| Īŗľ≠Õ∆ľŲ: |
őń’¬ ◊Ō»∂‘‘∆ żĺ›Ņ‚łŇ Ų°Ę‘∆ żĺ›Ņ‚≤ķ∆∑°Ę‘∆ żĺ›Ņ‚ŌĶÕ≥ľ‹ĻĻ°ĘAmazon
AWS£®Amazon Web Services£©ļÕ‘∆ żĺ›Ņ‚°ĘőĘ»Ū‘∆ żĺ›Ņ‚SQL
AzureĶ»ŌŗĻōńŕ»›°£
Īĺőńņī◊‘≤©ŅÕ‘į£¨”…ĽūŃķĻŻ»ŪľĢAnnaĪŗľ≠°ĘÕ∆ľŲ°£
|
|
‘∆ żĺ›Ņ‚łŇ Ų
‘∆ľ∆ň„ «‘∆ żĺ›Ņ‚–ň∆ūĶńĽýī°£ļ
‘∆ľ∆ň„ĶńłŇńÓ£ļÕ®Ļż’ŻļŌ°ĘĻ‹ņŪ°ĘĶųŇš∑÷≤ľ‘ŕÕݬÁłųī¶Ķńľ∆ň„◊ ‘ī£¨Õ®ĻżĽ•Ń™ÕÝ“‘Õ≥“ĽĹÁ√ś£¨Õ¨ ĪŌÚīůŃŅĶń”√ĽßŐŠĻ©∑ĢőŮ°£
‘∆ľ∆ň„ŐōĶ„£ļįī–Ť∑ĢőŮ£¨ňś Ī∑ĢőŮ£¨Õ®”√–Õ£¨łŖŅ…ŅŅ–‘£¨ľę∆šŃģľŘ£¨≥¨īůĻśń££¨–ťń‚ĽĮ£¨łŖņ©’Ļ–‘°£
‘∆ żĺ›Ņ‚ĶńłŇńÓ£ļ
‘∆ żĺ›Ņ‚ «≤Ņ ūļÕ–ťń‚ĽĮ‘ŕ‘∆ľ∆ň„Ľ∑ĺ≥÷–Ķń żĺ›Ņ‚°£‘∆ żĺ›Ņ‚ «‘ŕ‘∆ľ∆ň„ĶńīůĪ≥ĺįŌ¬∑Ę’Ļ∆ūņīĶń“Ľ÷÷–¬–ňĶńĻ≤ŌŪĽýī°ľ‹ĻĻĶń∑Ĺ∑®£¨ňŁľęīůĶō‘Ų«ŅŃň żĺ›Ņ‚ĶńīśīĘń‹Ń¶£¨ŌŻ≥żŃň»ň‘Ī°Ę”≤ľĢ°Ę»ŪľĢĶń÷ōłīŇš÷√£¨»√»Ū°Ę”≤ľĢ…żľ∂ĪšĶ√łŁľ”»›“◊°£‘∆ żĺ›Ņ‚ĺŖ”–łŖŅ…ņ©’Ļ–‘°ĘłŖŅ…”√–‘°Ę≤…”√∂ŗ◊‚–ő ĹļÕ÷ß≥÷◊ ‘ī”––ß∑÷∑ĘĶ»ŐōĶ„°£
‘∆ żĺ›Ņ‚ĶńŐō–‘£ļ
‘∆ żĺ›Ņ‚ĺŖ”–“‘Ō¬Őō–‘£ļ
∂ĮŐ¨Ņ…ņ©’Ļ
łŖŅ…”√–‘
ĹŌĶÕĶń Ļ”√īķľŘ
“◊”√–‘
łŖ–‘ń‹
√‚ő¨Ľ§
į≤»ę
Õľ£ļŐŕ—∂‘∆ żĺ›Ņ‚ļÕ◊‘Ĺ® żĺ›Ņ‚ĶńĪ»ĹŌ
‘∆ żĺ›Ņ‚ «łŲ–‘ĽĮ żĺ›Ņ‚īśīĘ–Ť«ůĶńņŪŌŽ—°‘Ů£ļ
∆ů“Ķņŗ–Õ≤ĽÕ¨£¨∂‘”ŕīśīĘĶń–Ť«ů“≤«ß≤ÓÕÚĪū£¨∂Ý‘∆ żĺ›Ņ‚Ņ…“‘ļ‹ļ√Ķō¬ķ◊„≤ĽÕ¨∆ů“ĶĶńłŲ–‘ĽĮīśīĘ–Ť«ů£ļ
◊Ō»£¨‘∆ żĺ›Ņ‚Ņ…“‘¬ķ◊„īů∆ů“ĶĶńļ£ŃŅ żĺ›īśīĘ–Ť«ů°£
∆šīő£¨‘∆ żĺ›Ņ‚Ņ…“‘¬ķ◊„÷––°∆ů“ĶĶńĶÕ≥…Īĺ żĺ›īśīĘ–Ť«ů°£
ŃŪÕ‚£¨‘∆ żĺ›Ņ‚Ņ…“‘¬ķ◊„∆ů“Ķ∂ĮŐ¨ĪšĽĮĶń żĺ›īśīĘ–Ť«ů°£
ĶĹĶ◊—°‘Ů◊‘Ĺ® żĺ›Ņ‚ĽĻ «—°‘Ů‘∆ żĺ›Ņ‚£¨»°ĺŲ”ŕ∆ů“Ķ◊‘…ŪĶńĺŖŐŚ–Ť«ů
∂‘”ŕ“Ľ–©īů–Õ∆ů“Ķ£¨ńŅ«įÕ®≥£≤…”√◊‘Ĺ® żĺ›Ņ‚
∂‘”ŕ“Ľ–©≤∆Ѷ”–ŌřĶń÷––°∆ů“Ķ∂Ý—‘£¨IT‘§ň„Ī»ĹŌ”–Ōř£¨‘∆ żĺ›Ņ‚’‚÷÷«į∆ŕŃ„Õ∂»Ž°Ęļů∆ŕ√‚ő¨Ľ§Ķń żĺ›Ņ‚∑ĢőŮ£¨Ņ…“‘ļ‹ļ√¬ķ◊„ňŁ√«Ķń–Ť«ů°£
‘∆ żĺ›Ņ‚”Ž∆šňŻ żĺ›Ņ‚ĶńĻōŌĶ£ļ
ī” żĺ›ń£–ÕĶńĹ«∂»ņīňĶ£¨‘∆ żĺ›Ņ‚≤Ę∑«“Ľ÷÷»ę–¬Ķń żĺ›Ņ‚ľľ ű£¨∂Ý÷Ľ «“‘∑ĢőŮĶń∑Ĺ ĹŐŠĻ© żĺ›Ņ‚Ļ¶ń‹°£
‘∆ żĺ›Ņ‚≤Ę√Ľ”–◊® Ű”ŕ◊‘ľļĶń żĺ›ń£–Õ£¨‘∆ żĺ›Ņ‚ňý≤…”√Ķń żĺ›ń£–ÕŅ…“‘ «ĻōŌĶ żĺ›Ņ‚ňý Ļ”√ĶńĻōŌĶń£–Õ£®őĘ»ŪĶńSQL
Azure‘∆ żĺ›Ņ‚°ĘįĘņÔ‘∆RDS∂ľ≤…”√ŃňĻōŌĶń£–Õ£©£¨“≤Ņ…“‘ «NoSQL żĺ›Ņ‚ňý Ļ”√Ķń∑«ĻōŌĶń£–Õ£®Amazon
Dynamo‘∆ żĺ›Ņ‚≤…”√Ķń «°įľŁ/÷Ķ°ĪīśīĘ£©°£
Õ¨“ĽłŲĻęňĺ“≤Ņ…ń‹ŐŠĻ©≤…”√≤ĽÕ¨ żĺ›ń£–ÕĶń∂ŗ÷÷‘∆ żĺ›Ņ‚∑ĢőŮ°£
–Ū∂ŗĻęňĺ‘ŕŅ™∑Ę‘∆ żĺ›Ņ‚ Ī£¨ļů∂ň żĺ›Ņ‚∂ľ «÷ĪĹ” Ļ”√Ō÷”–Ķńłų÷÷ĻōŌĶ żĺ›Ņ‚ĽÚNoSQL żĺ›Ņ‚≤ķ∆∑°£
‘∆ żĺ›Ņ‚≤ķ∆∑
‘∆ żĺ›Ņ‚≥ß…ŐĶńłŇ Ų£ļ
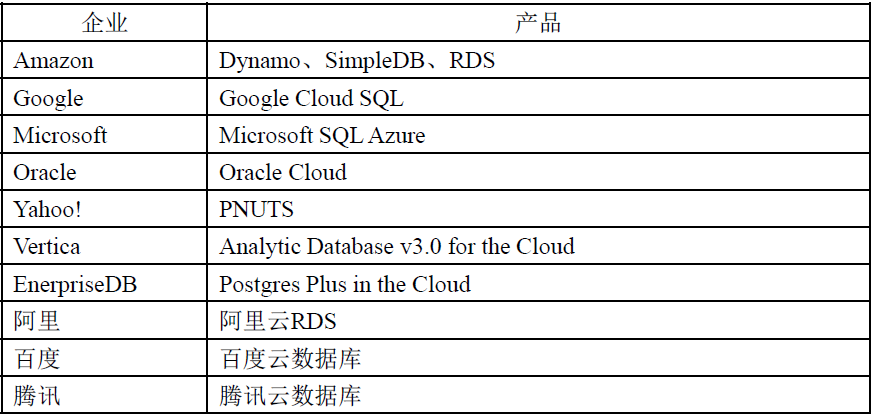
Õľ£ļ‘∆ żĺ›Ņ‚≤ķ∆∑
AmazonĶń‘∆ żĺ›Ņ‚≤ķ∆∑£ļ
Amazon «‘∆ żĺ›Ņ‚ –≥°ĶńŌ»––’Ŗ°£Amazon≥żŃňŐŠĻ©÷Ý√ŻĶńS3īśīĘ∑ĢőŮļÕEC2ľ∆ň„∑ĢőŮ“‘Õ‚£¨ĽĻŐŠĻ©Ľý”ŕ‘∆Ķń żĺ›Ņ‚∑ĢőŮ£ļ
Amazon RDS£ļ‘∆÷–ĶńĻōŌĶ żĺ›Ņ‚
Amazon SimpleDB£ļ‘∆÷–ĶńľŁ÷Ķ żĺ›Ņ‚
Amazon DynamoDB£ļ‘∆÷–ĶńNoSQL żĺ›Ņ‚
Amazon Redshift£ļ‘∆÷–Ķń żĺ›≤÷Ņ‚
Amazon ElastiCache£ļ‘∆÷–Ķń∑÷≤ľ ĹńŕīśĽļīś
GoogleĶń‘∆ żĺ›Ņ‚≤ķ∆∑£ļ
Google Cloud SQL «Ļ»łŤĻęňĺÕ∆≥ŲĶńĽý”ŕMySQLĶń‘∆ żĺ›Ņ‚°£
Ļ”√Cloud SQL£¨ňý”–Ķń ¬őŮ∂ľ‘ŕ‘∆÷–£¨≤Ę”…Ļ»łŤĻ‹ņŪ£¨”√Ľß≤Ľ–Ť“™Ňš÷√ĽÚ’ŖŇŇ≤ťīŪőů°£
Ļ»łŤĽĻŐŠĻ©Ķľ»ŽĽÚĶľ≥Ų∑ĢőŮ£¨∑ĹĪ„”√ĽßĹę żĺ›Ņ‚īÝĹÝĽÚīÝ≥Ų‘∆°£
Ļ»łŤ Ļ”√”√Ľß∑«≥£ žŌ§ĶńMySQL£¨īÝ”–JDBC÷ß≥÷£® ”√”ŕĽý”ŕJavaĶńApp Engine”¶”√£©ļÕDB-API÷ß≥÷£® ”√”ŕĽý”ŕPythonĶńApp
Engine”¶”√£©ĶńīęÕ≥MySQL żĺ›Ņ‚Ľ∑ĺ≥£¨“Úīň£¨∂ŗ ż”¶”√≥Ő–Ú≤Ľ–ŤĻż∂ŗĶų ‘ľīŅ…‘ň––£¨ żĺ›łŮ Ĺ∂‘”ŕīů∂ŗ żŅ™∑Ę’ŖļÕĻ‹ņŪ‘ĪņīňĶ“≤ «∑«≥£ žŌ§Ķń°£
Google Cloud SQLĽĻ”–“ĽłŲļ√ī¶ĺÕ «”ŽGoogle App EngineľĮ≥…°£
MicrosoftĶń‘∆ żĺ›Ņ‚≤ķ∆∑£ļ
SQL AzureĺŖ”–“‘Ō¬Őō–‘£ļ
Ű”ŕĻōŌĶ–Õ żĺ›Ņ‚£ļ÷ß≥÷ Ļ”√TSQL£®Transact Structured Query Language£©ņīĻ‹ņŪ°ĘīīĹ®ļÕ≤Ŕ◊ų‘∆ żĺ›Ņ‚°£
÷ß≥÷īśīĘĻż≥Ő£ļňŁĶń żĺ›ņŗ–Õ°ĘīśīĘĻż≥ŐļÕīęÕ≥ĶńSQL ServerĺŖ”–ļ‹īůĶńŌŗň∆–‘£¨“Úīň£¨”¶”√Ņ…“‘‘ŕĪĺĶōĹÝ––Ņ™∑Ę£¨»Ľļů≤Ņ ūĶĹ‘∆∆ĹŐ®…Ō°£
÷ß≥÷īůŃŅ żĺ›ņŗ–Õ£ļįŁļ¨Ńňľłļűňý”–Ķš–ÕĶńSQL Server 2008Ķń żĺ›ņŗ–Õ°£
÷ß≥÷‘∆÷–Ķń ¬őŮ£ļ÷ß≥÷ĺ÷≤Ņ ¬őŮ£¨Ķę «≤Ľ÷ß≥÷∑÷≤ľ Ĺ ¬őŮ°£
‘∆ żĺ›Ņ‚ŌĶÕ≥ľ‹ĻĻ
UMPŌĶÕ≥łŇ Ų£ļ
UMP£®Unified MySQL Platform£©ŌĶÕ≥ «ĶÕ≥…ĪĺļÕłŖ–‘ń‹ĶńMySQL‘∆ żĺ›Ņ‚∑Ĺįł°£◊‹ĶńņīňĶ£¨UMPŌĶÕ≥ľ‹ĻĻ…Ťľ∆◊Ů—≠Ńň“‘Ō¬‘≠‘Ú£ļ
Ī£≥÷Ķ•“ĽĶńŌĶÕ≥∂‘Õ‚»ŽŅŕ£¨≤Ę«“ő™ŌĶÕ≥ńŕ≤Ņő¨Ľ§Ķ•“ĽĶń◊ ‘ī≥ō°£
ŌŻ≥żĶ•Ķ„Ļ ’Ō£¨Ī£÷§∑ĢőŮĶńłŖŅ…”√–‘°£
Ī£÷§ŌĶÕ≥ĺŖ”–Ńľļ√ĶńŅ……žňű£¨ń‹ĻĽ∂ĮŐ¨Ķō‘Ųľ”°Ę…ĺľűľ∆ň„”ŽīśīĘĹŕĶ„°£
Ī£÷§∑÷ŇšłÝ”√ĽßĶń◊ ‘ī“≤ «ĶĮ–‘Ņ……žňűĶń£¨◊ ‘ī÷ģľšŌŗĽ•łŰņŽ£¨»∑Ī£”¶”√ļÕ żĺ›į≤»ę°£
UMPŌĶÕ≥ľ‹ĻĻ£ļ
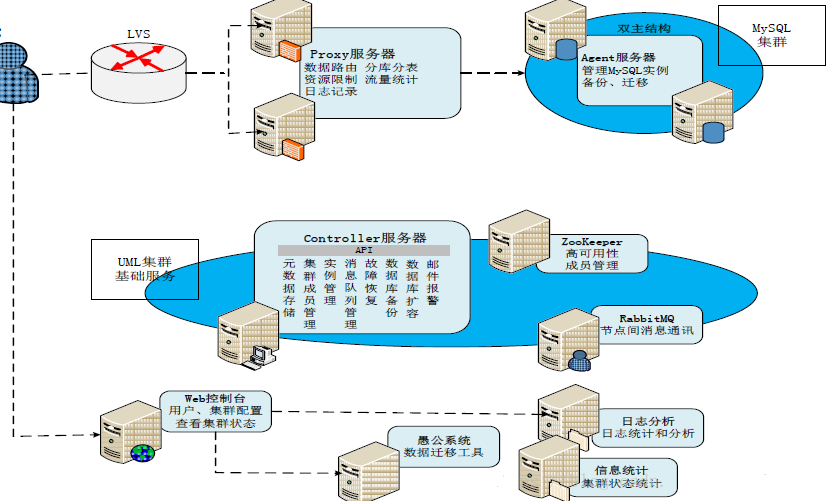
Õľ£ļUMPŌĶÕ≥ľ‹ĻĻ
UMPŌĶÕ≥÷–ĶńĹ«…ęįŁņ®£ļ
(1)Controller∑ĢőŮ∆ų
Controller∑ĢőŮ∆ųŌÚUMPľĮ»ļŐŠĻ©łų÷÷Ļ‹ņŪ∑ĢőŮ£¨ ĶŌ÷ľĮ»ļ≥…‘ĪĻ‹ņŪ°Ę‘™ żĺ›īśīĘ°ĘMySQL ĶņżĻ‹ņŪ°ĘĻ ’ŌĽ÷łī°ĘĪł∑›°Ę«®“∆°Ęņ©»›Ķ»Ļ¶ń‹.
Controller∑ĢőŮ∆ų…Ō‘ň––Ńň“Ľ◊ťMnesia∑÷≤ľ Ĺ żĺ›Ņ‚∑ĢőŮ£¨∆š÷–īśīĘŃňłų÷÷ŌĶÕ≥‘™ żĺ›£¨÷ų“™įŁņ®ľĮ»ļ≥…‘Ī°Ę”√ĽßĶńŇš÷√ļÕ◊īŐ¨–ŇŌĘ£¨“‘ľį”√Ľß√ŻĶĹļů∂ňMySQL ĶņżĶō÷∑Ķń”≥…šĻōŌĶ£®ĽÚ≥∆ő™°į¬∑”…ĪŪ°Ī£©Ķ»°£
ĶĪ∆šňŁ∑ĢőŮ∆ų◊ťľĢ–Ť“™ĽŮ»°”√Ľß żĺ› Ī£¨Ņ…“‘ŌÚController∑ĢőŮ∆ų∑ĘňÕ«Ž«ůĽŮ»° żĺ›°£
ő™ŃňĪ‹√‚Ķ•Ķ„Ļ ’Ō£¨Ī£÷§ŌĶÕ≥ĶńłŖŅ…”√–‘£¨UMPŌĶÕ≥÷–≤Ņ ūŃň∂ŗŐ®Controller∑ĢőŮ∆ų£¨»Ľļů£¨”…ZookeeperĶń∑÷≤ľ ĹňÝĻ¶ń‹ņīįÔ÷ķ—°≥Ų“ĽłŲ°į◊‹Ļ‹°Ī£¨łļ‘ūłų÷÷ŌĶÕ≥»őőŮĶńĶų∂»ļÕľŗŅō°£
(2)Proxy∑ĢőŮ∆ų
? Proxy∑ĢőŮ∆ųŌÚ”√ĽßŐŠĻ©∑√ő MySQL żĺ›Ņ‚Ķń∑ĢőŮ£¨ňŁÕÍ»ę ĶŌ÷ŃňMySQL–≠“ť£¨”√ĽßŅ…“‘ Ļ”√“—”–ĶńMySQLŅÕĽß∂ňѨŔĶĹProxy∑ĢőŮ∆ų£¨Proxy∑ĢőŮ∆ųÕ®Ļż”√Ľß√ŻĽŮ»°ĶĹ”√ĽßĶń»Ō÷§–ŇŌĘ°Ę◊ ‘īŇš∂ÓĶńŌř÷∆(ņż»ÁQPS°ĘIOPS£®I/O
Per Second£©°Ę◊ÓīůѨŔ żĶ»)£¨“‘ľįļůŐ®MySQL ĶņżĶńĶō÷∑£¨»Ľļů£¨”√ĽßĶńSQL≤ť—Į«Ž«ůĽŠĪĽ◊™∑ĘĶĹŌŗ”¶ĶńMySQL Ķņż…Ō°£≥żŃň żĺ›¬∑”…ĶńĽýĪĺĻ¶ń‹Õ‚£¨Proxy∑ĢőŮ∆ų÷–ĽĻ ĶŌ÷Ńňļ‹∂ŗ÷ō“™ĶńĻ¶ń‹£¨÷ų“™įŁņ®∆ŃĪőMySQL ĶņżĻ ’Ō°Ę∂Ń–ī∑÷ņŽ°Ę∑÷Ņ‚∑÷ĪŪ°Ę◊ ‘īłŰņŽ°Ęľ«¬ľ”√Ľß∑√ő »’÷ĺĶ»°£
(3)Agent∑ĢőŮ∆ų
? Agent∑ĢőŮ∆ų≤Ņ ū‘ŕ‘ň––MySQLĹÝ≥ŐĶńĽķ∆ų…Ō£¨”√ņīĻ‹ņŪ√ŅŐ®őÔņŪĽķ…ŌĶńMySQL Ķņż£¨÷ī––÷ųī”«–ĽĽ°ĘīīĹ®°Ę…ĺ≥ż°ĘĪł∑›°Ę«®“∆Ķ»≤Ŕ◊ų£¨Õ¨ Ī£¨ĽĻłļ‘ū ’ľĮļÕ∑÷őŲMySQLĹÝ≥ŐĶńÕ≥ľ∆–ŇŌʰʬż≤ť—Į»’÷ĺ£®Slow
Query Log£©ļÕbin-log°£
(4)WebŅō÷∆Ő®
? WebŅō÷∆Ő®ŌÚ”√ĽßŐŠĻ©ŌĶÕ≥Ļ‹ņŪĹÁ√ś°£
(5)»’÷ĺ∑÷őŲ∑ĢőŮ∆ų
? »’÷ĺ∑÷őŲ∑ĢőŮ∆ųīśīĘļÕ∑÷őŲProxy∑ĢőŮ∆ųī껎Ķń”√Ľß∑√ő »’÷ĺ£¨≤Ę÷ß≥÷ Ķ Ī≤ť—Į“Ľ∂ő ĪľšńŕĶń¬ż»’÷ĺļÕÕ≥ľ∆Ī®ĪŪ°£
(6)–ŇŌĘÕ≥ľ∆∑ĢőŮ∆ų
? –ŇŌĘÕ≥ľ∆∑ĢőŮ∆ų∂®∆ŕĹę≤…ľĮĶĹĶń”√ĽßĶńѨŔ ż°ĘQPS ż÷Ķ“‘ľįMySQL ĶņżĶńĹÝ≥Ő◊īŐ¨”√RRDtoolĹÝ––Õ≥ľ∆£¨Ņ…“‘‘ŕ
WebĹÁ√ś…ŌŅ… ”ĽĮ’Ļ ĺÕ≥ľ∆ĹŠĻŻ£¨“≤Ņ…“‘į—Õ≥ľ∆ĹŠĻŻ◊ųő™ĹŮļů ĶŌ÷ĶĮ–‘Ķń◊ ‘ī∑÷ŇšļÕ◊‘∂ĮĽĮĶńMySQL Ķņż«®“∆Ķń“ņĺ›°£
(7)”řĻęŌĶÕ≥
? ”řĻęŌĶÕ≥ «“ĽłŲ»ęŃŅłī÷∆ĹŠļŌbin-log∑÷őŲĹÝ––‘ŲŃŅłī÷∆ĶńĻ§ĺŖ£¨Ņ…“‘ ĶŌ÷‘ŕ≤ĽÕ£ĽķĶń«ťŅŲŌ¬∂ĮŐ¨ņ©»›°Ęňű»›ļÕ«®“∆°£
“ņņĶĶńŅ™‘ī◊ťľĢįŁņ®£ļ
(1)Mnesia
Mnesia «“ĽłŲ∑÷≤ľ Ĺ żĺ›Ņ‚Ļ‹ņŪŌĶÕ≥.
Mnesia÷ß≥÷ ¬őŮ£¨÷ß≥÷Õł√ųĶń żĺ›∑÷∆¨£¨ņŻ”√ŃĹĹ◊∂őňÝ ĶŌ÷∑÷≤ľ Ĺ ¬őŮ£¨Ņ…“‘ŌŖ–‘ņ©’ĻĶĹ÷Ń…Ŕ50łŲĹŕĶ„°£
MnesiaĶń żĺ›Ņ‚ń£ Ĺ(schema)Ņ…‘ŕ‘ň–– Ī∂ĮŐ¨÷ōŇš÷√£¨ĪŪń‹ĪĽ«®“∆ĽÚłī÷∆ĶĹ∂ŗłŲĹŕĶ„ņīłńĹÝ»›īŪ–‘°£
MnesiaĶń’‚–©Őō–‘£¨ Ļ∆š‘ŕŅ™∑Ę‘∆ żĺ›Ņ‚ ĪĪĽ”√ņīŐŠĻ©∑÷≤ľ Ĺ żĺ›Ņ‚∑ĢőŮ°£
£®2£©LVS
LVS(Linux Virtual Server)ľīLinux–ťń‚∑ĢőŮ∆ų£¨ «“ĽłŲ–ťń‚Ķń∑ĢőŮ∆ųľĮ»ļŌĶÕ≥°£
UMPŌĶÕ≥ĹŤ÷ķ”ŕLVSņī ĶŌ÷ľĮ»ļńŕ≤ŅĶńłļ‘ōĺýļ‚°£
LVSľĮ»ļ≤…”√IPłļ‘ōĺýļ‚ľľ űļÕĽý”ŕńŕ»›«Ž«ů∑÷∑Ęľľ ű°£
Ķų∂»∆ų «LVSľĮ»ļŌĶÕ≥Ķńő®“Ľ»ŽŅŕĶ„£¨Ķų∂»∆ųĺŖ”–ļ‹ļ√ĶńÕŐÕ¬¬ £¨Ĺę«Ž«ůĺýļ‚Ķō◊™“∆ĶĹ≤ĽÕ¨Ķń∑ĢőŮ∆ų…Ō÷ī––£¨«“Ķų∂»∆ų◊‘∂Į∆ŃĪőĶŰ∑ĢőŮ∆ųĶńĻ ’Ō£¨ī”∂ÝĹę“Ľ◊ť∑ĢőŮ∆ųĻĻ≥…“ĽłŲłŖ–‘ń‹Ķń°ĘłŖŅ…”√Ķń–ťń‚∑ĢőŮ∆ų°£
’ŻłŲ∑ĢőŮ∆ųľĮ»ļĶńĹŠĻĻ∂‘ŅÕĽß «Õł√ųĶń£¨∂Ý«“őř–Ť–řłńŅÕĽß∂ňļÕ∑ĢőŮ∆ų∂ňĶń≥Ő–Ú°£
£®3£©RabbitMQ
RabbitMQ «“ĽłŲĻ§“Ķľ∂ĶńŌŻŌĘ∂”Ń–≤ķ∆∑£®Ļ¶ń‹ņŗň∆”ŕIBMĻęňĺĶńŌŻŌĘ∂”Ń–≤ķ∆∑IBM Websphere
MQ£©£¨◊ųő™ŌŻŌĘīę š÷–ľšľĢņī Ļ”√£¨Ņ…“‘ ĶŌ÷Ņ…ŅŅĶńŌŻŌĘīęňÕ°£
UMPľĮ»ļ÷–łųłŲĹŕĶ„÷ģľšĶńÕ®–Ň£¨≤Ľ–Ť“™Ĺ®ŃĘ◊®√ŇĶńѨŔ£¨∂ľ «Õ®Ļż∂Ń–ī∂”Ń–ŌŻŌĘņī ĶŌ÷Ķń°£
£®4£©ZooKeeper
Zookeeper «łŖ–ßļÕŅ…ŅŅĶń–≠Õ¨Ļ§◊ųŌĶÕ≥£¨ŐŠĻ©∑÷≤ľ ĹňÝ÷ģņŗĶńĽýĪĺ∑ĢőŮ£®Ī»»ÁÕ≥“Ľ√Ł√Ż∑ĢőŮ°Ę◊īŐ¨Õ¨≤Ĺ∑ĢőŮ°ĘľĮ»ļĻ‹ņŪ°Ę∑÷≤ľ Ĺ”¶”√Ňš÷√ŌÓĶńĻ‹ņŪĶ»£©£¨”√”ŕĻĻĹ®∑÷≤ľ Ĺ”¶”√£¨ľű«Š∑÷≤ľ Ĺ”¶”√≥Ő–Úňý≥–Ķ£Ķń–≠Ķų»őőŮ.
‘ŕUMPŌĶÕ≥÷–£¨Zookeeper÷ų“™∑ĘĽ”»żłŲ◊ų”√£ļ
◊ųő™»ęĺ÷ĶńŇš÷√∑ĢőŮ∆ų
ŐŠĻ©∑÷≤ľ ĹňÝ£®—°≥Ų“ĽłŲľĮ»ļĶń°į◊‹Ļ‹°Ī£©
ľŗŅōňý”–MySQL Ķņż
UMPŌĶÕ≥Ļ¶ń‹£ļ
UMPŌĶÕ≥ «ĻĻĹ®‘ŕ“ĽłŲīůĶńľĮ»ļ÷ģ…ŌĶń£¨Õ®Ļż∂ŗłŲ◊ťľĢĶń–≠Õ¨◊ų“Ķ£¨’ŻłŲŌĶÕ≥ ĶŌ÷Ńň∂‘”√ĽßÕł√ųĶńłų÷÷Ļ¶ń‹£ļ
»›‘÷°Ę∂Ń–ī∑÷ņŽ°Ę∑÷Ņ‚∑÷ĪŪ°Ę◊ ‘īĻ‹ņŪ°Ę◊ ‘īĶų∂»°Ę◊ ‘īłŰņŽ°Ę żĺ›į≤»ę°£
»›‘÷£ļ
ő™Ńň ĶŌ÷»›‘÷£¨UMPŌĶÕ≥ĽŠő™√ŅłŲ”√ĽßīīĹ®ŃĹłŲMySQL Ķņż£¨“ĽłŲ «÷ųŅ‚£¨“ĽłŲ «ī”Ņ‚÷ųŅ‚ļÕī”Ņ‚Ķń◊īŐ¨ «”…Zookeeperłļ‘ūő¨Ľ§Ķń°£
÷ųī”«–ĽĽĻż≥Ő»ÁŌ¬£ļ
ZookeeperŐĹ≤‚ĶĹ÷ųŅ‚Ļ ’Ō£¨Õ®÷™Controller∑ĢőŮ∆ų°£
Controller∑ĢőŮ∆ų∆Ű∂Į÷ųī”«–ĽĽ Ī£¨ĽŠ–řłń°į¬∑”…ĪŪ°Ī£¨ľī”√Ľß√ŻĶĹļů∂ňMySQL ĶņżĶō÷∑Ķń”≥…šĻōŌĶ°£
į—÷ųŅ‚ĪÍľ«ő™≤ĽŅ…”√°£
ĹŤ÷ķ”ŕŌŻŌĘ÷–ľšľĢRabbitMQÕ®÷™ňý”–Proxy∑ĢőŮ∆ų–řłń”√Ľß√ŻĶĹļů∂ňMySQL ĶņżĶō÷∑Ķń”≥…šĻōŌĶ°£
»ę≤ŅĻż≥Ő∂‘”√ĽßÕł√ų°£
ŚīĽķļůĶń÷ųŅ‚‘ŕĹÝ––Ľ÷łīī¶ņŪļů–Ť“™‘Ŕīő…ŌŌŖ£¨Ļż≥Ő»ÁŌ¬£ļ
‘ŕ÷ųŅ‚Ľ÷łī Ī£¨ĽŠį—ī”Ņ‚ĶńłŁ–¬łī÷∆łÝ◊‘ľļ°£
ĶĪ÷ųŅ‚Ķń żĺ›Ņ‚◊īŐ¨Ņž“™īÔĶĹļÕī”Ņ‚“Ľ÷¬Ķń◊īŐ¨ Ī£¨Controller∑ĢőŮ∆ųĺÕĽŠ√ŁŃÓī”Ņ‚Õ£÷ĻłŁ–¬£¨ĹÝ»Ž≤ĽŅ…–ī◊īŐ¨£¨ĹŻ÷Ļ”√Ľß–ī»Ž żĺ›°£
Ķ»ĶĹ÷ųŅ‚łŁ–¬ĶĹļÕī”Ņ‚Õͻꓼ÷¬Ķń◊īŐ¨ Ī£¨Controller∑ĢőŮ∆ųĺÕĽŠ∑Ę∆ū÷ųī”«–ĽĽ≤Ŕ◊ų£¨≤Ę‘ŕ¬∑”…ĪŪ÷–į—÷ųŅ‚ĪÍľ«ő™Ņ…”√◊īŐ¨°£
Õ®÷™Proxy∑ĢőŮ∆ųį—–ī≤Ŕ◊ų«–Ľō÷ųŅ‚…Ō£¨”√Ľß–ī≤Ŕ◊ųŅ…“‘ľŐ–Ý÷ī––£¨÷ģļů‘Ŕį—ī”Ņ‚–řłńő™Ņ…–ī◊īŐ¨°£
∂Ń–ī∑÷ņŽ£ļ
≥š∑÷ņŻ”√÷ųī”Ņ‚ ĶŌ÷”√Ľß∂Ń–ī≤Ŕ◊ųĶń∑÷ņŽ£¨ ĶŌ÷łļ‘ōĺýļ‚°£
UMPŌĶÕ≥ ĶŌ÷Ńň∂‘”ŕ”√ĽßÕł√ųĶń∂Ń–ī∑÷ņŽĻ¶ń‹£¨ĶĪ’ŻłŲĻ¶ń‹ĪĽŅ™∆Ű Ī£¨łļ‘ūŌÚ”√ĽßŐŠĻ©∑√ő MySQL żĺ›Ņ‚∑ĢőŮĶńProxy∑ĢőŮ∆ų£¨ĺÕĽŠ∂‘”√Ľß∑Ę∆ūĶńSQL”ÔĺšĹÝ––Ĺ‚őŲ£¨»ÁĻŻ Ű”ŕ–ī≤Ŕ◊ų£¨ĺÕ÷ĪĹ”∑ĘňÕĶĹ÷ųŅ‚£¨»ÁĻŻ «∂Ń≤Ŕ◊ų£¨ĺÕĽŠĪĽĺýļ‚Ķō∑ĘňÕĶĹ÷ųŅ‚ļÕī”Ņ‚…Ō÷ī––°£
∑÷Ņ‚∑÷ĪŪ£ļ
UMP÷ß≥÷∂‘”√ĽßÕł√ųĶń∑÷Ņ‚∑÷ĪŪ£®shard / horizontal partition£© ĶĪ≤…”√∑÷Ņ‚∑÷ĪŪ Ī£¨ŌĶÕ≥ī¶ņŪ”√Ľß≤ť—ĮĶńĻż≥Ő»ÁŌ¬£ļ
◊Ō»£¨Proxy∑ĢőŮ∆ųĹ‚őŲ”√ĽßSQL”Ôĺš£¨ŐŠ»°≥Ų÷ō–īļÕ∑÷∑ĘSQL”Ôĺšňý–Ť“™Ķń–ŇŌĘ°£
∆šīő£¨∂‘SQL”ÔĺšĹÝ––÷ō–ī£¨Ķ√ĶĹ∂ŗłŲ’Ž∂‘Ōŗ”¶MySQL ĶņżĶń◊””Ôĺš£¨»Ľļůį—◊””Ôĺš∑÷∑ĘĶĹ∂‘”¶ĶńMySQL Ķņż…Ō÷ī––°£
◊Óļů£¨Ĺ” ’ņī◊‘łųłŲMySQL ĶņżĶńSQL”Ôĺš÷ī––ĹŠĻŻ£¨ļŌ≤ĘĶ√ĶĹ◊Ó÷’ĹŠĻŻ°£
◊ ‘īĻ‹ņŪ£ļ
UMPŌĶÕ≥≤…”√◊ ‘ī≥ōĽķ÷∆ņīĻ‹ņŪ żĺ›Ņ‚∑ĢőŮ∆ų…ŌĶńCPU°Ęńŕīś°ĘīŇŇŐĶ»ľ∆ň„◊ ‘ī£¨ňý”–Ķńľ∆ň„◊ ‘ī∂ľ∑Ň‘ŕ◊ ‘ī≥ōńŕĹÝ––Õ≥“Ľ∑÷Ňš£¨◊ ‘ī≥ō «ő™MySQL Ķņż∑÷Ňš◊ ‘īĶńĽýĪĺĶ•őĽ°£
’ŻłŲľĮ»ļ÷–Ķńňý”–∑ĢőŮ∆ųĽŠłýĺ›∆šĽķ–Õ°Ęňý‘ŕĽķ∑ŅĶ»“ÚňōĪĽĽģ∑÷∂ŗłŲ◊ ‘ī≥ō£¨√ŅŐ®∑ĢőŮ∆ųĽŠĪĽľ”»ŽĶĹŌŗ”¶Ķń◊ ‘ī≥ō÷–°£
∂‘”ŕ√ŅłŲĺŖŐŚMySQL Ķņż£¨Ļ‹ņŪ‘ĪĽŠłýĺ›”¶”√≤Ņ ū‘ŕńń–©Ľķ∑Ņ°Ę–Ť“™ńń–©ľ∆ň„◊ ‘īĶ»“Úňō£¨ő™ł√MySQL ĶņżĺŖŐŚ÷ł∂®÷ųŅ‚ļÕī”Ņ‚ňý‘ŕĶń◊ ‘ī≥ō£¨»Ľļů£¨ŌĶÕ≥Ķń ĶņżĻ‹ņŪ∑ĢőŮĽŠĪĺ◊Ňłļ‘ōĺýļ‚Ķń‘≠‘Ú£¨ī”◊ ‘ī≥ō÷–—°‘Ůłļ‘ōĹŌ«ŠĶń∑ĢőŮ∆ųņīīīĹ®MySQL Ķņż°£
◊ ‘īĶų∂»£ļ
UMPŌĶÕ≥÷–”–»ż÷÷ĻśłŮĶń”√Ľß£¨∑÷Īū « żĺ›ŃŅļÕŃųŃŅĪ»ĹŌ–°Ķń”√Ľß°Ę÷–Ķ»Ļśń£”√Ľß“‘ľį–Ť“™∑÷Ņ‚∑÷ĪŪĶń”√Ľß°£
∂ŗłŲ–°Ļśń£”√ĽßŅ…“‘Ļ≤ŌŪÕ¨“ĽłŲMySQL Ķņż
∂‘”ŕ÷–Ķ»Ļśń£Ķń”√Ľß£¨√ŅłŲ”√Ľß∂ņ’ľ“ĽłŲMySQL Ķņż
∂‘”ŕ∑÷Ņ‚∑÷ĪŪĶń”√Ľß£¨ĽŠ’ľ”–∂ŗłŲ∂ņŃĘĶńMySQL Ķņż
◊ ‘īłŰņŽ£ļ
UMP≤…”√ĶńŃĹ÷÷◊ ‘īłŰņŽ∑Ĺ Ĺ£ļ
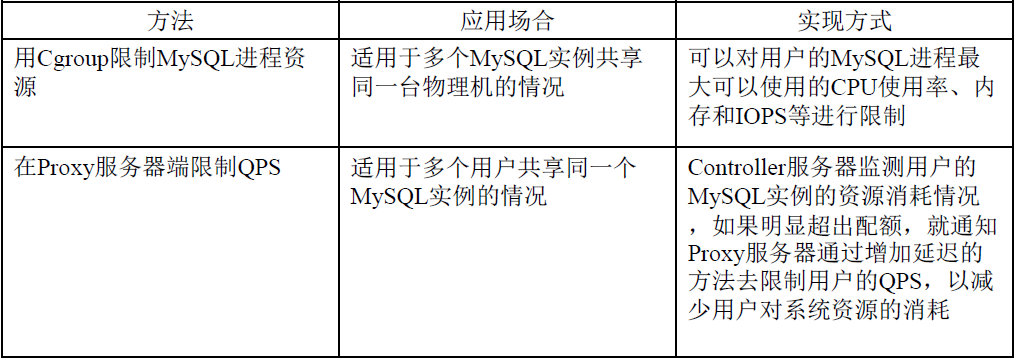
żĺ›į≤»ę£ļ
UMPŌĶÕ≥…Ťľ∆Ńň∂ŗ÷÷Ľķ÷∆ņīĪ£÷§ żĺ›į≤»ę£ļ
SSL żĺ›Ņ‚ѨŔ£ļSSL(Secure Sockets Layer) «ő™ÕݬÁÕ®–ŇŐŠĻ©į≤»ęľį żĺ›ÕÍ’Ż–‘Ķń“Ľ÷÷į≤»ę–≠“ť£¨ňŁ‘ŕīę š≤„∂‘ÕݬÁѨŔĹÝ––ľ”√‹°£Proxy∑ĢőŮ∆ų ĶŌ÷ŃňÕÍ’ŻĶńMySQLŅÕĽß∂ň/∑ĢőŮ∆ų–≠“ť£¨Ņ…“‘”ŽŅÕĽß∂ň÷ģľšĹ®ŃĘSSL żĺ›Ņ‚ѨŔ°£
żĺ›∑√ő IPį◊√ŻĶ•£ļŅ…“‘į—‘ –Ū∑√ő ‘∆ żĺ›Ņ‚ĶńIPĶō÷∑∑Ň»Ž°įį◊√ŻĶ•°Ī£¨÷Ľ”–į◊√ŻĶ•ńŕĶńIPĶō÷∑≤Ňń‹∑√ő £¨∆šňŻIPĶō÷∑Ķń∑√ő ∂ľĽŠĪĽĺ‹ĺÝ£¨ī”∂ÝĹÝ“Ľ≤ĹĪ£÷§’ňĽßį≤»ę°£
ľ«¬ľ”√Ľß≤Ŕ◊ų»’÷ĺ£ļ”√ĽßĶńňý”–≤Ŕ◊ųľ«¬ľ∂ľĽŠĪĽľ«¬ľĶĹ»’÷ĺ∑÷őŲ∑ĢőŮ∆ų£¨Õ®Ļżľž≤ť”√Ľß≤Ŕ◊ųľ«¬ľ£¨Ņ…“‘∑ĘŌ÷“Ģ≤ōĶńį≤»ę¬©∂ī°£
SQLņĻĹō£ļProxy∑ĢőŮ∆ųŅ…“‘łý囓™«ůņĻĹō∂ŗ÷÷ņŗ–ÕĶńSQL”Ôĺš£¨Ī»»Á»ęĪŪ…®√Ť”Ôĺš°įselect *°Ī°£
Amazon AWS£®Amazon Web Services£©ļÕ‘∆ żĺ›Ņ‚
AmazonļÕ‘∆ľ∆ň„Ķń‘®‘ī£ļ
2016ńÍ3‘¬14»’£¨—«¬Ū—∑ÕݬÁ∑ĢőŮ£®AWS£© ģňÍŃň°£
Amazon Web Services“ĶőŮŌŗĶĪ”ŕĹŰňś∆šļůĶń4īůĺļ’ý∂‘ ÷Ķń◊‹ļÕ°£
—«¬Ū—∑‘ŕ»ę«Ú”Ķ”–12łŲ«Ý”Ú–‘ żĺ›÷––ń°£
Amazon Web ServicesŐŠĻ©Ķń∂ŗłŲ—«¬Ū—∑ żĺ›Ņ‚∂ľ‘ŕ”Žľ◊Ļ«őń£®Oracle£©ľ§Ń“ĺļ’ý£¨∆š÷–Amazon
RDS”–10ÕÚ∂ŗłŲĽÓ‘ĺ”√Ľß°£
—«¬Ū—∑ żĺ›Ņ‚Aurora£¨ «Amazon Web Servicesņķ ∑…Ō‘Ų≥§◊ÓŅžĶń∑ĢőŮ°£
—«¬Ū—∑Ķń‘∆∑ĢőŮŐŠĻ©Ńň∂ŗīÔľł ģ÷÷∑ĢőŮ£¨ļ≠ł«ŃňIaaS°ĘPaaS°ĘSaaS’‚»ż≤„°£
Amazon AWS£ļ
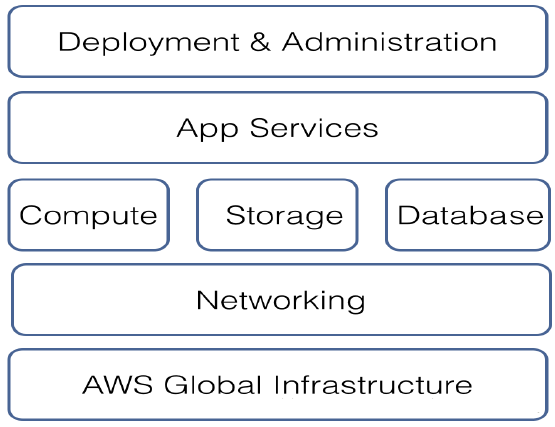
Õľ£ļAmazon AWSľ‹ĻĻÕľ
(1)AWS Global Infrastructure(AWS»ęĺ÷Ľýī°…Ť ©)
‘ŕ»ęĺ÷Ľýī°…Ť ©÷–”–3łŲļ‹÷ō“™ĶńłŇńÓ°£
Ķŕ“ĽłŲ «Region£®«Ý”Ú£©£¨√ŅłŲRegion «ŌŗĽ•∂ņŃĘĶń£¨◊‘≥…“ĽŐ◊‘∆∑ĢőŮŐŚŌĶ£¨∑÷≤ľ‘ŕ»ę«ÚłųĶō°£ńŅ«į»ę«Ú”–10łŲRegion£®Ī»»Á
ĪĪĺ©£©°£
Ķŕ∂ĢłŲ «Availability Zone(Ņ…”√«Ý)£¨√ŅłŲRegion”÷”… żłŲŅ…”√«Ý◊ť≥…£¨√ŅłŲŅ…”√«ÝŅ…“‘Ņī◊Ų“ĽłŲ żĺ›÷––ń£¨ŌŗĽ•÷ģľšÕ®ĻżĻ‚ŌňѨŔ°£
Ķ໿łŲ «Edge Locations£®ĪŖ‘ĶĹŕĶ„£©°£»ę«ÚńŅ«į”–50∂ŗłŲĪŖ‘ĶĹŕĶ„£¨ «“ĽłŲńŕ»›∑÷∑ĘÕݬÁ£®CDN£¨Content
Distrubtion Network£©£¨Ņ…“‘ĹĶĶÕńŕ»›∑÷∑ĘĶń—”≥Ŕ£¨Ī£÷§÷’∂ň”√ĽßĽŮ»°◊ ‘īĶńňŔ∂»°£
(2)Network(ÕݬÁ)£ļ
AWSŐŠĻ©ĶńÕݬÁ∑ĢőŮ÷ų“™”–£ļ
Direct Connect£ļ÷ß≥÷∆ů“Ķ◊‘…ŪĶń żĺ›÷––ń÷ĪĹ””ŽAWSĶń żĺ›÷––ń÷ĪѨ£¨≥š∑÷ņŻ”√∆ů“ĶŌ÷”–Ķń◊ ‘ī°£
VPN Connection£ļÕ®ĻżVPNѨŔAWS£¨Ī£÷§ żĺ›Ķńį≤»ę–‘°£
Virtual Private Cloud£ļ ňĹ”–‘∆£¨ī”AWS‘∆◊ ‘ī÷–∑÷“ĽŅťłÝń„ Ļ”√£¨ĹÝ“Ľ≤ĹŐŠłŖį≤»ę–‘°£
Route 53£ļ—«¬Ū—∑ŐŠĻ©ĶńłŖŅ…”√ĶńŅ……žňűĶń‘∆”Ú√ŻĹ‚őŲŌĶÕ≥°£Amazon Route 53 łŖ–ßĶōĹę”√Ľß«Ž«ůѨŔĶĹ
AWS ÷–‘ň––ĶńĽýī°…Ť ©£¨ņż»Á Amazon EC2 Ķņż°ĘElastic Load Balancing
łļ‘ōĺýļ‚∆ųĽÚ Amazon S3 īśīĘÕį°£
£®3£©Computer£®ľ∆ň„£©:
—«¬Ū—∑Ķńľ∆ň„ļň–ń£¨įŁņ®Ńň÷ŕ∂ŗĶń∑ĢőŮ:
EC2£ļ Elastic Compute Cloud£¨—«¬Ū—∑Ķń–ťń‚Ľķ£¨÷ß≥÷WindowsļÕLinuxĶń∂ŗłŲįśĪĺ£¨÷ß≥÷APIīīĹ®ļÕŌķĽŔ£¨”–∂ŗ÷÷–ÕļŇŅ…Ļ©—°‘Ů£¨įī–Ť Ļ”√°£≤Ę«“”–◊‘∂Įņ©’ĻĻ¶ń‹(5∑÷÷”ľīŅ…–¬Ĺ®“ĽłŲ–ťń‚Ľķ)£¨”––ßĹ‚ĺŲ”¶”√≥Ő–Ú–‘ń‹ő Ő‚°£
ELB£ļ Elastic Load Balancing£¨ —«¬Ū—∑ŐŠĻ©Ķńłļ‘ōĺýļ‚∆ų£¨Ņ…“‘ļÕEC2őř∑žŇšļŌ Ļ”√£¨ļŠŅÁ∂ŗłŲŅ…”√«Ý£¨Ņ…“‘◊‘∂Įľž≤ť ĶņżĶńĹ°ŅĶ◊īŅŲ£¨◊‘∂ĮŐř≥ż”–ő Ő‚Ķń Ķņż£¨Ī£÷§”¶”√≥Ő–ÚĶńŅ…ŅŅ–‘°£
Glacier£ļ÷ų“™”√”ŕĹŌ…Ŕ Ļ”√ĶńīśīĘīśĶĶőńľĢļÕĪł∑›őńľĢ£¨ľŘłŮĪ„“ňŃŅ”÷◊„£¨į≤»ę–‘łŖ°£
£®4£©DateBase£® żĺ›Ņ‚£©£ļ
—«¬Ū—∑ŐŠĻ©ĻōŌĶ–Õ żĺ›Ņ‚ļÕNoSQL żĺ›Ņ‚£¨“‘ľį“Ľ–©cacheĶ» żĺ›Ņ‚∑ĢőŮ£ļ
SimpleDB£ļĽý”ŕ‘∆ĶńľŁ / ÷Ķ żĺ›īśīĘ∑ĢőŮ°£
DynamoDB£ļ DynamoDB «—«¬Ū—∑◊‘÷ų—–∑ĘĶńNo SQL żĺ›Ņ‚£¨–‘ń‹łŖ£¨»›īŪ–‘«Ņ£¨÷ß≥÷∑÷≤ľ Ĺ°£
RDS£ļRelational Database Service£¨ĻōŌĶ–Õ żĺ›Ņ‚∑ĢőŮ°£÷ß≥÷MySQL£¨SQL
ServerļÕOracleĶ» żĺ›Ņ‚°£
Amazon ElastiCache£ļ żĺ›Ņ‚Ľļīś∑ĢőŮ°£
£®5£©Application Server£®”¶”√≥Ő–Ú∑ĢőŮ£©£ļ
Cloud Search: “ĽłŲĶĮ–‘Ķńň—ňų“ż«ś£¨Ņ…”√”ŕ∆ů“Ķľ∂ň—ňų
Amazon SQS£ļ ∂”Ń–∑ĢőŮ£¨īśīĘļÕ∑÷∑ĘŌŻŌĘ
Simple Workflow£ļ“ĽłŲĻ§◊ųŃųŅÚľ‹
CloudFront£ļ ņĹÁ∑∂őßĶńńŕ»›∑÷∑ĘÕݬÁ£®CDN£©
EMR£ļ Elastic MapReduce£¨“ĽłŲHadoopŅÚľ‹ľ‹Ķń Ķņż£¨Ņ…”√”ŕīů żĺ›ī¶ņŪ°£
£®6£©Deployment & Admin£®≤Ņ ūļÕĻ‹ņŪ£©£ļ
Elastic BeanStalk: “ĽľŁ ĹīīĹ®łų÷÷Ņ™∑ĘĽ∑ĺ≥ļÕ‘ň–– Ī°£
CloudFormation£ļ≤…”√JSONłŮ ĹĶńń£įŚőńľĢņīīīĹ®ļÕĻ‹ņŪ“ĽŌĶŃ–—«¬Ū—∑‘∆◊ ‘ī°£
OpsWorks£ļ OpsWorks‘ –Ū”√ĽßĹꔶ”√≥Ő–ÚĶń≤Ņ ūń£ŅťĽĮ£¨Ņ…“‘ ĶŌ÷∂‘ żĺ›Ņ‚°Ę‘ň–– Ī°Ę∑ĢőŮ∆ų»ŪľĢĶ»◊‘∂ĮĽĮ…Ť÷√ļÕį≤◊į°£
IAM£ļ Identity & Access Management£¨»Ō÷§ļÕ∑√ő Ļ‹ņŪ∑ĢőŮ°£”√Ľß Ļ”√‘∆∑ĢőŮ◊ÓĶ£–ńĶń ¬«ť÷ģ“ĽĺÕ «į≤»ęő Ő‚°£—«¬Ū—∑Õ®ĻżIAMŐŠĻ©ŃňŃĘŐŚĽĮĶńį≤»ę≤Ŗ¬‘£¨Ī£÷§”√Ľß‘ŕ‘∆…ŌĶń◊ ‘īĺÝ∂‘Ķńį≤»ę
◊‹ŐŚ∂Ý—‘£¨Amazon AWSĶń≤ķ∆∑∑÷ő™ľłłŲ≤Ņ∑÷£ļ
ľ∆ň„ņŗ
ĶĮ–‘ľ∆ň„‘∆EC2£ļEC2ŐŠĻ©Ńň‘∆÷–Ķń–ťń‚Ľķ°£
ĶĮ–‘MapReduce£ļĹęHadoop MapReduceįŠĶĹ‘∆Ľ∑ĺ≥÷–£¨īůŃŅEC2 Ķņż∂ĮŐ¨Ķō≥…ő™÷ī––īůĻśń£MapReduceľ∆ň„»őőŮĶńĻ§◊ųĽķ°£
īśīĘņŗ
ĶĮ–‘ŅťīśīĘEBS
ľÚĶ•ŌŻŌĘīśīĘSQS
Blob∂‘ŌůīśīĘS3
NoSQL–Õ żĺ›Ņ‚£ļSimpleDBļÕDynamoDB
ĻōŌĶ żĺ›Ņ‚RDS
Ļ§ĺŖ÷ß≥÷
AWS÷ß≥÷∂ŗ÷÷Ņ™∑ʔԗ‘£¨ŐŠĻ©Java°ĘRupy°ĘPython°ĘPHP°ĘWindows &.NET
“‘ľįAndroidļÕiOSĶńĻ§ĺŖľĮ°£
Ļ§ĺŖľĮ÷–įŁļ¨łų÷÷”Ô—‘ĶńSDK£¨≥Ő–Ú◊‘∂Į≤Ņ ū“‘ľįłų÷÷Ļ‹ņŪĻ§ĺŖ°£
AWSÕ®ĻżCloudWatchŌĶÕ≥ŐŠĻ©∑ŠłĽĶńľŗŅōĻ¶ń‹°£
őĘ»Ū‘∆ żĺ›Ņ‚SQL Azure
SQL AzureľÚĹť£ļ
SQL Azure «őĘ»ŪĶń‘∆ĻōŌĶ–Õ żĺ›Ņ‚£¨ļů∂ňīśīĘ”÷≥∆ő™°į‘∆SQL Server°Ī°£
ĻĻĹ®‘ŕSQL Server÷ģ…Ō£¨Õ®Ļż∑÷≤ľ Ĺľľ űŐŠ…żīęÕ≥ĻōŌĶ żĺ›Ņ‚ĶńŅ…ņ©’Ļ–‘ļÕ»›īŪń‹Ń¶°£
‘∆SQL Server żĺ›ń£–Õ:
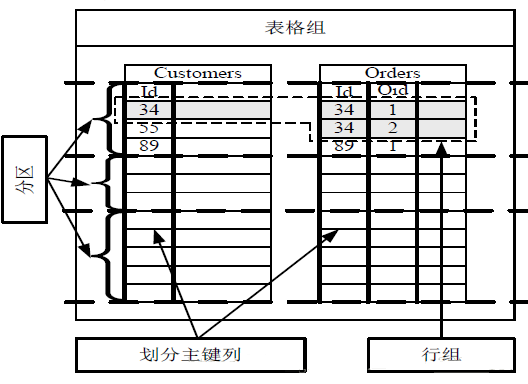
Õľ£ļ‘∆SQL Server żĺ›ń£–Õ
1.¬Ŗľ≠ń£–Õ:
“ĽłŲ¬Ŗľ≠ żĺ›Ņ‚≥∆ő™“ĽłŲĪŪłŮ◊ť
ĪŪłŮ◊ť÷–ňý”–Ľģ∑÷÷ųľŁŌŗÕ¨Ķń––ľĮļŌ≥∆ő™––◊ť£®row group£©
÷Ľ÷ß≥÷Õ¨“ĽłŲ––◊ťńŕĶń ¬őŮ£¨Õ¨“ĽłŲ––◊ťĶń żĺ›¬Ŗľ≠…ŌĽŠ∑÷≤ľĶĹ“ĽŐ®∑ĢőŮ∆ų£¨“‘īňĻśĪ‹∑÷≤ľ Ĺ ¬őŮ
Õ®Ļż÷ųĪłłī÷∆Ĺę żĺ›łī÷∆ĶĹ∂ŗłŲłĪĪĺ£¨Ī£÷§łŖŅ…”√–‘
2.őÔņŪń£–Õ£ļ
‘ŕőÔņŪ≤„√ś£¨√ŅłŲ”–÷ųľŁĶńĪŪłŮ◊ťłý囼ģ∑÷÷ųľŁŃ–”––ÚĶō∑÷≥…∂ŗłŲ żĺ›∑÷«Ý°£√ŅłŲ––◊ť Ű”ŕő®“Ľ∑÷«Ý°£
∑÷«Ý «SQL Azurełī÷∆°Ę«®“∆°Ęłļ‘ōĺýļ‚ĶńĽýĪĺĶ•őĽ°£√ŅłŲ∑÷«ÝįŁļ¨∂ŗłŲłĪĪĺ£®ń¨»Ōő™3£©£¨√ŅłŲłĪĪĺīśīĘ‘ŕ“ĽŐ®őÔņŪĶńSQL
Server…Ō°£
SQL AzureĪ£÷§√ŅłŲ∑÷«ÝĶń∂ŗłŲłĪĪĺ∑÷≤ľĶĹ≤ĽÕ¨ĶńĻ ’Ō”Ú°£√ŅłŲ∑÷«Ý”–“ĽłŲłĪĪĺő™÷ųłĪĪĺ£®Primary£©,∆šňŻłĪĪĺő™ī”łĪĪĺ£®Secondary£©°£÷ųłĪĪĺī¶ņŪňý”–Ķń≤ť—Į°ĘłŁ–¬ ¬őŮ£¨≤Ę“‘≤Ŕ◊ų»’÷ĺĶń–ő Ĺ£¨Ĺę ¬őŮÕ¨≤ĹĶĹī”łĪĪĺ£¨ī”łĪĪĺĹ” ’÷ųłĪĪĺ∑ĘňÕĶń ¬őŮ»’÷ĺ≤Ę”¶”√ĶĹĪĺĶō żĺ›Ņ‚°£
ŐŚŌĶľ‹ĻĻ£ļ

Õľ£ļ‘∆SQL ServerĶń∑÷≤„ľ‹ĻĻ
SQL Azure∑÷ő™ňńłŲ÷ų“™≤Ņ∑÷£ļ SQL Server Ķņż°Ę»ęĺ÷∑÷«ÝĻ‹ņŪ∆ų°Ę–≠“ťÕÝĻō°Ę∑÷≤ľ ĹĽýī°≤ŅľĢ°£
√ŅłŲSQL Server Ķņż «“ĽłŲ‘ň––◊ŇSQLServerĶńőÔņŪĹÝ≥Ő°£√ŅłŲőÔņŪ żĺ›Ņ‚įŁļ¨∂ŗłŲ◊” żĺ›Ņ‚£¨ňŁ√«÷ģľšŌŗĽ•łŰņŽ°£◊” żĺ›Ņ‚ «“ĽłŲ∑÷«Ý£¨įŁļ¨”√ĽßĶń żĺ›“‘ľįschema–ŇŌĘ.
»ęĺ÷∑÷«ÝĻ‹ņŪ∆ųő¨Ľ§∑÷«Ý”≥…šĪŪ–ŇŌĘ.
–≠“ťÕÝĻōłļ‘ūĹę”√ĽßĶń żĺ›Ņ‚ѨŔ«Ž«ů◊™∑ĘĶĹŌŗ”¶Ķń÷ų∑÷«Ý…Ō.
∑÷≤ľ ĹĽýī°≤ŅľĢ£®Fabric£©”√”ŕő¨Ľ§Ľķ∆ų…ŌŌ¬ŌŖ◊īŐ¨£¨ľž≤‚∑ĢőŮ∆ųĻ ’Ō≤Ęő™ľĮ»ļ÷–Ķńłų÷÷Ĺ«…ę÷ī––—°»°÷ųĹŕĶ„≤Ŕ◊ų.
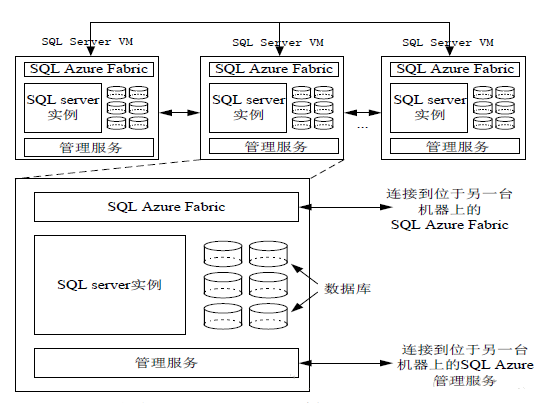
Õľ£ļSQL AzureĶńŐŚŌĶľ‹ĻĻ
SQL AzureĶńŐŚŌĶľ‹ĻĻ÷–įŁļ¨Ńň“ĽłŲ–ťń‚Ľķīō£¨Ņ…“‘łýĺ›Ļ§◊ųłļ‘ōĶńĪšĽĮ£¨∂ĮŐ¨‘Ųľ”ĽÚľű…Ŕ–ťń‚ĽķĶń żŃŅ°£
√ŅŐ®–ťń‚ĽķSQL Server VM(virtualmachine)į≤◊įŃňSQL Server żĺ›Ņ‚Ļ‹ņŪŌĶÕ≥£¨“‘ĻōŌĶń£–ÕīśīĘ żĺ›°£
Õ®≥££¨“ĽłŲ żĺ›Ņ‚ĽŠĪĽ…ĘīśīĘĶĹ3~5Ő®SQL Server VM÷–°£
įĘņÔ‘∆RDS
įĘņÔ‘∆RDSľÚĹť£ļ
RDS «įĘņÔ‘∆ŐŠĻ©ĶńĻōŌĶ–Õ żĺ›Ņ‚∑ĢőŮ£¨ňŁĹę÷ĪĹ”‘ň––”ŕőÔņŪ∑ĢőŮ∆ų…ŌĶń żĺ›Ņ‚ Ķņż◊‚łÝ”√Ľß£¨ «◊®“ĶĻ‹ņŪĶń°ĘłŖŅ…ŅŅĶń‘∆∂ň żĺ›Ņ‚∑ĢőŮ°£
RDS”…◊®“Ķ żĺ›Ņ‚Ļ‹ņŪÕŇ∂”ő¨Ľ§£¨ĽĻŅ…“‘ő™”√ĽßŐŠĻ© żĺ›Īł∑›°Ę żĺ›Ľ÷łī°Ęņ©’Ļ…żľ∂Ķ»Ļ‹ņŪĻ¶ń‹£¨Ōŗ∂‘”ŕ”√Ľß◊‘Ĺ® żĺ›Ņ‚∂Ý—‘£¨RDSĺŖ”–◊®“Ķ°ĘłŖŅ…ŅŅ°ĘłŖ–‘ń‹°ĘŃťĽÓ“◊”√Ķ»”ŇĶ„£¨ń‹ĻĽįÔ÷ķ”√ĽßĹ‚ĺŲ∑— Ī∑—ѶĶń żĺ›Ņ‚Ļ‹ņŪ»őőŮ£¨»√”√ĽßĹ곣∂ŗĶń ĪľšĺŘĹĻ‘ŕļň–ń“ĶőŮ…Ō°£
RDSĺŖ”–į≤»ęő»∂®°Ę żĺ›Ņ…ŅŅ°Ę◊‘∂ĮĪł∑›°ĘĻ‹ņŪÕł√ų°Ę–‘ń‹◊Ņ‘Ĺ£¨ŃťĽÓņ©»›Ķ»”ŇĶ„£¨Ņ…“‘ŐŠĻ©◊®“ĶĶń żĺ›Ņ‚Ļ‹ņŪ∆ĹŐ®°Ę◊®“ĶĶń żĺ›Ņ‚”ŇĽĮĹ®“ť“‘ľįÕÍ…∆ĶńľŗŅōŐŚŌĶ°£
RDS÷–ĶńłŇńÓ£ļ
RDS Ķņż£¨ «”√ĽßĻļ¬ÚRDS∑ĢőŮĶńĽýĪĺĶ•őĽ°£‘ŕ Ķņż÷–£ļ
Ņ…“‘īīĹ®∂ŗłŲ żĺ›Ņ‚
Ņ…“‘ Ļ”√≥£ľŻĶń żĺ›Ņ‚ŅÕĽß∂ňѨŔ°ĘĻ‹ņŪľį Ļ”√ żĺ›
Ņ…“‘Õ®ĻżRDSĻ‹ņŪŅō÷∆Ő®ĽÚOPEN APIņīīīĹ®°Ę–řłńļÕ…ĺ≥ż żĺ›Ņ‚
RDS żĺ›Ņ‚£¨ «”√Ľß‘ŕ“ĽłŲ ĶņżŌ¬īīĹ®Ķń¬Ŗľ≠Ķ•‘™
“ĽłŲ ĶņżŅ…“‘īīĹ®∂ŗłŲ żĺ›Ņ‚£¨‘ŕ Ķņżńŕ żĺ›Ņ‚√Ł√Żő®“Ľ£¨ňý”– żĺ›Ņ‚∂ľĽŠĻ≤ŌŪł√ ĶņżŌ¬Ķń◊ ‘ī£¨»ÁCPU°Ęńŕīś°ĘīŇŇŐ»›ŃŅĶ»
RDS≤Ľ÷ß≥÷ Ļ”√ĪÍ◊ľĶńSQL”Ô嚼ÚŅÕĽß∂ňĻ§ĺŖīīĹ® żĺ›Ņ‚£¨Īō–Ž Ļ”√OPEN APIĽÚRDSĻ‹ņŪŅō÷∆Ő®ĹÝ––≤Ŕ◊ų
Ķō”Ú÷łĶń «”√ĽßňýĻļ¬ÚĶńRDS ĶņżĶń∑ĢőŮ∆ųňýī¶ĶńĶōņŪőĽ÷√°£
RDSńŅ«į÷ß≥÷ļľ÷›°Ę«ŗĶļ°ĘĪĪĺ©°Ę…ÓŘŕļÕŌ„łŘőŚłŲĶō”Ú£¨∑ĢőŮ∆∑÷ ÕÍ»ęŌŗÕ¨°£”√ĽßŅ…“‘‘ŕĻļ¬ÚRDS Ķņż Ī÷ł∂®Ķō”Ú£¨Ļļ¬Ú Ķņżļů‘›≤Ľ÷ß≥÷łŁłń°£
RDSŅ…”√«Ý «÷ł‘ŕÕ¨“ĽĶō”ÚŌ¬£¨ĶÁѶ°ĘÕݬÁłŰņŽĶńőÔņŪ«Ý”Ú£¨Ņ…”√«Ý÷ģľšńŕÕÝĽ•Õ®£¨Ņ…”√«ÝńŕÕݬÁ—” ĪłŁ–°£¨≤ĽÕ¨Ņ…”√«Ý÷ģľšĻ ’ŌłŰņŽ°£
RDSŅ…”√«Ý”÷∑÷ő™Ķ•Ņ…”√«ÝļÕ∂ŗŅ…”√«Ý
Ķ•Ņ…”√«Ý «÷łRDS ĶņżĶń÷ųĪłĹŕĶ„őĽ”ŕŌŗÕ¨ĶńŅ…”√«Ý£¨ňŁŅ…“‘”––ßŅō÷∆‘∆≤ķ∆∑ľšĶńÕݬÁ—”≥Ŕ
∂ŗŅ…”√«Ý «÷łRDS ĶņżĶń÷ųĪłĹŕĶ„őĽ”ŕ≤ĽÕ¨ĶńŅ…”√«Ý£¨ĶĪ÷ųĹŕĶ„ňý‘ŕŅ…”√«Ý≥ŲŌ÷Ļ ’Ō£®»ÁĽķ∑Ņ∂ŌĶÁĶ»£©£¨RDSĹÝ––÷ųĪł«–ĽĽļů£¨ĽŠ«–ĽĽĶĹĪłĹŕĶ„ňý‘ŕĶńŅ…”√«ÝľŐ–ÝŐŠĻ©∑ĢőŮ°£∂ŗŅ…”√«ÝĶńRDS«Šň… ĶŌ÷ŃňÕ¨≥«»›‘÷
īŇŇŐ»›ŃŅ «”√ĽßĻļ¬ÚRDS Ķņż Ī£¨ňý—°‘ŮĻļ¬ÚĶńīŇŇŐīů–°
Ķņżňý’ľ”√ĶńīŇŇŐ»›ŃŅ£¨≥żŃňīśīĘĪŪłŮ żĺ›Õ‚£¨ĽĻ”– Ķņż’ż≥£‘ň––ňý–Ť“™ĶńŅ’ľš£¨»ÁŌĶÕ≥ żĺ›Ņ‚°Ę żĺ›Ņ‚ĽōĻŲ»’÷ĺ°Ę÷ō◊Ų»’÷ĺ°Ęňų“żĶ»°£
**RDSѨŔ ż£¨** «”¶”√≥Ő–ÚŅ…“‘Õ¨ ĪѨŔĶĹRDS ĶņżĶńѨŔ żŃŅ
»ő“‚ѨŔĶĹRDS ĶņżĶńѨŔĺýľ∆ň„‘ŕńŕ£¨”Ž”¶”√≥Ő–ÚĽÚ’ŖÕÝ’ĺń‹ĻĽ÷ß≥÷Ķń◊Óīů”√Ľß żőřĻō
”√Ľß‘ŕĻļ¬ÚRDS
| 







