| Īŗľ≠Õ∆ľŲ: |
Īĺ∆™őń’¬Ĺęő™īůľ“Ĺ≤Ĺ‚Ńňgreenplum « ≤√ī£¨ňŁĶńŐō–‘”– ≤√ī£¨greenplum
∆ū‘ī°Ęgreenplum◊‹ŐŚľ‹ĻĻ°Ę≤Ę––Ļ‹ņŪ“‘ľįĽžļŌĶńīśīĘļÕ÷ī––£®įīŃ–ĽÚįī––£©°£
Īĺőńņī◊‘”ŕ≤©ŅÕ‘į£¨”…ĽūŃķĻŻ»ŪľĢAnnaĪŗľ≠°ĘÕ∆ľŲ°£
|
|
greenplumľÚĹť GreenPlum «√śŌÚ żĺ›≤÷Ņ‚”¶”√ĶńĻōŌĶ–Õ żĺ›Ņ‚£¨Ľý”ŕPostgreSQLŅ™∑Ę£¨łķPostgreSQLĶńľś»›–‘∑«≥£ļ√£¨īů≤Ņ∑÷PostgreSQLŅÕĽß∂ňĻ§ĺŖľįPostgreSQL”¶”√∂ľń‹‘ň––‘ŕGreenPlum∆ĹŐ®…Ō°£ŌŽ“™—ßŌįGreenPlum£¨Ņ…“‘Ō»Ņī“ĽŅīPostgreSQLĶń◊ ŃŌ°£

1.greenplum Ű”ŕOLAP żĺ›Ņ‚ŌĶÕ≥“Ľį„∑÷ő™ŃĹ÷÷ņŗ–Õ£ļOLTP°ĘOLAP£ļ
OLTP£®On-Line Transaction Processing£¨Ń™Ľķ ¬őŮī¶ņŪ£©ŌĶÕ≥£ļ“≤≥∆ő™…ķ≤ķŌĶÕ≥£¨ňŁ « ¬ľĢ«ż∂ĮĶń°Ę√śŌÚ”¶”√Ķń£¨Ī»»ÁĶÁ◊”…ŐőŮÕÝ’ĺĶńĹĽ“◊ŌĶÕ≥ĺÕ «“ĽłŲĶš–ÕĶńOLTPŌĶÕ≥°£
OLTPĶńĽýĪĺŐōĶ„£ļ
żĺ›‘ŕŌĶÕ≥÷–≤ķ…ķ Ľý”ŕĹĽ“◊Ķńī¶ņŪŌĶÕ≥£®Transaction-Based£© √ŅīőĹĽ“◊«£…śĶń żĺ›ŃŅļ‹–° ∂‘Ōž”¶ Īľš“™«ů∑«≥£łŖ ”√Ľß żŃŅ∑«≥£Ň”īů£¨÷ų“™ «≤Ŕ◊ų»ň‘Ī żĺ›Ņ‚Ķńłų÷÷≤Ŕ◊ų÷ų“™Ľý”ŕňų“żĹÝ–– OLAP£®On-Line Analytical Processing£¨Ń™Ľķ∑÷őŲī¶ņŪ£©ŌĶÕ≥£ļ «Ľý”ŕ żĺ›≤÷Ņ‚Ķń–ŇŌĘ∑÷őŲī¶ņŪĻż≥Ő£¨ « żĺ›≤÷Ņ‚Ķń”√ĽßĹ”Ņŕ≤Ņ∑÷°£ «ŅÁ≤Ņ√ŇĶń°Ę√śŌÚ÷ųŐ‚Ķń°£
OLAPĶńĽýĪĺŐōĶ„ «£ļ
Īĺ…Ū≤Ľ≤ķ…ķ żĺ›£¨∆šĽýī° żĺ›ņī‘ī”ŕ…ķ≤ķŌĶÕ≥÷–Ķń≤Ŕ◊ų żĺ›£®OperationalData£© Ľý”ŕ≤ť—ĮĶń∑÷őŲŌĶÕ≥ łī‘”≤ť—Įĺ≠≥£ Ļ”√∂ŠĪÍљŊ°Ę»ęĪŪ…®√ŤĶ»£¨«£…śĶń żĺ›ŃŅÕýÕý ģ∑÷Ň”īů Ōž”¶ Īľš”ŽĺŖŐŚ≤ť—Į”–ļ‹īůĻōŌĶ ”√Ľß żŃŅŌŗ∂‘ĹŌ–°£¨∆š”√Ľß÷ų“™ «“ĶőŮ»ň‘Ī”ŽĻ‹ņŪ»ň‘Ī ”Ň”ŕ“ĶőŮő Ő‚≤ĽĻŐ∂®£¨ żĺ›Ņ‚Ķńłų÷÷≤Ŕ◊ų≤Ľń‹ÕÍ»ęĽý”ŕňų“żĹÝ–– 2.∑ŠłĽĶńŐō–‘ »ÁĻŻŌŽ‘ŕ żĺ›≤÷Ņ‚÷–ŅžňŔ≤ť—ĮĹŠĻŻ£¨Ņ…“‘ Ļ”√greenplum°£
Greenplum żĺ›Ņ‚“≤ľÚ≥∆GPDB°£ňŁ”Ķ”–∑ŠłĽĶńŐō–‘£ļ
Ķŕ“Ľ£¨ÕÍ…∆ĶńĪÍ◊ľ÷ß≥÷£ļGPDBÕÍ»ę÷ß≥÷ANSI SQL 2008ĪÍ◊ľļÕSQL OLAP 2003
ņ©’Ļ£Ľī””¶”√Īŗ≥ŐĹ”Ņŕ…ŌĹ≤£¨ňŁ÷ß≥÷ODBCļÕJDBC°£ÕÍ…∆ĶńĪÍ◊ľ÷ß≥÷ ĻĶ√ŌĶÕ≥Ņ™∑Ę°Ęő¨Ľ§ļÕĻ‹ņŪ∂ľīůő™∑ĹĪ„°£∂ÝŌ÷‘ŕĶń
NoSQL£¨NewSQLļÕHadoop ∂‘ SQL Ķń÷ß≥÷∂ľ≤ĽÕÍ…∆£¨≤ĽÕ¨ĶńŌĶÕ≥–Ť“™Ķ•∂ņŅ™∑ĘļÕĻ‹ņŪ£¨«““∆÷≤–‘≤Ľļ√°£
Ķŕ∂Ģ£¨÷ß≥÷∑÷≤ľ Ĺ ¬őŮ£¨÷ß≥÷ACID°£Ī£÷§ żĺ›Ķń«Ņ“Ľ÷¬–‘°£
Ķ໿£¨◊Ųő™∑÷≤ľ Ĺ żĺ›Ņ‚£¨”Ķ”–Ńľļ√ĶńŌŖ–‘ņ©’Ļń‹Ń¶°£‘ŕĻķńŕÕ‚”√Ľß…ķ≤ķĽ∑ĺ≥÷–£¨ĺŖ”–…ŌįŔłŲőÔņŪĹŕĶ„ĶńGPDBľĮ»ļ∂ľ”–ļ‹∂ŗįłņż°£
Ķŕňń£¨GPDB «∆ů“Ķľ∂ żĺ›Ņ‚≤ķ∆∑£¨»ę«Ú”–…Ō«ßłŲľĮ»ļ‘ŕ≤ĽÕ¨ŅÕĽßĶń…ķ≤ķĽ∑ĺ≥‘ň––°£’‚–©ľĮ»ļő™»ę«Úļ‹∂ŗīůĶńĹū»ŕ°Ę’Ģłģ°ĘőÔŃų°ĘŃ„ ŘĶ»ĻęňĺĶńĻōľŁ“ĶőŮŐŠĻ©∑ĢőŮ°£
ĶŕőŚ£¨GPDB «Greenplum£®Ō÷‘ŕĶńPivotal£©Ļęňĺ ģ∂ŗńÍ—–∑ĘÕ∂»ŽĶńĹŠĻŻ°£GPDBĽý”ŕPostgreSQL
8.2£¨PostgreSQL 8.2”–īů‘ľ80ÕÚ––‘īīķ¬Ž£¨∂ÝGPDBŌ÷‘ŕ”–130ÕÚ––‘ī¬Ž°£ŌŗĪ»PostgreSQL
8.2£¨‘Ųľ”Ńň‘ľ50ÕÚ––Ķń‘īīķ¬Ž°£
ĶŕŃý£¨Greenplum”–ļ‹∂ŗļŌ◊ųĽÔįť£¨GPDB”–ÕÍ…∆Ķń…ķŐ¨ŌĶÕ≥£¨Ņ…“‘”Žļ‹∂ŗ∆ů“Ķľ∂≤ķ∆∑ľĮ≥…£¨∆©»ÁSAS£¨Cognos£¨Informatic£¨TableauĶ»£Ľ“≤Ņ…“‘ļ‹∂ŗ÷÷Ņ™‘ī»ŪľĢľĮ≥…£¨∆©»ÁPentaho,Talend
Ķ»°£
3.greenplum∆ū‘ī Greenplum◊Ó‘Á «‘ŕ10∂ŗńÍ«į£®īů‘ľ‘ŕ2002ńÍ£©≥ŲŌ÷Ķń£¨ĽýĪĺ…ŌļÕHadoop «Õ¨“Ľ Ī∆ŕ£®Hadoop
‘ľ «2004ńÍ«įļů£¨‘Á∆ŕĶńNutchŅ…◊∑ň›ĶĹ2002ńÍ£©°£ĶĪ ĪĶńĪ≥ĺį «£ļ
Ľ•Ń™ÕÝ––“Ķĺ≠Ļż÷ģ«įĹŁ10ńÍĶń”…¬żĶĹŅžĶń∑Ę’Ļ£¨ņŘĽżŃňīůŃŅ–ŇŌĘļÕ żĺ›£¨ żĺ›‘ŕĪ¨∑Ę Ĺ‘Ų≥§£¨’‚–©ļ£ŃŅ żĺ›ľĪ–Ť–¬Ķńľ∆ň„∑Ĺ Ĺ£¨–Ť“™“Ľ≥°ľ∆ň„∑Ĺ ĹĶńłÔ√Ł£Ľ īęÕ≥Ķń÷ųĽķľ∆ň„ń£ Ĺ‘ŕļ£ŃŅ żĺ›√ś«į£¨≥żŃň‘žľŘįļĻůÕ‚£¨‘ŕľľ ű…Ō“≤ń—”ŕ¬ķ◊„ żĺ›ľ∆ň„–‘ń‹÷łĪÍ£¨īęÕ≥÷ųĽķĶńScale-upń£ Ĺ”ŲĶĹŃň∆ŅĺĪ£¨SMP£®∂‘≥∆∂ŗī¶ņŪ£©ľ‹ĻĻń—”ŕņ©’Ļ£¨≤Ę«“‘ŕCPUľ∆ň„ļÕIOÕŐÕ¬…Ō≤Ľń‹¬ķ◊„ļ£ŃŅ żĺ›Ķńľ∆ň„–Ť«ů£Ľ ∑÷≤ľ ĹīśīĘļÕ∑÷≤ľ Ĺľ∆ň„ņŪ¬Řł’ł’ĪĽŐŠ≥Ųņī£¨GoogleĶńŃĹ∆™÷Ý√Ż¬Řőń∑ĘĪŪļů“ż∆ū“ĶĹÁĶńĻō◊Ę£¨“Ľ∆™ «Ļō”ŕGFS∑÷≤ľ ĹőńľĢŌĶÕ≥£¨ŃŪÕ‚“Ľ∆™ «Ļō”ŕMapReduce
≤Ę––ľ∆ň„ŅÚľ‹ĶńņŪ¬Ř£¨∑÷≤ľ Ĺľ∆ň„ń£ ő༕љÕÝ––“ĶŐōĪū « ’ňų“ż«śļÕ∑÷ī ľžňųĶ»∑Ĺ√śĽŮĶ√Ńňĺřīů≥…Ļ¶°£ Ō¬ÕľĺÕ «GFSĶńľ‹ĻĻ
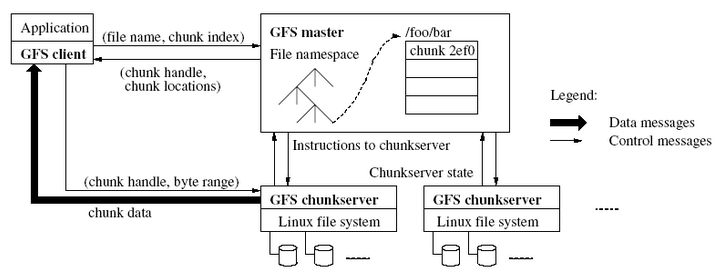
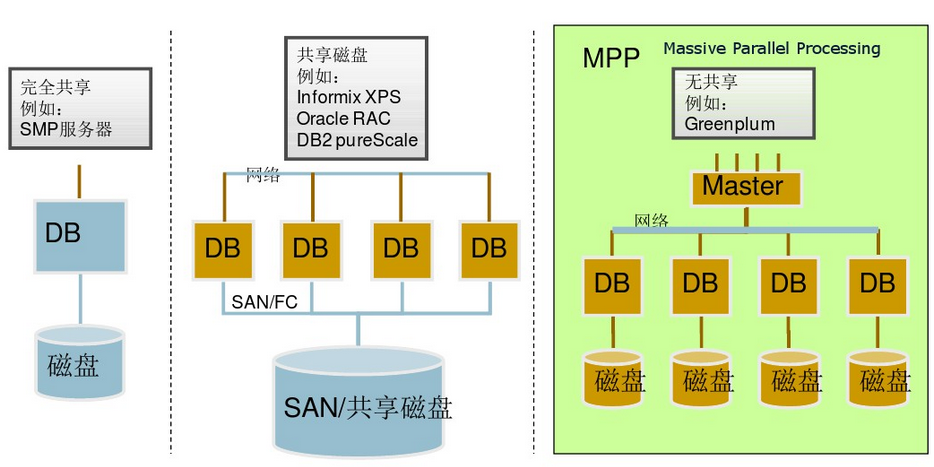
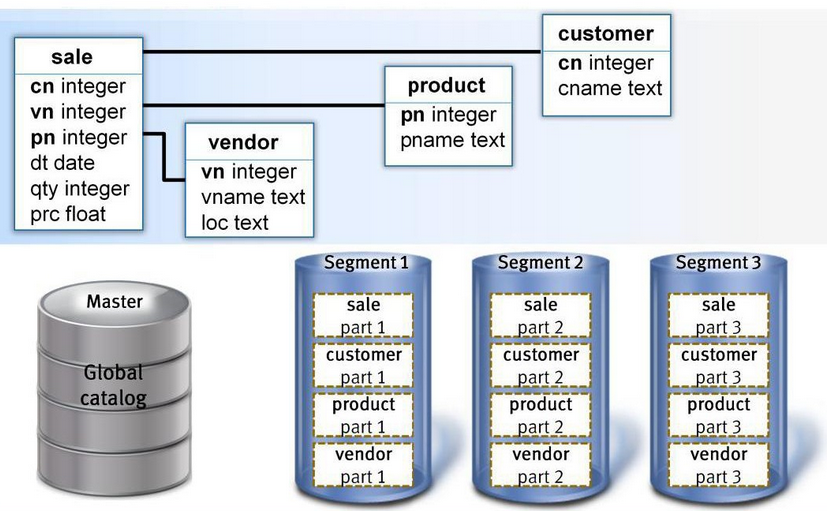
4.greenplum◊‹ŐŚľ‹ĻĻ 1.greenplumĶń◊‹ŐŚľ‹ĻĻ»ÁŌ¬£ļ 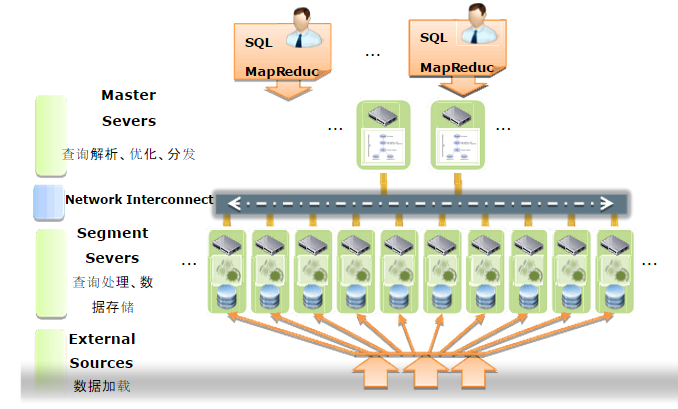
żĺ›Ņ‚”…Master SeversļÕSegment SeversÕ®ĻżInterconnectĽ•Ń™◊ť≥…°£
MasterĹŕĶ„£ļ «’ŻłŲŌĶÕ≥ĶńŅō÷∆÷––ńļÕ∂‘Õ‚Ķń∑ĢőŮĹ”»ŽĶ„£¨ňŁłļ‘ūĹ” ’”√ĽßSQL«Ž«ů£¨ĹęSQL…ķ≥…≤ť—Įľ∆Ľģ≤ĘĹÝ––≤Ę––ī¶ņŪ”ŇĽĮ£¨»ĽļůĹę≤ť—Įľ∆Ľģ∑÷Ňš£®dispatch£©ĶĹňý”–ĶńSegmentĹŕĶ„ĹÝ––≤Ę––ī¶ņŪ£¨–≠Ķų◊ť÷ĮłųłŲSegmentĹŕĶ„įī’’≤ť—Įľ∆Ľģ“Ľ≤Ĺ“Ľ≤ĹĶōĹÝ––≤Ę––ī¶ņŪ£¨◊ÓļůĽŮ»°ĶĹSegmentĶńľ∆ň„ĹŠĻŻ£¨‘Ŕ∑ĶĽōłÝŅÕĽß∂ň£Ľī””√ĽßĶńĹ«∂»ŅīGreenplumľĮ»ļ£¨ŅīĶĹĶń÷Ľ «MasterĹŕĶ„,őř–ŤĻō–ńľĮ»ļńŕ≤ŅĶńĽķ÷∆£¨ňý”–Ķń≤Ę––ī¶ņŪ∂ľ «‘ŕMasterŅō÷∆Ō¬◊‘∂ĮÕÍ≥…Ķń°£MasterĹŕĶ„“Ľį„÷Ľ”–“ĽłŲĽÚŃĹłŲ£®Ľ•ő™Īł∑›£©£Ľ SegmentĹŕĶ„£ļ «Greenplum÷ī––≤Ę––»őőŮĶń≤Ę––‘ňň„ĹŕĶ„£¨ňŁĹ” ’MasterĶń÷łŃÓĹÝ––MPP≤Ę––ľ∆ň„£¨“Úīňňý”–SegmentĹŕĶ„Ķńľ∆ň„–‘ń‹◊‹ļÕĺÕ «’ŻłŲľĮ»ļĶń–‘ń‹£¨Õ®Ļż‘Ųľ”SegmentĹŕĶ„£¨Ņ…“‘ŌŖ–‘ĽĮĶ√‘Ųľ”ľĮ»ļĶńī¶ņŪ–‘ń‹ļÕīśīĘ»›ŃŅ£¨SegmentĹŕĶ„Ņ…“‘ «1~10000łŲĹŕĶ„£Ľ Interconnect£ļ «MasterĹŕĶ„”ŽSegmentĹŕĶ„°ĘSegmentĹŕĶ„”ŽSegmentĹŕĶ„÷ģľšĶń żĺ›īę š◊ťľĢ£¨ňŁĽý”ŕ«ß’◊ĹĽĽĽĽķĽÚÕÚ’◊ĹĽĽĽĽķ ĶŌ÷ żĺ›‘ŕĹŕĶ„ľšĶńłŖňŔīę š£Ľ Õ‚≤Ņ żĺ›ľ”‘ōĶĹGreenplum Ī£¨≤…”√≤Ę–– żĺ›ŃųĹÝ––ľ”‘ō£¨÷ĪĹ”ľ”‘ōĶĹSegmentĹŕĶ„£¨’‚ŌÓ∂ņŐōĶńľľ ű «GreenplumĶń◊®”–ľľ ű£¨“‘īňĪ£÷§Õ‚≤Ņ żĺ›‘ŕ◊Ó∂Ő Īľšńŕľ”‘ōĶĹ żĺ›Ņ‚÷–°£ ľÚĶ•ņīňĶ
Master÷ųĽķłļ‘ū£ļĹ®ŃĘ”ŽŅÕĽß∂ňĶńѨŔļÕĻ‹ņŪ£ĽSQLĶńĹ‚őŲ≤Ę–ő≥…÷ī––ľ∆Ľģ£Ľ÷ī––ľ∆ĽģŌÚSegmentĶń∑÷∑Ę ’ľĮSegmentĶń÷ī––ĹŠĻŻ£ĽMaster≤ĽīśīĘ“ĶőŮ żĺ›£¨÷ĽīśīĘ żĺ›◊÷Ķš°£
Segment÷ųĽķłļ‘ū£ļ“ĶőŮ żĺ›ĶńīśīĘļÕīś»°£Ľ”√Ľß≤ť—ĮSQLĶń÷ī––°£
2.ĽýĪĺŐŚŌĶľ‹ĻĻ 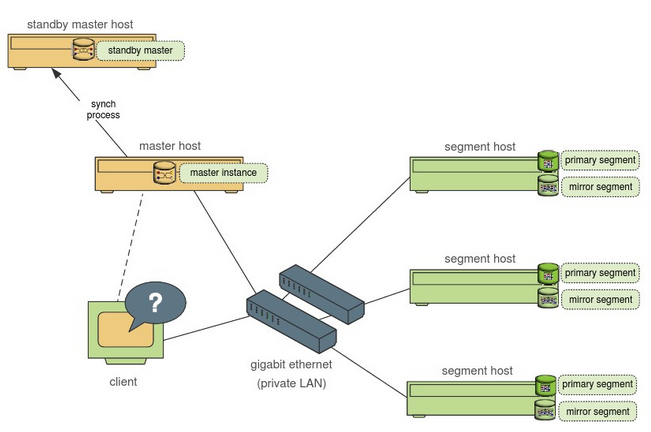
masterĹŕĶ„£¨Ņ…“‘◊Ų≥…łŖŅ…”√Ķńľ‹ĻĻ

master nodełŖŅ…”√£¨ņŗň∆”ŕhadoopĶńnamenodeļÕsecond namenode£¨ ĶŌ÷÷ųĪłĶńłŖŅ…”√°£
segmentsĹŕĶ„

3.őřĻ≤ŌŪ/MPPļň–ńľ‹ĻĻ Greenplum żĺ›Ņ‚»ŪľĢĹę żĺ›∆Ĺĺý∑÷≤ľĶĹŌĶÕ≥Ķńňý”–ĹŕĶ„∑ĢőŮ∆ų…Ō£¨ňý“‘ĹŕĶ„īśīĘ√Ņ’ŇĪŪĽÚĪŪ∑÷«ÝĶń≤Ņ∑÷––£¨ňý”– żĺ›ľ”‘ōļÕ≤ť—Į∂ľ «◊‘∂Į‘ŕłųłŲĹŕĶ„∑ĢőŮ∆ų…Ō≤Ę––‘ň––£¨≤Ę«“ł√ľ‹ĻĻ÷ß≥÷ņ©’ĻĶĹ…ŌÕÚłŲĹŕĶ„°£
5.≤Ę––Ļ‹ņŪ ∂‘”ŕ żĺ›Ķń◊į‘ōļÕ–‘ń‹ľŗŅō°£
≤Ę––Īł∑›ļÕĽ÷łī°£

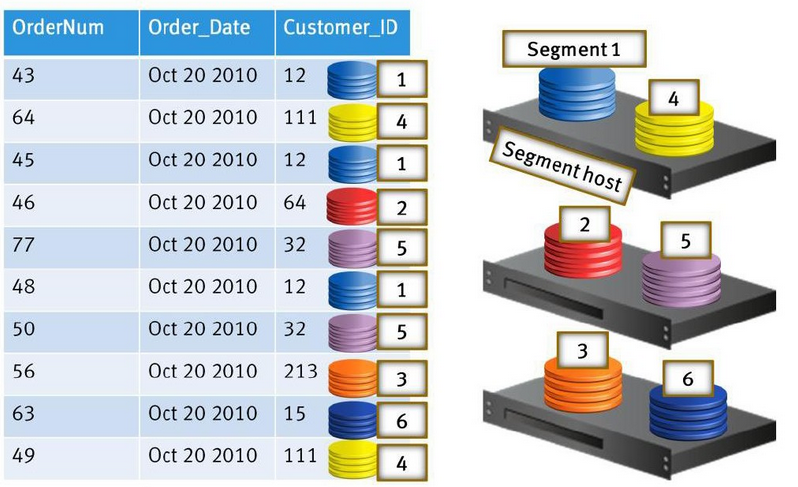
żĺ›∑√ő Ńų≥Ő£¨ żĺ›∑÷≤ľĶĹ≤ĽÕ¨—’…ęĶńĹŕĶ„…Ō
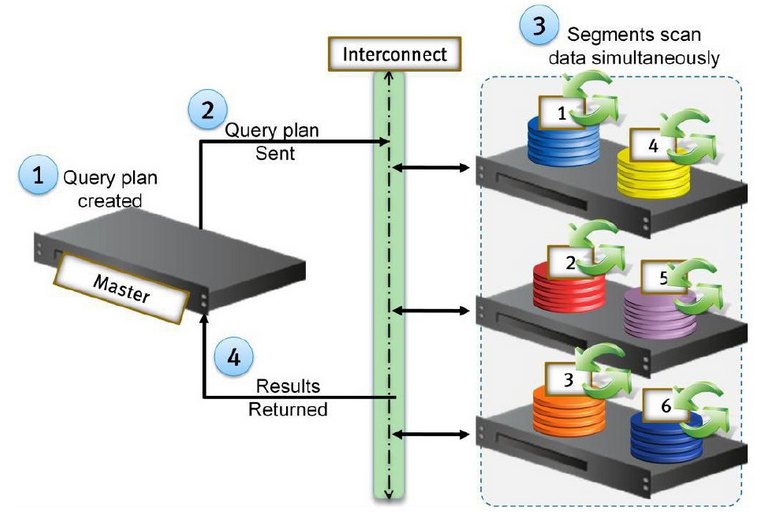
≤ť—ĮŃų≥Ő∑÷ő™≤ť—ĮīīĹ®ļÕ≤ť—Į∑÷∑Ę£¨ľ∆ň„ļůĹęĹŠĻŻ∑ĶĽō°£
∂‘”ŕīśīĘ£¨ĹęīśīĘĶńńŕ»›∑÷≤ľĶĹłųłŲĹŠĶ„…Ō°£
∂‘”ŕ żĺ›Ķń∑÷≤ľ£¨∑÷ő™hash∑÷≤ľļÕňśĽķ∑÷≤ľŃĹ÷÷°£
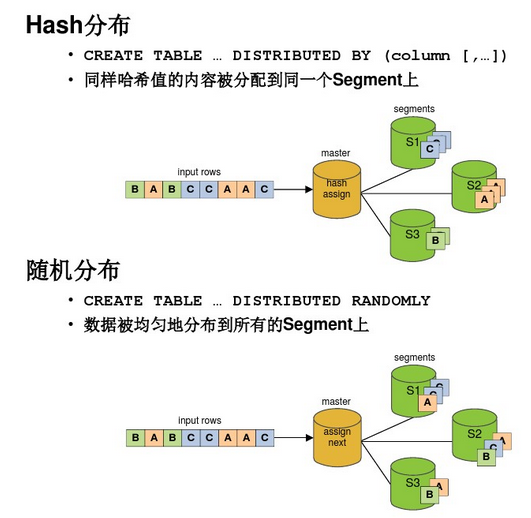
ĺý‘»∑÷≤ľĶń«ťŅŲ£ļ

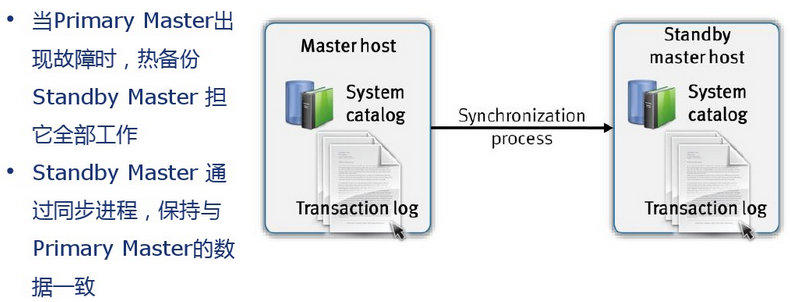
6.ĽžļŌĶńīśīĘļÕ÷ī––£®įīŃ–ĽÚįī––£© Greenplum∑Ę√ų÷ß≥÷ĽžļŌįīŃ–ĽÚįī––īśīĘ żĺ›£¨√Ņ’ŇĪŪĽÚĪŪ∑÷«ÝŅ…“‘”…Ļ‹ņŪ‘Īłýĺ›”¶”√–Ť“™£¨∑÷Īū÷ł∂®īśīĘļÕ—Ļňű∑Ĺ Ĺ°£Ľý”ŕ’‚łŲĻ¶ń‹£¨”√ĽßŅ…“‘∂‘»őļőĪŪĽÚĪŪ∑÷«Ý—°‘Ůįī––ĽÚįīŃ–īśīĘ żĺ›ļÕī¶ņŪ∑Ĺ Ĺ°£’‚–© «‘ŕĹ®ĪŪĽÚĪŪ∑÷«ÝĶńDDL”Ôĺš÷–Ňš÷√Ķń£¨÷Ľ–Ť‘ŕĹ®ĪŪĽÚĪŪ∑÷«Ý Ī÷ł∂®°£’‚łŲĻ¶ń‹Ľý”ŕGreenplumĶń∂ŗŐ¨ő¨ żĺ›īśīĘľľ ű°£
MasterļÕSegment∂ľ «“ĽłŲĶ•∂ņĶńPostgreSQL żĺ›Ņ‚°£√Ņ“ĽłŲ∂ľ”–◊‘ľļĶ•∂ņĶń“ĽŐ◊‘™ żĺ›◊÷Ķš°£
MasterĹŕĶ„“Ľį„“≤Ĺ–÷ųĹŕĶ„£¨SegmentĹ–◊Ų żĺ›ĹŕĶ„°£
ő™Ńň ĶŌ÷łŖŅ…”√£¨√ŅłŲSegment∂ľ”–∂‘”¶ĶńĪłĹŕĶ„ Mirror Segment∑÷Īūīś‘ŕ”Ž≤ĽÕ¨ĶńĽķ∆ų…Ō°£
Client“Ľį„÷Ľń‹”ŽMasterĹŕĶ„ĹÝ––ĹĽĽ•£¨ClientĹęSQL∑ĘłÝMaster£¨»ĽļůMaster∂‘SQLĹÝ––∑÷őŲļů‘ŔĹę∆š∑÷ŇšłÝňý”–ĶńSegmentĹÝ––≤Ŕ◊ų°£
Greenplum√Ľ”–WindowsįśĪĺ£¨÷Ľń‹į≤◊į‘ŕņŗUNIXĶń≤Ŕ◊ųŌĶÕ≥…Ō°£
Greenplumnľę∂»ŌŻļńI/O◊ ‘ī£¨ňý“‘∂‘īśīĘĶń“™«ůĪ»ĹŌłŖ°£
| 







