| БрМЭЦМі: |
БОЮФжївЊУшЪіЖдгкДцДЂВуЃЈstorageЃЉЕФЪ§ОнКЭЗўЮёЕФ
balanceЁЃетаЉЖМЪЧЭЈЙ§ Balance УќСюРДЪЕЯжЕФЃКBalance УќСюгаСНжжЃЌвЛжжашвЊЧЈвЦЪ§ОнЃЌУќСюЮЊ
BALANCE DATA ЃЛСэвЛжжВЛашвЊЧЈвЦЪ§ОнЃЌжЛИФБф partition ЕФ
raft-leader ЗжВМЃЈИКдиОљКтЃЉЃЌУќСюЮЊ BALANCE LEADER
ЁЃ
БОЮФРДздvesoftЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
ЦНКтжїЬхЧГЮі
дкЭМЪ§ОнПтNebula GraphжаЃЌBalanceжївЊгУгкbalance LeaderКЭpartitionЃЌжЛЩцМАLeaderКЭpartitionдкЛњЦїжЎМфзЊвЦЃЌВЛЛсдіМгЛђМѕЩйLeader
and partitionЕФЪ§СПЁЃ
ЩЯЯпаТЛњЦїВЂЦєЖЏЯргІЕФNebulaЗўЮёКѓЃЌДцДЂЛсздЖЏЯђmetametametaЁЃMetaЛсМЦЫуГівЛИіаТЕФpartitionЗжВМЃЌШЛКѓЭЈЙ§ЩОГ§partition
КЭadd partitionНЋЪ§ОнДгРЯЛњЦїАсЧЈЕНаТЕФЛњЦїЩЯЁЃетИіЙ§ГЬЫљЖдгІЕФУќСюЪЧBALANCE DATA
ЃЌЭЈГЃЪ§ОнАсЧЈЪЧИіБШНЯТўГЄЕФЙ§ГЬЁЃ
ЕЋBALANCE DATAНіИФБфСЫЪ§ОнКЭИББОдкЛњЦїжЎМфЕФОљКтЗжВМЃЌleaderЃЈКЭЖдгІЕФИКдиЃЉЪЧВЛЛсИФБфЕФЃЌвђДЫЛЙашвЊЭЈЙ§УќСюBALANCE
LEADERРДЪЕЯжИКдиЕФОљКтЁЃетИіЙ§ГЬвВЪЧЭЈЙ§metaЪЕЯжЕФЁЃ
ДѓЙцФЃЪ§ОнЧЈвЦ
ОйР§вдЯТЫЕУїBALANCE DATAЕФЪЙгУЗНЪНБОЁЃвыЮФНЋДг3ИіЪЕР§ЃЈНјГЬЃЉРЉеЙЕН8ИіЪЕР§ЃЈНјГЬЃЉЃК
ВНжш1ЃКзМБИЙЄзї
ВПЪ№вЛИі3ИББОЕФИББОЃЌ1ИіЭМаЮЃЌ1ИіmetadЃЌ3ИіДцДЂЃЈОпЬхВПЪ№ЗНЪНЧыВЮПМВПЪ№ВПЪ№ЮФЃКhttps
://zhuanlan.zhihu.com/p/80335605 ЃЉЃЌЭЈЙ§SHOW HOSTS УќСюПЩвдПДЕНжиаТЕФзДЬЌаХЯЂЃК
ВНжш1.1ВщПДЯжгазДЬЌ
АДееВПЪ№ВПЪ№ЮФЕЕВПЪ№КУ3ИББОКЯВЂжЎКѓЃЌгУSHOW HOSTS УќСюВщПДЯТЯждкПЩгУЧщПіЃК

SHOW HOSTS ЗЕЛиНсЙћНтЪЭЃК
IPЃЌЖЫПкБэЪОЕБЧАЕФДцДЂЪЕР§ЁЃетИізюДѓЛЏЦєЖЏСЫ3ИіstoragedЗўЮёЃЌВЂЧвЛЙУЛгаШЮКЮЪ§ОнЁЃЃЈ192.168.8.210:34600ЃЌ192.168.8.210:34700ЃЌ192.168.8.210:34500ЃЉ
зДЬЌБэЪОЕБЧАЪЕР§ЕФзДЬЌЃЌФПЧАгадкЯп/РыЯпСНжжЁЃЕБЛњЦїЯТЯпвдКѓЃЈmetadдквЛЖЮМфИєФкЪеВЛЕНЦфаФЬјЃЉЃЌНЋЦфИќИФЮЊРыЯпЁЃетИіЪБМфМфИєПЩвддкЦєЖЏmetadЕФЪБКђЭЈЙ§ЩшжУexpired_threshold_secРДаоИФЃЌЕБЧАФЌШЯжЕЪЧ10ЗжжгЁЃ
СьЕМШЫЪ§ЃКБэЪОЕБЧАЪЕР§
СьЕМепЗжВМЃКБэЪОЕБЧАСьЕМепдкУПИіПеМфЩЯЕФЗжВМЃЌФПЧАЩаЮДДДНЈШЮКЮПеМфЁЃЃЈspaceПЩвдРэНтЮЊвЛИіЖРСЂЕФЪ§ОнПеМфЃЌРрЫЦMySQLЕФЪ§ОнПтЃЉ
ЗжЧјЗжВМЃКВЛЭЌПеМфжаЗжЧјЕФЪ§СПЁЃ 
ПЩвдПДЕН СьЕМЗжВМКЭ ЗжЧјЗжВМднЪБЖМУЛгаЪ§ОнЁЃ
ВНжш1.2ДДНЈЭМПеМф
ДДНЈвЛИіГЦЮЊtestЕФЭМПеМфЃЌАќКЌ100ИіЗжЧјЃЌУПИіЗжЧјга3ИіИББОЁЃ

ЦЌПЬКѓЃЌЪЙгУSHOW HOSTSУќСюЯдЪОРлЛ§ЕФЗжВМЁЃ


ШчЩЯЃЌДДНЈАќКЌ100Иі_partitio_nКЭ3ИіИББОЭМПеМфжЎКѓЃЌ3ИіЪЕР§ЕФ СьЕМЗжВМКЭ_PartitionЗжВМ_ОпгаЖдгІЕФЪ§жЕЃЌЖдгІЕФ_PartitionЗжВМ_ЖМЮЊ100ЁЃЕБШЛЃЌетбљЕФlearderЗжВМЛЙВЛОљдШЁЃ
ВНжш2МгШыаТЪЕР§
ЦєЖЏ5ИіаТДцДЂЕФЪЕР§НјааРЉШнЁЃЦєЖЏЭъГЩКѓЃЌЪЙгУSHOW HOSTSУќСюВщПДаТЕФзДЬЌЃК


ЩЯаТЪЕР§жЎКѓЃЌеМгУгЩдРДЕФ3ИіЪЕР§БфГЩСЫ8ИіЪЕР§ЁЃЩЯЭМЪ§ОнПтiconЮЊРЖЩЋЕФЭМБъЮЊЬэМгЕФ5ИіЪЕР§ЃЌДЫЪБНіБЛМгШыСЫЬцДњЃЌаТЪЕР§ЕФзДЬЌЮЊOnline
ЃЌЃЌЕЋДЫЪБ СьЕМепЗжВМКЭ_ЗжЧјЗжВМ_ВЂУЛгаЪ§жЕЃЌЫЕУїЛЙВЛЛсВЮгыЗўЮёЁЃ
ВНжш3ЧЈвЦЪ§Он
дЫааBALANCE DATAУќСюЁЃ

ШчЙћвбОЛ§РлСЫаТЛњЦїМгШыЃЌдђЩњГЩвЛИіаТЕФМЦЛЎIDЁЃЖдгквбОЦНКтЕФзЊвЦЃЌжиИДдЫааBALANCE DATAВЛЛсгаШЮКЮаТВйзїЁЃШчЙћЕБЧАгае§дкжДааЕФМЦЛЎЃЌФЧЛсЯдЪОЕБЧАМЦЛЎЕФIDЁЃ
вВПЩЭЈЙ§BALANCE DATA $idВщПДетИіbalanceЕФОпЬхжДааНјЖШЁЃ

BALANCE DATA $id ЗЕЛиНсЙћЫЕУїЃК
ЕквЛСаbalanceIdЃЌspaceIdЃКPARTIDЃЌSRC-> DSTБэЪОвЛИіОпЬхЕФЦНКтШЮЮёвдЁЃ1570761786,
1:88, 192.168.8.210:34700->192.168.8.210:35940
ЮЊР§ЃК
1570761786ЮЊгрЖюID
1ЃК88ЃЌ1БэЪОЕБЧАЕФspaceIdЃЈвВОЭЪЧspace testЕФIDЃЉЃЌ88БэЪОЧЈвЦЕФpartitionId
192.168.8.210:34700->192.168.8.210:35940ЃЌБэЪОЪ§ОнДг192.168.8.210:34700АсЧЈжС
192.168.8.210:35940ЁЃЖјдЯШ192.168.8.210:34700жаЕФЪ§ОнНЋЛсдкЧЈвЦЭъГЩКѓдйGCЩОГ§
ЕкЖўСаБэЪОЕБЧАtaskЕФдЫаазДЬЌЃЌга4жжзДЬЌ
ГЩЙІЃКдЫааГЩЙІ
ЪЇАмЃКдЫааЪЇАм
НјаажаЃКдЫаажа
ЮоаЇЃКЮоаЇЕФШЮЮё
зюКѓЖдЫљгаШЮЮёдЫаазДЬЌЕФЭГМЦЃЌВПЗжЗжЧјЩаЮДЭъГЩЧЈвЦЁЃ
ВНжш4ШчЙћвЊжаЭОЭЃжЙгрЖюЪ§Он
BALANCE DATA STOP УќСювбЭЃжЙвбОПЊЪМжДааЕФгрЖюЪ§ОнМЦЛЎЁЃШчЙћУЛгае§дкдЫааЕФbalanceМЦЛЎЃЌдђЗЕЛиДэЮѓЬсЪОЁЃШчЙћгае§дкдЫааЕФbalanceМЦЛЎЃЌдђЗЕЛиМЦЛЎЖдгІЕФIDЁЃ
гЩгкУПИіbalanceМЦЛЎЖдгІBALANCE DATA STOPМИИіЦНКтШЮЮёЃЌВЛЛсЭЃжЙвбОПЊЪМжДааЕФbalanceШЮЮёЃЌжЛЛсШЁЯћКѓајЕФtaskЃЌвбОПЊЪМЕФtaskНЋМЬајжДаажБжСЭъГЩЁЃ
гУЛЇПЩвддкBALANCE DATA STOPжЎКѓЪфШыBALANCE DATA $idРДВщПДвбОЭЃжЙЕФbalanceМЦЛЎзДЬЌЁЃ
ЫљгавбОПЊЪМжДааЕФШЮЮёЭъГЩКѓЃЌПЩвддйДЮжДааBALANCE DATAЃЌжиаТПЊЪМгрЖюЁЃШчЙћжЎЧАЭЃжЙЕФМЦЛЎжагаЪЇАмЕФШЮЮёЃЌж№ВНМЬајжДаажЎЧАЕФМЦЛЎЃЌШчЙћжЎЧАЭЃжЙЕФМЦЛЎжаЫљгаШЮЮёаТНЈвЛИіbalanceМЦЛЎВЂПЊЪМжДааЁЃ
ВНжш5ВщПДЪ§ОнЧЈвЦНсЙћ
ДѓЖрЪ§ЧщПіЯТЃЌАсЧЈЪ§ОнЪЧИіБШНЯТўГЄЕФЙ§ГЬЁЃЕЋЪЧАсЧЈЙ§ГЬВЛЛсгАЯьЯжгаЗўЮёЁЃЯждкПЩвдЭЈЙ§SHOW HOSTSВщПДдЫааКѓЕФpartitionЗжВМЁЃ


ЗжЧјЗжВМЯрНќЃЌЗжЧјзмЪ§300ВЛБфЧвpartitionвбОљКтЕФЗжВМжСИїИіЪЕР§ЁЃ
ШчЙћгадЫааЪЇАмЕФШЮЮёЃЌПЩдйДЮдЫааBALANCE DATAУќСюНјаааоИДЁЃШчЙћЖрДЮдЫааШдЮоЗЈаоИДЃЌЧыгыЩчЧјСЊЯЕGitHubЁЃ
ВНжш6ЦНКтСьЕМеп
BALANCE DATAНіФмЦНКтЗжЧјЃЌЕЋЪЧСьЕМепЗжВМШдШЛВЛОљКтЃЌвтЮЖзХетОЩЪЕР§ЕФЗўЮёНЯжиЃЌаТЖјЪЕР§ЕФЗўЮёФмСІЮДЕУЕНГфЗжЪЙгУдЫааЁЃBALANCE
LEADERжиаТЗжВМЗЄИКд№ШЫЃК

ЦЌПЬКѓЃЌЪЙгУSHOW HOSTSУќСюВщПДЃЌДЫЪБRaft LeaderвбОљдШЗжВМжСЫљгаЕФЪЕР§ЁЃ
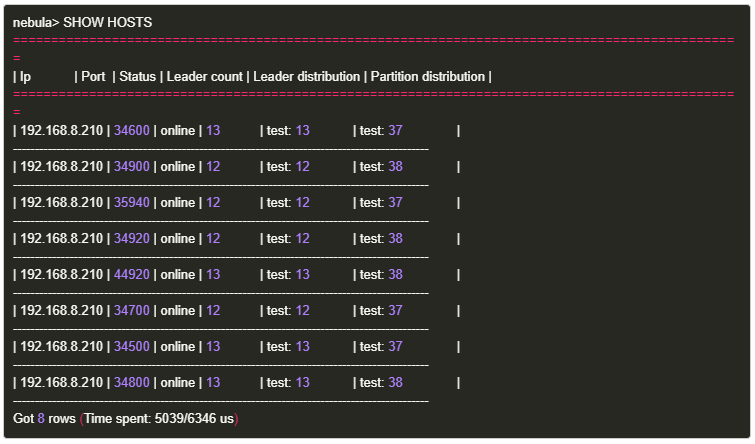

ШчЩЯЃЌBALANCE LEADER ГЩЙІжДааКѓЃЌЬэМгЕФЪЕР§КЭдРДЕФЪЕР§ЃЈЖдгІЩЯЭМЭМБъРЖЩЋКЭКкЩЋЭМБъЃЉЕФ_Leader
distribution _ЯрНќЃЌЫљгаЪЕР§вбОљКтЃЌПЩвдЃЌвВПЩвд ПДЕНгрЖюУќСюжЛЩцМАLeaderКЭpartitionдкЮяРэЛњЦїЩЯЕФзЊвЦЃЌВЂЧвУЛгадіМгЛђМѕЩйLeaderКЭpartitionЁЃ
ХњСПЫѕШн
аЧдЦЭМжЇГжжИЖЈашвЊЯТЯпЕФЛњЦїНјааХњСПЫѕШнгяЗЈЮЊЁЃBALANCE DATA REMOVE $host_listЃЌР§ШчЃКBALANCE
DATA REMOVE 192.168.0.1:50000,192.168.0.2:50000ЃЌНЋжИЖЈвЦГ§192.168.0.1:50000,192.168.0.2:50000СНЬЈЛњЦїЁЃ
ШчЙћПЩвЦГ§жИЖЈЛњЦїКѓЃЌВЛТњзуИББОЪ§вЊЧѓЃЈР§ШчЪЃгрЛњЦїЪ§аЁгкИББОЪ§ЃЉЃЌаЧдЦЭМНЋОмОјБОДЮbalanceЧыЧѓЃЌВЂЗЕЛиЯрЙиДэЮѓТыЁЃ
ЪОР§Ъ§ОнЧЈвЦ
ЩЯУцНВСЫШчКЮДг3ИіЪЕР§БфГЩ8ИіЪЕР§ЕФЪЕР§ЃЌШчЙћФуЖдЩЯЮФгавЩЮЪЃЌМЧЕУдкетРяЕФЦРТлЧјСєбдЙўЁЃЮвУЧЯждкПДПДЩЯУцЧЈвЦЕФЙ§ГЬЃЌ192.168.8.210:
34600 етИіЪЕР§ЕФзДЬЌБфЛЏЁЃ

ЫЕУїЃКгабеЩЋЮЊКьЩЋЫЕУїЖдгІЕФЪ§жЕЗЂЩњБфЛЏЃЌШчЙћЪ§жЕВЛБфЃЌдђЮЊКкЩЋЁЃ
| 







