| БрМЭЦМі: |
БОЮФжївЊНщЩмRedis
Ъ§ОнРраЭЃЌЭЈЙ§ЪЕР§бнЪОСЫЗЂВМЖЉдФЪЧШчКЮЙЄзїЕФ,ВЂЖдRedis ЪТЮёУќСюЃЌГжОУЛЏЁЂЩкБјЁЂЗжЦЌНјааСЫВћЪіЃЌЯЃЭћЖдФњгаЫљАяжњЁЃ
БОЮФРДздНёШеЭЗЬѕЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
Redis МђНщ
Redis ЪЧЭъШЋПЊдДУтЗбЕФЃЌзёЪи BSD авщЃЌЪЧвЛИіИпадФмЕФ key - value Ъ§ОнПт
Redis гы ЦфЫћ key - value ЛКДцВњЦЗгавдЯТШ§ИіЬиЕуЃК
Redis жЇГжЪ§ОнГжОУЛЏЃЌПЩвдНЋФкДцжаЕФЪ§ОнБЃДцдкДХХЬжаЃЌжиЦєЕФЪБКђПЩвддйДЮМгдиНјааЪЙгУЁЃ
Redis ВЛНіНіжЇГжМђЕЅЕФ key - value РраЭЕФЪ§ОнЃЌЭЌЪБЛЙЬсЙЉ listЃЌsetЃЌzsetЃЌhash
ЕШЪ§ОнНсЙЙЕФДцДЂ
Redis жЇГжЪ§ОнЕФБИЗнЃЌМД master - slave ФЃЪНЕФЪ§ОнБИЗн
Redis гХЪЦ
адФмМЋИп ЈC Redis ЖСЕФЫйЖШЪЧ 110000 ДЮ /s, аДЕФЫйЖШЪЧ 81000 ДЮ /s ЁЃ
ЗсИЛЕФЪ§ОнРраЭ - Redis жЇГжЖўНјжЦАИР§ЕФ Strings, Lists, Hashes, Sets
МА Ordered Sets Ъ§ОнРраЭВйзїЁЃ
дзгад - Redis ЕФЫљгаВйзїЖМЪЧдзгадЕФЃЌвтЫМОЭЪЧвЊУДГЩЙІжДаавЊУДЪЇАмЭъШЋВЛжДааЁЃЕЅИіВйзїЪЧдзгадЕФЁЃЖрИіВйзївВжЇГжЪТЮёЃЌМДдзгадЃЌЭЈЙ§
MULTI КЭ EXEC жИСюАќЦ№РДЁЃ
ЦфЫћЬиад - Redis ЛЙжЇГж publish/subscribe ЭЈжЊЃЌkey Й§ЦкЕШЬиадЁЃ
Redis Ъ§ОнРраЭ
Redis жЇГж 5 жаЪ§ОнРраЭЃКstringЃЈзжЗћДЎЃЉЃЌhashЃЈЙўЯЃЃЉЃЌlistЃЈСаБэЃЉЃЌsetЃЈМЏКЯЃЉЃЌzsetЃЈsorted
setЃКгаађМЏКЯЃЉЁЃ
string
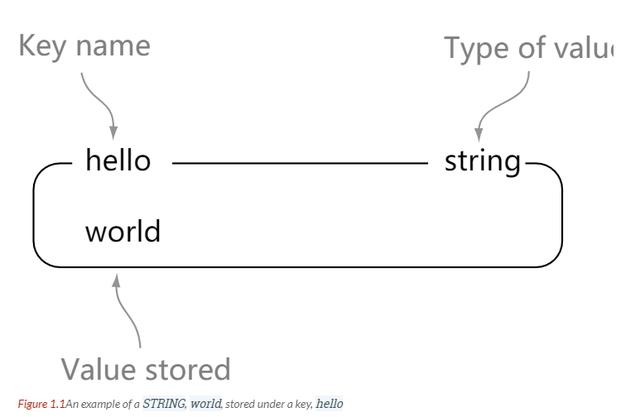
string ЪЧ redis зюЛљБОЕФЪ§ОнРраЭЁЃвЛИі key ЖдгІвЛИі valueЁЃ
string ЪЧЖўНјжЦАВШЋЕФЁЃвВОЭЪЧЫЕ redis ЕФ string ПЩвдАќКЌШЮКЮЪ§ОнЁЃБШШч jpg
ЭМЦЌЛђепађСаЛЏЕФЖдЯѓЁЃ
string РраЭЪЧ redis зюЛљБОЕФЪ§ОнРраЭЃЌstring РраЭЕФжЕзюДѓФмДцДЂ 512 MBЁЃ
РэНтЃКstring ОЭЯёЪЧ java жаЕФ map вЛбљЃЌвЛИі key ЖдгІвЛИі value
127.0.0.1:6379>
set hello world
OK
127.0.0.1:6379> get hello
"world" |
hash
Redis hash ЪЧвЛИіМќжЕЖдЃЈkey - valueЃЉМЏКЯЁЃ
Redis hash ЪЧвЛИі string РраЭЕФ key КЭ value ЕФгГЩфБэЃЌhash ЬиБ№ЪЪКЯгУгкДцДЂЖдЯѓЁЃ
РэНтЃКПЩвдНЋ hash ПДГЩвЛИі key - value ЕФМЏКЯЁЃвВПЩвдНЋЦфЯыГЩвЛИі hash ЖдгІзХЖрИі
stringЁЃ
гы string ЧјБ№ЃКstring ЪЧ вЛИі key - value МќжЕЖдЃЌЖј hash ЪЧЖрИі
key - value МќжЕЖдЁЃ
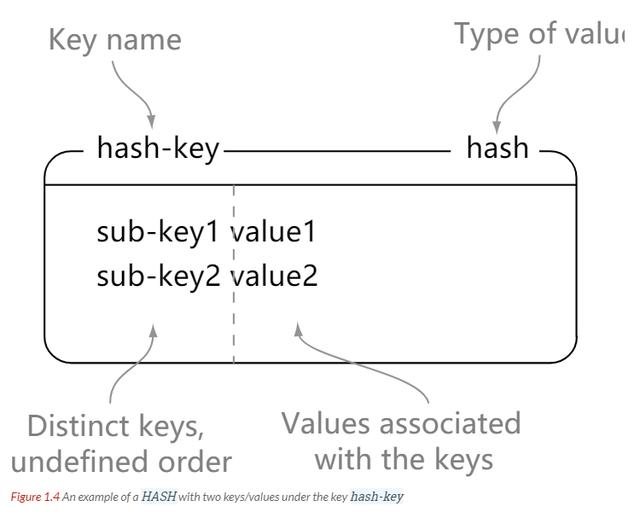
// hash-key ПЩвдПДГЩЪЧвЛИіМќжЕЖдМЏКЯЕФУћзж,дкетРяЗжБ№ЮЊЦфЬэМгСЫ
sub-key1 : value1ЁЂ
sub-key2 : value2ЁЂsub-key3 : value3 етШ§ИіМќжЕЖд
127.0.0.1:6379> hset hash-key sub-key1 value1
(integer) 1
127.0.0.1:6379> hset hash-key sub-key2 value2
(integer) 1
127.0.0.1:6379> hset hash-key sub-key3 value3
(integer) 1
// ЛёШЁ hash-key етИі hash РяУцЕФЫљгаМќжЕЖд
127.0.0.1:6379> hgetall hash-key
1) "sub-key1"
2) "value1"
3) "sub-key2"
4) "value2"
5) "sub-key3"
6) "value3"
// ЩОГ§ hash-key етИі hash РяУцЕФ sub-key2 МќжЕЖд
127.0.0.1:6379> hdel hash-key sub-key2
(integer) 1
127.0.0.1:6379> hget hash-key sub-key2
(nil)
127.0.0.1:6379> hget hash-key sub-key1
"value1"
127.0.0.1:6379> hgetall hash-key
1) "sub-key1"
2) "value1"
3) "sub-key3"
4) "value3" |
list
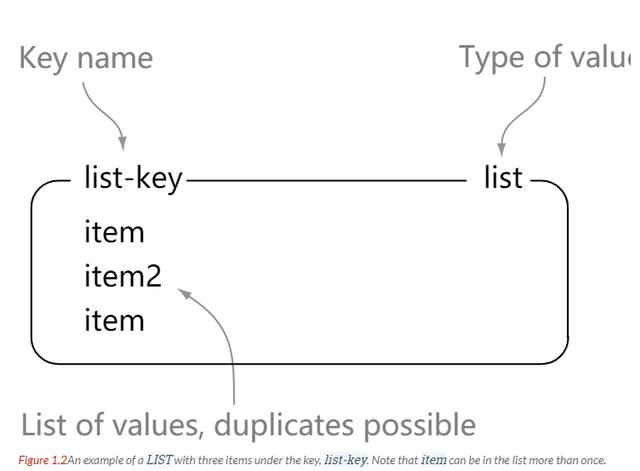
Redis СаБэЪЧМђЕЅЕФзжЗћДЎСаБэЃЌАДееВхШыЫГађХХађЁЃЮвУЧПЩвдЭјСаБэЕФзѓБпЛђепгвБпЬэМгдЊЫиЁЃ
127.0.0.1:6379>
rpush list-key v1
(integer) 1
127.0.0.1:6379> rpush list-key v2
(integer) 2
127.0.0.1:6379> rpush list-key v1
(integer) 3
127.0.0.1:6379> lrange list-key 0 -1
1) "v1"
2) "v2"
3) "v1"
127.0.0.1:6379> lindex list-key 1
"v2"
127.0.0.1:6379> lpop list
(nil)
127.0.0.1:6379> lpop list-key
"v1"
127.0.0.1:6379> lrange list-key 0 -1
1) "v2"
2) "v1" |
ЮвУЧПЩвдПДГі list ОЭЪЧвЛИіМђЕЅЕФзжЗћДЎМЏКЯЃЌКЭ Java жаЕФ list ЯрВюВЛДѓЃЌЧјБ№ОЭЪЧетРяЕФ
list ДцЗХЕФЪЧзжЗћДЎЁЃlist ФкЕФдЊЫиЪЧПЩжиИДЕФЁЃ
set
redis ЕФ set ЪЧзжЗћДЎРраЭЕФЮоађМЏКЯЁЃМЏКЯЪЧЭЈЙ§ЙўЯЃБэЪЕЯжЕФЃЌвђДЫЬэМгЁЂЩОГ§ЁЂВщевЕФИДдгЖШЖМЪЧ
OЃЈ1ЃЉЁЃ

127.0.0.1:6379>
sadd k1 v1
(integer) 1
127.0.0.1:6379> sadd k1 v2
(integer) 1
127.0.0.1:6379> sadd k1 v3
(integer) 1
127.0.0.1:6379> sadd k1 v1
(integer) 0
127.0.0.1:6379> smembers k1
1) "v3"
2) "v2"
3) "v1"
127.0.0.1:6379>
127.0.0.1:6379> sismember k1 k4
(integer) 0
127.0.0.1:6379> sismember k1 v1
(integer) 1
127.0.0.1:6379> srem k1 v2
(integer) 1
127.0.0.1:6379> srem k1 v2
(integer) 0
127.0.0.1:6379> smembers k1
1) "v3"
2) "v1" |
redis ЕФ set гы java жаЕФ set ЛЙЪЧгаЕуЧјБ№ЕФЁЃredis ЕФ set ЪЧвЛИі
key ЖдгІзХ ЖрИізжЗћДЎРраЭЕФ valueЃЌвВЪЧвЛИізжЗћДЎРраЭЕФМЏКЯЃЌЕЋЪЧКЭ redis ЕФ list
ВЛЭЌЕФЪЧ set жаЕФзжЗћДЎМЏКЯдЊЫиВЛФмжиИДЃЌЕЋЪЧ list ПЩвдЁЃ
Zset
redis zset КЭ set вЛбљЖМЪЧ зжЗћДЎРраЭдЊЫиЕФМЏКЯЃЌВЂЧвМЏКЯФкЕФдЊЫиВЛФмжиИДЁЃ
ВЛЭЌЕФЪЧ zset УПИідЊЫиЖМЛсЙиСЊвЛИі double РраЭЕФЗжЪ§ЁЃredis ЭЈЙ§ЗжЪ§РДЮЊМЏКЯжаЕФГЩдБНјааДгаЁЕНДѓЕФХХађЁЃ
zset ЕФдЊЫиЪЧЮЈвЛЕФЃЌЕЋЪЧЗжЪ§ЃЈscoreЃЉШДПЩвджиИДЁЃ

127.0.0.1:6379>
zadd zset-key 728 member1
(integer) 1
127.0.0.1:6379> zadd zset-key 982 member0
(integer) 1
127.0.0.1:6379> zadd zset-key 982 member0
(integer) 0
127.0.0.1:6379> zrange zset-key 0 -1 withscores
1) "member1"
2) "728"
3) "member0"
4) "982"
127.0.0.1:6379> zrangebyscore zset-key 0 800
withscores
1) "member1"
2) "728"
127.0.0.1:6379> zrem zset-key member1
(integer) 1
127.0.0.1:6379> zrem zset-key member1
(integer) 0
127.0.0.1:6379> zrange zset-key 0 -1 withscores
1) "member0"
2) "982" |
zset ЪЧАДее ЗжЪфЕФДѓаЁРДХХађЕФЁЃ
аЁзмНс
РраЭМђНщЬиадГЁОАstringЃЈзжЗћДЎЃЉЖўНјжЦАВШЋПЩвдАќКЌШЮКЮЪ§ОнЃЌБШШч jpg ЭМЦЌЛђепађСаЛЏЕФЖдЯѓЃЌвЛИіМќзюДѓФмДцДЂ
521M---HashЃЈЙўЯЃЃЉМќжЕЖдМЏКЯЃЌМДБрГЬгябджаЕФ Map РраЭЪЪКЯДцДЂЖдЯѓЃЌВЂЧвПЩвдЯёЪ§ОнПтжа
update вЛбљжЛаоИФФГвЛЯюЪєаджЕДцДЂЁЂЖСШЁЁЂаоИФгУЛЇЪєадListЃЈСаБэЃЉЫЋЯђСДБэдіЩОПьЃЌЬсЙЉСЫВйзїФГвЛЖЮдЊЫиЕФ
API1ЁЂзюаТЯћЯЂХХааЕШЙІФмЃЈХѓгбШІЕФЪБМфЯпЃЉ2ЁЂЯћЯЂЖгСаSetЃЈМЏКЯЃЉЙўЯЃБэЪЕЯжЃЌдЊЫиВЛФмжиИДЬэМгЩОГ§ВщевЕФИДдгЖШЖМЪЧ
O(1);ЮЊМЏКЯЬсЙЉСЫЧѓНЛМЏЁЂВЂМЏЁЂВюМЏЕШВйзїЙВЭЌКУгбЃЛРћгУЮЈвЛадЃЌЭГМЦЗУЮЪЭјеОЕФЫљгаЖРСЂ ipЃЛКУгбЭЦМіЪБЃЌИљОн
tag ЧѓНЛМЏЃЌДѓгкФГИіуажЕОЭПЩвдЭЦМіZsetЃЈгаађМЏКЯЃЉНЋ Set жаЕФдЊЫидіМгвЛИіШЈжиВЮЪ§ scoreЃЌдЊЫиАД
score гаађХХСаЪ§ОнВхШыМЏКЯЪБЃЌвбОНјааЬьШЛХХађХХааАёЃЛДјШЈжиЕФЯћЯЂЖгСа
ЛљБОУќСю
здааВщдФ
ЗЂВМЖЉдФ
вЛАуВЛгУ Redis зіЯћЯЂЗЂВМЖЉдФЁЃ
МђНщ
Redis ЗЂВМЖЉдФ (pub/sub) ЪЧвЛжжЯћЯЂЭЈаХФЃЪНЃКЗЂЫЭеп (pub) ЗЂЫЭЯћЯЂЃЌЖЉдФеп
(sub) НгЪеЯћЯЂЁЃ
Redis ПЭЛЇЖЫПЩвдЖЉдФШЮвтЪ§СПЕФЦЕЕРЁЃ
ЯТЭМеЙЪОСЫЦЕЕР channel1 ЃЌ вдМАЖЉдФетИіЦЕЕРЕФШ§ИіПЭЛЇЖЫ ЁЊЁЊ client2 ЁЂ client5
КЭ client1 жЎМфЕФЙиЯЕЃК
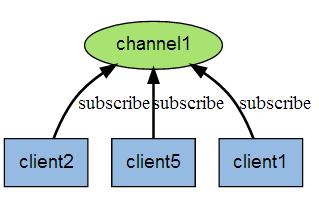
ЕБгааТЯћЯЂЭЈЙ§ PUBLISH УќСюЗЂЫЭИјЦЕЕР channel1 ЪБЃЌ етИіЯћЯЂОЭЛсБЛЗЂЫЭИјЖЉдФЫќЕФШ§ИіПЭЛЇЖЫЃК
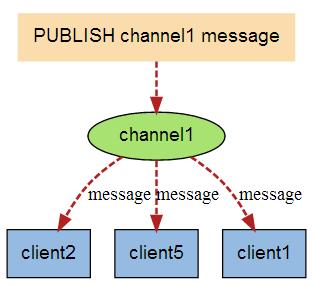
ЪЕР§
вдЯТЪЕР§бнЪОСЫЗЂВМЖЉдФЪЧШчКЮЙЄзїЕФЁЃдкЮвУЧЪЕР§жаЮвУЧДДНЈСЫЖЉдФЦЕЕРУћЮЊ redisChat:
127.0.0.1:6379>
SUBsCRIBE redisChat
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "redisChat" |
ЯждкЃЌЮвУЧЯШжиаТПЊЦєИі redis ПЭЛЇЖЫЃЌШЛКѓдкЭЌвЛИіЦЕЕР redisChat ЗЂВМСНДЮЯћЯЂЃЌЖЉдФепОЭФмНгЪеЕНЯћЯЂЁЃ
127.0.0.1:6379>
PUBLISH redisChat "send message"
(integer) 1
127.0.0.1:6379> PUBLISH redisChat "hello
world"
(integer) 1
# ЖЉдФепЕФПЭЛЇЖЫЯдЪОШчЯТ
1) "message"
2) "redisChat"
3) "send message"
1) "message"
2) "redisChat"
3) "hello world" |
ЗЂВМЖЉдФГЃгУУќСю
здааВщдФ
ЪТЮё
redis ЪТЮёвЛДЮПЩвджДааЖрЬѕУќСюЃЌЗўЮёЦїдкжДааУќСюЦкМфЃЌВЛЛсШЅжДааЦфЫћПЭЛЇЖЫЕФУќСюЧыЧѓЁЃ
ЪТЮёжаЕФЖрЬѕУќСюБЛвЛДЮадЗЂЫЭИјЗўЮёЦїЃЌЖјВЛЪЧвЛЬѕвЛЬѕЕиЗЂЫЭЃЌетжжЗНЪНБЛГЦЮЊСїЫЎЯпЃЌЫќПЩвдМѕЩйПЭЛЇЖЫгыЗўЮёЦїжЎМфЕФЭјТчЭЈаХДЮЪ§ДгЖјЬсЩ§адФмЁЃ
Redis зюМђЕЅЕФЪТЮёЪЕЯжЗНЪНЪЧЪЙгУ MULTI КЭ EXEC УќСюНЋЪТЮёВйзїАќЮЇЦ№РДЁЃ
ХњСПВйзїдкЗЂЫЭ EXEC УќСюЧАБЛЗХШыЖгСаЛКДцЁЃ
ЪеЕН EXEC УќСюКѓНјШыЪТЮёжДааЃЌЪТЮёжаШЮвтУќСюжДааЪЇАмЃЌЦфгрУќСювРШЛБЛжДааЁЃвВОЭЪЧЫЕ Redis
ЪТЮёВЛБЃжЄдзгадЁЃ
дкЪТЮёжДааЙ§ГЬжаЃЌЦфЫћПЭЛЇЖЫЬсНЛЕФУќСюЧыЧѓВЛЛсВхШыЕНЪТЮёжДааУќСюађСажаЁЃ
вЛИіЪТЮёДгПЊЪМЕНжДааЛсОРњвдЯТШ§ИіНзЖЮЃК
ПЊЪМЪТЮёЁЃ
УќСюШыЖгЁЃ
жДааЪТЮёЁЃ
ЪЕР§
вдЯТЪЧвЛИіЪТЮёЕФР§згЃЌ ЫќЯШвд MULTI ПЊЪМвЛИіЪТЮёЃЌ ШЛКѓНЋЖрИіУќСюШыЖгЕНЪТЮёжаЃЌ зюКѓгЩ
EXEC УќСюДЅЗЂЪТЮёЃЌ вЛВЂжДааЪТЮёжаЕФЫљгаУќСюЃК
redis 127.0.0.1:6379>
MULTI
OK
redis 127.0.0.1:6379> SET book-name "Mastering
C++ in 21 days"
QUEUED
redis 127.0.0.1:6379> GET book-name
QUEUED
redis 127.0.0.1:6379> SADD tag "C++"
"Programming" "Mastering Series"
QUEUED
redis 127.0.0.1:6379> SMEMBERS tag
QUEUED
redis 127.0.0.1:6379> EXEC
1) OK
2) "Mastering C++ in 21 days"
3) (integer) 3
4) 1) "Mastering Series"
2) "C++"
3) "Programming" |
ЕЅИі Redis УќСюЕФжДааЪЧдзгадЕФЃЌЕЋ Redis УЛгадкЪТЮёЩЯдіМгШЮКЮЮЌГждзгадЕФЛњжЦЃЌЫљвд
Redis ЪТЮёЕФжДааВЂВЛЪЧдзгадЕФЁЃ
ЪТЮёПЩвдРэНтЮЊвЛИіДђАќЕФХњСПжДааНХБОЃЌЕЋХњСПжИСюВЂЗЧдзгЛЏЕФВйзїЃЌжаМфФГЬѕжИСюЕФЪЇАмВЛЛсЕМжТЧАУцвбзіжИСюЕФЛиЙіЃЌвВВЛЛсдьГЩКѓајЕФжИСюВЛзіЁЃ
етЪЧЙйЭјЩЯЕФЫЕУї From redis docs on transactions:
It's important to note that even when a command fails,
all the other commands in the queue are processed
ЈC Redis will not stop the processing of commands.
БШШчЃК
redis 127.0.0.1:7000>
multi
OK
redis 127.0.0.1:7000> set a aaa
QUEUED
redis 127.0.0.1:7000> set b bbb
QUEUED
redis 127.0.0.1:7000> set c ccc
QUEUED
redis 127.0.0.1:7000> exec
1) OK
2) OK
3) OK |
ШчЙћдк set b bbb ДІЪЇАмЃЌset a вбГЩЙІВЛЛсЛиЙіЃЌset c ЛЙЛсМЬајжДааЁЃ
Redis ЪТЮёУќСю
ЯТБэСаГіСЫ redis ЪТЮёЕФЯрЙиУќСюЃК
ађКХУќСюМАУшЪі1DISCARD ШЁЯћЪТЮёЃЌЗХЦњжДааЪТЮёПщФкЕФЫљгаУќСюЁЃ2EXEC жДааЫљгаЪТЮёПщФкЕФУќСюЁЃ3MULTI
БъМЧвЛИіЪТЮёПщЕФПЊЪМЁЃ4UNWATCH ШЁЯћ WATCH УќСюЖдЫљга key ЕФМрЪгЁЃ5WATCH
key [key ...] МрЪгвЛИі (ЛђЖрИі) key ЃЌШчЙћдкЪТЮёжДаажЎЧАетИі (ЛђетаЉ) key
БЛЦфЫћУќСюЫљИФЖЏЃЌФЧУДЪТЮёНЋБЛДђЖЯЁЃ
ГжОУЛЏ
Redis ЪЧФкДцаЭЪ§ОнПтЃЌЮЊСЫБЃжЄЪ§ОндкЖЯЕчКѓВЛЛсЖЊЪЇЃЌашвЊНЋФкДцжаЕФЪ§ОнГжОУЛЏЕНгВХЬЩЯЁЃ
RDB ГжОУЛЏ
НЋФГИіЪБМфЕуЕФЫљгаЪ§ОнЖМДцЗХЕНгВХЬЩЯЁЃ
ПЩвдНЋПьееИДжЦЕНЦфЫћЗўЮёЦїДгЖјДДНЈОпгаЯрЭЌЪ§ОнЕФЗўЮёЦїИББОЁЃ
ШчЙћЯЕЭГЗЂЩњЙЪеЯЃЌНЋЛсЖЊЪЇзюКѓвЛДЮДДНЈПьеежЎКѓЕФЪ§ОнЁЃ
ШчЙћЪ§ОнСПДѓЃЌБЃДцПьееЕФЪБМфЛсКмГЄЁЃ
AOF ГжОУЛЏ
НЋаДУќСюЬэМгЕН AOF ЮФМўЃЈappend only fileЃЉФЉЮВЁЃ
ЪЙгУ AOF ГжОУЛЏашвЊЩшжУЭЌВНбЁЯюЃЌДгЖјШЗБЃаДУќСюЭЌВНЕНДХХЬЮФМўЩЯЕФЪБЛњЁЃетЪЧвђЮЊЖдЮФМўНјаааДШыВЂВЛЛсТэЩЯНЋФкШнЭЌВНЕНДХХЬЩЯЃЌЖјЪЧЯШДцДЂЕНЛКГхЧјЃЌШЛКѓгЩВйзїЯЕЭГОіЖЈЪВУДЪБКђЭЌВНЕНДХХЬЁЃ
бЁЯюЭЌВНЦЕТЪalwaysУПИіаДУќСюЖМЭЌВНeyerysecУПУыЭЌВНвЛДЮnoШУВйзїЯЕЭГРДОіЖЈКЮЪБЭЌВН
always бЁЯюЛсбЯжиМѕЕЭЗўЮёЦїЕФадФм
everysec бЁЯюБШНЯКЯЪЪЃЌПЩвдБЃжЄЯЕЭГБРРЃЪБжЛЛсЖЊЪЇвЛУызѓгвЕФЪ§ОнЃЌВЂЧв Redis УПУыжДаавЛДЮЭЌВНЖдЗўЮёЦїМИКѕУЛгаШЮКЮгАЯьЁЃ
no бЁЯюВЂВЛФмИјЗўЮёЦїадФмДјРДЖрДѓЕФЬсЩ§ЃЌЖјЧвЛсдіМгЯЕЭГБРРЃЪБЪ§ОнЖЊЪЇЕФЪ§СПЁЃ
ЫцзХЗўЮёЦїаДЧыЧѓЕФдіЖрЃЌAOF ЮФМўЛсдНРДдНДѓЁЃRedis ЬсЙЉСЫвЛжжНЋ AOF жиаДЕФЬиадЃЌФмЙЛШЅГ§
AOF ЮФМўжаЕФШпграДУќСюЁЃ
ИДжЦ
ЭЈЙ§ЪЙгУ slaveof host port УќСюРДШУвЛИіЗўЮёЦїГЩЮЊСэвЛИіЗўЮёЦїЕФДгЗўЮёЦїЁЃ
вЛИіДгЗўЮёЦїжЛФмгавЛИіжїЗўЮёЦїЃЌВЂЧвВЛжЇГжжїжїИДжЦЁЃ
СЌНгЙ§ГЬ
жїЗўЮёЦїДДНЈПьееЮФМўЃЌМД RDB ЮФМўЃЌЗЂЫЭИјДгЗўЮёЦїЃЌВЂдкЗЂЫЭЦкМфЪЙгУЛКГхЧјМЧТМжДааЕФаДУќСюЁЃПьееЮФМўЗЂЫЭЭъБЯжЎКѓЃЌПЊЪМЯёДгЗўЮёЦїЗЂЫЭДцДЂдкЛКГхЧјЕФаДУќСюЁЃ
ДгЗўЮёЦїЖЊЦњЫљгаОЩЪ§ОнЃЌдиШыжїЗўЮёЦїЗЂРДЕФПьееЮФМўЃЌжЎКѓДгЗўЮёЦїПЊЪМНгЪмжїЗўЮёЦїЗЂРДЕФаДУќСюЁЃ
жїЗўЮёЦїУПжДаавЛДЮаДУќСюЃЌОЭЯђДгЗўЮёЦїЗЂЫЭЯрЭЌЕФаДУќСюЁЃ
жїДгСД
ЫцзХИКдиВЛЖЯЩЯЩ§ЃЌжїЗўЮёЦїЮоЗЈКмПьЕФИќаТЫљгаДгЗўЮёЦїЃЌЛђепжиаТСЌНгКЭжиаТЭЌВНДгЗўЮёЦїНЋЕМжТЯЕЭГГЌдиЁЃЮЊСЫНтОіетИіЮЪЬтЃЌПЩвдДДНЈвЛИіжаМфВуРДЗжЕЃжїЗўЮёЦїЕФИДжЦЙЄзїЁЃжаМфВуЕФЗўЮёЦїЪЧзюЩЯВуЗўЮёЦїЕФДгЗўЮёЦїЃЌгжЪЧзюЯТВуЗўЮёЦїЕФжїЗўЮёЦїЁЃ

ЩкБј
SentinelЃЈЩкБјЃЉПЩвдМрЬ§МЏШКжаЕФЗўЮёЦїЃЌВЂдкжїЗўЮёЦїНјШыЯТЯпзДЬЌЪБЃЌздЖЏДгДгЗўЮёЦїжабЁОйДІаТЕФжїЗўЮёЦїЁЃ
ЗжЦЌ
ЗжЦЌЪЧНЋЪ§ОнЛЎЗжЮЊЖрИіВПЗжЕФЗНЗЈЃЌПЩвдНЋЪ§ОнДцДЂЕНЖрЬЈЛњЦїРяУцЃЌетжжЗНЗЈдкНтОіФГаЉЮЪЬтЪБПЩвдЛёЕУЯпадМЖБ№ЕФадФмЬсЩ§ЁЃ
МйЩшга 4 Иі Redis ЪЕР§ R0, R1, R2, R3, ЛЙгаКмЖрБэЪОгУЛЇЕФМќ user:1,
user:2, ... , гаВЛЭЌЕФЗНЪНРДбЁдёвЛИіжИЖЈЕФМќДцДЂдкФФИіЪЕР§жаЁЃ
зюМђЕЅЕФЪЧЗЖЮЇЗжЦЌЃЌР§ШчгУЛЇ id Дг 0 ~ 1000 ЕФДцДЂЕНЪЕР§ R0 жаЃЌгУЛЇ id Дг
1001 ~ 2000 ЕФДцДЂЕНЪЕР§ R1жаЃЌЕШЕШЁЃЕЋЪЧетбљашвЊЮЌЛЄвЛеХгГЩфЗЖЮЇБэЃЌЮЌЛЄВйзїДњМлИпЁЃ
ЛЙгавЛжжЪЧЙўЯЃЗжЦЌЁЃЪЙгУ CRC32 ЙўЯЃКЏЪ§НЋМќзЊЛЛЮЊвЛИіЪ§зжЃЌдйЖдЪЕР§Ъ§СПЧѓФЃОЭФмжЊЕРДцДЂЕФЪЕР§ЁЃ
ИљОнжДааЗжЦЌЕФЮЛжУЃЌПЩвдЗжЮЊШ§жжЗжЦЌЗНЪНЃК
ПЭЛЇЖЫЗжЦЌЃКПЭЛЇЖЫЪЙгУвЛжТадЙўЯЃЕШЫуЗЈОіЖЈгІЕБЗжВМЕНФФИіНкЕуЁЃ
ДњРэЗжЦЌЃКНЋПЭЛЇЖЫЕФЧыЧѓЗЂЫЭЕНДњРэЩЯЃЌгЩДњРэзЊЗЂЕНе§ШЗЕФНкЕуЩЯЁЃ
ЗўЮёЦїЗжЦЌЃКRedis ClusterЁЃ
| 







