| БрМЭЦМі: |
дрЪ§ОнЖдЪ§ОнМЦЫуЕФе§ШЗадДјРДСЫКмбЯжиЕФгАЯьЁЃвђДЫЃЌЮвУЧашвЊЬНЫївЛжжЗНЗЈЃЌФмЙЛЪЕЯжSparkаДШыElasticsearchЪ§ОнЕФПЩППадгые§ШЗадЁЃ
БОЮФРДinfoqЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
ИХЪі
SparkгыElasticsearchЃЈesЃЉЕФНсКЯЃЌЪЧНќФъРДДѓЪ§ОнНтОіЗНАИКмЛ№ШШЕФвЛИіЛАЬтЁЃвЛИіЪЧГіЩЋЕФЗжВМЪНМЦЫув§ЧцЃЌСэвЛИіЪЧГіЩЋЕФЫбЫїв§ЧцЁЃНќФъРДЃЌдНРДдНЖрЕФГЩЪьЗНАИТфЕиЕНаавЕВњЦЗжаЃЌАќРЈЮвУЧЖњЪьФмЯъЕФSpark+ES+HBaseШежОЗжЮіЦНЬЈЁЃ
ФПЧАЃЌЛЊЮЊдЦЪ§ОнКўЬНЫїЃЈDLIЃЉЗўЮёвбШЋУцжЇГжSpark/FlinkПчдДЗУЮЪElasticsearchЁЃЖјжЎЧАдкЪЕЯжЙ§ГЬжавВгіЕНЙ§КмЖрГЁОАЛЏЮЪЬтЃЌБОЮФНЋЬєбЁЦфжаБШНЯОЕфЕФЗжВМЪНвЛжТадЮЪЬтНјааЬНЬжЁЃ
ЗжВМЪНвЛжТадЮЪЬт
ЮЪЬтУшЪі
Ъ§ОнШнДэЪЧДѓЪ§ОнМЦЫув§ЧцУцСйЕФжївЊЮЪЬтжЎвЛЁЃФПЧАЃЌжїСїЕФПЊдДДѓЪ§ОнБШШчApache SparkКЭApache
FlinkвбОЭъШЋЪЕЯжСЫExactly OnceгявхЃЌБЃжЄСЫФкВПЪ§ОнДІРэЕФе§ШЗадЁЃЕЋЪЧдкНЋМЦЫуНсЙћаДШыЕНЭтВПЪ§ОндДЪБЃЌвђЮЊЭтВПЪ§ОндДМмЙЙгыЗУЮЪЗНЪНЕФЖрбљадЃЌЪМжеУЛФмевЕНвЛИіЭГвЛЕФНтОіЗНАИРДБЃжЄвЛжТадЃЈЮвУЧГЦЮЊSinkЫузгвЛжТадЮЪЬтЃЉЁЃдйМгЩЯesБОЩэУЛгаЪТЮёДІРэЕФФмСІЃЌвђДЫШчКЮБЃжЄаДШыesЪ§ОнвЛжТадГЩЮЊСЫШШЕуЛАЬтЁЃ
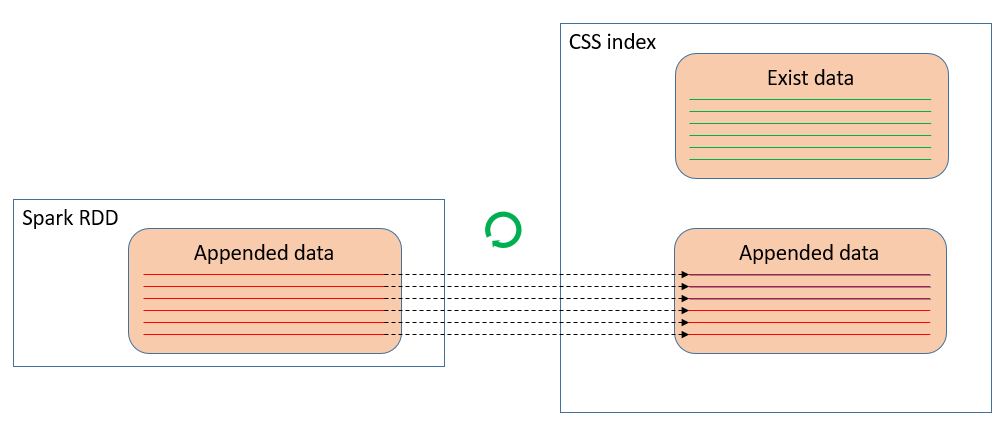
ЮвУЧОйвЛИіМђЕЅЕФР§згРДЫЕУївЛЯТЃЌЭМ1дкSparkRDDжаЃЈетРяМйЩшЪЧвЛИіtaskЃЉЃЌУПвЛЬѕРЖЩЋЕФЯпДњБэ100ЭђЬѕЪ§ОнЃЌФЧУД10ЬѕРЖЩЋЕФЯпБэЪОСЫга1000ЭђЬѕЪ§ОнзМБИаДШыЕНCSSЃЈЛЊЮЊдЦЫбЫїЗўЮёЃЌФкВПЮЊesЃЉЕФФГИіindexжаЁЃдкаДШыЙ§ГЬжаЃЌЯЕЭГЗЂЩњСЫЙЪеЯЃЌЕМжТжЛгавЛАыЃЈ500ЭђЬѕЃЉЪ§ОнГЩЙІаДШыЁЃ
taskЪЧSparkжДааШЮЮёЕФзюаЁЕЅдЊЃЌШчЙћtaskЪЇАмСЫЃЌЕБЧАtaskашвЊећИіжиаТжДааЁЃЫљвдЃЌЕБЮвУЧжиаТжДаааДШыВйзїЃЈЭМ2ЃЉЃЌВЂзюжежиЪдГЩЙІжЎКѓЃЈетДЮгУКьЩЋРДБэЪОЯрЭЌЕФ1000ЭђЬѕЪ§ОнЃЉЃЌЩЯвЛДЮЪЇАмСєЯТЕФ500ЭђЬѕЪ§ОнвРШЛДцдкЃЈРЖЩЋЕФЯпЃЉЃЌБфГЩдрЪ§ОнЁЃдрЪ§ОнЖдЪ§ОнМЦЫуЕФе§ШЗадДјРДСЫКмбЯжиЕФгАЯьЁЃвђДЫЃЌЮвУЧашвЊЬНЫївЛжжЗНЗЈЃЌФмЙЛЪЕЯжSparkаДШыesЪ§ОнЕФПЩППадгые§ШЗадЁЃ
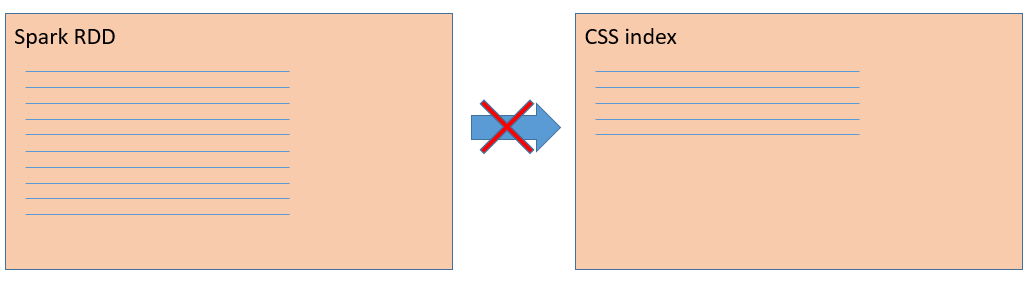
ЭМ1 Spark taskЪЇАмЪБЯђesаДШыСЫВПЗжЪ§Он
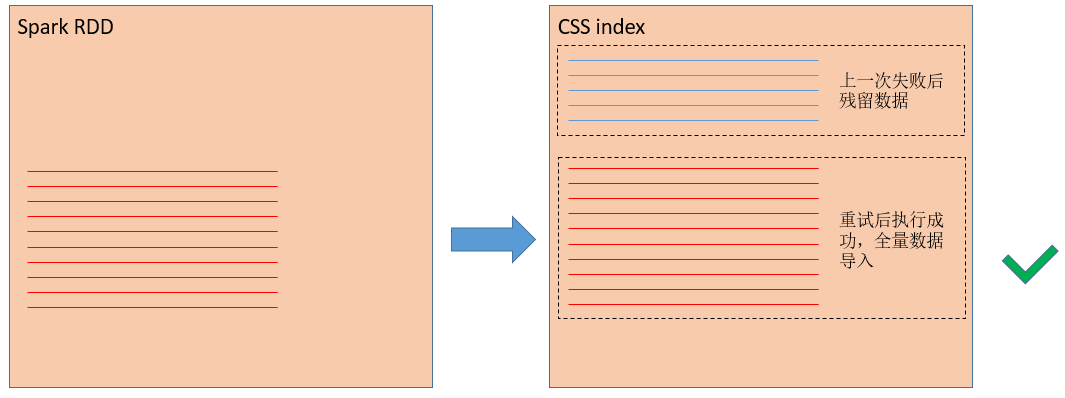
ЭМ2 taskжиЪдГЩЙІКѓЩЯвЛДЮаДШыЕФВПЗжЪ§ОнГЩЮЊдрЪ§Он
НтОіЗНАИ
1.аДИВИЧ
ДгЩЯЭМжаЃЌЮвУЧПЩвдКмжБЙлЕФПДГіРДЃЌУПДЮtaskВхШыЪ§ОнЧАЃЌЯШНЋesЕФindexжаЕФЪ§ОнЖМЧхПеОЭПЩвдСЫЁЃФЧУДЃЌУПДЮаДШыВйзїПЩвдПДГЩЪЧвдЯТ3ИіВНжшЕФзщКЯЃК
ВНжшвЛ ХаЖЯЕБЧАindexжаЪЧЗёгаЪ§Он
ВНжшЖў ЧхПеЕБЧАindexжаЕФЪ§Он
ВНжшШ§ ЯђindexжааДШыЪ§Он
ЛЛвЛжжНЧЖШЃЌЮвУЧПЩвдРэНтЮЊЃЌВЛЙмжЎЧАЪЧЗёжДааСЫЪ§ОнаДШыЃЌвВВЛЙмжЎЧАЪ§ОнаДШыСЫЖрЩйДЮЃЌЮвУЧжЛЯывЊБЃжЄЕБЧАетвЛДЮаДШыФмЙЛЖРСЂЧве§ШЗЕиЭъГЩЃЌетжжЫМЯыЮвУЧГЦЮЊУнЕШЁЃ
УнЕШЪНаДШыЪЧДѓЪ§ОнsinkЫузгНтОівЛжТадЮЪЬтЕФвЛжжГЃМћЫМТЗЃЌСэвЛжжЫЕЗЈНазізюжевЛжТадЃЌЦфжазюМђЕЅЕФзіЗЈОЭЪЧЁАinsert
overwriteЁБЁЃЕБSparkЪ§ОнаДШыesЪЇАмВЂГЂЪджиаТжДааЕФЪБКђЃЌРћгУИВИЧЪНаДШыЃЌПЩвдНЋindexжаЕФВаСєЪ§ОнИВИЧЕєЁЃ
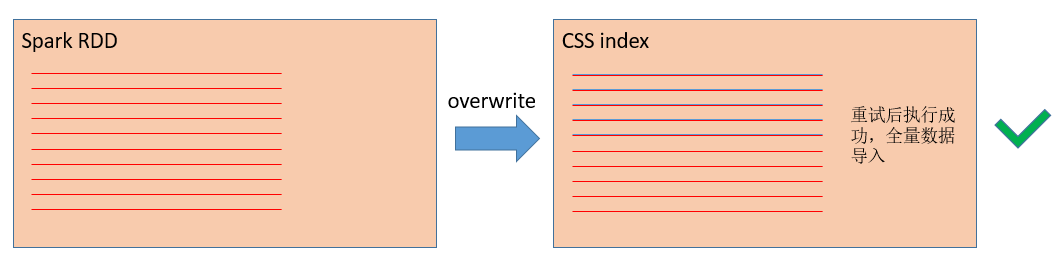
ЭМ ЪЙгУoverwriteФЃЪНЃЌtaskжиЪдЪБИВИЧЩЯвЛДЮЪ§Он
дкDLIжаЃЌПЩвддкDataFrameНгПкРяНЋmodeЩшжУГЩЁАoverwriteЁБРДЪЕЯжИВИЧаДesЃК
val dfWriter
= sparkSession.createDataFrame(rdd, schema)
//
// аДШыЪ§ОнжСes
//
dfWriter.write
.format("es")
.option("es.resource", resource)
.option("es.nodes", nodes)
.mode(SaveMode.Overwrite)
.save()
|
вВПЩвджБНгЪЙгУsqlгяОфЃК
// ВхШыЪ§ОнжСes
sparkSession.sql ("insert overwrite table
es_table values (1, 'John'),(2, 'Bob')") |
2.зюжевЛжТад
РћгУЩЯЪіЁАoverwriteЁБЕФЗНЪННтОіШнДэЮЪЬтгавЛИіКмДѓЕФШБЯнЁЃШчЙћesвбОДцдкСЫе§ШЗЕФЪ§ОнЃЌетДЮжЛЪЧашвЊзЗМгаДШыЁЃФЧУДoverwriteЛсАбжЎЧАindexЕФе§ШЗЕФЪ§ОнЖМИВИЧЕєЁЃ
БШШчЫЕЃЌгаЖрИіtaskВЂЗЂжДаааДШыЪ§ОнЕФВйзїЃЌЦфжавЛИіtaskжДааЪЇАмЖјЦфЫћtaskжДааГЩЙІЃЌжиаТжДааЪЇАмЕФtaskНјааЁАoverwriteЁБЛсНЋЦфЫћвбОГЩЙІаДШыЕФЪ§ОнИВИЧЕєЁЃдйБШШчЫЕЃЌStreamingГЁОАжаЃЌУПвЛХњДЮЪ§ОнаДШыЖМБфГЩИВИЧЃЌетЪЧВЛКЯРэЕФЗНЪНЁЃ

ЭМ SparkзЗМгЪ§ОнаДШыes

ЭМ гУoverwriteаДШыЛсНЋдЯШе§ШЗЕФЪ§ОнИВИЧЕє
ЦфЪЕЃЌЮвУЧЯызіЕФЪТЧщЃЌжЛЪЧЧхРэдрЪ§ОнЖјВЛЪЧЫљгаindexжаЕФЪ§ОнЁЃвђДЫЃЌКЫаФЮЪЬтБфГЩСЫШчКЮЪЖБ№дрЪ§ОнЃПНшМјЦфЫћЪ§ОнПтНтОіЗНАИЃЌЮвУЧЫЦКѕПЩвдевЕНЗНЗЈЁЃдкMySQLжаЃЌгавЛИіinsert
ignore intoЕФгяЗЈЃЌШчЙћгіЕНжїМќГхЭЛЃЌФмЙЛЕЅЕЅЖдетвЛааЪ§ОнНјааКіТдВйзїЃЌЖјШчЙћУЛгаГхЭЛЃЌдђНјааЦеЭЈЕФВхШыВйзїЁЃетбљОЭПЩвдНЋИВИЧЪ§ОнЕФСІЖШЯИЛЏЕНСЫааМЖБ№ЁЃ
esжагаРрЫЦЕФЙІФмУДЃПМйШчesжаУПвЛЬѕЪ§ОнЖМгажїМќЃЌжїМќГхЭЛЪБПЩвдНјааИВИЧЃЈКіТдКЭИВИЧЦфЪЕЖМФмНтОіетИіЮЪЬтЃЉЃЌФЧУДдкtaskЪЇАмжиЪдЪБЃЌОЭПЩвдНіеыЖддрЪ§ОнНјааИВИЧЁЃ
ЮвУЧЯШРДПДвЛЯТElasticsearchжаЕФИХФюгыЙиЯЕаЭЪ§ОнПтжЎМфЕФвЛжжЖдееЙиЯЕЃК

ЮвУЧжЊЕРЃЌMySQLжаЕФжїМќЪЧЖдгквЛааЪ§ОнЃЈRowЃЉЕФЮЈвЛБъЪЖЁЃДгБэжаПЩвдПДЕНЃЌRowЖдгІЕФОЭЪЧesжаЕФDocumentЁЃФЧУДЃЌDocumentгаУЛгаЮЈвЛЕФБъЪЖФиЃП
Д№АИЪЧПЯЖЈЕФЃЌУПвЛИіDocumentЖМгавЛИіidЃЌМДdoc_idЁЃdoc_idЪЧПЩХфжУЕФЃЌindexЁЂtypeЁЂdoc_idШ§епжИЖЈСЫЮЈвЛЕФвЛЬѕЪ§ОнЃЈDocumentЃЉЁЃВЂЧвЃЌдкВхШыesЪБЃЌindexЁЂtypeЁЂdoc_idЯрЭЌЃЌдЯШЕФdocumentЪ§ОнНЋЛсБЛИВИЧЕєЁЃвђДЫЃЌdoc_idПЩвдЕШаЇгкЁАMySQLжїМќГхЭЛКіТдВхШыЁБЙІФмЃЌМДЁАdoc_idГхЭЛИВИЧВхШыЁБЙІФмЁЃ
вђДЫЃЌDLIЕФSQLгяЗЈжаЬсЙЉСЫХфжУЯюЁАes.mapping.idЁБЃЌПЩвджИЖЈвЛИізжЖЮзїЮЊDocument
idЃЌР§ШчЃК
create table
es_table(id int, name string) using es options(
'es.nodes' 'localhost:9200',
'es.resource' '/mytest/anytype',
'es.mapping.id' 'id')") |
етРяжИЖЈСЫзжЖЮЁАidЁБзїЮЊesЕФdoc_idЃЌЕБВхШыЪ§ОнЪБЃЌзжЖЮЁАidЁБЕФжЕНЋГЩЮЊВхШыDocumentЕФidЁЃжЕЕУзЂвтЕФЪЧЃЌЁАidЁБЕФжЕвЊЮЈвЛЃЌЗёдђЯрЭЌЕФЁАidЁБНЋЛсЪЙЪ§ОнБЛИВИЧЁЃ
етЪБЃЌШчЙћгіЕНзївЕЛђепtaskЪЇАмЕФЧщПіЃЌжБНгжиаТжДааМДПЩЁЃЕБзюжезївЕжДааГЩЙІЪБЃЌesжаНЋВЛЛсГіЯжВаСєЕФдрЪ§ОнЃЌМДЪЕЯжСЫзюжевЛжТадЁЃ
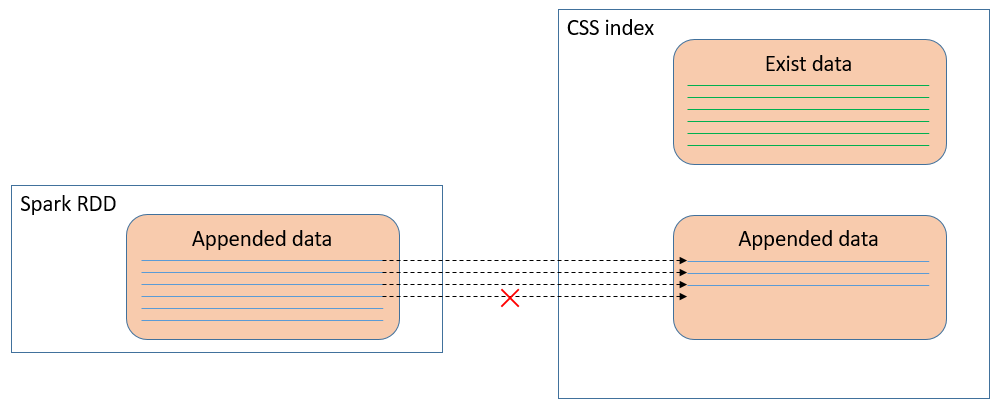
ЭМ дкВхШыЪ§ОнЪБНЋжїМќЩшЮЊdoc_idЃЌРћгУУнЕШВхШыРДЪЕЯжзюжевЛжТад
змНс
БОЮФПЩвдвЛОфЛАзмНсЮЊЁАРћгУdoc_idЪЕЯжаДШыesЕФзюжевЛжТадЁБЁЃЖјетжжЮЪЬтЃЌЪЕМЪЩЯВЛашвЊШчДЫДѓЗбжмеТЕФЬНЫїЃЌвђЮЊдкesЕФдЩњAPIжаЃЌВхШыЪ§ОнЪЧашвЊжИЖЈdoc_idЃЌетгІИУЪЧвЛИіЛљБОГЃЪЖЃКЯъЯИAPIЫЕУїПЩвдВЮПМ.

ЭМ esЪЙгУbulkНгПкНјааЪ§ОнаДШы
ШЈЕБЯћЧВЃЌСФвдЮПНхЁЃ
ЕУвцгкBaseРэТлЃЌзюжевЛжТадГЩЮЊЗжВМЪНМЦЫужаживЊЕФНтОіЗНАИжЎвЛЁЃОЁЙмИУНтОіЗНАИЛЙгавЛЖЈЕФЯожЦЃЈБШШчБОЮФЕФНтОіЗНАИжаЪ§ОнБиаыЪЙгУжїМќЃЉЃЌЖјвЕНчЛЙгаКмЖрЗжВМЪНвЛжТадЕФНтОіЗНАИЃЈБШШч2PCЁЂ3PCЃЉЁЃЕЋИіШЫШЯЮЊЃЌКтСПЙЄзїСПгызюжеаЇЙћЃЌзюжевЛжТадЪЧвЛжжКмгааЇЧвКмМђдМЕФНтОіЗНАИЁЃ
РЉеЙдФЖСЃКElasticsearch Datasource
МђНщ
DatasourceЪЧApache SparkЬсЙЉЕФЗУЮЪЭтВПЪ§ОндДЕФЭГвЛНгПкЁЃSparkЬсЙЉСЫSPIЛњжЦЖдDatasourceНјааСЫВхМўЪНЙмРэЃЌПЩвдЭЈЙ§SparkЕФDatasourceФЃПщздЖЈвхЗУЮЪElasticsearchЕФТпМЁЃ
ЛЊЮЊдЦDLIЃЈЪ§ОнКўЬНЫїЃЉЗўЮёвбЭъШЋЪЕЯжСЫes datasourceЙІФмЃЌгУЛЇжЛвЊЭЈЙ§МђЕЅЕФSQLгяОфЛђепSpark
DataFrame APIОЭФмЪЕЯжSparkЗУЮЪesЁЃ
ЙІФмУшЪі
ЭЈЙ§SparkЗУЮЪesЃЌПЩвддкDLIЙйЗНЮФЕЕжаевЕНЯъЯИзЪСЯ,ЃЈElasticsearchЪЧгЩЛЊЮЊдЦCSSдЦЫбЫїЗўЮёЬсЙЉЃЉЁЃ
ПЩвдЪЙгУSpark DataFrame APIЗНЪНРДНјааЪ§ОнЕФЖСаДЃК
//
// ГѕЪМЛЏЩшжУ
//
// ЩшжУesЕФ/index/typeЃЈes 6.xАцБОВЛжЇГжЭЌвЛИіindexжаДцдкЖрИіtypeЃЌ7.xАцБОВЛжЇГжЩшжУtypeЃЉ
val resource = "/mytest/anytype";
// ЩшжУesЕФСЌНгЕижЗ(ИёЪНЮЊЁБnode1:port, node2:port...ЁБ,вђЮЊesЕФreplicaЛњжЦ,МДЪЙЗУЮЪesМЏШК,жЛашвЊХфжУвЛИіЕижЗМДПЩ.)
val nodes = "localhost:9200"
// ЙЙдьЪ§Он
val schema = StructType(Seq (StructField("id",
IntegerType, false), StructField("name",
StringType, false)))
val rdd = sparkSession.sparkContext.parallelize
(Seq(Row(1, "John"), Row(2,"Bob")))
val dfWriter = sparkSession.createDataFrame (rdd,
schema)
//
// аДШыЪ§ОнжСes
//
dfWriter.write
.format("es")
.option("es.resource", resource)
.option("es.nodes", nodes)
.mode(SaveMode.Append)
.save()
//
// ДгesЖСШЁЪ§Он
//
val dfReader = sparkSession.read.format( "es"
).option ("es.resource",resource ).option
("es.nodes", nodes ).load()
dfReader.show() |
вВПЩвдЪЙгУSpark SQLРДЗУЮЪЃК
// ДДНЈвЛеХЙиСЊes /index/typeЕФSparkСйЪББэ,ИУБэВЂВЛДцЗХЪЕМЪЪ§Он
val sparkSession = SparkSession.builder( ).getOrCreate()
sparkSession.sql ("create table es_table(id
int, name string) using es options(
'es.nodes' 'localhost:9200',
'es.resource' '/mytest/anytype')")
// ВхШыЪ§ОнжСes
sparkSession.sql("insert into es_table values(1,
'John'),(2, 'Bob')")
// ДгesжаЖСШЁЪ§Он
val dataFrame = sparkSession.sql("select
* from es_table")
dataFrame.show() |
| 







