| 编辑推荐: |
本文重点介绍了Adamic-Adar算法、Common
Neighbors、Preferential Attachment等相关内容。
本文来自简书,由火龙果软件Anna编辑、推荐。
|
|
链接预测是图数据挖掘中的一个重要问题。链接预测旨在预测图中丢失的边,
或者未来可能会出现的边。这些算法主要用于判断相邻的两个节点之间的亲密程度。通常亲密度越大的节点之间的亲密分值越高。
The Adamic Adar algorithm (algo.linkprediction
.adamicAdar)
Adamic Adar是一种基于节点之间共同邻居的亲密度测算方法。2003年由 Lada Adamic
和 Eytan Adar t在 predict links in a social network中提出的,计算亲密度的公式如下:
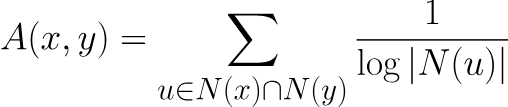
其中N(u)是与节点u相邻的节点集合。A(x,y)为0表明节点x和y不接近,该值越高表明两个节点间的亲密度越大。Neo4j-algo包提供了该算法的具体实现,下面我们可以看一个例子。
创建节点和边:
MERGE (zhen:Person
{name: "Zhen"})
MERGE (praveena:Person {name: "Praveena"})
MERGE (michael:Person {name: "Michael"})
MERGE (arya:Person {name: "Arya"})
MERGE (karin:Person {name: "Karin"})
MERGE (zhen)-[:FRIENDS]-(arya)
MERGE (zhen)-[:FRIENDS]-(praveena)
MERGE (praveena)-[:WORKS_WITH]-(karin)
MERGE (praveena)-[:FRIENDS]-(michael)
MERGE (michael)-[:WORKS_WITH]-(karin)
MERGE (arya)-[:FRIENDS]-(karin) |
创建完成之后的图结构如下:
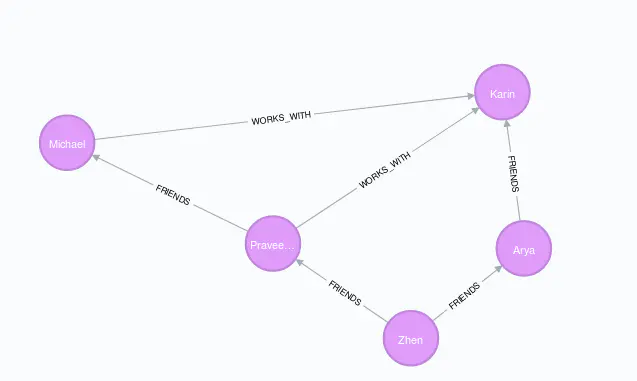
graph
计算两个指定节点之间的亲密度:
MATCH (p1:Person
{name: 'Michael'})
MATCH (p2:Person {name: 'Karin'})
RETURN algo.linkprediction.adamicAdar (p1, p2)
AS score |
计算结果如下所示:

score
另外,我们还可以基于特定的关系类型和关系指向,计算一对节点之间的亲密度。
MATCH (p1:Person
{name: 'Michael'})
MATCH (p2:Person {name: 'Karin'})
RETURN algo.linkprediction.adamicAdar(p1, p2,
{relationshipQuery: " FRIENDS",
direction: "BOTH"}) AS score |
计算结果如下:

score
Common Neighbors (algo.linkprediction
.commonNeighbors)
相同邻居,顾名思义,指的是两个节点同时关联的节点、数量。
计算公式如下:
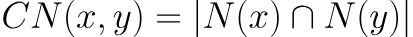
formula
其中N(x)是与节点x相邻的节点集合,N(y)是与节点y相邻的节点集合,相同邻居指的是两个集合的交集。该值越高表明两个节点之间亲密度越高。当节点x和节点y不相邻时,该值为0。
还使用上面的数据集合,则计算两个节点的相同邻居的代码如下:
MATCH (p1:Person
{name: 'Michael'})
MATCH (p2:Person {name: 'Karin'})
RETURN algo.linkprediction.commonNeighbors (p1,
p2) AS score |
结果如下:
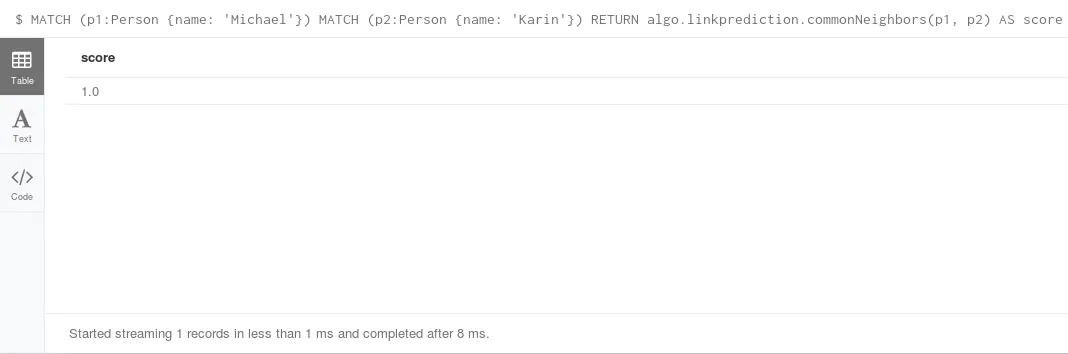
image.png
同样的,该度量方法也可以指定关系的类型和关系的方向,这里不再赘述。
Preferential Attachment (algo.linkprediction
.preferentialAttachment)
优先连接依赖于两个节点的连接数,如果两个节点的连接数都很大,标签该节点对被连接的概率越大。计算公式如下:
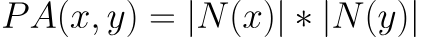
其中N(u)是与节点u相邻的节点集合。该值为0表明节点x和y不接近,该值越高表明两个节点间的亲密度越大。示例如下:
MATCH (p1:Person
{name: 'Michael'})
MATCH (p2:Person {name: 'Karin'})
RETURN algo.linkprediction.preferentialAttachment (p1,
p2) AS score |
Resource Allocation (algo.linkprediction
.resourceAllocation)
资源分配算法公式如下: 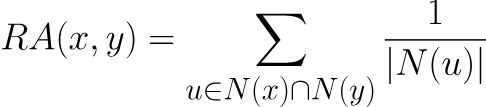
其中N(u)是与节点u相邻的节点集合。该值为0表明节点x和y不接近,该值越高表明两个节点间的亲密度越大。示例如下:
MATCH (p1:Person
{name: 'Michael'})
MATCH (p2:Person {name: 'Karin'})
RETURN algo.linkprediction.resourceAllocation (p1,
p2) AS score |
Total Neighbors (algo.linkprediction.totalNeighbors)
总邻居数指的是两个相邻节点之间的总邻居数,计算公式如下:
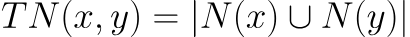
其中N(u)是与节点u相邻的节点集合。该值为0表明节点x和y不接近,该值越高表明两个节点间的亲密度越大。示例如下:
MATCH (p1:Person
{name: 'Michael'})
MATCH (p2:Person {name: 'Karin'})
RETURN algo.linkprediction.totalNeighbors (p1,
p2) AS score |
| 







