| Īŗľ≠Õ∆ľŲ: |
Īĺőń∑÷őŲŌ¬
InnoDBĶńńŕ≤Ņ ĶŌ÷Ľķ÷∆£¨≤Ę∂‘InnoDB ľ‹ĻĻ,InnoDB ńŕīś÷–ĶńĹŠĻĻīŇŇŐ…ŌĶńĹŠĻĻ◊ŲŃňĹť…‹,◊Óļů∑÷őŲŃňInnoDB
ļÕ ACID ń£–Õ£¨Ō£ÕŻ∂‘ńķĶń—ßŌį”–ňýįÔ÷ķ°£
Īĺőńņī◊‘ľÚ ť£¨”…ĽūŃķĻŻ»ŪľĢAliceĪŗľ≠°ĘÕ∆ľŲ°£ |
|
MySQL InnoDB “ż«śŌ÷‘ŕĻ„ő™ Ļ”√£¨ňŁŐŠĻ©Ńň ¬őŮ£¨––ňÝ£¨»’÷ĺĶ»“ĽŌĶŃ–Őō–‘£¨Īĺőń∑÷őŲŌ¬
InnoDBĶńńŕ≤Ņ ĶŌ÷Ľķ÷∆£¨MySQL įśĪĺő™ 5.7.24£¨≤Ŕ◊ųŌĶÕ≥ő™ Debian 9°£MySQL
InnoDB Ķń ĶŌ÷∑«≥£łī‘”£¨Īĺőń÷Ľ «◊‹ĹŠŃň“Ľ–©∆§√ę£¨Ō£ÕŻ“‘ļůń‹ĻĽ—–ĺŅĶńłŁľ”…Ó»Ž–©°£
1 InnoDB ľ‹ĻĻ
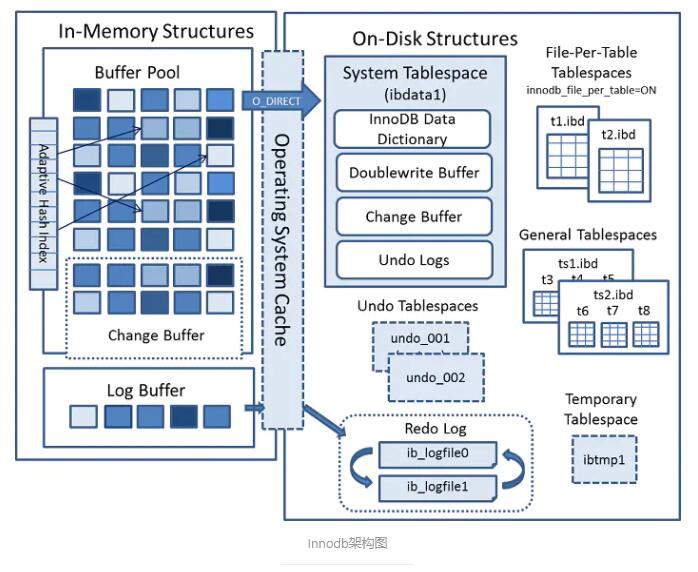
InnoDB Ķńľ‹ĻĻ∑÷ő™ŃĹŅť£ļńŕīś÷–ĶńĹŠĻĻļÕīŇŇŐ…ŌĶńĹŠĻĻ°£InnoDB Ļ”√»’÷ĺŌ»––≤Ŗ¬‘£¨Ĺę żĺ›–řłńŌ»‘ŕńŕīś÷–ÕÍ≥…£¨≤Ę«“Ĺę ¬őŮľ«¬ľ≥…÷ō◊Ų»’÷ĺ(Redo
Log)£¨◊™ĽĽő™ň≥–ÚIOłŖ–ßĶńŐŠĹĽ ¬őŮ°£’‚ņÔ»’÷ĺŌ»––£¨ňĶĶń «»’÷ĺľ«¬ľĶĹ żĺ›Ņ‚“‘ļů£¨∂‘”¶Ķń ¬őŮĺÕŅ…“‘∑ĶĽōłÝ”√Ľß£¨ĪŪ ĺ ¬őŮÕÍ≥…°£Ķę « Ķľ …Ō£¨’‚łŲ żĺ›Ņ…ń‹ĽĻ÷Ľ‘ŕńŕīś÷––řłńÕÍ£¨≤Ę√Ľ”–ňĘĶĹīŇŇŐ…Ō»•°£ńŕīś «“◊ ßĶń£¨»ÁĻŻ‘ŕ żĺ›¬šĶō«į£¨Ľķ∆ųĻ“Ńň£¨ń«√ī’‚≤Ņ∑÷ żĺ›ĺÕ∂™ ßŃň°£
InnoDB Õ®Ļż redo »’÷ĺņīĪ£÷§ żĺ›Ķń“Ľ÷¬–‘°£»ÁĻŻĪ£īśňý”–Ķń÷ō◊Ų»’÷ĺ£¨Ō‘»ĽŅ…“‘‘ŕŌĶÕ≥Īņņ£ Īłýĺ›»’÷ĺ÷ōĹ® żĺ›°£ĶĪ»Ľľ«¬ľňý”–Ķń÷ō◊Ų»’÷ĺ≤ĽŐęŌ÷ Ķ£¨ňý“‘
InnoDB “ż»ŽŃňľž≤ťĶ„Ľķ÷∆°£ľī∂®∆ŕľž≤ť£¨Ī£÷§ľž≤ťĶ„÷ģ«įĶń»’÷ĺ∂ľ“—ĺ≠–īĶĹīŇŇŐ£¨‘ÚŌ¬īőĽ÷łī÷Ľ–Ť“™ī”ľž≤ťĶ„Ņ™ ľ°£
2 InnoDB ńŕīś÷–ĶńĹŠĻĻ
ńŕīś÷–ĶńĹŠĻĻ÷ų“™įŁņ® Buffer Pool£¨Change Buffer°ĘAdaptive Hash
Index“‘ľį Log Buffer ňń≤Ņ∑÷°£»ÁĻŻī”ńŕīś…ŌņīŅī£¨Change Buffer ļÕ Adaptive
Hash Index ’ľ”√Ķńńŕīś∂ľ Ű”ŕ Buffer Pool£¨Log Buffer’ľ”√Ķńńŕīś”Ž Buffer
Pool∂ņŃĘ°£
Buffer Pool
Ľļ≥Ś≥ōĽļīśĶń żĺ›įŁņ®Page Cache°ĘChange Buffer°ĘData Dictionary
CacheĶ»£¨Õ®≥£ MySQL ∑ĢőŮ∆ųĶń 80% ĶńőÔņŪńŕīśĽŠ∑÷ŇšłÝ Buffer Pool°£
Ľý”ŕ–߬ Ņľ¬«£¨InnoDB÷– żĺ›Ļ‹ņŪĶń◊Ó–°Ķ•őĽő™“≥£¨ń¨»Ō√Ņ“≥īů–°ő™16KB£¨√Ņ“≥įŁļ¨»Űł…–– żĺ›°£ő™ŃňŐŠłŖĽļīśĻ‹ņŪ–߬ £¨InnoDBĶńĽļīś≥ōÕ®Ļż“ĽłŲ“≥ŃīĪŪ ĶŌ÷£¨ļ‹…Ŕ∑√ő Ķń“≥ĽŠÕ®ĻżĽļīś≥ōĶń
LRU ň„∑®Ő‘Ő≠≥Ų»•°£InnoDB ĶńĽļ≥Ś≥ō“≥ŃīĪŪ∑÷ő™ŃĹ≤Ņ∑÷£ļNew sublist(ń¨»Ō’ľ5/8Ľļīś≥ō)
ļÕ Old sublist(ń¨»Ō’ľ3/8Ľļīś≥ō£¨Ņ…“‘Õ®Ļż innodb_old_blocks_pct–řłń£¨ń¨»Ō÷Ķő™
37)£¨∆š÷––¬∂Ń»°Ķń“≥ĽŠľ”»ŽĶĹ Old sublistĶńÕ∑≤Ņ£¨∂Ý Old sublist÷–Ķń“≥»ÁĻŻĪĽ∑√ő £¨‘ÚĽŠ“∆ĶĹ
New sublistĶńÕ∑≤Ņ°£Ľļ≥Ś≥ōĶń Ļ”√«ťŅŲŅ…“‘Õ®Ļż show engine innodb status
√ŁŃÓ≤ťŅī°£∆š÷–“Ľ–©÷ų“™–ŇŌĘ»ÁŌ¬£ļ
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 137428992 # ∑÷ŇšłÝInnoDBĽļīś≥ōĶńńŕīś(◊÷Ĺŕ)
Dictionary memory allocated 102398 # ∑÷ŇšłÝInnoDB żĺ›◊÷ĶšĶńńŕīś(◊÷Ĺŕ)
Buffer pool size 8191 # Ľļīś≥ōĶń“≥ żńŅ
Free buffers 7893 # Ľļīś≥ōŅ’Ō–ŃīĪŪĶń“≥ żńŅ
Database pages 298 # Ľļīś≥ōLRUŃīĪŪĶń“≥ żńŅ
Modified db pages 0 # –řłńĻżĶń“≥ żńŅ
...... |
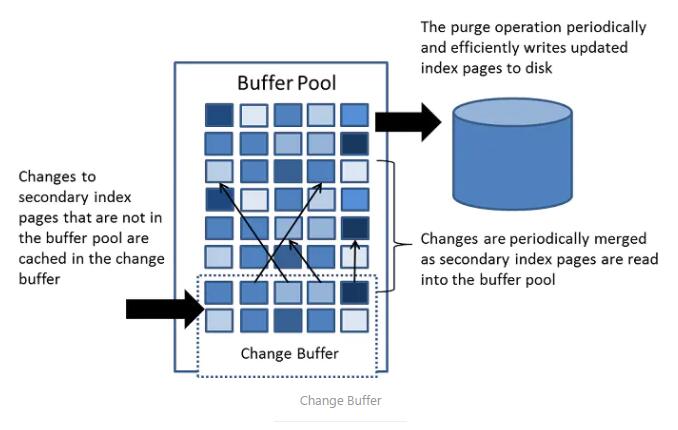
Change Buffer
Õ®≥£ņīňĶ£¨InnoDBł®÷ķňų“ż≤ĽÕ¨”ŕĺŘľĮňų“żĶńň≥–Ú≤Ś»Ž£¨»ÁĻŻ√Ņīő–řłń∂Ģľ∂ňų“ż∂ľ÷ĪĹ”–ī»ŽīŇŇŐ£¨‘ÚĽŠ”–īůŃŅ∆Ķ∑ĪĶńňśĽķIO°£Change
buffer Ķń÷ų“™ńŅĶń «Ĺę∂‘ ∑«ő®“Ľ ł®÷ķňų“ż“≥Ķń≤Ŕ◊ųĽļīśŌ¬ņī£¨“‘īňľű…Ŕł®÷ķňų“żĶńňśĽķIO£¨≤ĘīÔĶĹ≤Ŕ◊ųļŌ≤ĘĶń–ßĻŻ°£ňŁĽŠ’ľ”√≤Ņ∑÷Buffer
Pool ĶńńŕīśŅ’ľš°£‘ŕ MySQL5.5 ÷ģ«į Change Buffer∆š ĶĹ– Insert Buffer£¨◊Ó≥ű÷Ľ÷ß≥÷
insert ≤Ŕ◊ųĶńĽļīś£¨ňś◊Ň÷ß≥÷≤Ŕ◊ųņŗ–ÕĶń‘Ųľ”£¨łń√Żő™ Change Buffer°£»ÁĻŻł®÷ķňų“ż“≥“—ĺ≠‘ŕĽļ≥Ś«ÝŃň£¨‘Ú÷ĪĹ”–řłńľīŅ…£Ľ»ÁĻŻ≤Ľ‘ŕ£¨‘ÚŌ»Ĺę–řłńĪ£īśĶĹ
Change Buffer°£Change BufferĶń żĺ›‘ŕ∂‘”¶ł®÷ķňų“ż“≥∂Ń»°ĶĹĽļ≥Ś«Ý ĪļŌ≤ĘĶĹ’ś’żĶńł®÷ķňų“ż“≥÷–°£Change
Buffer ńŕ≤Ņ ĶŌ÷“≤ « Ļ”√Ķń B+ ų°£
Ņ…“‘Õ®Ļż innodb_change_buffering Ňš÷√ «∑ŮĽļīśł®÷ķňų“ż“≥Ķń–řłń£¨ń¨»Ōő™
all£¨ľīĽļīś insert/delete-mark/purge ≤Ŕ◊ų(◊Ę£ļMySQL …ĺ≥ż żĺ›Õ®≥£∑÷ő™ŃĹ≤Ĺ£¨Ķŕ“Ľ≤Ĺ «delete-mark£¨ľī÷ĽĪÍľ«£¨∂Ýpurge≤Ň «’ś’żĶń…ĺ≥ż żĺ›)°£
Change Buffer
≤ťŅīChange Buffer–ŇŌĘ“≤Ņ…“‘Õ®Ļż show engine
innodb status √ŁŃÓ°£
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 34673, node heap has 0 buffer(s)
Hash table size 34673, node heap has 0 buffer(s)
Hash table size 34673, node heap has 0 buffer(s)
Hash table size 34673, node heap has 0 buffer(s)
Hash table size 34673, node heap has 0 buffer(s)
Hash table size 34673, node heap has 0 buffer(s)
Hash table size 34673, node heap has 0 buffer(s)
Hash table size 34673, node heap has 0 buffer(s) |
Adaptive Hash Index
◊‘ ”¶ĻĢŌ£ňų“ż(AHI)≤ť—Į∑«≥£Ņž£¨“Ľį„ Īľšłī‘”∂»ő™ O(1)£¨ŌŗĪ» B+ ųÕ®≥£“™≤ť—Į 3~4īő£¨–߬ ĽŠ”–ļ‹īůŐŠ…ż°£innodb
Õ®ĻżĻŘ≤žňų“ż“≥…ŌĶń≤ť—Įīő ż£¨»ÁĻŻ∑ĘŌ÷Ĺ®ŃĘĻĢŌ£ňų“żŅ…“‘ŐŠ…ż≤ť—Į–߬ £¨‘ÚĽŠ◊‘∂ĮĹ®ŃĘĻĢŌ£ňų“ż£¨≥∆÷ģő™◊‘ ”¶ĻĢŌ£ňų“ż£¨≤Ľ–Ť“™»ňĻ§ł…‘§£¨Ņ…“‘Õ®Ļż
innodb_adaptive_hash_index Ņ™∆Ű£¨MySQL5.7 ń¨»ŌŅ™∆Ű°£
Ņľ¬«ĶĹ≤ĽÕ¨ŌĶÕ≥Ķń≤Ó“ž£¨”––©ŌĶÕ≥Ņ™∆Ű◊‘ ”¶ĻĢŌ£ňų“żŅ…ń‹ĽŠĶľ÷¬–‘ń‹ŐŠ…ż≤Ľ√ųŌ‘£¨∂Ý«“ő™ľŗŅōňų“ż“≥≤ť—Įīő ż‘Ųľ”Ńň∂ŗ”ŗĶń–‘ń‹ňūļń£¨
MySQL5.7 łŁłńŃň AHI ĶŌ÷Ľķ÷∆£¨√ŅłŲ AHI ∂ľ∑÷ŇšŃň◊®√Ň∑÷«Ý£¨Õ®Ļż innodb_adaptive_hash_index_partsŇš÷√∑÷«Ý żńŅ£¨ń¨»Ō «8łŲ£¨»Á«į“ĽĹŕ√ŁŃÓŃ–≥Ųňý ĺ°£
Log Buffer
Log Buffer « ÷ō◊Ų»’÷ĺ‘ŕńŕīś÷–ĶńĽļ≥Ś«Ý£¨īů–°”… innodb_log_buffer_size
∂®“Ś£¨ń¨»Ō « 16M°£“ĽłŲīůĶń Log BufferŅ…“‘»√īů ¬őŮ‘ŕŐŠĹĽ«į≤ĽĪōĹę»’÷ĺ÷–ÕĺňĘĶĹīŇŇŐ£¨Ņ…“‘ŐŠłŖ–߬ °£»ÁĻŻń„ĶńŌĶÕ≥”–ļ‹∂ŗ–řłńļ‹∂ŗ––ľ«¬ľĶńīů ¬őŮ£¨Ņ…“‘‘Ųīůł√÷Ķ°£
Ňš÷√ŌÓ innodb_flush_log_at_trx_commit ”√”ŕŅō÷∆ Log Buffer
»Áļő–ī»ŽļÕňĘĶĹīŇŇŐ°£◊Ę“‚£¨≥żŃň MySQL ĶńĽļ≥Ś«Ý£¨≤Ŕ◊ųŌĶÕ≥Īĺ…Ū“≤”–ńŕļňĽļ≥Ś«Ý°£
ń¨»Ōő™1£¨ĪŪ ĺ√Ņīő ¬őŮŐŠĹĽ∂ľĽŠĹę Log Buffer –ī»Ž≤Ŕ◊ųŌĶÕ≥Ľļīś£¨≤ĘĶų”√Ňš÷√Ķń "flush"
∑Ĺ∑®Ĺę żĺ›–īĶĹīŇŇŐ°£…Ť÷√ő™ 1 “Úő™∆Ķ∑ĪňĘīŇŇՖ߬ ĽŠ∆ęĶÕ£¨Ķę «į≤»ę–‘łŖ£¨◊Ó∂ŗ∂™ ß 1łŲ ¬őŮ żĺ›°£∂Ý…Ť÷√ő™
0 ļÕ 2 ‘ÚŅ…ń‹∂™ ß 1√Ž“‘…Ō Ķń ¬őŮ żĺ›°£
ő™ 0 ‘ÚĪŪ ĺ√Ņ√Ž≤ŇĹę Log Buffer –ī»ŽńŕļňĽļ≥Ś«Ý≤ĘĶų”√ "flush"
∑Ĺ∑®Ĺę żĺ›–īĶĹīŇŇŐ°£
ő™ 2 ‘Ú «√Ņīő ¬őŮŐŠĹĽ∂ľĹę Log Buffer–ī»ŽńŕļňĽļ≥Ś«Ý£¨Ķę «√Ņ√Ž≤ŇĶų”√ "flush"
ĹęńŕļňĽļ≥Ś«ÝĶń żĺ›ňĘĶĹīŇŇŐ°£
Ňš÷√≤ĽÕ¨Ķń÷Ķ–ßĻŻ»ÁŌ¬Õľňý ĺ£ļ
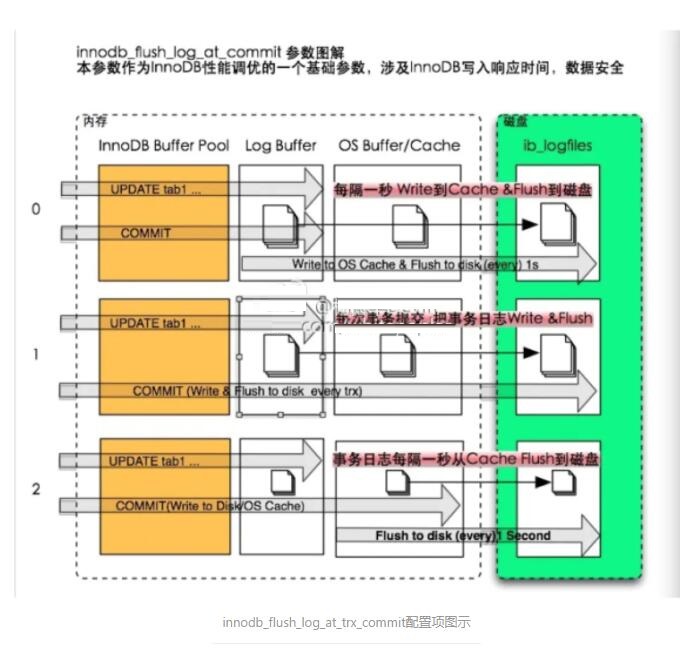
innodb_flush_log_at_timeout Ņ…“‘Ňš÷√ňĘ–¬»’÷ĺĽļīśĶĹīŇŇŐĶń∆Ķ¬ £¨ń¨»Ō «1√Ž°£◊Ę“‚ňĘīŇŇŐĶń∆Ķ¬ ≤Ę≤ĽĪ£÷§ĺÕ’żļ√ «’‚łŲ Īľš£¨Ņ…ń‹“Úő™MySQLĶń“Ľ–©≤Ŕ◊ųĶľ÷¬Õ∆≥ŔĽÚŐŠ«į°£∂Ý’‚łŲ
"flush" ∑Ĺ∑®≤Ę≤Ľ «CĪÍ◊ľŅ‚Ķń fflush ∑Ĺ∑®(fflush «ĹęCĪÍ◊ľŅ‚ĶńĽļ≥Ś–īĶĹńŕļňĽļ≥Ś«Ý£¨≤Ę≤ĽĪ£÷§ňĘĶĹīŇŇŐ)£¨ňŁÕ®Ļż
innodb_flush_method Ňš÷√Ķń£¨ń¨»Ō « fsync£¨ľī»’÷ĺļÕ żĺ›∂ľÕ®Ļż fsync
ŌĶÕ≥Ķų”√ňĘĶĹīŇŇŐ°£
Ņ…“‘∑ĘŌ÷£¨InnoDB ĽýĪĺ√Ņ√Ž∂ľĽŠĹę Log buffer¬šŇŐ°£∂ÝInnoDB÷– Ļ”√Ķń redo
log ļÕ undo log£¨ňŁ√« «∑÷Ņ™īśīĘĶń°£redo log‘ŕńŕīś÷–”–log buffer£¨‘ŕīŇŇŐ∂‘”¶ib_logfileőńľĢ°£∂Ýundo
log «ľ«¬ľ‘ŕĪŪŅ’ľšibdőńľĢ÷–Ķń£¨InnoDBő™undo logĽŠ…ķ≥…undo“≥£¨∂‘undo logĪĺ…ŪĶń≤Ŕ◊ų£®Ī»»ÁŌÚundo
log≤Ś»Ž“ĽŐűľ«¬ľ£©£¨“≤ĽŠľ«¬ľredo log£¨“Úīňundo log≤Ę≤Ľ–Ť“™¬Ū…Ō¬šŇŐ°£∂Ý redo
log‘ÚÕ®≥£ĽŠ∑÷Ňš“ĽŅťŃ¨–ÝĶńīŇŇŐŅ’ľš£¨»ĽļůŌ»–īĶĹlog buffer£¨≤Ę√Ņ√ŽňĘ“ĽīőīŇŇŐ°£redo logĪō–Ž‘ŕ żĺ›¬šŇŐ«įŌ»¬šŇŐ(Write
Ahead Log)£¨ī”∂ÝĪ£÷§ żĺ›≥÷ĺ√–‘ļÕ“Ľ÷¬–‘°£∂Ý żĺ›Īĺ…ŪĶń–řłńŅ…“‘Ō»◊§ŃŰ‘ŕńŕīśĽļ≥Ś≥ō÷–£¨‘Ŕłýĺ›Őō∂®Ķń≤Ŗ¬‘∂®∆ŕňĘĶĹīŇŇŐ°£
3 InnoDB īŇŇŐ…ŌĶńĹŠĻĻ
īŇŇŐ÷–ĶńĹŠĻĻ∑÷ő™ŃĹīůņŗ£ļĪŪŅ’ľšļÕ÷ō◊Ų»’÷ĺ°£
ĪŪŅ’ľš£ļ∑÷ő™ŌĶÕ≥ĪŪŅ’ľš(MySQL ńŅ¬ľĶń ibdata1 őńľĢ)£¨ŃŔ ĪĪŪŅ’ľš£¨≥£ĻśĪŪŅ’ľš£¨Undo
ĪŪŅ’ľš“‘ľį file-per-table ĪŪŅ’ľš(MySQL5.7ń¨»ŌīÚŅ™file_per_table
Ňš÷√£©°£ŌĶÕ≥ĪŪŅ’ľš”÷įŁņ®ŃňInnoDB żĺ›◊÷Ķš£¨ňę–īĽļ≥Ś«Ý(Doublewrite Buffer)£¨–řłńĽļīś(Change
Buffer£©£¨Undo»’÷ĺĶ»°£
Redo»’÷ĺ£ļīśīĘĶńĺÕ « Log Buffer ňĘĶĹīŇŇŐĶń żĺ›°£
ő™Ńňļů√ś≤‚ ‘∑ĹĪ„£¨ő“√«Ō»Ĺ®ŃĘ“ĽłŲ≤‚ ‘ żĺ›Ņ‚ test£¨»ĽļůĹ®ŃĘ“ĽłŲ≤‚ ‘ĪŪ t°£
mysql> create
database test;
mysql> use test;
mysql> create table t (id int auto_increment
primary key, ch varchar(5000));
mysql> insert into t (ch) values('abc');
mysql> insert into t (ch) values('defgh'); |
Ĺ®ŃĘÕÍ≥…ļů£¨Ņ…“‘‘ŕ MySQL ńŅ¬ľ÷–ŅīĶĹ test żĺ›Ņ‚ńŅ¬ľ£¨»ĽļůņÔ√ś”– db.opt£¨ t.frm
ļÕ t.ibd 3łŲőńľĢ°£∆š÷– db.opt Ī£īśŃň żĺ›Ņ‚testĶńń¨»Ō◊÷∑ŻľĮ utf8mb4 ļÕ–£—ť∑Ĺ∑®
utf8mb4_general_ci£¨t.frm «ĪŪĶń żĺ›◊÷Ķš–ŇŌĘ(InnoDB żĺ›◊÷Ķš–ŇŌĘ÷ų“™ «īśīĘ‘ŕŌĶÕ≥ĪŪŅ’ľšibdata1őńľĢ÷–£¨”…”ŕņķ ∑‘≠“Ú≤Ň‘ŕ
t.frm ∂ŗĪ£ŃŰŃň“Ľ∑›)£¨t.ibd «ĪŪĶń żĺ›ļÕňų“ż°£
3.1 InnoDB ĪŪĹŠĻĻ
InnoDB ”Ž MyISAM ≤ĽÕ¨£¨ňŁ‘ŕŌĶÕ≥ĪŪŅ’ľšīśīĘ żĺ›◊÷Ķš–ŇŌĘ£¨“ÚīňňŁĶńĪŪ≤Ľń‹ŌŮ MyISAM
ń«—ý÷ĪĹ”ŅĹĪī żĺ›ĪŪőńľĢ“∆∂Į°£MySQL5.7 ≤…”√ĶńőńľĢłŮ Ĺ « Barracuda£¨ňŁ÷ß≥÷ COMPACT
ļÕ DYNAMIC ’‚ŃĹ÷÷–¬Ķń––ľ«¬ľłŮ Ĺ°£īīĹ®ĪŪ ĪŅ…“‘Õ®Ļż ROW_FORMAT ÷ł∂®––ľ«¬ľłŮ Ĺ£¨ń¨»Ō «
DYNAMIC°£Ņ…“‘Õ®Ļż√ŁŃÓ SHOW TABLE STATUS ≤ťŅīĪŪ–ŇŌĘ£¨īňÕ‚£¨“≤Ņ… Ļ”√ SELECT
* FROM INFORMATION_SCHEMA.INNODB_SYS_TABLES WHERE
NAME='test/t' ≤ťŅī°£
mysql> SHOW
TABLE STATUS FROM test LIKE 't' \G
*************************** 1. row ***************************
Name: t
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 2
Avg_row_length: 8192
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: 3
Create_time: 2019-01-13 02:24:52
Update_time: 2019-01-13 02:28:16
Check_time: NULL
Collation: utf8mb4_general_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec) |
InnoDBĪŪ Ļ”√…Ō”–“Ľ–©Ōř÷∆£¨»Á“ĽłŲĪŪ◊Ó∂ŗ÷Ľń‹”–64łŲł®÷ķňų“ż£¨“Ľ––īů–°≤Ľń‹≥¨Ļż65535Ķ»£¨◊ťļŌňų“ż≤Ľń‹≥¨Ļż16łŲ◊÷∂őĶ»£¨“Ľį„”¶ł√≤ĽĽŠÕĽ∆∆Ōř÷∆£¨ŌÍŌłľŻ
innodb-restrictions°£
3.2 InnoDB ĪŪŅ’ľšłŇ Ų
ĪŪŅ’ľšłýĺ›ņŗ–ÕŅ…“‘∑÷ő™ŌĶÕ≥ĪŪŅ’ľš£¨File-Per-Table ĪŪŅ’ľš£¨≥£ĻśĪŪŅ’ľš£¨UndoĪŪŅ’ľš£¨ŃŔ ĪĪŪŅ’ľšĶ»°£ĪĺĹŕ∑÷őŲ
File-Per-Table ĪŪŅ’ľš°£
ŌĶÕ≥ĪŪŅ’ľš£ļįŁļ¨ńŕ»›”– żĺ›◊÷Ķš£¨ňę–īĽļ≥Ś£¨–řłńĽļ≥Ś“‘ľįundo»’÷ĺ£¨“‘ľį‘ŕŌĶÕ≥ĪŪŅ’ľšīīĹ®ĶńĪŪĶń żĺ›ļÕňų“ż°£
≥£ĻśĪŪŅ’ľš£ļņŗň∆ŌĶÕ≥ĪŪŅ’ľš£¨“≤ «“Ľ÷÷Ļ≤ŌŪĶńĪŪŅ’ľš£¨Ņ…“‘Õ®Ļż CREATE TABLESPACE īīĹ®≥£ĻśĪŪŅ’ľš£¨∂ŗłŲĪŪŅ…Ļ≤ŌŪ“ĽłŲ≥£ĻśĪŪŅ’ľš£¨“≤Ņ…“‘–řłńĪŪĶńĪŪŅ’ľš°£◊Ę“‚£ļĪō–Ž…ĺ≥ż≥£ĻśĪŪŅ’ľš÷–ĶńĪŪļů≤Ňń‹…ĺ≥ż≥£ĻśĪŪŅ’ľš°£
CREATE TABLESPACE
`ts1` ADD DATAFILE 'ts1.ibd' Engine=InnoDB;
CREATE TABLE t1 (c1 INT PRIMARY KEY) TABLESPACE
ts1;
CREATE TABLE t2 (c2 INT PRIMARY KEY) TABLESPACE
ts1;
ALTER TABLE t2 TABLESPACE=innodb_file_per_table;
DROP TABLE t1;
DROP TABLESPACE ts1; |
File-Per-TableĪŪŅ’ľš£ļMySQL InnoDB–¬įśĪĺŐŠĻ©Ńň innodb_file_per_table
—°ŌÓ£¨√ŅłŲĪŪŅ…“‘”–Ķ•∂ņĶńĪŪŅ’ľš żĺ›őńľĢ(.ibd)£¨∂Ý≤Ľ «»ę≤Ņ∑ŇĶĹŌĶÕ≥ĪŪŅ’ľš żĺ›őńľĢ ibdata1
÷–°£‘ŕ MySQL5.7 ÷–ł√—°ŌÓń¨»ŌŅ™∆Ű°£
∆šňŻĪŪŅ’ľš£ļ∆šňŻĪŪŅ’ľš÷–UndoĪŪŅ’ľšīśīĘĶń «Undo»’÷ĺ°£≥żŃňīśīĘ‘ŕŌĶÕ≥ĪŪŅ’ľšÕ‚£¨Undo»’÷ĺ“≤Ņ…“‘īśīĘ‘ŕĶ•∂ņĶńUndoĪŪŅ’ľš÷–°£ŃŔ ĪĪŪŅ’ľš‘Ú «∑«—ĻňűĶńŃŔ ĪĪŪĶńīśīĘŅ’ľš£¨ń¨»Ō « żĺ›ńŅ¬ľĶń
ibtmp1 őńľĢ£¨ňý”–ŃŔ ĪĪŪĻ≤ŌŪ£¨—ĻňűĶńŃŔ ĪĪŪ”√Ķń « File-Per-Table ĪŪŅ’ľš°£
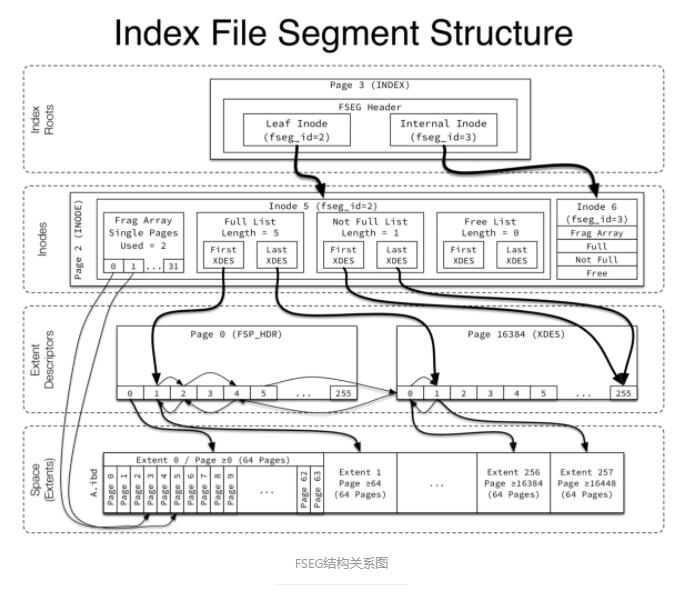
ĪŪŅ’ľšőńľĢĹŠĻĻ…Ō∑÷ő™∂ő°Ę«Ý°Ę“≥°£

∂ő(Segment)∑÷ő™ňų“ż∂ő£¨ żĺ›∂ő£¨ĽōĻŲ∂őĶ»°£∆š÷–ňų“ż∂őĺÕ «∑«“∂◊”ĹŠĶ„≤Ņ∑÷£¨∂Ý żĺ›∂őĺÕ «“∂◊”ĹŠĶ„≤Ņ∑÷£¨ĽōĻŲ∂ő”√”ŕ żĺ›ĶńĽōĻŲļÕ∂ŗįśĪĺŅō÷∆°£“ĽłŲ∂őįŁļ¨256łŲ«Ý(256Mīů–°)°£
«Ý «“≥ĶńľĮļŌ£¨“ĽłŲ«ÝįŁļ¨64łŲѨ–ÝĶń“≥£¨ń¨»Ōīů–°ő™ 1MB (64*16K)°£
“≥ « InnoDB Ļ‹ņŪĶń◊Ó–°Ķ•őĽ£¨≥£ľŻĶń”– FSP_HDR£¨INODE, INDEX Ķ»ņŗ–Õ°£ňý”–“≥ĶńĹŠĻĻ∂ľ «“Ľ—ýĶń£¨∑÷ő™őńľĢÕ∑(«į38◊÷Ĺŕ)£¨“≥ żĺ›ļÕőńľĢő≤(ļů8◊÷Ĺŕ)°£“≥ żĺ›łý囓≥Ķńņŗ–Õ≤ĽÕ¨∂Ý≤Ľ“Ľ—ý°£
FILE_SPACE_HEADER “≥£ļ”√”ŕīśīĘ«ÝĶń‘™–ŇŌĘ°£ibdőńľĢĶńĶŕ“Ľ“≥ FSP_HDR “≥Õ®≥£ĺÕ”√”ŕīśīĘ«ÝĶń‘™–ŇŌĘ£¨ņÔ√śĶń256łŲ
XDES(extent descriptors) ŌÓīśīĘŃň256łŲ«ÝĶń‘™–ŇŌĘ£¨įŁņ®«ÝĶń Ļ”√«ťŅŲļÕ«ÝņÔ√ś“≥Ķń Ļ”√«ťŅŲ°£
IBUF_BITMAP “≥£ļ”√”ŕľ«¬ľ change bufferĶń Ļ”√«ťŅŲ°£
INODE “≥£ļ”√”ŕľ«¬ľőńľĢ∂ő(FSEG)Ķń–ŇŌĘ£¨√Ņ“≥”–85łŲINODE entry£¨√ŅłŲINODE
entry’ľ”√192◊÷Ĺŕ£¨”√”ŕ√Ť Ų“ĽłŲőńľĢ∂ő°£√ŅłŲINODE entryįŁņ®őńľĢ∂őID°Ę Ű”ŕł√∂őĶń«ÝĶń–ŇŌĘ“‘ľįňť∆¨“≥ ż◊ť°£«Ý–ŇŌĘįŁņ®
FREE(ÕÍ»ęŅ’Ō–Ķń«Ý), NOT_FULL(÷Ń…Ŕ Ļ”√Ńň“ĽłŲ“≥Ķń«Ý), FULL(√ĽŅ’Ō–“≥Ķń«Ý)»ż÷÷ņŗ–ÕĶń«ÝĶńList
Base Node(įŁļ¨ŃīĪŪ≥§∂»ļÕÕ∑ő≤“≥ļŇļÕ∆ę“∆ĶńĹŠĻĻŐŚ)°£ňť∆¨“≥ ż◊ť‘Ú «≤ĽÕ¨”ŕ∑÷Ňš’ŻłŲ«ÝĶńĶ•∂ņ∑÷ŇšĶń32łŲ“≥°£
INDEX “≥£ļňų“ż“≥Ķń“∂◊”ĹŠĶ„ĶńdataĺÕ « żĺ›£¨»ÁĺŘľĮňų“żīśīĘĶń–– żĺ›£¨ł®÷ķňų“żīśīĘĶń÷ųľŁ÷Ķ°£
3.3 InnoDB File-Per-TableĪŪŅ’ľš
≤…”√ File-Per-Table Ķń”Ň»ĪĶ„»ÁŌ¬£ļ
”ŇĶ„£ļŅ…“‘∑ĹĪ„Ľō ’…ĺ≥żĪŪňý’ľĶńīŇŇŐŅ’ľš°£»ÁĻŻ Ļ”√ŌĶÕ≥ĪŪŅ’ľšĶńĽį£¨…ĺ≥żĪŪļůŅ’Ō–Ņ’ľš÷Ľń‹ĪĽ InnoDB
żĺ› Ļ”√°£TRUNCATE TABLE ≤Ŕ◊ųĽŠłŁŅž°£Ņ…“‘Ķ•∂ņŅĹĪīĪŪŅ’ľš żĺ›ĶĹ∆šňŻ żĺ›Ņ‚( Ļ”√ transportable
tablespace Őō–‘)£¨Ņ…“‘łŁ∑ĹĪ„ĶńĻŘ≤‚√ŅłŲĪŪŅ’ľš żĺ›Ķńīů–°°£
»ĪĶ„£ļfsync ≤Ŕ◊ų–Ť“™◊ų”√Ķń∂ŗłŲĪŪŅ’ľšőńľĢ£¨Ī»÷Ľ∂‘ŌĶÕ≥ĪŪŅ’ľš’‚“ĽłŲőńľĢĹÝ––fsync≤Ŕ◊ųĽŠ∂ŗ“Ľ–©
IO ≤Ŕ◊ų°£īňÕ‚£¨mysqld–Ť“™ő¨Ľ§łŁ∂ŗĶńőńľĢ√Ť Ų∑Ż°£
ĪŪŅ’ľšőńľĢĹŠĻĻ
InnoDB ĪŪŅ’ľšőńľĢ .ibd ≥ű ľīů–°ő™ 96K£¨∂ÝInnoDBń¨»Ō“≥īů–°ő™ 16K£¨“≥īů–°“≤Ņ…“‘Õ®Ļż
innodb_page_size Ňš÷√ő™ 4K, 8K...64K Ķ»°£‘ŕibdőńľĢ÷–£¨0-16KB∆ę“∆ŃŅľīő™0ļŇ żĺ›“≥£¨16KB-32KBĶńő™1ļŇ żĺ›“≥£¨“‘īňņŗÕ∆°£“≥ĶńÕ∑ő≤≥żŃň“Ľ–©‘™–ŇŌĘÕ‚£¨ĽĻ”–Checksum–£—ť÷Ķ£¨’‚–©–£—ť÷Ķ‘ŕ–ī»ŽīŇŇŐ«įľ∆ň„Ķ√ĶĹ£¨ĶĪī”īŇŇŐ÷–∂Ń»° Ī£¨÷ō–¬ľ∆ň„–£—ť÷Ķ≤Ę”Ž żĺ›“≥÷–īśīĘĶń∂‘Ī»£¨»ÁĻŻ∑ĘŌ÷≤ĽÕ¨£¨‘ÚĽŠĶľ÷¬
MySQL Īņņ£°£
ibdőńľĢīśīĘĹŠĻĻ»ÁŌ¬ňý ĺ£ļ

ibdőńľĢīśīĘĹŠĻĻ
InnoDB“≥∑÷ő™INDEX“≥°ĘUndo“≥°ĘŌĶÕ≥“≥£¨IBUF_BITMAP“≥, INODE“≥Ķ»∂ŗ÷÷°£
Ķŕ0“≥ « FSP_HDR “≥£¨÷ų“™”√”ŕłķ◊ŔĪŪŅ’ľš£¨Ņ’Ō–ŃīĪŪ°Ęňť∆¨“≥“‘ľį«ÝĶ»–ŇŌĘ°£
Ķŕ1“≥ « IBUF_BITMAP “≥£¨Ī£īśChange BufferĶńőĽÕľ°£
Ķŕ2“≥ « INODE “≥£¨”√”ŕīśīĘ«ÝļÕĶ•∂ņ∑÷ŇšĶńňť∆¨“≥–ŇŌĘ£¨įŁņ®FULL°ĘFREE°ĘNOT_FULL
Ķ»“≥Ń–ĪŪĶńĽýī°ĹŠĶ„–ŇŌĘ(Ľýī°ĹŠĶ„–ŇŌĘľ«¬ľŃňŃ–ĪŪĶń∆ū ľļÕĹŠ Ý“≥ļŇļÕ∆ę“∆Ķ»)£¨’‚–©ĹŠĶ„÷łŌÚĶń « FSP_HDR
“≥÷–ĶńŌÓ£¨”√”ŕľ«¬ľ“≥Ķń Ļ”√«ťŅŲ£¨ňŁ√«÷ģľšĻōŌĶ»ÁŌ¬Õľňý ĺ°£
Ķŕ3“≥Ņ™ ľ «ňų“ż“≥ INDEX(B-tree node)£¨ī” 0xc000(√Ņ“≥16K) Ņ™ ľ£¨ļů√śĽĻ”––©∑÷ŇšĶńőī Ļ”√Ķń“≥°£
Ņ…“‘‘ŕ innodb_sys_tables ĪŪ÷–≤ťĶĹĪŪtĶńĪŪŅ’ľšIDő™28£¨»ĽļůŅ…“‘‘ŕ innodb_buffer_page≤ťĶĹňý”–“≥–ŇŌĘ£¨“ĽĻ≤4łŲ“≥°£∑÷Īū «
FSP_HDR, IBUF_BITMAP, INODE, INDEX°£
select * from
information_schema.innodb_sys_tables where name='test/t';
select * from information_schema.innodb_buffer_page
where SPACE=28; |
ňų“ż“≥∑÷őŲ
InnoDB“ż«śňų“ż“≥ĶńĹŠĻĻ»ÁŌ¬Õľ£¨Ņ…“‘”√ hexdump≤ťŅī t.ibd
őńľĢ£¨»Ľļů∂‘’’InnoDB“≥ĶńĹŠĻĻ∑÷őŲŌ¬łųłŲ“≥Ķń◊÷∂ő°£

# hexdump -C
t.ibd
0000c000 95 45 82 8a 00 00 00 03 ff ff ff ff ff
ff ff ff |.E..............|
0000c010 00 00 00 00 00 28 85 7c 45 bf 00 00 00
00 00 00 |.....(.|E.......|
0000c020 00 00 00 00 00 1c 00 02 00 b0 80 04 00
00 00 00 |................|
0000c030 00 9a 00 02 00 01 00 02 00 00 00 00 00
00 00 00 |................|
0000c040 00 00 00 00 00 00 00 00 00 2f 00 00 00
1c 00 00 |........./......|
0000c050 00 02 00 f2 00 00 00 1c 00 00 00 02 00
32 01 00 |.............2..|
0000c060 02 00 1c 69 6e 66 69 6d 75 6d 00 03 00
0b 00 00 |...infimum......|
0000c070 73 75 70 72 65 6d 75 6d 03 00 00 00 10
00 1b 80 |supremum........|
0000c080 00 00 01 00 00 00 00 05 68 d1 00 00 01
54 01 10 |........h....T..|
0000c090 61 62 63 05 00 00 00 18 ff d6 80 00 00
02 00 00 |abc.............|
0000c0a0 00 00 05 69 d2 00 00 01 55 01 10 64 65
66 67 68 |...i....U..defgh|
0000c0b0 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 |................|
*
0000fff0 00 00 00 00 00 70 00 63 95 45 82 8a 00
28 85 7c |.....p.c.E...(.||
00010000 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 |................| |
FIL Header£®38◊÷Ĺŕ): ľ«¬ľőńľĢÕ∑–ŇŌĘ°£«į4◊÷Ĺŕ 95 45 82 8a « checksum£¨Ĺ”◊Ň
00 00 00 03 «“≥∆ę“∆÷Ķ 3£¨ľī’‚ «Ķŕ3“≥°£Ĺ”◊Ň 4 ◊÷Ĺŕ «…Ō“Ľ“≥∆ę“∆÷Ķ£¨“Úő™÷Ľ”–“ĽłŲ żĺ›“≥£¨ňý“‘’‚ņÔő™
ff ff ff ff£¨Ĺ”◊Ň 4 ◊÷Ĺŕ «Ō¬“Ľ“≥∆ę“∆÷Ķ ff ff ff ff°£»Ľļů 8 ◊÷Ĺŕ 00
00 00 00 00 28 85 7c «»’÷ĺ–ÚŃ–ļŇ LSN°£ňśļůĶń 2 ◊÷Ĺŕ 45 bf «“≥ņŗ–Õ£¨īķĪŪ «
INDEX “≥°£Ĺ”◊Ň 8 ◊÷Ĺŕ 00 00 00 00 00 00 00 00ĪŪ ĺĪĽłŁ–¬ĶĹĶńLSN£¨‘ŕ
File-Per-Table ĪŪŅ’ľš÷–∂ľ «0°£»Ľļů 4 ◊÷Ĺŕ 00 00 00 1c ĪŪ ĺł√ żĺ›“≥ Ű”ŕĶńĪŪtĶńĪŪŅ’ľšID «
0x1c(28)°£
INDEX Header£®36◊÷Ĺŕ): ľ«¬ľĶń « INDEX “≥Ķń◊īŐ¨–ŇŌĘ°£«į2◊÷Ĺŕ 00 02 ĪŪ ĺ“≥ńŅ¬ľĶń
slot żńŅő™2£ĽĹ”◊Ň2◊÷Ĺŕ 00 b0 «“≥÷–Ķŕ“ĽłŲľ«¬ľĶń÷ł’Ž°£80 04 «’‚“≥ĶńłŮ Ĺő™DYNAMICļÕľ«¬ľ ż4(įŁņ®2ŐűSystem
Recordső“√«≤Ś»ŽĶń2Őűľ«¬ľ)°£Ĺ”◊Ň 00 00 «Ņ…÷ō”√Ņ’ľš ◊÷ł’Ž£¨‘Ŕļů√ś2◊÷Ĺŕ00 00 «“—…ĺ≥żľ«¬ľ ż£Ľ00
9a «◊Óļů≤Ś»Žľ«¬ľĶńőĽ÷√∆ę“∆£¨ľī◊Óļů≤Ś»ŽőĽ÷√ « 0xc09a£¨ľīĶŕ2Őűľ«¬ľŅ™ ľĶō÷∑°£00 02 «◊Óļů≤Ś»ŽĶń∑ĹŌÚ£¨2
ĪŪ ĺ PAGE_DIRECTION_RIGHT£¨ľī◊‘‘Ų≥§∑Ĺ Ĺ≤Ś»Ž°£00 01 ÷ł“ĽłŲ∑ĹŌÚѨ–Ý≤Ś»ŽĶń żŃŅ£¨’‚ņÔő™1°£Ĺ”◊ŇĶń00
02 « INDEX “≥÷–Ķń’ś Ķľ«¬ľ ż£¨ő“√«÷Ľ”–2Őűľ«¬ľ°£»Ľļů8◊÷Ĺŕ00...00ő™–řłńł√“≥Ķń◊Óīů ¬őŮID£¨’‚łŲ÷Ķ÷Ľ‘ŕł®÷ķňų“ż÷–īś‘ŕ£¨’‚ņÔő™0°£Ĺ”◊Ň2◊÷Ĺŕ00
00ő™“≥‘ŕňų“ż ųĶń≤„ľ∂£¨0ĪŪ ĺ“∂◊”ĹŠĶ„°£◊Óļů8łŲ◊÷Ĺŕ 00...2fő™ňų“żID 47(ňų“żIDŅ…“‘‘ŕinformation_schema.INNODB_SYS_INDEXES
÷–≤ť—Į£¨Ņ…“‘»∑»Ō 47 ’żļ√ «ĪŪ t Ķń÷ųňų“ż)°£
FSEG Header£ļ’‚ «INDEX“≥÷–ĶńłýĹŠĶ„≤Ň”–Ķń£¨∑«łýĹŠĶ„Ķńő™0°£«į10◊÷Ĺŕ
00 00 00 1c 00 00 00 02 00 f2 «“∂◊”ĹŠĶ„ňý‘ŕ∂őĶńsegment header£¨∑÷Īūľ«¬ľŃň“∂◊”ĹŠĶ„ĶńĪŪŅ’ľšID
0x1c£¨INODE“≥Ķń“≥ļŇ 2 ļÕ INODEŌÓ∆ę“∆ 0xf2°£∂Ýļů10◊÷Ĺŕ 00 00 00 1c
00 00 00 02 00 32 «∑«“∂◊”ĹŠĶ„ňý‘ŕ∂őĶńsegment header£¨∆ę“∆∑÷Īū «0xf2
ļÕ 0x32£¨ľīINODE“≥Ķń«į2łŲEntry£¨őńľĢ∂őID∑÷Īū «1ļÕ2°£FSEG Header÷–īśīĘŃňł√
INDEX “≥ĶńINODEŌÓ£¨INODEŌÓņÔ√ś‘Úľ«¬ľŃňł√“≥īśīĘňý‘ŕĶńőńľĢ∂ő“‘ľįőńľĢ∂ő“≥Ķń Ļ”√«ťŅŲ°£∂‘”ŕ
File-Per-Table«ťŅŲŌ¬£¨√ŅłŲĶ•∂ņĶńĪŪŅ’ľšőńľĢĶń FSP_HDR “≥łļ‘ūĻ‹ņŪ“≥ Ļ”√«ťŅŲ°£
System Records(26◊÷Ĺŕ): √ŅłŲ INDEX “≥∂ľ”–ŃĹŐű–ťń‚ľ«¬ľ infimum ļÕ
supremum£¨”√”ŕŌř∂®ľ«¬ľĶńĪŖĹÁ£¨łų’ľ 13 łŲ◊÷Ĺŕ°£∆š÷–ľ«¬ľÕ∑Ķń5łŲ◊÷Ĺŕ∑÷ĪūĪÍ ∂Ńň”Ķ”–ľ«¬ľĶń żńŅļÕņŗ–Õ(”Ķ”–ľ«¬ľ żńŅ «ľīļů√ś“≥ńŅ¬ľ≤Ņ∑÷Ķńowned÷Ķ£¨ĶĪ«į“≥ńŅ¬ľ÷Ľ”–ŃĹłŲ≤Ř£¨infimum”Ķ”–ľ«¬ľ ż÷Ľ”–ňŁ◊‘ľļő™1£¨∂Ýsupremum”Ķ”–ő“√«≤Ś»ŽĶń2Őűľ«¬ľļÕňŁ◊‘ľļ£¨Ļ ő™3)°ĘŌ¬“ĽŐűľ«¬ľĶń∆ę“∆
0x1c£¨ľīőĽ÷√ « 0xc07f£¨’‚ĺÕ «ő“√« Ķľ ľ«¬ľŅ™ ľőĽ÷√°£ļů√ś8łŲ◊÷Ĺŕő™ infimum + Ņ’÷Ķ£¨supremumņŗň∆£¨÷Ľ «ňŁŌ¬“ĽŐűľ«¬ľ∆ę“∆ő™0°£
01 00 02 00 1c
69 6e 66 69 6d 75 6d 00 # infimum
03 00 0b 00 00 73 75 70 72 65 6d 75 6d # supermum |
User Records: Ĺ”Ō¬ņī «2Őűő“√«≤Ś»ŽĶńľ«¬ľ°£Ķŕ1Őűľ«¬ľ«į√ś7◊÷Ĺŕ «ľ«¬ľÕ∑(Record
Header)£¨∆š÷–«į√śĶń 1◊÷Ĺŕľ«¬ľĶń «Ņ…ĪšĪšŃŅĶń≥§∂»03£¨“Úő™ő“√«ľ«¬ľ÷–cĶń÷Ķ « abc°£»Ľļů1◊÷Ĺŕľ«¬ľĶń «Ņ…ő™NULLĶńĪšŃŅ «∑Ů «NULL£¨’‚ņÔ≤Ľő™
NULL£¨Ļ ő™0°£Ĺ”◊ŇĶń5◊÷Ĺŕľ«¬ľŃň≤Ś»Žň≥–Ú2(infimum≤Ś»Žň≥–ÚĻŐ∂® «0£¨supremum≤Ś»Žň≥–Ú «1£¨∆šňŻľ«¬ľ‘Ú «ī”2Ņ™ ľ)£¨Ō¬“ĽłŲľ«¬ľĶń∆ę“∆
0x1b(ľīŌ¬“ĽłŲľ«¬ľŅ™ ľőĽ÷√ «0xc078+0x1b=0xc093)£¨…ĺ≥żĪÍľ«Ķ»°£ļů√śĺÕ «ľ«¬ľńŕ»›°£Ķŕ2Őűľ«¬ľÕ¨ņŪ°£’‚ņÔĶń ¬őŮIDŅ…“‘Õ®Ļż
select * from information_schema.innodb_trx ĹÝ––—ť÷§°£
03 00 00 00
10 00 1b # ľ«¬ľÕ∑
80 00 00 01 # ÷ųľŁ÷Ķ1
00 00 00 00 05 68 # ¬őŮID
d1 00 00 01 54 01 10 # ĽōĻŲ÷ł’Ž
61 62 63 # chĶń÷Ķ abc
05 00 00 00 18 ff d6 # Ķŕ2Őűľ«¬ľÕ∑
80 00 00 02 # ÷ųľŁ÷Ķ2
00 00 00 00 05 69 # ¬őŮID
d2 00 00 01 55 01 10 # ĽōĻŲ÷ł’Ž
64 65 66 67 68 # chĶń÷Ķ defgh |
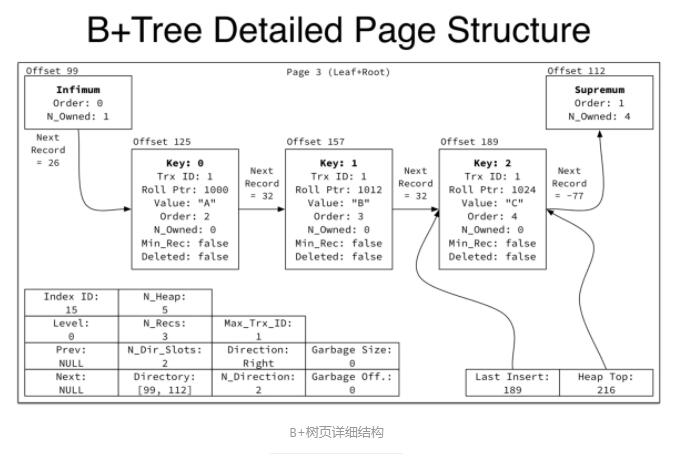
Page Directory(4◊÷Ĺŕ)£ļ“Úő™“≥ńŅ¬ľĶńslot÷Ľ”–2łŲ£¨√ŅłŲslot’ľ2◊÷Ĺŕ£¨Ļ “≥ńŅ¬ľő™
00 70 00 63 ’‚4◊÷Ĺŕ£¨īśīĘĶń «Ōŗ∂‘”ŕ◊Ó≥ű––ĶńőĽ÷√°£∆š÷– 0xc063 ’żļ√ « infimum
ľ«¬ľĶńŅ™ ľőĽ÷√£¨∂Ý 0xc070 ’żļ√ « supremum ľ«¬ľĶńŅ™ ľőĽ÷√°£ Ļ”√“≥ńŅ¬ľĹÝ––∂Ģ∑÷≤ť’“£¨Ņ…“‘ľ”ňŔ≤ť—Į£¨ŌÍŌłľŻļů√ś∑÷őŲ°£
FIL Tail (8◊÷Ĺŕ): ◊Óļů8◊÷Ĺŕő™ 95 45 82 8a 00 28 85 7c£¨∆š÷–
95 45 82 8a ő™ checknum£¨łķ FIL HeaderĶńchecksum“Ľ—ý°£ļů4◊÷Ĺŕ00
28 85 7c ”Ž FIL HeaderĶńLSNĶńļů4łŲ◊÷Ĺŕ“Ľ÷¬°£
ĶĪ»Ľ£¨ő“√«“≤Ņ…“‘Õ®Ļż innodb_ruby Ļ§ĺŖņī∑÷őŲĪŪŅ’ľšőńľĢ°£
root@stretch:/home/vagrant#
innodb_space -s /var/lib/mysql/ibdata1 -T test/t
space-page-type-regions
start end count type
0 0 1 FSP_HDR
1 1 1 IBUF_BITMAP
2 2 1 INODE
3 3 1 INDEX
4 5 2 FREE (ALLOCATED)
root@stretch:/home/vagrant# innodb_space -s /var/lib/mysql/ibdata1
-T test/t -p 3 page-records
Record 127: (id=1) °ķ (ch="abc") Record
154: (id=2) °ķ (ch="defgh") |
InnoDB żĺ›őńľĢĪĺ…ŪĺÕ «ňų“żőńľĢ£¨∆šňų“ż∑÷ĺŘľĮňų“żļÕł®÷ķňų“ż£¨ĺŘľĮňų“żĶń“∂ĹŕĶ„įŁļ¨ŃňÕÍ’ŻĶń żĺ›ľ«¬ľ£¨ł®÷ķňų“ż“∂ĹŕĶ„ żĺ›≤Ņ∑÷ «÷ųľŁĶń÷Ķ£¨≥żŃňŅ’ľšňų“żÕ‚£¨InnoDBĶńňų“ż ĶŌ÷ĽýĪĺ∂ľ «
B+ ų£¨»ÁÕľňý ĺ°£∆š÷–∑«“∂◊”ĹŠĶ„īśīĘĶń «◊”“≥Ķń◊Ó–°ĶńľŁ÷ĶļÕ◊”“≥Ķń“≥ļŇ£¨“∂◊”ĹŠĶ„īśīĘĶń « żĺ›£¨ żĺ›įī’’ňų“żľŁŇŇ–Ú°£Õ¨“Ľ≤„Ķń“≥÷ģľš”√ňęŌÚŃīĪŪѨŔ(«į√śŐŠĶĹĶńFIL
Header÷–PREV PAGE ļÕ NEXT PAGE)£¨Õ¨“Ľ“≥ńŕĶńľ«¬ľ”√Ķ•ŌÚŃīĪŪѨŔ(Record
Header÷–ľ«¬ľŃňŌ¬“ĽŐűľ«¬ľĶń∆ę“∆)°£√Ņ“Ľ“≥…Ť÷√ŃňŃĹłŲ–ťń‚ľ«¬ľInfimumļÕSupremum”√”ŕĪÍ ∂“≥ĶńŅ™ ľļÕĹŠ Ý°£
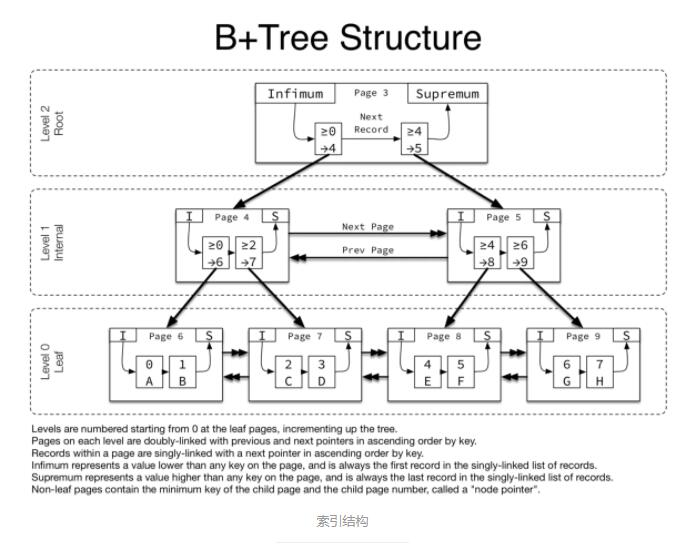
ňų“żĹŠĻĻ
‘ŕInnoDB÷–łý図®÷ķňų“ż≤ť—Į£¨»ÁĻŻ≥żŃň÷ųľŁÕ‚ĽĻ”–∆šňŻ◊÷∂ő£¨‘Ú–Ť“™≤ť—ĮŃĹĪť£¨Ō»łý図®÷ķňų“ż≤ť—Į÷ųľŁĶń÷Ķ£¨»Ľļů‘ŔĶĹ÷ųňų“ż÷–≤ť—ĮĶ√ĶĹľ«¬ľ°£īňÕ‚£¨“Úő™ł®÷ķňų“żĶń żĺ›≤Ņ∑÷ «÷ųľŁ÷Ķ£¨÷ųľŁ≤Ľń‹Ļżīů£¨∑Ů‘ÚĽŠĶľ÷¬ł®÷ķňų“ż’ľ”√Ņ’ľšĪšīů£¨”√◊‘‘ŲID◊Ų÷ųľŁ «łŲ≤ĽīŪĶń—°‘Ů°£
mysql> create
table t2(id int auto_increment primary key, ch
varchar(10), key(ch));
mysql> insert into t2(ch) values('ab'); |
īīĹ®“ĽłŲ–¬Ķń≤‚ ‘ĪŪ t2£¨”–÷ųňų“ż id ļÕ ł®÷ķňų“ż ch£¨∑÷őŲ t2.ibd őńľĢŅ…—ť÷§£ļ
∂‘Ī»ĪŪt£¨ĪŪt2∂ŗ“ĽłŲINDEX“≥£¨”√”ŕīśīĘł®÷ķňų“żĶńłýĹŠĶ„°£
ł®÷ķňų“żĶńINDEX“≥“≤”–ŃĹłŲŌĶÕ≥ľ«¬ľ infimum ļÕ supremum°£∂Ý”√Ľßľ«¬ľńŕ»›łŮ Ĺłķ«į√ś∑÷őŲĽýĪĺ“Ľ÷¬£¨ńŕ»›ő™ł®÷ķňų“ż
ch Ń–Ķń÷Ķ ab ļÕ ÷ųľŁ÷Ķ1°£
“≥ńŅ¬ľ
«į√śŐŠĶĹINDEX“≥ńŕĶńľ«¬ľ «Õ®ĻżĶ•ŌÚŃīĪŪѨŔ‘ŕ“Ľ∆ūĶń£¨ĪťņķŃ–ĪŪ–‘ń‹ĽŠĪ»ĹŌ≤Ó£¨∂ÝINDEX“≥Ķń“≥ńŅ¬ľĺÕ «ő™Ńňľ”ňŔľ«¬ľň—ňų°£ĪŪ
t2 ÷–Ķń“≥ńŅ¬ľ÷Ľ”–ŃĹŌÓ£¨∑÷Īū « 0x63 ļÕ 0x70£¨ľī 99 ļÕ 112°£Ō¬√śĶńownedkeyő™’‚łŲ“≥ńŅ¬ľ≤Ř”Ķ”–Ķń–°”ŕĶ»”ŕňŁĶńľ«¬ľ żńŅ£¨Ō‘»Ľ
infimum Ķńownedkeyő™ 1£¨ľī÷Ľ”–ňŁ◊‘ľļ£¨√Ľ”–keyĽŠĪ»infimum–°°£∂Ý supremum
Ķńowned «3£¨∑÷Īū «ő“√«≤Ś»ŽĶńŃĹŐűľ«¬ľļÕňŁ◊‘ľļ°£
slot offset type
owned key
0 99 infimum 1
1 112 supremum 3 |
√ŅłŲ“≥ńŅ¬ľ≤Ř◊Ó…Ŕ“™įŁļ¨4łŲľ«¬ľ£¨◊Ó∂ŗįŁļ¨8łŲľ«¬ľ(įŁņ®ňŁ◊‘ľļ)°£»ÁĻŻő“√«‘ŕĪŪ t2 ÷–ŃŪÕ‚≤Ś»Ž 7
Őűľ«¬ľ£¨‘ÚĽŠ‘Ųľ”“ĽłŲ–¬Ķńslot£¨ľī id ő™ 4 Ķńľ«¬ľ£¨»ÁŌ¬£ļ
slot offset type
owned key
0 99 infimum 1
1 207 conventional 4 (i=4)
2 112 supremum 5 |
Ō¬Õľ «“≥ńŅ¬ľĹŠĻĻÕľ£¨Ņ…“‘Õ®Ļż“≥ńŅ¬ľĶń∂Ģ∑÷≤ť’“ŐŠłŖ“≥ńŕ żĺ›Ķń≤ť—Į–‘ń‹°£
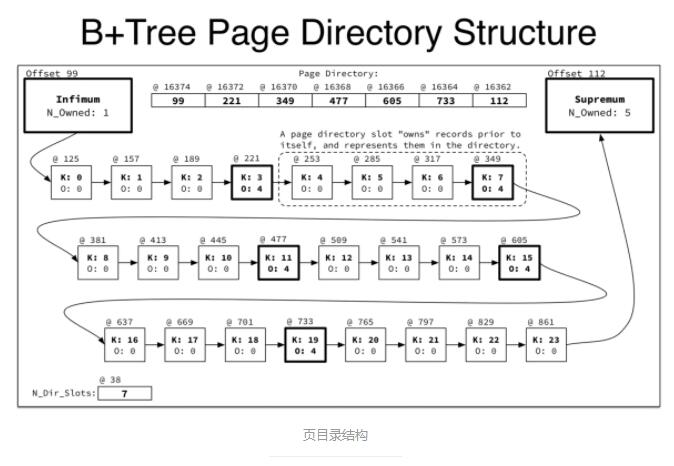
3.4 InnoDB ŌĶÕ≥ĪŪŅ’ľš
ŌĶÕ≥ĪŪŅ’ľšįŁļ¨ńŕ»›”–£ļ żĺ›◊÷Ķš£¨ňę–īĽļ≥Ś£¨–řłńĽļ≥Ś£¨undo»’÷ĺ£¨“‘ľį‘ŕŌĶÕ≥ĪŪŅ’ľšīīĹ®ĶńĪŪĶń żĺ›ļÕňų“ż°£Ņ…“‘ŅīĶĹ£¨≥żŃň∑÷Ňšőī Ļ”√Ķń“≥Õ‚£¨
UNDO_LOG£¨SYS, INDEX “≥’ľĺ›Ńň≤Ľ…ŔĶńŅ’ľš°£UNDO_LOG “≥īśīĘĶń «Undo log£¨SYS
“≥īśīĘĶń « żĺ›◊÷Ķš°ĘĽōĻŲ∂ő°Ę–řłńĽļīśĶ»–ŇŌĘ£¨INDEX «ňų“ż“≥£¨TRX_SYS “≥”√”ŕInnoDBĶń ¬őŮŌĶÕ≥°£ żĺ›◊÷ĶšĺÕ « żĺ›ĪŪĶń‘™–ŇŌĘ£¨–řłńĽļ≥Ś«į√śŐŠĶĹ «ő™ŃňŐŠłŖIO–‘ń‹“≤≤Ľ‘Ŕ◊ł Ų£¨’‚ņÔ÷ų“™∑÷őŲŌ¬
Undo »’÷ĺļÕňę–īĽļ≥Ś°£
root@stretch:/home/vagrant#
innodb_space -s /var/lib/mysql/ibdata1 space-page-type-summary
type count percent description
ALLOCATED 427 55.60 Freshly allocated
UNDO_LOG 125 16.28 Undo log
SYS 110 14.32 System internal
INDEX 71 9.24 B+Tree index
INODE 11 1.43 File segment inode
FSP_HDR 9 1.17 File space header
IBUF_BITMAP 8 1.04 Insert buffer bitmap
BLOB 5 0.65 Uncompressed BLOB
TRX_SYS 2 0.26 Transaction system header |
Undo »’÷ĺ
MySQLĶńMVCC(∂ŗįśĪĺ≤Ę∑ĘŅō÷∆)“ņņĶUndo Log ĶŌ÷°£MySQLĶńĪŪŅ’ľšőńľĢ t.ibd
īśīĘĶń «ľ«¬ľ◊Ó–¬÷Ķ£¨√ŅłŲľ«¬ľ∂ľ”–“ĽłŲĽōĻŲ÷ł’Ž(ľŻ«į√śÕľ÷–ĶńRoll Ptr)£¨÷łŌÚł√ľ«¬ľĶń◊ÓĹŁ“ĽŐűUndoľ«¬ľ£¨∂Ý√ŅŐűUndoľ«¬ľ∂ľĽŠ÷łŌÚňŁĶń«į“ĽŐűUndoľ«¬ľ£¨»ÁŌ¬Õľňý ĺ°£ń¨»Ō«ťŅŲŌ¬
undo logīśīĘ‘ŕŌĶÕ≥ĪŪŅ’ľš ibdata1 ÷–°£
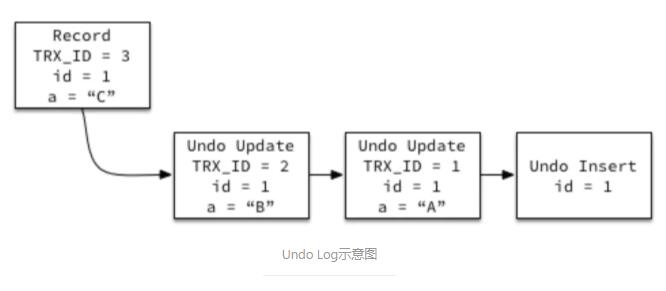
CREATE TABLE
`t3` (
`id` int(11) NOT NULL,
`a` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into t3 values(1, 'A');
update t3 set a='B' where id=1;
update t3 set a='C' where id=1; |
≤Ś»Ž“ĽŐű żĺ›ļů£¨Ņ…“‘∑ĘŌ÷ĶĪ«į t3.ibd őńľĢ÷–Ķńľ«¬ľ « (1, 'A')£¨∂Ý Undo Logīň Ī”–“ĽŐű
insert Ķńľ«¬ľ°£»ÁŌ¬£ļ
root@stretch:/var/lib/mysql#
innodb_space -s ibdata1 -T test/t3 -p 3 -R 127
record-history
Transaction Type Undo record
(n/a) insert (id=1) °ķ () |
÷ī––ļů√śĶńupdate”Ôĺš£¨Ņ…“‘ŅīĶĹ undo log»ÁŌ¬£ļ
root@stretch:/var/lib/mysql#
innodb_space -s ibdata1 -T test/t3 -p 3 -R 127
record-history
Transaction Type Undo record
2333 update_existing (id=1) °ķ (a="B")
2330 update_existing (id=1) °ķ (a="A")
(n/a) insert (id=1) °ķ () |
–Ť“™◊Ę“‚Ķń «£¨Undo Log ‘ŕ ¬őŮ÷ī––Ļż≥Ő÷–ĺÕĽŠ≤ķ…ķ£¨ ¬őŮŐŠĹĽļů≤ŇĽŠ≥÷ĺ√ĽĮ£¨»ÁĻŻ ¬őŮĽōĻŲŃň‘ÚUndo
Log“≤ĽŠ…ĺ≥ż°£
ŃŪÕ‚£¨…ĺ≥żľ«¬ľ≤Ę≤ĽĽŠŃĘľī‘ŕĪŪŅ’ľš÷–…ĺ≥żł√ľ«¬ľ£¨∂Ý÷Ľ «◊ŲłŲĪÍľ«(delete-mark)£¨’ś’żĶń…ĺ≥ż‘Ú «Ķ»”…ļůŐ®‘ň––Ķń
purge ĹÝ≥Őī¶ņŪ°£≥żŃň√ŅŐűľ«¬ľ”–Undo LogĶńŃ–ĪŪÕ‚£¨’ŻłŲ żĺ›Ņ‚“≤ĽŠ”–“ĽłŲņķ ∑Ń–ĪŪ£¨purge
ĹÝ≥ŐĽŠłý図√ņķ ∑Ń–ĪŪ’ś’ż…ĺ≥ż“—ĺ≠√Ľ”–‘ŔĪĽ∆šňŻ ¬őŮ Ļ”√Ķń delete-mark Ķńľ«¬ľ°£purge
ĹÝ≥ŐĽŠ…ĺ≥żł√ľ«¬ľ“‘ľįł√ľ«¬ľĶń Undo Log°£
ňę–īĽļ≥Ś
Ō»ĽōĻňŌ¬InnoDBĶńľ«¬ľłŁ–¬Ńų≥Ő£ļŌ»‘ŕBuffer Pool÷–łŁ–¬£¨≤ĘĹ곣–¬ľ«¬ľĶĹ Redo Log
őńľĢ÷–£¨Buffer Pool÷–Ķńľ«¬ľĽŠĪÍľ«ő™‘ŗ żĺ›≤Ę∂®∆ŕňĘĶĹīŇŇŐ°£”…”ŕInnoDBń¨»ŌPageīů–° «16KB£¨∂ÝīŇŇŐÕ®≥£“‘…»«Ýő™Ķ•őĽ–ī»Ž£¨√Ņīőń¨»Ō÷Ľń‹–ī»Ž512łŲ◊÷Ĺŕ£¨őř∑®Ī£÷§16K żĺ›Ņ…“‘‘≠◊”Ķń–ī»Ž°£»ÁĻŻ–ī»ŽĻż≥Ő∑Ę…ķĻ ’Ō(Ī»»ÁĽķ∆ųĶŰĶÁĽÚ’Ŗ≤Ŕ◊ųŌĶÕ≥Īņņ£)£¨ĽŠ≥ŲŌ÷“≥Ķń≤Ņ∑÷–ī»Ž(partial
page writes)£¨Ķľ÷¬ń—“‘Ľ÷łī°£“Úő™ MySQL Ķń÷ō◊Ų»’÷ĺ≤…”√Ķń «őÔņŪ¬Ŗľ≠»’÷ĺ£¨ľī“≥ľš «őÔņŪ–ŇŌĘ£¨∂Ý“≥ńŕ «¬Ŗľ≠–ŇŌĘ£¨‘ŕ∑Ę…ķ“≥≤Ņ∑÷–ī»Ž Ī£¨őř∑®»∑»Ō żĺ›“≥ĶńĺŖŐŚ–řłń∂ÝĶľ÷¬ń—“‘Ľ÷łī°£
MySQL Ķń żĺ›“≥‘ŕ’ś’ż–ī»ŽĶĹĪŪŅ’ľšőńľĢ«į£¨ĽŠŌ»–īĶĹŌĶÕ≥ĪŪŅ’ľšőńľĢĶń“Ľ∂őѨ–Ý«Ý”Úňę–īĽļ≥Ś(Double-Write
Buffer£¨ń¨»Ōīů–°ő™ 2MB£¨128łŲ“≥)≤Ę fsync ¬šŇŐ£¨Ķ»ňę–īĽļ≥Ś–ī»Ž≥…Ļ¶ļů≤ŇĽŠĹę żĺ›“≥–īĶĹ Ķľ ĪŪŅ’ľšĶńőĽ÷√°£“Úő™ňę–īĽļ≥ŚļÕ żĺ›“≥Ķń–ī»Ž ĪĽķ≤Ľ“Ľ÷¬£¨»ÁĻŻ‘ŕ–ī»Žňę–īĽļ≥Ś≥ŲīŪ£¨Ņ…“‘÷ĪĹ”∂™∆ķł√Ľļ≥Ś“≥£¨∂Ý»ÁĻŻ «–ī»Ž żĺ›“≥ Ī≥ŲīŪ£¨‘ÚŅ…“‘łýĺ›ňę–īĽļ≥Ś«Ý żĺ›Ľ÷łīĪŪŅ’ľšőńľĢ°£
4 InnoDB ¬őŮłŰņŽľ∂Īū
InnoDBĶń∂ŗįśĪĺ≤Ę∑ĘŅō÷∆ «Ľý”ŕ ¬őŮłŰņŽľ∂Īū ĶŌ÷Ķń£¨∂Ý ¬őŮłŰņŽľ∂Īū‘Ú «“ņÕ–«į√śŐŠĶĹĶń Undo Log
ĶŌ÷Ķń°£ĶĪ∂Ń»°“ĽłŲ żĺ›ľ«¬ľ Ī£¨√ŅłŲ ¬őŮĽŠ Ļ”√“ĽłŲ∂Ń ”Õľ(Read View)£¨∂Ń ”Õľ”√”ŕŅō÷∆ ¬őŮń‹∂Ń»°ĶĹĶńľ«¬ľĶńįśĪĺ°£
InnoDBĶń ¬őŮłŰņŽľ∂Īū∑÷ő™£ļRead UnCommitted£¨Read Committed£¨Repeatable
Read“‘ľįSerializable°£∆š÷–Serializable «Ľý”ŕňÝ ĶŌ÷Ķńīģ––ĽĮ∑Ĺ Ĺ£¨—ŌłŮņīňĶ≤Ľ « ¬őŮŅ…ľŻ–‘∑∂≥Ž°£
Read Uncommitted£ļőīŐŠĹĽ∂Ń“≤≥∆ő™‘ŗ∂Ń£¨ňŁ∂Ń»°Ķń «ĶĪ«į◊Ó–¬–řłńĶńľ«¬ľ£¨ľīĪ„’‚łŲ–řłń◊Óļů≤Ęőī…ķ–ß°£
Read Committed£ļŐŠĹĽ∂Ń°£ňŁĽý”ŕĶń «ĶĪ«į ¬őŮńŕĶń”ÔĺšŅ™ ľ÷ī–– ĪĶń◊ÓīůĶń ¬őŮID°£»ÁĻŻ∆šňŻ ¬őŮ–řłńÕ¨“ĽłŲľ«¬ľ£¨‘ŕ√Ľ”–ŐŠĹĽ«į£¨‘Úł√”Ôĺš∂Ń»°Ķńľ«¬ľĽĻ «≤ĽĽŠĪš°£Ķę «’‚÷÷«ťŅŲĽŠ≤ķ…ķ≤ĽŅ…÷ōłī∂Ń£¨ľī“ĽłŲ ¬őŮńŕ∂ŗīő∂Ń»°Õ¨“ĽŐűľ«¬ľŅ…ń‹Ķ√ĶĹ≤ĽÕ¨ĶńĹŠĻŻ(ł√ľ«¬ľĪĽ∆šňŻ ¬őŮ–řłń≤ĘŐŠĹĽŃň)°£
Repeatable Read£ļŅ…÷ōłī∂Ń°£ňŁĽý”ŕĶń « ¬őŮŅ™ ľ ĪĶń∂Ń ”Õľ£¨÷ĪĶĹ ¬őŮĹŠ Ý°£≤Ľ∂Ń»°∆šňŻ–¬Ķń ¬őŮ∂‘ł√ľ«¬ľĶń–řłń£¨Ī£÷§Õ¨“ĽłŲ ¬őŮńŕĶńŅ…÷ōłī∂Ń»°°£InnoDBŐŠĻ©Ńň
next-key lockņīĹ‚ĺŲĽ√∂Ńő Ő‚£¨≤ĽĻż‘ŕ“Ľ–©Őō ‚≥°ĺįŌ¬£¨Ņ…÷ōłī∂ŃĽĻ «Ņ…ń‹≥ŲŌ÷Ľ√∂ŃĶń«ťŅŲ°£‘ŕ Ķľ Ņ™∑Ę÷–”įŌž≤Ľīů£¨ĺÕ≤Ľ◊ł ŲŃň°£
5 InnoDB ļÕ ACID ń£–Õ
¬őŮ”– ACID ňńłŲ Ű–‘£¨ InnoDB «÷ß≥÷ ¬őŮĶń£¨ňŁ ĶŌ÷ ACID ĶńĽķ÷∆»ÁŌ¬£ļ
Atomicity
innodbĶń‘≠◊”–‘÷ų“™ «Õ®ĻżŐŠĻ©Ķń ¬őŮĽķ÷∆ ĶŌ÷£¨”Ž‘≠◊”–‘ŌŗĻōĶńŐō–‘”–£ļ
Autocommit …Ť÷√°£
COMMIT ļÕ ROLLBACK ”Ôĺš(Õ®Ļż Undo Log ĶŌ÷)°£
Consistency
innodbĶń“Ľ÷¬–‘÷ų“™ «÷łĪ£Ľ§ żĺ›≤Ľ ‹ŌĶÕ≥Īņņ£”įŌž£¨ŌŗĻōŐō–‘įŁņ®£ļ
InnoDB Ķńňę–īĽļ≥Ś«Ý(doublewrite buffer)°£
InnoDB ĶńĻ ’ŌĽ÷łīĽķ÷∆(crash recovery)°£
Isolation
innodbĶńłŰņŽ–‘“≤ «÷ų“™Õ®Ļż ¬őŮĽķ÷∆ ĶŌ÷£¨ŐōĪū «ő™ ¬őŮŐŠĻ©Ķń∂ŗ÷÷łŰņŽľ∂Īū£¨ŌŗĻōŐō–‘įŁņ®£ļ
Autocommit…Ť÷√°£
SET ISOLATION LEVEL ”Ôĺš°£
InnoDB ňÝĽķ÷∆°£
Durability
innodbĶń≥÷ĺ√–‘ŌŗĻōŐō–‘£ļ
Redo log°£
ňę–īĽļ≥ŚĻ¶ń‹°£Ņ…“‘Õ®ĻżŇš÷√ŌÓ innodb_doublewrite Ņ™∆ŰĽÚ’ŖĻōĪ’°£
Ňš÷√ innodb_flush_log_at_trx_commit°£”√”ŕŇš÷√innodb»Áļő–ī»ŽļÕňĘ–¬
redo »’÷ĺĽļīśĶĹīŇŇŐ°£ń¨»Ōő™1£¨ĪŪ ĺ√Ņīő ¬őŮŐŠĹĽ∂ľĽŠĹę»’÷ĺĽļīś–ī»Ž≤ĘňĘĶĹīŇŇŐ°£innodb_flush_log_at_timeout
Ņ…“‘Ňš÷√ňĘ–¬»’÷ĺĽļīśĶĹīŇŇŐĶń∆Ķ¬ £¨ń¨»Ō «1√Ž°£
Ňš÷√ sync_binlog°£”√”ŕ…Ť÷√Õ¨≤Ĺ binlog ĶĹīŇŇŐĶń∆Ķ¬ £¨ő™0ĪŪ ĺĹŻ÷ĻMySQLÕ¨≤ĹbinlogĶĹīŇŇŐ£¨binlogňĘĶĹīŇŇŐĶń∆Ķ¬ ”…≤Ŕ◊ųŌĶÕ≥ĺŲ∂®£¨–‘ń‹◊Óļ√Ķę «◊Ó≤Ľį≤»ę°£ő™1ĪŪ ĺ√Ņīő ¬őŮŐŠĹĽ«įÕ¨≤ĹĶĹīŇŇŐ£¨–‘ń‹◊Ó≤ÓĶę «◊Óį≤»ę°£MySQLőńĶĶÕ∆ľŲ «
sync_binlog ļÕ innodb_flush_log_at_trx_commit ∂ľ…Ť÷√ő™
1°£
≤Ŕ◊ųŌĶÕ≥Ķń fsync ŌĶÕ≥Ķų”√°£
| 







