| БрМЭЦМі: |
БОЮФДѓжТНщЩмСЫTokuDBЪТЮёЕФИєРыадЪЕЯждРэЃЌ
АќРЈTokuDBЕФЪТЮёБэЪОЁЂЗжаЮЪїЕФLeafEntryЕФНсЙЙЁЂMVCCЕФЪЕЯжСїГЬЁЂЖрАцБОМЧТМЛиЪеЗНЪНетаЉЗНУцЕФФкШнЁЃ
БОЮФРДздгкЮЂаХЬ§дЦЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ
|
|
дкАВзАMariaDBЕФЪБКђСЫНтЕНДњЬцInnoDBЕФTokuDBЃЌПДМђНщЗЧГЃЕФАєЃЌетРяЖдToduDBзівЛИіГѕВНЕФећРэЃЌЪЙгУКѓдйзіИќЖрЕФЗжЯэЁЃ
ЪВУДЪЧTokuDBЃП
дкMySQLзюСїааЕФжЇГжШЋЪТЮёЕФв§ЧцЮЊINNODBЁЃЦфЬиЕуЪЧЪ§ОнБОЩэЪЧгУB-TREEРДзщжЏЃЌЪ§ОнБОЩэМДЪЧХгДѓЕФИљОнжїМќОлДиЕФB-TREEЫїв§ЁЃ
ЫљвддкетЕуЩЯЃЌаДШыЫйЖШОЭЛсгааЉНЕЕЭЃЌвђЮЊвЊУПДЮаДШывЊгУвЛДЮIOРДзіЫїв§ЪїЕФжиХХЁЃЬиБ№ЪЧЕБЪ§ОнСПБОЩэБШФкДцДѓКмЖрЕФЧщПіЯТЃЌCPUБОЩэБЛДХХЬIOОРВјЕФзіВЛСЫЦфЫћЪТЧщСЫЁЃетЪБЮвУЧвЊПМТЧШчКЮМѕЩйЖдДХХЬЕФIOРДХХНтCPUЕФДІОГЃЌГЃМћЕФЗНЗЈгаЃК
АбINNODB ИіPAGEдіДѓЃЈФЌШЯ16KBЃЉЃЌЕЋдіДѓвВОЭДјРДСЫвЛаЉШБЯнЁЃ БШШчЃЌЖдДХХЬНјааCHECKPOINTЕФЪБМфНЋбгКѓЁЃ
АбШежОЮФМўЗХЕНИќПьЫйЕФДХХЬЩЯЃЌБШШчSSDЁЃ
TokuDB ЪЧвЛИіжЇГжЪТЮёЕФЁАаТЁБв§ЧцЃЌгазХГіЩЋЕФЪ§ОнбЙЫѕЙІФмЃЌгЩУРЙњ TokuTek ЙЋЫОЃЈЯждквбОБЛ
Percona ЙЋЫОЪеЙКЃЉбаЗЂЁЃгЕгаГіЩЋЕФЪ§ОнбЙЫѕЙІФмЃЌШчЙћФњЕФЪ§ОнаДЖрЖСЩйЃЌЖјЧвЪ§ОнСПБШНЯДѓЃЌЧПСвНЈвщФњЪЙгУTokuDBЃЌвдНкЪЁПеМфГЩБОЃЌВЂДѓЗљЖШНЕЕЭДцДЂЪЙгУСПКЭIOPSПЊЯњЃЌВЛЙ§ЯргІЕФЛсдіМг
CPU ЕФбЙСІЁЃ
TokuDB ЕФЬиад
1.ЗсИЛЕФЫїв§РраЭвдМАЫїв§ЕФПьЫйДДНЈ
TokuDB Г§СЫжЇГжЯжгаЕФЫїв§РраЭЭтЃЌ ЛЙдіМгСЫ(ЕкЖў)МЏКЯЫїв§, вдТњзуЖрбљадЕФИВИЧЫїв§ЕФВщбЏ,
дкПьЫйДДНЈЫїв§ЗНУцЬсИпСЫВщбЏЕФаЇТЪ
2.(ЕкЖў)МЏКЯЫїв§
вВПЩвдГЦзїЗЧжїМќЕФМЏКЯЫїв§, етРрЫїв§вВАќКЌСЫБэжаЕФЫљгаСа, ПЩвдгУгкИВИЧЫїв§ЕФВщбЏашвЊ, БШШчвдЯТЪОР§,
дкwhere ЬѕМўжажБНгУќжа index_b Ыїв§, БмУтСЫДгжїМќжадйВщеввЛДЮЁЃ
Мћ
3.Ыїв§дкЯпДДНЈ(Hot Index Creation)
TokuDB дЪаэжБНгИјБэдіМгЫїв§ЖјВЛгАЯьИќаТгяОф(insert, update ЕШ)ЕФжДааЁЃПЩвдЭЈЙ§БфСП
tokudb_create_index_online РДПижЦЪЧЗёПЊЦєИУЬиад, ВЛЙ§вХКЖЕФЪЧФПЧАЛЙжЛФмЭЈЙ§
CREATE INDEX гяЗЈЪЕЯждкЯпДДНЈ, ВЛФмЭЈЙ§ ALTER TABLE ЪЕЯжЁЃ етжжЗНЪНБШЭЈГЃЕФДДНЈЗНЪНТ§СЫаэЖр,
ДДНЈЕФЙ§ГЬПЩвдЭЈЙ§ show processlist ВщПДЁЃВЛЙ§ tokudb ВЛжЇГждкЯпЩОГ§Ыїв§,
ЩОГ§Ыїв§ЕФЪБКђЛсЖдБъМгШЋОжЫјЁЃ

4.дкЯпИќИФСа(Add, Delete, Expand, Rename)
TokuDB ПЩвддкЧсЮЂзшШћИќаТЛђВщбЏгяОфЕФЧщПіЯТЃЌ дЪаэЪЕЯжвдЯТВйзїЃК
діМгЛђЩОГ§БэжаЕФСа
РЉГфзжЖЮ: char, varchar, varbinary КЭ int РраЭЕФСа
жиУќУћСа, ВЛжЇГжзжЖЮРраЭ: TIME, ENUM, BLOB, TINYBLOB, MEDIUMBLOB,
LONGBLOB
етаЉВйзїЭЈГЃЪЧвдБэЫјМЖБ№зшШћ(МИУыжгЪБМф)ЦфЫћВщбЏЕФжДаа, ЕББэМЧТМЯТДЮДгДХХЬМгдиЕНФкДцЕФЪБКђ,
ЯЕЭГОЭЛсЫцжЎЖдМЧТМНјаааоИФВйзї(add, delete Лђ expand)ЃЌ ШчЙћЪЧ rename
Вйзї, дђЛсдкМИУыжгЕФЭЃЛњЪБМфФкЭъГЩЫљгаВйзїЁЃ
TokuDBЕФетаЉВйзїВЛЭЌгк InnoDB, ЖдБэНјааИќаТКѓПЩвдПДЕН rows affected
ЮЊ 0, МДИќИФВйзїЛсЗХЕНКѓЬЈжДаа, БШНЯПьЫйЕФдвђПЩФмЪЧгЩгк Fractal-tree Ыїв§ЕФЬиад,
НЋЫцЛњЕФ IO ВйзїЬцЛЛЮЊЫГађ IO ВйзїЃЌ Fractal-treeЕФЬиаджаЃЌЛсНЋетаЉВйзїЙуВЅЕНЫљгааа,
ВЛЯё InnoDB, ашвЊ open table ВЂДДНЈСйЪББэРДЭъГЩЁЃ
ПДПДЙйЗНЖдИУЬиадЕФвЛаЉжИЕМЫЕУї:
ЫљгаЕФетаЉВйзїВЛЪЧСЂМДжДааЃЌ ЖјЪЧЗХЕНКѓЬЈжагЩ Fractal Tree ЭъГЩ, ВйзїАќРЈжїМќКЭЗЧжїМќЫїв§ЁЃвВПЩвдЪжЙЄЧПжЦжДааетаЉВйзї,
ЪЙгУ OPTIMIZE TABLE X УќСюМДПЩ, TokuDB Дг1.0 ПЊЪМOPTIMIZE TABLEУќСювВжЇГждкЯпЭъГЩ,
ЕЋЪЧВЛЛсжиНЈЫїв§
ВЛвЊвЛДЮИќаТЖрСа, ЗжПЊЖдУПСаНјааВйзї
БмУтЭЌЪБЖдвЛСаНјаа add, delete, expand Лђ drop Вйзї
БэЫјЕФЪБМфжївЊгЩЛКДцжаЕФдрвГ(dirty page)ОіЖЈ, дрвГдНЖр flush ЕФЪБМфОЭдНГЄЃЌУПзівЛДЮИќаТ,
MySQL ЖМЛсЙиБевЛДЮБэЕФСЌНгвдЪЭЗХжЎЧАЕФзЪдД
БмУтЩОГ§ЕФСаЪЧЫїв§ЕФвЛВПЗж, етРрВйзїЛсЬиБ№Т§, ЗЧвЊЩОГ§ЕФЛАПЩвдШЅЕєЫїв§КЭИУСаЕФЙиСЊдйНјааЩОГ§Вйзї
РЉГфРрЕФВйзїжЛжЇГж char, varchar, varbinary КЭ int РраЭЕФзжЖЮ
вЛДЮжЛ rename вЛСа, ВйзїЖрСаЛсНЕМЖЮЊБъзМЕФ MySQL ааЮЊ, гяЗЈжаСаЕФЪєадБиаывЊжИЖЈЩЯ,
ШчЯТ:

rename ВйзїЛЙВЛжЇГжзжЖЮ: TIME, ENUM, BLOB, TINYBLOB, MEDIUMBLOB,
LONGBLOB.
ВЛжЇГжИќаТСйЪББэ;
5.Ъ§ОнбЙЫѕ
TokuDBжаЫљгаЕФбЙЫѕВйзїЖМдкКѓЬЈжДаа, ИпМЖБ№ЕФбЙЫѕЛсНЕЕЭЯЕЭГЕФадФм, гааЉГЁОАЯТЛсашвЊИпМЖБ№ЕФбЙЫѕ.
АДееЙйЗНЕФНЈвщ: 6КЫЪ§вдЯТЕФЛњЦїНЈвщБъзМбЙЫѕ, ЗДжЎПЩвдЪЙгУИпМЖБ№ЕФбЙЫѕЁЃУПИіБэдк create
table Лђ alter table ЕФЪБКђЭЈЙ§ ROW_FORMAT РДжИЖЈбЙЫѕЕФЫуЗЈ:

ROW_FORMATФЌШЯгЩБфСП tokudb_row_format ПижЦ, ФЌШЯЮЊ tokudb_zlib,
ПЩвдЕФжЕАќРЈ:
tokudb_zlib: ЪЙгУ zlib ПтЕФбЙЫѕФЃЪНЃЌЬсЙЉСЫжаЕШМЖБ№ЕФбЙЫѕБШКЭжаЕШМЖБ№ЕФCPUЯћКФЁЃ
tokudb_quicklz: ЪЙгУ quicklz ПтЕФбЙЫѕФЃЪНЃЌ ЬсЙЉСЫЧсСПМЖЕФбЙЫѕБШКЭНЯЕЭЛљБОЕФCPUЯћКФЁЃ
tokudb_lzma: ЪЙгУlzmaПтбЙЫѕФЃЪНЃЌЬсЙЉСЫИпбЙЫѕБШКЭИпCPUЯћКФЁЃ
tokudb_uncompressed: ВЛЪЙгУбЙЫѕФЃЪНЁЃ
6.Read free ИДжЦЬиад
ЕУвцгк Fracal Tree Ыїв§ЕФЬиад, TokuDB ЕФ slave ЖЫФмЙЛвдЕЭгкЖСIOЕФЯћКФРДгІгУ
master ЖЫЕФБфЛЏ, ЦфжївЊвРРЕ Fractal Tree Ыїв§ЕФЬиадЃЌПЩвддкХфжУРяЦєгУЬиад
insert/delete/updateВйзїВПЗжПЩвджБНгВхШыЕНКЯЪЪЕФ Fractal Tree Ыїв§жа,
БмУт read-modify-write ааЮЊЕФПЊЯњ;
delete/update ВйзїПЩвдКіТдЮЈвЛадМьВщДјРДЕФ IO ЗНУцЕФПЊЯњ
ВЛКУЕФЪЧ, ШчЙћЦєгУСЫ Read Free Replication ЙІФм, Server ЖЫашвЊзіШчЯТЩшжУ:
masterЃКИДжЦИёЪНБиаыЮЊ ROWЃЌ вђЮЊ tokudb ЛЙУЛгаЪЕЯжЖд auto-incrementКЏЪ§НјааМгЫјДІРэ,
ЫљвдЖрИіВЂЗЂЕФВхШыгяОфПЩФмЛсв§Ц№ВЛШЗЖЈЕФ auto-incrementжЕ, гЩДЫдьГЩжїДгСНБпЕФЪ§ОнВЛвЛжТ.
slaveЃКПЊЦє read-only; ЙиБеЮЈвЛадМьВщ(set tokudb_rpl_unique_checks=0);ЙиБеВщев(read-modify-write)ЙІФм(set
tokudb_rpl_lookup_rows=0);
slave ЖЫЕФЩшжУПЩвддквЛЬЈЛђЖрЬЈ slave жаЩшжУЃКMySQL5.5 КЭ MariaDB5.5жажЛгаЖЈвхСЫжїМќЕФБэВХФмЪЙгУИУЙІФм,
MySQL 5.6, Percona 5.6 КЭ MariaDB 10.X УЛгаДЫЯожЦ
7.ЪТЮё, ACID КЭЛжИД
ФЌШЯЧщПіЯТ, TokuDB ЖЈЦкМьВщЫљгаДђПЊЕФБэ, ВЂМЧТМ checkpoint ЦкМфЫљгаЕФИќаТ,
ЫљвддкЯЕЭГБРРЃЕФЪБКђ, ПЩвдЛжИДБэЕНжЎЧАЕФзДЬЌ(ACID-compliant), ЫљгаЕФвбЬсНЛЕФЪТЮёЛсИќаТЕНБэРя,ЮДЬсНЛЕФЪТЮёдђНјааЛиЙі.
ФЌШЯЕФМьВщжмЦкУП60sвЛДЮ, ЪЧДгЕБЧАМьВщЕуЕФПЊЪМЪБМфЕНЯТДЮМьВщЕуЕФПЊЪМЪБМф, ШчЙћ checkpoint
ашвЊИќЖрЕФаХЯЂ, ЯТДЮЕФcheckpoint МьВщЛсСЂМДПЊЪМ, ВЛЙ§етКЭ log ЮФМўЕФЦЕЗБЫЂаТгаЙи.
гУЛЇвВПЩвддкШЮКЮЪБКђЪжЙЄжДаа flush logs УќСюРДв§Ц№вЛДЮ checkpoint МьВщ; дкЪ§ОнПте§ГЃЙиБеЕФЪБКђ,
ЫљгаПЊЦєЕФЪТЮёЖМЛсБЛКіТд.
ЙмРэШежОЕФДѓаЁ: TokuDB вЛжББЃДцзюНќЕФcheckpoingЕНШежОЮФМўжа, ЕБШежОДяЕН100MЕФЪБКђ,
ЛсЦ№вЛИіаТЕФШежОЮФМў; УПДЮcheckpointЕФЪБКђ, ШежОжаОЩгкЕБЧАМьВщЕуЕФЖМЛсБЛКіТд, ШчЙћМьВщЕФжмЦкЩшжУЗЧГЃДѓ,
ШежОЕФЧхРэЦЕТЪвВЛсМѕЩйЁЃ TokuDBвВЛсЮЊУПИіДђПЊЕФЪТЮёЮЌЛЄЛиЙіШежО, ШежОЕФДѓаЁКЭЪТЮёСПгаЙиЃЌ
БЛбЙЫѕБЃДцЕНДХХЬжа, ЕБЪТЮёНсЪјКѓЃЌЛиЙіШежОЛсБЛЯргІЧхРэ.
ЛжИД: TokuDBздЖЏНјааЛжИДВйзї, дкБРРЃКѓЪЙгУШежОКЭЛиЙіШежОНјааЛжИД, ЛжИДЪБМфгЩШежОДѓаЁ(АќРЈЮДбЙЫѕЕФЛиЙіШежО)ОіЖЈ.
НћгУаДЛКДц: ШчЙћвЊБЃжЄЪТЮёАВШЋ, ОЭЕУПМТЧЕНгВМўЗНУцЕФаДЛКДц. TokuDB дк MySQL РявВжЇГжЪТЮёАВШЋЬиад(transaction
safe), ЖдЯЕЭГЖјбд, Ъ§ОнПтИќаТЕФЪ§ОнВЛвЛбљецЕФаДЕНДХХЬРя, ЖјЪЧЛКДцЦ№РД, дкЯЕЭГБРРЃЕФЪБКђЛЙЪЧЛсГіЯжЖЊЪ§ОнЕФЯжЯѓ,
БШШчTokuDBВЛФмБЃжЄЙвдиЕФNFSОэПЩвде§ГЃЛжИД, ЫљвдШчЙћвЊБЃжЄАВШЋ,зюКУЙиБеаДЛКДц, ЕЋЪЧПЩФмЛсдьГЩадФмЕФНЕЕЭ.ЭЈГЃЧщПіЯТашвЊЙиБеДХХЬЕФаДЛКДц,
ВЛЙ§ПМТЧЕНадФмдвђ, XFSЮФМўЯЕЭГЕФЛКДцПЩвдПЊЦє, ВЛЙ§ДЉЯпДэЮѓЁБDisabling barriersЁБКѓЃЌОЭашвЊЙиБеЛКДц.
вЛаЉГЁОАЯТашвЊЙиБеЮФМўЯЕЭГ(ext3)ЛКДц, LVM, ШэRAID КЭДјга BBU(battery-backed-up)
ЬиадЕФRAIDПЈ
8.Й§ГЬзЗзй
TokuDB ЬсЙЉСЫзЗзйГЄЪБМфдЫаагяОфЕФЛњжЦ. Жд LOAD DATA УќСюРДЫЕЃЌSHOW PROCESSLIST
ПЩвдЯдЪОЙ§ГЬаХЯЂ, ЕквЛИіЪЧРрЫЦ ЁАInserted about 1000000 rowsЁБ ЕФзДЬЌаХЯЂ,
ЯТвЛИіЪЧЭъГЩАйЗжБШЕФаХЯЂ, БШШч ЁАLoading of data about 45% doneЁБ;
діМгЫїв§ЕФЪБКђ, SHOW PROCESSLIST ПЩвдЯдЪО CREATE INDEX КЭ ALTER
TABLE ЕФЙ§ГЬаХЯЂ, ЦфЛсЯдЪОааЪ§ЕФЙРЫужЕ, вВЛсЯдЪОЭъГЩЕФАйЗжБШ; SHOW PROCESSLIST
вВЛсЯдЪОЪТЮёЕФжДааЧщПі, БШШч committing Лђ aborting зДЬЌЁЃ
9.ЧЈвЦЕН TokuDB
ПЩвдЪЙгУДЋЭГЕФЗНЪНИќИФБэЕФДцДЂв§Чц, БШШч ЁАALTER TABLE Ё ENGINE = TokuDBЁБ
Лђ mysqldump ЕМГідйЕЙШы, INTO OUTFILE КЭ LOAD DATA INFILE
ЕФЗНЪНвВПЩвдЁЃ
10.ШШБИ
Percona Xtrabackup ЛЙЮДжЇГж TokuDB ЕФШШБИЙІФм, percona вВЮЊБэЪОгажЇГжЕФДђЫу
http://www.percona.com/blog/2014/07/15/tokudb-tips-mysql-backups/
;ЖдгкДѓБэПЩвдЪЙгУ LVM ЬиадНјааБИЗн, https://launchpad.net/mylvmbackup
, Лђ mysdumper НјааБИЗнЁЃTokuDB ЙйЗНЬсЙЉСЫвЛИіШШБИВхМў tokudb_backup.so,
ПЩвдНјаадкЯпБИЗн, ЯъМћ https://github.com/Tokutek/tokudb-backup-pluginЃЌ
ВЛЙ§ЦфвРРЕ backup-enterprise, ЮоЗЈБрвыГі so ЖЏЬЌПт, ЪЧИіЩЬвЕЕФЪеЗбАцБО,
Мћ https://www.percona.com/doc/percona-server/5.6/tokudb/tokudb_installation.html
змНс
TokuDBЕФгХЕу:
ИпбЙЫѕБШЃЌФЌШЯЪЙгУzlibНјаабЙЫѕЃЌгШЦфЪЧЖдзжЗћДЎ(varchar,textЕШ)РраЭгаЗЧГЃИпЕФбЙЫѕБШЃЌБШНЯЪЪКЯДцДЂШежОЁЂдЪМЪ§ОнЕШЁЃЙйЗНаћГЦПЩвдДяЕН1ЃК12ЁЃ
дкЯпЬэМгЫїв§ЃЌВЛгАЯьЖСаДВйзї
HCADER ЬиадЃЌжЇГждкЯпзжЖЮдіМгЁЂЩОГ§ЁЂРЉеЙЁЂжиУќУћВйзїЃЌЃЈЫВМфЛђУыМЖЭъГЩЃЉ
жЇГжЭъећЕФACIDЬиадКЭЪТЮёЛњжЦ
ЗЧГЃПьЕФаДШыадФмЃЌ Fractal-treeдкЪТЮёЪЕЯжЩЯгагХЪЦ,Юоundo logЃЌЙйЗНГЦжСЩйБШinnodbИп9БЖЁЃ
жЇГжshow processlist НјЖШВщПД
Ъ§ОнСППЩвдРЉеЙЕНМИИіTBЃЛ
ВЛЛсВњЩњЫїв§ЫщЦЌЃЛ
жЇГжhot column addition,hot indexing,mvcc
TokuDBШБЕуЃК
ВЛжЇГжЭтМќ(foreign key)ЙІФмЃЌШчЙћФњЕФБэгаЭтМќЃЌЧаЛЛЕН TokuDBв§ЧцКѓЃЌДЫдМЪјНЋБЛКіТдЁЃ
TokuDB ВЛЪЪДѓСПЖСШЁЕФГЁОАЃЌвђЮЊбЙЫѕНтбЙЫѕЕФдвђЁЃCPUеМгУЛсИп2-3БЖЃЌЕЋгЩгкбЙЫѕКѓПеМфаЁЃЌIOПЊЯњЕЭЃЌЦНОљЯьгІЪБМфДѓИХЪЧ2БЖзѓгвЁЃ
online ddl Ждtext,blobЕШРраЭЕФзжЖЮВЛЪЪгУ
УЛгаЭъЩЦЕФШШБИЙЄОпЃЌжЛФмЭЈЙ§mysqldumpНјааТпМБИЗн
ЪЪгУГЁОАЃК
ЗУЮЪЦЕТЪВЛИпЕФЪ§ОнЛђРњЪЗЪ§ОнЙщЕЕ
Ъ§ОнБэЗЧГЃДѓВЂЧвЪБВЛЪБЛЙашвЊНјааDDLВйзї
TokuDBЕФЫїв§НсЙЙЈCЗжаЮЪїЕФЪЕЯж
TokuDBКЭInnoDBзюДѓЕФВЛЭЌдкгкTokuDBВЩгУСЫвЛжжНазіFractal TreeЕФЫїв§НсЙЙЃЌЪЙЦфдкЫцЛњаДЪ§ОнЕФДІРэЩЯгаКмДѓЬсЩ§ЁЃФПЧАЮоТлЪЧSQL
ServerЃЌЛЙЪЧMySQLЕФinnodbЃЌЖМЪЧгУЕФB+TreeЃЈSQL ServerгУЕФЪЧБъзМЕФB-TreeЃЉЕФЫїв§НсЙЙЁЃInnoDBЪЧвджїМќзщжЏЕФB+TreeНсЙЙЃЌЪ§ОнАДеежїМќЫГађХХСаЁЃЖдгкЫГађЕФзддіжїМќгаКмКУЕФадФмЃЌЕЋЪЧВЛЪЪКЯЫцЛњаДШыЃЌДѓСПЕФЫцЛњI/OЛсЪЙЪ§ОнвГЗжСбВњЩњЫщЦЌЃЌЫїв§ЮЌЛЄПЊЯњКмЖрДѓЁЃTokuDBНтОіЫцЛњаДШыЕФЮЪЬтЕУвцгкЦфЫїв§НсЙЙЃЌFractal
Tree КЭ B-TreeЕФВюБ№жївЊдкгкЫїв§ЪїЕФФкВПНкЕуЩЯЃЌB-TreeЫїв§ЕФФкВПНсЙЙжЛгажИЯђИИНкЕуКЭзгНкЕуЕФжИеыЃЌЖјFractal
TreeЕФФкВПНкЕуВЛНігажИЯђИИНкЕуКЭзгНкЕуЕФжИеыЃЌЛЙгавЛПщBufferЧјЁЃЕБЪ§ОнаДШыЪБЛсЯШТфЕНетИіBufferЧјЩЯЃЌИУЧјЪЧвЛИіFIFOНсЙЙЃЌаДЪЧвЛИіЫГађЕФЙ§ГЬЃЌКЭЦфЫћЛКГхЧјвЛбљЃЌТњСЫОЭвЛДЮадЫЂаДЪ§ОнЁЃЫљвдTokuDBЩЯВхШыЪ§ОнЛљБОЩЯБфГЩСЫвЛИіЫГађЬэМгЕФЙ§ГЬЁЃ
BTreeКЭFractal treeЕФБШНЯЃК

Fractal tree(ЗжаЮЪї)МђНщ
ЗжаЮЪїЪЧвЛжжаДгХЛЏЕФДХХЬЫїв§Ъ§ОнНсЙЙЁЃ дквЛАуЧщПіЯТЃЌ ЗжаЮЪїЕФаДВйзїЃЈInsert/Update/DeleteЃЉадФмБШНЯКУЃЌЭЌЪБЫќЛЙФмБЃжЄЖСВйзїНќЫЦгкB+ЪїЕФЖСадФмЁЃОнPerconaЙЋЫОВтЪдНсЙћЯдЪО,
TokuDBЗжаЮЪїЕФаДадФмгХгкInnoDBЕФB+Ъї)ЃЌ ЖСадФмТдЕЭгкB+ЪїЁЃ
ft-indexЕФДХХЬДцДЂНсЙЙ
ft-indexВЩгУИќДѓЕФЫїв§вГКЭЪ§ОнвГЃЈft-indexФЌШЯЮЊ4M, InnoDBФЌШЯЮЊ16KЃЉЃЌ
етЪЙЕУft-indexЕФЪ§ОнвГКЭЫїв§вГЕФбЙЫѕБШИќИпЁЃвВОЭЪЧЫЕЃЌдкДђПЊЫїв§вГКЭЪ§ОнвГбЙЫѕЕФЧщПіЯТЃЌВхШыЕШСПЕФЪ§ОнЃЌ
ft-indexеМгУЕФДцДЂПеМфИќЩйЁЃft-indexжЇГждкЯпаоИФDDL (Hot Schema Change)ЁЃ
МђЕЅРДНВЃЌОЭЪЧдкзіDDLВйзїЕФЭЌЪБ(Р§ШчЬэМгЫїв§)ЃЌгУЛЇвРШЛПЩвджДаааДШыВйзїЃЌ етИіЬиЕуЪЧft-indexЪїаЮНсЙЙЬьШЛжЇГжЕФЁЃ
ДЫЭтЃЌ ft-indexЛЙжЇГжЪТЮё(ACID)вдМАЪТЮёЕФMVCC(Multiple Version
Cocurrency Control ЖрАцБОВЂЗЂПижЦ)ЃЌ жЇГжБРРЃЛжИДЁЃе§вђЮЊЩЯЪіЬиЕуЃЌ PerconaЙЋЫОаћГЦTokuDBвЛЗНУцДјИјПЭЛЇМЋДѓЕФадФмЬсЩ§ЃЌ
СэвЛЗНУцЛЙНЕЕЭСЫПЭЛЇЕФДцДЂЪЙгУГЩБОЁЃ
ft-indexЕФЫїв§НсЙЙЭМШчЯТЃК
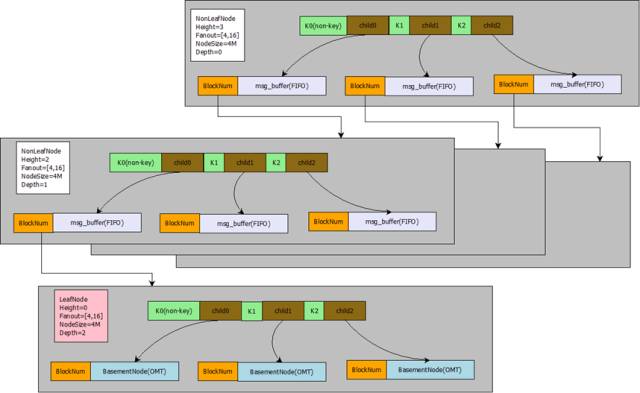
ЛвЩЋЧјгђБэЪОft-indexЗжаЮЪїЕФвЛИівГЃЌТЬЩЋЧјгђБэЪОвЛИіМќжЕЃЌСНИёТЬЩЋЧјгђжЎМфБэЪОвЛИіЖљзгжИеыЁЃ
BlockNumБэЪОЖљзгжИеыжИЯђЕФвГЕФЦЋвЦСПЁЃFanoutБэЪОЗжаЮЪїЕФЩШГіЃЌвВОЭЪЧЖљзгжИеыЕФИіЪ§ЁЃ
NodeSizeБэЪОвЛИівГеМгУЕФзжНкЪ§ЁЃNonLeafNodeБэЪОЕБЧАвГЪЧвЛИіЗЧвЖзгНкЕуЃЌLeafNodeБэЪОЕБЧАвГЪЧвЛИівЖзгНкЕуЃЌвЖзгНкЕуЪЧзюЕзВуЕФДцЗХKey-valueМќжЕЖдЕФНкЕуЃЌ
ЗЧвЖзгНкЕуВЛДцЗХvalueЁЃ HeigthБэЪОЪїЕФИпЖШЃЌ ИљНкЕуЕФИпЖШЮЊ3ЃЌ ИљНкЕуЯТвЛВуНкЕуЕФИпЖШЮЊ2ЃЌ
зюЕзВувЖзгНкЕуЕФИпЖШЮЊ1ЁЃDepthБэЪОЪїЕФЩюЖШЃЌИљНкЕуЕФЩюЖШЮЊ0ЃЌ ИљНкЕуЕФЯТвЛВуНкЕуЩюЖШЮЊ1ЁЃ
ЗжаЮЪїЕФЪїаЮНсЙЙЗЧГЃРрЫЦгкB+Ъї, ЫќЕФЪїаЮНсЙЙгЩШєИЩИіНкЕузщГЩЃЈЮвУЧГЦжЎЮЊNodeЛђепBlockЃЌдкInnoDBжаЃЌЮвУЧГЦжЎЮЊPageЛђепвГЃЉЁЃ
УПИіНкЕугЩвЛзщгаађЕФМќжЕзщГЩЁЃМйЩшвЛИіНкЕуЕФМќжЕађСаЮЊ[3, 8], ФЧУДетИіМќжЕНЋ(-00, +00)ећИіЧјМфЛЎЗжЮЊ(-00,
3), [3, 8), [8, +00) етбљ3ИіЧјМфЃЌ УПвЛИіЧјМфОЭЖдгІзХвЛИіЖљзгжИеыЃЈChildжИеыЃЉЁЃ
дкB+ЪїжаЃЌ ChildжИеывЛАужИЯђвЛИівГЃЌ ЖјдкЗжаЮЪїжаЃЌУПвЛИіChildжИеыГ§СЫашвЊжИЯђвЛИіNodeЕФЕижЗ(BlockNum)жЎЭтЃЌЛЙЛсДјгавЛИіMessage
Buffer (msg_buffer)ЃЌ етИіMessage Buffer ЪЧвЛИіЯШНјЯШГі(FIFO)ЕФЖгСаЃЌгУРДДцЗХInsert/Delete/Update/HotSchemaChangeетбљЕФИќаТВйзїЁЃ
АДееft-indexдДДњТыЕФЪЕЯжЃЌ Ждft-indexжаЗжаЮЪїИќЮЊбЯНїЕФЫЕЗЈЃК
НкЕу(blockЛђепnode, дкInnoDBжаЮвУЧГЦжЎЮЊPageЛђепвГ)ЪЧгЩвЛзщгаађЕФМќжЕзщГЩЃЌ
ЕквЛИіМќжЕЩшжУЮЊnullМќжЕЃЌ БэЪОИКЮоЧюДѓЁЃ
НкЕуЗжЮЊСНжжРраЭЃЌвЛжжЪЧвЖзгНкЕуЃЌ вЛжжЪЧЗЧвЖзгНкЕуЁЃ вЖзгНкЕуЕФЖљзгжИеыжИЯђЕФЪЧBasementNode,
ЗЧвЖзгНкЕужИЯђЕФЪЧе§ГЃЕФNode ЁЃ етРяЕФBasementNodeНкЕуДцЗХЕФЪЧЖрИіK-VМќжЕЖдЃЌ
вВОЭЪЧЫЕзюКѓЫљгаЕФВщевВйзїЖМашвЊЖЈЮЛЕНBasementNodeВХФмГЩЙІЛёШЁЕНЪ§Он(Value)ЁЃетвЛЕувВКЭB+ЪїЕФLeafPageРрЫЦЃЌ
Ъ§Он(Value)ЖМЪЧДцЗХдквЖзгНкЕуЃЌ ЗЧвЖзгНкЕугУРДДцЗХМќжЕ(Key)зіЫїв§ЁЃ ЕБвЖзгНкЕуМгдиЕНФкДцКѓЃЌЮЊСЫПьЫйВщевЕНBasementNodeжаЕФЪ§Он(Value)ЃЌ
ft-indexЛсАбећИіBasementNodeжаЕФkey-valueЖМзЊЛЛЮЊвЛПУШѕЦНКтЖўВцЪїЃЌ етПУЦНКтЖўВцЪїгавЛИіКмЖКБЦЕФУћзжЃЌНазіЬцзябђЪїЁЃ
УПИіНкЕуЕФМќжЕЧјМфЖдгІзХвЛИіЖљзгжИеы(Child Pointer)ЁЃ ЗЧвЖзгНкЕуЕФЖљзгжИеыаЏДјзХвЛИіMessageBufferЃЌ
MessageBufferЪЧвЛИіFIFOЖгСаЁЃгУРДДцЗХInsert/Delete/Update/HotSchemaChangeетбљЕФИќаТВйзїЁЃЖљзгжИеывдМАMessageBufferЖМЛсађСаЛЏДцЗХдкNodeЕФДХХЬЮФМўжаЁЃ
УПИіЗЧвЖзгНкЕу(Non Leaf Node)ЖљзгжИеыЕФИіЪ§Биаыдк[fantout/4, fantout]етИіЧјМфжЎФкЁЃ
етРяfantoutЪЧЗжаЮЪїЃЈB+ЪївВгаетИіИХФюЃЉЕФвЛИіВЮЪ§ЃЌетИіВЮЪ§жївЊгУРДЮЌГжЪїЕФИпЖШЁЃЕБвЛИіЗЧвЖзгНкЕуЕФЖљзгжИеыИіЪ§аЁгкfantout/4
ЃЌ ФЧУДЮвУЧШЯЮЊетИіНкЕуЕФЬЋПеащСЫЃЌашвЊКЭЦфЫћНкЕуКЯВЂЮЊвЛИіНкЕу(Node Merge)ЃЌ етбљФмМѕЩйећИіЪїЕФИпЖШЁЃЕБвЛИіЗЧвЖзгНкЕуЕФЖљзгжИеыИіЪ§ГЌЙ§fantoutЃЌ
ФЧУДЮвУЧШЯЮЊетИіНкЕуЬЋБЅТњСЫЃЌ ашвЊНЋвЛИіНкЕувЛВ№ЮЊЖў(Node Split)ЁЃ ЭЈЙ§етжждМЪјПижЦЃЌРэТлЩЯОЭФмНЋДХХЬЪ§ОнЮЌГждквЛИіе§ГЃЕФЯрЖдЦНКтЕФЪїаЮНсЙЙЃЌетбљПЩвдПижЦВхШыКЭВщбЏИДдгЖШЩЯЯоЁЃ
зЂвтЃК дкft-indexЪЕЯжжаЃЌПижЦЪїЦНКтЕФЬѕМўИќМгИДдгЃЌ Р§ШчГ§СЫПМТЧfantoutжЎЭтЃЌЛЙвЊБЃжЄНкЕузмзжНкЪ§дк[NodeSize/4,
NodeSize]етИіЧјМфЃЌ NodeSizeвЛАуЮЊ4M ЃЌЕБВЛдкетИіЧјМфЪБЃЌ ашвЊзіЖдгІЕФКЯВЂ(Merge)ЛђепЗжСб(Split)ВйзїЁЃ
ЗжаЮЪїЕФInsert/Delete/UpdateЪЕЯж
ЮвУЧЫЕЕНЗжаЮЪїЪЧвЛжжаДгХЛЏЕФЪ§ОнНсЙЙЃЌ ЫќЕФаДВйзїадФмвЊгХгкB+ЪїЕФаДВйзїадФмЁЃ ФЧУДЫќОПОЙШчКЮзіЕНИќгХЕФаДВйзїадФмФиЃПЪзЯШЃЌ
етРяЫЕЕФаДВйзїадФмЃЌжИЕФЪЧЫцЛњаДВйзїЁЃ ОйИіМђЕЅР§згЃЌМйЩшЮвУЧдкMySQLЕФInnoDBБэжаВЛЖЯжДааетИіSQLгяОфЃК
insert into sbtest set x = uuid()ЃЌ ЦфжаsbtestБэжагавЛИіЮЈвЛЫїв§зжЖЮЮЊxЁЃ
гЩгкuuid()ЕФЫцЛњадЃЌНЋЕМжТВхШыЕНsbtestБэжаЕФЪ§ОнЩЂТфдкИїИіВЛЭЌЕФвЖзгНкЕу(Leaf Node)жаЁЃ
дкB+ЪїжаЃЌ ДѓСПЕФетжжЫцЛњаДВйзїНЋЕМжТLRU-CacheжаДѓСПЕФШШЕуЪ§ОнвГТфдкB+ЪїЕФЩЯВу(ШчЯТЭМЫљЪОЃЉЁЃетбљЕзВуЕФвЖзгНкЕуУќжаCacheЕФИХТЪНЕЕЭЃЌДгЖјдьГЩДѓСПЕФДХХЬIOВйзїЃЌ
вВОЭЕМжТB+ЪїЕФЫцЛњаДадФмЦПОБЁЃЕЋB+ЪїЕФЫГађаДВйзїКмПьЃЌвђЮЊЫГађаДВйзїГфЗжРћгУСЫОжВПШШЕуЪ§ОнЃЌ ДХХЬIOДЮЪ§ДѓДѓНЕЕЭЁЃ
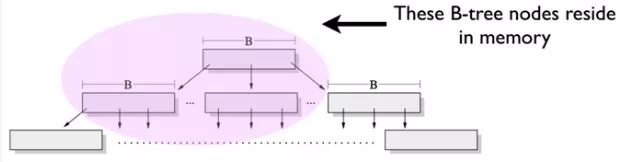
ЯТУцРДЫЕЫЕЗжаЮЪїВхШыВйзїЕФСїГЬЁЃ ЮЊСЫЗНБуКѓУцУшЪіЃЌдМЖЈШчЯТЃК
вдInsertВйзїЮЊР§ЃЌ МйЖЈВхШыЕФЪ§ОнЮЊ(Key, Value)
МгдиНкЕу(Load Page)ЃЌЖМЪЧЯШХаЖЯИУНкЕуЪЧЗёУќжаLRU-CacheЁЃНіЕБЛКДцВЛУќжаЪБЃЌ ft-indexВХЛсЭЈЙ§seedЖЈЮЛЕНЦЋвЦСПЖСШЁЪ§ОнвГЕНФкДц
днЪБВЛПМТЧБРРЃШежОКЭЪТЮёДІРэЁЃ
ЯъЯИСїГЬШчЯТЃК
1ЁЂМгдиRootНкЕуЃЛ
2ЁЂХаЖЯRootНкЕуЪЧЗёашвЊЗжСб(ЛђКЯВЂ)ЃЌШчЙћТњзуЗжСб(ЛђепКЯВЂ)ЬѕМўЃЌдђЗжСб(ЛђепКЯВЂ)RootНкЕуЁЃ
ОпЬхЗжСбRootНкЕуЕФСїГЬЃЌИааЫШЄЕФЭЌбЇПЩвдПЊПЊФдЖДЁЃ
3ЁЂЕБRootНкЕуheight>0, вВОЭЪЧRootЪЧЗЧвЖзгНкЕуЪБЃЌ ЭЈЙ§ЖўЗжЫбЫїевЕНKeyЫљдкЕФМќжЕЧјМфRangeЃЌНЋ(Key,
Value)АќзАГЩвЛЬѕЯћЯЂ(Insert, Key, Value) ЃЌ ЗХШыЕНМќжЕЧјМфRangeЖдгІЕФChildжИеыЕФMessage
BufferжаЁЃ
4ЁЂЕБRootНкЕуheight=0ЪБЃЌМДRootЪЧвЖзгНкЕуЪБЃЌ НЋЯћЯЂ(Insert, Key,
Value) гІгУ(Apply)ЕНBasementNodeЩЯЃЌ вВОЭЪЧВхШы(Key, Value)ЕНBasementNodeжаЁЃ
етРягавЛИіЗЧГЃЙювьЕФЕиЗНЃЌдкДѓСПЕФВхШыЃЈАќРЈЫцЛњКЭЫГађВхШыЃЉЧщПіЯТЃЌ RootНкЕуЛсОГЃадЕФБЛГХБЅТњЃЌетНЋЛсЕМжТRootНкЕузіДѓСПЕФЗжСбВйзїЁЃШЛКѓЃЌRootНкЕузіСЫДѓСПЕФЗжСбВйзїжЎКѓЃЌВњЩњДѓСПЕФheight=1ЕФНкЕуЃЌ
ШЛКѓheight=1ЕФНкЕуБЛГХБЌТњжЎКѓЃЌгжЛсВњЩњДѓСПheight=2ЕФНкЕуЃЌ зюжеЪїЕФИпЖШдНРДдНИпЁЃ
етИіЙювьЕФжЎДІОЭвўВиСЫЗжаЮЪїаДВйзїадФмБШB+ЪїИпЕФУиОїЃК УПвЛДЮВхШыВйзїЖМТфдкRootНкЕуОЭТэЩЯЗЕЛиСЫЃЌ
УПДЮаДВйзїВЂВЛашвЊЫбЫїЪїаЮНсЙЙзюЕзВуЕФBasementNodeЃЌ етбљЛсЕМжТДѓСПЕФШШЕуЪ§ОнМЏжаТфдкдкRootНкЕуЕФЩЯВу(ДЫЪБЕФШШЕуЪ§ОнЗжВМЭМРрЫЦгкЩЯЭМ)ЃЌ
ДгЖјГфЗжРћгУШШЕуЪ§ОнЕФОжВПадЃЌДѓДѓМѕЩйСЫДХХЬIOВйзїЁЃ
Update/DeleteВйзїЕФЧщПіКЭInsertВйзїЕФЧщПіРрЫЦЃЌ ЕЋЪЧашвЊЬиБ№зЂвтЕФЕиЗНдкгкЃЌгЩгкЗжаЮЪїЫцЛњЖСадФмВЂВЛШчInnoDBЕФB+ЪїЁЃвђДЫЃЌUpdate/DeleteВйзїашвЊЯИЗжЮЊСНжжЧщПіПМТЧЃЌетСНжжЧщПіВтЪдадФмПЩФмВюОрОоДѓЃК
ИВИЧЪНЕФUpdate/Delete (overwrite)ЁЃ вВОЭЪЧЕБkeyДцдкЪБЃЌ жДааUpdate/DeleteЃЛ
ЕБkeyВЛДцдкЪБЃЌВЛзіШЮКЮВйзїЃЌвВВЛашвЊБЈДэЁЃ
бЯИёЦЅХфЕФUpdate/DeleteЁЃ ЕБkeyДцдкЪБЃЌ жДааupdate/delete ; ЕБkeyВЛДцдкЪБЃЌ
ашвЊБЈДэИјЩЯВугІгУЗНЁЃ дкетжжЧщПіЯТЃЌЮвУЧашвЊЯШВщбЏkeyЪЧЗёДцдкгкft-indexЕФbasementnodeжаЃЌгкЪЧPoint-QueryФЌФЌЕФЭЯСЫUpdate/DeleteВйзїЕФадФмКѓЭЫЁЃ
ДЫЭтЃЌft-indexЮЊСЫЬсЩ§ЫГађаДЕФадФмЃЌЖдЫГађВхШыВйзїзіСЫвЛаЉгХЛЏЃЌР§ШчЫГађаДМгЫйЁЃ
ЗжаЮЪїЕФPoint-QueryЪЕЯж
дкft-indexжаЃЌ РрЫЦselect from table where id = ? ЃЈЦфжаidЪЧЫїв§ЃЉЕФВщбЏВйзїГЦжЎЮЊPoint-QueryЃЛ
РрЫЦselect from table where id >= ? and id <=
? ЃЈЦфжаidЪЧЫїв§ЃЉЕФВщбЏВйзїГЦжЎЮЊRange-QueryЁЃ ЩЯЮФвбОЬсЕНЃЌ Point-QueryЖСВйзїадФмВЂВЛШчInnoDBЕФB+ЪїЃЌ
етРяЯъЯИУшЪіPoint-QueryЕФЯрЙиСїГЬЁЃ ЃЈетРяМйЩшвЊВщбЏЕФМќжЕЮЊKeyЃЉ
1ЁЂМгдиRootНкЕуЃЌЭЈЙ§ЖўЗжЫбЫїШЗЖЈKeyТфдкRootНкЕуЕФМќжЕЧјМфRange, евЕНЖдгІЕФRangeЕФChildжИеыЁЃ
2ЁЂМгдиChildжИеыЖдгІЕФЕФНкЕуЁЃ ШєИУНкЕуЮЊЗЧвЖзгНкЕуЃЌдђМЬајбизХЗжаЮЪївЛжБЭљЯТВщевЃЌвЛжБЕНвЖзгНкЕуЭЃжЙЁЃ
ШєЕБЧАНкЕуЮЊвЖзгНкЕуЃЌдђЭЃжЙВщевЁЃ
ВщевЕНвЖзгНкЕуКѓЃЌЮвУЧВЂВЛФмжБНгЗЕЛивЖзгНкЕужаЕФBasementNodeЕФValueИјгУЛЇЁЃ вђЮЊЗжаЮЪїЕФВхШыВйзїЪЧЭЈЙ§ЯћЯЂ(Message)ЕФЗНЪНВхШыЕФЃЌ
ДЫЪБашвЊАбДгRootНкЕуЕНвЖзгНкЕуетЬѕТЗОЖЩЯЕФЫљгаЯћЯЂвРДЮapplyЕНвЖзгНкЕуЕФBasementNodeЁЃ
Д§applyЫљгаЕФЯћЯЂЭъГЩжЎКѓЃЌВщевBasementNodeжаЕФkeyЖдгІЕФvalueЃЌОЭЪЧгУЛЇашвЊВщевЕФжЕЁЃ
ЗжаЮЪїЕФВщевСїГЬЛљБОКЭ InnoDBЕФB+ЪїЕФВщевСїГЬРрЫЦЃЌ ЧјБ№дкгкЗжаЮЪїашвЊНЋДгRootНкЕуЕНвЖзгНкЕуетЬѕТЗОЖЩЯЕФmessge
bufferЖМЭљЯТЭЦЃЌВЂНЋЯћЯЂapplyЕНBasementNodeНкЕуЩЯЁЃзЂвтВщевСїГЬашвЊЯТЭЦЯћЯЂЃЌ
етПЩФмЛсдьГЩТЗОЖЩЯЕФВПЗжНкЕуБЛГХБЅТњЃЌЕЋЪЧft-indexдкВщбЏЙ§ГЬжаВЂВЛЛсЖдвЖзгНкЕузіЗжСбКЭКЯВЂВйзїЃЌ
вђЮЊft-indexЕФЩшМЦддђЪЧЃК Insert/Update/DeleteВйзїИКд№НкЕуЕФSplitКЭMerge,
SelectВйзїИКд№ЯћЯЂЕФбгГйЯТЭЦ(Lazy Push)ЁЃ етбљЃЌЗжаЮЪїОЭНЋInsert/Delete/UpdateетРрИќаТВйзїЭЈЙ§ЮДРДЕФSelectВйзїгІгУЕНОпЬхЕФЪ§ОнНкЕуЃЌДгЖјЭъГЩИќаТЁЃ
ЗжаЮЪїЕФRange-QueryЪЕЯж
ЯТУцРДНщЩмRange-QueryЕФВщбЏЪЕЯжЁЃМђЕЅРДНВЃЌ ЗжаЮЪїЕФRange-QueryЛљБОЕШМлгкНјааNДЮPoint-QueryВйзїЃЌВйзїЕФДњМлвВЛљБОЕШМлгкNДЮPoint-QueryВйзїЕФДњМлЁЃ
гЩгкЗжаЮЪїдкЗЧвЖзгНкЕуЕФmsg_bufferжаДцЗХзХBasementNodeЕФИќаТВйзїЃЌвђДЫЮвУЧдкВщевУПвЛИіKeyЕФValueЪБЃЌЖМашвЊДгИљНкЕуВщевЕНвЖзгНкЕуЃЌ
ШЛКѓНЋетЬѕТЗОЖЩЯЕФЯћЯЂapplyЕНbasenmentNodeЕФValueЩЯЁЃ етИіСїГЬПЩвдгУЯТЭМРДБэЪОЁЃ
.jpg)
ЕЋЪЧдкB+ЪїжаЃЌ гЩгкЕзВуЕФИїИівЖзгНкЕуЖМЭЈЙ§жИеызщжЏГЩвЛИіЫЋЯђСДБэЃЌ НсЙЙШчЯТЭМЫљЪОЁЃ вђДЫЃЌЮвУЧжЛашвЊДгИњНкЕуЕНвЖзгНкЕуЖЈЮЛЕНЕквЛИіТњзуЬѕМўЕФKey,
ШЛКѓВЛЖЯдквЖзгНкЕуЕќДњnextжИеыЃЌМДПЩЛёШЁЕНRange-QueryЕФЫљгаKey-ValueМќжЕЁЃвђДЫЃЌЖдгкB+ЪїЕФRange-QueryВйзїРДЫЕЃЌГ§СЫЕквЛДЮашвЊДгrootНкЕуБщРњЕНвЖзгНкЕузіЫцЛњаДВйзїЃЌКѓМЬЪ§ОнЖСШЁЛљБОПЩвдПДзіЪЧЫГађIOЁЃ
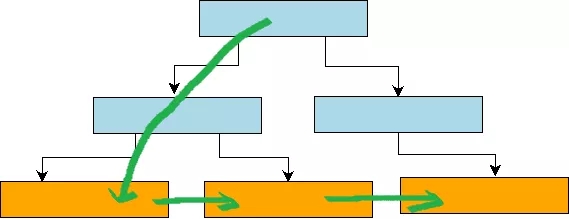
ЭЈЙ§БШНЯЗжаЮЪїКЭB+ЪїЕФRange-QueryЪЕЯжПЩвдЗЂЯжЃЌ ЗжаЮЪїЕФRange-QueryВщбЏДњМлУїЯдБШB+ЪїДњМлИпЃЌвђЮЊЗжаЭЪїашвЊБщРњRootНкЕуЕФИВИЧRangeЕФећПХзгЪїЃЌЖјB+ЪїжЛашвЊвЛДЮSeedЕНRangeЕФЦ№ЪМKeyЃЌКѓајЕќДњЛљБОЕШМлгкЫГађIOЁЃ
змНс
змЬхРДЫЕЃЌЗжаЮЪїЪЧвЛжжаДгХЛЏЕФЪ§ОнНсЙЙЃЌЫќЕФКЫаФЫМЯыЪЧРћгУНкЕуЕФMessageBufferЛКДцИќаТВйзїЃЌГфЗжРћгУЪ§ОнОжВПаддРэЃЌ
НЋЫцЛњаДзЊЛЛЮЊЫГађаДЃЌетбљМЋДѓЕФЬсИпСЫЫцЛњаДЕФаЇТЪЁЃTokutekбаЗЂЭХЖгЕФiiBenchВтЪдНсЙћЯдЪОЃК
TokuDBЕФinsertВйзї(ЫцЛњаД)ЕФадФмБШInnoDBПьКмЖрЃЌЖјSelectВйзї(ЫцЛњЖС)ЕФадФмЕЭгкInnoDBЕФадФмЃЌЕЋЪЧВюОрНЯаЁЃЌЭЌЪБгЩгкTokuDBВЩгУга4MЕФДѓвГДцДЂЃЌЪЙЕУбЙЫѕБШНЯИпЁЃетвВЪЧPerconaЙЋЫОаћГЦTokuDBИќИпадФмЃЌИќЕЭГЩБОЕФдвђЁЃ
СэЭтЃЌдкЯпИќаТБэНсЙЙ(Hot Schema Change)ЪЕЯжвВЪЧЛљгкMessageBufferРДЪЕЯжЕФЃЌ
ЕЋКЭInsert/Delete/UpdateВйзїВЛЭЌЕФЪЧЃЌ ЧАепЕФЯћЯЂЯТЭЦЗНЪНЪЧЙуВЅЪНЯТЭЦЃЈИИНкЕуЕФвЛЬѕЯћЯЂЃЌгІгУЕНЫљгаЕФЖљзгНкЕуЃЉЃЌ
КѓепЕФЯћЯЂЯТЭЦЗНЪНЕЅВЅЪНЯТЭЦЃЈИИНкЕуЕФвЛЬѕЯћЯЂЃЌгІгУЕНЖдгІМќжЕЧјМфЕФЖљзгНкЕу)ЃЌ гЩгкЪЕЯжРрЫЦгкInsertВйзїЃЌЫљвдВЛдйеЙПЊУшЪіЁЃ
TokuDBЕФЖрАцБОВЂЗЂПижЦ(MVCC)
дкДЋЭГЕФЙиЯЕаЭЪ§ОнПтЃЈР§ШчOracle, MySQL, SQLServerЃЉжаЃЌЪТЮёПЩвдЫЕЪЧбаЗЂКЭЬжТлзюКЫаФФкШнЁЃЖјЪТЮёзюКЫаФЕФаджЪОЭЪЧACIDЁЃ
AБэЪОдзгадЃЌвВОЭЪЧзщГЩЪТЮёЕФЫљгазгШЮЮёжЛгаСНжжНсЙћЃКвЊУДЫцзХЪТЮёЕФЬсНЛЃЌЫљгазгШЮЮёЖМГЩЙІжДааЃЛвЊУДЫцзХЪТЮёЕФЛиЙіЃЌЫљгазгШЮЮёЖМГЗЯњЁЃ
CБэЪОвЛжТадЃЌвВОЭЪЧЮоТлЪТЮёЬсНЛЛђепЛиЙіЃЌЖМВЛФмЦЦЛЕЪ§ОнЕФвЛжТаддМЪјЃЌетаЉвЛжТаддМЪјАќРЈМќжЕЮЈвЛдМЪјЁЂМќжЕЙиСЊЙиЯЕдМЪјЕШЁЃ
IБэЪОИєРыадЃЌИєРыадвЛАуЪЧеыЖдЖрИіВЂЗЂЪТЮёЖјбдЕФЃЌвВОЭЪЧдкЭЌвЛИіЪБМфЕуЃЌt1ЪТЮёКЭt2ЪТЮёЖСШЁЕФЪ§ОнгІИУЪЧИєРыЕФЃЌетСНИіЪТЮёОЭКУЯёНјСЫЭЌвЛОЦЕъЕФСНМфЗПМфвЛбљЃЌИїзддкИїздЕФЗПМфРяУцЛюЖЏЃЌЫћУЧЯрЛЅжЎМфВЂВЛФмПДЕНИїзддкИЩТяЁЃ
DБэЪОГжОУадЃЌетИіаджЪБЃжЄСЫвЛИіЪТЮёвЛЕЉГаХЕгУЛЇГЩЙІЬсНЛЃЌФЧУДМДБуЪЧКѓМЬЪ§ОнПтНјГЬcrashЛђепВйзїЯЕЭГcrashЃЌжЛвЊДХХЬЪ§ОнУЛЛЕЃЌФЧУДЯТДЮЦєЖЏЪ§ОнПтКѓЃЌетИіЪТЮёЕФжДааНсЙћШдШЛПЩвдЖСШЁЕНЁЃ
TokuDBФПЧАЭъШЋжЇГжЪТЮёЕФACIDЁЃ ДгЪЕЯжЩЯПДЃЌ гЩгкTokuDBВЩгУЕФЗжаЮЪїзїЮЊЫїв§ЃЌЖјInnoDBВЩгУB+ЪїзїЮЊЫїв§НсЙЙЃЌвђЖјTokuDBдкЪТЮёЕФЪЕЯжЩЯКЭInnoDBгаКмДѓВЛЭЌЁЃ
дкInnoDBжаЃЌ ЩшМЦСЫredoКЭundoСНжжШежОЃЌredoДцЗХвГЕФЮяРэаоИФШежОЃЌгУРДБЃжЄЪТЮёЕФГжОУадЃЛ
undoДцЗХЪТЮёЕФТпМаоИФШежОЃЌЫќЪЕМЪДцЗХСЫвЛЬѕМЧТМдкЖрИіВЂЗЂЪТЮёЯТЕФЖрИіАцБОЃЌгУРДЪЕЯжЪТЮёЕФИєРыад(MVCC)КЭЛиЙіВйзїЁЃгЩгкTokuDBЕФЗжаЮЪїВЩгУЯћЯЂДЋЕнЕФЗНЪНРДзідіЩОИФИќаТВйзїЃЌвЛЬѕЯћЯЂОЭЪЧЪТЮёЖдИУМЧТМаоИФЕФвЛИіАцБОЃЌвђДЫЃЌдкTokuDBдДТыЪЕЯжжаЃЌВЂУЛгаЖюЭтЕФundo-logЕФИХФюКЭЪЕЯжЃЌШЁЖјДњжЎЕФЪЧвЛЬѕМЧТМЖрЬѕЯћЯЂЕФЙмРэЛњжЦЁЃЫфШЛвЛЬѕМЧТМЖрЬѕЯћЯЂЕФЗНЪНПЩвдЪЕЯжЪТЮёЕФMVCCЃЌШДЮоЗЈНтОіЪТЮёЛиЙіЕФЮЪЬтЃЌвђДЫTokuDBЖюЭтЩшМЦСЫtokudb.rollbackетИіШежОЮФМўРДзіАяжњЪЕЯжЪТЮёЛиЙіЁЃ
етРяжївЊЗжЮіTokuDBЕФЪТЮёИєРыадЕФЪЕЯжЃЌвВОЭЪЧГЃЬсЕНЕФЖрАцБОВЂЗЂПижЦ(MVCC)ЁЃ
TokuDBЕФЪТЮёБэЪО
дкtokudbжаЃЌ дкгУЛЇжДааЕФвЛИіЪТЮёЃЌОпЬхЕНДцДЂв§ЧцВуУцЛсБЛВ№ПЊГЩаэЖрИіаЁЪТЮё(етжжаЁЪТЮёМЧЮЊtxn)ЁЃ
Р§ШчгУЛЇжДааетбљвЛИіЪТЮёЃК

ЖдгІЕНTokuDBДцДЂв§ЧцЕФredo-logжаЕФМЧТМЮЊЃК

ЖдгІЕФЪТЮёЪїШчЯТЭМЫљЪОЃК
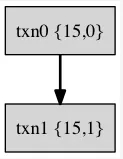
ЖдвЛИіНЯЮЊИДдгвЛЕуЃЌДјгаsavepointЕФЪТЮёР§згЃК
ЖдгІЕФredo-logЕФМЧТМЮЊЃК

етИіЪТЮёзщГЩЕФвЛПУЪТЮёЪїШчЯТЃК
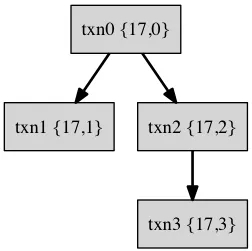
дкtokudbжаЃЌЪЙгУ{parent_id, child_id}етбљвЛИіЖўдЊзщРДМЧТМвЛИіtxnКЭЦфЫћtxnЕФвРРЕЙиЯЕЁЃетбљДгИљЪТЮёЕНвЖзгМИЕуЕФвЛзщБъКХОЭПЩвдЮЈвЛБъЪОвЛИіtxnЃЌ
етвЛзщБъКХСаБэГЦжЎЮЊxidsЃЌ xidsЮвШЯЮЊвВПЩвдГЦЮЊЪТЮёКХЁЃ Р§Шчtxn3ЕФxids = {17,
2, 3 } , txn2ЕФxids = {17, 2}, txn1ЕФxids= {17, 1},
txn0ЕФxids = {17, 0}ЁЃ
гкЪЧЖдгкЪТЮёжаЕФУПвЛИіВйзї(xbegin/xcommit/enq_insert/xprepare)ЃЌЖМгавЛИіxidsРДБъЪЖетИіВйзїЫљдкЕФЪТЮёКХЁЃ
TokuDBжаЕФУПвЛЬѕЯћЯЂЃЈinsert/delete/updateЯћЯЂЃЉЖМЛсаЏДјетбљвЛИіxidsЪТЮёКХЁЃетИіxidsЪТЮёКХЃЌдкTokuDBЕФЪЕЯжжаАчбнетЗЧГЃживЊЕФНЧЩЋЃЌгыжЎЯрЙиЕФЙІФмвВЬиБ№ИДдгЁЃ
ЪТЮёЙмРэЦї
ЪТЮёЙмРэЦїгУРДЙмРэTokuDBДцДЂв§ЧцЫљгаЪТЮёМЏКЯЃЌ ЫќжївЊЮЌЛЄзХетМИИіаХЯЂЃК
ЛюдОЪТЮёСаБэЁЃЛюдОЪТЮёСаБэжЛЛсМЧТМrootЪТЮёЃЌвђЮЊИљОнrootЪТЮёЦфЪЕПЩвдевЕНећПУЪТЮёЪїЕФЫљгаchildЪТЮёЁЃ
етИіЪТЮёСаБэБЃДцетЕБЧАЪБМфЕувбОПЊЪМЃЌЕЋЪЧЩаЮДНсЪјЕФЫљгаrootЪТЮёЁЃ
ОЕЯёЖСЪТЮёСаБэЃЈsnapshot read transactionЃЉЁЃ
ЛюдОЪТЮёЕФв§гУСаБэ(referenced_xids)ЁЃетИіИХФюгаЕуВЛКУРэНтЃЌМйЩшвЛИіЛюдОЪТЮёПЊЪМ(xbegin)ЪБМфЕуЮЊbegin_id,
ЬсНЛ(xcommit)ЕФЪБМфЕуЮЊend_idЁЃФЧУДreferenced_xidsОЭЪЧЮЌЛЄ(begin_id,
end_id)етбљвЛИіЖўдЊзщЃЌетИіЖўдЊзщЕФгУДІОЭЪЧПЩвдевЕНвЛИіЪТЮёЕФећИіЩњУќжмЦкЕФЫљгаЛюдОЪТЮёЃЌгУДІжївЊЪЧгУРДзіКѓЮФЫЕЕНЕФfull
gcВйзїЁЃ
ЗжаЮЪїLeafEntry
ЩЯЮФЗжаЮЪїЕФЪїаЮНсЙЙжаЫЕЕНЃЌдкзіinsert/delete/updateетбљЕФВйзїЪБЃЌЛсАбДгrootЕНleafЕФЫљгаЯћЯЂЖМapplyЕНLeafNodeНкЕужаЁЃ
ЮЊСЫКѓУцЯъЯИУшЪіapplyЕФЙ§ГЬЃЌЯШНщЩмЯТLeafNodeЕФДцДЂНсЙЙЁЃ
leafNodeМђЕЅРДЫЕЃЌОЭЪЧгЩЖрИіleafEntryзщГЩЃЌУПИіleafEntryОЭЪЧвЛИі{k,
v1, v2, Ё }етбљЕФМќжЕЖдЃЌ Цфжаv1, v2 .. БэЪОвЛИіkeyЖдгІЕФжЕЕФЖрИіАцБОЁЃОпЬхЕНвЛИіkeyЖдгІЕУleafEntryЕФНсЙЙЯъЯИШчЯТЭМЫљЪОЁЃ
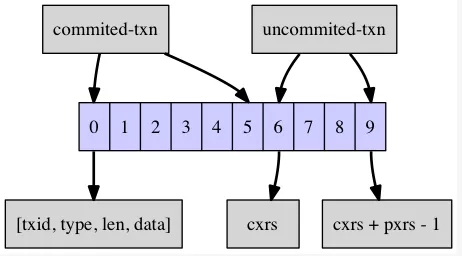
гЩЩЯЭМПДГіЃЌвЛИіleafEntryЦфЪЕОЭЪЧвЛИіеЛЃЌ етИіеЛЕзВП[0~5]етвЛЖЮБэЪОвбОЬсНЛ(commited
transaction)ЕФЪТЮёЕФValueжЕЁЃеЛЕФЖЅВП[6~9]етвЛЖЮБэЪОЕБЧАЩаЮДЬсНЛЕФЛюдОЪТЮё(uncommited
transaction)ЁЃ еЛжаДцЗХЕФЕЅИідЊЫиЮЊ(txid, type, len, data)етбљвЛИіЫФдЊзщЃЌБэУїСЫетИіЪТЮёЖдгІЕФvalueШЁжЕЁЃИќЭЈгУвЛЕуНВЃЌ[0,
cxrs-1]етвЛЖЮеЛБэЪОвбОЬсНЛЕФЪТЮёЃЌБОРДвбОЬсНЛЕФЪТЮёВЛгІДцдкгкеЛжаЃЌЕЋжЎЫљвдДцдкЃЌОЭЪЧвђЮЊгаЦфЫћЪТЮёЭЈЙ§snapshot
readЕФЗНЪНв§гУСЫетаЉЪТЮёЃЌвђДЫЃЌГ§ЗЧЫљгав§гУ[0, cxrs-1]етЖЮЪТЮёЕФЫљгаЪТЮёЖМЬсНЛЃЌЗёдђ[0,
cxrs-1]етЖЮеЛЕФЪТЮёОЭВЛЛсБЛЛиЪеЁЃ[cxrs, cxrs+pxrs-1]етвЛЖЮеЛБэЪОЕБЧАЛюдОЕФЩаЮДЬсНЛЕФЪТЮёСаБэЃЌЕБетВПЗжЪТЮёЬсНЛЪБЃЌcxrsЛсЭљКѓвЦЖЏЃЌзюжеЕНеЛЖЅЁЃ
MVCCЪЕЯж
1ЃЉаДШыВйзї
етРяЮвУЧШЯЮЊаДШыВйзїАќРЈШ§жжЃЌЗжБ№ЮЊinsert / delete / commit Ш§жжРраЭЁЃЖдгкinsertКЭdeleteетСНжжРраЭЕФаДШыВйзїЃЌжЛашвЊдкLeafEntryЕФеЛЖЅЗХжУвЛИідЊЫиМДПЩЁЃ
ШчЯТЭМЫљЪОЃК

ЖдгкcommitВйзїЃЌжЛашАбLeafEntryЕФеЛЖЅдЊЫиЗХЕНcxrsетИіжИеыДІЃЌШЛКѓЪеЫѕеЛЖЅжИеыМДПЩЁЃШчЯТЭМЫљЪОЃК

2ЃЉЖСШЁВйзї
ЖдЖСШЁВйзїЖјбдЃЌ Ъ§ОнПтвЛАужЇГжЖрИіИєРыМЖБ№ЁЃMySQLЕФInnoDBжЇГжRead UnCommitted(RU)ЁЂRead
REPEATABLE(RR)ЁЂRead Commited(RC)ЁЂSERIALIZABLE(S)ЁЃЦфжаRUДцдкдрЖСЕФЧщПі(дрЖСжИЖСШЁЕНЮДЬсНЛЕФЪТЮё)ЃЌ
RC/RR/RUДцдкЛУЖСЕФЧщПіЃЈЛУЖСвЛАужИвЛИіЪТЮёдкИќаТЪБПЩФмЛсИќаТЕНЦфЫћЪТЮёвбОЬсНЛЕФМЧТМЃЉЁЃ
TokuDBЭЌбљжЇГжЩЯЪі4жаИєРыМЖБ№ЃЌ дкдДТыЪЕЯжЪБ, ft-indexНЋЪТЮёЕФЖСШЁВйзїАДееЪТЮёИєРыМЖБ№ЗжГЩ3Рр:
TXN_SNAPSHOT_NONE : етРрВЛашвЊsnapshot readЃЌ SERIALIZABLEКЭRead
UncommitedСНИіИєРыМЖБ№ЪєгкетвЛРрЁЃ
TXN_SNAPSHOT_ROOT : Read REPEATABLEИєРыМЖБ№ЪєгкетРрЁЃдкетжжЦфЧщПіЯТЃЌ
ЫЕУїЪТЮёжЛашвЊЖСШЁЕНrootЪТЮёЖдгІЕФxidжЎЧАвбОЬсНЛЕФМЧТММДПЩЁЃ
TXN_SNAPSHOT_CHILD: READ COMMITTEDЪєгкетРрЁЃдкетжжЧщПіЯТЃЌЖљзгЪТЮёAашвЊИљОнздМКЪТЮёЕФxidРДевЕНsnapshotЖСЕФАцБОЃЌвђЮЊдкетИіЪТЮёAПЊЦєЪБЃЌПЩФмгаЦфЫћЪТЮёBзіСЫИќаТЃЌВЂЬсНЛЃЌФЧУДЪТЮёAБиаыЖСШЁBИќаТжЎКѓЕФНсЙћЁЃ
ЖрАцБОМЧТМЛиЪе
ЫцзХЪБМфЕФЭЦвЦЃЌдНРДдНЖрЕФРЯЪТЮёБЛЬсНЛЃЌаТЪТЮёПЊЪМжДааЁЃ дкЗжаЮЪїжаЕФLeafNodeжаcommitedЕФЪТЮёЪ§СПЛсдНРДдНЖрЃЌМйЩшВЛЯыЗНЩшЗЈАбетаЉЙ§ЦкЕФЪТЮёМЧТМЧхРэЕєЕФЛАЃЌЛсдьГЩBasementNodeНкЕуеМгУДѓСППеМфЃЌвВЛсдьГЩTokuDBЕФЪ§ОнЮФМўДцЗХДѓСПЮогУЕФЪ§ОнЁЃ
дкTokuDBжаЃЌ ЧхРэетаЉЙ§ЦкЪТЮёЕФВйзїГЦжЎЮЊРЌЛјЛиЪеЃЈGarbage CollectionЃЉЁЃ
ЦфЪЕInnoDBвВДцдкЙ§ЦкЪТЮёЛиЪеетУДвЛИіЙ§ГЬЃЌInnoDBЕФЭЌвЛИіKeyЕФЖрИіАцБОЕФValueДцЗХдкundo
log вГЩЯЃЌ ЕБЪТЮёЙ§ЦкЪБЃЌ КѓЬЈгавЛИіpurgeЯпГЬзЈУХРДИДдгЧхРэетаЉЙ§ЦкЕФЪТЮёЃЌДгЖјЬкГіundo
logвГИјКѓУцЕФЪТЮёЪЙгУЃЌ етбљПЩвдПижЦundo logЮоЯодіГЄЁЃ
TokuDBДцДЂв§ЧцжаУЛгаРрЫЦгкInnoDBЕФpurgeЯпГЬРДИКд№ЧхРэЙ§ЦкЪТЮёЃЌвђЮЊЙ§ЦкЪТЮёЕФЧхРэЖМЪЧдкжДааИќаТВйзїЪЧЫГБуGCЕФЁЃ
вВОЭЪЧдкInsert/Delete/UpdateетаЉВйзїжДааЪБЃЌЖМЛсХаЖЯвдЯТЕБЧАЕФLeafEntryЪЧЗёТњзуGCЕФЬѕМўЃЌ
ШєТњзуGCЬѕМўЪБЃЌОЭЩОГ§LeafEntryжаЙ§ЦкЕФЪТЮёЃЌ жиаТећРэLeafEntry ЕФФкДцПеМфЁЃАДееTokuDBдДТыЕФЪЕЯжЃЌGCЗжЮЊСНжжРраЭЃК
Simple GCЃКдкУПДЮapply ЯћЯЂЕНleafentry ЪБЃЌ ЖМЛсаЏДјвЛИіgc_infoЃЌ
етИіgc_info жаАќКЌСЫoldest_referenced_xidетИізжЖЮЁЃ ФЧУДsimple_gcЕФвтЫМЪЧЪВУДФиЃП
simple_gcОЭЪЧзівЛДЮМђЕЅЕФGCЃЌ жБНгАбcommitedЕФЪТЮёСаБэЧхРэЕєЃЈМЧзЁвЊЪЃЯТвЛИіcommitЪТЮёЕФМЧТМЃЌ
ЗёдђЯТДЮВщеветЬѕcommitedЕФМЧТМдѕУДевЕФЕНЃП ЃЉЁЃетОЭЪЧsimple_gcЃЌ МђЕЅБЉСІИпаЇЁЃ
Full GCЃКfull gcЕФДЅЗЂЬѕМўКЭgcСїГЬЖМБШНЯИДдгЃЌ ИљБОвтЭМЖМЪЧвЊЧхРэЕєЙ§ЦкЕФвбОЬсНЛЕФЪТЮёЁЃетРяВЛдйеЙПЊЁЃ
змНс
БОЮФДѓжТНщЩмСЫTokuDBЪТЮёЕФИєРыадЪЕЯждРэЃЌ АќРЈTokuDBЕФЪТЮёБэЪОЁЂЗжаЮЪїЕФLeafEntryЕФНсЙЙЁЂMVCCЕФЪЕЯжСїГЬЁЂЖрАцБОМЧТМЛиЪеЗНЪНетаЉЗНУцЕФФкШнЁЃ
TokuDBжЎЫљгаУЛгаundo logЃЌОЭЪЧвђЮЊЗжаЮЪїжаЕФИќаТЯћЯЂБОЩэОЭМЧТМСЫЪТЮёЕФМЧТМАцБОЁЃСэЭтЃЌ
TokuDBЕФЙ§ЦкЪТЮёЛиЪевВВЛашвЊЯёInnoDBФЧбљзЈУХПЊЦєвЛИіКѓЬЈЯпГЬвьВНЛиЪеЃЌЖјЪЧВХгУдкИќаТВйзїжДааЕФЙ§ГЬжаЗжЬЏЛиЪеЁЃзмжЎЃЌгЩгкTokuDBЛљгкЗжаЮЪїжЎЩЯЪЕЯжЪТЮёЃЌвђЖјИїЗНУцЕФЫМТЗЖМгаДѓЕФВювьЃЌетвВЪЧTokuDBЭХЖгЕФДДаТАЩЁЃ
| 







