| БрМЭЦМі: |
БОЮФжївЊНВНтСЫTidbЕФБГОАЁЂМђНщЁЂгХЪЦМАгІгУЪЕеНЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздTesterHomeЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
БГОА
ЕБ mysql ЕФвЛИіДѓБэзмЪ§ДяЩЯвкЪБЃЌmysql адФмБфЕФКмВюЃЌЧваТдіЛђаоИФзжЖЮЁЂЫїв§вВашвЊЛЈЗбКмГЄЪБМфЃЌжСЩйЪЎМИИіаЁЪБЁЃетжжЧщПіЃЌвЛАуЕФзіЗЈЪЧЗжПтЗжБэЃЌетжжЗНЗЈашвЊвЕЮёВуИљОнЙцдђЃЌЮяРэЗжПтЗжБэЃЌБШШчАДееЪБМфЗжБэЃЌвЕЮёДњТыашвЊМцШнЁЃTidb
ЪЧЗжВМЪН newsql Ъ§ОнПтЃЌМцШнСЫДѓВПЗж mysql авщКЭВйзїЃЌвЕЮёВЛашвЊЕїећЃЌЪ§ОнПтадФмвВФмБЃжЄЁЃ
Tidb НщЩм
1.ПЊдДЗжВМЪНЕФЙиЯЕаЭЪ§ОнПт
TiDB ЪЧПЊдДЗжВМЪН HTAP (Hybrid Transactional and Analytical
Processing) Ъ§ОнПтЃЌНсКЯСЫДЋЭГЕФ RDBMS КЭ NoSQL ЕФзюМбЬиадЁЃTiDB МцШн
MySQLЃЌжЇГжЮоЯоЕФЫЎЦНРЉеЙЃЌОпБИЧПвЛжТадКЭИпПЩгУадЁЃTiDB ЕФФПБъЪЧЮЊ OLTP (Online
Transactional Processing) КЭ OLAP (Online Analytical
Processing) ГЁОАЬсЙЉвЛеОЪНЕФНтОіЗНАИ
2.ећЬхМмЙЙ
вЊЩюШыСЫНт TiDB ЕФЫЎЦНРЉеЙКЭИпПЩгУЬиЕуЃЌашвЊСЫНт TiDB ЕФећЬхМмЙЙЁЃTiDB МЏШКжївЊАќРЈШ§ИіКЫаФзщМўЃКTiDB
ServerЃЌPD Server КЭ TiKV ServerЁЃДЫЭтЃЌЛЙгагУгкНтОігУЛЇИДдг OLAP
ашЧѓЕФ TiSpark зщМўЁЃ

2.1.TiDB Server
TiDB Server ИКд№НгЪе SQL ЧыЧѓЃЌДІРэ SQL ЯрЙиЕФТпМЃЌВЂЭЈЙ§ PD евЕНДцДЂМЦЫуЫљашЪ§ОнЕФ
TiKV ЕижЗЃЌгы TiKV НЛЛЅЛёШЁЪ§ОнЃЌзюжеЗЕЛиНсЙћЁЃTiDB Server ЪЧЮозДЬЌЕФЃЌЦфБОЩэВЂВЛДцДЂЪ§ОнЃЌжЛИКд№МЦЫуЃЌПЩвдЮоЯоЫЎЦНРЉеЙЃЌПЩвдЭЈЙ§ИКдиОљКтзщМўЃЈШч
LVSЁЂHAProxy Лђ F5ЃЉЖдЭтЬсЙЉЭГвЛЕФНгШыЕижЗЁЃ
2.2.PD Server
Placement Driver (МђГЦ PD) ЪЧећИіМЏШКЕФЙмРэФЃПщЃЌЦфжївЊЙЄзїгаШ§ИіЃКвЛЪЧДцДЂМЏШКЕФдЊаХЯЂЃЈФГИі
Key ДцДЂдкФФИі TiKV НкЕуЃЉЃЛЖўЪЧЖд TiKV МЏШКНјааЕїЖШКЭИКдиОљКтЃЈШчЪ§ОнЕФЧЈвЦЁЂRaft
group leader ЕФЧЈвЦЕШЃЉЃЛШ§ЪЧЗжХфШЋОжЮЈвЛЧвЕндіЕФЪТЮё IDЁЃ
PD ЭЈЙ§ Raft авщБЃжЄЪ§ОнЕФАВШЋадЁЃRaft ЕФ leader server ИКд№ДІРэЫљгаВйзїЃЌЦфгрЕФ
PD server НігУгкБЃжЄИпПЩгУЁЃНЈвщВПЪ№ЦцЪ§Иі PD НкЕуЁЃ
2.3.TiKV Server
TiKV Server ИКд№ДцДЂЪ§ОнЃЌДгЭтВППД TiKV ЪЧвЛИіЗжВМЪНЕФЬсЙЉЪТЮёЕФ Key-Value
ДцДЂв§ЧцЁЃДцДЂЪ§ОнЕФЛљБОЕЅЮЛЪЧ RegionЃЌУПИі Region ИКд№ДцДЂвЛИі Key RangeЃЈДг
StartKey ЕН EndKey ЕФзѓБегвПЊЧјМфЃЉЕФЪ§ОнЃЌУПИі TiKV НкЕуЛсИКд№ЖрИі RegionЁЃTiKV
ЪЙгУ Raft авщзіИДжЦЃЌБЃГжЪ§ОнЕФвЛжТадКЭШнджЁЃИББОвд Region ЮЊЕЅЮЛНјааЙмРэЃЌВЛЭЌНкЕуЩЯЕФЖрИі
Region ЙЙГЩвЛИі Raft GroupЃЌЛЅЮЊИББОЁЃЪ§ОндкЖрИі TiKV жЎМфЕФИКдиОљКтгЩ PD
ЕїЖШЃЌетРявВЪЧвд Region ЮЊЕЅЮЛНјааЕїЖШЁЃ
2.4.TiSpark
TiSpark зїЮЊ TiDB жаНтОігУЛЇИДдг OLAP ашЧѓЕФжївЊзщМўЃЌНЋ Spark SQL жБНгдЫаадк
TiDB ДцДЂВуЩЯЃЌЭЌЪБШкКЯ TiKV ЗжВМЪНМЏШКЕФгХЪЦЃЌВЂШкШыДѓЪ§ОнЩчЧјЩњЬЌЁЃжСДЫЃЌTiDB ПЩвдЭЈЙ§вЛЬзЯЕЭГЃЌЭЌЪБжЇГж
OLTP гы OLAPЃЌУтГ§гУЛЇЪ§ОнЭЌВНЕФЗГФеЁЃ
3.ЛЗОГВПЪ№
Linux ВйзїЯЕЭГЦНЬЈНЈвщЮЊ CentOS7.3 МАвдЩЯЃЌЭЌЪБвВжЇГжЦфЫћжїСїЕФ Linux ВйзїЯЕЭГЛЗОГЁЃ
гВХЬжСЩйЪЧ SSD ЕФЛњЦїЃЌSAS ХЬВЛааЃЌЭЦМі pcieЁЃ
ВПЪ№вЛЬзМЏШКжСЩйашвЊ 5 ЬЈЛњЦїЃЌ2TiDBЃЌ3TikVЃЌPD ПЩвдКЭ TiDB ВПЪ№дкЭЌЗўЮёЦїЩЯЁЃ
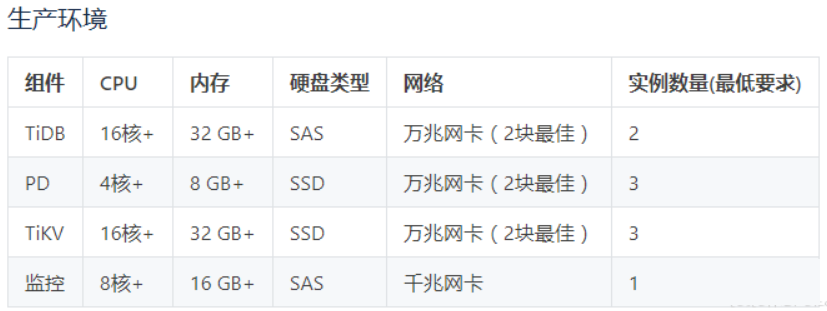
Tidb гХЪЦ
1.ЫЎЦНЕЏадЮоЯожЦРЉеЙ
ЗжВМЪНЕФ TiDB ПЩЫцзХФуЕФЪ§ОндіГЄЖјЮоЗьЕиЫЎЦНРЉеЙЃЌжЛашвЊЭЈЙ§діМгИќЖрЕФЛњЦїРДТњзувЕЮёдіГЄашвЊЃЌгІгУВуПЩвдВЛгУЙиаФДцДЂЕФШнСПКЭЭЬЭТЁЃЖдБШ
mysqlЃЌашвЊ lvm ИЈжњДХХЬРЉШнЁЃ
2.ЙЪеЯздЛжИДМАвьЕиЖрЛю
TiDB ЪЙгУЖрИББОНјааЪ§ОнДцДЂЃЌВЂвРРЕвЕНчзюЯШНјЕФ Raft ЖрЪ§ХЩбЁОйЫуЗЈШЗБЃЪ§Он 100% ЧПвЛжТадКЭИпПЩгУЁЃИББОПЩПчЕигђВПЪ№дкВЛЭЌЕФЪ§ОнжааФЃЌжїИББОЙЪеЯЪБздЖЏЧаЛЛЃЌЮоашШЫЙЄНщШыЃЌздЖЏБЃеЯвЕЮёЕФСЌајадЃЌЪЕЯжеце§втвхЩЯЕФвьЕиЖрЛюЁЃ
3.вЛжТадЕФЗжВМЪНЪТЮё
ПЩвдАб TiDB ЯыЯѓГЩвЛИіЕЅЛњЕФ RDBMSЃЌACID ЪТЮёПЩвддкЖрНкЕуМфНјааЃЌЮоашЕЃаФвЛжТадЮЪЬтЁЃ
TiDB ЖдвЕЮёУЛгаШЮКЮЧжШыадЃЌЪЧДЋЭГЕФЪ§ОнПтжаМфМўЁЂЪ§ОнПтЗжПтЗжБэЕШгХбХЕФЬцЛЛЗНАИЁЃ
4.ИпЖШМцШн MySQLЃЌСуГЩБОЧЈвЦ
TiDB ЕФЭЈбЖавщгы MySQL ИпЖШМцШнЃЌФуПЩвдЧсЫЩЕиЯёЪЙгУЕЅЛњЪ§ОнПтвЛбљЃЌгУ TiDB ЬцЛЛ
MySQL РДжЇГжФуЕФвЕЮёЃЌЖјМИКѕЮоашаоИФДњТыЁЃ MySQL ЕФПЭЛЇЖЫЙмРэЙЄОпМАЩчЧјЫљгаЕФжмБпЙЄОпЖМПЩжБНгНгШыЃЌМЋДѓНЕЕЭбЇЯАКЭЪЙгУГЩБОЁЃ
змжЎЃЌЧЈвЦЗНБуЃЌВЛгУЗжПтЗжБэЃЌТпМВЛгУзіМцШнДІРэЃЌГЬађЕїгУвВЮоашДІРэЃЌmysql ЕФПЭЛЇЖЫЙЄОпе§ГЃЪЙгУЁЃ
5.ИќгХЕФадФмгХЪЦ
TiDB ИљОнДцДЂЁЂЭјТчЁЂОрРыЕШвђЫиЃЌЖЏЬЌНјааИКдиОљКтЕїећЃЌвдБЃжЄИќгХЕФЖСаДадФмЁЃTiDB дкДѓЪ§ОнСПЯТИДдгВщбЏЗНУцЃЌЯрБШ
MySQL гаОјЖдЕФадФмгХЪЦЁЃ
5.1 ДѓБэНЈСЂЫїв§Пь
5.2 ДѓБэаоИФСаБэПьЃЌБШШчМгСаЃЌаоИФСаЪєад
Mysql ДѓБэНЈСЂЫїв§КЭаоИФБэашвЊЛЈЗбДѓСПЕФЪБМфЁЃ
Tidb ЕФгІгУЪЕМљ
дкЪЕМЪЪЙгУ tidb Й§ГЬжаЃЌзмНсСЫвЛЯТгІгУЙ§ГЬжаЕФвЛаЉзЂвтЪТЯюЃЌБШШчКЭ mysql ЕФВЛЭЌЕуЃЌадФмгХЛЏЃЌгХЛЏЙЄОпЕШЁЃ
1.ШЅЕєздді id
дкДЋЭГЕФЙиЯЕаЭЪ§ОнПтжаЃЌПЊЗЂепОГЃЛсвРРЕздді ID РДзїЮЊ PRIMARY KEYЃЌЕЋЪЧЦфЪЕДѓЖрЪ§ГЁОАДѓМвЯывЊЕФжЛЪЧвЛИіВЛжиИДЕФ
ID ЖјвбЃЌжСгкЪЧВЛЪЧзддіЦфЪЕЮоЫљЮНЃЌЕЋЪЧетИіЖдгкЗжВМЪНЪ§ОнПтРДЫЕЪЧВЛЭЦМіЕФЃЌЫцзХВхШыЕФбЙСІдіДѓЃЌЛсдкетеХБэЕФЮВВП
Region аЮГЩШШЕуЃЌЖјЧветИіШШЕуВЂУЛгаАьЗЈЗжЩЂЕНЖрЬЈЛњЦїЁЃTiDB дк GA ЕФАцБОжаЛсЖдЗЧздді
ID жїМќНјаагХЛЏЃЌШУ insert workload ОЁПЩФмЗжЩЂЁЃ
НЈвщЃК
ШчЙћвЕЮёУЛгаБивЊЪЙгУЕЅЕїЕнді ID зїЮЊжїМќЃЌОЭБ№гУЃЌЪЙгУеце§гавтвхЕФСазїЮЊжїМќЃЈвЛАуРДЫЕЃЌР§ШчЃКгЪЯфЁЂгУЛЇУћЕШЃЉ
ПЩвдЪЙгУЗжВМЪН id ЩњГЩЫуЗЈЩњГЩЮЈвЛ keyЃЌОпЬхЗНЗЈПЩвдВЮПМЩЯвЛЦЊЮФеТ ЁАЛљгк python ЕФЗжВМЪН
id ЩњГЩЫуЗЈЪЕЯжЁБЁЃ
2.Ъ§ОнБэЕФаоИФВйзїЕЅвЛ
ДДНЈЭъГЩвЛеХЪ§ОнБэКѓЃЌаоИФВйзїЗЧГЃРЇФбЃЌгаКмЖрЯожЦЬѕМўЃЌПЩФмвВКЭЗжВМЪНЯрЙиЃЌВЛдЪаэЭЌЪБВйзїЖрИіСаЃЌНЈвщзюКУОЭАбБэЕФНсЙЙЖЈвхКУЃЌаоИФВЛвЊЬЋЦЕЗБЁЃ
ВЛжЇГжЭЌЪБДДНЈЖрИіЫїв§
ВЛжЇГжЭЌЪБДДНЈЖрИіСа
ВЛжЇГжЩОГ§жїМќСаЛђЫїв§Са
ВЛжЇГжаоИФЫїв§
вЛДЮжЛФмаоИФвЛСа
3.АцБОЮЪЬт
TiDB вЛжБдкГжајЗЂеЙгХЛЏжаЃЌгааЉЕЭАцБОЕФЛсДцдквЛаЉЮЪЬтЃЌдкгІгУЙ§ГЬжаЃЌЗЂЯж 3.0 етИіАцБОгаШчЯТЮЪЬтЃК
ВхШыжїМќжиИДЕФЪ§ОнЃЌвЛАуЧщПіЯТЪЧЛсБЈзжЖЮжиИДЃЌУЛгаВхШыГЩЙІЕФДэЮѓЁЃЕЋетИіАцБОВЛЛсБЈДэЁЃ
Ыїв§ГЄЖШУЛгаЯожЦЃЌПЩвдНЈКмГЄзжЖЮЕФЫїв§ЃЌетбљЛсгаадФмЮЪЬтЁЃ
Щ§МЖжС 3.1 АцБОКѓЃЌвдЩЯ 2 ИіЮЪЬтЖМНтОіСЫЁЃ
4.БмУтЗДЯђЩИбЁВщбЏЮЪЬт
ЗДЯђЩИбЁдкЫљгаЙиЯЕаЭЪ§ОнПтРяЛљБОЖМЪЧШЋБэЩЈЃЌnot inЃЌЃЁ=ЃЌ%%ЃЌетаЉЗДЯђЩИбЁВйзїгУВЛЕНЫїв§ЃЌОљЪЧШЋБэЩЈЁЃ
ВЛТлдкФФИіМЏШКЗДЯђЩИбЁЖМЪЧВЛдЪаэЕФЃЌЛсгАЯьМЏШКЕФ ioЃЌЕМжТМЏШКадФмЖЖЖЏЃЌвЕЮёвЛЖЈвЊМЋСІБмУтШЋБэЩЈЁЃ
5.ДѓБэЕФШШЕуЮЪЬт
дк TiDB жааТНЈвЛИіБэКѓЃЌФЌШЯЛсЕЅЖРЧаЗжГі 1 Иі Region РДДцДЂетИіБэЕФЪ§ОнЃЌетИіФЌШЯааЮЊгЩХфжУЮФМўжаЕФ
split-table ПижЦЁЃЕБетИі Region жаЕФЪ§ОнГЌЙ§ФЌШЯ Region ДѓаЁЯожЦКѓЃЌетИі
Region ЛсПЊЪМЗжСбГЩ 2 Иі RegionЁЃ
ЩЯЪіЧщПіжаЃЌШчЙћдкаТНЈЕФБэЩЯЗЂЩњДѓХњСПаДШыЃЌдђЛсдьГЩаДШШЕуЃЌвђЮЊПЊЪМжЛгавЛИі RegionЃЌЫљгаЕФаДЧыЧѓЖМЗЂЩњдкИУ
Region ЫљдкЕФФЧЬЈ TiKV ЩЯЃЌетИіНзЖЮЪєгкБэ Region ЕФдЄШШНзЖЮЁЃ
ЮЊНтОіЩЯЪіГЁОАжаЕФШШЕуЮЪЬтЃЌTiDB в§ШыСЫдЄЧаЗж Region ЕФЙІФмЃЌМДПЩвдИљОнжИЖЈЕФВЮЪ§ЃЌдЄЯШЮЊФГИіБэЧаЗжГіЖрИі
RegionЃЌВЂДђЩЂЕНИїИі TiKV ЩЯШЅЁЃИљОн PKЃЌЗжЮЊ 2 жжЧщПіЃК
PK ЪЧ int РраЭ
БОвЕЮёаДШыЪЧдке§Ъ§ЗЖЮЇФкЭъШЋРыЩЂЃЌдк Int64 ПеМфФкЬсЧАНЋБэЧаЩЂЮЊ 128 Иі RegionЃЌгяОфШчЯТЃК
| SPLIT TABLE
file_HOTSPOT BETWEEN (0) AND (9223372036854775807)
REGIONS 128; |
ЧаЗжЭъГЩвдКѓЃЌПЩвдЭЈЙ§ SHOW TABLE file_hotspot REGIONS; гяОфВщПДДђЩЂЕФЧщПіЃЌШчЙћ
SCATTERING СажЕШЋВПЮЊ 0ЃЌДњБэЕїЖШГЩЙІЁЃ
PK ЗЧ int РраЭЛђУЛга PK
Ждгк PK ЗЧећЪ§ЛђУЛга PK ЕФБэЃЌTiDB ЛсЪЙгУвЛИівўЪНЕФздді rowidЃЌДѓСП INSERT
ЪБЛсАбЪ§ОнМЏжааДШыЕЅИі RegionЃЌдьГЩаДШыШШЕуЁЃ
ЭЈЙ§ЩшжУ SHARD_ROW_ID_BITSЃЌПЩвдАб rowid ДђЩЂаДШыЖрИіВЛЭЌЕФ RegionЃЌЛКНтаДШыШШЕуЮЪЬтЁЃЕЋЪЧЩшжУЕФЙ§ДѓЛсдьГЩ
RPC ЧыЧѓЪ§ЗХДѓЃЌдіМг CPU КЭЭјТчПЊЯњЁЃХфКЯ pre_split_regions вЛЦ№ЪЙгУЃЌгУРДдкНЈБэГЩЙІКѓОЭПЊЪМдЄОљдШЧаЗж
2pre_split_regions Иі RegionЁЃ
pre_split_regions БиаыаЁгкЕШгк shard_row_id_bitsЁЃгяОфШчЯТЃЌДјЩЯ
2 ИігХЛЏВЮЪ§
shard_row_id_bits=4
pre_split_regions=3ЃК
create table t (a int, b int,index idx1(a)) shard_row_id_bits
= 4 pre_split_regions=2; |
ЁёSHARD_ROW_ID_BITS = 4 БэЪО tidb_rowid ЕФжЕЛсЫцЛњЗжВМГЩ 16ЃЈ16=24ЃЉИіЗЖЮЇЧјМфЁЃ
Ёёpre_split_regions=3 БэЪОНЈЭъБэКѓЬсЧА split Гі 8 (23) Иі regionЁЃ
дкБэ t ПЊЪМаДШыКѓЃЌЪ§ОнаДШыЕНЬсЧА split КУЕФ 8 Иі region жаЃЌетбљвВБмУтСЫИеПЊЪМНЈБэЭъКѓвђЮЊжЛгавЛИі
region ЖјДцдкЕФаДШШЕуЮЪЬтЁЃ
зЂЃКеыЖд PK ЮЊ int РраЭЕФБэдіМгет 2 ИіВЮЪ§ЃЌЛиБЈШчЯТДэЮѓЁЃ

6.ЕЅЬѕМЧТМДѓаЁЯожЦ
гаИіБэЕФгаИізжЖЮРраЭЪЧ longblobЃЌlongblob ЕФзюДѓЮЊ 4GЃЌВтЪдЙ§ГЬжаЗЂЯжзюДѓЪЧ 6MЃЌДѓгк
6M ЕФФкШнВхШыВЛНјШЅЃЌВщПДЮФЕЕЫЕУїКѓЗЂЯжетЪЧЯЕЭГЯожЦЁЃ
ЕЅЬѕ KV entry ВЛГЌЙ§ 6MB
KV entry ЕФзмЬѕЪ§ВЛГЌЙ§ 30w
KV entry ЕФзмДѓаЁВЛГЌЙ§ 100MB
ЕЅИіЪТЮёАќКЌЕФ SQL гяОфВЛГЌЙ§ 5000 ЬѕЃЈФЌШЯЃЉ
7.Ъ§ОнШндж
TIDB ИББОНЈвщЪЧ 3 ИіЛђвдЩЯЃЌТњзуШнджашЧѓЃЌВЛашвЊЪ§ОнЫЋаДЃЌПЩвддк mysql зіЪ§ОнЖЈЪЧБИЗнЁЃ
ШчЙћЩЯгЮВйзїЃЌБШШчЩОГ§вЛИіЪ§ОнПтЃЌЛсЕМжТИББОЕФЪ§ОнЖМЖЊЪЇЃЌПЩвдзіЪ§ОнБИЗнЁЃ
8.БИЗнгыЛжИДЮЪЬт
tidb ЕФ br ЮяРэБИЗнЃЌвЊЧѓЛжИДЪБвЊШЋаТМЏШКЃЈМЏШКФкВЛФмгаШЮКЮЪ§ОнЃЉЃЌФПЧАвЕЮёетРяУЛгаЛжИДгУЕФЛњЦїЃЌЛЙЮоЗЈЬсЙЉЪ§ОнЛжИДЁЃ
9.Ыїв§ГЄЖШЕФЮЪЬт
3.0.6 АцБОМгШыСЫЫїв§КЯЗЈадДДНЈМьВщЁЃtidb Ыїв§зюДѓГЄЖШЪЧ 3072byteЃЌutf8m64
зжЗћМЏЯТ varchar ЪЧ 4 зжНкЕФЃЌЫљвджЇГжЕФзюДѓЫїв§ГЄЖШЪЧ 768ЁЃ
НЈСЂЫїв§ЪБЃЌзжЖЮ varchar ЬЋГЄЃЌПЩвдПМТЧЛЛГЩЖдгІЕФ md5 жЕЁЃ
10.жЇГж Grafana
Grafana ЪЧвЛПюПЊдДМрПиЯдЪОШэМўЃЌЖдЪ§ОнПтМЏШКЕФИїЯюжИБъНјааПЩЪгЛЏеЙЯжЃЌGrafana жЇГж
Mysql авщЃЌвВОЭжЇГж TiDB Ъ§ОндДЁЃНЋЪ§ОнЭЈЙ§ Grafana еЙЪОЃЌВЛНіФмЙЛжБЙлЕФПДЕНЪ§ОнЕФБфЖЏЧїЪЦЃЌЗЂЯжЪ§ОнБГКѓЕФЙцТЩЃЌЭЌЪБЛЙФмАяжњзіЗўЮёМрПиЁЃ
ЂйдіМг TiDB Ъ§ОндД
ЂкЪ§ОнеЙЪО

змНс
ЗжВМЪН TiDB ЪЧ Mysql ЗжПтЗжБэЕФИќКУЕФЬцДњЗНАИЃЌЦфгажюЖргХЕуЃЌФмЙЛжЇГжЫЎЦНЕЏадРЉШнЃЌМцШнДѓВПЗж
Mysql авщЃЌСуГЩБОЧЈвЦЃЌжЇГжИїРр Mysql ВйзїЙЄОпЃЌЬьЩњЕФШнджЬиадЕШЁЃЕЋЪЧЃЌгагХЪЦЯрЖдвВгаЮўЩќЃЌДюНЈ
TiDB ЕФЩњВњЛЗОГвЊЧѓБШНЯИпЃЌВПЪ№вЛЬзМЏШКжСЩйашвЊ 5 ЬЈИпадФмЛњЦїЁЃ
TiDB етПюВњЦЗдкПьЫйЗЂеЙжаЃЌдкЪЕМљЙ§ГЬжаЃЌЛсгіЕНИїжжЮЪЬтЃЌБОЮФзмНсСЫ 10 ИіЯрЙиЮЪЬтКЭНтОігХЛЏЗНЗЈЃЌжМдкФмЙЛИќКУЕФАяжњаТЪжЩЯЪжЁЃ
ОнСЫНтЃЌИїДѓЙЋЫОвбОЯрМЬДюНЈКЭЪЙгУСЫ TiDB МЏШКЃЌЪЙгУБШНЯЙуЗКЃЌДѓМвПЩвдЗХаФЕФНЋ TiDB ж№НЅгІгУЕНашвЊЕФвЕЮёжаЁЃ
| 







