| БрМЭЦМі: |
БОЮФНщЩмСЫ
GreenplumЃЈGPЃЉЗжВМЪНЪ§ОнПтЕФЙўЯЃЗжВМВпТдЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздГЬађдБжТжЊТМЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
GreenplumЃЈGPЃЉЪЧЗжВМЪНЪ§ОнПтЃЌвђДЫЃЌЪ§ОнЕФЗжВМЪЧЛљДЁЁЃGPЬсЙЉСЫЖржжЗжВМВпТдЃКЙўЯЃЗжВМЁЂЫцЛњЗжВМКЭИДжЦБэЁЃЦфжаЃЌзюГЃгУЕФОЭЪЧЙўЯЃЗжВМЁЃБОЦЊЮФеТЮвНЋЯђДѓМвНщЩмGPЕФЙўЯЃЗжВМЁЃ
ЪзЯШЃЌЮвУЧЯШЛиЙЫвЛЯТЩЯЦЊЮФеТгУгкЕїЪдЕФФЧеХБэЃК
| CREATE table
t1 AS SELECT g c1, g + 1 as c2 FROM generate_series(1,
10) g DISTRIBUTED BY (c1); |
ДѓМвПЩвдПДЕННЈБэгяОфФЉЮВгаDISTRIBUTED BY (c1)ЃЌетОЭБэЪОЩЯУцетеХБэЪЧвЛеХЙўЯЃЗжВМБэЃЌЧвЭЈЙ§Саc1ЕФжЕЩЂСаЪ§ОнЁЃЮвУЧдйРДПДЯТБэРяЕФЪ§ОнЃК
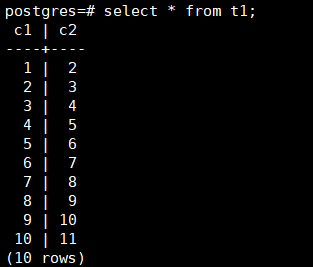
вђЮЊpsqlФЌШЯСЌНгЕФЪЧMasterЃЌЫљвдетРяжЛФмПДЕНећеХБэЕФЪ§ОнЁЃШчЙћЮвУЧЯыЙлВьЪ§ОндкSegmentжаЕФЗжВМЧщПіЃЌФЧУДгаУЛгаАьЗЈжЛПДФГИіSegmentжаДцДЂЕФЪ§ОнФиЃПД№АИЪЧгаЕФЁЃгЩгкSegmentвВЪЧвЛИіPostgresQLЃЈPGЃЉЪЕР§ЃЌpsqlЬсЙЉСЫвЛИіutilityФЃЪНЃЌПЩвджБНгСЌНгSegmentЃЈзЂвтВЛвЊЭЈЙ§ДЫФЃЪНЃЌШЦЙ§MasterЃЌжБНгдкSegmentжДааDDLЛђЪ§ОнВхШыгяОфЃЌетбљзіПЩФмЛсв§ЗЂМЏШКвьГЃЃЉЁЃжДаавдЯТУќСюЃЌжБСЌSegmentЃК
| PGOPTIONS='-c
gp_session_role=utility' psql -p 6000 postgres |
СЌНгЩЯSegmentКѓЃЌдйДЮВщПДSegmentЩЯt1БэЕФЪ§ОнЃК
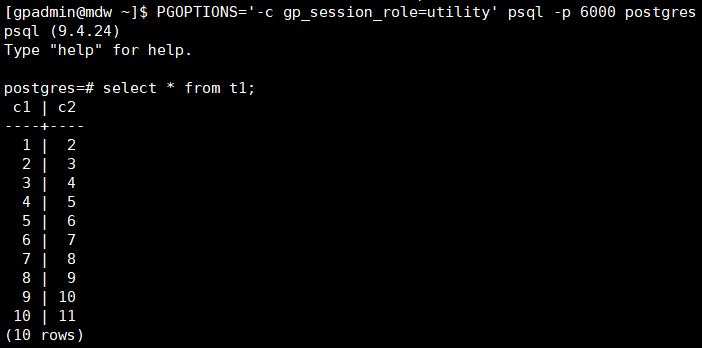
гЩгкЮвУЧЩЯДЮДюНЈЕФЛЗОГжЛгавЛЬЈSegmentЃЌБэt1ЕФЪ§ОнРэЫљЕБШЛШЋВПДцДЂдкетЬЈSegmentЩЯЁЃЫљвдЃЌЯТУцЮвУЧашвЊНЋМЏШКРЉШнЃЌдйНЋt1ЕФЪ§ОнжиЗжВМЃЌШЛКѓдйЙлВьЁЃ
РЉШн
GPЕФЙйЗНЮФЕЕжаЃЌгаЖдРЉШнЕФЯъЯИНщЩмЃЌОпЬхПЩвдВщдФЁЖGPDB62DocsЁЗЁЊЁЊ Chapter 4
Greenplum Database Administrator Guide ЁЊЁЊ Managing
a Greenplum System ЁЊЁЊ Expanding a Greenplum SystemЁЃ
1ЃЌГѕЪМЛЏаТЕФSegments
cd /home/gpadmin/
#вдНЛЛЅФЃЪНДДНЈРЉШнЪфШыЮФМў
gpexpand
# ЪЧЗёГѕЪМЛЏаТЕФРЉШн
> y
# ЪфШыашвЊРЉШнЕФжїЛњУћЃЌЖрИіжїЛњжЎМфвдЖККХЗжИє(ШєжЛдкЕБЧАвбДцдкжїЛњдіМгsegmentsЃЌЪфШыПеааМДПЩ)
>
# ЪфШыаТМгШыЕФprimary segmentsЪ§СП
> 1
# ЪфШыаТprimary segmentsЕФФПТМ
> /home/data/primary |
ЭъГЩКѓЃЌЛсдкЕБЧАФПТМЩњГЩвЛИіinput fileЃЌgpexpand_inputfile_yyyymmdd_xxxxЁЃ 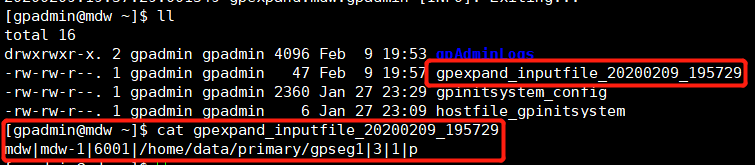
2ЃЌжДааРЉШн
# РЉШнЧАашвЊШЗБЃЯЕЭГАВзАСЫrsyncУќСюЃЌУЛгаЕФЛАЯШyum
-y install rsync
gpexpand -i input_file
# ШчЙћжДааЪЇАмЃЌдйДЮжДааЧАашЛиЙіЩЯДЮЪЇАмЕФРЉШнаХЯЂ
# gpexpand --rollback |
ВщПДРЉШнзДЬЌЃК
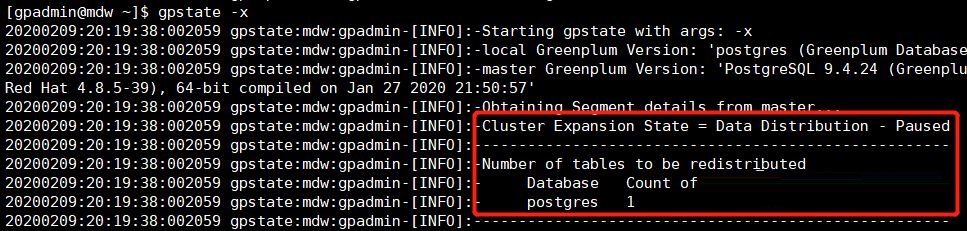
3ЃЌжДааЪ§ОнжиЗжВМ
дйДЮВщПДРЉШнзДЬЌЃК

4ЃЌЩОГ§БОДЮРЉШнЕФschemaаХЯЂЃК
ЮвУЧПДвЛЯТДЫЪБКѓЬЈЕФНјГЬЪ§ЃК
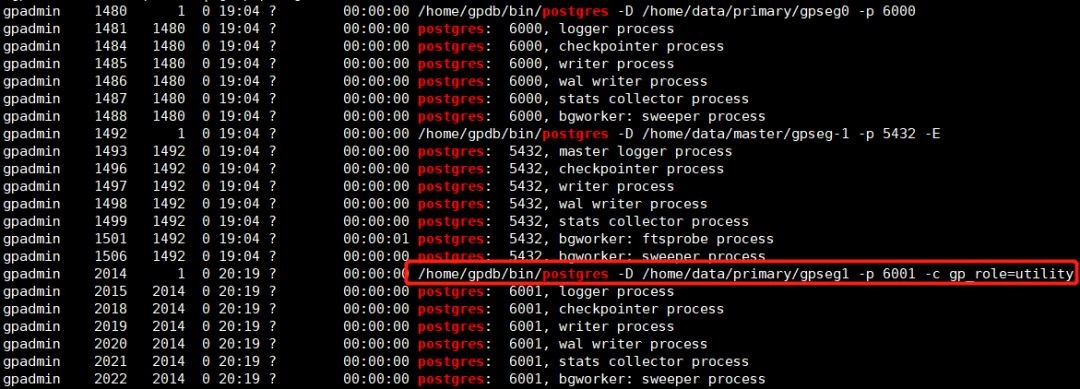
ПЩвдПДЕНаТЕФSegmentвбЦєЖЏЃЌжСДЫЃЌРЉШнвбЭъГЩЁЃ
Ъ§ОнЗжВМ
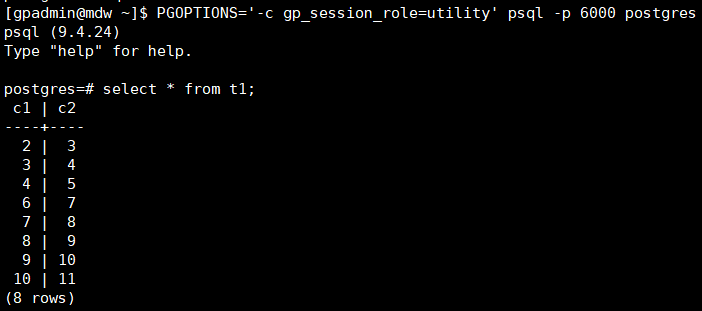
РЉШнКѓЃЌЮвУЧЗжБ№РћгУpsqlСЌНгСНИіSegmentЃЌВщПДЪ§ОнЗжВМЧщПіЁЃ
ЕквЛИіSegmentЃК
ЕкЖўИіSegmentЃК
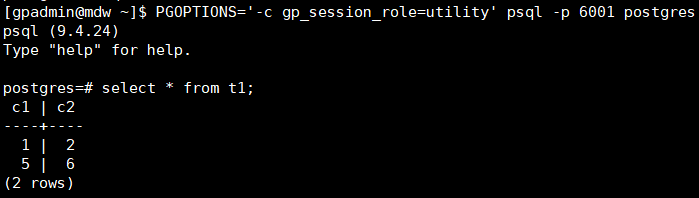
ДгЩЯУцСНеХЭМЦЌПЩвдПДЕНЃЌдЯШШЋВПДцДЂгкЕквЛИіSegmentжаЕФЪ§ОнБЛЗжЩЂЕНСЫСНИіSegmentжаЃЌВЛЙ§Ъ§ОнБШНЯЧуаБЃЈгЩгкt1БэЕФЪ§ОнСПБШНЯЩйЃЌЕБЧАЕФЯжЯѓВЂВЛФмЫЕУїЪВУДЮЪЬтЃЉЁЃ
ЭЈЙ§дФЖСЙйЗНЮФЕЕЁЖGPDB62DocsЁЗПЩжЊЃЌДг6.0АцБОПЊЪМЃЌGPЪЙгУСЫаТЕФЙўЯЃЫуЗЈЁЊЁЊJump
Consistent HashЁЃетЪЧЙШИшЬсГіЕФвЛИівЛжТадЙўЯЃЫуЗЈЃЌаЇТЪКмИпЁЃБОЮФднВЛЖдетИіЫуЗЈеЙПЊЬжТлЃЌЮвУЧжБНгДгдДТыжаевЕНетИіЫуЗЈЕФДњТыЃК
/*
* The following jump consistent hash algorithm
is
* just the one from the original paper:
* https://arxiv.org/abs/1406.2294
*/
static inline int32
jump_consistent_hash(uint64 key, int32 num_segments)
{
int64 b = -1;
int64 j = 0;
while (j < num_segments)
{
b = j;
key = key * 2862933555777941757ULL + 1;
j = (b + 1) * ((double)(1LL << 31) / (double)((key
>> 33) + 1));
}
return b;
} |
ОнДЫЃЌЮвУЧПЩвдбщжЄвЛЯТЃЌЩЯУцЕФЪ§ОнЪЧЗёАДееДЫЫуЗЈЗжВМЃК
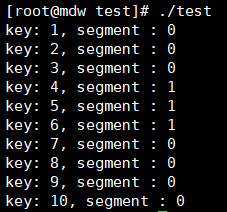
жБНгЭЈЙ§Саc1ЕФжЕШЅЙўЯЃЃЌЕУЕНЕФНсЙћКЭt1БэЪЕМЪЕФЪ§ОнЗжВМЪЧВЛвЛжТЕФЁЃЮЊДЫЃЌЮвУЧПЩвдЭЈЙ§ЕїЪддДТыЃЌвЛЬНОПОЙЃЈЕїЪдЗНЗЈДѓМвПЩвдЛиЙЫвЛЯТЩЯвЛЦЊЮФеТЃЉЁЃетДЮЮвУЧжБНгдкjump_consistent_hashДІДђвЛИіЖЯЕуЃЌЭЈЙ§psqlжДаавЛЬѕsqlЃК
| insert into t1
values(1, 3); |
ГЬађжаЖЯКѓВщПДДЋШыjump_consistent_hashЕФБфСПжЕЃК
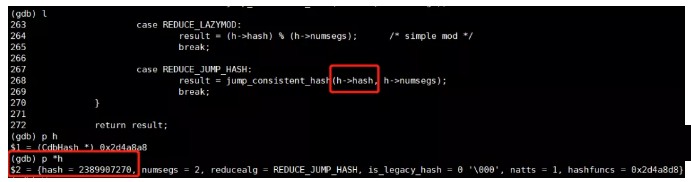
ПЩвдЗЂЯжЃЌДЋШыjump_consistent_hashЕФШыВЮВЂВЛЪЧЮвУЧВхШыЕФc1ЕФжЕ1ЃЌЖјЪЧБфГЩСЫ2389907270ЃЌКмУїЯдетЪЧРрЫЦЙўЯЃжЕЕФвЛИіЖЋЖЋЁЃМЬајПДЯТЕБЧАЖбеЛЃК

ЯђЩЯЫндДевЕНnodeResult.c:279ДІЕФдДТыЃЌЮвУЧПДЯТh->hashЪЧШчКЮВњЩњЕФЃК
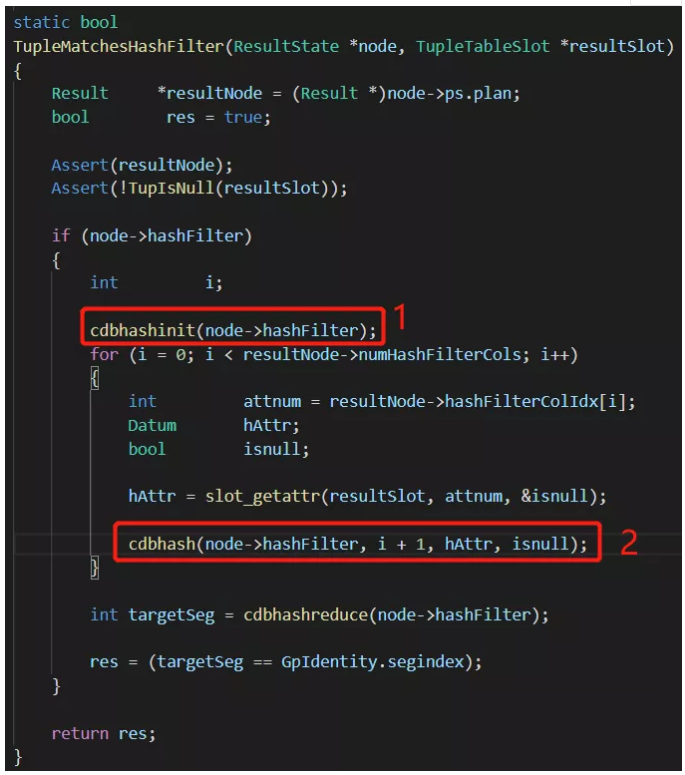
ЭМжа1ДІЃЌНЋh->hashжУЮЊ0ЁЃЭМ2ИљОнc1ЕФжЕжиаТМЦЫуhashkeyЃЌВЂИГИјh->hashЁЃМЬајВщПДcdbhashЕФДњТыЃК
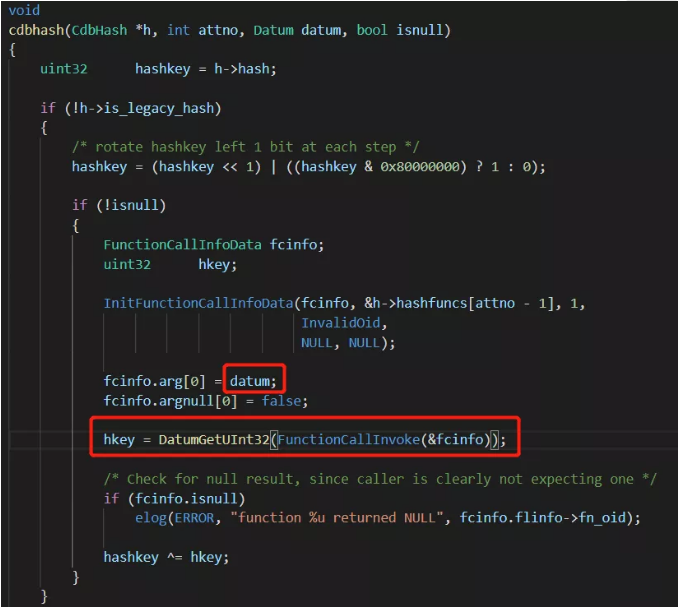
дкcdbhashжаПЩвдПДЕНЃЌdatumМДЮЊc1ЕФецЪЕжЕ1ЃЌЭЈЙ§FunctionCallInvoke(&fcinfo)ВњЩњСЫаТЕФhkeyЃЌЭЈЙ§ЕїЪдПЩвдЗЂЯжЃЌДЫДІЕїгУЕФКЏЪ§МДhashint4ЃК
Datum hashint4(PG_FUNCTION_ARGS)
{
return hash_uint32(PG_GETARG_INT32(0));
}
Datum hash_uint32(uint32 k)
{
register uint32 a,
b,
c;
a = b = c = 0x9e3779b9 + (uint32) sizeof(uint32)
+ 3923095;
a += k;
final(a, b, c);
/* report the result */
return UInt32GetDatum(c);
} |
ПДЕНетРяЃЌецЯрДѓАзЁЃдРДЪЧИљОнСаЕФРраЭЕїгУЯргІЕФhashКЏЪ§ЃЌЯШЖдСажЕМЦЫуСЫвЛДЮhashжЕЃЌШЛКѓдйЖдДЫЙўЯЃжЕНјааjumpЙўЯЃевЕНЖдгІЕФsegmentБрКХЁЃШчДЫвЛРДЃЌЮвУЧдкВтЪдДњТыжаЬэМгhash_uint32ЃЌМЬајбщжЄЃК

ПЩвдПДЕНЃЌетДЮЕФбщжЄНсЙћгыЪЕМЪЕФЪ§ОнЗжВМНсЙћЪЧвЛжТЕФЁЃжСДЫЃЌGPЕФЙўЯЃЗжВМВпТдНщЩмЭъБЯЁЃ
| 







