| БрМЭЦМі: |
БОЮФНщЩмСЫkuduЪЧЪВУДЃЌЮЊЪВУДашвЊkudu?
ЛљДЁМмЙЙЃЌДцДЂЛњжЦЃЌkuduЕФЙЄзїЛњжЦМАKUDUЕФjavaВйзїАИР§ЁЃ
БОЮФРДзд csdnЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
Redis МЏШКЕФ TCP ЖЫПк(Redis Cluster TCP ports)
УПИі Redis МЏШКНкЕуашвЊСНИі TCP СЌНгДђПЊЁЃе§ГЃЕФ TCP
ЖЫПкгУРДЗўЮёПЭЛЇЖЫЃЌР§Шч 6379ЃЌМг 10000 ЕФЖЫПкгУзїЪ§ОнЖЫПкЃЌдкЩЯУцЕФР§згжаОЭЪЧ 16379ЁЃ
ЕкЖўИіДѓвЛаЉЕФЖЫПкгУгкМЏШКзмЯп(bus)ЃЌвВОЭЪЧЪЙгУЖўНјжЦавщЕФЕуЕНЕуЭЈаХЭЈЕРЁЃМЏШКзмЯпБЛНкЕугУ гкДэЮѓМьВтЃЌХфжУИќаТЃЌЙЪеЯзЊвЦЪкШЈЕШЕШЁЃПЭЛЇЖЫВЛгІИУГЂЪдСЌНгМЏШКзмЯпЖЫПкЃЌЖјгІвЛжБгые§ГЃЕФ
Redis УќСюЖЫПкЭЈаХЃЌЕЋЪЧвЊШЗБЃдкЗРЛ№ЧНжаДђПЊСЫетСНИіЖЫПкЃЌЗёдђ Redis МЏШКЕФНкЕуВЛФмЯрЛЅЭЈаХЁЃ
УќСюЖЫПкКЭМЏШКзмЯпЖЫПкЕФЦЋвЦСПвЛжБЙЬЖЈЮЊ 10000ЁЃ зЂвтЃЌЮЊСЫШУ Redis МЏШКЙЄзїе§ГЃЃЌЖдУПИіНкЕуЃК
1. гУгкгыПЭЛЇЖЫЭЈаХЕФе§ГЃЕФПЭЛЇЖЫЭЈаХЖЫПк(ЭЈГЃЮЊ 6379)ашвЊПЊЗХИјЫљгаашвЊСЌНгМЏШКЕФПЭЛЇЖЫ
вдМАЦфЫћМЏШКНкЕу(ЪЙгУПЭЛЇЖЫЖЫПкРДНјааМќЧЈвЦ)ЁЃ 2. МЏШКзмЯпЖЫПк(ПЭЛЇЖЫЖЫПкМг 10000)БиаыДгЫљгаЕФЦфЫћМЏШКНкЕуПЩДяЁЃ
ШчЙћФуВЛДђПЊетСНИі TCP ЖЫПкЃЌМЏШКОЭЮоЗЈе§ГЃЙЄзїЁЃ
Redis МЏШКЕФЪ§ОнЗжЦЌ(Redis Cluster data sharding)
Redis МЏШКУЛгаЪЙгУвЛжТадЙўЯЃЃЌЖјЪЧСэЭтвЛжжВЛЭЌЕФЗжЦЌаЮЪНЃЌУПИіМќИХФюЩЯЪЧБЛЮвУЧГЦЮЊЙўЯЃВл (hash
slot)ЕФЖЋЮїЕФвЛВПЗжЁЃ Redis МЏШКга 16384 ИіЙўЯЃВлЃЌЮвУЧжЛЪЧЪЙгУМќЕФ CRC16
БрТыЖд 16384 ШЁФЃРДМЦЫувЛИіжИЖЈМќЫљЪєЕФ ЙўЯЃВлЁЃ УПвЛИі Redis МЏШКжаЕФНкЕуЖМГаЕЃвЛИіЙўЯЃВлЕФзгМЏЃЌР§ШчЃЌФуПЩФмгавЛИі
3 ИіНкЕуЕФМЏШКЃЌЦфжаЃК

НкЕу A АќКЌДг 0 ЕН 5500 ЕФЙўЯЃВлЁЃ
НкЕу B АќКЌДг 5501 ЕН 11000 ЕФЙўЯЃВлЁЃ
НкЕу C АќКЌДг 11001 ЕН 16384 ЕФЙўЯЃВлЁЃ
етПЩвдШУдкМЏШКжаЬэМгКЭвЦГ§НкЕуЗЧГЃШнвзЁЃР§ШчЃЌШчЙћЮвЯыЬэМгвЛИіаТНкЕу DЃЌЮвашвЊДгНкЕу AЃЌBЃЌ
C вЦЖЏвЛаЉЙўЯЃВлЕННкЕу DЁЃЭЌбљЕиЃЌШчЙћЮвЯыДгМЏШКжавЦГ§НкЕу AЃЌЮвжЛашвЊвЦЖЏ A ЕФЙўЯЃВлЕН B
КЭ CЁЃ ЕБНкЕу A БфГЩПеЕФвдКѓЃЌЮвОЭПЩвдДгМЏШКжаГЙЕзЩОГ§ЫќЁЃ вђЮЊДгвЛИіНкЕуЯђСэвЛИіНкЕувЦЖЏЙўЯЃВлВЂВЛашвЊЭЃжЙВйзїЃЌЫљвдЬэМгКЭвЦГ§НкЕуЃЌЛђепИФБфНкЕуГжга
ЕФЙўЯЃВлАйЗжБШЃЌЖМВЛашвЊШЮКЮЭЃЛњЪБМф(downtime)ЁЃ
Redis cluster МмЙЙ(Redis Cluster Architecture)
redis-cluster МмЙЙЭМ
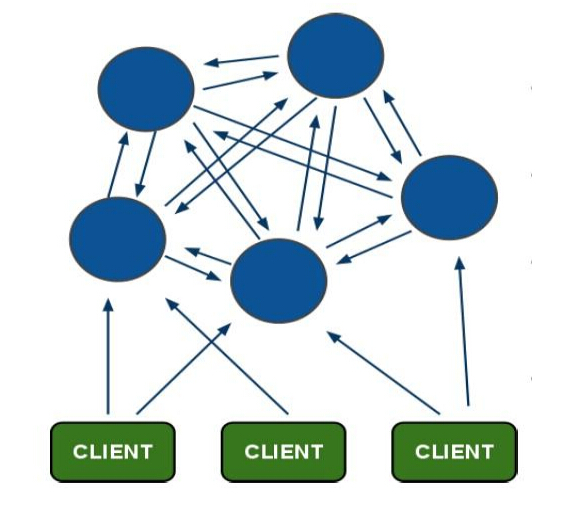
МмЙЙЯИНк:
ЫљгаЕФ redis НкЕуБЫДЫЛЅСЊ(PING-PONG ЛњжЦ),ФкВПЪЙгУЖўНјжЦавщгХЛЏДЋЪфЫйЖШКЭДјПэ.
НкЕуЕФ fail ЪЧЭЈЙ§МЏШКжаГЌЙ§АыЪ§ЕФНкЕуМьВтЪЇаЇЪБВХЩњаЇ.
ПЭЛЇЖЫгы redis НкЕужБСЌ,ВЛашвЊжаМф proxy Ву.ПЭЛЇЖЫВЛашвЊСЌНгМЏШКЫљгаНкЕу,СЌНгМЏШКжаШЮКЮвЛИі
ПЩгУНкЕуМДПЩ
redis-cluster АбЫљгаЕФЮяРэНкЕугГЩфЕН[0-16383]slot ЩЯ,cluster
ИКд№ЮЌЛЄ node<->slot<->value
redis-cluster бЁОй:ШнДэ
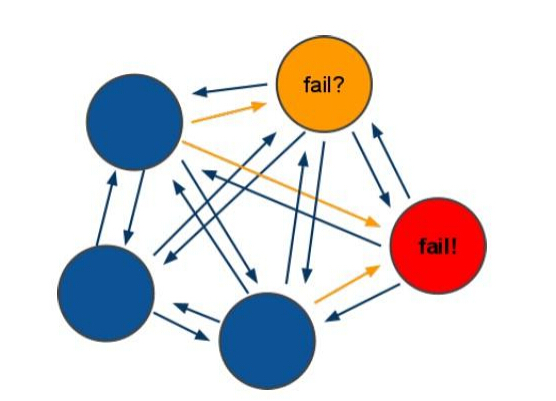
СьафбЁОйЙ§ГЬЪЧМЏШКжаЫљга master ВЮгы,ШчЙћАыЪ§вдЩЯ master
НкЕугы master НкЕуЭЈаХГЌЙ§ (cluster-node-timeout),ШЯЮЊЕБЧА master
НкЕуЙвЕє.
ЪВУДЪБКђећИіМЏШКВЛПЩгУ(cluster_state:fail)
a:ШчЙћМЏШКШЮвт master ЙвЕє,ЧвЕБЧА master УЛга slave.МЏШКНјШы fail
зДЬЌ,вВПЩвдРэНтГЩМЏШКЕФ slot гГ Щф[0-16383]ВЛЭъГЩЪБНјШы fail зДЬЌ. ps :
redis-3.0.0.rc1 МгШы cluster-require-full-coverage ВЮЪ§,ФЌШЯЙиБе,
ДђПЊМЏШКМцШнВПЗжЪЇАм.
b:ШчЙћМЏШКГЌЙ§АыЪ§вдЩЯ master ЙвЕєЃЌЮоТлЪЧЗёга slave МЏШКНјШы fail зДЬЌ.
ps:ЕБМЏШКВЛПЩгУЪБ,ЫљгаЖдМЏШКЕФВйзїзіЖМВЛПЩгУЃЌЪеЕН((error) CLUSTERDOWN The
cluster is down) ДэЮѓ
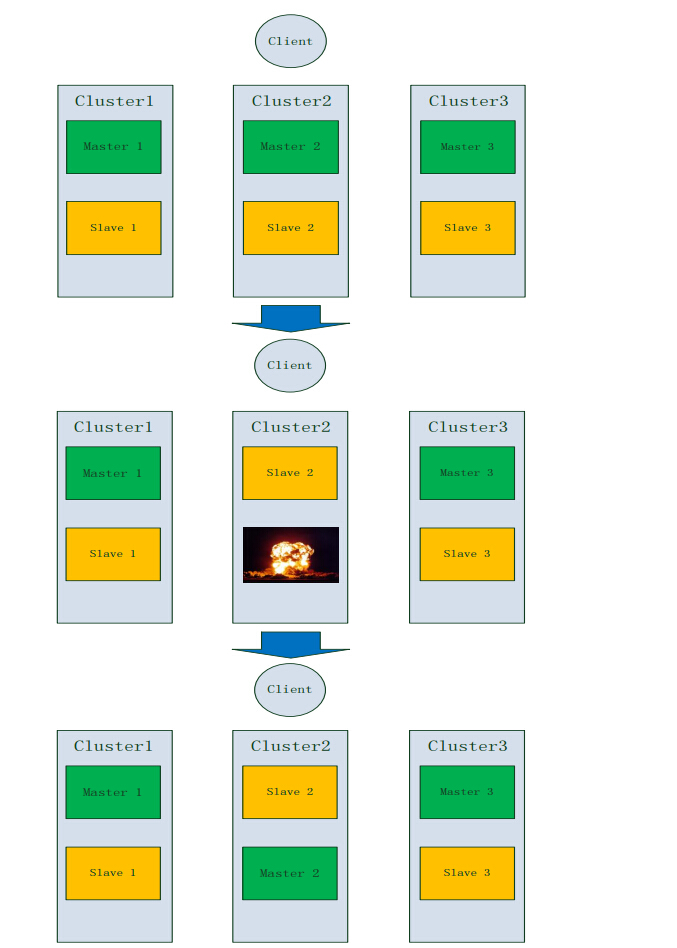
Redis МЏШКЕФжїДгФЃаЭ(Redis Cluster master-slave model)
ЮЊСЫЕБВПЗжНкЕуЪЇаЇЪБЃЌЛђепЮоЗЈгыДѓЖрЪ§НкЕуЭЈаХЪБШдФмБЃГжПЩгУЃЌRedis МЏШКВЩгУУПИіНкЕугЕга 1(жї
ЗўЮёздЩэ)ЕН N ИіИББО(N-1 ИіИНМгЕФДгЗўЮёЦї)ЕФжїДгФЃаЭЁЃ дкЮвУЧЕФР§згжаЃЌМЏШКгЕга AЃЌBЃЌC
Ш§ИіНкЕуЃЌШчЙћНкЕу B ЪЇаЇМЏШКНЋВЛФмМЬајЗўЮёЃЌвђЮЊЮвУЧВЛдй гаАьЗЈРДЗўЮёдк 5501-11000
ЗЖЮЇФкЕФЙўЯЃВлЁЃ ЕЋЪЧЃЌШчЙћЕБЮвУЧДДНЈМЏШККѓ(ЛђепЩдКѓ)ЃЌЮвУЧЮЊУПвЛИіжїЗўЮёЦїЬэМгвЛИіДгЗўЮёЦїЃЌетбљзюжеЕФМЏШК
ОЭгЩжїЗўЮёЦї AЃЌBЃЌC КЭДгЗўЮёЦї A1ЃЌB1ЃЌC1 зщГЩЃЌШчЙћ B НкЕуЪЇаЇЯЕЭГШдФмМЬајЗўЮёЁЃ
B1 НкЕуИДжЦ B НкЕуЃЌгкЪЧМЏШКЛсбЁОй B1 НкЕузїЮЊаТЕФжїЗўЮёЦїЃЌВЂМЬаје§ШЗЕФдЫзЊЁЃ
Redis МЏШКЕФвЛжТадБЃжЄ(Redis Cluster consistency guarantees)
Redis МЏШКВЛБЃжЄЧПвЛжТадЁЃЪЕМљжаЃЌетвтЮЖзХдкЬиЖЈЕФЬѕМўЯТЃЌRedis МЏШКПЩФмЛсЖЊЕєвЛаЉБЛЯЕЭГЪе
ЕНЕФаДШыЧыЧѓУќСюЁЃ
Redis МЏШКЮЊЪВУДЛсЖЊЪЇаДЧыЧѓЕФЕквЛИідвђЃЌЪЧвђЮЊВЩгУСЫвьВНИДжЦЁЃетвтЮЖзХдкаДЦкМфЯТУцЕФЪТЧщ
ЗЂЩњСЫЃК
ФуЕФПЭЛЇЖЫЯђжїЗўЮёЦї B аДШыЁЃ
жїЗўЮёЦї B ЛиИД OK ИјФуЕФПЭЛЇЖЫЁЃ
жїЗўЮёЦї B ДЋВЅаДШыВйзїЕНЦфДгЗўЮёЦї B1ЃЌB2 КЭ B3ЁЃ
ЪжЖЏЙЪеЯзЊвЦ(Manual failover)
гаЪБКђдкжїЗўЮёЦїЪТЪЕЩЯУЛгаШЮКЮЙЪеЯЕФЧщПіЯТЧПжЦвЛДЮЙЪеЯзЊвЦЪЧКмгагУЕФЁЃР§ШчЃЌЮЊСЫЩ§МЖжїЗўЮё ЦїНкЕужаЕФвЛИіНјГЬЃЌПЩвдЖдЦфНјааЙЪеЯзЊвЦЪЙЦфБфЮЊвЛИіДгЗўЮёЦїЃЌетбљзюаЁЛЏСЫЖдПЩгУадЕФгАЯьЁЃ
Redis МЏШКжЇГжЪЙгУ CLUSTER FAILOVER УќСюРДЪжЖЏЙЪеЯзЊвЦЃЌБиаыдкФуЯыНјааЙЪеЯзЊвЦЕФжїЗўЮёЕФ
ЦфжавЛИіДгЗўЮёЦїЩЯжДааЁЃ
ЪжЖЏЙЪеЯзЊвЦКмЬиБ№ЃЌКЭеце§вђЮЊжїЗўЮёЦїЪЇаЇЖјВњЩњЕФЙЪеЯзЊвЦвЊИќАВШЋЃЌвђЮЊВЩШЁСЫБмУтЙ§ГЬжаЪ§ ОнЖЊЪЇЕФЗНЪНЃЌНіЕБЯЕЭГШЗШЯаТЕФжїЗўЮёЦїДІРэЭъСЫОЩЕФжїЗўЮёЦїЕФИДжЦСїЪБЃЌПЭЛЇЖЫВХДгджїЗўЮёЦїЧа
ЛЛЕНаТжїЗўЮёЦїЁЃ
ДДНЈredisМЏШК(create a new cluser)
redis-trib create --replicas 1 127.0.0.1:6379 127.0.0.1:7379
127.0.0.2:6379 127.0.0.2:7379 127.0.0.3:6379 127.0.0.3:7379
127.0.0.4:6379 127.0.0.4:7379 127.0.0.5:6379 127.0.0.5:7379
ВщПДredisМЏШКзДЬЌ(check cluser status)
redis-trib check 127.0.0.1:7379
ВщПДnodeзДЬЌ(check node status)
# redis-cli -c -p 6379
# INFO
ЬэМгаТНкЕу(Adding a new node)
ЬэМгвЛИіаТНкЕуЕФЙ§ГЬЛљБОЩЯОЭЪЧЃЌЬэМгвЛИіПеНкЕуЃЌШЛКѓЃЌШчЙћЪЧзїЮЊжїНкЕудђвЦЖЏвЛаЉЪ§ОнНјШЅЃЌ ШчЙћЪЧДгНкЕудђЦфзїЮЊФГИіНкЕуЕФИББОЁЃ
СНжжЧщПіЮвУЧЖМЛсЬжТлЃЌЯШДгЬэМгвЛИіаТЕФжїЗўЮёЦїЪЕР§ПЊЪМЁЃ
СНжжЧщПіЯТЃЌЕквЛВНвЊЭъГЩЕФЖМЪЧЬэМгвЛИіПеНкЕуЁЃ
ЮвУЧЪЙгУгыЦфЫћНкЕуЯрЭЌЕФХфжУ(ЖЫПкКХГ§Эт)дк 7006 ЖЫПк(ЮвУЧвбДцдкЕФ 6 ИіНкЕувбОЪЙгУСЫДг
7000 ЕН 7005 ЕФЖЫПк)ЩЯПЊЦєвЛИіаТЕФНкЕуЃЌФЧУДЮЊСЫгыЮвУЧжЎЧАЕФНкЕуВМОжвЛжТЃЌФуЕУетУДзіЃК
дкФуЕФжеЖЫГЬађжаПЊЦєвЛИіаТЕФБъЧЉДАПкЁЃ
НјШы cluster-test ФПТМЁЃ
ДДНЈвЛИіУћЮЊ 7006 ЕФФПТМЁЃ
дкРяУцДДНЈвЛИі redis.conf ЕФЮФМўЃЌРрЫЦгкЦфЫќНкЕуЪЙгУЕФЮФМўЃЌЕЋЪЧЪЙгУ
7006 зїЮЊЖЫПкКХЁЃ
зюКѓЪЙгУ../redis-server ./redis.conf ЦєЖЏЗўЮёЦїЁЃ
| ./redis-trib.rb
add-node 127.0.0.1:7006 127.0.0.1:7000
|
ЬэМгИББОНкЕу(Adding a new node as a replica)
ЬэМгвЛИіаТИББОПЩвдгаСНжжЗНЪНЁЃЯдЖјвзМћЕФвЛжжЗНЪНЪЧдйДЮЪЙгУ redis-tribЃЌЕЋЪЧвЊЪЙгУЁЊslave
бЁЯюЃЌ ЯёетбљЃК
| ./redis-trib.rb
add-node --slave 127.0.0.1:7006 127.0.0.1:7000
|
зЂвтЃЌетРяЕФУќСюааЭъШЋЯёЮвУЧдкЬэМгвЛИіаТжїЗўЮёЦїЪБЪЙгУЕФвЛбљЃЌЫљвдЮвУЧУЛгажИЖЈвЊИјФФИіжїЗў ЮёЦїЬэМгИББОЁЃетжжЧщПіЯТЃЌredis-trib
ЛсЬэМгвЛИіаТНкЕузїЮЊвЛИіОпгаНЯЩйИББОЕФЫцЛњЕФжїЗўЮёЦїЕФИББОЁЃ
ЕЋЪЧЃЌФуПЩвдЪЙгУЯТУцЕФУќСюааОЋШЗЕижИЖЈФуЯывЊЕФжїЗўЮёЦїзїЮЊИББОЕФФПБъЃК
./redis-trib.rb
add-node --slave --master-id 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e
127.
0.0.1:7006 127.0.0.1:7000 |
вЦГ§НкЕу(Removing a node)
вЊвЦГ§вЛИіДгЗўЮёЦїНкЕуЃЌжЛвЊЪЙгУ redis-trib ЕФ del-node
УќСюОЭПЩвдЃК
| ./redis-trib
del-node 127.0.0.1:7000 <node-id> |
Щ§МЖНкЕу(Upgrading nodes in a Redis Cluster)
Щ§МЖДгЗўЮёЦїНкЕуКмМђЕЅЃЌвђЮЊФужЛашвЊЭЃжЙНкЕуШЛКѓгУвбИќаТЕФ Redis АцБОжиЦєЁЃШчЙћгаПЭЛЇЖЫЪЙгУ
ДгЗўЮёЦїНкЕуЗжРыЖСЧыЧѓЃЌЫќУЧгІИУФмЙЛдкФГИіНкЕуВЛПЩгУЪБжиаТСЌНгСэвЛИіДгЗўЮёЦїЁЃ
Щ§МЖжїЗўЮёЦївЊЩдЮЂИДдгвЛаЉЃЌНЈвщЕФВНжшЪЧЃК
1. ЪЙгУ CLUSTER FAILOVER РДДЅЗЂвЛДЮЪжЙЄЙЪеЯзЊвЦжїЗўЮёЦї(ЧыПДБОЮФЕЕЕФЪжЙЄЙЪеЯзЊвЦаЁ
Нк)ЁЃ
2. ЕШД§жїЗўЮёЦїБфЮЊДгЗўЮёЦїЁЃ
3. ЯёЩ§МЖДгЗўЮёЦїФЧбљЩ§МЖетИіНкЕуЁЃ
4. ШчЙћФуЯыШУФуИеИеЩ§МЖЕФНкЕуГЩЮЊжїЗўЮёЦїЃЌДЅЗЂвЛДЮаТЕФЪжЙЄЙЪеЯзЊвЦЃЌШУЩ§МЖЕФНкЕужиаТБф ЛижїЗўЮёЦїЁЃ
| 







