|
Ķľ∂Ń£ļ
Īĺőń÷ų“™Ĺť…‹ő™ ≤√ī“™ żĺ›Ĺ®ń£°Ę żĺ›Ĺ®ń£÷÷ņŗ°Ę3NF żĺ›Ĺ®ń£°Ęő¨∂»Ĺ®ń£°Ę3NFĹ®ń£”Žő¨∂»Ĺ®ń£Ķń«ÝĪū°Ę÷łĪÍļÕő¨∂»Ĺ®ń£≤Ĺ÷ŤĶ»ńŕ»›°£ Īĺőńņī◊‘csdn£¨”…ĽūŃķĻŻ»ŪľĢAnnaĪŗľ≠°ĘÕ∆ľŲ°£ |
| Īĺőńņī◊‘csdn£¨”…ĽūŃķĻŻ»ŪľĢAnnaĪŗľ≠°ĘÕ∆ľŲ°£ |
|
| ő™Ńň∑ĹĪ„∂Ń’Ŗ‘ń∂Ń£¨≤…”√CML£®Concept
Model Language powered by ĽūŃķĻŻ»ŪľĢ£©∂‘ĪĺőńĹ®ń£»ÁŌ¬£ļ |
 |
| √ś∂‘‘Ĺņī‘Ĺ∂ŗĶń–ŇŌĘ£¨ő“√«Ķń”Ô—‘–Ť“™ĹÝĽĮ£¨CML£®Concep
Model Language£©ĶńńŅĪÍ£ļ |
|
| ňý”–»ň∂ľń‹ĻĽ Ļ”√£ļŅ∆—ßľ“°ĘĻ§≥Ő ¶°Ę—ß…ķ
Ņ…“‘÷ß≥÷łųłŲ◊®“Ķ£ļőÔņŪ°Ę ż—ß°Ę∑…Ľķ°Ę∆Ż≥Ķ...
Ĺ®ŃĘ◊‘»Ľ”Ô—‘ļÕ◊®“Ķń£–Õ÷ģ…ŌĶń¬Ŗľ≠”Ô—‘ |
|
|
| Ĺ®ń£’Ŗ£ļAnna Ļ§ĺŖ£ļEA |
|
’żőń£ļ
“Ľ°Ęő™ ≤√ī“™ żĺ›Ĺ®ń£
Ň–∂Ō“ĽłŲńÍ«Š»ň”–√Ľ”–«ĪѶ£¨ļ‹÷ō“™ĶńĪÍ◊ľ£¨ĺÕ «ŅīňŻ»Áļő∂‘īż“ĽŌÓī”ņī√Ľ”–◊ŲĻżĶń ¬«ť°£ő“√«≥£≥£ĽŠ“ż»Ž°įŐŚŌĶł–°Īņī√Ť Ų’‚łŲ—ßŌįļÕ…Ō ÷ĶńĻż≥Ő°£ňýőĹŐŚŌĶ£¨ĺÕ «Ĺę◊Ų ¬Ķń∑Ĺ∑®°Ę≤Ĺ÷ŤļÕŃų≥Ő£¨Õ®Ļż≤ū∑÷”Ž◊ťļŌ£¨ĻĻĹ®≥Ų“ĽŐűīÔĶĹńŅĪÍĶń¬∑ĺ∂Õľ°£őř¬Ř «ĹĽīķŌ¬ņīĶń–¬»őőŮ£¨ĽĻ «ī¶ņŪ“ĽľĢļ‹ľ¨ ÷Ķń–¬ ¬«ť£¨ňŁ√«Ī≥ļůĽÚ∂ŗĽÚ…Ŕ∂ľ“Ľ∂®”–“ĽŐ◊ŐŚŌĶ∑Ĺ∑®īś‘ŕ°£ňŁľ» «◊Ų ¬ĺų«Ō£¨“≤ «Ī‹Ņ”÷łńŌ£¨łŁ «įÔ÷ķő“√«ŅžňŔłŖ–ßīÔĶĹńŅĪÍĶń––∂Į÷ł“ż°£
»Ľ∂Ýļ‹…Ŕ”–»ň‘ŕ◊Ų ¬÷ģ«į£¨ĽŠ»•Ņľ¬«’‚–©∂ęőų°£īů∂ŗ ż»ňÕýÕý «°į÷Īĺű–Õ°Ī—° ÷°£≤ľ÷√Ō¬ņī ¬«ťŃň£¨ ≤√ī∂ľ≤Ľ∂ŗő £¨ ≤√ī“≤≤Ľ∂ŗŌŽ£¨≤ĽĻ‹»ż∆Ŗ∂Ģ ģ“Ľ∆ĺł–ĺűŅ‘ŖÍŅ‘ŖÍ»•ł…°£»ÁĻŻ√Ľ”–“ĽłŲ”–ĺ≠—ťĶń»ň»ę≥Őľŗ∂ĹīÝ◊Ňń„£¨“Ľ∂®ĽŠ◊Ŗ–Ū∂ŗ‘©Õų¬∑£¨◊Ų–Ū∂ŗőř”√Ļ¶°£’‚∑ī”≥‘ŕņŌįŚ—ŘņÔ£¨ĺÕ «“ĽłŲ–߬ ĶÕŌ¬Ķń”°Ōů°£∆’Õ®»ň «Ō»ł…‘ŔŌŽ£¨≥ŲŃňő Ő‚‘ŔĽōÕ∑»•◊Ńń•‘≠“Ú£ĽīŌ√ų»ň «Ō»ŌŽ‘Ŕł…£¨į—Ņ…ń‹≥ŲŌ÷ĶńīŪőůľű…ŔĶĹ◊ÓĶÕ£¨◊Óīů≥Ő∂»Ī‹√‚Õš¬∑≥ŲŌ÷°£’‚÷–ľšĶń«ÝĪū£¨ĺÕ «ŐŚŌĶł–£®»ÁŌ¬Õľ£©£ļ

Õľ÷–Ķń–°ĪŗļŇĺÕ «◊Ų ¬Ķń≤Ĺ÷Ť°£’‚÷÷ŐŚŌĶŃų≥ŐĽĮĶńňľő¨“ĽĶ©Īš≥…ŌįĻŖ£¨ń‹ĻĽľęīůŐŠ…żĻ§◊ų–߬ °£
°įYou might put up a camping tent without
assembly instructions£¨but would you really try to
build your corporate headquarters without a documented
blueprint ?°Ī
‘ŕĹ®∑Ņ◊”Ķń ĪļÚő“√«“≤–Ť“™Õľ÷Ĺ°£»ÁĻŻ√Ľ”–Õľ÷ĹĶńĻśĽģ£¨Ņ…ŌŽ∂Ý÷™Ĺ®≥…Ķń∑Ņ◊”ľ»≥ů¬™”÷≤ĽĹŠ Ķ°£

ő“√«Õ®Ļż°įŐŚŌĶł–°Īņīį—Ņō◊‘ľļ£¨Õ®ĻżÕľ÷ĹņīĹ®ŃĘłŖ¬•īůŌ√°£Õ¨—ý£¨ő“√«Ņ…“‘Õ®Ļż°į żĺ›ń£–Õ°ĪņīĻ‹ņŪő“√«Ķń żĺ›°£
żĺ›ń£–ÕĺÕ « żĺ›Ķń◊ť÷ĮļÕīśīĘ∑Ĺ∑®£¨ňŁ«ŅĶųŃňī”“ĶőŮ°Ę żĺ›īś»°ļÕ Ļ”√Ĺ«∂»ļŌņŪīśīĘ żĺ›°Ę”–Ńň ļŌ“ĶőŮļÕĽýī° żĺ›īśīĘĽ∑ĺ≥Ķńń£–Õ£¨ń«√īīů żĺ›ĺÕĽŠĽŮĶ√“‘Ō¬ļ√ī¶£ļ
–‘ń‹
Ńľļ√Ķń żĺ›ń£–Õń„įÔ÷ķő“√«ŅžňŔ≤ť—Įňý–Ť“™Ķń żĺ›£¨ľű…Ŕ żĺ›ĶńIOÕŐÕ¬°£
≥…Īĺ
Ńľļ√Ķń żĺ›ń£–Õń‹ľęīůĶōľű…Ŕ≤ĽĪō“™Ķń żĺ›»Ŗ”ŗ£¨“≤ń‹ ĶŌ÷ľ∆ň„ĹŠĻŻłī”√£¨
ľęīůĶōĹĶĶÕīů żĺ›ŌĶÕ≥÷–ĶńīśīĘļÕľ∆ň„≥…Īĺ°£
–߬
Ńľļ√Ķń żĺ›ń£–Õń‹ľęīůĶōłń…∆”√Ľß Ļ”√ żĺ›ĶńŐŚ—ť£¨ŐŠłŖ Ļ”√ żĺ›Ķń–߬ °£
÷ ŃŅ
Ńľļ√Ķń żĺ›ń£–Õń‹łń…∆ żĺ›Õ≥ľ∆Ņŕĺ∂Ķń≤Ľ“Ľ÷¬–‘£¨ľű…Ŕľ∆ň„īŪőůĶńŅ…ń‹Ō¬°£
∂Ģ°Ę żĺ›Ĺ®ń£÷÷ņŗ
1°ĘĻōŌĶĹ®ń££®3NF£©
∂®“Ś£ļÕ®Ļż ĶŐŚĻōŌĶ(E-R)ŐŚŌ÷∆ů“Ķĺ≠”™ĽÓ∂ĮĶń“ĶőŮ“™ňōļÕ“ĶőŮĻś‘Ú£¨Õ®Ļż¬ķ◊„
3NF …Ťľ∆ŌŻ≥ż żĺ›»Ŗ”ŗ°£
”ŇĶ„£ļń£–Õő»∂®°ĘŃťĽÓ°Ęņ©’Ļ–‘«Ņ
»ĪĶ„£ļőĢ…Ł“Ľ∂® żĺ›∑√ő ĶńĪ„ņŻ–‘ļÕ“ĶőŮĶńŅ…ņŪĹ‚–‘
”√–‘£ļ ”√ļň–ńĽýī° żĺ›Ķń◊ť÷ĮļÕĻ‹ņŪ(ODS≤„)
”¶”√––“Ķ£ļ∑«Ľ•Ń™ÕÝ––“Ķ£¨»ÁīęÕ≥Ĺū»ŕ°Ę÷§»Į––“Ķ°ĘĶÁ–Ň––“Ķ°ĘŃ„ Ř°ĘļĹŅ’Ķ»
3NFļň–ńĪŪľšĻōŌĶ£ļ1-1£Ľn-1£Ľ1-n£Ľn-n£Ľ
żĺ›Ņ‚Ķń…Ťľ∆£ļī” ¬őÔ≥Ų∑Ę°Ęľű…Ŕ»Ŗ”ŗ£Ľ
żĺ›Ķń≤÷Ņ‚£ļī”∑÷őŲ≥Ų∑Ę
2°Ęő¨∂»Ĺ®ń£
∂®“Ś£ļįī’’ő¨∂»ĪŪ°Ę ¬ ĶĪŪĻĻĹ® żĺ›ń£–Õ£¨Õ®Ļż÷łĪÍ∆ņľŘ∆ů“Ķĺ≠”™ĽÓ∂Į
”ŇĶ„£ļ»›“◊ņŪĹ‚£¨Ņ…∑÷őŲ–‘łŖ(DM≤„)
»ĪĶ„£ļő»∂®–‘ņ©’Ļ–‘»ű°Ę żĺ›»Ŗ”ŗ
”√–‘£ļī”“ĶőŮ–Ť«ů≥Ų∑Ę£¨ő™∑÷őŲŐŠĻ©∑ĢőŮ
”√––“Ķ£ļĽ•Ń™ÕÝ––“Ķ
»ż°Ę3NF żĺ›Ĺ®ń£
1°Ę∑∂ ĹĹť…‹
1NF£ļ Ű–‘‘≠◊”≤ĽŅ…∑÷
2NF£ļ¬ķ◊„ 1NF£¨«“ĪŪ÷–Ķń√Ņ“ĽłŲ∑«÷ų Ű–‘£¨Īō–ŽÕÍ»ę“ņņĶ”ŕĪĺĪŪĶń÷ųľŁ
3NF£ļ»∑Ī£√ŅŃ–∂ľļÕ÷ųľŁŃ–÷ĪĹ”ŌŗĻō,∂Ý≤Ľ «ľšĹ”ŌŗĻō
2°Ę3NFĹ®ń£ Ķ’Ĺ
“ĶőŮ≥°ĺį£ļń≥łŲÕ¨—ß‘ŕ XXX “Ý––Ķń XXX ÷ß––ĶńĻŮŐ®–¬Ņ™Ńň“ĽłŲ’ňĽß£¨≤Ę«“īś»ŽŃň100»ň√ŮĪ“ĽÓ∆ŕ°£
“ĶőŮ“™ňō£ļŅÕĽß–ŇŌĘ°Ę’ňĽß–ŇŌĘļÕĹĽ“◊–ŇŌĘĶ»
3NFĹ®ń££ļ

ňń°Ęő¨∂»Ĺ®ń£
1°Ęő¨∂»ļÕ÷łĪÍĶńłŇńÓ
įī’’ő¨∂»ĪŪ°Ę ¬ ĶĪŪĻĻĹ® żĺ›ń£–Õ£¨Õ®Ļż÷łĪÍ∆ņľŘ∆ů“Ķĺ≠”™ĽÓ∂Į°£
ő¨∂»“Ľį„įŁņ®£ļĶō«Ý°Ę Īľš°Ę≤Ņ√Ň°Ę≤ķ∆∑Ķ»Ķ»°£
÷łĪÍ“Ľį„įŁņ®£ļŌķ Ř żŃŅ°ĘŌķ ŘĹū∂Ó°Ę∆ĹĺýŌķ ŘĹū∂ÓĶ»Ķ»°£
2°Ę–«–Õń£–Õ
–«–Õń£ «“Ľ÷÷∂ŗő¨Ķń żĺ›ĻōŌĶ£¨ňŁ”…“ĽłŲ ¬ ĶĪŪļÕ“Ľ◊ťő¨ĪŪ◊ť≥…°£√ŅłŲő¨ĪŪ∂ľ”–“ĽłŲő¨◊ųő™÷ųľŁ£¨ňý”–’‚–©ő¨Ķń÷ųľŁ◊ťļŌ≥… ¬ ĶĪŪĶń÷ųľŁ°£«ŅĶųĶń «∂‘ő¨∂»ĹÝ––‘§ī¶ņŪ£¨Ĺę∂ŗłŲő¨∂»ľĮļŌĶĹ“ĽłŲ ¬ ĶĪŪ£¨–ő≥…“ĽłŲŅŪĪŪ°£’‚“≤ «ő“√«‘ŕ Ļ”√
hive Ī£¨ĺ≠≥£ĽŠŅīĶĹ“Ľ–©īůŅŪĪŪĶń‘≠“Ú£¨īůŅŪĪŪ“Ľį„∂ľ « ¬ ĶĪŪ£¨įŁļ¨Ńňő¨∂»ĻōŃ™Ķń÷ųľŁļÕ“Ľ–©∂»ŃŅ–ŇŌĘ£¨∂Ýő¨∂»ĪŪ‘Ú « ¬ ĶĪŪņÔ√śő¨∂»ĶńĺŖŐŚ–ŇŌĘ£¨ Ļ”√ ĪļÚ“Ľį„Õ®Ļż
join ņī◊ťļŌ żĺ›£¨Ōŗ∂‘ņīňĶ∂‘OLAP Ķń∑÷őŲĪ»ĹŌ∑ĹĪ„°£
–«–Õń£–Õ“‘ ¬ ĶĪŪő™÷––ń£¨÷‹őßŅ…“‘”–ļ‹∂ŗő¨∂»£¨’‚–©ő¨∂»÷Ľń‹”–“Ľľ∂ő¨∂»(ő¨∂»Ō¬√ś≤Ľń‹”–◊”ő¨∂»)
3°Ę—©Ľ®ń£–Õ
ĶĪ”–“ĽłŲĽÚ∂ŗłŲő¨ĪŪ√Ľ”–÷ĪŔѨŔĶĹ ¬ ĶĪŪ…Ō£¨∂Ý «Õ®Ļż∆šňŻő¨ĪŪѨŔĶĹ ¬ ĶĪŪ…Ō Ī£¨∆šÕľĹ‚ĺÕŌŮ∂ŗłŲ—©Ľ®Ń¨Ĺ”‘ŕ“Ľ∆ū£¨Ļ ≥∆—©Ľ®ń£–Õ°£—©Ľ®ń£–Õ «∂‘–«–Õń£–ÕĶńņ©’Ļ°£ňŁ∂‘–«–Õń£–ÕĶńő¨ĪŪĹÝ“Ľ≤Ĺ≤„īőĽĮ£¨‘≠”–Ķńłųő¨ĪŪŅ…ń‹ĪĽņ©’Ļő™–°Ķń ¬ ĶĪŪ£¨–ő≥…“Ľ–©ĺ÷≤ŅĶń
"≤„īő " «Ý”Ú£¨’‚–©ĪĽ∑÷Ĺ‚ĶńĪŪ∂ľŃ¨Ĺ”ĶĹ÷ųő¨∂»ĪŪ∂Ý≤Ľ « ¬ ĶĪŪ°£—©Ľ®ń£–ÕłŁľ”∑ŻļŌ żĺ›Ņ‚∑∂ Ĺ£¨ľű…Ŕ żĺ›»Ŗ”ŗ£¨Ķę «‘ŕ∑÷őŲ żĺ›Ķń ĪļÚ£¨≤Ŕ◊ųĪ»ĹŌłī‘”£¨–Ť“™
join ĶńĪŪĪ»ĹŌ∂ŗňý“‘∆š–‘ń‹≤Ę≤Ľ“Ľ∂®Ī»–«–Õń£–ÕłŖ°£

—©Ľ®ń£–Õ“‘ ¬ ĶĪŪő™÷––ń£¨÷‹őßŅ…“‘”–ļ‹∂ŗő¨∂»£¨ő¨∂»Ō¬√śŅ…“‘”–◊”ő¨∂»
4°Ę–«–Õ”Ž—©Ľ®ń£–Õ∂‘Ī»
| |
≤ť—ĮňŔ∂» |
ņ©’Ļ–‘ |
»Ŗ”ŗ∂» |
∂‘ ¬ ĶĪŪĶń«ťŅŲ |
ĪŪłŲ ż |
| –«–Õń£–Õ |
Ņž(“Ľį„2’ŇĪŪjoin) |
ņ©’Ļ–‘Ī»ĹŌ»ű |
łŖ |
ĶÕ |
…Ŕ |
| —©Ľ®ń£–Õ |
Ņž(“Ľį„2’ŇĪŪjoin) |
ņ©’Ļ–‘Ī»ĹŌ»ű |
łŖ |
ĶÕ |
…Ŕ |
5°Ęő¨∂»Ĺ®ń£≤‚ ‘įłņż
“ĶőŮ–Ť«ů£ļłŖ≤„ŃžĶľŌŽŅī≤ĽÕ¨Ķō«Ý°Ę≤ĽÕ¨ Īľš°Ę≤ĽÕ¨≤Ņ√Ň°Ę≤ĽÕ¨≤ķ∆∑ĶńŌķ Ř żŃŅ°ĘŌķ ŘĹū∂ÓļÕ∆ĹĺýŌķ ŘĹū∂Ó£Ņ
ŠņŪő¨∂»ļÕ÷łĪÍ
ő¨∂»įŁņ®£ļ
Ķō«Ý
Īľš£®√ŅŐž°Ę√Ņ÷‹°Ę√Ņ‘¬£©
Īľš «yyyy-mm-DD HH:mm:ss
ĽýĪĺő¨∂»£ļyyyy-mm-DD HH:mm:ss
—‹…ķő¨∂»£ļday°Ęweek°Ęmonth°Ęquarter°Ęyear
≤Ņ√Ň
≤ķ∆∑
÷łĪÍįŁņ®£ļ
Ľýī°÷łĪÍ
Ōķ Ř żŃŅ°ĘŌķ ŘĹū∂Ó
—‹…ķ÷łĪÍ
∆ĹĺýŌķ ŘĹū∂Ó
“ĶőŮŌĶÕ≥ņÔ√ś”–“Ľ’ŇŌķ ŘĪŪ£ļ
| saler_id |
productName |
date |
amount |
price |
city |
| 001 |
P30 |
2019-09-05
20:05:30 |
1 |
3000 |
ĪĪĺ© |
≤ķ∆∑ő¨∂»£ļ
| productId |
productName |
| s001 |
iphoneX |
| s002 |
P30 |
| s003 |
MI8 |
| s004 |
R20 |
Īľšő¨∂»£ļ
| date |
day |
week |
month |
quarter |
year |
| 2019-09-05
20:05:30 |
20190905 |
36 |
201909 |
3 |
2019 |
Ķō«Ýő¨∂»£ļ
| area_id |
cityName |
| 010 |
ĪĪĺ© |
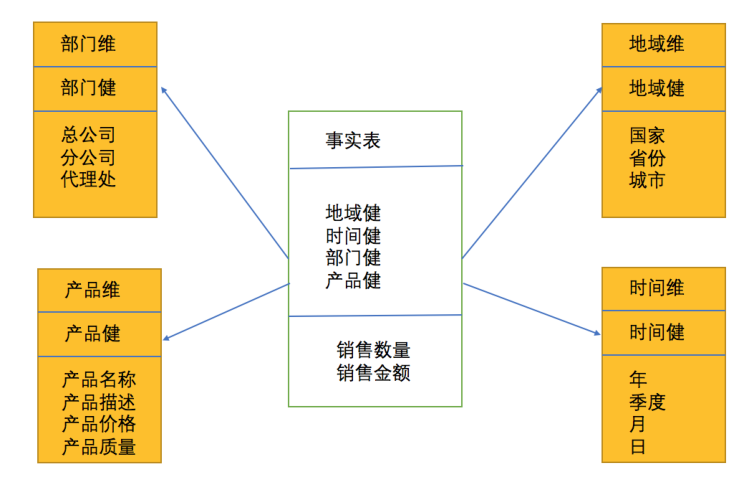
īīĹ® ¬ ĶĪŪ£®fact£©£ļ
| saler_id |
productId |
date |
area_id |
count |
price |
| 01 |
P30 |
2019-09-05
|
010 |
1000 |
3000 |

∑÷őŲ÷łĪÍ£ļ
select p.productName,sum(price) from
fact f join product p on f.productId = p.productId
group by p.productName;
őŚ°Ę3NFĹ®ń£”Žő¨∂»Ĺ®ń£Ķń«ÝĪū
“ĶőŮ≥°ĺį£ļīůľ“»•≥¨ –¬Ú∂ęőų£¨ł∂ÕÍ«ģĽŠłÝń„“Ľ’ŇĻļőÔ√ųŌł£¨Õ¨—ß√«ŌŽ“ĽŌ¬£¨’‚’ŇĻļőÔ√ųŌł∑÷Īū”√3NFĹ®ń£ļÕő¨∂»Ĺ®ń££¨‘ű√ī◊Ų£Ņ
3NFĹ®ń£»ÁŌ¬£ļ

ő¨∂»Ĺ®ń£»ÁŌ¬£ļ

Ńý°Ę÷łĪÍļÕő¨∂»Ĺ®ń£≤Ĺ÷Ť
1°Ę“ĶőŮ–Ť«ů◊™ĽĮő™ żĺ›Ĺ”Ņŕ
2°Ęő¨∂» ŠņŪ
3°Ę÷łĪÍ ŠņŪļÕ»∑»Ō
÷łĪÍ∑÷ņŗ£ļ
Ņ…ľ”£ļ»ÁĹū∂Ó°Ę żŃŅĶ»
≤ĽŅ…ľ”£ļ»Á’ŘŅŘ°ĘĽ„¬ Ķ»
4°Ę“Ľ÷¬–‘∑÷őŲĺō’ů
| ő¨∂»\÷łĪÍ |
Ōķ ŘŃŅ |
Ōķ ŘĹū∂Ó |
∆ĹĺýŌķ ŘĹū∂Ó |
| »’∆ŕ |
|
|
°Ő |
| Īľš |
°Ő |
|
|
| Ķō«Ý |
|
°Ő
|
|
| »’∆ŕ |
°Ő |
|
|
| 







