| БрМЭЦМі: |
БОНкжївЊНщЩмTsFileЫїв§ПщЕФзщГЩЁЂЫїв§ПщЕФВщбЏЙ§ГЬЁЂЫїв§ПщФПЧАдкзіЕФИФНјЯюЁЃ
БОЮФРДздПЊдДВЉПЭ ЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
ЩЯвЛеТСФЕН TsFile ЕФЮФМўзщГЩЃЌвдМАЪ§ОнПщЕФЯъЯИНщЩмЁЃЯъЧщЧыМћЃК
ЪБађЪ§ОнПт Apache-IoTDB дДТыНтЮіжЎЮФМўЪ§ОнПщЃЈЫФЃЉ
Ыїв§Пщ
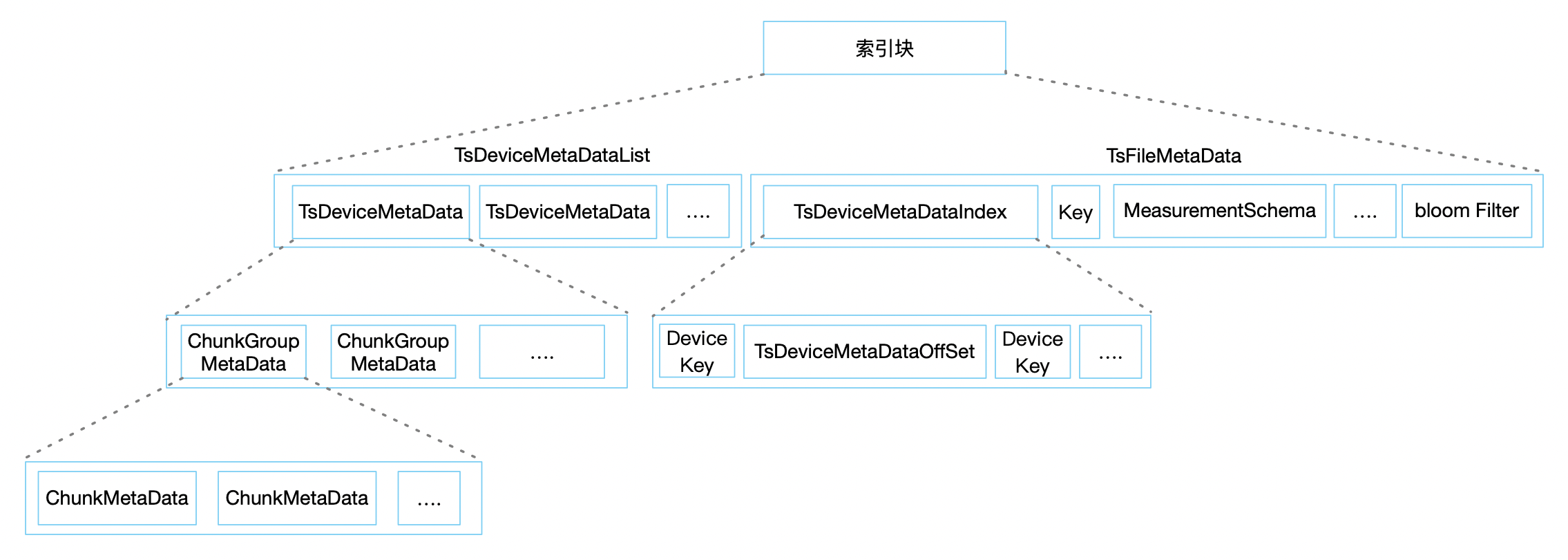
Ыїв§ПщгЩСНДѓВПЗжзщГЩЃЌЦфаДШыЕФЗНЪНЪЧДгзѓЕНгваДШыЃЌвВОЭЪЧДгЮФМўЭЗЯђЮФМўЮВаДШыЁЃЕЋЖСГіЕФЗНЪНЪЧЯШЖСГіTsFileMetaData
дйЖСГі TsDeviceMetaDataList жаЕФОпЬхвЛВПЗжЁЃЮвУЧАДееЖСШЁЪ§ОнЕФЫГађНщЩмЃК
TsFileMetaData
TsFileMetaDataЪєгкЮФМўЕФ 1 МЖЫїв§ЃЌгУРДЫїв§ Device ЪЧЗёДцдкЁЂдкФФРяЕШаХЯЂЃЌЦфжажївЊБЃДцСЫЃК
DeviceMetaDataIndexMapЃКMapНсЙЙЃЌKey ЪЧЩшБИУћЃЌValue ЪЧ TsDeviceMetaDataIndex
ЃЌБЃДцСЫАќКЌФФаЉ DeviceЃЈТпМИХФюЩЯЕФвЛИіМЏКЯвЛЖЮЪБМфФкЕФЪ§ОнЃЌР§ШчЧАМИеТЮвУЧНВЕНЕФЃКеХШ§ЁЂРюЫФЁЂЭѕЮхЃЉвдМАЫћУЧЕФПЊЪМЪБМфМАНсЪјЪБМфЁЂдкзѓВр
TsDeviceMetaDataList ЮФМўПщжаЕФЦЋвЦСПЕШЁЃ
MeasurementSchemaMapЃКMapНсЙЙЃЌKey ЪЧВтЕуЕФвЛИіШЋТЗОЖЃЌValue ЪЧ measurementSchema
ЃЌБЃДцСЫАќКЌЕФВтЕуЪ§Он(ТпМИХФюЩЯЕФФГвЛРрЪ§ОнЕФМЏКЯ,ШчЬхЮТЪ§Он)ЕФдаХЯЂЃЌШчЃКбЙЫѕЗНЪНЃЌЪ§ОнРраЭЃЌБрТыЗНЪНЕШЁЃ
зюКѓЪЧвЛИіВМТЁЙ§ТЫЦїЃЌПьЫйМьВтФГвЛИі ЪБМфађСа ЪЧВЛЪЧДцдкгкЮФМўФк(етРяЕШСФЕН server ФЃПщаДЮФМўЕФВпТдЪБКђдйСФ)ЁЃЮвУЧжЊЕРетИіЙ§ТЫЦїЕФЬиЕуОЭЪЧЃКУЛгаЕФвЛЖЈУЛгаЃЌЕЋгаЕФВЛвЛЖЈгаЁЃЮЊСЫБЃжЄзМШЗадКЭЙ§ТЫЦїађСаЛЏКѓЕФДѓаЁОљКтЃЌетРяЬсЙЉСЫвЛИі
1% - 10% ДэЮѓТЪЕФПЩХфжУЃЌЕБЮЊ 1% ДэЮѓТЪЪБЃЌБЃДц 1 ЭђИіВтЕуаХЯЂЃЌДѓИХЪЧ 11.7 KЁЃ
ЮвУЧдйЛиЯы SQL ЃКSELECT ЬхЮТ FROM ЭѕЮх WHERE time = 1 ЁЃЖСЮФМўЕФЙ§ГЬОЭгІИУЪЧЃК
ЯШгУВМТЁЙ§ТЫЦїХаЖЯЮФМўФкЪЧЗёгаЭѕЮхЕФЬхЮТСаЃЌШчЙћУЛгаЃЌВщевЯТвЛИіЮФМўЁЃ
Дг DeviceMetaDataIndexMap жаевЕНЭѕЮхЕФ TsDeviceMetaDataIndex
ЃЌДгЖјЕУЕНСЫЭѕЮхЕФ TsDeviceMetadata ЕФ offsetЃЌНгЯТРДОЭбАЕРжСетИі offset
АбЭѕЮхЕФ TsDeviceMetadata ЖСГіРДЁЃ
MeasurementSchemaMap ВЛгУЙизЂЃЌжївЊЪЧИј Spark ЪЙгУЕФЃЌChunkHeader
жавВБЃДцСЫетаЉаХЯЂЁЃ
TsDeviceMetaDataList
TsDeviceMetaDataList ЪєгкЮФМўЕФ 2 МЖЫїв§ЃЌгУРДЫїв§ОпЬхЕФВтЕуЪ§ОнЪЧВЛЪЧДцдкЁЂдкФФРяЕШаХЯЂЁЃЦфжажївЊБЃДцСЫЃК
ChunkGroupMetaDataЃКChunkGroup ЕФЫїв§аХЯЂЃЌжївЊАќКЌСЫУПИі ChunkGroup
Ъ§ОнПщЕФЦ№жЙЮЛжУвдМААќКЌЕФЫљгаЕФВтЕудЊаХЯЂЃЈChunkMetaDataЃЉЁЃ
ChunkMetaData ЃКChunk ЕФЫїв§аХЯЂЃЌжївЊАќКЌСЫУПИіЩшБИЕФВтЕудкЮФМўжаЕФЦ№жЙЮЛжУЁЂПЊЪМНсЪјЪБМфЁЂЪ§ОнРраЭКЭдЄОлКЯаХЯЂЁЃ
ЩЯУцЕФР§згжаЃЌДг TsFileMetadata вбОФУЕНСЫЭѕЮхЕФ TsDeviceMetadataIndexЃЌетРяОЭПЩвджБНгЖСГіЭѕЮхЕФ
TsDeviceMetadataЃЌВЂЧвБщРњРяБпЕФ ChunkGroupMetadata жаЕФ ChunkMetadataЃЌевЕНЬхЮТЖдгІЕФЫљгаЕФ
ChunkMetadataЁЃЭЈЙ§дЄОлКЯаХЯЂЖдЪБМфЙ§ТЫЃЌХаЖЯФмЗёЪЙгУЕБЧАЕФ Chunk ЛђепФмЗёжБНгЪЙгУдЄОлКЯаХЯЂжБНгЗЕЛиЪ§Он(ЕШНщЩмЕН
server ЕФВщбЏв§ЧцЪБКђЯИСФ)ЁЃ
ШчЙћВЛФмжБНгЗЕЛиЃЌвђЮЊ ChunkMetaData АќКЌСЫетИі Chunk ЖдгІЕФЮФМўЕФЦЋвЦСПЃЌжЛашвЊЪЙгУ
seek(offSet) ОЭЛсЬјзЊЕНЪ§ОнПщЃЌЪЙгУЩЯвЛеТНщЩмЕФЖСШЁЗНЗЈНјааБщРњОЭЭъГЩСЫећИіЖСШЁЁЃ
дЄОлКЯаХЯЂЃЈStatisticsЃЉ
ЮФжаЖрДЮЬсЕНСЫдЄОлКЯдкетРяЯъЯИНщЩмвЛЯТЫќЕФЪ§ОнНсЙЙЁЃ
// ЫљЪєЮФМўПщЕФПЊЪМЪБМф
private long startTime;
// ЫљЪєЮФМўПщЕФНсЪјЪБМф
private long endTime;
// ЫљЪєЮФМўПщЕФЪ§ОнРраЭ
private TSDataType tsDataType;
// ЫљЪєЮФМўПщЕФзюаЁжЕ
private int minValue;
// ЫљЪєЮФМўПщЕФзюДѓжЕ
private int maxValue;
// ЫљЪєЮФМўПщЕФЕквЛИіжЕ
private int firstValue;
// ЫљЪєЮФМўПщЕФзюКѓвЛИіжЕ
private int lastValue;
// ЫљЪєЮФМўПщЕФЫљгажЕЕФКЭ
private double sumValue; |
етИіНсЙЙжївЊБЃДцдк ChunkMetaData КЭ PageHeader жаЃЌетбљзіЕФКУДІОЭЪЧЃЌФуВЛБиДггВХЬжаЖСШЁОпЬхЕФPage
Лђеп Chunk ЕФЮФМўФкШнОЭПЩвдЛёЕУзюжеЕФНсЙћЃЌР§ШчЃКSELECT SUM(ЬхЮТ) FROM ЭѕЮх
ЃЌЕБЖЈЮЛЕН ChunkMetaData ЪБЃЌХаЖЯФмЗёжБНгЪЙгУетИі Statistics аХЯЂЃЈОпЬхдѕУДХаЖЯЃЌжЎКѓЛсдкНщЩм
server ЪБОпЬхНщЩмЃЉЃЌШчЙћФмЪЙгУЃЌФЧУДжБНгЗЕЛи sumValueЁЃетбљЗЕЛиЕФЫйЖШЃЌЮоТлДцСЫЖрЩйЪ§ОнЃЌЫќЕФОлКЯНсЙћЯьгІЪБМфМђжБОЭЪЧ
1 КСУывдФкЁЃ
бљР§Ъ§Он
ЮвУЧМЬајЪЙгУЩЯвЛеТСФЕНЕФЪОР§Ъ§ОнРДеЙЪОЁЃ
| ЪБМфДС |
ШЫУћ |
ЬхЮТ |
аФТЪ |
| 1580950800 |
ЭѕЮх |
36.7 |
100 |
| 1580950911 |
ЭѕЮх |
36.6 |
90 |
ЭъећЕФЮФМўаХЯЂШчЯТЃК
POSITION| CONTENT
-------- -------
0| [magic head] TsFile
6| [version number] 000002
// Ъ§ОнПщПЊЪМ
||||||||||||||||||||| [Chunk Group] of wangwu
begins at pos 12, ends at pos 253, version:0,
num of Chunks:2
12| [Chunk] of xinlv, numOfPoints:1, time range: [1580950800,1580950800],
tsDataType:INT32,
[minValue:100,maxValue:100, firstValue:100, lastValue:100, sumValue:100.0]
| [marker] 1
| [ChunkHeader]
| 1 pages
121| [Chunk] of tiwen, numOfPoints: 1, time range: [1580950800,1580950800],
tsDataType: FLOAT,
[minValue:36.7,maxValue:36.7, firstValue:36.7, lastValue:36.7, sumValue: 36.70000076293945]
| [marker] 1
| [ChunkHeader]
| 1 pages
230| [Chunk Group Footer]
| [marker] 0
| [deviceID] wangwu
| [dataSize] 218
| [num of chunks] 2
||||||||||||||||||||| [Chunk Group] of wangwu
ends
// Ыїв§ПщПЊЪМ
253| [marker] 2
254| [TsDeviceMetadata] of wangwu, startTime:1580950800,
endTime:1580950800
| [startTime] 1580950800
| [endTime] 1580950800
| [ChunkGroupMetaData] of wangwu, startOffset12,
endOffset253, version:0, numberOfChunks:2
| [ChunkMetaData] of xinlv, startTime:1580950800,
endTime:1580950800, offsetOfChunkHeader:12, dataType:INT32,
statistics:[minValue:100, maxValue:100,firstValue:100, lastValue:100,sumValue:100.0]
| [ChunkMetaData] of tiwen, startTime:1580950800,
endTime:1580950800, offsetOfChunkHeader: 121,
dataType:FLOAT, statistics:[minValue: 36.7, maxValue:
36.7, firstValue:36.7, lastValue:36.7, sumValue:
36.70000076293945]
446| [TsFileMetaData]
| [num of devices] 1
| [TsDeviceMetadataIndex] of wangwu, startTime:
1580950800, endTime: 1580950800, offSet:254, len:192
| [num of measurements] 2
| 2 key& measurementSchema
| [createBy isNotNull] false
| [totalChunkNum] 2
| [invalidChunkNum] 0
//ВМТЁЙ§ТЫЦї
| [bloom filter bit vector byte array length]
30
| [bloom filter bit vector byte array]
| [bloom filter number of bits] 256
| [bloom filter number of hash functions] 5
599| [TsFileMetaDataSize] 153
603| [magic tail] TsFile
609| END of TsFile |
ЕБжДааЃК SELECT ЬхЮТ FROM ЭѕЮх ЪБЃК
Дг 599 ПЊЪМЖСЃЌ1 МЖЫїв§ГЄЖШЮЊ 153.
599 - 153 = 446 ОЭЪЧ 1 МЖЫїв§ЖСПЊЪМЮЛжУЃЌВЂЖСГі TsDeviceMetadataIndex
of ЭѕЮхЃЌЦфжаМЧТМСЫЃЌЭѕЮхЩшБИЕФ 2 МЖЫїв§ЕФ offset ЮЊ 254.
ЬјЕН 254 ПЊЪМЖС 2 МЖЫїв§ЃЌевЕН ChunkMetaData of ЬхЮТЃЌ ЦфжаМЧТМСЫЬхЮТЪ§ОнЕФ
Chunk ЕФoffset ЮЊ 121
ЬјЕН 121 ЃЌетРяНјШыСЫЪ§ОнПщЃЌДг 121 ЖСШЁЕН 230 ЃЌЖСГіЕФЪ§ОнОЭШЋВПЪЧЬхЮТЪ§ОнЁЃ
ИФНјЯю
1. жЛЖСЭЖгАСа
ЧАУцЕк 3 ВНжаЃЌЖСШЁ 2 МЖЫїв§ЪБКђЃЌЛсНЋетИіЩшБИЯТЕФЫљгаВтЕуЪ§ОнШЋВПЖСГіРДЃЌетвРШЛВЛЬЋЗћКЯжЛЖСЭЖгАСаЕФЩшМЦЃЌЫљвддкаТЕФ
TsFile жаЃЌаоИФСЫ 1МЖЫїв§КЭ 2 МЖЫїв§ЕФВПЗжНсЙЙЃЌЪЙЕУЖСГіЕФЪ§ОнИќЩйЃЌИќИпаЇЁЃгааЫШЄЕФЭЌбЇПЩвдЙизЂ
PRЃК Refactor TsFile #736
2. ЮФМўМЖ Statistics
дкЮяСЊЭјГЁОАжаОГЃЛсЩцМАЕНВщбЏФГИіЩшБИЕФзюКѓзДЬЌЃЌБШШчЃКГЕСЊЭјжаЃЌВщбЏГЕСОЕФФЉДЮЮЛжУ( SELECT
LAST(lat,lon) FROM VechicleID )ЃЌЛђепЕБЧАЕФЕуЛ№ЁЂЯЈЛ№зДЬЌЕШ SELECT
LAST(accStatus) FROM VechicleID ЁЃ
ЛђепЕБФГаЉЗжвГВщбЏЕШЧщПіЪБКђЃЌОГЃЛсЪЙгУЕН COUNT(*) ЕШВйзїЃЌетаЉЖМЗЧГЃЗћКЯ Statistics
НсЙЙЃЌетаЉГЁОАЩцМАЕНЕФЫїв§ЩшМЦвВЖМЛсЬхЯжЕНаТЕФ TsFile Ыїв§ИФЖЏжаЁЃ
ЕНДЫвбОНщЩмЭъСЫЮФМўЕФећЬхНсЙЙЃЌСЫНтСЫДѓЬхЕФаДШыКЭЖСШЁЙ§ГЬЃЌЕЋЪЧ TsFile ЕФ API ЪЧШчКЮЩшМЦЕФЃЌдѕбљдкДњТыРязівЛаЉЬиЪтЕФЙІПЮЃЌРДШЦЙ§
Java зАЯфЁЂGC ЕШЮЪЬтФиЃПЛЖгГжајЙизЂЁЃЁЃЁЃЁЃ
|








