| БрМЭЦМі: |
БОЮФНщЩмСЫInnoDBЪЧЪТЮёАВШЋЕФMySQLДцДЂв§ЧцЃЌжЇГжACIDЪТЮёЁЃInnoDBЬхЯЕМмЙЙКЭInnoDBживЊЬиадЁЃ
БОЮФРДздгкжЊКѕЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ
|
|
вЛЁЂв§бд
дкMySQLзіЭъгХЛЏЙЄзїКѓЃЌеце§жДааSQLгяОфЕФВПМўЪЧДцДЂв§ЧцЁЃдкMySQLжкЖрв§ЧцжЎжаЃЌInnoDBЪЧФПЧАФЌШЯЕФДцДЂв§ЧцЃЌвВЪЧЪЙгУзюЙуЗКЕФв§ЧцЁЃ
InnoDBЪЧЪТЮёАВШЋЕФMySQLДцДЂв§ЧцЃЌжЇГжACIDЪТЮёЁЃЦфЩшМЦФПБъжївЊУцЯђдкЯпЪТЮёДІРэ(OLTP)ЕФгІгУЁЃЦфЬиЕуЪЧааЫјЩшМЦЁЂжЇГжЭтМќЃЌВЂжЇГжЗЧЫјЖЈЖСЃЌМДФЌШЯЖСВйзїВЛЛсВњЩњЫјЁЃInnoDBДцДЂЪ§ОнЪЧЛљгкДХХЬДцДЂЕФ,ЧвЦфМЧТМЪЧАДеевГЕФЗНЪННјааЙмРэЁЃФЧУДНЋв§ГіШчЯТвЩЮЪЃК
ЕБЧАЕФДХХЬЫйЖШКЭCPUжЎМфгЕгавЛЬѕОоДѓЕФКшЙЕЃЌInnoDBШчКЮНтОіЃПЁЃ
Ъ§ОнПтЖдЪ§ОнНјааВйзїЃЈВщбЏЃЌаоИФЃЌВхШыЃЉЪБЃЌЪ§ОндкДХХЬЩЯЕФЮЛжУЪЧЫцЛњЕФЃЌНЋЛсИќМггАЯьВйзїЪ§ОнЕФадФмЃЌInnoDBгжЪЧШчКЮНтОіЕФЃП
еыЖдЮЪЬт1ЃЌЗЧГЃгааЇЕФАьЗЈЪЧв§ШыЛКДцРДНтОіЃЌЕЋЪЧв§ШыЛКДцКѓЃЌЛсЕМжТЛКДцЪ§ОнКЭДХХЬЪ§ОнвЛжТадКЭMySQLЗЧе§ГЃЫРЭіЪБЛКДцЪ§ОнЖЊЪЇЕФЮЪЬтЁЃ
InnoDBгаФФаЉживЊЬиадЃП
ЖўЁЂInnoDBЬхЯЕМмЙЙ
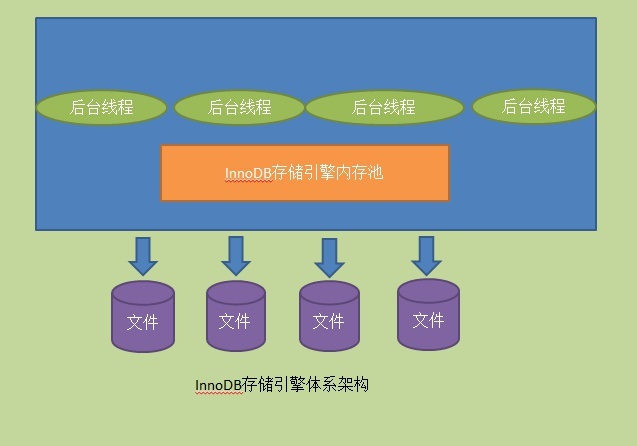
ШчЭМЫљЪОЃЌInnoDBДцДЂв§ЧцгЩФкДцГиКЭвЛаЉКѓЬЈЯпГЬзщГЩЃЌЦфИїзджївЊЕФЙЄзїЪЧЃК
ФкДцГижївЊЙЄзї
ЮЌЛЄЫљгаНјГЬ/ЯпГЬашвЊЗУЮЪЕФЖрИіФкВПЪ§ОнНсЙЙ
ЛКДцДХХЬЩЯЕФЪ§ОнЃЌЗНБуПьЫйЖСШЁЃЌЭЌЪБдкЖдДХХЬЮФМўаоИФжЎЧАНјааЛКДц
ЛКДцжизіШежОЃЈredo logЃЉ
КѓЬЈЯпГЬжївЊЙЄзї
ЫЂаТФкДцГижаЕФЪ§ОнЃЌБЃжЄЛКГхГижаЛКДцЕФЪ§ОнзюаТ
НЋвбаоИФЪ§ОнЮФМўЫЂаТЕНДХХЬЮФМў
БЃжЄЪ§ОнПтвьГЃЪБInnoDBФмЛжИДЕНе§ГЃдЫаазДЬЌ
2.1ЁЂ InnoDBФкДцГи
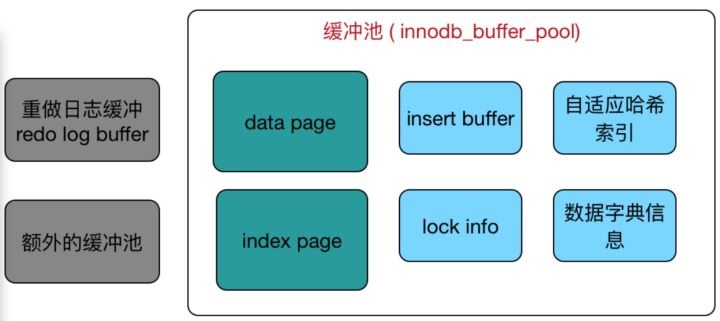
2.1.1. InnoDBФкДцГиМмЙЙЭМ
2.1.2ЁЂ ЛКГхГи
InnoDBЛКГхГиЪЧЮЊСЫЭЈЙ§ФкДцЕФЫйЖШРДУжВЙДХХЬЫйЖШТ§ЖдЪ§ОнПтадФмдьГЩЕФгАЯьЁЃЦфЙЄзїЗНЪНзмЪЧНЋЪ§ОнПтЮФМўАДвГЃЈУПвГ16KЃЉЖСШЁЕНЛКГхГиЃЌШЛКѓАДзюНќзюЩйЪЙгУЃЈLRUЃЉЕФЫуЗЈРДБЃСєдкЛКГхГижаЕФЛКДцЪ§ОнЁЃдкЪ§ОнПтжаНјааЖСВйзїЪБЃЌЪзЯШНЋДгДХХЬЖСЕНЕФвГДцЗХдкЛКГхГижаЃЌЯТвЛДЮЖСШЁЯрЭЌЕФвГЪБЃЌЪзЯШХаЖЈЪЧЗёДцдкЛКГхГижаЃЌШчЙћгаОЭЪЧБЛУќжажБНгЖСШЁЃЌУЛгаЕФЛАОЭДгДХХЬжаЖСШЁЁЃдкЪ§ОнПтНјааИФВйзїЪБЃЌЪзЯШаоИФЛКГхГижаЕФвГЃЈаоИФКѓЃЌИУвГМДЮЊдрвГЃЉЃЌШЛКѓдквдвЛЖЈЕФЦЕТЪЫЂаТЕНДХХЬЩЯЁЃетРяЕФЫЂаТЛњжЦВЛЪЧУПвГдкЗЂЩњБфИќЪБДЅЗЂЁЃЖјЪЧЭЈЙ§вЛжжcheckpointЛњжЦЫЂаТЕНДХХЬЕФЁЃ
ЫљвдЛКГхГиЕФДѓаЁжБНггАЯьзХЪ§ОнПтЕФећЬхадФмЃЌПЩвдЭЈЙ§ХфжУВЮЪ§innodb_buffer_pool_sizeРДЩшжУЁЃ
ДгМмЙЙЭМжаПЩвдПДГіЛКГхГижаЛКДцЕФЪ§ОнвГРраЭга:Ыїв§вГЁЂЪ§ОнвГЁЂ undo вГЁЂВхШыЛКГхЁЂздЪЪгІЙўЯЃЫїв§ЁЂ
InnoDB ЕФЫјаХЯЂЁЂЪ§ОнзжЕфаХЯЂЕШЁЃЫїв§вГКЭЪ§ОнвГеМЛКГхГиЕФКмДѓвЛВПЗжЁЃ
Ъ§ОнвГКЭЫїв§вГ: PageЪЧInnodbДцДЂЕФзюЛљБОНсЙЙЃЌвВЪЧInnodbДХХЬЙмРэЕФзюаЁЕЅЮЛЃЌгыЪ§ОнПтЯрЙиЕФЫљгаФкШнЖМДцДЂдкPageНсЙЙРяЁЃPageЗжЮЊМИжжРраЭЃЌЪ§ОнвГКЭЫїв§вГОЭЪЧЦфжазюЮЊживЊЕФСНжжРраЭЁЃ
ВхШыЛКДц: дкInnoDBв§ЧцЩЯНјааВхШыВйзїЪБЃЌвЛАуашвЊАДеежїМќЫГађНјааВхШыЃЌетбљВХФмЛёЕУНЯИпЕФВхШыадФмЁЃЕБвЛеХБэжаДцдкЗЧОлДиЕФЧвВЛЮЈвЛЕФЫїв§ЪБЃЌдкВхШыЪБЃЌЪ§ОнвГЕФДцЗХЛЙЪЧАДеежїМќНјааЫГађДцЗХЃЌЕЋЪЧЖдгкЗЧОлДиЫїв§вЖНкЕуЕФВхШыВЛдйЪЧЫГађЕФСЫЃЌетЪБОЭашвЊРыЩЂЕФЗУЮЪЗЧОлДиЫїв§вГЃЌгЩгкЫцЛњЖСШЁЕФДцдкЕМжТВхШыВйзїадФмЯТНЕЁЃ
InnoDBЮЊДЫЩшМЦСЫInsert BufferРДНјааВхШыгХЛЏЁЃЖдгкЗЧОлДиЫїв§ЕФВхШыЛђепИќаТВйзїЃЌВЛЪЧУПвЛДЮЖМжБНгВхШыЕНЫїв§вГжаЃЌЖјЪЧЯШХаЖЯВхШыЕФЗЧОлМЏЫїв§ЪЧЗёдкЛКГхГижаЃЌШєдкЃЌдђжБНгВхШыЃЛШєВЛдкЃЌдђЯШЗХШыЕНвЛИіInsert
BufferжаЁЃПДЫЦЪ§ОнПтетИіЗЧОлМЏЕФЫїв§вбОВщЕНвЖНкЕуЃЌЖјЪЕМЪУЛгаЃЌетЪБДцЗХдкСэЭтвЛИіЮЛжУЁЃШЛКѓдйвдвЛЖЈЕФЦЕТЪКЭЧщПіНјааInsert
BufferКЭЗЧОлДиЫїв§вГзгНкЕуЕФКЯВЂВйзїЁЃетЪБЭЈГЃФмЙЛНЋЖрИіВхШыКЯВЂЕНвЛИіВйзїжаЃЌетбљОЭДѓДѓЬсИпСЫЖдгкЗЧОлДиЫїв§ЕФВхШыадФмЁЃ
здЪЪгІЙўЯЃЫїв§: InnoDBЛсИљОнЗУЮЪЕФЦЕТЪКЭФЃЪНЃЌЮЊШШЕувГНЈСЂЙўЯЃЫїв§ЃЌРДЬсИпВщбЏаЇТЪЁЃInnoDBДцДЂв§ЧцЛсМрПиЖдБэЩЯИїИіЫїв§вГЕФВщбЏЃЌШчЙћЙлВьЕННЈСЂЙўЯЃЫїв§ПЩвдДјРДЫйЖШЩЯЕФЬсЩ§ЃЌдђНЈСЂЙўЯЃЫїв§ЃЌЫљвдНазіздЪЪгІЙўЯЃЫїв§ЁЃ
здЪЪгІЙўЯЃЫїв§ЪЧЭЈЙ§ЛКГхГиЕФB+ЪївГЙЙНЈЖјРДЃЌвђДЫНЈСЂЫйЖШКмПьЃЌЖјЧвВЛашвЊЖдећеХЪ§ОнБэНЈСЂЙўЯЃЫїв§ЁЃЦф
гавЛИівЊЧѓЃЌМДЖдетИівГЕФСЌајЗУЮЪФЃЪНБиаыЪЧвЛбљЕФЃЌвВОЭЪЧЫЕЦфВщбЏЕФЬѕМў(WHERE)БиаыЭъШЋвЛбљЃЌЖјЧвБиаыЪЧСЌајЕФЁЃ
ЫјаХЯЂ : nnoDBДцДЂв§ЧцЛсдкааМЖБ№ЩЯЖдБэЪ§ОнНјааЩЯЫјЁЃВЛЙ§InnoDBвВЛсдкЪ§ОнПтФкВПЦфЫћКмЖрЕиЗНЪЙгУЫјЃЌДгЖјдЪаэЖдЖржжВЛЭЌзЪдДЬсЙЉВЂЗЂЗУЮЪЁЃЪ§ОнПтЯЕЭГЪЙгУЫјЪЧЮЊСЫжЇГжЖдЙВЯэзЪдДНјааВЂЗЂЗУЮЪЃЌЬсЙЉЪ§ОнЕФЭъећадКЭвЛжТадЁЃЙигкЫјЕФОпЬхжЊЪЖЮвУЧжЎКѓдйНјааЯъЯИбЇЯАЁЃ
Ъ§ОнзжЕфаХЯЂ : InnoDBгаздМКЕФБэЛКДцЃЌПЩвдГЦЮЊБэЖЈвхЛКДцЛђепЪ§ОнзжЕфЁЃЕБInnoDBДђПЊвЛеХБэЃЌОЭдіМгвЛИіЖдгІЕФЖдЯѓЕНЪ§ОнзжЕфЁЃ
Ъ§ОнзжЕфЪЧЖдЪ§ОнПтжаЕФЪ§ОнЁЂПтЖдЯѓЁЂБэЖдЯѓЕШЕФдЊаХЯЂЕФМЏКЯЁЃдкMySQLжаЃЌЪ§ОнзжЕфаХЯЂФкШнОЭАќРЈБэНсЙЙЁЂЪ§ОнПтУћЛђБэУћЁЂзжЖЮЕФЪ§ОнРраЭЁЂЪгЭМЁЂЫїв§ЁЂБэзжЖЮаХЯЂЁЂДцДЂЙ§ГЬЁЂДЅЗЂЦїЕШФкШнЁЃMySQL
INFORMATION_SCHEMAПтЬсЙЉСЫЖдЪ§ОнОждЊЪ§ОнЁЂЭГМЦаХЯЂЁЂвдМАгаЙиMySQL serverЕФЗУЮЪаХЯЂЃЈР§ШчЃКЪ§ОнПтУћЛђБэУћЃЌзжЖЮЕФЪ§ОнРраЭКЭЗУЮЪШЈЯоЕШЃЉЁЃИУПтжаБЃДцЕФаХЯЂвВПЩвдГЦЮЊMySQLЕФЪ§ОнзжЕфЁЃ
2.1.3. жизіШежОГхГи
InnoDBгаbuffer poolЃЈМђГЦbpЃЉЁЃbpЪЧЪ§ОнПтвГУцЕФЛКДцЃЌЖдInnoDBЕФШЮКЮаоИФВйзїЖМЛсЪзЯШдкbpЕФpageЩЯНјааЃЌШЛКѓетбљЕФвГУцНЋБЛБъМЧЮЊdirtyВЂБЛЗХЕНзЈУХЕФflush
listЩЯЃЌКѓајНЋгЩmaster threadЛђзЈУХЕФЫЂдрЯпГЬНзЖЮадЕФНЋетаЉвГУцаДШыДХХЬЃЈdisk
or ssdЃЉЁЃетбљЕФКУДІЪЧБмУтУПДЮаДВйзїЖМВйзїДХХЬЕМжТДѓСПЕФЫцЛњIOЃЌНзЖЮадЕФЫЂдрПЩвдНЋЖрДЮЖдвГУцЕФаоИФmergeГЩвЛДЮIOВйзїЃЌЭЌЪБвьВНаДШывВНЕЕЭСЫЗУЮЪЕФЪБбгЁЃШЛЖјЃЌШчЙћдкdirty
pageЛЙЮДЫЂШыДХХЬЪБЃЌserverЗЧе§ГЃЙиБеЃЌетаЉаоИФВйзїНЋЛсЖЊЪЇЃЌШчЙћаДШыВйзїе§дкНјааЃЌЩѕжСЛсгЩгкЫ№ЛЕЪ§ОнЮФМўЕМжТЪ§ОнПтВЛПЩгУЁЃЮЊСЫБмУтЩЯЪіЮЪЬтЕФЗЂЩњЃЌInnodbНЋЫљгаЖдвГУцЕФаоИФВйзїаДШывЛИізЈУХЕФЮФМўЃЌВЂдкЪ§ОнПтЦєЖЏЪБДгДЫЮФМўНјааЛжИДВйзїЃЌетИіЮФМўОЭЪЧredo
log fileЁЃетбљЕФММЪѕЭЦГйСЫbpвГУцЕФЫЂаТЃЌДгЖјЬсЩ§СЫЪ§ОнПтЕФЭЬЭТЃЌгааЇЕФНЕЕЭСЫЗУЮЪЪБбгЁЃДјРДЕФЮЪЬтЪЧЖюЭтЕФаДredo
logВйзїЕФПЊЯњЃЈЫГађIOЃЌЕБШЛКмПьЃЉЃЌвдМАЪ§ОнПтЦєЖЏЪБЛжИДВйзїЫљашЕФЪБМфЁЃ
redoШежОгЩСНВПЗжЙЙГЩЃКredo log bufferЁЂredo log fileЁЃinnodbЪЧжЇГжЪТЮёЕФДцДЂв§ЧцЃЌдкЪТЮёЬсНЛЪБЃЌБиаыЯШНЋИУЪТЮёЕФЫљгаШежОаДШыЕНredoШежОЮФМўжаЃЌД§ЪТЮёЕФcommitВйзїЭъГЩВХЫуећИіЪТЮёВйзїЭъГЩЁЃдкУПДЮНЋredo
log bufferаДШыredo log fileКѓЃЌЖМашвЊЕїгУвЛДЮfsyncВйзїЃЌвђЮЊжизіШежОЛКГхжЛЪЧАбФкШнЯШаДШыВйзїЯЕЭГЕФЛКГхЯЕЭГжаЃЌВЂУЛгаШЗБЃжБНгаДШыЕНДХХЬЩЯЃЌЫљвдБиаыНјаавЛДЮfsyncВйзїЁЃвђДЫЃЌДХХЬЕФадФмдквЛЖЈГЬЖШЩЯвВОіЖЈСЫЪТЮёЬсНЛЕФадФмЁЃ
InnoDB ДцДЂв§ЧцЯШНЋжизіШежОаХЯЂЗХШыетИіЛКГхЧј,ШЛКѓвдвЛЖЈЦЕТЪНЋЦфЫЂаТЕНжизіШежОЮФМўЁЃжизіШежОЮФМўвЛАуВЛашвЊЩшжУЕУКмДѓ,вђЮЊдкЯТСаШ§жжЧщПіЯТжизіШежОЛКГхжаЕФФкШнЛсЫЂаТЕНДХХЬЕФжизіШежОЮФМўжаЁЃ
Master Thread УПвЛУыНЋжизіШежОЛКГхЫЂаТЕНжизіШежОЮФМў
УПИіЪТЮяЬсНЛЪБЛсНЋжизіШежОЛКГхЫЂаТЕНжизіШежОЮФМў
ЕБжизіШежОЛКГхЪЃгрПеМфаЁгк1/2ЪБ,жизіШежОЛКГхЫЂаТЕНжизіШежОЮФМў
2.1.4. ЖюЭтЕФЛКГхГи
дк InnoDB ДцДЂв§ЧцжаЃЌЖдвЛаЉЪ§ОнНсЙЙБОЩэЕФФкДцНјааЗжХфЪБЃЌашвЊДгЖюЭтЕФФкДцГижаНјааЩъЧыЁЃР§Шч:
ЗжХфСЫЛКГхГи,ЕЋЪЧУПИіЛКГхГижаЕФжЁЛКГхЛЙгаЖдгІЕФЛКГхПижЦЖдЯѓЃЌетаЉЖдЯѓМЧТМвдвЛаЉжюШч LRU, Ыј,ЕШД§ЕШаХЯЂ,ЖјетИіЖдЯѓЕФФкДцашвЊДгЖюЭтЕФФкДцГижаЩъЧыЁЃ
2.2 жївЊКѓЬЈЯпГЬ
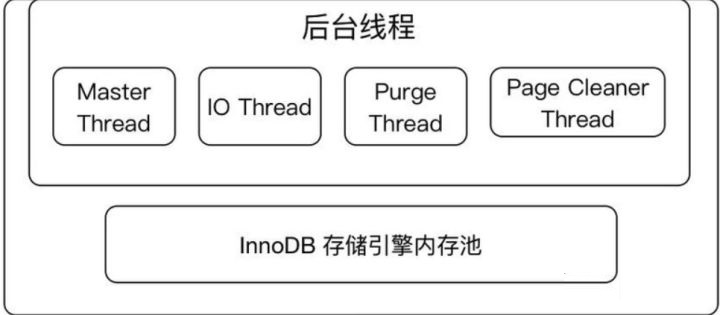
2.2.1. master thread
КЫаФЕФКѓЬЈЯпГЬЃЌжївЊИКд№НЋЛКГхГижаЕФЪ§ОнвьВНЫЂаТЕНДХХЬЃЌБЃжЄЪ§ОнЕФвЛжТадЃЌАќРЈдрвГЕФЫЂаТЁЂКЯВЂВхШыЛКГхЁЂundoвГЕФЛиЪеЕШЁЃ
Master threadдкжїбЛЗжаЃЌЗжСНДѓВПЗжВйзїЃЌУПУыжгЕФВйзїКЭУП10УыжгЕФВйзїЃК
УПУывЛДЮЕФВйзї
ШежОЛКГхЫЂаТЕНДХХЬ: МДЪЙетИіЪТЮёЛЙУЛгаЬсНЛЃЈзмЪЧЃЉЃЌетЕуНтЪЭСЫЮЊЪВУДдйДѓЕФЪТЮёcommitЪБЖМКмПьЃЛ
КЯВЂВхШыЛКГхЃЈПЩФмЃЉ: КЯВЂВхШыВЂВЛЪЧУПУыЖМЗЂЩњЃЌInnoDBЛсХаЖЯЕБЧАвЛУыФкЗЂЩњЕФIOДЮЪ§ЪЧЗёаЁгк5ЃЌШчЙћЪЧЃЌдђЯЕЭГШЯЮЊЕБЧАЕФIOбЙСІКмаЁЃЌПЩвджДааКЯВЂВхШыЛКГхЕФВйзїЁЃ
жСЖрЫЂаТ100ИіInnoDBЕФЛКГхГиЕФдрвГЕНДХХЬЃЈПЩФм) : етИіЫЂаТ100ИідрвГвВВЛЪЧУПУыЖМдкзіЃЌInnoDBв§ЧцЭЈЙ§ХаЖЯЕБЧАЛКГхГижадрвГЕФБШР§(buf_get_modified_ratio_pct)ЪЧЗёГЌЙ§СЫХфжУЮФМўжаinnodb_max_drity_pages_pctВЮЪ§(ФЌШЯЪЧ90ЃЌМД90%)ЃЌШчЙћГЌЙ§СЫетИіуажЕЃЌInnoDBв§ЧцШЯЮЊашвЊзіДХХЬЭЌВНВйзїЃЌНЋ100ИідрвГаДШыДХХЬЁЃ
УП10УывЛДЮЕФВйзї
ЫЂаТ100ИідрвГЕНДХХЬЃЈПЩФмЃЉ: InnoDBв§ЧцЯШХаЖЯЙ§ШЅ10УыФкДХХЬЕФIOВйзїЪЧЗёаЁгк200ДЮЃЌШчЙћЪЧЃЌШЯЮЊЕБЧАДХХЬгазуЙЛЕФIOВйзїФмСІЃЌМДНЋ100ИідрвГЫЂаТЕНДХХЬЁЃ
КЯВЂжСЖр5ИіВхШыЛКГхЃЈзмЪЧЃЉ: ДЫДЮЕФКЯВЂВхШыЛКГхВйзїзмЛсжДааЃЌВЛЭЌгкУПУыВйзїЪБПЩФмЗЂЩњЕФКЯВЂВйзїЁЃ
НЋШежОЛКГхЫЂаТЕНДХХЬЃЈзмЪЧЃЉ: InnoDBв§ЧцЛсдйДЮжДааШежОЛКГхЫЂаТЕНДХХЬЕФВйзїЃЌгыУПУыЗЂЩњЕФВйзївЛбљЁЃ
ЩОГ§ЮогУЕФundoвГЃЈзмЪЧЃЉ: ЕБЖдБэжДааupdateЃЌdeleteВйзїЪБЃЌдЯШЕФааЛсБЛБъМЧЮЊЩОГ§ЃЌЕЋЪЧЮЊСЫвЛжТадЖСЕФЙиЯЕЃЌашБЃСєетаЉааАцБОЕФаХЯЂЃЌдкНјаа10SвЛДЮЕФЩОГ§ВйзїЪБЃЌInnoDBв§ЧцЛсХаЖЯЕБЧАЪТЮёЯЕЭГжавбБЛЩОГ§ЕФааЪЧЗёПЩвдЩОГ§ЃЌШчЙћПЩвдЃЌInnoDBЛсСЂМДНЋЦфЩОГ§ЁЃInnoDBУПДЮзюЖрЩОГ§20ИіUndoвГЁЃ
ВњЩњвЛИіМьВщЕуЃЈcheckpoingЃЉЃЛ
2.2.2. IO threads
дк InnoDB ДцДЂв§ЧцжаДѓСПЪЙгУСЫвьВН IO РДДІРэаД IO ЧыЧѓЃЌIO Thread ЕФЙЄзїжївЊЪЧИКд№етаЉ
IO ЧыЧѓЕФЛиЕї.ЁЃЗжБ№ЮЊwriteЁЂreadЁЂinsert bufferКЭlog IO threadЁЃЯпГЬЪ§СППЩвдЭЈЙ§ВЮЪ§НјааЕїећЁЃ5.6вдКѓЕФАцБОПЩвдЭЈЙ§innodb_write_io_threadsКЭinnodb_read_io_threadsРДЯожЦЖСаДЯпГЬЃЌЖјдк5.6АцБОвдЧАЃЌжЛгавЛИіВЮЪ§innodb_file_io_threadsРДПижЦЖСаДзмЯпГЬЪ§ЁЃ
2.2.3. purge threads
ИКд№ЛиЪевбОЪЙгУВЂЗжХфЕФundoвГЃЌpurgeВйзїФЌШЯЪЧгЩmaster threadжаЭъГЩЕФЃЌЮЊСЫМѕЧсmaster
threadЕФЙЄзїЃЌЬсИпcpuЪЙгУТЪвдМАЬсЩ§ДцДЂв§ЧцЕФадФмЁЃгУЛЇПЩвддкВЮЪ§ЮФМўжаЬэМгШчЯТУќСюРДЦєЖЏЖРСЂЕФpurge
threadЁЃ
innodb_purge_threads=1
Дгinnodb1.2АцБОПЊЪМЃЌПЩвджИЖЈЖрИіinnodb_purge_threadsРДНјвЛВНМгПьКЭЬсИпundoЛиЪеЫйЖШЁЃ
2.2.4. page cleaner threads
Page Cleaner ThreadЪЧдкInnoDB1.2.XАцБОжав§ШыЕФЁЃЦфзїгУЪЧНЋжЎЧААцБОжадрвГЕФЫЂаТВйзїЖМЗХШыЕНЕЅЖРЕФЯпГЬжаРДЭъГЩЁЃ
ЦфФПЕФЪЧМѕЧсmaster threadЕФЙЄзївдМАЖдгкгУЛЇВщбЏЯпГЬЕФзшШћЃЌНјвЛВНЬсИпInnoDBДцДЂв§ЧцЕФадФмЁЃ
Ш§ЁЂInnoDBживЊЬиад
MySQL InnoDBЭЈЙ§ШчЯТживЊЬиадЪЕЯжСЫИќКУЕФаТФмКЭИќИпЕФЬиад
ВхШыЛКГхЃЈinsert bufferЃЉ
СНДЮаДЃЈDouble writeЃЉ
здЪЪгІЙўЯЃЫїв§ЃЈadaptive hash indexЃЉ
вьВНioЃЈAsync IOЃЉ
ЫЂаТСьНгвГЃЈFlush Neighbor PageЃЉ
3.1 ВхШыЛКГх
3.1.1. ОйИіРѕзг
ЮвУЧШЅЭМЪщЙнЛЙЪщЃЌЖдгІЭМЪщЙнРДЫЕЃЌЫћЪЧзіСЫinsert(діМг)ВйзїЃЌЙмРэдБдк1аЁЪБФкНгЪмСЫ100БОЪщЃЌетЪБКђЫћга2жжзіЗЈАбЛЙЛиРДЕФЪщЙщЮЛЕНЪщМмЩЯ:
1ЃЉУПЛЙЛиРДвЛБОЪщЃЌИљОнетБОЪщЕФБрТыЃЈЪщЙёЧј-ХХ-КХЃЉАбЪщЫЭЛиМмЩЯ
2ЃЉднЪБВЛзіЙщЮЛВйзїЃЌЯШЗХЕНЙёУцЩЯЃЌЕШВЛУІЕФЪБКђЃЌдйАбетаЉЪщАДееЪщЙёЧј-ХХ-КХЯШХХКУЃЌШЛКѓвЛДЮадЙщЮЛ
гУЗНЗЈ1ЃЌЙмРэдБашвЊНјГіЃЈIOЃЉВиЪщЧј100ДЮЃЌВЛЭЃЕФЕЧИпХРЕЭЭъГЩЭМЪщЙщЮЛВйзїЃЌРлЫРРлЛюЃЌаЇТЪКмВюЁЃ
гУЗНЗЈ2ЃЌЙмРэдБжЛашвЊНјГіЃЈIOЃЉВиЪщЧј1ДЮЃЌЖдЭЌвЛИіЮЛжУЕФЪщЃЌВЛЙмЖрЩйЃЌЖМжЛвЊХРвЛДЮТЅЬнЃЌДѓДѓМѕЧсСЫЙмРэдБЕФЙЄзїСПЁЃ
ЫљвдЭМЪщЙнЖМЪЧАДееЗНЗЈ2РДзіЛЙЪщЖЏзїЕФЁЃЕЋЪЧФувЊЫЕЃЌЮвЕФЭМЪщЙнОЭ20БОЪщЃЌ1Иі0.5УзЕФМмзгЃЌЗНЗЈ2КЭ1ЙмРэЦ№РДЖМКмЗНБуЃЌетжжЧщПіВЛдкЮвУЧЬжТлЕФЗЖЮЇЁЃЕБЪ§ОнСПЗЧГЃаЁЕФЪБКђЃЌОЭВЛДцдкаЇТЪЮЪЬтСЫЁЃ
ЙиЯЕЪ§ОнПтдкДІРэВхШыВйзїЕФЪБКђЃЌДІРэЕФЗНЗЈКЭЩЯУцРрЫЦЃЌУПвЛДЮВхШыЖМЯрЕБгкЛЙвЛБОЪщЃЌЫќвВашвЊвЛИіЙёЬЈРДБЃДцВхШыЕФЪ§ОнЃЌШЛКѓЗжРрЙщЕЕЃЌдкВЛУІЕФЪБКђзіХњСПЕФЙщЮЛЁЃетИіЙёЬЈОЭЪЧinsert
buffer.
етОЭЪЧЮЊЪВУДЛсгаinsert bufferЃЌИќЖрЕФЪЧДІгкадФмгХЛЏЕФПМТЧЁЃ
3.1.2. ЪВУДЪЧВхШыЛКГх
insert bufferЪЧвЛжжЬиЪтЕФЪ§ОнНсЙЙЃЈB+ treeЃЉВЂВЛЪЧЛКДцЕФвЛВПЗжЃЌЖјЪЧЮяРэвГЁЃЖдгкЗЧОлМЏЫїв§ЕФВхШыЛђИќаТВйзї,ВЛЪЧУПвЛДЮжБНгВхШыЫїв§вГ.ЖјЪЧЯШХаЖЯВхШыЕФЗЧОлМЏЫїв§вГЪЧЗёдкЛКГхГижа.ШчЙћдк,дђжБНгВхШы,ШчЙћВЛдй,дђЯШЗХШывЛИіВхШыЛКГхЧјжа.ШЛКѓдйвдвЛЖЈЕФЦЕТЪжДааВхШыЛКГхКЭЗЧОлМЏЫїв§вГзгНкЕуЕФКЯВЂВйзї.ЪЙгУЬѕМў:ЗЧОлМЏЫїв§,ЗЧЮЈвЛЃЌдвђШчЯТ:
primary key ЪЧАДееЕндіЕФЫГађНјааВхШыЕФЃЌвьГЃВхШыОлзхЫїв§вЛАувВЫГађЕФЃЌЗЧЫцЛњIOЁЃ
аДЮЈвЛЫїв§вЊМьВщМЧТМЪЧВЛЪЧДцдкЃЌЫљвддкаоИФЮЈвЛЫїв§жЎЧА,БиаыАбаоИФЕФМЧТМЯрЙиЕФЫїв§вГЖСГіРДВХжЊЕРЪЧВЛЪЧЮЈвЛЁЂетбљInsert
bufferОЭУЛвтвхСЫЃЌвЊЖСГіРД(ЫцЛњIO)ЃЌЫљвджЛЖдЗЧЮЈвЛЫїв§гааЇЁЃ
3.1.3. insert bufferЕФдРэ
ЖдгкЮЊЗЧЮЈвЛЫїв§ЃЌИЈжњЫїв§ЕФаоИФВйзїВЂЗЧЪЕЪБИќаТЫїв§ЕФвЖзгвГЃЌЖјЪЧАбШєИЩЖдЭЌвЛвГУцЕФИќаТЛКДцЦ№РДзіЃЌКЯВЂЮЊвЛДЮадИќаТВй
зїЃЌМѕЩйIOЃЌзЊЫцЛњIOЮЊЫГађIO,етбљПЩвдБмУтЫцЛњIOДјРДадФмЫ№КФЃЌЬсИпЪ§ОнПтЕФаДадФмЃЌОпЬхСїГЬ:
1) ЯШХаЖЯвЊИќаТЕФетвЛвГдкВЛдкЛКГхГижа
aЁЂШєдкЃЌдђжБНгВхШыЃЛ
bЁЂШєВЛдкЃЌдђНЋindex page ДцШыInsert BufferЃЌАДееMaster ThreadЕФЕїЖШЙцдђРДКЯВЂЗЧЮЈвЛЫїв§КЭЫїв§вГжаЕФвЖзгНсЕу
2) Master ThreadЕФЕїЖШЙцдђ
aЁЂжїЖЏmerger: innodbжїЯпГЬЖЈЦкЭъГЩЃЌгУЛЇЯпГЬЮоИажЊ
жїЖЏmergeЭЈЙ§innodbжїЯпГЬ(svr_master_threadЃЉХаЖЯЃКШєЙ§ШЅ1sжЎФкЗЂЩњЕФI/OаЁгкЯЕЭГI/OФмСІЕФ5%ЃЌдђжїЖЏНјаавЛДЮinsert
bufferЕФmergeВйзїЁЃmergeЕФвГУцЪ§ЮЊЯЕЭГI/OФмСІЕФ5%ЃЌЖСШЁВЩгУasync ioФЃЪНЁЃУП10s,БиЖЈДЅЗЂвЛДЮinsert
buffer megerВйзїЁЃmegerЕФвГУцЪ§ШдОЩЮЊЯЕЭГ I/OФмСІЕФ5%ЁЃ
жїЯпГЬЗЂГіasync ioЧыЧѓЃЌasyncЖСШЁашвЊБЛmergeЕФЫїв§вГУц
I/O handler ЯпГЬЃЌдкНгЪмЕНЭъГЩЕФasync I/OжЎКѓЃЌНјааmerge
b ЁЂБЛЖЏmerge: гУЛЇЯпГЬЭъГЩЃЌгУЛЇФмИаЪмЕНmegerВйзїДјРДЕФадФмгАЯь
insertВйзїЃЌЕМжТвГУцПеМфВЛзуЃЌашвЊЗжСб(split)ЁЃгЩгкinsert bufferжЛеыЖдЕЅИівГУцЃЌВЛФмbuffer
page split[вГвбОдкФкДцРя]ЃЌвђДЫв§Ц№вГУцЕФБЛЖЏmegerЁЃЭЌРэЃЌupdateВйзїЕМжТвГУцПеМфВЛ
зуЃЛpurgeЕМжТвГУцЮЊПеЕШЁЃзмжЎ,ШєЕБЧАВйзїв§Ц№вГУцsplit or mergeЃЌФЧУДОЭЛсЕМжТБЛЖЏmergeЃЛ
insertВйзїЃЌгЩгкЦфЫќИїжждвђЃЌinsert bufferгХЛЏЗЕЛиfalseЃЌашвЊеце§ЖСШЁpageЪБЃЌвЊНјааБЛЖЏmergeЁЃгывЛВЛЭЌЕФЪЧЃЌвГдкdiskЩЯЃЌашвЊЖСШЁЕНФкДцРяЃЛ
дкНјааinsert bufferВйзїЃЌЗЂЯжinsert bufferЬЋДѓЃЌашвЊбЙЫѕinsert bufferЃЌетЪБашвЊЧПжЦБЛЖЏmergeЃЌВЛдЪаэ
insert ВйзїНјааЁЃ
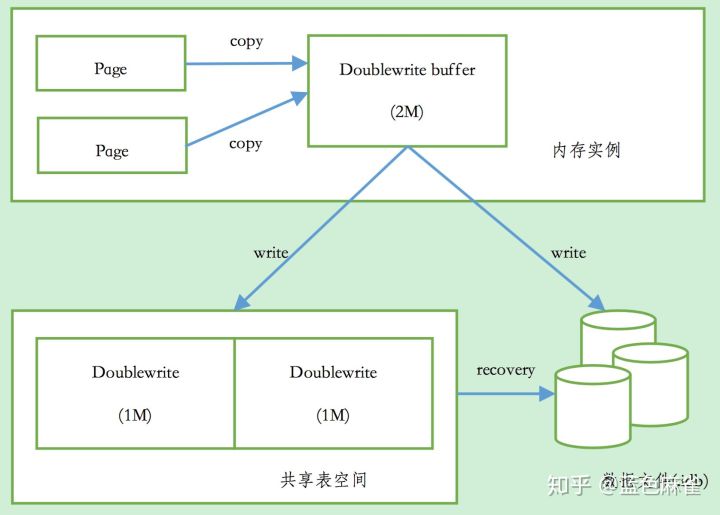
3.2 СНДЮаД
Insert BufferДјИјInnoDBДцДЂв§ЧцЕФЪЧадФмЩЯЕФЬсЩ§ЃЌdoublewriteЃЈСНДЮаДЃЉДјИјInnoDBДцДЂв§ЧцЕФЪЧЪ§ОнвГЕФПЩППадЁЃ
ЕБЗЂЩњЪ§ОнПтхДЛњЪБЃЌПЩФмInnoDBДцДЂв§Чце§дкаДШыФГИівГЕНБэжаЃЌЖјетИівГжЛаДСЫвЛВПЗжЃЌБШШч16KBЕФвГЃЌжЛаДСЫЧА4KBЃЌжЎКѓОЭЗЂЩњСЫхДЛњЃЌетжжЧщПіБЛГЦЮЊВПЗжаДЪЇаЇЃЈpartial
page write)ЁЃдкInnoDBДцДЂв§ЧцЮДЪЙгУdoublewriteММЪѕЧАЃЌдјОГіЯжЙ§вђЮЊВПЗжаДЪЇаЇЖјЕМжТЪ§ОнЖЊЪЇЕФЧщПіЁЃ
гаОбщЕФDBAвВаэЛсЯыЃЌШчЙћЗЂЩњаДЪЇаЇЃЌПЩвдЭЈЙ§жизіШежОНјааЛжИДЁЃетЪЧвЛИіАьЗЈЁЃЕЋЪЧБиаыЧхГўЕиШЯЪЖЕНЃЌжизіШежОжаМЧТМЕФЪЧЖдвГЕФЮяРэВйзїЃЌШчЦЋвЦСП800ЃЌаДЁЎaaaaЁЏМЧТМЁЃШчЙћетИівГБОЩэвбОЗЂЩњСЫЫ№ЛЕЃЌдйЖдЦфНјаажизіЪЧУЛгавтвхЕФЁЃетОЭЪЧЫЕЃЌдкгІгУжизіШежОЧАЃЌгУЛЇашвЊвЛИівГЕФИББОЃЌЕБаДШыЪЇаЇЗЂЩњЪБЃЌЯШЭЈЙ§вГЕФИББОРДЛЙдИУвГЃЌдйНјаажизіЃЌетОЭЪЧdoublewriteЁЃдкInnoDBДцДЂв§ЧцжаdoublewriteЕФЬхЯЕМмЙЙШчЭМЫљЪОЃК
3.3 здЪЪгІЙўЯЃЫїв§
ЙўЯЃЃЈhashЃЉЪЧвЛжжЗЧГЃПьЕФВщевЗНЗЈЃЌдквЛАуЧщПіЯТетжжВщевЕФЪБМфИДдгЖШЮЊO(1)ЃЌМДвЛАуНіашвЊвЛДЮВщевОЭФмЖЈЮЛЪ§ОнЁЃ
ЖјB+ЪїЕФВщевДЮЪ§ЃЌШЁОігкB+ЪїЕФИпЖШЃЌдкЩњВњЛЗОГжаЃЌB+ЪїЕФИпЖШвЛАуЮЊ3~4ВуЃЌЫљвдашвЊ3~4ДЮЕФВщбЏЁЃ
InnoDBДцДЂв§ЧцЛсМрПиЖдБэЩЯИїЫїв§вГЕФВщбЏЁЃШчЙћЙлВьЕННЈСЂЙўЯЃЫїв§ПЩвдДјРДЫйЖШЬсЩ§ЃЌдђНЈСЂЙўЯЃЫїв§ЃЌГЦжЎЮЊздЪЪгІЙўЯЃЫїв§(Adaptive
Hash Index, AHI)ЁЃAHIЪЧЭЈЙ§ЛКГхГиЕФB+ЪївГЙЙдьЖјРДЃЌвђДЫНЈСЂЕФЫйЖШКмПьЃЌЖјЧвВЛашвЊЖдећеХБэЙЙНЈЙўЯЃЫїв§ЁЃInnoDBДцДЂв§ЧцЛсздЖЏИљОнЗУЮЪЕФЦЕТЪКЭФЃЪНРДздЖЏЕиЮЊФГаЉШШЕувГНЈСЂЙўЯЃЫїв§ЁЃ
AHIгавЛИівЊЧѓЃЌЖдетИівГЕФСЌајЗУЮЪФЃЪНБиаыЪЧвЛбљЕФЁЃР§ШчЖдгк(a,b)етбљЕФСЊКЯЫїв§вГЃЌЦфЗУЮЪФЃЪНПЩвдЪЧЯТУцЧщПіЃК
where a=xxx
where a =xxx and b=xxx
ЗУЮЪФЃЪНвЛбљЪЧжИВщбЏЕФЬѕМўЪЧвЛбљЕФЃЌШєНЛЬцНјааЩЯЪіСНжжВщбЏЃЌФЧУДInnoDBДцДЂв§ЧцВЛЛсЖдИУвГЙЙдьAHIЁЃ
AHIЛЙгаЯТУцМИИівЊЧѓЃК
вдИУФЃЪНЗУЮЪСЫ100ДЮ
вГЭЈЙ§ИУФЃЪНЗУЮЪСЫNДЮЃЌЦфжаN=вГжаМЧТМ*1/16
InnoDBДцДЂв§ЧцЙйЗНЮФЕЕЯдЪОЃЌЦєгУAHIКѓЃЌЖСШЁКЭаДШыЫйЖШПЩвдЬсИп2БЖЃЌИЈжњЫїв§ЕФСЌНгВйзїадФмПЩвдЬсИп5БЖЁЃAHIЕФЩшМЦЫМЯыЪЧЪ§ОнПтздгХЛЏЃЌВЛашвЊDBAЖдЪ§ОнПтНјааЪжЖЏЕїећЁЃ
3.4 вьВНIO
sync IO ЃКЭЌВНIO МДУПНјаавЛДЮIOВйзїЃЌДЫДЮВйзїНсЪјВХФмМЬајНгЯТРДЕФВйзїЁЃ ЕЋЪЧШчЙћгУЛЇЗЂашвЊЕШД§ГівЛЬѕЫїв§ЩЈУшЕФВщбЏЃЌФЧУДетЬѕSQLВщбЏгяОфПЩФмашвЊЩЈУшЖрИіЫїв§вГЃЌвВОЭЪЧашвЊНјааЖрДЮЕФIOВйзїЁЃдкУПЩЈУшвЛИівГВЂЕШД§ЦкЭъГЩдйНјааЯТвЛДЮЕФЩЈУшЪЧУЛгаБивЊЕФЁЃ
вьВНIOЃК гУЛЇПЩвддкЗЂГівЛИіIOЧыЧѓКѓСЂМДдйЗЂГіСэвЛИіIOЧыЧѓЃЌЕБШЋВПIOЧыЧѓЗЂЫЭЭъБЯКѓЃЌЕШД§ЫљгаIOВйзїЕФЭъГЩЃЌетОЭЪЧAIOЁЃ
AIOСэвЛИігХЪЦПЩвдНЋЖрИіIOЃЌКЯВЂЮЊ1ИіIOЃЌвдЬсИпIOаЇТЪЁЃР§ШчЃКгУЛЇашвЊЗУЮЪ3вГФкШнЃЌЕЋет3вГЪБСЌајЕФЁЃЭЌВНIOашвЊНјаа3ДЮIO,ЖјAIOжЛашвЊвЛДЮ
ОЭПЩвдСЫЁЃ
3.5 ЫЂаТСьНгвГ
ЕБЫЂаТвЛИідрвГЪБЃЌinnodbЛсМьВтИУвГЫљдкЧјЃЈextentЃЉЕФЫљгавГЃЌШчЙћЪЧдрвГЃЌФЧУДвЛЦ№НјааЫЂаТЁЃетбљзіЃЌЭЈЙ§AIOНЋЖрИіIOаДШыВйзїКЯВЂЮЊвЛИіIOВйзїЁЃдкДЋЭГЛњаЕДХХЬЯТгазХЯджјгХЪЦ
| 







