЕвЊУцЖдЕФЪЧетбљЕФ3*3ЕФОиеѓЃЌШчЙћвЊПМТЧБэЕФЖСаДБШР§ЃЈЖСЖраДЩйЃЌЖСЩйаДЖр...ЃЉЃЌФЧУДОЭЛсЪЧ3*3*4=24жжЃЌЯдШЛзіЧюОйЪЧВЛЯдЪОЕФЃЌЖјЧввВЭъШЋУЛгаБивЊЃЌПЩвдеыЖдВЛЭЌЕФЪ§ОнДцДЂЬиадКЭвЕЮёЬиЕуРДжИЖЈВЛЭЌЕФвЕЮёВпТдЁЃ
ЖдДЫЮвУЧВЩШЁзЅзЁжиЕуЕФЗНЪНЃЌАбГЃМћЕФвЛаЉгХЛЏЫМТЗЪсРэГіРДЃЌгШЦфЪЧРяУцЕФКЫаФЫМЯыЃЌвВЪЧЮвУЧећИігХЛЏЩшМЦЕФвЛАбГпзгЃЌЖјФбЖШОіЖЈСЫЮвУЧзіетМўЪТЧщЕФЖЏСІКЭЗчЯеЁЃ

ЖјЖдгкгХЛЏЗНАИЃЌЮвЯыВЩгУУцЯђвЕЮёЕФЮЌЖШРДНјааВћЪіЁЃ
3.ФПБъЃКгХЛЏ
дкетИіНзЖЮЃЌЮвУЧвЊЫЕгХЛЏЕФЗНАИСЫЃЌзмНсЕФгаЕуЖрЃЌЯрЖдРДЫЕЪЧБШНЯШЋСЫЁЃ
ећЬхЗжЮЊЮхИіВПЗжЃК

ЦфЪЕЮвУЧЭЈГЃЫљЫЕЕФЗжПтЗжБэЕШЗНАИжЛЪЧЦфжаЕФвЛаЁВПЗжЃЌШчЙћеЙПЊжЎКѓОЭБШНЯЗсИЛСЫЁЃ

ЦфЪЕВЛФбРэНтЃЌЮвУЧвЊжЇГХЕФБэЪ§ОнСПЪЧЧЇЭђМЖБ№ЃЌЯрЖдРДЫЕЪЧБШНЯДѓСЫЃЌDBAвЊЮЌЛЄЕФБэПЯЖЈВЛжЙвЛеХЃЌШчКЮФмЙЛИќКУЕФЙмРэЃЌЭЌЪБдквЕЮёЗЂеЙжаФмЙЛжЇГХРЉеЙЃЌЭЌЪББЃжЄадФмЃЌетЪЧАкдкЮвУЧУцЧАЕФМИзљДѓЩНЁЃ
ЮвУЧЗжБ№РДЫЕвЛЯТетЮхРрИФНјЗНАИЃК
гХЛЏЩшМЦЗНАИ1.ЙцЗЖЩшМЦ
дкДЫЮвУЧЯШЬсЕНЕФЪЧЙцЗЖЩшМЦЃЌЖјВЛЪЧЦфЫћИпДѓЩЯЕФЩшМЦЗНАИЁЃ
КкИёЖћЫЕЃКжШађЪЧздгЩЕФЕквЛЬѕМўЁЃдкЗжЙЄазїЕФЙЄзїГЁОАжагШЦфживЊЃЌЗёдђЭХЖгжЎМфЛЅЯрЧЃжЦЬЋЖрЃЌЮЪЬтЖрЖрЁЃ
ЙцЗЖЩшМЦЮвЯыЬсЕНШчЯТЕФМИИіЙцЗЖЃЌЦфЪЕжЛЪЧЪєгкПЊЗЂЙцЗЖЕФвЛВПЗжФкШнЃЌПЩвдзїЮЊВЮПМЁЃ

ЙцЗЖЕФБОжЪВЛЪЧНтОіЮЪЬтЃЌЖјЪЧгааЇЖХОјвЛаЉЧБдкЮЪЬтЃЌЖдгкЧЇЭђМЖДѓБэвЊзёЪиЕФЙцЗЖЃЌЮвЪсРэСЫШчЯТЕФвЛаЉЯИдђЃЌЛљБОПЩвдКИЧЮвУЧГЃМћЕФвЛаЉЩшМЦКЭЪЙгУЮЪЬтЃЌБШШчБэЕФзжЖЮЩшМЦВЛЙмШ§ЦпЖўЪЎвЛЃЌЖМЪЧvarchar(500),ЦфЪЕЪЧКмВЛЙцЗЖЕФвЛжжЪЕЯжЗНЪНЃЌЮвУЧРДеЙПЊЫЕвЛЯТетМИИіЙцЗЖЁЃ
1ЃЉХфжУЙцЗЖ
ЃЈ1ЃЉMySQLЪ§ОнПтФЌШЯЪЙгУInnoDBДцДЂв§ЧцЁЃ
ЃЈ2ЃЉБЃжЄзжЗћМЏЩшжУЭГвЛЃЌMySQLЪ§ОнПтЯрЙиЯЕЭГЁЂЪ§ОнПтЁЂБэЕФзжЗћМЏЪЙЖМгУUTF8ЃЌгІгУГЬађСЌНгЁЂеЙЪОЕШПЩвдЩшжУзжЗћМЏЕФЕиЗНвВЖМЭГвЛЩшжУЮЊUTF8зжЗћМЏЁЃ
зЂЃКUTF8ИёЪНЪЧДцДЂВЛСЫБэЧщРрЪ§ОнЃЌашвЊЪЙгУUTF8MB4ЃЌПЩдкMySQLзжЗћМЏРяУцЩшжУЁЃдк8.0жавбОФЌШЯЮЊUTF8MB4ЃЌПЩвдИљОнЙЋЫОЕФвЕЮёЧщПіНјааЭГвЛЛђепЖЈжЦЛЏЩшжУЁЃ
ЃЈ3ЃЉMySQLЪ§ОнПтЕФЪТЮёИєРыМЖБ№ФЌШЯЮЊRRЃЈRepeatable-ReadЃЉЃЌНЈвщГѕЪМЛЏЪБЭГвЛЩшжУЮЊRCЃЈRead-CommittedЃЉЃЌЖдгкOLTPвЕЮёИќЪЪКЯЁЃ
ЃЈ4ЃЉЪ§ОнПтжаЕФБэвЊКЯРэЙцЛЎЃЌПижЦЕЅБэЪ§ОнСПЃЌЖдгкMySQLЪ§ОнПтРДЫЕЃЌНЈвщЕЅБэМЧТМЪ§ПижЦдк2000WвдФкЁЃ
ЃЈ5ЃЉMySQLЪЕР§ЯТЃЌЪ§ОнПтЁЂБэЪ§СПОЁПЩФмЩйЃЛЪ§ОнПтвЛАуВЛГЌЙ§50ИіЃЌУПИіЪ§ОнПтЯТЃЌЪ§ОнБэЪ§СПвЛАуВЛГЌЙ§500ИіЃЈАќРЈЗжЧјБэЃЉЁЃ
2ЃЉНЈБэЙцЗЖ
ЃЈ1ЃЉInnoDBНћжЙЪЙгУЭтМќдМЪјЃЌПЩвдЭЈЙ§ГЬађВуУцБЃжЄЁЃ
ЃЈ2ЃЉДцДЂОЋШЗИЁЕуЪ§БиаыЪЙгУDECIMALЬцДњFLOATКЭDOUBLEЁЃ
ЃЈ3ЃЉећаЭЖЈвхжаЮоашЖЈвхЯдЪОПэЖШЃЌБШШчЃКЪЙгУINTЃЌЖјВЛЪЧINT(4)ЁЃ
ЃЈ4ЃЉВЛНЈвщЪЙгУENUMРраЭЃЌПЩЪЙгУTINYINTРДДњЬцЁЃ
ЃЈ5ЃЉОЁПЩФмВЛЪЙгУTEXTЁЂBLOBРраЭЃЌШчЙћБиаыЪЙгУЃЌНЈвщНЋЙ§ДѓзжЖЮЛђЪЧВЛГЃгУЕФУшЪіаЭНЯДѓзжЖЮВ№ЗжЕНЦфЫћБэжаЃЛСэЭтЃЌНћжЙгУЪ§ОнПтДцДЂЭМЦЌЛђЮФМўЁЃ
ЃЈ6ЃЉДцДЂФъЪБЪЙгУYEAR(4)ЃЌВЛЪЙгУYEAR(2)ЁЃ
ЃЈ7ЃЉНЈвщзжЖЮЖЈвхЮЊNOT NULLЁЃ
ЃЈ8ЃЉНЈвщDBAЬсЙЉSQLЩѓКЫЙЄОпЃЌНЈБэЙцЗЖадашвЊЭЈЙ§ЩѓКЫЙЄОпЩѓКЫКѓ
3ЃЉУќУћЙцЗЖ
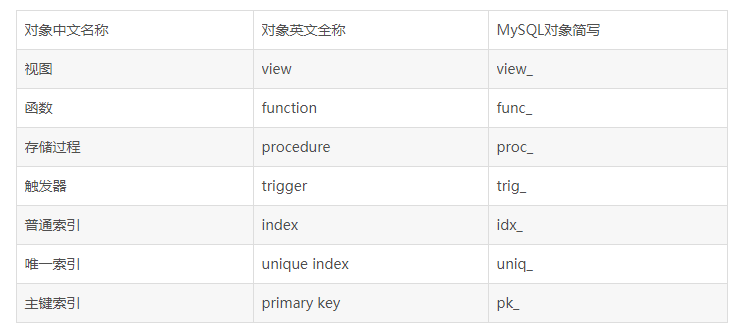
ЃЈ1ЃЉПтЁЂБэЁЂзжЖЮШЋВПВЩгУаЁаДЁЃ
ЃЈ2ЃЉПтУћЁЂБэУћЁЂзжЖЮУћЁЂЫїв§УћГЦОљЪЙгУаЁаДзжФИЃЌВЂвдЁА_ЁБЗжИюЁЃ
ЃЈ3ЃЉПтУћЁЂБэУћЁЂзжЖЮУћНЈвщВЛГЌЙ§12ИізжЗћЁЃЃЈПтУћЁЂБэУћЁЂзжЖЮУћжЇГжзюЖр64ИізжЗћЃЌЕЋЮЊСЫЭГвЛЙцЗЖЁЂвзгкБцЪЖвдМАМѕЩйДЋЪфСПЃЌЭГвЛВЛГЌЙ§12зжЗћЃЉ
ЃЈ4ЃЉПтУћЁЂБэУћЁЂзжЖЮУћМћУћжЊвтЃЌВЛашвЊЬэМгзЂЪЭЁЃ
ЖдгкЖдЯѓУќУћЙцЗЖЕФвЛИіМђвЊзмНсШчЯТБэ4-1ЫљЪОЃЌЙЉВЮПМЁЃ
УќУћСаБэ
4ЃЉЫїв§ЙцЗЖ
ЃЈ1ЃЉЫїв§НЈвщУќУћЙцдђЃКidx_col1_col2[_colN]ЁЂuniq_col1_col2[_colN]ЃЈШчЙћзжЖЮЙ§ГЄНЈвщВЩгУЫѕаДЃЉЁЃ
ЃЈ2ЃЉЫїв§жаЕФзжЖЮЪ§НЈвщВЛГЌЙ§5ИіЁЃ
ЃЈ3ЃЉЕЅеХБэЕФЫїв§ИіЪ§ПижЦдк5ИівдФкЁЃ
ЃЈ4ЃЉInnoDBБэвЛАуЖМНЈвщгажїМќСаЃЌгШЦфдкИпПЩгУМЏШКЗНАИжаЪЧзїЮЊБиаыЯюЕФЁЃ
ЃЈ5ЃЉНЈСЂИДКЯЫїв§ЪБЃЌгХЯШНЋбЁдёадИпЕФзжЖЮЗХдкЧАУцЁЃ
ЃЈ6ЃЉUPDATEЁЂDELETEгяОфашвЊИљОнWHEREЬѕМўЬэМгЫїв§ЁЃ
ЃЈ7ЃЉВЛНЈвщЪЙгУ%ЧАзКФЃК§ВщбЏЃЌР§ШчLIKE ЁА%weiboЁБЃЌЮоЗЈгУЕНЫїв§ЃЌЛсЕМжТШЋБэЩЈУшЁЃ
ЃЈ8ЃЉКЯРэРћгУИВИЧЫїв§ЃЌР§ШчЃК
ЃЈ9ЃЉSELECT email,uid FROM user_email WHERE uid=xxЃЌШчЙћuidВЛЪЧжїМќЃЌПЩвдДДНЈИВИЧЫїв§idx_uid_email(uid,email)РДЬсИпВщбЏаЇТЪЁЃ
ЃЈ10ЃЉБмУтдкЫїв§зжЖЮЩЯЪЙгУКЏЪ§ЃЌЗёдђЛсЕМжТВщбЏЪБЫїв§ЪЇаЇЁЃ
ЃЈ11ЃЉШЗШЯЫїв§ЪЧЗёашвЊБфИќЪБвЊСЊЯЕDBAЁЃ
5ЃЉгІгУЙцЗЖ
ЃЈ1ЃЉБмУтЪЙгУДцДЂЙ§ГЬЁЂДЅЗЂЦїЁЂздЖЈвхКЏЪ§ЕШЃЌШнвзНЋвЕЮёТпМКЭDBёюКЯдквЛЦ№ЃЌКѓЦкзіЗжВМЪНЗНАИЪБЛсГЩЮЊЦПОБЁЃ
ЃЈ2ЃЉПМТЧЪЙгУUNION ALLЃЌМѕЩйЪЙгУUNIONЃЌвђЮЊUNION ALLВЛШЅжиЃЌЖјЩйСЫХХађВйзїЃЌЫйЖШЯрЖдБШUNIONвЊПьЃЌШчЙћУЛгаШЅжиЕФашЧѓЃЌгХЯШЪЙгУUNION ALLЁЃ
ЃЈ3ЃЉПМТЧЪЙгУlimit NЃЌЩйгУlimit MЃЌNЃЌЬиБ№ЪЧДѓБэЛђMБШНЯДѓЕФЪБКђЁЃ
ЃЈ4ЃЉМѕЩйЛђБмУтХХађЃЌШчЃКgroup byгяОфжаШчЙћВЛашвЊХХађЃЌПЩвддіМгorder by nullЁЃ
ЃЈ5ЃЉЭГМЦБэжаМЧТМЪ§ЪБЪЙгУCOUNT(*)ЃЌЖјВЛЪЧCOUNT(primary_key)КЭCOUNT(1)ЃЛInnoDBБэБмУтЪЙгУCOUNT(*)ВйзїЃЌМЦЪ§ЭГМЦЪЕЪБвЊЧѓНЯЧППЩвдЪЙгУMemcacheЛђепRedisЃЌЗЧЪЕЪБЭГМЦПЩвдЪЙгУЕЅЖРЭГМЦБэЃЌЖЈЪБИќаТЁЃ
ЃЈ6ЃЉзізжЖЮБфИќВйзїЃЈmodify column/change columnЃЉЕФЪБКђБиаыМгЩЯдгаЕФзЂЪЭЪєадЃЌЗёдђаоИФКѓЃЌзЂЪЭЛсЖЊЪЇЁЃ
ЃЈ7ЃЉЪЙгУprepared statementПЩвдЬсИпадФмВЂЧвБмУтSQLзЂШыЁЃ
ЃЈ8ЃЉSQLгяОфжаINАќКЌЕФжЕВЛгІЙ§ЖрЁЃ
ЃЈ9ЃЉUPDATEЁЂDELETEгяОфвЛЖЈвЊгаУїШЗЕФWHEREЬѕМўЁЃ
ЃЈ10ЃЉWHEREЬѕМўжаЕФзжЖЮжЕашвЊЗћКЯИУзжЖЮЕФЪ§ОнРраЭЃЌБмУтMySQLНјаавўЪНРраЭзЊЛЏЁЃ
ЃЈ11ЃЉSELECTЁЂINSERTгяОфБиаыЯдЪНЕФжИУїзжЖЮУћГЦЃЌНћжЙЪЙгУSELECT *?ЛђЪЧINSERT INTO table_name values()ЁЃ
ЃЈ12ЃЉINSERTгяОфЪЙгУbatchЬсНЛЃЈINSERT INTO table_name VALUES(),(),()ЁЁЃЉЃЌvaluesЕФИіЪ§ВЛгІЙ§ЖрЁЃ
гХЛЏЩшМЦЗНАИ2ЃКвЕЮёВугХЛЏ
вЕЮёВугХЛЏгІИУЪЧЪевцзюИпЕФгХЛЏЗНЪНСЫЃЌЖјЧвЖдгквЕЮёВуЭъШЋПЩМћЃЌжївЊгавЕЮёВ№ЗжЃЌЪ§ОнВ№ЗжКЭСНРрГЃМћЕФгХЛЏГЁОАЃЈЖСЖраДЩйЃЌЖСЩйаДЖрЃЉ

1ЃЉвЕЮёВ№Зж
НЋЛьКЯвЕЮёВ№ЗжЮЊЖРСЂвЕЮё
НЋзДЬЌКЭРњЪЗЪ§ОнЗжРы
вЕЮёВ№ЗжЦфЪЕЪЧАбвЛИіЛьКЯЕФвЕЮёАўРыГЩЮЊИќМгЧхЮњЕФЖРСЂвЕЮёЃЌетбљвЕЮё1ЃЌвЕЮё2ЁЃЁЃЁЃЖРСЂЕФвЕЮёЪЙЕУвЕЮёзмСПвРОЩКмДѓЃЌЕЋЪЧУПИіВПЗжЖМЪЧЯрЖдЖРСЂЕФЃЌПЩППадвРШЛгаБЃжЄЁЃ
ЖдгкзДЬЌКЭРњЪЗЪ§ОнЗжРыЃЌЮвПЩвдОйвЛИіР§згРДЫЕУїЁЃ
Р§ШчЃКЮвУЧгавЛеХБэAccountЃЌМйЩшгУЛЇгрЖюЮЊ100ЁЃ

ЮвУЧашвЊдкЗЂЩњЪ§ОнБфИќКѓЃЌФмЙЛзЗЫнЪ§ОнБфИќЕФРњЪЗаХЯЂЃЌШчЙћЖдеЫЛЇИќаТзДЬЌЪ§ОнЃЌдіМг100ЕФгрЖюЃЌетбљгрЖюЮЊ200ЁЃ
етИіЙ§ГЬПЩФмЖдгІвЛЬѕupdateгяОфЃЌвЛЬѕinsertгяОфЁЃ
ЖдДЫЮвУЧПЩвдИФдьЮЊСНИіВЛЭЌЕФЪ§ОндДЃЌaccountКЭaccount_hist
дкaccount_histжаОЭЛсЪЧСНЬѕinsertМЧТМЃЌШчЯТ:

ЖјдкaccountжадђЪЧвЛЬѕupdateгяОфЃЌШчЯТЃК

етвВЪЧвЛжжКмЛљДЁЕФРфШШЗжРыЃЌПЩвдДѓДѓМѕЩйЮЌЛЄЕФИДдгЖШЃЌЬсИпвЕЮёЯьгІаЇТЪЁЃ
2ЃЉЪ§ОнВ№Зж
2.1 АДееШеЦкВ№ЗжЃЌетжжЪЙгУЗНЪНБШНЯЦеБщЃЌгШЦфЪЧАДееШеЦкЮЌЖШЕФВ№ЗжЃЌЦфЪЕдкГЬађВуУцЕФИФЖЏКмаЁЃЌЕЋЪЧРЉеЙадЗНУцЕФЪевцКмДѓЁЃ
Ъ§ОнАДееШеЦкЮЌЖШВ№ЗжЃЌШчtest_20191021
Ъ§ОнАДеежмдТЮЊЮЌЖШВ№Зж,Шчtest_201910
Ъ§ОнАДееМОЖШЃЌФъЮЌЖШВ№Зж,Шчtest_2019
2.2 ВЩгУЗжЧјФЃЪНЃЌЗжЧјФЃЪНвВЪЧГЃМћЕФЪЙгУЗНЪНЃЌВЩгУhash,rangeЕШЗНЪНЛсЖрвЛаЉЃЌдкMySQLжаЮвЪЧВЛДѓНЈвщЪЙгУЗжЧјБэЕФЪЙгУЗНЪНЃЌвђЮЊЫцзХДцДЂШнСПЕФдіГЄЃЌЪ§ОнЫфШЛзіСЫДЙжБВ№ЗжЃЌЕЋЪЧЙщИљНсЕзЃЌЪ§ОнЦфЪЕФбвдЪЕЯжЫЎЦНРЉеЙЃЌдкMySQLжаЪЧгаИќКУЕФРЉеЙЗНЪНЁЃ
2.3 ЖСЖраДЩйгХЛЏГЁОА
ВЩгУЛКДцЃЌВЩгУRedisММЪѕЃЌНЋЖСЧыЧѓДђдкЛКДцВуУцЃЌетбљПЩвдДѓДѓНЕЕЭMySQLВуУцЕФШШЕуЪ§ОнВщбЏбЙСІЁЃ
2.4ЖСЩйаДЖргХЛЏГЁОАЃЌПЩвдВЩгУШ§ВНзпЃК
1)ВЩгУвьВНЬсНЛФЃЪНЃЌвьВНЖдгкгІгУВуРДЫЕзюжБЙлЕФОЭЪЧадФмЕФЬсЩ§ЃЌВњЩњзюЩйЕФЭЌВНЕШД§ЁЃ
2)ЪЙгУЖгСаММЪѕЃЌДѓСПЕФаДЧыЧѓПЩвдЭЈЙ§ЖгСаЕФЗНЪНРДНјааРЉеЙЃЌЪЕЯжХњСПЕФЪ§ОнаДШыЁЃ
3)НЕЕЭаДШыЦЕТЪЃЌетИіБШНЯФбРэНтЃЌЮвОйИіР§зг
ЖдгквЕЮёЪ§ОнЃЌБШШчЛ§ЗжРрЃЌЯрБШгкН№ЖюРДЫЕвЕЮёгХЯШМЖТдЕЭЕФГЁОАЃЌШчЙћЪ§ОнЕФИќаТЙ§гкЦЕЗБЃЌПЩвдЪЪЖШЕїећЪ§ОнИќаТЕФЗЖЮЇЃЈБШШчДгдРДЕФУПЗжжгЕїећЮЊ10ЗжжгЃЉРДМѕЩйИќаТЕФЦЕТЪЁЃ
Р§ШчЃКИќаТзДЬЌЪ§ОнЃЌЛ§ЗжЮЊ200ЃЌШчЯТЭМЫљЪО

ПЩвдИФдьЮЊЃЌШчЯТЭМЫљЪОЁЃ

ШчЙћвЕЮёЪ§ОндкЖЬЪБМфФкИќаТЙ§гкЦЕЗБЃЌБШШч1ЗжжгИќаТ100ДЮЃЌЛ§ЗжДг100ЕН10000ЃЌдђПЩвдИљОнЪБМфЦЕТЪХњСПЬсНЛЁЃ
Р§ШчЃКИќаТзДЬЌЪ§ОнЃЌЛ§ЗжЮЊ100ЃЌШчЯТЭМЫљЪОЁЃ

ЮоашЩњГЩ100ИіЪТЮёЃЈ200ЬѕSQLгяОфЃЉПЩвдИФдьЮЊ2ЬѕSQLгяОфЃЌШчЯТЭМЫљЪОЁЃ

ЖдгквЕЮёжИБъЃЌБШШчИќаТЦЕТЪЯИНкаХЯЂЃЌПЩвдИљОнОпЬхвЕЮёГЁОАРДЬжТлОіЖЈЁЃ
гХЛЏЩшМЦЗНАИ3ЃКМмЙЙВугХЛЏ
МмЙЙВугХЛЏЦфЪЕОЭЪЧЮвУЧШЯЮЊЕФФЧжжММЪѕКЌСПКмИпЕФЙЄзїЃЌЮвУЧашвЊИљОнвЕЮёГЁОАдкМмЙЙВуУцв§ШывЛаЉаТЕФЛЈбљРДЁЃ

3.1.ЯЕЭГЫЎЦНРЉеЙГЁОА
3.1.1ВЩгУжаМфМўММЪѕЃЌПЩвдЪЕЯжЪ§ОнТЗгЩЃЌЫЎЦНРЉеЙЃЌГЃМћЕФжаМфМўгаMyCATЃЌShardingSphere,ProxySQLЕШ

3.1.2 ВЩгУЖСаДЗжРыММЪѕЃЌетЪЧеыЖдЖСашЧѓЕФРЉеЙЃЌИќВржигкзДЬЌБэЃЌдкдЪаэвЛЖЈбгГйЕФЧщПіЯТЃЌПЩвдВЩгУЖрИББОЕФФЃЪНЪЕЯжЖСашЧѓЕФЫЎЦНРЉеЙЃЌвВПЩвдВЩгУжаМфМўРДЪЕЯжЃЌШчMyCAT,ProxySQL,MaxScale,MySQL RouterЕШ

3.1.3 ВЩгУИКдиОљКтММЪѕЃЌГЃМћЕФгаLVSММЪѕЛђепЛљгкгђУћЗўЮёЕФConsulММЪѕЕШ
3.2.МцЙЫOLTP+OLAPЕФвЕЮёГЁОАЃЌПЩвдВЩгУNewSQLЃЌгХЯШМцШнMySQLавщЕФHTAPММЪѕеЛЃЌШчTiDB
3.3.РыЯпЭГМЦЕФвЕЮёГЁОАЃЌгаМИРрЗНАИПЩЙЉбЁдёЁЃ
3.3.1 ВЩгУNoSQLЬхЯЕЃЌжївЊгаСНРрЃЌвЛРрЪЧЪЪКЯМцШнMySQLавщЕФЪ§ОнВжПтЬхЯЕЃЌГЃМћЕФгаInfobrightЛђепColumnStoreЃЌСэЭтвЛРрЪЧЛљгкСаЪНДцДЂЃЌЪєгквьЙЙЗНЯђЃЌШчHBaseММЪѕ
3.3.2 ВЩгУЪ§ВжЬхЯЕЃЌЛљгкMPPМмЙЙ,ШчЪЙгУGreenplumЭГМЦЃЌШчT+1ЭГМЦ
гХЛЏЩшМЦЗНАИ4ЃКЪ§ОнПтгХЛЏ
Ъ§ОнПтгХЛЏЃЌЦфЪЕПЩДђЕФХЦвВВЛЩйЃЌЕЋЪЧЯрЖдРДЫЕПеМфУЛгаФЧУДДѓСЫЃЌЮвУЧРДж№ИіЫЕвЛЯТЁЃ

4.1 ЪТЮёгХЛЏ
ИљОнвЕЮёГЁОАбЁдёЪТЮёФЃаЭЃЌЪЧЗёЪЧЧПЪТЮёвРРЕ
ЖдгкЪТЮёНЕЮЌВпТдЃЌЮвУЧРДОйГіМИИіаЁР§згРДЁЃ
4.1.1 НЕЮЌВпТд1ЃКДцДЂЙ§ГЬЕїгУзЊЛЛЮЊЭИУїЕФSQLЕїгУ
ЖдгкаТвЕЮёЖјбдЃЌЪЙгУДцДЂЙ§ГЬЯдШЛВЛЪЧвЛИіКУжївтЃЌMySQLЕФДцДЂЙ§ГЬКЭЦфЫћЩЬвЕЪ§ОнПтЯрБШЃЌЙІФмКЭадФмЖМгаД§бщжЄЃЌЖјЧвдкФПЧАЧсСПЛЏЕФвЕЮёДІРэжаЃЌДцДЂЙ§ГЬЕФДІРэЗНЪНЬЋЁАжиЁБСЫЁЃ
гааЉгІгУМмЙЙПДЦ№РДЪЧАДееЗжВМЪНВПЪ№ЕФЃЌЕЋдкЪ§ОнПтВуЕФЕїгУЗНЪНЪЧЛљгкДцДЂЙ§ГЬЃЌвђЮЊДцДЂЙ§ГЬЗтзАСЫДѓСПЕФТпМЃЌФбвдЕїЪдЃЌЖјЧввЦжВадВЛИпЃЌетбљвЕЮёТпМКЭадФмбЙСІЖМдкЪ§ОнПтВуУцСЫЃЌЪЙЕУЪ§ОнПтВуКмШнвзГЩЮЊЦПОБЃЌЖјЧвФбвдЪЕЯжеце§ЕФЗжВМЪНЁЃ
ЫљвдгавЛИіУїШЗЕФИФНјЗНЯђОЭЪЧЖдгкДцДЂЙ§ГЬЕФИФдьЃЌАбЫќИФдьЮЊSQLЕїгУЕФЗНЪНЃЌПЩвдМЋДѓЕиЬсИпвЕЮёЕФДІРэаЇТЪЃЌдкЪ§ОнПтЕФНгПкЕїгУЩЯзуЙЛМђЕЅЖјЧвЧхЮњПЩПиЁЃ
4.1.2 НЕЮЌВпТд2ЃКDDLВйзїзЊЛЛЮЊDMLВйзї
гааЉвЕЮёОГЃЛсгавЛжжНєМБашЧѓЃЌзмЪЧашвЊИјвЛИіБэЬэМгзжЖЮЃЌИуЕУDBAКЭвЕЮёЭЌбЇЖМЭІРлЃЌПЩвдЯыЯѓвЛИіБэгаЩЯАйИізжЖЮЃЌЖјЧвЛљБОЖМЪЧname1ЃЌname2ЁЁname100ЃЌетжжЩшМЦБОЩэОЭЪЧгаЮЪЬтЕФЃЌИќВЛгУПМТЧадФмСЫЁЃОПЦфдвђЃЌЪЧвђЮЊвЕЮёЕФашЧѓЖЏЬЌБфЛЏЃЌБШШчвЛИігЮЯЗзАБИга20ИіЪєадЃЌПЩФмЙ§СЫвЛИідТжЎКѓОЭдіМгЕНСЫ40ИіЪєадЃЌетбљвЛРДЃЌЫљгаЕФзАБИЖМга40ИіЪєадЃЌВЛЙмгУУЛгУЕНЃЌЖјЧветжжЗНЪНвВДцдкжюЖрЕФШпгрЁЃ
ЮвУЧдкЩшМЦЙцЗЖРяУцвВЬсЕНСЫвЛаЉЩшМЦЕФЛљБОвЊЫиЃЌдкетаЉЛљДЁЩЯашвЊВЙГфЕФЪЧЃЌБЃГжгаЯоЕФзжЖЮЃЌШчЙћвЊЪЕЯжетаЉЙІФмЕФРЉеЙЃЌЦфЪЕЭъШЋПЩвдЭЈЙ§ХфжУЛЏЕФЗНЪНРДЪЕЯжЃЌБШШчАбвЛаЉЖЏЬЌЬэМгЕФзжЖЮзЊЛЛЮЊвЛаЉХфжУаХЯЂЁЃХфжУаХЯЂПЩвдЭЈЙ§DMLЕФЗНЪННјаааоИФКЭВЙГфЃЌЖдгкЪ§ОнШыПквВПЩвдИќМгЖЏЬЌЁЂвзРЉеЙЁЃ
4.1.3 НЕЮЌВпТд3ЃКDeleteВйзїзЊЛЛЮЊИпаЇВйзї
гааЉвЕЮёашвЊЖЈЦкРДЧхРэвЛаЉжмЦкадЪ§ОнЃЌБШШчБэРяЕФЪ§ОнжЛБЃСєвЛИідТЃЌФЧУДГЌГіЪБМфЗЖЮЇЕФЪ§ОнОЭвЊЧхРэЕєСЫЃЌЖјШчЙћБэЕФСПМЖБШНЯДѓЕФЧщПіЯТЃЌетжжDeleteВйзїЕФДњМлЪЕдкЬЋИпЃЌЮвУЧПЩвдгаСНРрНтОіЗНАИРДАбDeleteВйзїзЊЛЛЮЊИќЮЊИпаЇЕФЗНЪНЁЃ
ЕквЛжжЪЧИљОнвЕЮёНЈСЂжмЦкБэЃЌБШШчАДеедТБэЁЂжмБэЁЂШеБэЕШЮЌЖШРДЩшМЦЃЌетбљЪ§ОнЕФЧхРэОЭЪЧвЛИіЯрЖдПЩПиЖјЧвИпаЇЕФЗНЪНСЫЁЃ
ЕкЖўжжЗНАИЪЧЪЙгУMySQL renameЕФВйзїЗНЪНЃЌБШШчвЛеХ2ЧЇЭђЕФДѓБэвЊЧхРэ99%ЕФЪ§ОнЃЌФЧУДашвЊБЃСєЕФ1%ЕФЪ§ОнЮвУЧПЩвдКмПьИљОнЬѕМўЙ§ТЫВЙТМЃЌЪЕЯжЁАвЦаЮЛЛЮЛЁБЁЃ
4.2 SQLгХЛЏ
ЦфЪЕЯрЖдРДЫЕашвЊЕФМЋМђЕФЩшМЦЃЌКмЖрЕуЖМдкЙцЗЖЩшМЦРяУцСЫЃЌШчЙћзёЪиЙцЗЖЃЌАЫОХВЛРыЪЎЕФЮЪЬтЖМЛсЖХОјЕєЃЌдкДЫВЙГфМИЕуЃК
4.2.1 SQLгяОфМђЛЏЃЌМђЛЏЪЧSQLгХЛЏЕФвЛДѓРћЦїЃЌвђЮЊМђЕЅЃЌЫљвдгХдНЁЃ
4.2.2 ОЁПЩФмБмУтЛђепЖХОјЖрБэИДдгЙиСЊЃЌДѓБэЙиСЊЪЧДѓБэДІРэЕФиЌУЮЃЌвЛЕЉДђПЊСЫетИіПкзгЃЌдНРДдНЖрЕФашЧѓашвЊЙиСЊЃЌадФмгХЛЏОЭУЛгаЛиЭЗТЗСЫЃЌИќКЮПіДѓБэЙиСЊЪЧMySQLЕФШѕЯюЃЌОЁЙмHash JoinВХЭЦГіЃЌВЛвЊЯёеЦЮеСЫОјЖдДѓЩБЦївЛбљЃЌдкЩЬвЕЪ§ОнПтжадчОЭДцдкЃЌЮЪЬтеебљВуГіВЛЧюЁЃ
4.2.3 SQLжаОЁПЩФмБмУтЗДСЌНгЃЌБмУтАыСЌНгЃЌетЪЧгХЛЏЦїзіЕУБЁШѕЕФвЛЗНУцЃЌЪВУДЪЧЗДСЌНгЃЌАыСЌНгЦфЪЕБШНЯКУРэНтЃЌОйИіР§згЃЌnot in,not existsОЭЪЧЗДСЌНгЃЌin,existsОЭЪЧАыСЌНгЃЌдкЧЇЭђМЖДѓБэжаГіЯжетжжЮЪЬтЃЌадФмЪЧМИИіЪ§СПМЖЕФВювьЁЃ
4.3 Ыїв§гХЛЏ
гІИУЪЧДѓБэгХЛЏжаашвЊАбЮеЕФвЛИіЖШЁЃ
4.3.1 ЪзЯШБиаыгажїМќЃЌЙцЗЖЩшМЦжаЕквЛЬѕОЭЪЧЃЌДЫДІВЛНгЪеЗДВЕЁЃ
4.3.2 ЦфДЮЃЌSQLВщбЏЛљгкЫїв§ЛђепЮЈвЛадЫїв§ЃЌЪЙЕУВщбЏФЃаЭОЁПЩФмМђЕЅЁЃ
4.3.3 зюКѓЃЌОЁПЩФмЖХОјЗЖЮЇЪ§ОнЕФВщбЏЃЌЗЖЮЇЩЈУшдкЧЇЭђМЖДѓБэЧщПіЯТЛЙЪЧОЁПЩФмМѕЩйЁЃ
гХЛЏЩшМЦЗНАИ4ЃКЙмРэгХЛЏ
етВПЗжгІИУЪЧдкЫљгаЕФНтОіЗНАИжазюШнвзБЛКіЪгЕФВПЗжСЫЃЌЮвЗХдкзюКѓЃЌдкДЫвВЯђдЫЮЌЭЌЪТжТОДЃЌзмЪЧЮЊКмЖрШЯЮЊБОгІИУе§ГЃЕФЮЪЬтОЁжАОЁд№ЃЈБГЙјЃЉЁЃ

ЧЇЭђМЖДѓБэЕФЪ§ОнЧхРэвЛАуРДЫЕЪЧБШНЯКФЪБЕФЃЌдкДЫНЈвщдкЩшМЦжаашвЊЭъЩЦРфШШЪ§ОнЗжРыЕФВпТдЃЌПЩФмЬ§Ц№РДБШНЯожПкЃЌЮвРДОйвЛИіР§згЃЌАбДѓБэЕФDrop ВйзїзЊЛЛЮЊПЩФцЕФDDLВйзїЁЃ
DropВйзїЪЧФЌШЯЬсНЛЕФЃЌЖјЧвЪЧВЛПЩФцЕФЃЌдкЪ§ОнПтВйзїжаЖМЪЧХмТЗЕФДњУћДЪЃЌMySQLВуУцФПЧАУЛгаЯргІЕФDropВйзїЛжИДЙІФмЃЌГ§ЗЧЭЈЙ§БИЗнРДЛжИДЃЌЕЋЪЧЮвУЧПЩвдПМТЧНЋDropВйзїзЊЛЛЮЊвЛжжПЩФцЕФDDLВйзїЁЃ
MySQLжаФЌШЯУПИіБэгавЛИіЖдгІЕФibdЮФМўЃЌЦфЪЕПЩвдАбDropВйзїзЊЛЛЮЊвЛИіrenameВйзїЃЌМДАбЮФМўДгtestdbЧЈвЦЕНtestdb_archЯТУцЃЛДгШЈЯоЩЯРДЫЕЃЌtestdb_archЪЧвЕЮёВЛПЩМћЕФЃЌrenameВйзїПЩвдЦНЛЌЕФЪЕЯжетИіЩОГ§ЙІФмЃЌШчЙћдквЛЖЈЪБМфКѓШЗШЯПЩвдЧхРэЃЌдђЪ§ОнЧхРэЖдгквбгаЕФвЕЮёСїГЬЪЧВЛПЩМћЕФЃЌШчЯТЭМЫљЪОЁЃ

ДЫЭтЃЌЛЙгаСНИіЖюЭтНЈвщЃЌвЛИіЪЧЖдгкДѓБэБфИќЃЌОЁПЩФмПМТЧЕЭЗхЪБЖЮЕФдкЯпБфИќЃЌБШШчЪЙгУpt-oscЙЄОпЛђепЪЧЮЌЛЄЪБЖЮЕФБфИќЃЌОЭВЛдйзИЪіСЫЁЃ
зюКѓзмНсвЛЯТЃЌЦфЪЕОЭЪЧвЛОфЛАЃК
ЧЇЭђМЖДѓБэЕФгХЛЏЪЧИљОнвЕЮёГЁОАЃЌвдГЩБОЮЊДњМлНјаагХЛЏЕФЃЌОјЖдВЛЪЧЙТСЂЕФвЛИіВуУцЕФгХЛЏЁЃ
| 







