| БрМЭЦМі: |
ЯраХДѓМвЖМгУЙ§ЪТЮёвдМАСЫНтЫћЕФЬиЕуЃЌШчдзгад(Atomicity),вЛжТад(Consistency),ИєРыаЭ(Isolation)вдМАГжОУад(Durability)ЕШЁЃНёЬьЯыИњДѓМввЛЦ№баОПЯТЪТЮёФкВПЕНЕзЪЧдѕУДЪЕЯжЕФЁЃ
БОЮФРДздЫбКќЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ
|
|
дкНВНтЧАЮвЯыЯШХзГіИіЮЪЬтЃК
ЪТЮёЯывЊзіЕНЪВУДаЇЙћЃП
АДЮвРэНтЃЌЮоЗЧЪЧвЊзіЕНПЩППадвдМАВЂЗЂДІРэЁЃ
ПЩППадЃКЪ§ОнПтвЊБЃжЄЕБinsertЛђupdateВйзїЪБХзвьГЃЛђепЪ§ОнПтcrashЕФЪБКђашвЊБЃеЯЪ§ОнЕФВйзїЧАКѓЕФвЛжТЃЌЯывЊзіЕНетИіЃЌЮвашвЊжЊЕРЮваоИФжЎЧАКЭаоИФжЎКѓЕФзДЬЌЃЌЫљвдОЭгаСЫundo
logКЭredo logЁЃ
ВЂЗЂДІРэЃКвВОЭЪЧЫЕЕБЖрИіВЂЗЂЧыЧѓЙ§РДЃЌВЂЧвЦфжагавЛИіЧыЧѓЪЧЖдЪ§ОнаоИФВйзїЕФЪБКђЛсгагАЯьЃЌЮЊСЫБмУтЖСЕНдрЪ§ОнЃЌЫљвдашвЊЖдЪТЮёжЎМфЕФЖСаДНјааИєРыЃЌжСгкИєРыЕНЩЖГЬЖШЕУПДвЕЮёЯЕЭГЕФГЁОАСЫЃЌЪЕЯжетИіОЭЕУгУMySQL
ЕФИєРыМЖБ№ЁЃ
ЯТУцЮвЪзЯШНВЪЕЯжЪТЮёЙІФмЕФШ§ИіММЪѕЃЌЗжБ№ЪЧШежОЮФМў(redo log КЭ undo log)ЃЌЫјММЪѕвдМАMVCCЃЌШЛКѓдйНВЪТЮёЕФЪЕЯждРэЃЌАќРЈдзгадЪЧдѕУДЪЕЯжЕФЃЌИєРыаЭЪЧдѕУДЪЕЯжЕФЕШЕШЁЃзюКѓдкзівЛИізмНсЃЌЯЃЭћДѓМвФмЙЛФЭаФПДЭъ
redo logгыundo logНщЩм
mysqlЫјММЪѕвдМАMVCCЛљДЁ
ЪТЮёЕФЪЕЯждРэ
змНс
redo log гы undo logНщЩм
1. redo log
ЪВУДЪЧredo log ?
redo logНазіжизіШежОЃЌЪЧгУРДЪЕЯжЪТЮёЕФГжОУадЁЃИУШежОЮФМўгЩСНВПЗжзщГЩЃКжизіШежОЛКГхЃЈredo
log bufferЃЉвдМАжизіШежОЮФМўЃЈredo logЃЉ,ЧАепЪЧдкФкДцжаЃЌКѓепдкДХХЬжаЁЃЕБЪТЮёЬсНЛжЎКѓЛсАбЫљгааоИФаХЯЂЖМЛсДцЕНИУШежОжаЁЃМйЩшгаИіБэНазіtb1(id,username)
ЯждквЊВхШыЪ§ОнЃЈ3ЃЌceshiЃЉ
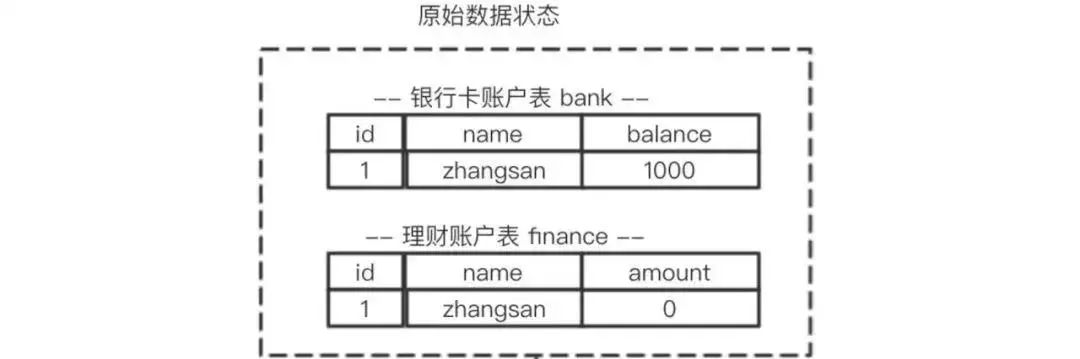
starttransaction; selectbalancefrombankwherename="zhangsan";//ЩњГЩжизіШежО
balance=600updatebanksetbalance= balance-400;//ЩњГЩжизіШежО
amount=400updatefinancesetamount =amount+400;commit;
redo log гаЪВУДзїгУЃП
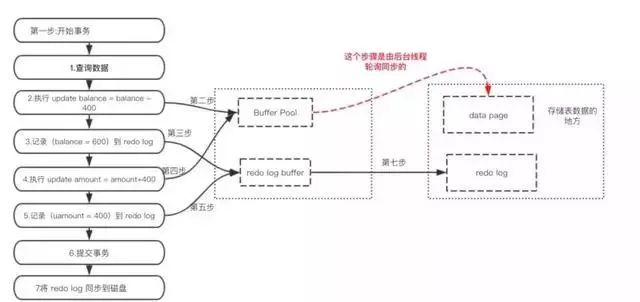
mysql ЮЊСЫЬсЩ§адФмВЛЛсАбУПДЮЕФаоИФЖМЪЕЪБЭЌВНЕНДХХЬЃЌЖјЪЧЛсЯШДцЕНBoffer Pool(ЛКГхГи)РяЭЗЃЌАбетИіЕБзїЛКДцРДгУЁЃШЛКѓЪЙгУКѓЬЈЯпГЬШЅзіЛКГхГиКЭДХХЬжЎМфЕФЭЌВНЁЃ
ФЧУДЮЪЬтРДСЫЃЌШчЙћЛЙУЛРДЕФЭЌВНЕФЪБКђхДЛњЛђЖЯЕчСЫдѕУДАьЃПЛЙУЛРДЕУМАжДааЩЯУцЭМжаКьЩЋЕФВйзїЁЃетбљЛсЕМжТЖЊВПЗжвбЬсНЛЪТЮёЕФаоИФаХЯЂЃЁ
Ыљвдв§ШыСЫredo logРДМЧТМвбГЩЙІЬсНЛЪТЮёЕФаоИФаХЯЂЃЌВЂЧвЛсАбredo logГжОУЛЏЕНДХХЬЃЌЯЕЭГжиЦєжЎКѓдкЖСШЁredo
logЛжИДзюаТЪ§ОнЁЃ
змНсЃК
redo logЪЧгУРДЛжИДЪ§ОнЕФ гУгкБЃеЯвбЬсНЛЪТЮёЕФГжОУЛЏЬиадЁЃ
2.undo log
ЪВУДЪЧ undo log ЃП
undo log НазіЛиЙіШежОЃЌгУгкМЧТМЪ§ОнБЛаоИФЧАЕФаХЯЂЁЃЫће§КУИњЧАУцЫљЫЕЕФжизіШежОЫљМЧТМЕФЯрЗДЃЌжизіШежОМЧТМЪ§ОнБЛаоИФКѓЕФаХЯЂЁЃundo
logжївЊМЧТМЕФЪЧЪ§ОнЕФТпМБфЛЏЃЌЮЊСЫдкЗЂЩњДэЮѓЪБЛиЙіжЎЧАЕФВйзїЃЌашвЊНЋжЎЧАЕФВйзїЖММЧТМЯТРДЃЌШЛКѓдкЗЂЩњДэЮѓЪБВХПЩвдЛиЙіЁЃ
ЛЙгУЩЯУцФЧСНеХБэ
УПДЮаДШыЪ§ОнЛђепаоИФЪ§ОнжЎЧАЖМЛсАбаоИФЧАЕФаХЯЂМЧТМЕН undo logЁЃ
undo log гаЪВУДзїгУЃП
undo log МЧТМЪТЮёаоИФжЎЧААцБОЕФЪ§ОнаХЯЂЃЌвђДЫМйШчгЩгкЯЕЭГДэЮѓЛђепrollbackВйзїЖјЛиЙіЕФЛАПЩвдИљОнundo
logЕФаХЯЂРДНјааЛиЙіЕНУЛБЛаоИФЧАЕФзДЬЌЁЃ
змНсЃК
undo logЪЧгУРДЛиЙіЪ§ОнЕФгУгкБЃеЯ ЮДЬсНЛЪТЮёЕФдзгад
mysqlЫјММЪѕвдМАMVCCЛљДЁ
1. mysqlЫјММЪѕ
ЕБгаЖрИіЧыЧѓРДЖСШЁБэжаЕФЪ§ОнЪБПЩвдВЛВЩШЁШЮКЮВйзїЃЌЕЋЪЧЖрИіЧыЧѓРягаЖСЧыЧѓЃЌгжгааоИФЧыЧѓЪББиаыгавЛжжДыЪЉРДНјааВЂЗЂПижЦЁЃВЛШЛКмгаПЩФмЛсдьГЩВЛвЛжТЁЃ
ЖСаДЫј
НтОіЩЯЪіЮЪЬтКмМђЕЅЃЌжЛашгУСНжжЫјЕФзщКЯРДЖдЖСаДЧыЧѓНјааПижЦМДПЩЃЌетСНжжЫјБЛГЦЮЊЃК
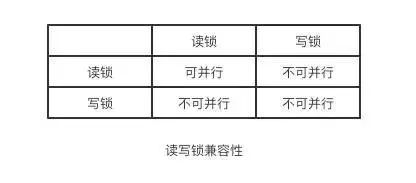
ЙВЯэЫј(shared lock),гжНазі"ЖСЫј"
ЖСЫјЪЧПЩвдЙВЯэЕФЃЌЛђепЫЕЖрИіЖСЧыЧѓПЩвдЙВЯэвЛАбЫјЖСЪ§ОнЃЌВЛЛсдьГЩзшШћЁЃ
ХХЫћЫј(exclusive lock),гжНазі"аДЫј"
аДЫјЛсХХГтЦфЫћЫљгаЛёШЁЫјЕФЧыЧѓЃЌвЛжБзшШћЃЌжБЕНаДШыЭъГЩЪЭЗХЫјЁЃ
змНсЃК
ЭЈЙ§ЖСаДЫјЃЌПЩвдзіЕНЖСЖСПЩвдВЂааЃЌЕЋЪЧВЛФмзіЕНаДЖСЃЌаДаДВЂаа
ЪТЮёЕФИєРыадОЭЪЧИљОнЖСаДЫјРДЪЕЯжЕФЃЁЃЁЃЁетИіКѓУцдйЫЕЁЃ
2. MVCCЛљДЁ
MVCC (MultiVersion Concurrency Control) НазіЖрАцБОВЂЗЂПижЦЁЃ
InnoDBЕФ MVCC ЃЌЪЧЭЈЙ§дкУПааМЧТМЕФКѓУцБЃДцСНИівўВиЕФСаРДЪЕЯжЕФЁЃетСНИіСаЃЌвЛИіБЃДцСЫааЕФДДНЈЪБМфЃЌвЛИіБЃДцСЫааЕФЙ§ЦкЪБМфЃЌЕБШЛДцДЂЕФВЂВЛЪЧЪЕМЪЕФЪБМфжЕЃЌЖјЪЧЯЕЭГАцБОКХ
вдЩЯЦЌЖЮеЊздЁЖИпадФмMysqlЁЗетБОЪщЖдMVCCЕФЖЈвхЁЃЫћЕФжївЊЪЕЯжЫМЯыЪЧЭЈЙ§Ъ§ОнЖрАцБОРДзіЕНЖСаДЗжРыЁЃДгЖјЪЕЯжВЛМгЫјЖСНјЖјзіЕНЖСаДВЂааЁЃ
MVCCдкmysqlжаЕФЪЕЯжвРРЕЕФЪЧundo logгыread view
undo log :undo log жаМЧТМФГааЪ§ОнЕФЖрИіАцБОЕФЪ§ОнЁЃ
read view :гУРДХаЖЯЕБЧААцБОЪ§ОнЕФПЩМћад
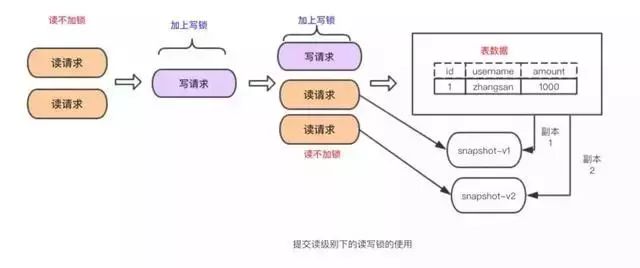
ЪТЮёЕФЪЕЯж
ЧАУцНВЕФжизіШежОЃЌЛиЙіШежОвдМАЫјММЪѕОЭЪЧЪЕЯжЪТЮёЕФЛљДЁЁЃ
ЪТЮёЕФдзгадЪЧЭЈЙ§undologРДЪЕЯжЕФЪТЮёЕФГжОУададЪЧЭЈЙ§redologРДЪЕЯжЕФЪТЮёЕФИєРыадЪЧЭЈЙ§(ЖСаДЫј+MVCC)РДЪЕЯжЕФЖјЪТЮёЕФжеМЋДѓ
boss вЛжТадЪЧЭЈЙ§дзгадЃЌГжОУадЃЌИєРыадРДЪЕЯжЕФЃЁЃЁЃЁ
дзгадЃЌГжОУадЃЌИєРыаделЬкАыЬьЕФФПЕФвВЪЧЮЊСЫБЃеЯЪ§ОнЕФвЛжТадЃЁ
змжЎЃЌACIDжЛЪЧИіИХФюЃЌЪТЮёзюжеФПЕФЪЧвЊБЃеЯЪ§ОнЕФПЩППадЃЌвЛжТадЁЃ
1.дзгадЕФЪЕЯж
ЪВУДЪЧдзгадЃК
вЛИіЪТЮёБиаыБЛЪгЮЊВЛПЩЗжИюЕФзюаЁЙЄзїЕЅЮЛЃЌвЛИіЪТЮёжаЕФЫљгаВйзївЊУДШЋВПГЩЙІЬсНЛЃЌвЊУДШЋВПЪЇАмЛиЙіЃЌЖдгквЛИіЪТЮёРДЫЕВЛПЩФмжЛжДааЦфжаЕФВПЗжВйзїЃЌетОЭЪЧЪТЮёЕФдзгадЁЃ
ЩЯУцетЖЮЛАШЁздЁЖИпадФмMySQLЁЗетБОЪщЖддзгадЕФЖЈвхЃЌдзгадПЩвдИХРЈЮЊОЭЪЧвЊЪЕЯжвЊУДШЋВПЪЇАмЃЌвЊУДШЋВПГЩЙІЁЃ
вдЩЯИХФюЯраХДѓМвЛяЖљЖМСЫНтЃЌФЧУДЪ§ОнПтЪЧдѕУДЪЕЯжЕФФиЃПОЭЪЧЭЈЙ§ЛиЙіВйзїЁЃЫљЮНЛиЙіВйзїОЭЪЧЕБЗЂЩњДэЮѓвьГЃЛђепЯдЪНЕФжДааrollbackгяОфЪБашвЊАбЪ§ОнЛЙдЕНдЯШЕФФЃбљЃЌЫљвдетЪБКђОЭашвЊгУЕНundo
logРДНјааЛиЙіЃЌНгЯТРДПДвЛЯТundo logдкЪЕЯжЪТЮёдзгадЪБдѕУДЗЂЛгзїгУЕФ
1.1 undo log ЕФЩњГЩ
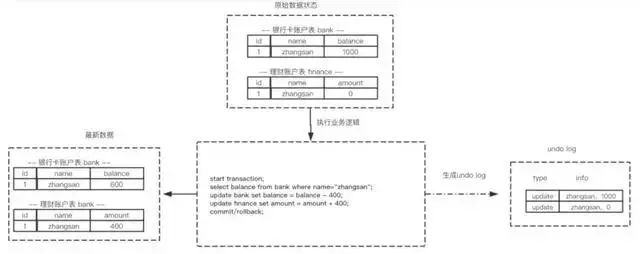
МйЩшгаСНИіБэ bankКЭfinanceЃЌБэжадЪМЪ§ОнШчЭМЫљЪОЃЌЕБНјааВхШыЃЌЩОГ§вдМАИќаТВйзїЪБЩњГЩЕФundo
logШчЯТУцЭМЫљЪОЃК
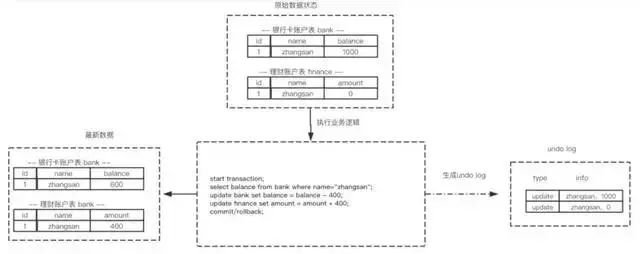

ДгЩЯЭМПЩвдСЫНтЕНЪ§ОнЕФБфИќЖМАщЫцзХЛиЙіШежОЕФВњЩњЃК
(1) ВњЩњСЫБЛаоИФЧАЪ§Он(zhangsan,1000) ЕФЛиЙіШежО
(2) ВњЩњСЫБЛаоИФЧАЪ§Он(zhangsan,0) ЕФЛиЙіШежО
ИљОнЩЯУцСїГЬПЩвдЕУГіШчЯТНсТлЃК
1.УПЬѕЪ§ОнБфИќ(insert/update/delete)ВйзїЖМАщЫцвЛЬѕundo logЕФЩњГЩ,ВЂЧвЛиЙіШежОБиаыЯШгкЪ§ОнГжОУЛЏЕНДХХЬЩЯ
2.ЫљЮНЕФЛиЙіОЭЪЧИљОнЛиЙіШежОзіФцЯђВйзїЃЌБШШчdeleteЕФФцЯђВйзїЮЊinsertЃЌinsertЕФФцЯђВйзїЮЊdeleteЃЌupdateЕФФцЯђЮЊupdateЕШЁЃ
ЫМПМЃКЮЊЪВУДЯШаДШежОКѓаДЪ§ОнПтЃП--- ЩдКѓзіНтЪЭ
1.2 ИљОнundo log НјааЛиЙі
ЮЊСЫзіЕНЭЌЪБГЩЙІЛђепЪЇАмЃЌЕБЯЕЭГЗЂЩњДэЮѓЛђепжДааrollbackВйзїЪБашвЊИљОнundo log НјааЛиЙі
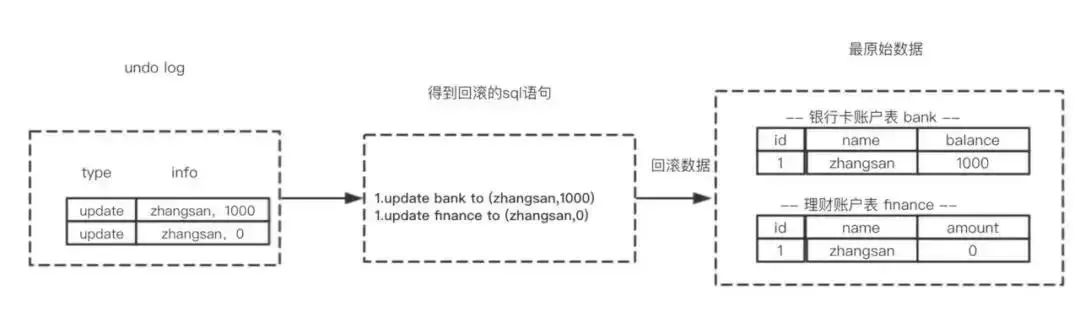
ЛиЙіВйзїОЭЪЧвЊЛЙдЕНдРДЕФзДЬЌЃЌundo logМЧТМСЫЪ§ОнБЛаоИФЧАЕФаХЯЂвдМАаТдіКЭБЛЩОГ§ЕФЪ§ОнаХЯЂЃЌИљОнundo
logЩњГЩЛиЙігяОфЃЌБШШчЃК
(1) ШчЙћдкЛиЙіШежОРягааТдіЪ§ОнМЧТМЃЌдђЩњГЩЩОГ§ИУЬѕЕФгяОф
(2) ШчЙћдкЛиЙіШежОРягаЩОГ§Ъ§ОнМЧТМЃЌдђЩњГЩЩњГЩИУЬѕЕФгяОф
(3) ШчЙћдкЛиЙіШежОРягааоИФЪ§ОнМЧТМЃЌдђЩњГЩаоИФЕНдЯШЪ§ОнЕФгяОф
2.ГжОУадЕФЪЕЯж
ЪТЮёвЛЕЉЬсНЛЃЌЦфЫљзіЕФаоИФЛсгРОУБЃДцЕНЪ§ОнПтжаЃЌДЫЪБМДЪЙЯЕЭГБРРЃаоИФЕФЪ§ОнвВВЛЛсЖЊЪЇЁЃ
ЯШСЫНтвЛЯТMySQLЕФЪ§ОнДцДЂЛњжЦЃЌMySQLЕФБэЪ§ОнЪЧДцЗХдкДХХЬЩЯЕФЃЌвђДЫЯывЊДцШЁЕФЪБКђЖМвЊОРњДХХЬIO,ШЛЖјМДЪЙЪЧЪЙгУSSDДХХЬIOвВЪЧЗЧГЃЯћКФадФмЕФЁЃЮЊДЫЃЌЮЊСЫЬсЩ§адФмInnoDBЬсЙЉСЫЛКГхГи(Buffer
Pool)ЃЌBuffer PoolжаАќКЌСЫДХХЬЪ§ОнвГЕФгГЩфЃЌПЩвдЕБзіЛКДцРДЪЙгУЃК
ЖСЪ§ОнЃКЛсЪзЯШДгЛКГхГижаЖСШЁЃЌШчЙћЛКГхГижаУЛгаЃЌдђДгДХХЬЖСШЁдйЗХШыЛКГхГиЃЛ
аДЪ§ОнЃКЛсЪзЯШаДШыЛКГхГиЃЌЛКГхГижаЕФЪ§ОнЛсЖЈЦкЭЌВНЕНДХХЬжаЃЛ
ЩЯУцетжжЛКГхГиЕФДыЪЉЫфШЛдкадФмЗНУцДјРДСЫжЪЕФЗЩдОЃЌЕЋЪЧЫќвВДјРДСЫаТЕФЮЪЬтЃЌЕБMySQLЯЕЭГхДЛњЃЌЖЯЕчЕФЪБКђПЩФмЛсЖЊЪ§ОнЃЁЃЁЃЁ
вђЮЊЮвУЧЕФЪ§ОнвбОЬсНЛСЫЃЌЕЋДЫЪБЪЧдкЛКГхГиРяЭЗЃЌЛЙУЛРДЕУМАдкДХХЬГжОУЛЏЃЌЫљвдЮвУЧМБашвЛжжЛњжЦашвЊДцвЛЯТвбЬсНЛЪТЮёЕФЪ§ОнЃЌЮЊЛжИДЪ§ОнЪЙгУЁЃ
гкЪЧ redo logОЭХЩЩЯгУГЁСЫЁЃЯТУцПДЯТredo logЪЧЪВУДЪБКђВњЩњЕФ
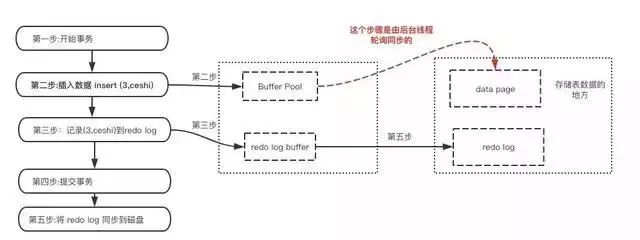
МШШЛredo logвВашвЊДцДЂЃЌвВЩцМАДХХЬIOЮЊЩЖЛЙгУЫќЃП
ЃЈ1ЃЉredo log ЕФДцДЂЪЧЫГађДцДЂЃЌЖјЛКДцЭЌВНЪЧЫцЛњВйзїЁЃ
ЃЈ2ЃЉЛКДцЭЌВНЪЧвдЪ§ОнвГЮЊЕЅЮЛЕФЃЌУПДЮДЋЪфЕФЪ§ОнДѓаЁДѓгкredo logЁЃ
3.ИєРыадЪЕЯж
ИєРыадЪЧЪТЮёACIDЬиадРязюИДдгЕФвЛИіЁЃдкSQLБъзМРяЖЈвхСЫЫФжжИєРыМЖБ№ЃЌУПвЛжжМЖБ№ЖМЙцЖЈвЛИіЪТЮёжаЕФаоИФЃЌФФаЉЪЧЪТЮёжЎМфПЩМћЕФЃЌФФаЉЪЧВЛПЩМћЕФЁЃ
МЖБ№дНЕЭЕФИєРыМЖБ№ПЩвджДаадНИпЕФВЂЗЂЃЌЕЋЭЌЪБЪЕЯжИДдгЖШвдМАПЊЯњвВдНДѓЁЃ
MySQLИєРыМЖБ№гавдЯТЫФжжЃЈМЖБ№гЩЕЭЕНИпЃЉЃК
READUNCOMMITED(ЮДЬсНЛЖС)
READCOMMITED(ЬсНЛЖС)
REPEATABLEREAD(ПЩжиИДЖС)
SERIALIZABLE (ПЩжиИДЖС)
жЛвЊГЙЕзРэНтСЫИєРыМЖБ№вдМАЫћЕФЪЕЯждРэОЭЯрЕБгкРэНтСЫACIDРяЕФИєРыаЭЁЃЧАУцЫЕЙ§дзгадЃЌИєРыадЃЌГжОУадЕФФПЕФЖМЪЧЮЊСЫвЊзіЕНвЛжТадЃЌЕЋИєРыаЭИњЦфЫћСНИігаЫљЧјБ№ЃЌдзгадКЭГжОУадЪЧЮЊСЫвЊЪЕЯжЪ§ОнЕФПЩадБЃеЯППЃЌБШШчвЊзіЕНхДЛњКѓЕФЛжИДЃЌвдМАДэЮѓКѓЕФЛиЙіЁЃ
ФЧУДИєРыадЪЧвЊзіЕНЪВУДФиЃПИєРыадЪЧвЊЙмРэЖрИіВЂЗЂЖСаДЧыЧѓЕФЗУЮЪЫГађЁЃетжжЫГађАќРЈДЎааЛђепЪЧВЂаа
ЫЕУївЛЕуЃЌаДЧыЧѓВЛНіНіЪЧжИinsertВйзїЃЌгжАќРЈupdateВйзїЁЃ
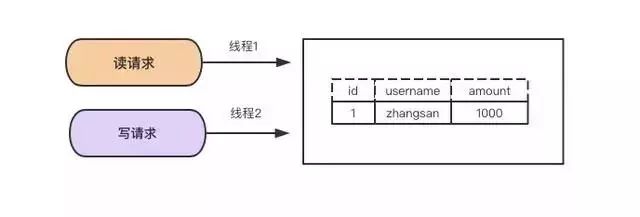
змжЎЃЌДгИєРыадЕФЪЕЯжПЩвдПДГіетЪЧвЛГЁЪ§ОнЕФ ПЩППадгыадФмжЎМфЕФШЈКтЃК
ПЩППададИпЕФЃЌВЂЗЂадФмЕЭ(БШШчSerializable)ЁЃПЩППадЕЭЕФЃЌВЂЗЂадФмИп(БШШч Read
Uncommited)
READ UNCOMMITTED
дкREAD UNCOMMITTEDИєРыМЖБ№ЯТЃЌЪТЮёжаЕФаоИФМДЪЙЛЙУЛЬсНЛЃЌЖдЦфЫћЪТЮёЪЧПЩМћЕФЁЃЪТЮёПЩвдЖСШЁЮДЬсНЛЕФЪ§ОнЃЌдьГЩдрЖСЁЃ
вђЮЊЖСВЛЛсМгШЮКЮЫјЃЌЫљвдаДВйзїдкЖСЕФЙ§ГЬжааоИФЪ§ОнЃЌЫљвдЛсдьГЩдрЖСЁЃКУДІЪЧПЩвдЬсЩ§ВЂЗЂДІРэадФмЃЌФмзіЕНЖСаДВЂааЁЃ
ЛЛОфЛАЫЕЃЌЖСЕФВйзїВЛФмХХГтаДЧыЧѓЁЃ
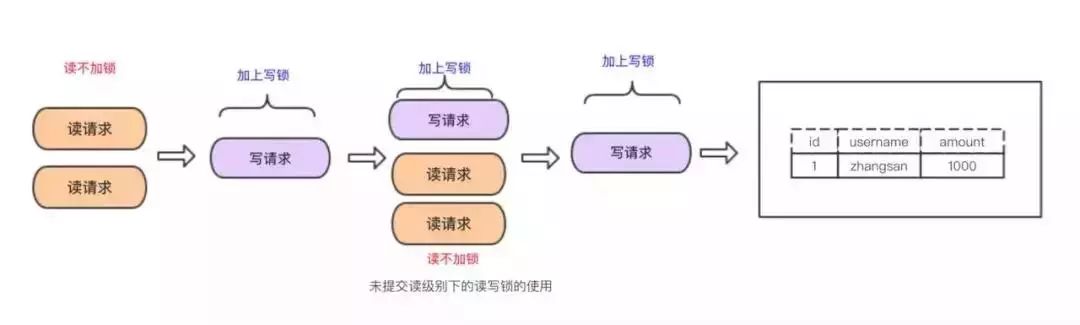
гХЕуЃКЖСаДВЂааЃЌадФмИп
ШБЕуЃКдьГЩдрЖС
READ COMMITTED
вЛИіЪТЮёЕФаоИФдкЫћЬсНЛжЎЧАЕФЫљгааоИФЃЌЖдЦфЫћЪТЮёЖМЪЧВЛПЩМћЕФЁЃЦфЫћЪТЮёФмЖСЕНвбЬсНЛЕФаоИФБфЛЏЁЃдкКмЖрГЁОАЯТетжжТпМЪЧПЩвдНгЪмЕФЁЃ
InnoDBдк READ COMMITTEDЃЌЪЙгУХХЫќЫј,ЖСШЁЪ§ОнВЛМгЫјЖјЪЧЪЙгУСЫMVCCЛњжЦЁЃЛђепЛЛОфЛАЫЕЫћВЩгУСЫЖСаДЗжРыЛњжЦЁЃ
ЕЋЪЧИУМЖБ№ЛсВњЩњВЛПЩжиЖСвдМАЛУЖСЮЪЬтЁЃ
ЪВУДЪЧВЛПЩжиЖСЃП
дквЛИіЪТЮёФкЖрДЮЖСШЁЕФНсЙћВЛвЛбљЁЃ
ЮЊЪВУДЛсВњЩњВЛПЩжиИДЖСЃП
етИњ READ COMMITTED МЖБ№ЯТЕФMVCCЛњжЦгаЙиЯЕЃЌдкИУИєРыМЖБ№ЯТУПДЮ selectЕФЪБКђаТЩњГЩвЛИіАцБОКХЃЌЫљвдУПДЮselectЕФЪБКђЖСЕФВЛЪЧвЛИіИББОЖјЪЧВЛЭЌЕФИББОЁЃ
дкУПДЮselectжЎМфгаЦфЫћЪТЮёИќаТСЫЮвУЧЖСШЁЕФЪ§ОнВЂЬсНЛСЫЃЌФЧОЭГіЯжСЫВЛПЩжиИДЖС
REPEATABLE READ(MysqlФЌШЯИєРыМЖБ№)
дквЛИіЪТЮёФкЕФЖрДЮЖСШЁЕФНсЙћЪЧвЛбљЕФЁЃетжжМЖБ№ЯТПЩвдБмУтЃЌдрЖСЃЌВЛПЩжиИДЖСЕШВщбЏЮЪЬтЁЃmysql
гаСНжжЛњжЦПЩвдДяЕНетжжИєРыМЖБ№ЕФаЇЙћЃЌЗжБ№ЪЧВЩгУЖСаДЫјвдМАMVCCЁЃ
ВЩгУЖСаДЫјЪЕЯжЃК
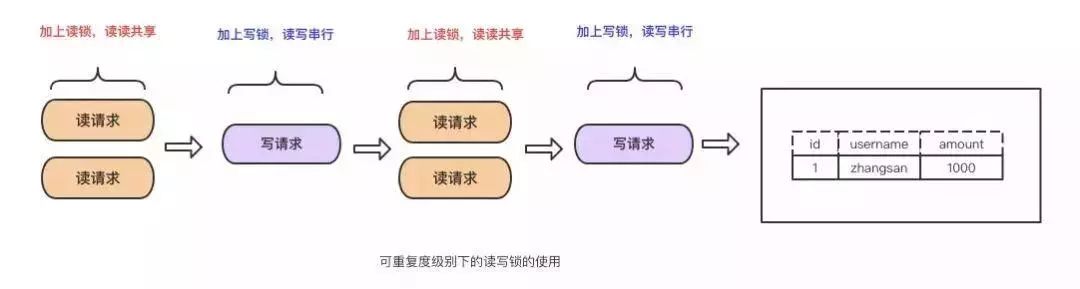
ЮЊЪВУДФмПЩжиИДЖСЃПжЛвЊУЛЪЭЗХЖСЫјЃЌдкДЮЖСЕФЪБКђЛЙЪЧПЩвдЖСЕНЕквЛДЮЖСЕФЪ§ОнЁЃ
гХЕуЃКЪЕЯжЦ№РДМђЕЅ
ШБЕуЃКЮоЗЈзіЕНЖСаДВЂаа
ВЩгУMVCCЪЕЯжЃК
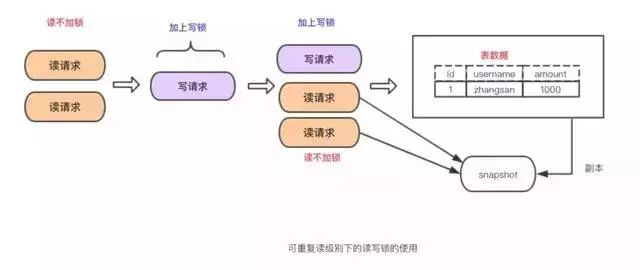
ЮЊЪВУДФмПЩжиИДЖСЃПвђЮЊЖрДЮЖСШЁжЛЩњГЩвЛИіАцБОЃЌЖСЕНЕФздШЛЪЧЯрЭЌЪ§ОнЁЃ
гХЕуЃКЖСаДВЂаа
ШБЕуЃКЪЕЯжЕФИДдгЖШИп
ЕЋЪЧдкИУИєРыМЖБ№ЯТШдЛсДцдкЛУЖСЕФЮЪЬтЃЌЙигкЛУЖСЕФНтОіЮвДђЫуСэПЊвЛЦЊРДНщЩмЁЃ
SERIALIZABLE
ИУИєРыМЖБ№РэНтЦ№РДзюМђЕЅЃЌЪЕЯжвВзюМђЕЅЁЃдкИєРыМЖБ№ЯТГ§СЫВЛЛсдьГЩЪ§ОнВЛвЛжТЮЪЬтЃЌУЛЦфЫћгХЕуЁЃ

--еЊздЁЖИпадФмMysqlЁЗ
4.вЛжТадЕФЪЕЯж
Ъ§ОнПтзмЪЧДгвЛИівЛжТадЕФзДЬЌзЊвЦЕНСэвЛИівЛжТадЕФзДЬЌЁЃ
ЯТУцОйИіР§згЃЌzhangsan ДгвјааПЈзЊ400ЕНРэВЦеЫЛЇ:
starttransaction; selectbalancefrombankwherename
="zhangsan";//ЩњГЩжизіШежО
balance=600updatebanksetbalance =balance-400;//ЩњГЩжизіШежО
amount=400updatefinancesetamount =amount+400;commit;
1.МйШчжДааЭъ update bank set balance =
balance - 400;жЎЗЂЩњвьГЃСЫЃЌвјааПЈЕФЧЎвВВЛФмЦНАзЮоЙЪЕФМѕЩйЃЌЖјЪЧЛиЙіЕНзюГѕзДЬЌЁЃ
2.гжЛђепЪТЮёЬсНЛжЎКѓЃЌЛКГхГиЛЙУЛЭЌВНЕНДХХЬЕФЪБКђхДЛњСЫЃЌетвВЪЧВЛФмНгЪмЕФЃЌгІИУдкжиЦєЕФЪБКђЛжИДВЂГжОУЛЏЁЃ
3.МйШчгаВЂЗЂЪТЮёЧыЧѓЕФЪБКђвВгІИУзіКУЪТЮёжЎМфЕФПЩМћадЮЪЬтЃЌБмУтдьГЩдрЖСЃЌВЛПЩжиИДЖСЃЌЛУЖСЕШЁЃдкЩцМАВЂЗЂЕФЧщПіЯТЭљЭљдкадФмКЭвЛжТаджЎМфзіЦНКтЃЌзівЛЖЈЕФШЁЩсЃЌЫљвдИєРыадвВЪЧЖдвЛжТадЕФвЛжжЦЦЛЕЁЃ
змНс
БОГіЗЂЕуЪЧЯыНВвЛЯТMysqlЕФЪТЮёЕФЪЕЯждРэЁЃ
ЪЕЯжЪТЮёВЩШЁСЫФФаЉММЪѕвдМАЫМЯыЃП
дзгадЃК ЪЙгУ undo log ЃЌДгЖјДяЕНЛиЙі
ГжОУадЃК ЪЙгУ redo logЃЌДгЖјДяЕНЙЪеЯКѓЛжИД
ИєРыадЃК ЪЙгУЫјвдМАMVCC,дЫгУЕФгХЛЏЫМЯыгаЖСаДЗжРыЃЌЖСЖСВЂааЃЌЖСаДВЂаа
вЛжТадЃК ЭЈЙ§ЛиЙіЃЌвдМАЛжИДЃЌКЭдкВЂЗЂЛЗОГЯТЕФИєРызіЕНвЛжТадЁЃ
| 







