| Īŗľ≠Õ∆ľŲ: |
Īĺőń÷ų“™ľŘ…‹Ńň ¬őŮļÕ ¬őŮ“ż∑ĘĶńő Ő‚
, MVCC∂ŗįśĪĺ≤Ę∑ĘŅō÷∆£®“Ľ÷¬–‘∑«ňÝ∂®∂Ń£©, ––ňÝň„∑®£®“Ľ÷¬–‘ňÝ∂®∂Ń£©,ňņňÝő Ő‚Ķ»ŌŗĻōńŕ»›°£
Īĺőńņī◊‘ľÚ ť£¨”…ĽūŃķĻŻ»ŪľĢAnnaĪŗľ≠°ĘÕ∆ľŲ°£
|
|
InnoDB“ż«śĶń ¬őŮ”ŽňÝ
“Ľ. Ī≥ĺį£ļ ¬őŮļÕ ¬őŮ“ż∑ĘĶńő Ő‚
1. ACID
‘≠◊”–‘£ļĪŪ ĺ’ŻłŲ ¬őŮ «≤ĽŅ…∑÷łÓĶń£¨“™√ī∂ľ÷ī––≥…Ļ¶£¨“™√ī∂ľ÷ī–– ßį‹°£
“Ľ÷¬–‘£ļĪ£÷§ÕÍ’Ż–‘‘ľ Ý√Ľ”–ĪĽ∆∆ĽĶ°£
łŰņŽ–‘£ļ ¬őŮ≤ĽŅ…ľŻ––£¨ ¬őŮ”Ž ¬őŮ÷ģľš∑÷ņŽ≤ĽŅ…ľŻ°£
≥÷ĺ√–‘: ¬őŮ“ĽĶ©ŐŠĹĽ£¨∆šĹŠĻŻĺÕ «”ņĺ√–‘Ķń£¨ľī Ļ∑Ę…ķŚīĽķ£¨ żĺ›“≤ «Ņ…“‘Ľ÷łīĶń°£
2. ¬őŮĶń∑÷ņŗ
1. Ī‚∆Ĺ ¬őŮ
Ī‚∆Ĺ ¬őŮ « ¬őŮ÷–◊ÓľÚĶ•Ķń“Ľ÷÷£¨“≤ « Ļ”√◊Ó∆Ķ∑ĪĶń£¨‘ŕĪ‚∆Ĺ ¬őŮ÷–£¨ňý”–≤Ŕ◊ų∂ľī¶”ŕÕ¨“Ľ≤„īő£¨”…BEGINŅ™ ľ£¨COMMIT
ĽÚ’ŖROLLBACKĹŠ Ý£¨∆š≤Ŕ◊ų∂ľ «‘≠◊”–‘Ķń°£
2. īÝ”–Ī£īśĶ„ĶńĪ‚∆Ĺ ¬őŮ
‘ŕĪ‚∆Ĺ ¬őŮĶńĽýī°…Ō£¨‘Ųľ”ŃňĪ£īśĶ„, ‘ –ŪĽōĻŲĶĹÕ¨“Ľ ¬őŮ÷–ĹŌ‘ÁĶń“ĽłŲ◊īŐ¨£¨“Úő™‘ŕń≥–©≥°ĺį£¨∑Ň∆ķ’ŻłŲ ¬őŮĽŠņň∑—≤ĽĪō“™ĶńŅ™Ōķ£¨∂‘”ŕĪ‚∆Ĺ ¬őŮņīňĶ£¨“Ģ ĹĶń‘Ųľ”Ńň“ĽłŲĪ£īśĶ„£¨Ī£īśĶ„”√SAVE
WORKļĮ żĹ®ŃĘ£¨»Ľļů‘ŕ ¬őŮ÷– ÷Ľ”–’‚“ĽłŲĪ£īśĶ„£¨ Ī£īśĶ„ «“ņīőĶ›‘ŲĶń°£
3. Ńī ¬őŮ
Ņ…“‘Ņī◊ų «Ī£īśĶ„ń£ ĹĶńĪš÷÷£¨ĶĪŌĶÕ≥∑Ę…ķĪņņ£Ķń ĪļÚ£¨ňý”–ĶńĪ£īśĶ„∂ľĽŠŌŻ ߣ¨“Úő™Ī£īśĶ„ « “◊ ß(volatile)
ĶńļÕ ∑«≥÷ĺ√(persistent) Ķń£¨Ńī ¬őŮĶńňľŌŽ «£ļŐŠĹĽĶĪ«į ¬őŮļÕŅ™ ľŌ¬“ĽłŲ ¬őŮ≤Ŕ◊ųļŌ≤Ęő™“ĽłŲ‘≠◊”≤Ŕ◊ų£¨’‚“‚ő∂’‚Ō¬“ĽłŲ ¬őŮ «ń‹ŅīĶĹ…Ō“ĽłŲ ¬őŮĶńī¶ņŪĹŠĻŻĶń£¨»ÁÕľ
£ļ
4. «∂Ő◊ ¬őŮ
«∂Ő◊ ¬őŮ «“ĽłŲ≤„īőĹŠĻĻŅÚľ‹£¨InnoDBĪĺ ¬≤Ę≤Ľń‹ļ‹ļ√Ķń÷ß≥÷£¨“Úīň–Ť“™“ņ囫į√ś»ż÷÷ ¬őŮ£¨◊‘ľļ ĶŌ÷°£
«∂Ő◊ ¬őŮ”…“ĽłŲ∂•≤„ ¬őŮŅō÷∆◊ŇłųłŲ≤„īőĶń ¬őŮ£¨ĪĽ«∂Ő◊Ķń ¬őŮĪĽ≥∆ő™◊” ¬őŮ£¨»ÁÕľ£ļ
(1). «∂Ő◊ ¬őŮ « ¬őŮ◊ť≥…Ķń“ĽłŲ ų£¨◊” ųľ»Ņ…“‘ ««∂Ő◊ ¬őŮ£¨“≤Ņ…“‘ «Ī‚∆Ĺ ¬őŮ°£
(2). ī¶‘ŕ“∂◊”ĹŕĶ„Ķń ¬őŮ «Ī‚∆Ĺ ¬őŮ°£
(3). “∂◊”ĹŕĶ„Ķń…Ó∂»Ņ…“‘≤ĽÕ¨°£
(4). ◊” ¬őŮľ»Ņ…“‘ŐŠĹĽ“≤Ņ…“‘ĽōĻŲ£¨Ķę≤ĽĽŠŃʬŪ…ķ–ߣ¨“™Ķ»łł ¬őŮŐŠĹĽ£¨“Úīň∂•≤„ ¬őŮ «ňý”–◊” ¬őŮĶń«į÷√ ¬őŮ°£
(5). ų÷–Ķń»ő“‚łŲ ¬őŮĶńĽōĻŲĽŠ“ż∆ūňŁĶń◊” ¬őŮĶńĽōĻŲ£¨Ļ ◊” ¬őŮĹŲĪ£ŃŰA,C,IŐō–‘£¨≤ĽĺŖ”–DŐō–‘°£
∑÷≤ľ Ĺ ¬őŮ
Õ®≥£ «“ĽłŲ‘ŕ∑÷≤ľ ĹĽ∑ĺ≥Ō¬‘ň––ĶńĪ‚∆Ĺ ¬őŮ£¨“Ľį„∑÷ő™«Ņ“Ľ÷¬–‘ ¬őŮļÕ»Š“Ľ÷¬–‘ ¬őŮ£¨Ī»»ÁĽý”ŕXAĶń∂ĢĹ◊∂őŐŠĹĽĺÕ Ű”ŕ«Ņ“Ľ÷¬–‘ ¬őŮ£¨∂ÝĽý”ŕMQĽÚ’Ŗ≤Ļ≥•Ľķ÷∆Ķń∑÷≤ľ Ĺ ¬ő٠۔໊“Ľ÷¬–‘ ¬őŮ£¨Ľý”ŕBASEņŪ¬Ř£¨«Ņ“Ľ÷¬–‘ ¬őŮ“™Ī£÷§«Ņ“Ľ÷¬–‘£¨∂Ý»Š“Ľ÷¬–‘ ¬őŮĪ£÷§Ķń żĺ›Ķń◊Ó÷’“Ľ÷¬–‘£¨’‚ņÔ≤Ľ’ĻŅ™Ő÷¬Ř∑÷≤ľ Ĺ ¬őŮ£¨‘ŕ÷ģļůĶńőń’¬ĽŠ’ĻŅ™Ő÷¬Ř∑÷≤ľ Ĺ ¬őŮĶń≥£ľŻ ĶŌ÷ļÕ‘≠ņŪ°£
3. ¬őŮĶń ĶŌ÷
¬őŮĶń ĶŌ÷ “Ľį„“ņņĶ”ŕRedo log ļÕ Undo Log°£
1.Redo Log :
÷ō◊Ų»’÷ĺ «”√ņī ĶŌ÷ ¬őŮĶń≥÷ĺ√–‘£¨ľī ¬őŮACID÷–ĶńD°£∆š”…ŃĹ≤Ņ∑÷◊ť≥…£ļ“ĽłŲ «ńŕīś÷–Ķń÷ō◊Ų»’÷ĺĽļīś(redo
log buffer)£¨ňŁ «“◊ ßĶń£Ľ∂Ģ «÷ō◊Ų»’÷ĺőńľĢ(redo log file)£¨ «≥÷ĺ√Ķń°£
ĶĪ ¬őŮŐŠĹĽĶń ĪļÚ£¨Īō–ŽŌ»Ĺęł√ ¬őŮĶńňý”–»’÷ĺ–ī»ŽĶĹ÷ō◊Ų»’÷ĺőńľĢĹÝ––≥÷ĺ√ĽĮ£¨īżŐŠĹĽĶń ¬őŮCOMMIT≤Ňň„ÕÍ≥…°£÷ō◊Ų»’÷ĺłŮ Ĺ «Ľý”ŕ“≥Ķń£¨őńľĢľ«¬ľĶń «√Ņ“ĽłŲ ¬őŮ≤Ŕ◊ųĶńőÔņŪĶō÷∑ļÕ∆ę“∆ŃŅ£¨≤Ę≤Ľ «ľ«¬ľĶń żĺ›Īĺ…Ū£¨ĶĪ żĺ›Ņ‚ŚīĽķ÷ō∆Ű£¨ĺÕ «“ņņĶ”ŕ÷ō◊Ų»’÷ĺĽ÷łīĶń°£
’‚ņÔ”–“ĽłŲ”–“‚ňľĶńĶ„ « żĺ›Ņ‚IOĶń“≥“Ľį„∂ľ « 16K īů–°£¨∂Ýľ∆ň„ĽķIOĶń“≥“Ľį„ « 4K īů–°£¨Redo
log‘ŕ żĺ›Ņ‚ļÕĽķ∆ųÕ¨≤ĹĶń ĪļÚ£¨īś‘ŕIO–ī»ŽĶľ÷¬pageňūĽĶĶńő Ő‚£¨ő™ŃňĪ£÷§ żĺ›≤ĽĽŠ∂™ ߣ¨ĽŠ≤…”√Double
WriteĶńňľŌŽ£¨Double Write’‚ņÔ≤Ľ◊ŲĻż∂ŗ–ū Ų£¨ł––ň»§Ķń–°ĽÔįťŅ…“‘»•≤ť‘ńŌ¬ŌŗĻō◊ ŃŌ°£
2.Undo Log :
undo logĺÕ «įÔő“√«Ĺ‚ĺŲ ¬őŮĽōĻŲĶńĻ¶ń‹£¨”Žredo log≤ĽÕ¨Ķń «£¨ undo logīś∑Ň‘ŕ żĺ›Ņ‚ńŕ≤ŅĶń“ĽłŲŐō ‚∂ő÷–£¨őĽ”ŕĻ≤ŌŪĪŪŅ’ľš°£
undo log∑÷ő™ insert undo log ļÕ update undo log£¨insert
ĺÕ «‘ŕ≤Ś»Ž żĺ›Ķń ĪļÚ≤ķ…ķĶń undo log £¨÷Ľ∂‘◊‘…Ū ¬őŮŅ…ľŻ£¨∂‘∆šňŻ ¬őÔ≤ĽŅ…ľŻ£Ľ∂Ý update
undo logľ«¬ľĶń «∂‘update ļÕ delete≤Ŕ◊ų≤ķ…ķĶń undo log£¨ł√logŅ…ń‹–Ť“™ŐŠĻ©MVCCĽķ÷∆(Ō¬√śĽŠňĶĶĹ)£¨“Úīň≤Ľń‹‘ŕ ¬őŮŐŠĹĽĶń ĪļÚĺÕ…ĺ≥ż£¨ŐŠĹĽĶń ĪļÚ∑ŇĶĹ
undo logŃīĪŪ£¨Ķ»īżpurgeŌŖ≥ŐĹÝ––◊ÓļůĶń…ĺ≥ż°£
purgeŌŖ≥Ő÷™ ∂£ļ
3. ¬őŮ“ż∑ĘĶńő Ő‚£ļ
1.‘ŗ∂Ń£ļ
÷ł“ĽłŲ ¬őŮ∂Ń»°ŃňŃŪÕ‚“ĽłŲ ¬őŮőīŐŠĹĽĶń żĺ›°£
| ¬őŮ“Ľ |
¬őŮ∂Ģ |
| select * from
user; //≤ť≥Ųidő™1Ķń żĺ› |
|
| |
insert into user(id,name)
values (2,°ģcoco°Į); |
| select * from
user; //≤ť≥Ųidő™1 ļÕ 2 Ķń żĺ› |
|
| |
ROLLBACK |
| select * from
user; //≤ť≥Ųidő™1 |
|
2. ≤ĽŅ…÷ōłī∂Ń£ļ
‘ŕ“ĽłŲ ¬őŮńŕ∂Ń»°ĪŪ÷–Ķńń≥“Ľ–– żĺ›£¨∂ŗīő∂Ń»°ĹŠĻŻ≤ĽÕ¨°££®’‚łŲ≤Ľ“Ľ∂® «īŪőů£¨÷Ľ «ń≥–©≥°ļŌ≤Ľ∂‘£©
| ¬őŮ“Ľ |
¬őŮ∂Ģ |
| select * from
user; //≤ť≥Ųid=1,name='leeco°ĮĶń żĺ› |
|
| |
update user set
name=°ģleeco2°Į where id = 1; |
| |
COMMIT |
| select * from
user; //≤ť≥Ųid=1,name='leeco°ĮĶń żĺ› |
|
3.Ľ√∂Ń£ļ
«÷ł‘ŕ“ĽłŲ ¬őŮńŕ∂Ń»°ĶĹŃňĪūĶń ¬őŮ≤Ś»ŽĶń żĺ›£¨Ķľ÷¬«įļů∂Ń»°≤Ľ“Ľ÷¬(łŁ∆ęŌÚ”ŕ żŃŅ)
| ¬őŮ“Ľ |
¬őŮ∂Ģ |
| select * from
user; //≤ť≥Ųidő™1Ķń żĺ› |
|
| |
insert into user(id,name)
values(2,°ģcoco°Į); |
| |
COMMIT |
| select * from
user; //≤ť≥Ųidő™1 ļÕ 2 Ķń żĺ› |
|
∂Ģ. MVCC∂ŗįśĪĺ≤Ę∑ĘŅō÷∆£®“Ľ÷¬–‘∑«ňÝ∂®∂Ń£©
ńŅĶń : Ĺ‚ĺŲ“Ľ÷¬–‘Ķń∑«ňÝ∂®∂Ń ≥∆ő™Ņž’’∂Ń
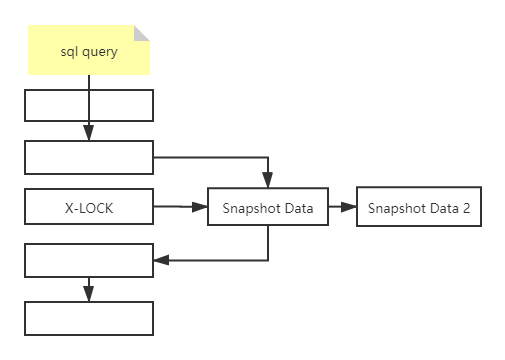
ł√Õľ÷ĪĻŘĶń’Ļ ĺŃň∑«ňÝ∂®∂Ń£¨÷ģňý“‘≥∆ő™≤ĽňÝ∂®∂Ń£¨ «“Úő™≤Ľ–Ť“™Ķ»īż––X(ŇŇňŻ)ňÝĶń Õ∑Ň°£Ņž’’ żĺ› «÷łł√––÷ģ«įįśĪĺĶń żĺ›£¨ł√ ĶŌ÷ «”…undo∂őņīÕÍ≥…Ķń°£∂Ýundo”√ņī‘ŕ ¬őŮ÷–ĽōĻŲ żĺ›£¨“Úő™Ņž’’ żĺ›Īĺ…Ū≤Ę√Ľ”–∂ÓÕ‚ĶńŅ™Ōķ°£īňÕ‚£¨∂Ń»°Ņž’’ żĺ› «≤Ľ–Ť“™…ŌňÝĶń£¨“Úő™√Ľ”– ¬őŮ–Ť“™∂‘ņķ ∑Ķń żĺ›ĹÝ–––řłń≤Ŕ◊ų°£
ÕÝ…Ō”…ļ‹∂ŗ»ňį—ňŁņŪĹ‚ő™“Ģ ĹĶń‘ŕ√Ņ––ľ«¬ľļů√śĪ£īśŃĹłŲ“Ģ≤ōĶńŃ–ņī ĶŌ÷£ļ“ĽłŲĪ£īśŃňīīĹ®ł√––Ķń ¬őŮID£¨“ĽłŲĪ£īś…ĺ≥żł√––Ķń ¬őŮID£¨ňš»Ľ’‚łŲĶ„ļ√ŌŮ≤Ę√Ľ”–ĻŔ∑ĹňĶ√ų£¨Ķę «’‚√ī»•ņŪĹ‚MVCCĽŠłŁ»›“◊“Ľ–©£¨ņż»Á
| id |
name |
īīĹ®ID |
…ĺ≥żID |
| 1 |
leeco |
3 |
null |
īň Ī£¨ ¬őŮ“Ľ≤ť—Į≥ŲņīĶń÷Ľ”–ID=1Ķń żĺ›£¨»Ľļů ¬őŮ∂Ģinsert“ĽŐűID=2Ķń żĺ›
| id |
name |
īīĹ®ID |
…ĺ≥żID |
| 1 |
leeco |
3 |
null |
| 2 |
leeco |
4 |
null |
’‚łŲ ĪļÚ ¬őŮ“Ľ≤ť—ĮĶń ĪļÚ ÷ĽĽŠ≤ť’“ ¬őŮID<=3Ķń żĺ›£¨“Úīň≤ĽĽŠ≤ť≥Ųņīľ«¬ľID=2Ķń żĺ›°£
–Ť“™◊Ę“‚“ĽĶ„£¨update≤Ŕ◊ųInnoDB∆š Ķ «Ō»…ĺ≥ż£¨»Ľļů–¬‘Ų£¨
ņż»Á update user set name = °ģcoco°Į
where id = 2; »ÁŌ¬:
| id |
name |
īīĹ®ID |
…ĺ≥żID |
| 1 |
leeco |
3 |
null |
| 2 |
leeco |
4 |
5 |
| 2 |
leeco |
5 |
null |
“Úīň£¨∑«ňÝ∂®∂ŃīůīůŐŠłŖŃň≤Ę∑Ę–‘°£Ķę «‘ŕ≤ĽÕ¨Ķń ¬őŮłŰņŽľ∂ĪūŌ¬£¨∂Ń»°Ķń∑Ĺ Ĺ «≤ĽÕ¨Ķń£¨‘ŕń¨»ŌĶńŅ…÷ōłī∂Ń(Repeatable
Read)ľ∂ĪūŌ¬£¨◊‹ «∂Ń»°Ņž’’ĶńŅ™ ľ ĪļÚĶńįśĪĺ£¨∂Ý‘ŕ∂Ń“—ŐŠĹĽ(Read Committed)Ķńľ∂ĪūŌ¬£¨◊‹ «∂Ń»°◊Ó–¬ĶńŅž’’įśĪĺ£¨“Úīň∂Ń“—ŐŠĹĽĽŠ≥ŲŌ÷Ľ√∂ŃĶńő Ő‚°£
MVCCĹ‚ĺŲŅž’’∂ŃĶńĽ√∂Ńő Ő‚ : ’Ž∂‘”ŽMVCC «∑Ůń‹Ĺ‚ĺŲĽ√∂ŃĶńő Ő‚£¨ «īś‘ŕ’ý“ťĶń£¨ĺÝīů∂ŗ ż»ň»Ōő™ «Ņ…“‘Ĺ‚ĺŲĽ√∂ŃĶń£¨…Ŕ ż»ň»Ōő™őř∑®Ĺ‚ĺŲĽ√∂Ń£¨Ō¬ņż“ż∑ĘňľŅľ£ļ
ľŔ…Ť £ļŌ÷‘ŕuserĪŪ”–1Őű żĺ›
Ō÷‘ŕ◊Ų»ÁŌ¬≤Ŕ◊ų£ļ
| ¬őŮ“Ľ |
¬őŮ∂Ģ |
| select * from
user; //≤ť≥Ųidő™1Ķń żĺ› |
|
| |
insert into user(id,name)
values(2,°ģcoco°Į); |
| select * from
user; //≤ť≥Ųidő™1Ķń żĺ› |
|
| update user set
name=°ģcoco°Į where id=2; |
|
| select * from
user; //≤ť≥Ųidő™1 ļÕ 2 Ķń żĺ› |
|
ňľŅľ£ļ’‚÷÷«ťŅŲĶĹĶ◊ň„≤Ľň„Ľ√∂Ńő Ő‚? Ľ∂”≠∆ņ¬Ř
»ż. ––ňÝň„∑®£®“Ľ÷¬–‘ňÝ∂®∂Ń£©
ňÝň„∑®∂ľ «Ľý”ŕňų“żĶń,«“ňÝĶńĺÕ «ňų“żĪĺ…Ū£¨∂ÝInnoDBń¨»Ō Ļ”√Ķń «next-key Lock
“‘Ō¬ńŕ»› ∑«Őō ‚«ťŅŲ ∂ľ «Ľý”ŕń¨»ŌĶńŅ…÷ōłī∂ŃĶńłŰņŽľ∂Īū’ĻŅ™ňĶ√ų
Īĺ’¬Ĺŕ≤Ľ∂‘ĪŪňÝĹÝ––Ő÷¬Ř
| |
Ļ≤ŌŪňÝ(S) |
ŇŇňŻňÝ(X) |
| Ļ≤ŌŪňÝ(S) |
ľś»› |
≤Ľľś»› |
| ŇŇňŻňÝ(X) |
≤Ľľś»› |
≤Ľľś»› |
“Ľ÷¬–‘ňÝ∂®∂Ń£¨ «Ō‘ Ĺ‘ŕSELECTĶń ĪļÚľ”ňÝ“‘Ī£÷§ żĺ›¬Ŗľ≠Ķń“Ľ÷¬–‘£¨∂Ý’‚“™«ů∂‘≤Ŕ◊ų––ĹÝ––ľ”ňÝ”Ô∑®
SELECT °≠ FOR UPDATE; ľ”“ĽłŲXňÝ£¨īň Ī∆šňŻ ¬őŮ≤Ľń‹◊Ų»őļő≤Ŕ◊ų
SELECT °≠ LOCK IN SHARE MODE£Ľľ”“ĽłŲSňÝ£¨īň Ī∆šňŻ ¬őŮŅ…“‘ľ”SňÝ£¨Ķę «ľ”XňÝĽŠĪĽ◊Ť»Ż
1. ľšŌ∂ňÝ(Gap Lcok)
ňÝ∂®“Ľ∂®Ķń∑∂őߣ¨Ķę≤ĽįŁļ¨Īĺ…Ū (◊ůŅ™”“Ņ™)
2. ŃŔľŁňÝ(Next-Key Lock)
ňÝ∂®“Ľ∂®Ķń∑∂őߣ¨≤Ę«“ňÝ◊°Īĺ…Ū ľīGapLock + Record Lock (◊ůŅ™”“Ī’)
3. ľ«¬ľňÝ(Record Lock)
ňÝ∂®Ķ•––ľ«¬ľ
Ī»»Á żĺ›ľ«¬ľ 1£¨5£¨9£¨Record LockňÝ◊°ĶńĺÕ «1£¨5£¨9£¨Gap LcokňÝ◊°Ķń «(-°ř,1),(1,5),(5,9),(9,+°ř)£¨
Next-Key LockňÝ◊°Ķń « (-°ř,1], (1,5], (5,9], (9,+°ř]
◊Ę“‚Ńň£¨’‚ņÔĹŲ’Ž∂‘RRłŰņŽľ∂Īū£¨∂‘”ŕRCłŰņŽľ∂≥żŃňÕ‚ľŁ‘ľ ÝļÕő®“Ľ–‘‘ľ ÝĽŠľ”ľšŌ∂ňÝ£¨√Ľ”–ľšŌ∂ňÝ£¨◊‘»Ľ“≤ĺÕ√Ľ”–ŃňŃŔľŁňÝ£¨ňý“‘RCľ∂ĪūŌ¬ľ”Ķń––ňÝ∂ľ «ľ«¬ľňÝ£¨√Ľ”–√Ł÷–ľ«¬ľ‘Ú≤Ľľ”ňÝ£¨ňý“‘RCľ∂Īū «√Ľ”–Ĺ‚ĺŲĽ√∂Ńő Ő‚Ķń°£
ń«√ī’‚»ż÷÷ňÝ∑÷Īū‘ŕ ≤√ī ĪļÚ…ķ–ßńō£¨ ◊Ō»£¨––ňÝ «Ľý”ŕňų“żĶń£¨InnoDBń¨»Ō «Ķń≤…”√Next-Key
LockňÝň„∑®, ņż»Á…Ōņż£¨
ĶĪ SELECT °≠ WHERE ID = 5; Ķń ĪļÚ£¨»ŰID∑«ňų“ż£¨‘ÚÕňĽĮ≥…ĪŪňÝ£Ľ»ÁĻŻID «ł®÷ķňų“ż£¨‘ÚĽŠ∂‘«į“ĽłŲ«Ý”Ú Ļ”√ŃŔľŁňÝ£¨ľīňÝ◊°Ńň
(1,5] £¨»Ľļů∂‘Ō¬“ĽłŲ«Ý”Ú Ļ”√ľšŌ∂ňÝ£¨ľīňÝ◊°Ńň(5,9)£¨◊‹ĹŠĺÕ «ňÝ◊°Ńň(1,9); ÷Ľ”–ĶĪID «∑«Ņ’ő®“Ľňų“żĶń ĪļÚ£¨ĽŠ…żľ∂ő™ľ«¬ľňÝ(Record
Lock), ÷ĽňÝ◊°ID=5Ķń’‚“Ľ––ľ«¬ľĶńňų“ż°£
◊Ę“‚£ļňš»ĽID «∑«Ņ’ő®“Ľňų“ż£¨Ķę «ĶĪ≤ť—ĮŐűľĢ «∑∂őß≤ť—ĮĶń ĪļÚ “≤ĽŠÕňĽĮő™ŃŔľŁňÝ°£
ņż»Á…Ōņż÷–£¨select * from id > 6; īň Ī ÷Ľń‹≤ť≥ŲņīID=9Ķń żĺ›£¨»ĽļůŐŪľ”“ĽŐűID=10Ķń żĺ›£¨»ÁĻŻ√Ľ”–ŃŔľŁňÝ£¨‘ÚŌ¬īő≤ť—ĮĽŠ≤ť≥ŲņīID=9ļÕID=10ŃĹŐű żĺ›£¨ĺÕ≥ŲŌ÷ŃňĽ√∂Ń°£∂Ý’ś ««ťŅŲ «£ļ“Úő™ «∑∂őß≤ť’“£¨InnoDB≤…”√ŃŔľŁňÝ£¨īň ĪĽŠ∂‘(6,9]ļÕ(9,+°ř)∑∂őßĹÝ––ľ”ňÝ,
īň Ī≤Ś»ŽID=10Ķń żĺ›ĽŠĪĽ◊Ť»Ż£¨ňý“‘≤ĽĽŠ≥ŲŌ÷Ľ√∂Ń.
“Úīň ‘ŕĶĪ«į∂ŃĶńĽ∑ĺ≥Ō¬ ŃŔľŁňÝĹ‚ĺŲŃňĽ√∂Ńő Ő‚°£
ňń. ňņňÝő Ő‚
ňņňÝ «÷łŃĹłŲĽÚŃĹłŲ“‘…ŌĶń ¬őŮ‘ŕ÷ī––Ļż≥Ő÷–£¨“Úő™«ņ∂Š◊ ‘ī∂Ý‘ž≥…Ķń“Ľ÷÷Ľ•ŌŗĶ»īżĶńŌ÷Ōů°£
| ¬őŮ“Ľ |
¬őŮ∂Ģ |
| select * from
user where id = 1 for update |
|
| |
select * from
user where id = 2 for update |
| update user set
name=°ģleeco°Į where id=2 |
|
| |
update user set
name=°ģleeco°Į where id=1 |
”…”ŕ ¬őŮ“ĽĶ»īż ¬őŮ∂Ģ Õ∑ŇID=2ĶńňÝ£¨∂Ý ¬őŮ∂ĢĶ»īż ¬őŮ“Ľ Õ∑ŇID=1ĶńňÝ£¨“Úīň‘ž≥…Ľ•ŌŗĶ»īż£¨–ő≥…ňņňÝ°£
Ĺ‚ĺŲňņňÝĶń∑Ĺ Ĺ◊ÓľÚĶ•Ķń «≥¨ Ī£¨ĶĪ≥¨ĻżĶ»īż Īľš ‘ÚĹÝ––ĽōĻŲ£Ľ
ĽĻ”–“Ľ÷÷∆’ĪťĶń∑Ĺ ĹĺÕ «≤…”√ wait-for graph(Ķ»īżÕľ) ,“™«ů żĺ›Ņ‚Ī£īśŃĹ÷÷–ŇŌĘ: ňÝĶń–ŇŌĘŃīĪŪ£¨ ¬őŮĶ»īżŃīĪŪ£¨
Õ®Ļż…Ō ŲŃīĪŪŅ…“‘ĻĻ‘ž≥Ų“Ľ’ŇÕľ£¨»Áīś‘ŕĽō¬∑£¨‘ÚĪŪ ĺīś‘ŕňņňÝő Ő‚£¨»ÁÕľ£ļ
őŚ. ◊‹ĹŠ£ļ
1. InnoDB Õ®Ļż MVCC ļÕ NEXT-KEY LOCK£¨Ĺ‚ĺŲŃň‘ŕŅ…÷ōłī∂ŃĶń ¬őŮłŰņŽľ∂ĪūŌ¬≥ŲŌ÷Ľ√∂ŃĶńő Ő‚°£
2. ľī ĻInnoDBń¨»Ō «≤…”√Ņ…÷ōłī∂ŃĶń ¬őŮłŰņŽľ∂Īū£¨Ķę «’ż «”…”ŕMVCCļÕŃŔľŁňÝĶńīś‘ŕ£¨Ĺ‚ĺŲŃňĽ√∂ŃĶńő Ő‚£¨“Úīň“—ĺ≠īÔĶĹŃňīģ––ĽĮĶńłŰņŽľ∂Īū°£
| 







