| 编辑推荐: |
本文简单介绍一下2PC(二阶段提交)算法,它被提出以使基于分布式系统架构下的所有节点在进行事务提交时保持ACID原则。
本文来自csdn,由火龙果软件Alice编辑、推荐。 |
|
1. 理论
1)ACID特性
在介绍CAP原则之前,我们首先来看一个大家比较熟悉的概念:ACID。它是指在数据库管理系统中为了保证事务的准确可靠所具备的四个特性,分别是:
Atomciity(原子性):一个事务中的所有操作,或者全部完成,或者全部不完成,不会结束在中间某个环节。
Consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。
Isolation(隔离性):多个事务并发访问时,事务之间是隔离的,一个事务不应该影响其它事务运行效果。
Durability(持久性):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
这是本地事务(单机)需要具备的特性,但是随着互联网高速发展,性能要求、业务复杂度的提升,我们可能会对数据库进行分区,分区之后不同库会处于不同的服务器上,产生了分布式事务。如果对分布式事务也追求满足ACID特性,可能就会遇到很大的挫折。
这里我们简单介绍一下2PC(二阶段提交)算法,它被提出以使基于分布式系统架构下的所有节点在进行事务提交时保持ACID原则。
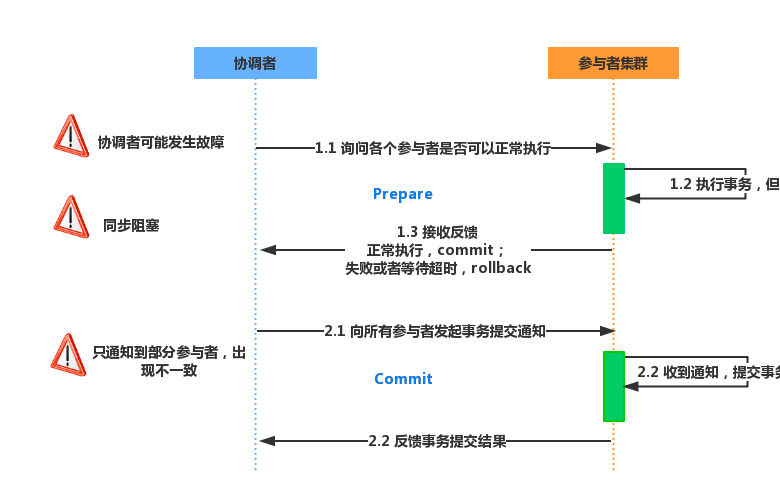
图片出处
参与者可视为集群中的数据库。当协调者收到来自客户端的操作请求时,它将首先向所有参与者发送问询,确认是否可以执行提交的操作。在受到全部参与者的确认后才会正式提交请求。当第一阶段内收到某一个参与者的拒绝或者无回应,则协调者会向所有参与者发送“回滚操作”的请求,以此来保证事务的原子性,也保证了一致性。参与者在整一个过程中为了保证事务的隔离性,都始终处于阻塞状态,根据隔离等级会拒绝其他的请求。
同步阻塞:各个参与者在等待其他参与者响应的过程中,将无法进行其他任何操作,性能较低
单点问题:协调者只有1个,一旦出现问题,整个协议无法运转
太过保守:任何一个参与者出现问题,都会发生回滚
从中我们可以看出,2PC算法为了保证ACID特性,在很大程度上牺牲了效率和性能。由此看来,数据的一致性和系统服务的可用性,似乎是不可兼得的,是这样吗?
2)CAP定理
2000年,加州大学柏克莱分校的计算机科学家埃里克·布鲁尔在当年的分布式计算原理研讨会(PODC)上提出的一个猜想:任何一个分布式系统都不可能同时满足以下三点:
一致性(Consistency):所有节点访问同一份最新的数据副本。
可用性(Availability):对于非故障节点,每次请求都能获取到非错的响应——但是不保证获取的数据为最新数据。
分区容错性(Partition tolerance):当节点间出现任意数量的消息丢失或高延迟的时候,系统任然能对外提供一致性和可用性的服务。以实际效果而言,分区相当于通信的时限要求。系统如果不能在一定实现内达成数据一致性,也就意味着发生了分区的情况。
简单翻译一下,就是一个分布式系统不能同时对客户端实现以下三条承诺:
不管你访问哪个节点,要么读到的都是同一份最新写入的数据,要么读取失败。
我尽力给你返回数据,不会不响应你,但是我不保证每个节点给你的数据都是最新的。
不管我的内部出现什么样的数据同步问题,我会一直运行。
后来在2002年,该猜想被麻省理工学院(MIT)的赛斯·吉尔伯特和南希·林奇发文证明,真正成为一个定理。
那么我们该怎么理解CAP定理呢?为什么3个特性不能被同时满足呢?这里面有一个很重要的前提,那就是“分布式系统”,只要是分布式系统就必须要满足分区容错性P。我认为相较与CA,P实际上更像是一个对于分布式系统的描述而非一个可选项。P可以说是简单的,也是难理解的。说简单因为分布式系统必然满足它,说难理解也是真的,什么叫网络分区,什么叫分区发生时还能提供服务?追求满足一致性时,系统不是也不能提供服务吗?为什么也叫满足了P?
说一说我的理解,从集群中某一个节点的视角来看,它搞不清楚一次内部通信的timeout是因为高延迟、分区(路由器、交换机故障)还是目标机器故障。而所谓分区容错,就是指在一次内部通信timeout发生之后,此节点选择如何回应客户端。由于某个节点无法认清真实情况,所以机器故障也可认为是分区的一种。那么该属性就可以重新解释为“当某些节点宕机时,整个集群是否还有能力提供服务”。若是单点系统,肯定不行,所以说单点系统满足不了P。对于多节点的分布式系统,则系统应该被设计为可以满足P的,只挂掉一个节点的情况下其他节点应该要继续提供服务(而不是表现得像一个单点系统那样完全无法服务)。在内部通信timeout时选择一致性,那么就应该继续不停重发消息而非直接放弃,虽然对于客户端来说结果并没有多大差别,可到底是一直努力重连还是直接平躺放弃,就是C和P的区别。单点系统可以平躺放弃,若一个分布式系统也如此,那么它就没必要被设计出来。
那在确认了P必须被满足的前提下,CA特性能否兼得呢?也就是回归到我们前面提到的问题,一致性和系统的可用性能否兼得,答案是两者不可能被百分百满足。
原因很简单,在集群发生分区时,不同区域内的节点是否还被允许对外提供服务?若仍然可以提供服务,那么由于内部分区,其内部状态极有可能不再一致,C不能满足。若不再提供服务,那么一致性虽然可以被满足,那可用性A就不满足了。所以这是一个两难的问题。
但是值得注意的是,这并非是0和1的问题,而是一个取舍程度的问题。我们想要的分布式系统不可能完全抛弃C或A(完全抛弃C或P的系统是没有意义的),相反,网络分区的情况虽然不可避免但它并非是常态,在网络正常的情况下CA特性的同时满足也是我们追求的目标。
总结一下CAP理论给我们的启示,分布式系统应该尽量保持其一致性C和可用性A,但当网络分区发生时,势必要舍弃一部分A或P以保证系统能够正常运作。根据取舍的不同,分布式系统的设计基本可以被分为CP型和AP型。上面介绍到的2PC算法就是为极致的C型分布式系统服务的。考虑KV存储的话,CP模型适合提供基础服务保存少量的重要数据,读写频率不会特别高,AP型适合查询量较大的场景。设计分布式系统时选取两模型的最重要依据是能否容忍短暂的一致性延迟。
此外,对于一个复杂系统来说,它可能同时需要满足多项业务要求,它的数据服务可能是强一致的CP型,它的内部健康状态检查则可能需要追求极高的可用性而对一致性延迟容忍度较高。因此,某个系统到底是CP还是AP也不能一概而论。
3)BASE理论
BASE理论是由eBay架构师提出的。BASE是对CAP中一致性和可用性权衡的结果,其来源于对大规模互联网分布式系统实践的总结,是基于CAP定律逐步演化而来。它的内容如下:
基本可用(Basically Available)
软状态(Soft-state)
最终一致性(Eventually Consistency)
其核心思想是:在无法做到强一致性(会舍弃大部可用性)的情况下,应该根据每个应用自身的业务特点,采用适当的方法使系统达到最终一致性,而整个过程中又可以满足系统的基本可用。
那么什么是基本可用呢?即是说当系统出现了故障时(如出现分区),应该保证其能够继续对外提供服务,但相较于正常的系统,它被允许出现一些功能上的、响应时间上的缺失。例如,充值延迟显示、购物库存延迟展示、提高响应延迟、上线排队等待机制等。
那么什么是最终一致性呢?
4)一致性
所谓一致性(指数据一致,非事务的一致性),绝非指物理上的一致,而是逻辑上的一致。由于光速、硬件读写的限制,我们肯定无法要求不同地点的两个服务器时时刻刻保持一份相同的数据。一致性指的是集群作为一个整体,能像单点系统一样为外界提供一份唯一的最新的数据视图。
假若你的系统中不同节点的数据同步进度相差万里,但却能保证多个客户端不论向哪几个节点同时发起读请求(来自外部的读请求是验证系统一致性的有效手段),都能通过内部的某些算法保证时时提供一份唯一的最新数据副本,那你既然有此本事也可以称你实现的系统具备强一致性,哪怕它们的数据在物理上千差万别。
现实中,一致性有下面几种级别:
强一致性:更新操作完成后,任何后续访问请求都会获得最新的更新后的值。这种实现需要牺牲可用性。分为顺序一致Sequential
Consistency和线性一致Linearizability Consistency
顺序一致or线性一致
Paxos 协议作者Lamport 在 1979 年首次提出顺序一致的概念。
“the result of any execution is the same as if the
operations of all the processors were executed in
some sequential order, and the operations of each
individual processor appear in this sequence in the
order specified by its program.”
"任意一种可能的执行的结果和某一种所有的处理器的操作按照顺序排列执行的结果是一样的,并且每个独立的处理器的操作都会按照程序指定的顺序出现在操作队列中。"

上图展示了三种情况,分别对应:顺序一致、线性一致和非顺序一致的情况。我们先看第一种情况,以我们的上帝视角观察,能明显发现系统出错,在P1成功写下x=4后,P2仍然读到了x=0(初始值)。但是站在P1、P2的视角,他们可能觉得顺序是这样的:W(y,
2)-->R(x, 0)-->W(x, 4)-->R(y, 2),两人都不会觉得系统有何异常。
情况二是正确是执行结果,称之为线性一致,也是真正的强一致。情况三中,P1和P2都无法正确解释结果对于P2,它认为P1既然读到y=0,则该读操作肯定发送在自己的W(y,
2)前面,但自己却读不到更前的W(x, 4),矛盾。对于P1也是一样。
顺序一致的重点是在保证按某个客户端的提交顺序执行命令的同时,整个系统对命令执行顺序也能有合理解释。
弱一致性:更新操作完成后,后续的访问请求并不会被承诺一定能读取到最新的值,也不会具体承诺多久后可以获得。
最终一致性:是弱一致的一种特殊形式,系统保证在没有新的更新的情况下,最终所有访问都能得到最新的值(和弱一致的区别在于,即使没有新的更新,弱一致也不能保证,它只会在一个受网络、机器性能影响的“不一致窗口期”之后一致,也就说不准)
因果一致性(Casual Consistency):如果进程A通知进程B它已更新了一个数据项,那么进程B的后续访问将返回更新后的值,且一次写入将保证取代前一次写入。无因果关系的进程无此保证。
读己之所写(read-your-writes):当进程A自己更新一个数据项之后,它总是访问到更新过的值,绝不会看到旧值。这是因果一致性模型的一个特例。
会话(Session)一致性:这是上一个模型的实用版本,它把访问存储系统的进程放到会话的上下文中。只要会话还存在,系统就保证“读己之所写”一致性。
单调(Monotonic)读一致性:如果进程已经看到过数据对象的某个值,那么任何后续访问都不会返回在那个值之前的值。
单调写一致性:系统保证来自同一个进程的写操作顺序执行。要是系统不能保证这种程度的一致性,就非常难以编程了。
5)共识算法
什么是共识算法,实际上指的是集群中所有节点彼此间进行协调来确定所有相关进程的下一个操作的动态过程。一个正确的共识算法应该具备:
协定性(Agreement):所有正确进程(节点)决定相同的值。
终止性(Termination):所有正确进程最后都能完成决定。
完备性(Integrity):如果正确的进程都提议同一个值,那么所有正确进程最终决定该值。
我们借助(consensus)共识算法解决(consistency)一致性问题。
上面的关于一致性的讨论,是基于一个分布式系统的。我们知道分布式系统中的每台机器上提供的服务、拥有的工作模块、逻辑等都可能是十分复杂的(基于需求),它可能拥有传输模块、存储模块、调度模块等等。而共识算法,被作为一个实现一致性需求的模块(暂称为协议层/协议模块/共识模块),被加入到集群的每个节点上。如etcd是一个应用,它使用raft算法保证一致性。
当集群接收到一个客户端的请求,如果没有协议层,也就是说每个节点单独处理get/set/delete请求,那么集群的一致性大概率是不能保证的。我们需要专门使用一个共识算法来处理一致性问题,因此共识算法是没有所谓强一致、弱一致的区别的,它被引入就是为了实现强一致(强弱一致、可用性是分布式系统层面的概念)。
当一个请求被提交给协议层(共识算法)去处理,我们就称它为一个提案,协议层负责在集群间对此提案形成一个共识,也就是集群对这个提案的结果(丢弃、接受)有了一个确定的、统一的结论,则协议层使命已达到。当协议层使命达成时,整个分布式系统状态一致了吗?未必,存储模块是否正确接受并执行了提案?假若集群的协议层完美达成了共识(如何才算达成共识?),但某一个节点未能将此决议写入数据库而它又被客户端发起读请求,那么客户端就会发现这个系统的数据仍然是不一致的。
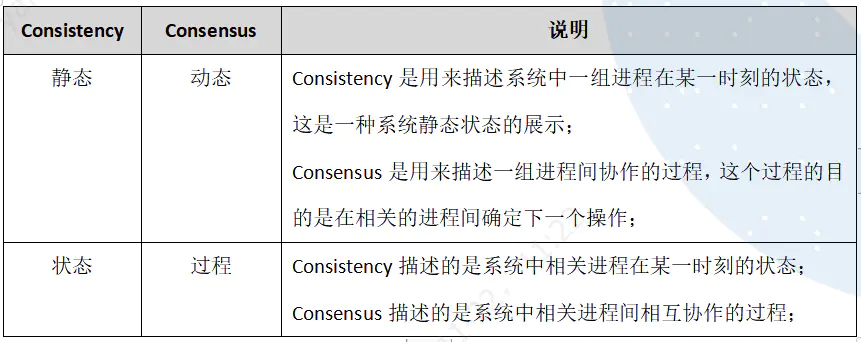
(共识和一致的区别--- 图片出处)
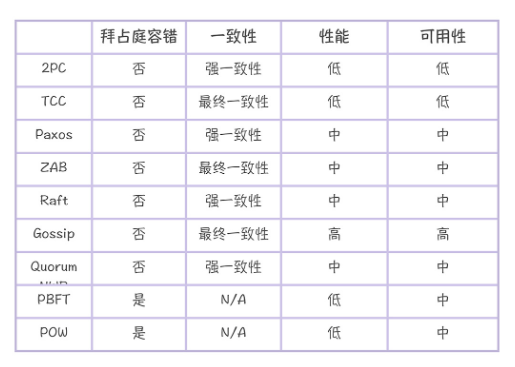
所以我们说,共识算法被用来帮助系统达成一致性,实际上也啃下了最难啃的骨头,之后的其余处理方式可由应用(业务)层自行决定。也就是说,共识算法负责形成共识,但共识形成和系统状态一致之间可能存在延迟,期间如何处理交由应用层决定。当然,共识算法需要为应用层可能做出的决定提供支持。下表列举了一些共识算法的相关特性,其中的”一致性“一列,实际上显示了该算法最高能够支持使用它的分布式系统达到哪一种一致性等级。
Raft能够支持强一致,倘若你为了追求性能,用它实现了弱一致的系统,也是可以的。(那一开始何必用Raft呢?)
FLP 不可能原理
”在网络可靠,但允许节点失效(即便只有一个)的最小化异步模型系统中,不存在一个可以解决一致性问题的确定性共识算法。”
该原理告诉我们,不要浪费时间,去试图为异步分布式系统设计面向任意场景的共识算法。但是,我们可以使用工程手段,将错误发生情况降到最低。也就是说,你不该期待你所使用的共识算法每次都能成功达成共识,所以你的应用层也应该为此出一份力。
2. Raft共识算法
raft算法是对Paxos算法的简化设计和优化,毕竟世界上只有一种共识算法,那就是Paxos。但是该算法以复杂难以理解和难以实现闻名,Raft算法的提出者也说了他们花了很长时间来理解Paxos,觉得过于复杂所以才研究出了Raft算法。
名字由来
Raft 不是某几个单词首字母的缩写,但可以联想到:reliable(可靠的),replicated(可复制的),redundant(冗余的)和
fault-toleran (容错的);
logs(算法中意为 “日志”,英文还有一个意思是 “原木”),Raft在英语中有“筏”的意思,将原木(logs)组合起来构成筏子(raft);
把 Paxos 想象成了一个岛,并谋划着怎么逃离这个岛;
Raft共识算法与分布式系统的一致性的关系
在Raft算法中,作者将一致性问题看成系统中进程间(在不同机器上)一个状态机同步问题,为保证每个机器上的进程具有一致性(即状态改变的过程一样,以此保证数据的一致),作者使用了Raft这个共识算法来保证在每个进程初始状态相同的情况下,每个进程的下一个操作(状态改变操作)相同,这样就能保证所有进程的状态机的改变过程是一样的,即系统中的进程最终会达成(数据)一致状态。
而日志(log)就是raft共识算法对对每个操作(提案)的一种建模。日志在集群中的复制过程,就是共识形成的过程。

在这一部分,我会按照Raft论文中的顺序,依次介绍领导人选举、日志复制和成员变更三个部分的内容。
首先,Raft算法中各个节点有角色的区别,其中最为重要的一个身份是Leader,负责整个集群状态的同步和对外部事件的处理,那么如何从集群中选举出一个leader,同时还要保证其唯一性和权威性就是一个很关键的问题。
第二,前面说过,Raft将来自集群外部的客户端请求称之为一条提案proposal,提案在被提交commit之前是不稳定的,需要Raft来让整个集群来决定,产生共识,确定是提交该提案还是抛弃它,此过程中该提案会被打包成为一条日志项log
entry,在集群之间传播。在确定可以提交该log entry之后,会将其送入每个节点内部的状态机,成为一个无法被改变的事实。如何让集群对一个提案产生共识,就是第二部分“日志复制”会介绍的问题。
最后,我们会介绍一下集群成员置变更的问题,也就是加入或删除成员对整个集群的影响以及处理方式。
1)领导人选举
在Raft集群中,每一个节点任意时刻都处于以下三个状态之一:
leader 领导者
follower 跟随者
candidate 候选者
正常状态下,集群中只有一个leader,其余全部都是follower。follower是被动的,它们不会主动发出消息,只是响应leader或candidate的消息,或者转发客户端的请求给leader。candidate是一种临时的状态。
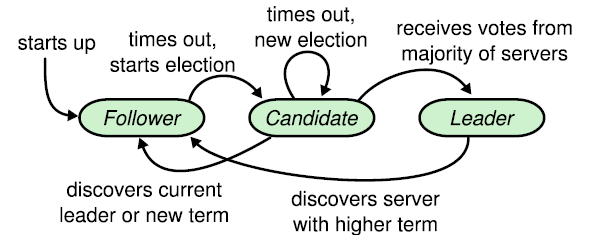
每个节点在加入集群的时候都会初始化为follower,而当前集群没有leader的时候,follower会进行选举试图成为leader,首先他们会将自己的状态转变为candidate,然后向集群内的其他成员发起投票请求,若该candidate收到了大多数人的赞成票,那么它就会变成leader,然后在集群内广播心跳消息,接到心跳消息的follower或其他candidate就会认识到此时已有leader,会停止自己的竞选行为而重新变为follower,稳定的集群状态就形成了。
当然,上面这段叙述可以提出很多很多问题:
a. follower怎么知道何时应该发起竞选?
答:每个节点内部都有一个被称之为选举时停electionTime的属性,当在此时间段内,没有收到来自leader的心跳消息,就可以认为当前没有leader存在,可以发起竞选。
b. 什么是心跳消息,怎么发送?
答:leader内部有一个称之为心跳时停heartbeatTimeout的属性,定时向集群内部的其他节点发送心跳,以确定他们的活跃状态,并抑制其竞选(还可用于同步日志的提交情况)。
c. 成为candidate需要进行什么操作?
答:实际上有两个至关重要的概念,那就是任期Term和日志序号Index。任期Term是一个全局可见递增的数字(几乎每个在集群间传播的消息都会携带者发送者所属的Term),它表示一个Leader发挥其影响力的一段时期的序号。Term的增加发生在一个follower成为candidate时,一个follower长时间未收到leader的心跳,它就认为新的时代要到来了,因此它自增此Term,成为候选者发起竞选,同时将此更新后的Term发送给其他节点以彰显自己的竞选资格。日志序号Index也会被一并发送,炫耀自己的工作能力以期获得选票。

d. follower依据什么向candidate投赞成票?
答:投票的原则是先来先投票,在一个Term内只能投一次赞成票,如若下一个来请求投票的candidat的Term更大,那么投票者会重置自己的Term为最新然后重新投票。节点不会向Term小于自身的节点投赞成票,同时日志Index小于自己的也不会赞成,Term小于自身的消息可能来自新加入的节点,或者那些因为网络延迟而导致自身状态落后于集群的节点,这些节点自然无资格获得赞成票。
e. 若选票被瓜分,无人能够获得大多数人的赞成票,会怎么样?
答:candidate的选举活动有一个最大时限,超过该时限他还没有成功胜出,就会被宣布为失败,重新变为follower然后重新开始选举时停的计时。为了保证选票瓜分的情况不会频繁出现,每一个节点的选举时停都是随机的。
经过上面这些流程的限制,对于领导人的选举,Raft做出了如下的保证:
"对于一个给定的任期号,最多只有一个领导人会被选举出来"
对于同一个任期号,每个成员只投票给一个候选者,而且候选者必须得到超过半数的赞成票才会成为Leader,那么就必然只有一个leader会在一轮选举中获胜。(挖个坑,不是必然,当集群成员发生变更时,对于“大多数”的概念不同的成员可能有不同的理解,可能导致两个leader的出现。后面会介绍)
现在我们总结一下选举流程:
follower长时间未收到来自leader的心跳消息,触发选举时停,转变为candidate,将Term加一,然后将新Term和自身的最新日志序号进行广播以期获取选票。
其他收到投票请求的节点先过滤掉Term小于自己的请求,然后判断1.自己是否已投票;2.是否认为现在有leader;3.该投票请求的日志index是否大于自己。若判断全通过则投赞成票。
收到过半数节点的赞成票的candidate将转变成为leader,开始定时发送心跳消息抑制其他节点的选举行为。
投票条件被用来保证leader选举的正确性(唯一),随机的选举时停则被用来保证选举的效率,因为集群处于选举状态时是无法对外提供服务的,应当尽量缩短该状态的持续时间,尽量减小竞选失败发生的概率。
2) 日志复制
leader产生了,假设现在是一个处于正常状态下的系统。它要怎么向外界提供服务呢?
我们以简单的KV数据库系统为例,当客户端向集群发送一条写请求时,Raft规定只有leader有权处理该请求,如果时follower收到该请求则会转发给leader。(如果时candidate则会直接拒绝该请求,因为它认为当前系统不是正常的可提供服务状态)
leader会将每一个收到的来自客户端的请求(提案),包装为一个记录Entry存入log库中,每个entry会有一个全局递增的下标index。注意,此时的entry处于一个未被形成共识的状态,因此它是不稳定的。leader将向整个集群发出复制消息,试图就此达成共识。最简单的情况下,leader向集群发出AppendEntry消息,即将entry同步过去,若收到集群中大多数节点的确认回应,则说明共识达成,可以向客户端返回ok的标志。注意,此时只有leader知道该entry已经被达成共识,确认可以被提交了。那么leader就需要通知集群中的其他节点该entry可被提交,其他节点收到消息后,将该写命令真正在kv数据库中执行,同时log也会被持久化存储。
乍一看,这个流程和2PC及其相似,都是有一个类似于预提交(问询),然后收到确认回复后再向集群发送正式提交请求的过程,无非就是从2PC的全部确认改成了大多数确认?
实际上并非如此。我们观察一条来自客户端的请求的生命周期,可以总结出如下四个阶段。
提案阶段:是一个初始阶段,当leader收到来自客户端的一条请求后,会将请求打包成为一个entry,该entry便处于此阶段。它是不稳定的,也就是说集群没有办法保证此entry会被集群接受还是抛弃(网络、机器原因),需要raft共识算法发挥其作用来确定。
达成共识阶段/可提交阶段:一旦某一entry被集群内大多数节点所持有,该entry就已经处于达成共识阶段,它已经能够确定将会被集群接受(提交),但具体何时写入状态机,外部客户端何时能够验证此命令已经生效,则是没有办法保证的(网络延迟、机器故障都会影响)这是一个基于上帝视角观测到的状态(代码实现无法判断此状态)。或者称之为“可提交阶段”,为了与“被提交阶段”对比明显,下面仍然称之为“达成共识阶段”。
被提交阶段:可认为是显式的达成共识阶段。当leader意识到某一个entry已经进入了达成共识阶段,则leader将会将它标记为被提交状态。并将此信息广播给集群中的其他节点声明该entry已经被集群接受,可以将其应用进状态机了。需要注意的是,每个节点对于哪些entry是被提交的可能存在认知上的不同步(但绝不会冲突),我们这里认为当leader标记其已被提交,那么该entry就进入了被提交阶段。
被应用状态:当集群中的任意节点意识到某一个entry已经被标记为已提交,而且自身也持有这个entry,就会将其应用进状态机,对于KV数据库可能是写、删除操作等,此时一个请求才真正被完成,可以被外部验证其已被执行。
在一个网络通信正常、机器无故障的集群中,每一个请求都可以顺利走完上面的四个阶段。但真实情况下,其中每个阶段的衔接都有可能出现问题,导致系统处于某种不那么“协调”的状态。
提案状态--达成共识:无法顺利进入达成共识的状态可能是leader在接收到一条来自客户端的请求后,将其打包为entry但还没有广播出去就宕机或由于网络原因数据包在网络中丢失,一直无法被大多数节点接收到。则该请求会一直处于提案状态。我们说过提案状态是一个不稳定的状态,它可能最终被系统确认接受也可能会被丢弃。对于集群来说两种情况都是可以接受的(在发生机器宕机、网络不可用的情况下),因为处于此状态的提案不会对系统造成任何一致性方面的影响。对于发出该请求的客户端,这种情况下它收到的反馈应该是Timeout,也就是请求超时。那么我们认为,客户端对此次请求的结果不应该做任何预期,它可以选择重发请求(前提是幂等),但不能假设之前的请求已成功或失败。
达成共识--被提交:假设这样一种情况,由于网络原因leader可以发送给follower消息但却无法接收到回复,由于被提交状态commit是由leader拍板确认的,所以leader迟迟无法得知一个entry已进入达成共识阶段,也就迟迟无法将其标记为被提交(集群中其他节点自然也不知道),即使从上帝视角我们知道它已被大多数follower接收。我们断言,只要系统以后还能恢复正常功能,那么这些处于达成共识阶段的entry就一定会被提交,但具体是何时无法保证。
被提交--被应用状态:其实一个entry被标记为被提交并送入状态机,那么raft作为一个共识算法的使命就算完成了,状态机(KV数据库)是否能够操作成功应该是由更上层的应用进行保证的。当然,raft为了提供线性一致性的功能,也会关注一个entry是否真的已被状态机执行,但这个先不讨论,后面就先假设被提交和被应用是无缝衔接的。也就是说,当一个entry已被提交,就认为它已经可以被外部观察到此命令的执行结果。但是,这并不意味着集群内所有的节点都已提交该entry(执行该命令),因为commit状态是由leader确认的,其余节点得知此信息可能会有延迟,但并不影响raft集群对外的一致性。
现在我们知道了处于各个状态下的entry能得到的保证,但是可能对其中的种种断言、保证存在很大的疑惑。没关系,我们通过一个具体的例子来演示一下:
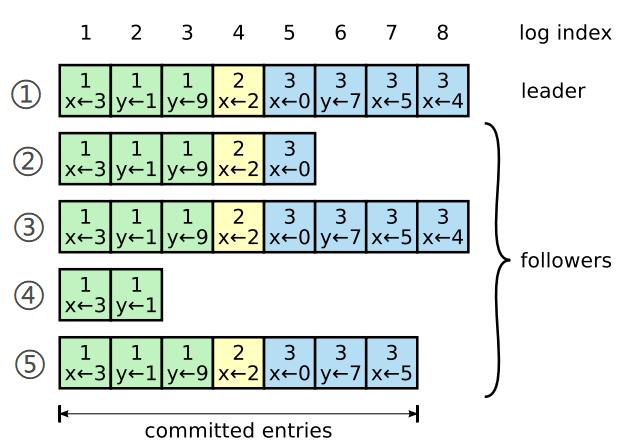
首先理解一下这张图中的情况:leader是1号节点,它在日志复制过程中显然是因为网络延迟或其他原因,导致其他follower的日志情况各不相同。我们可以试着判断一下这些日志分别属于哪个阶段?
8号entry属于提案阶段,因为它并未被大多数节点所持有(2/5)。剩下的其余日志都 至少处于共识达成阶段。那么是否处于被提交阶段呢(也就是说leader是否知道大多数节点已持有它们呢)?起码我们能判断绿色黄色的日志(Term1、2)都是极有可能被提交了的。因为既然Term3能够选举出leader,说明起码选举时大多数节点是可以互相通信的,一旦完成可互相通信且选出leader,那么之前的已达成共识阶段的日志就都会被标记为已提交。因为选举成功之后,新leader会立即广播一条空提案,试图借此复制之前的所有日志到follower中,以期获得回应,获得回应后肯定可以提交它们(以达成共识)。由此图中的日志5的复制情况来看,前面的日志确实是已经被提交了的。
对于Term3的日志我们只能确定8号是提案状态,其余是达成共识状态,是否已提交不可确定(当然,leader肯定是知道它们是否被提交的)。
现在我们假设节点1此时发生故障重启,由leader变成follower,此时五个节点开始试图发起竞选。那么哪些节点有资格竞选成功呢?考虑到投赞成票的条件之一是日志需要和投票者相同或者更加新,所以我们就可以确定2、4号节点是不可能赢得选举(当然4号节点有Term落后的原因),那么1、3、5号节点都有可能胜出,假设5号节点抢先一步获得了2、4节点的选票,那么它将成为leader,我们可以看到成为leader的必要条件不是拥有最新的日志,而是要拥有最新的共识达成阶段的日志。
那么此后8号entry的结果会如何呢?这个卡在提案阶段的日志会被丢弃掉。因为它与leader上的日志发生冲突,因此拥有绝对权威的leader会将follower上的不同步日志清除。
假如是1或3节点抢先一步赢得了选举呢?那么8号entry就会被保存下来,尝试进入下一达成共识状态。因此处于提案阶段的日志其结果是不可预料的,但是其结果是都可被接受的(因为客户端对于timeout请求不会做任何预期)。
转过头来看其他的日志,无论是哪个有资格的候选人当选(1、3、5),已达成共识的日志(5~7)都会被保留下来,然后在新leader的后续工作过程中,leader会意识到大多数节点已拥有了这些entry,就会将它们标记为可被提交状态,进入下一个阶段。
我们可以看到,5~7号entry(共识达成状态)无论在此之前是否已被前任leader标记为已提交,它们都会在以后集群正常工作时被提交。这一切都得源于选举机制和投票条件,它们给予我们一个保证:
“Leader必然持有最新的‘达成共识’状态的日志”
除此之外,raft还保证了“leader不会删除或覆盖自己的日志,只可能会追加”。这一条保证是因为,新leader无法确定自己所持有的日志,哪一些是在前一个leader的任期内达成共识,但却未被提交的。(当然,已提交的也不能随便删除,集群中可能有follower落后于leader需要同步进度,新加入的节点与需要同步。)但是,日志的压缩是可以的(后面补充)。正是基于这些保证,我们才能断言处于达成共识状态的entry,在集群正常工作后一定会被leader提交。而进入被提交状态相当于一个最终确认,使得该命令可以被外部验证已执行。
讨论:Leader权力(权威性)从何而来?
投票规则,除了限制每个Term只有可能选出一个Leader外,还保证了选举出来的Leader必定是可接受的,具有代表性的。是否可接受是基于其日志与集群平均水平的对比。成为leader,代表着认为某个节点它拥有的日志足以代表整个集群,再多一些自然更好,但是不能再少了。
而leader的权力,并不来源于这个头衔,不是君权神授,恰恰相反,权力来自于人民,群众选举出来的leader代表着集群的集体意志,只要他不是卧底(非拜占庭问题),承诺绝不修改已达成的共识,那么它就能够代表集群,清除其他节点上一些不和谐的日志。
并且我们规定,处理请求发起提案,提交提案,包括广播提案已被提交的信号,都是由leader率先处理的,合法的leader的信息始终是集群中最新的信息,其状态始终是最新的状态,这也是其权威性的保障。
日志的连续性
raft的原则之一,就是如果两个不同节点上相同序号的日志,只要term相同,那么这两条日志必然相同,且这和这之前的日志必然也相同的。同时Raft协议中日志的提交也是连续的,一条日志被提交,代表这条日志之前所有的日志都已被提交,一条日志可以被提交,代表之前所有的日志都可以被提交。日志的连续性使得Raft协议中,知道一个节点的日志情况非常简单,只需要获取它最后一条日志的序号和term。
该原则不难理解,正是由于只有leader能接受提案、决定日志的提交顺序,并且承诺不会覆盖或修改已有的日志,最后还确保当选的leader肯定持有最新的达成共识状态的日志,使得日志的连续性可以被自然推断出来。这一原则使得leader和follower同步日志时,比对日志同步进度的了解非常的快速和方便。日志的连续性对于后面要提到的“只读请求”的处理也能带来帮助。
3)安全性
上文已经在不同的地方解释了raft论文中关于安全性的问题,这里做一个总结:
选举安全:在一次任期内最多只有一个领导者被选出
leader 只添加操作:领导者在其日志中只添加新条目,不覆盖删除条目
日志匹配:如果两个log包含拥有相同索引和任期的条目,那么这两个log从之前到给定索引处的所有日志条目都是相同的
leader完整性:如果在给定的任期中提交了一个日志条目,那么该entry将出现在所有后续更高任期号的领导者的日志中
状态机安全性: 如果服务器已将给定索引处的日志条目应用于其状态机,则其他服务器不能在该索引位置应用别的日志条目
4)成员变更
多数派
基于前面的介绍,我们能够意识到一个重要的概念贯穿着领导选举和日志复制两个部分,那就是“多数派”的概念。
选举要经过大多数人同意
被大多数节点所持有的日志才能进入“达成共识阶段”
结合种种条件和保证,最终确保了raft的一个核心机制:进入“达成共识阶段”的日志最终会被提交。为了加深对于“多数派”概念及其作用的理解,我们不妨回到前面所提到的一个raft的原则:“Leader必然持有最新的‘达成共识’状态的日志”。相信通过前面的例子,这个结论确实是显而易见的,但是如何证明呢?可以通过反证法。
我们假设有一个candidate并不持有最新的“达成共识”状态的日志却成功当选leader,也就是说大多数人都拥有某一个entry,但是该candidate却不持有它。那么基于投票条件,这些人并不会给他投票。也就是说大多数人不会给该candidate投赞成票。而它却成功当选leader,也就是说有大多数人给他投了赞成票。
我们知道,一个成员人数固定的集群,不存在两个不相交的多数派。因此上面的假设不成立。从正面论证,两个多数派必然至少有一个相交的节点,该节点既拥有“达成共识”的日志,又给某个candidate助他成为了leader,结合投票原则,该leader必然也拥有了最新的已达成共识的日志。
联合共识
那么对于如此重要的一个属性,raft如何保证整个集群任意时刻都能持有一个相同的”大多数“的具体数值呢?相当于说,集群成员能否时刻知晓正确的集群成员数量?
对于一个成员不变的集群,“大多数”的数量是固定不变的。 但是当集群成员数量发生改变,特别是增加成员时,对于多数派的认知,集群的不同成员之间可能会发生分歧。考虑这样一个例子:

原本集群中有1、2、3三个节点,随后加入了4、5两个节点。集群有新成员的加入首先会通知当前leader,加入节点3是leader,他得知了成员变更的消息之后,其对于“大多数”的理解发生了改变,也就是说他现在认为当前集群成员共5个,3个成员才可以视为一个多数派。但是,在节点3将此信息同步给1、2之前,1、2节点仍然认为此时集群的多数派应该是2个。假如不幸地,集群在此时发生分区,1、2节点共处一个分区,剩下的节点在另一个分区。那么1、2节点会自己
开始选举,且能够选出一个合法的leader,只要某个节点获得2票即可。在另一边,也可以合法选出另一个leader,因为它有收获3票的可能性。
此时一个集群内部出现了两个合法的leader,且它们也都有能力对外提供服务。这种情况称为“脑裂”,将极大破坏集群的一致性。发生这种情况的原因,是成员变更导致出现了两个无交集多数派:【1,2】和【3,4,5】并且两个多数派做出了不相同的决定。
一个最简单的解决方法就是,每次只允许最多一个新节点加入集群。当原集群的多数派成员的接受此次变更后,才允许下一个新节点的加入。这种做法效率并不高,但确实有效,因为每次只新增一个新成员无论如何不会产生2个无交集的多数派。以3个成员的集群为例,多数派此时指由至少2个成员构成的集体,当加入一个新节点时,新“多数派”指由3个成员构成的集体,2+3>4,新旧“多数派”不可能做出完全相反的决定,因为必然有一个节点既存在于旧多数派中,又存在于新多数派中。

当然,为了解决一次加入多个新节点的问题,raft论文提出了一种称之为“联合共识”的技巧。我们知道如果一次加入多个节点,无法阻止两个多数派无交集的问题,但是只要限定两个多数派不能做出不同决定即可。联合共识的核心思想是引入一种中间状态,即让节点明白此时正处于集群成员变更的特殊时期,让它知晓两个集群的成员情况,例如【1、2、3】和【1、2、3、4、5】。当该节点知道当前处于中间状态时,它的投票必须要同时获得两个集群的多数派的支持。以此保证两个多数派不会做出截然相反的行为。举个例子来说明联合共识的内容。这里我们用新旧配置表示节点对于集群情况的认知(因此成员变更也被成为配置变更),例如旧配置有3个节点的地址和序号,新配置有5个。
当leader3得知成员变更的消息时,它并不是立即改变自己的配置为新配置,而是同时持有新旧配置,并且我们规定选举、日志复制过程中的“多数派”必须同时满足新旧两个配置。此时若网络与上面一样发生分区,1、2仍然能准确选举出leader,而3、4、5这边由于其选举必须经过旧配置中的大多数节点的赞成,也就是需要收到【1、2、3】节点的多数派赞成票才能胜出,即使获得了新配置【1、2、3、4、5】的多数派赞成票也不一定有用。而网络分区决定了1、2不能给3、4、5投票,所以3、4、5不可能当选,脑裂的隐患被解决。
配置变更如同来自客户端的提案一样,也会被当作日志在集群中复制。当leader确认一条配置变更的日志进入“达成共识状态”时(注意,同样也是新旧配置的多数派持有),他会先将自己的中间状态清除,转变为彻底的新配置,然后将单纯的新配置作为一条日志进行广播通知其他节点可以直接变为新配置了。由于日志的新旧也是投票的依据之一,此时仍然处于单纯旧配置的节点无法胜出可能的选举。只有中间状态或者新配置的节点才能胜出,这两种节点的共同点就是都需要获得新配置中的多数派的赞成票,所以不可能选举出两个leader。
3. raft的可用性和一致性
1)只读请求
对于客户端的只读请求,我们可以有以下几种方法进行处理:
follower自行处理:一致性最低,最无法保证,效率最高。
leader立即回复:leader可能并不合法(分区),导致数据不一致
将读请求与写请求等同处理:保证强一致,但性能最差
readIndex方法:由leader处理,处理之前首先向集群发生确认信息保证自己是合法leader,随后等待状态机已将请求到来时的commitIndex应用(说明请求到来之前的所有操作都已被状态机执行),才能回复读请求。保证一致,性能较好,是etcd建议的一种方式。
LeaseRead方法:Leader 取一个比 Election Timeout 小的租期,在租期不会发生选举,确保
Leader 不会变,即可跳过群发确认消息的步骤。性能较高,一致性可能会受服务器时钟频率影响。
对于读请求的处理能够让我们明显地看出共识算法和分布式系统一致性之间的关系。当共识达成时,即leader已将某entry提交,则整个系统已经具备了提供强一致服务的能力。但是,可能由于状态机执行失败、选择其他读请求处理方案等因素,导致在外部看来系统是不一致的。
2)网络分区
节点数量超过 n/2+1的一边可以继续提供服务,即使可能没有leader,也可以通过再次选举产生。而另一边的旧leader并不能发挥其作用,因为它并不能联系到大多数节点。
问题:raft属于A型还是C型?我们认为raft是一个强一致、高可用的共识算法。即使网络分区发生,只要由半数以上的节点处于同一个分区(假设60%),那么系统就能提供60%的服务,并且还能保证是强一致的。
3)预选举
由于接收不到leader的心跳,它们会自己开始选举,但由于人数过少不能成功选举出leader,所以会一直尝试竞选。它们的term可能会一直增加到一个危险的值。但分区结束时,通过心跳回应,原leader知道了集群中存在一群Term如此大的节点,它会修改自己的Term到已知的最大值,然后变为follower。此时集群中没有leader,需要重新选举。但是那几个原先被隔离的节点可能由于日志较为落后,而无法获得选举,新leader仍然会在原来的正常工作的那一部分节点中产生。
虽说最终结果没错,但是选举阶段会使得集群暂时无法正常工作,应该尽量避免这种扰乱集群正常工作的情况的发生,所以raft存在一种预选举的机制。真正的选举尽管失败还是会增加自己的Term,预选举失败后会将term恢复原样。只有预选举获得成功的candidate才能开始真正的选举。这样就可以避免不必要的term持续增加的情况发生。
4)快照
长时间运作的集群,其内部的日志会不断增长。因此需要对其进行压缩,并持久化保存。对于新加入集群的节点,可以直接将压缩好的日志(称之为快照Snapshot)发送过去即可。
5)Learner
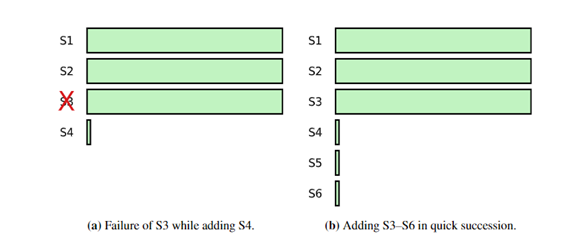
加入一个或多个新节点,都有可能因为数据同步的缓慢而影响系统的可用性。为此,raft引入一个Learner的角色,该角色不参与共识形成的过程,例如选举和日志提交的判断。但是具体何时learner可以参与投票,可由应用层根据接受程度自行决定。
| 







