| БрМЭЦМі: |
БОЮФжївЊЖдRedisЕУНщЩмЃЌRedisЕФЪ§ОнРраЭЃЌredisЪЪгУГЁОАЃЌRedisИпВЂЗЂМАШШkeyНтОіжЎЕРЕШЯрЙиФкШнЁЃ
БОЮФРДздМђЪщЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
вЛ.RedisМђНщ
Redis ЪЧЭъШЋПЊдДУтЗбЕФЃЌЪЧвЛИіИпадФмЕФkey-valueРраЭЕФФкДцЪ§ОнПтЁЃећИіЪ§ОнПтЭГЭГМгдидкФкДцЕБжаНјааВйзїЃЌЖЈЦкЭЈЙ§вьВНВйзїАбЪ§ОнПтЪ§ОнflushЕНгВХЬЩЯНјааБЃДцЁЃвђЮЊЪЧДПФкДцВйзїЃЌRedisЕФадФмЗЧГЃГіЩЋЃЌУПУыПЩвдДІРэГЌЙ§
10ЭђДЮЖСаДВйзїЃЌЪЧвбжЊадФмзюПьЕФKey-Value DBЁЃ
RedisЕФГіЩЋжЎДІВЛНіНіЪЧадФмЃЌRedisзюДѓЕФїШСІЪЧжЇГжБЃДцЖржжЪ§ОнНсЙЙЃЌДЫЭтЕЅИіvalueЕФзюДѓЯожЦЪЧ1GBЃЌвђДЫRedisПЩвдгУРДЪЕЯжКмЖргагУЕФЙІФмЃЌБШЗНЫЕгУListРДзіFIFOЫЋЯђСДБэЃЌЪЕЯжвЛИіЧсСПМЖЕФИпад
ФмЯћЯЂЖгСаЗўЮёЃЌгУЫћЕФSetПЩвдзіИпадФмЕФtagЯЕЭГЕШЕШЁЃСэЭтRedisвВПЩвдЖдДцШыЕФKey-ValueЩшжУexpireЪБМфЁЃзмНсРДЫЕЃЌЪЙгУRedisЕФКУДІШчЯТЃК
1.ЫйЖШПьЃЌвђЮЊЪ§ОнДцдкФкДцжаЃЌЖСЕФЫйЖШЪЧ 110000 ДЮ /s,
аДЕФЫйЖШЪЧ 81000 ДЮ /sЃЛ
2.жЇГжЗсИЛЪ§ОнРраЭЃЌжЇГжstringЃЌlistЃЌsetЃЌsorted
setЃЌhashЃЛ
3.жЇГжЪТЮёЃЌВйзїЖМЪЧдзгадЃЌЖдЪ§ОнЕФИќИФвЊУДШЋВПжДааЃЌвЊУДШЋВПВЛжДааЃЌЪТЮёжаШЮвтУќСюжДааЪЇАмЃЌЦфгрУќСювРШЛБЛжДааЁЃвВОЭЪЧЫЕ
Redis ЪТЮёВЛБЃжЄдзгадЃЌвВВЛжЇГжЛиЙіЃЛЪТЮёжаЕФЖрЬѕУќСюБЛвЛДЮадЗЂЫЭИјЗўЮёЦїЃЌЗўЮёЦїдкжДааУќСюЦкМфЃЌВЛЛсШЅжДааЦфЫћПЭЛЇЖЫЕФУќСюЧыЧѓЁЃ
4.ЗсИЛЕФЬиадЃКПЩгУгкЛКДцЃЌЯћЯЂЃЈжЇГж publish/subscribe
ЭЈжЊЃЉЃЌАДkeyЩшжУЙ§ЦкЪБМфЃЌЙ§ЦкКѓНЋЛсздЖЏЩОГ§ЃЌОпЬхЬдЬВпТдгаЃК
ЁЁЁЁ4.1.volatile-lruЃКДгвбОЩшжУЙ§ЦкЪБМфЕФЪ§ОнМЏжаЃЌЬєбЁзюНќзюЩйЪЙгУЕФЪ§ОнЬдЬ
ЁЁЁЁ4.2.volatile-ttlЃКДгвбОЩшжУЙ§ЦкЪБМфЕФЪ§ОнМЏжаЃЌЬєбЁМДНЋвЊЙ§ЦкЕФЪ§ОнЬдЬ
ЁЁЁЁ4.3.volatile-randomЃКДгвбОЩшжУЙ§ЦкЪБМфЕФЪ§ОнМЏжаЃЌЫцЛњЬєбЁЪ§ОнЬдЬ
ЁЁЁЁ4.4.allkeys-lruЃКДгЫљгаЕФЪ§ОнМЏжаЃЌЬєбЁзюНќзюЩйЪЙгУЕФЪ§ОнЬдЬ
ЁЁЁЁ4.5.allkeys-randomЃКДгЫљгаЕФЪ§ОнМЏжаЃЌЫцЛњЬєбЁЪ§ОнЬдЬ
ЁЁЁЁ4.6.no-envictionЃКНћжЙЬдЬЪ§Он
ОпЬхЙ§ЦкМќЕФВпТдгаЃКЖЈЪБЩОГ§ЃЈЛКДцЙ§ЦкЪБМфЕНОЭЩОГ§ЃЌДДНЈtimerКФCPUЃЉЃЌЖшадЩОГ§ЃЈЛёШЁЕФЪБКђМьВщЃЌВЛЛёШЁвЛжБСєдкФкДцЃЌЖдФкДцВЛгбКУЃЉЃЌЖЈЦкЩОГ§ЃЈCPUКЭФкДцЕФелжаЗНАИЃЉ
5.жЇГжЪ§ОнГжОУЛЏЃЌПЩвдНЋФкДцжаЕФЪ§ОнБЃДцдкДХХЬжаЃЌжиЦєЕФЪБКђПЩвддйДЮМгдиНјааЪЙгУЃЛ
6.жЇГжЪ§ОнЕФБИЗнЃЌМД master - slave ФЃЪНЕФЪ§ОнБИЗнЁЃ
RedisЕФжївЊШБЕуЪЧЪ§ОнПтШнСПЪмЕНЮяРэФкДцЕФЯожЦЃЌВЛФмгУзїКЃСПЪ§ОнЕФИпадФмЖСаДЃЌвђДЫRedisЪЪКЯЕФГЁОАжївЊОжЯодкНЯаЁЪ§ОнСПЕФИпадФмВйзїКЭдЫЫуЩЯЁЃ
Жў.RedisЕФЪ§ОнРраЭ
Redis жЇГж 5 жаЪ§ОнРраЭЃКstringЃЈзжЗћДЎЃЉЃЌhashЃЈЙўЯЃЃЉЃЌlistЃЈСаБэЃЉЃЌsetЃЈМЏКЯЃЉЃЌzsetЃЈsorted
setЃКгаађМЏКЯЃЉЁЃУПжжЪ§ОнРраЭЕФОпЬхУќСюЧыВЮПМRedis УќСюВЮПМ
string
string ЪЧ redis зюЛљБОЕФЪ§ОнРраЭЁЃвЛИі key ЖдгІвЛИі
valueЁЃstring ЪЧЖўНјжЦАВШЋЕФЁЃвВОЭЪЧЫЕ redis ЕФ string ПЩвдАќКЌШЮКЮЪ§ОнЁЃБШШч
jpg ЭМЦЌЛђепађСаЛЏЕФЖдЯѓЁЃstring РраЭЪЧ redis зюЛљБОЕФЪ§ОнРраЭЃЌstring РраЭЕФжЕзюДѓФмДцДЂ
512 MBЁЃ
hash
Redis hash ЪЧвЛИіМќжЕЖдЃЈkey - valueЃЉМЏКЯЁЃRedis
hash ЪЧвЛИі string РраЭЕФ key КЭ value ЕФгГЩфБэЃЌhash ЬиБ№ЪЪКЯгУгкДцДЂЖдЯѓЁЃВЂЧвПЩвдЯёЪ§ОнПтжавЛбљжЛЖдФГвЛЯюЪєаджЕНјааДцДЂЁЂЖСШЁЁЂаоИФЕШВйзїЁЃ
list
Redis СаБэЪЧМђЕЅЕФзжЗћДЎСаБэЃЌАДееВхШыЫГађХХађЁЃЮвУЧПЩвдЭјСаБэЕФзѓБпЛђепгвБпЬэМгдЊЫиЁЃ
list ОЭЪЧвЛИіМђЕЅЕФзжЗћДЎМЏКЯЃЌКЭ Java жаЕФ list ЯрВюВЛДѓЃЌЧјБ№ОЭЪЧетРяЕФ list
ДцЗХЕФЪЧзжЗћДЎЁЃlist ФкЕФдЊЫиЪЧПЩжиИДЕФЁЃПЩвдзіЯћЯЂЖгСаЛђзюаТЯћЯЂХХааЕШЙІФмЁЃ
set
redis ЕФ set ЪЧзжЗћДЎРраЭЕФЮоађМЏКЯЁЃМЏКЯЪЧЭЈЙ§ЙўЯЃБэЪЕЯжЕФЃЌвђДЫЬэМгЁЂЩОГ§ЁЂВщевЕФИДдгЖШЖМЪЧ
OЃЈ1ЃЉЁЃredis ЕФ set ЪЧвЛИі key ЖдгІзХЖрИізжЗћДЎРраЭЕФ valueЃЌвВЪЧвЛИізжЗћДЎРраЭЕФМЏКЯЃЌКЭ
redis ЕФ list ВЛЭЌЕФЪЧ set жаЕФзжЗћДЎМЏКЯдЊЫиВЛФмжиИДЃЌЕЋЪЧ list ПЩвдЁЃРћгУЮЈвЛадЃЌПЩвдЭГМЦЗУЮЪЭјеОЕФЫљгаЖРСЂ
ipЁЃ
Zset
redis zset КЭ set вЛбљЖМЪЧзжЗћДЎРраЭдЊЫиЕФМЏКЯЃЌВЂЧвМЏКЯФкЕФдЊЫиВЛФмжиИДЁЃВЛЭЌЕФЪЧ
zset УПИідЊЫиЖМЛсЙиСЊвЛИі double РраЭЕФЗжЪ§ЁЃredis ЭЈЙ§ЗжЪ§РДЮЊМЏКЯжаЕФГЩдБНјааДгаЁЕНДѓЕФХХађЁЃzset
ЕФдЊЫиЪЧЮЈвЛЕФЃЌЕЋЪЧЗжЪ§ЃЈscoreЃЉШДПЩвджиИДЁЃПЩгУзїХХааАёЕШГЁОАЁЃ
Ш§.redisЪЪгУГЁОА
1.ЛсЛАЛКДцЃЈSession CacheЃЉ
зюГЃгУЕФвЛжжЪЙгУRedisЕФЧщОАЪЧЛсЛАЛКДцЃЈsession cacheЃЉЁЃгУRedisЛКДцЛсЛАБШЦфЫћДцДЂЃЈШчMemcachedЃЉЕФгХЪЦдкгкЃКRedisЬсЙЉГжОУЛЏЁЃЕБЮЌЛЄвЛИіВЛЪЧбЯИёвЊЧѓвЛжТадЕФЛКДцЪБЃЌШчЙћгУЛЇЕФЙКЮяГЕаХЯЂШЋВПЖЊЪЇЃЌДѓВПЗжШЫЖМЛсВЛИпаЫЕФЁЃ
2.ЖгСа
ReidsдкФкДцДцДЂв§ЧцСьгђЕФвЛДѓгХЕуЪЧЬсЙЉ list КЭ set
ВйзїЃЌетЪЙЕУRedisФмзїЮЊвЛИіКмКУЕФЯћЯЂЖгСаЦНЬЈРДЪЙгУЁЃRedisзїЮЊЖгСаЪЙгУЕФВйзїЃЌОЭРрЫЦгкБОЕиГЬађгябдЃЈШчPythonЃЉЖд
list ЕФ push/pop ВйзїЁЃ
3.ШЋвГЛКДц
ДѓаЭЛЅСЊЭјЙЋЫОЖМЛсЪЙгУRedisзїЮЊЛКДцДцДЂЪ§ОнЃЌЬсЩ§вГУцЯргІЫйЖШЁЃМДЪЙжиЦєСЫRedisЪЕР§ЃЌвђЮЊгаДХХЬЕФГжОУЛЏЃЌгУЛЇвВВЛЛсПДЕНвГУцМгдиЫйЖШЕФЯТНЕЁЃ
4.ХХааАё/МЦЪ§Цї
RedisдкФкДцжаЖдЪ§зжНјааЕндіЛђЕнМѕЕФВйзїЪЕЯжЕФЗЧГЃКУЁЃМЏКЯЃЈSetЃЉКЭгаађМЏКЯЃЈSorted
SetЃЉвВЪЙЕУЮвУЧдкжДааетаЉВйзїЕФЪБКђБфЕФЗЧГЃМђЕЅЁЃ
ЫФ.RedisИпПЩгУМмЙЙ
1.ГжОУЛЏ
Redis ЪЧФкДцаЭЪ§ОнПтЃЌЮЊСЫБЃжЄЪ§ОндкЖЯЕчКѓВЛЛсЖЊЪЇЃЌашвЊНЋФкДцжаЕФЪ§ОнГжОУЛЏЕНгВХЬЩЯЁЃRedisЬсЙЉСЫСНжжГжОУЛЏЕФЗНЪНЃЌЗжБ№ЪЧRDBЃЈRedis
DataBaseЃЉКЭAOFЃЈAppend Only FileЃЉЁЃ
RDB
МђЖјбджЎЃЌОЭЪЧдкВЛЭЌЕФЪБМфЕуЃЌНЋredisДцДЂЕФЪ§ОнЩњГЩПьееВЂДцДЂЕНДХХЬЕШНщжЪЩЯЃЌПЩвдНЋПьееИДжЦЕНЦфЫћЗўЮёЦїДгЖјДДНЈОпгаЯрЭЌЪ§ОнЕФЗўЮёЦїИББОЁЃШчЙћЯЕЭГЗЂЩњЙЪеЯЃЌНЋЛсЖЊЪЇзюКѓвЛДЮДДНЈПьеежЎКѓЕФЪ§ОнЁЃШчЙћЪ§ОнСПДѓЃЌБЃДцПьееЕФЪБМфЛсКмГЄЁЃ
AOF
ЛЛСЫвЛИіНЧЖШРДЪЕЯжГжОУЛЏЃЌФЧОЭЪЧНЋredisжДааЙ§ЕФЫљгааДжИСюМЧТМЯТРДЃЌдкЯТДЮredisжиаТЦєЖЏЪБЃЌжЛвЊАбетаЉаДжИСюДгЧАЕНКѓдйжиИДжДаавЛБщЃЌОЭПЩвдЪЕЯжЪ§ОнЛжИДСЫЁЃНЋаДУќСюЬэМгЕН
AOF ЮФМўЃЈappend only fileЃЉФЉЮВЁЃ
ЪЙгУ AOF ГжОУЛЏашвЊЩшжУЭЌВНбЁЯюЃЌДгЖјШЗБЃаДУќСюЭЌВНЕНДХХЬЮФМўЩЯЕФЪБЛњЁЃетЪЧвђЮЊЖдЮФМўНјаааДШыВЂВЛЛсТэЩЯНЋФкШнЭЌВНЕНДХХЬЩЯЃЌЖјЪЧЯШДцДЂЕНЛКГхЧјЃЌШЛКѓгЩВйзїЯЕЭГОіЖЈЪВУДЪБКђЭЌВНЕНДХХЬЁЃбЁЯюЭЌВНЦЕТЪalwaysУПИіаДУќСюЖМЭЌВНЃЌeyerysecУПУыЭЌВНвЛДЮЃЌnoШУВйзїЯЕЭГРДОіЖЈКЮЪБЭЌВНЃЌalways
бЁЯюЛсбЯжиМѕЕЭЗўЮёЦїЕФадФмЃЌeverysec бЁЯюБШНЯКЯЪЪЃЌПЩвдБЃжЄЯЕЭГБРРЃЪБжЛЛсЖЊЪЇвЛУызѓгвЕФЪ§ОнЃЌВЂЧв
Redis УПУыжДаавЛДЮЭЌВНЖдЗўЮёЦїМИКѕУЛгаШЮКЮгАЯьЁЃno бЁЯюВЂВЛФмИјЗўЮёЦїадФмДјРДЖрДѓЕФЬсЩ§ЃЌЖјЧвЛсдіМгЯЕЭГБРРЃЪБЪ§ОнЖЊЪЇЕФЪ§СПЁЃЫцзХЗўЮёЦїаДЧыЧѓЕФдіЖрЃЌAOF
ЮФМўЛсдНРДдНДѓЁЃRedis ЬсЙЉСЫвЛжжНЋ AOF жиаДЕФЬиадЃЌФмЙЛШЅГ§ AOF ЮФМўжаЕФШпграДУќСюЁЃ
ЦфЪЕRDBКЭAOFСНжжЗНЪНвВПЩвдЭЌЪБЪЙгУЃЌдкетжжЧщПіЯТЃЌШчЙћredisжиЦєЕФЛАЃЌдђЛсгХЯШВЩгУAOFЗНЪНРДНјааЪ§ОнЛжИДЃЌетЪЧвђЮЊAOFЗНЪНЕФЪ§ОнЛжИДЭъећЖШИќИпЁЃШчЙћФуУЛгаЪ§ОнГжОУЛЏЕФашЧѓЃЌвВЭъШЋПЩвдЙиБеRDBКЭAOFЗНЪНЃЌетбљЕФЛАЃЌredisНЋБфГЩвЛИіДПФкДцЪ§ОнПтЁЃ
2.ИДжЦ
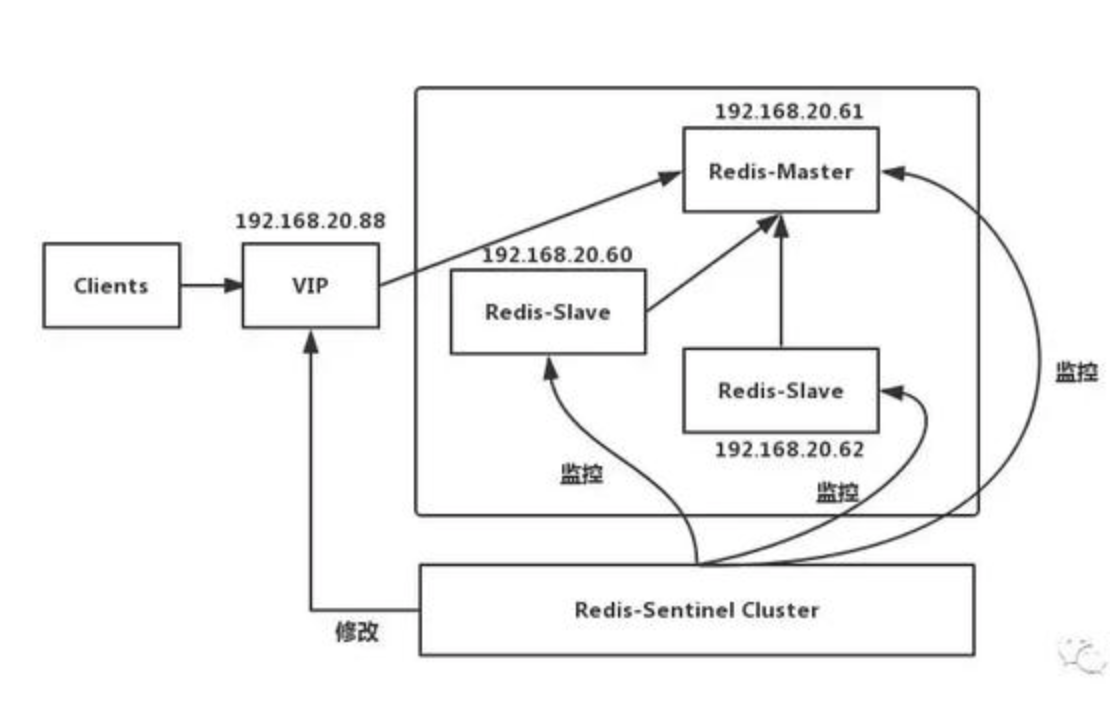
RedisЮЊСЫНтОіЕЅЕуЪ§ОнПтЮЪЬтЃЌЛсАбЪ§ОнИДжЦЖрИіИББОВПЪ№ЕНЦфЫћНкЕуЩЯЃЌЭЈЙ§ИДжЦЃЌЪЕЯжRedisЕФИпПЩгУадЃЌЪЕЯжЖдЪ§ОнЕФШпгрБИЗнЃЌБЃжЄЪ§ОнКЭЗўЮёЕФИпЖШПЩППадЁЃRedisгажїДгКЭжїБИСНжжЗНЪННтОіЕЅЕуЮЪЬтЃЌжїБИЃЈkeepalivedЃЉФЃЪНЯТжїЛњБИЛњЖдЭтЬсЙЉЭЌвЛИіащФтIPЃЌПЭЛЇЖЫЭЈЙ§ащФтIPНјааЪ§ОнВйзїЃЌе§ГЃЦкМфжїЛњвЛжБЖдЭтЬсЙЉЗўЮёЃЌхДЛњКѓVIPздЖЏЦЏвЦЕНБИЛњЩЯЁЃ
жїДгФЃЪНЯТЕБMasterхДЛњКѓЃЌЭЈЙ§бЁОйЫуЗЈ(PaxosЁЂRaft)ДгslaveжабЁОйГіаТMasterМЬајЖдЭтЬсЙЉЗўЮёЃЌжїЛњЛжИДКѓвдslaveЕФЩэЗнжиаТМгШыЃЌДЫФЃЪНЯТПЩвдЪЙгУЖСаДЗжРыЃЌШчЙћЪ§ОнСПБШНЯДѓЃЌВЛЯЃЭћЙ§ЖрРЫЗбЛњЦїЃЌЛЙЯЃЭћдкхДЛњКѓЃЌзівЛаЉздЖЈвхЕФДыЪЉЃЌБШШчБЈОЏЁЂМЧШежОЁЂЪ§ОнЧЈвЦЕШВйзїЃЌЭЦМіЪЙгУжїДгЗНЪНЃЌвђЮЊКЭжїДгДюХфЕФвЛАуЛЙгаИіЙмРэМрПижааФЃЈЩкБјЃЉЁЃ
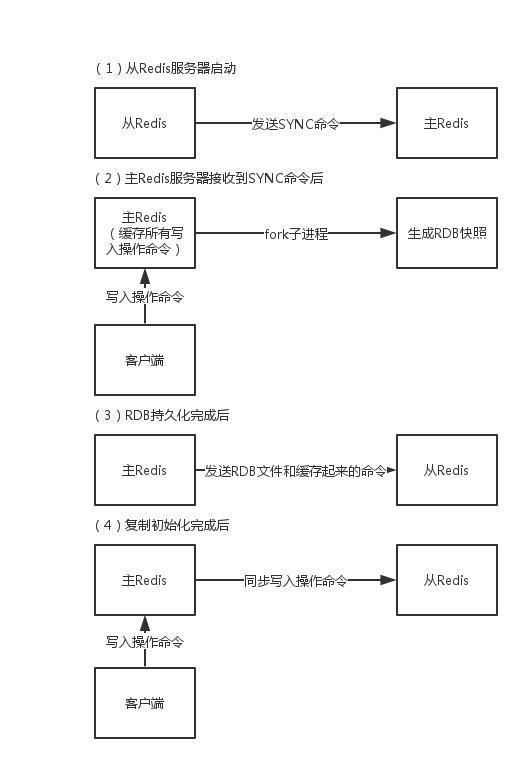
ЂйДгЪ§ОнПтЯђжїЪ§ОнПтЗЂЫЭsync(Ъ§ОнЭЌВН)УќСюЁЃ
ЂкжїЪ§ОнПтНгЪеЭЌВНУќСюКѓЃЌЛсБЃДцПьееЃЌДДНЈвЛИіRDBЮФМўЁЃ
ЂлЕБжїЪ§ОнПтжДааЭъБЃГжПьееКѓЃЌЛсЯђДгЪ§ОнПтЗЂЫЭRDBЮФМўЃЌЖјДгЪ§ОнПтЛсНгЪеВЂдиШыИУЮФМўЁЃ
ЂмжїЪ§ОнПтНЋЛКГхЧјЕФЫљгааДУќСюЗЂИјДгЗўЮёЦїжДааЁЃ
ЂнвдЩЯДІРэЭъжЎКѓЃЌжЎКѓжїЪ§ОнПтУПжДаавЛИіаДУќСюЃЌЖМЛсНЋБЛжДааЕФаДУќСюЗЂЫЭИјДгЪ§ОнПтЁЃПЩвдЭЌВНЗЂЫЭвВПЩвдвьВНЗЂЫЭЃЌЭЌВНЗЂЫЭПЩвдВЛгУУПЬЈЖМЭЌВНЃЌПЩвдХфжУвЛЬЈmasterЃЌвЛЬЈslaveЃЌЭЌЪБетЬЈsalveгжзїЮЊЦфЫћslaveЕФmasterЁЃвьВНЗНЪНЮоЗЈБЃжЄЪ§ОнЕФЭъећадЃЌБШШчдквьВНЭЌВНЙ§ГЬжажїЛњЭЛШЛхДЛњСЫЃЌвВГЦетжжЗНЪНЮЊЪ§ОнШѕвЛжТадЁЃ
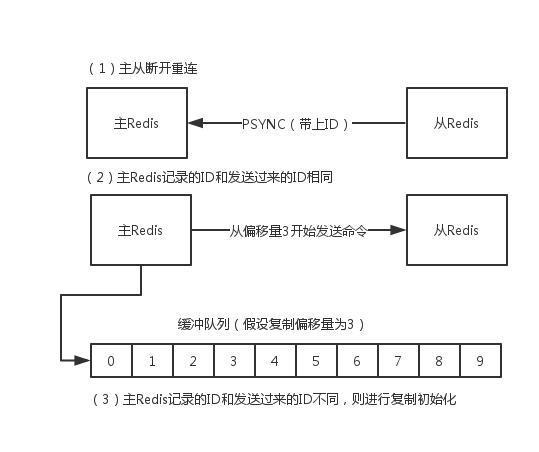
зЂвтЃКдкRedis2.8жЎКѓЃЌжїДгЖЯПЊжиСЌКѓЛсИљОнЖЯПЊжЎЧАзюаТЕФУќСюЦЋвЦСПНјаадіСПИДжЦЁЃ
3.ЩкБј
ЩкБјЪЧRedisМЏШКМмЙЙжаЗЧГЃживЊЕФвЛИізщМўЃЌЩкБјЕФГіЯжжївЊЪЧНтОіСЫжїДгИДжЦГіЯжЙЪеЯЪБашвЊШЫЮЊИЩдЄЕФЮЪЬтЁЃ
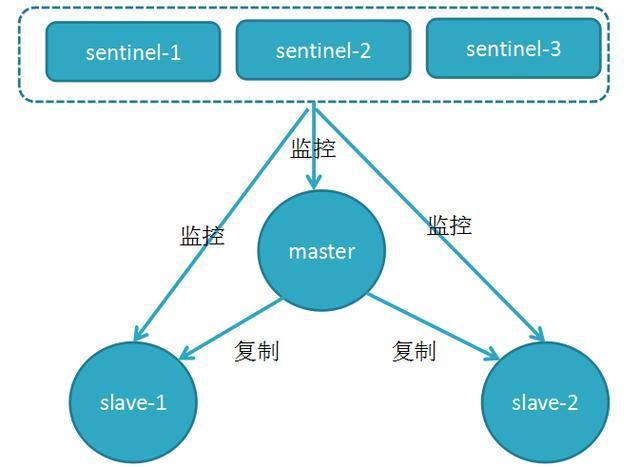
1.RedisЩкБјжївЊЙІФм
ЃЈ1ЃЉМЏШКМрПиЃКИКд№МрПиRedis masterКЭslaveНјГЬЪЧЗёе§ГЃЙЄзї
ЃЈ2ЃЉЯћЯЂЭЈжЊЃКШчЙћФГИіRedisЪЕР§гаЙЪеЯЃЌФЧУДЩкБјИКд№ЗЂЫЭЯћЯЂзїЮЊБЈОЏЭЈжЊИјЙмРэдБ
ЃЈ3ЃЉЙЪеЯзЊвЦЃКШчЙћmaster nodeЙвЕєСЫЃЌЛсздЖЏзЊвЦЕНslave
nodeЩЯ
ЃЈ4ЃЉХфжУжааФЃКШчЙћЙЪеЯзЊвЦЗЂЩњСЫЃЌЭЈжЊclientПЭЛЇЖЫаТЕФmasterЕижЗ
2.RedisЩкБјЕФИпПЩгУ
дРэЃКЕБжїНкЕуГіЯжЙЪеЯЪБЃЌгЩRedis SentinelздЖЏЭъГЩЙЪеЯЗЂЯжКЭзЊвЦЃЌВЂЭЈжЊгІгУЗНЃЌЪЕЯжИпПЩгУадЁЃЩкБјЛњжЦНЈСЂСЫЖрИіЩкБјНкЕу(НјГЬ)ЃЌЙВЭЌМрПиЪ§ОнНкЕуЕФдЫаазДПіЁЃЭЌЪБЩкБјНкЕужЎМфвВЛЅЯрЭЈаХЃЌНЛЛЛЖджїДгНкЕуЕФМрПизДПіЁЃУПИє1УыУПИіЩкБјЛсЯђећИіМЏШКЃКMasterжїЗўЮёЦї+SlaveДгЗўЮёЦї+ЦфЫћSentinelЃЈЩкБјЃЉНјГЬЃЌЗЂЫЭвЛДЮpingУќСюзівЛДЮаФЬјМьВтЁЃетИіОЭЪЧЩкБјгУРДХаЖЯНкЕуЪЧЗёе§ГЃЕФживЊвРОнЃЌЩцМАСНИіаТЕФИХФюЃКжїЙлЯТЯпКЭПЭЙлЯТЯпЁЃвЛИіЩкБјНкЕуХаЖЈжїНкЕуdownЕєЪЧжїЙлЯТЯпЃЌжЛгаАыЪ§ЩкБјНкЕуЖМжїЙлХаЖЈжїНкЕуdownЕєЃЌДЫЪБЖрИіЩкБјНкЕуНЛЛЛжїЙлХаЖЈНсЙћЃЌВХЛсХаЖЈжїНкЕуПЭЙлЯТЯпЁЃЛљБОЩЯФФИіЩкБјНкЕузюЯШХаЖЯГіетИіжїНкЕуПЭЙлЯТЯпЃЌОЭЛсдкИїИіЩкБјНкЕужаЗЂЦ№ЭЖЦБЛњжЦRaftЫуЗЈЃЈбЁОйЫуЗЈЃЉЃЌзюжеБЛЭЖЮЊСьЕМепЕФЩкБјНкЕуЭъГЩжїДгздЖЏЛЏЧаЛЛЕФЙ§ГЬЁЃ
4.МЏШК
жСЩйВПЪ№СНЬЈRedisЗўЮёЦїЙЙГЩвЛИіаЁЕФМЏШКЃЌжївЊга2ИіФПЕФЃК
ИпПЩгУадЃКдкжїЛњЙвЕєКѓЃЌздЖЏЙЪеЯзЊвЦЃЌЪЙЧАЖЫЗўЮёЖдгУЛЇЮогАЯьЁЃ
ЖСаДЗжРыЃКНЋжїЛњЖСбЙСІЗжСїЕНДгЛњЩЯЁЃ
ПЩдкПЭЛЇЖЫзщМўЩЯЪЕЯжИКдиОљКтЃЌИљОнВЛЭЌЗўЮёЦїЕФдЫааЧщПіЃЌЗжЕЃВЛЭЌБШР§ЕФЖСЧыЧѓбЙСІЁЃ
ЛКДцЪ§ОнСПВЛЖЯдіМгЪБЃЌЕЅЛњФкДцВЛЙЛЪЙгУЃЌашвЊАбЪ§ОнЧаЗжВЛЭЌВПЗжЃЌЗжВМЕНЖрЬЈЗўЮёЦїЩЯЁЃ
ПЩдкПЭЛЇЖЫЖдЪ§ОнНјааЗжЦЌЃЌЪ§ОнЗжЦЌЫуЗЈЯъМћвЛжТадHashЯъНтЁЂащФтЭАЗжЦЌЁЃ
ЕБЪ§ОнСПГжајдіМгЪБЃЌгІгУПЩИљОнВЛЭЌГЁОАЯТЕФвЕЮёЩъЧыЖдгІЕФЗжВМЪНМЏШКЁЃ
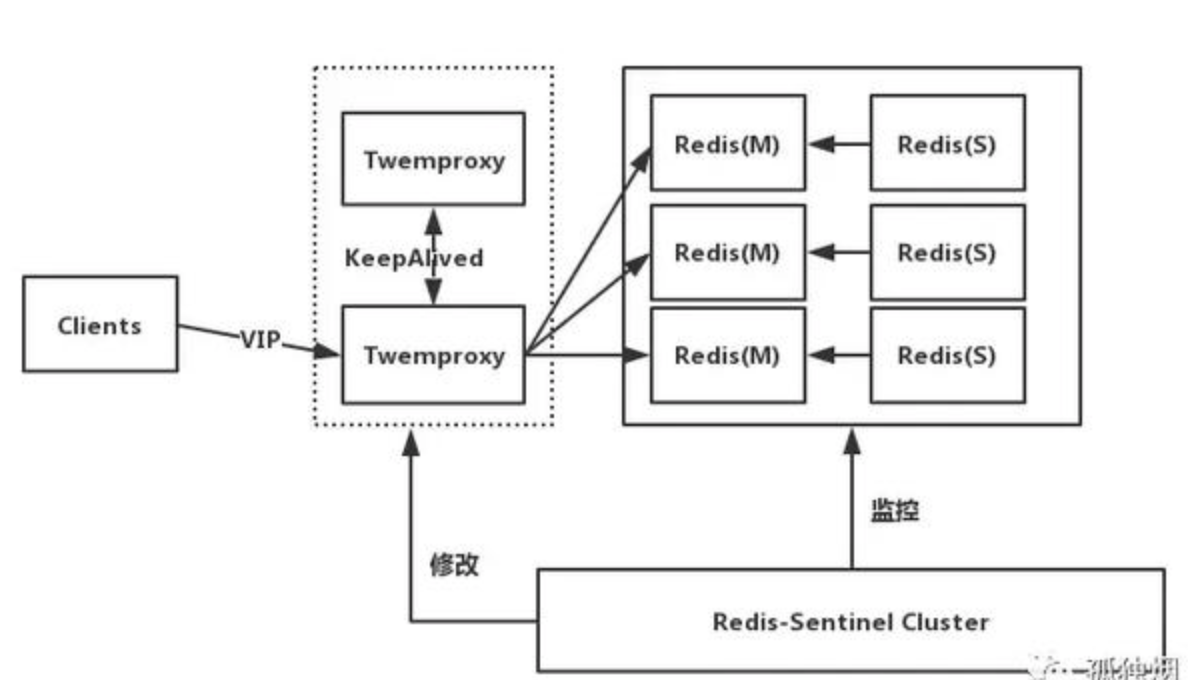
етПщзюЙиМќЕФЪЧЛКДцжЮРэетПщЃЌЦфжазюживЊЕФВПЗжЪЧМгШыСЫДњРэЗўЮёЃЈCodisКЭTwemproxyЃЉЁЃ гІгУЭЈЙ§ДњРэЗУЮЪецЪЕЕФRedisЗўЮёЦїНјааЖСаДЃЌетбљзіЕФКУДІЪЧБмУтдНРДдНЖрЕФПЭЛЇЖЫжБНгЗУЮЪRedisЗўЮёЦїФбвдЙмРэЃЌЖјдьГЩЗчЯеЃЌдкДњРэетвЛВуПЩвдзіЖдгІЕФАВШЋДыЪЉЃЌБШШчЯоСїЁЂЪкШЈЁЂЗжЦЌЃЌБмУтПЭЛЇЖЫдНРДдНЖрЕФТпМДњТыЃЌВЛЕЋгЗжзЩ§МЖЛЙБШНЯТщЗГЁЃДњРэетВуЮозДЬЌЕФЃЌПЩШЮвтРЉеЙНкЕуЃЌЖдгкПЭЛЇЖЫРДЫЕЃЌЗУЮЪДњРэИњЗУЮЪЕЅЛњRedisвЛбљЁЃ
Redis ClusterЪЧRedisЙйЭјИјГіЕФМЏШКМмЙЙ

ПЭЛЇЖЫгыRedisНкЕужБСЌ,ВЛашвЊжаМфProxyВуЃЌжБНгСЌНгШЮвтвЛИіMasterНкЕуЃЌИљОнЙЋЪНHASH_SLOT=CRC16(key)
mod 16384ЃЌМЦЫуГігГЩфЕНФФИіЗжЦЌЩЯЃЌШЛКѓRedisЛсШЅЯргІЕФНкЕуНјааВйзї
ОпгаШчЯТгХЕу:
(1)ЮоашSentinelЩкБјМрПиЃЌШчЙћMasterЙвСЫЃЌRedis
ClusterФкВПздЖЏНЋSlaveЧаЛЛMaster
(2)ПЩвдНјааЫЎЦНРЉШн
(3)жЇГжздЖЏЛЏЧЈвЦЃЌЕБГіЯжФГИіSlaveхДЛњСЫЃЌФЧУДОЭжЛгаMasterСЫЃЌетЪБКђЕФИпПЩгУадОЭЮоЗЈКмКУЕФБЃжЄСЫЃЌЭђвЛMasterвВхДЛњСЫЃЌеІАьФиЃП
еыЖдетжжЧщПіЃЌШчЙћЫЕЦфЫћMasterгаЖргрЕФSlave ЃЌМЏШКздЖЏАбЖргрЕФSlaveЧЈвЦЕНУЛгаSlaveЕФMaster
жаЁЃ
ШБЕу:
(1)ХњСПВйзїЪЧИіПгЃЌВЛЭЌЕФkeyЛсЛЎЗжЕНВЛЭЌЕФslotжаЃЌвђДЫжБНгЪЙгУmsetЛђепmgetЕШВйзїЪЧааВЛЭЈЕФЁЃШчЙћжДааЕФkeyЪ§СПБШНЯЩйЃЌОЭВЛгУmgetСЫЃЌОЭгУДЎааgetВйзїЁЃШчЙћецЕФашвЊжДааЕФkeyКмЖрЃЌОЭЪЙгУHashtagБЃжЄетаЉkeyгГЩфЕНЭЌвЛЬЈRedisНкЕуЩЯЁЃ
(2)зЪдДИєРыадНЯВюЃЌШнвзГіЯжЯрЛЅгАЯьЕФЧщПіЁЃ
Юх.RedisИпВЂЗЂМАШШkeyНтОіжЎЕР
1.ВЂЗЂЩшжУkeyМАЗжВМЪНЫј
RedisЪЧвЛжжЕЅЯпГЬЛњжЦЕФnosqlЪ§ОнПтЃЌЛљгкkey-valueЃЌЪ§ОнПЩГжОУЛЏТфХЬЁЃгЩгкЕЅЯпГЬЫљвдRedisБОЩэВЂУЛгаЫјЕФИХФюЃЌЖрИіПЭЛЇЖЫСЌНгВЂВЛДцдкОКељЙиЯЕЃЌЕЋЪЧРћгУjedisЕШПЭЛЇЖЫЖдRedisНјааВЂЗЂЗУЮЪЪБЛсГіЯжЮЪЬтЁЃБШШчЖрПЭЛЇЖЫЭЌЪБВЂЗЂаДвЛИіkeyЃЌвЛИіkeyЕФжЕЪЧ1ЃЌБОРДАДЫГађаоИФЮЊ2,3,4ЃЌзюКѓЪЧ4ЃЌЕЋЪЧЫГађБфГЩСЫ4,3,2ЃЌзюКѓБфГЩСЫ2ЁЃЪЙгУЗжВМЪНЫјЗРжЙВЂЗЂЩшжУKeyЕФдРэМАДњТыМћЃКЪЙгУRedisЪЕЯжЗжВМЪНЫјМАЦфгХЛЏЃЌСэЭтвЛжжЗНЪНЪЧЪЙгУЯћЯЂЖгСа,АбВЂааЖСаДНјааДЎааЛЏЁЃ
2.ШШkeyЮЪЬт
ШШkeyЮЪЬтЫЕРДвВКмМђЕЅЃЌОЭЪЧЫВМфгаМИЪЎЭђЕФЧыЧѓШЅЗУЮЪredisЩЯФГИіЙЬЖЈЕФkeyЃЌДгЖјбЙПхЛКДцЗўЮёЕФЧщЧщПіЁЃЦфЪЕЩњЛюжавВЪЧгаВЛЩйетбљЕФР§згЁЃБШШчXXУїаЧНсЛщЁЃФЧУДЙигкXXУїаЧЕФKeyОЭЛсЫВМфдіДѓЃЌОЭЛсГіЯжШШЪ§ОнЮЪЬтЁЃФЧУДШчКЮЗЂЯжШШKEYФиЃК
1.ЦОНшвЕЮёОбщЃЌНјаадЄЙРФФаЉЪЧШШkey
2.дкПЭЛЇЖЫНјааЪеМЏ
3.дкProxyВузіЪеМЏ
4.гУredisздДјУќСюЃЈmonitorУќСюЁЂhotkeysВЮЪ§ЃЉ
5.здМКзЅАќЦРЙР
НтОіЗНАИЃК
1.РћгУЖўМЖЛКДцЃЌБШШчРћгУehcacheЃЌЛђепвЛИіHashMapЖМПЩвдЁЃдкФуЗЂЯжШШkeyвдКѓЃЌАбШШkeyМгдиЕНЯЕЭГЕФJVMжаЁЃ
2.БИЗнШШkeyЃЌВЛвЊШУkeyзпЕНЭЌвЛЬЈredisЩЯЁЃЮвУЧАбетИіkeyЃЌдкЖрИіredisЩЯЖМДцвЛЗнЁЃПЩвдгУHOTKEYМгЩЯвЛИіЫцЛњЪ§ЃЈNЃЌМЏШКЗжЦЌЪ§ЃЉзщГЩвЛИіаТkeyЁЃ
3.ШШЕуЪ§ОнОЁСПВЛвЊЩшжУЙ§ЦкЪБМфЃЌдкЪ§ОнБфИќЪБЭЌВНаДЛКДцЃЌЗРжЙИпВЂЗЂЯТжиНЈЛКДцЕФзЪдДЫ№КФЁЃПЩвдгУsetnxзіЗжВМЪНЫјБЃжЄжЛгавЛИіЯпГЬдкжиНЈЛКДцЃЌЦфЫћЯпГЬЕШД§жиНЈЛКДцЕФЯпГЬжДааЭъЃЌжиаТДгЛКДцЛёШЁЪ§ОнМДПЩЁЃ
3.ЛКДцДЉЭИ
ЛКДцДЉЭИЪЧжИВщбЏвЛИіИљБОВЛДцдкЕФЪ§ОнЃЌЛКДцВуКЭДцДЂВуЖМВЛЛсУќжаЃЌЕЋЪЧГігкШнДэЕФПМТЧЃЌШчЙћДгДцДЂВуВщВЛЕНЪ§ОндђВЛаДШыЛКДцВуЁЃЛКДцДЉЭИНЋЕМжТВЛДцдкЕФЪ§ОнУПДЮЧыЧѓЖМвЊЕНДцДЂВуШЅВщбЏЃЌЪЇШЅСЫЛКДцБЃЛЄКѓЖЫДцДЂЕФвтвхЁЃдьГЩЛКДцДЉЭИЕФЛљБОгаСНИіЁЃЕквЛЃЌвЕЮёздЩэДњТыЛђепЪ§ОнГіЯжЮЪЬтЃЌЕкЖўЃЌвЛаЉЖёвтЙЅЛїЁЂХРГцЕШдьГЩДѓСППеУќжаЃЌЯТУцЮвУЧРДПДвЛЯТШчКЮНтОіЛКДцДЉЭИЮЪЬтЁЃНтОіЛКДцДЉЭИЕФСНжжЗНАИЃК
1ЃЉЛКДцПеЖдЯѓ
ЛКДцПеЖдЯѓЛсгаСНИіЮЪЬтЃК
ЕквЛЃЌПежЕзіСЫЛКДцЃЌвтЮЖзХЛКДцВужаДцСЫИќЖрЕФМќЃЌашвЊИќЖрЕФФкДцПеМф
( ШчЙћЪЧЙЅЛїЃЌЮЪЬтИќбЯжи )ЃЌБШНЯгааЇЕФЗНЗЈЪЧеыЖдетРрЪ§ОнЩшжУвЛИіНЯЖЬЕФЙ§ЦкЪБМфЃЌШУЦфздЖЏЬоГ§ЁЃ
ЕкЖўЃЌЛКДцВуКЭДцДЂВуЕФЪ§ОнЛсгавЛЖЮЪБМфДАПкЕФВЛвЛжТЃЌПЩФмЛсЖдвЕЮёгавЛЖЈгАЯьЁЃР§ШчЙ§ЦкЪБМфЩшжУЮЊ
5 ЗжжгЃЌШчЙћДЫЪБДцДЂВуЬэМгСЫетИіЪ§ОнЃЌФЧДЫЖЮЪБМфОЭЛсГіЯжЛКДцВуКЭДцДЂВуЪ§ОнЕФВЛвЛжТЃЌДЫЪБПЩвдРћгУЯћЯЂЯЕЭГЛђепЦфЫћЗНЪНЧхГ§ЕєЛКДцВужаЕФПеЖдЯѓЁЃ
2ЃЉВМТЁЙ§ТЫЦїРЙНи
ШчЯТЭМЫљЪОЃЌдкЗУЮЪЛКДцВуКЭДцДЂВужЎЧАЃЌНЋДцдкЕФ key гУВМТЁЙ§ТЫЦїЬсЧАБЃДцЦ№РДЃЌзіЕквЛВуРЙНиЁЃШчЙћВМТЁЙ§ТЫЦїШЯЮЊИУгУЛЇ
ID ВЛДцдкЃЌФЧУДОЭВЛЛсЗУЮЪДцДЂВуЃЌдквЛЖЈГЬЖШБЃЛЄСЫДцДЂВуЁЃгаЙиВМТЁЙ§ТЫЦїЕФЯрЙижЊЪЖЃЌПЩвдВЮПМЃК ВМТЁЙ§ТЫЦїЃЌПЩвдРћгУ
Redis ЕФ Bitmaps ЪЕЯжВМТЁЙ§ТЫЦїЃЌGitHub ЩЯвбОПЊдДСЫРрЫЦЕФЗНАИЃЌЖСепПЩвдНјааВЮПМЃКredis
bitmapsЪЕЯжВМТЁЙ§ТЫЦї
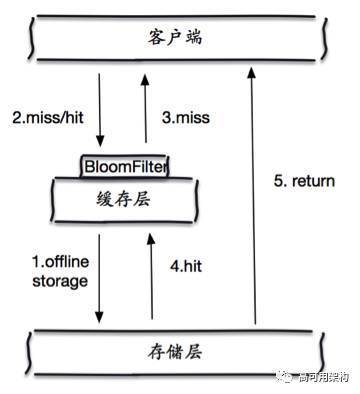
ЛКДцПеЖдЯѓКЭВМТЁЙ§ТЫЦїЗНАИЖдБШ
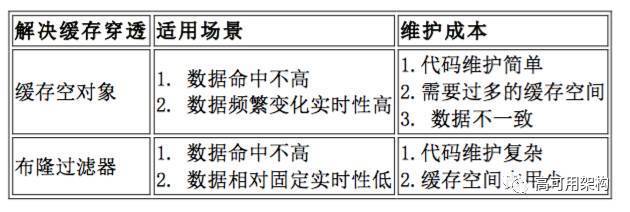
4.ЛКДцбЉБР
Ъ§ОнЮДМгдиЕНЛКДцжаЃЌЛђепЛКДцЭЌвЛЪБМфДѓУцЛ§ЕФЪЇаЇЃЌДгЖјЕМжТЫљгаЧыЧѓЖМШЅВщЪ§ОнПтЃЌЕМжТЪ§ОнПтCPUКЭФкДцИКдиЙ§ИпЃЌЩѕжСхДЛњЁЃ
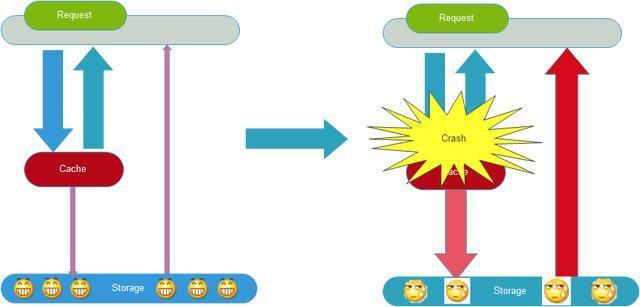
ПЩвдДгвдЯТМИИіЗНУцЗРжЙЛКДцбЉБРЃК
1ЃЉБЃжЄЛКДцВуЗўЮёИпПЩгУад
КЭЗЩЛњЖМгаЖрИів§ЧцвЛбљЃЌШчЙћЛКДцВуЩшМЦГЩИпПЩгУЕФЃЌМДЪЙИіБ№НкЕуЁЂИіБ№ЛњЦїЁЂЩѕжСЪЧЛњЗПхДЕєЃЌвРШЛПЩвдЬсЙЉЗўЮёЃЌР§ШчЧАУцНщЩмЙ§ЕФ
Redis Sentinel КЭ Redis Cluster ЖМЪЕЯжСЫИпПЩгУЁЃ
2ЃЉRedisБИЗнКЭПьЫйдЄШШ
RedisБИЗнБЃжЄmasterГіЮЪЬтЧаЛЛЮЊslaveбИЫйФмЙЛГаЕЃЯпЩЯЪЕМЪСїСПЃЌПьЫйдЄШШБЃжЄЛКДцМАЪББЛаДШыЛКДцЃЌЗРжЙДЉЭИЕНПтЁЃ
3ЃЉвРРЕИєРызщМўЮЊКѓЖЫЯоСїВЂНЕМЖ
ЮоТлЪЧЛКДцВуЛЙЪЧДцДЂВуЖМЛсгаГіДэЕФИХТЪЃЌПЩвдНЋЫќУЧЪгЭЌЮЊзЪдДЁЃзїЮЊВЂЗЂСПНЯДѓЕФЯЕЭГЃЌМйШчгавЛИізЪдДВЛПЩгУЃЌПЩФмЛсдьГЩЯпГЬШЋВП
hang дкетИізЪдДЩЯЃЌдьГЩећИіЯЕЭГВЛПЩгУЁЃНЕМЖдкИпВЂЗЂЯЕЭГжаЪЧЗЧГЃе§ГЃЕФЃКБШШчЭЦМіЗўЮёжаЃЌШчЙћИіадЛЏЭЦМіЗўЮёВЛПЩгУЃЌПЩвдНЕМЖВЙГфШШЕуЪ§ОнЃЌВЛжСгкдьГЩЧАЖЫвГУцЪЧПЊЬьДАЁЃ
дкЪЕМЪЯюФПжаЃЌЮвУЧашвЊЖдживЊЕФзЪдД ( Р§Шч RedisЁЂ MySQLЁЂ
HbaseЁЂЭтВПНгПк ) ЖМНјааИєРыЃЌШУУПжжзЪдДЖМЕЅЖРдЫаадкздМКЕФЯпГЬГижаЃЌМДЪЙИіБ№зЪдДГіЯжСЫЮЪЬтЃЌЖдЦфЫћЗўЮёУЛгагАЯьЁЃЕЋЪЧЯпГЬГиШчКЮЙмРэЃЌБШШчШчКЮЙиБезЪдДГиЃЌПЊЦєзЪдДГиЃЌзЪдДГиЗЇжЕЙмРэЃЌетаЉзіЦ№РДЛЙЪЧЯрЕБИДдгЕФЃЌетРяЭЦМівЛИі
Java вРРЕИєРыЙЄОпHystrix(https://github.com/Netflix/Hystrix)ЁЃ
4ЃЉЬсЧАбнСЗ
дкЯюФПЩЯЯпЧАЃЌбнСЗЛКДцВухДЕєКѓЃЌгІгУвдМАКѓЖЫЕФИКдиЧщПівдМАПЩФмГіЯжЕФЮЪЬтЃЌдкДЫЛљДЁЩЯзівЛаЉдЄАИЩшЖЈЁЃ
5.ЛКДцдЄШШ
ЛКДцдЄШШОЭЪЧЯЕЭГЩЯЯпЧАЃЌНЋЯрЙиЕФЛКДцЪ§ОнжБНгМгдиЕНЛКДцЯЕЭГЁЃетбљОЭПЩвдБмУтЩЯЯпКѓдкгУЛЇЧыЧѓЕФЪБКђЃЌЯШВщбЏЪ§ОнПтЃЌШЛКѓдйНЋЪ§ОнЛКДцЕФЮЪЬтЃЁгУЛЇжБНгВщбЏЪТЯШБЛдЄШШЕФЛКДцЪ§ОнЃЁ
| 







