| БрМЭЦМі: |
БОНкжївЊНщЩм
СЫIoTDB ЪЧЪВУДЃПвдМАЯрЙиЕФгІгУГЁОАЁЃ
БОЮФРДздЮЂаХїшЫМУюЯыЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
IotDBМђНщ
Apache IoTDB(ЮяСЊЭјЪ§ОнПт)ЪЧвЛЬхЛЏЪеМЏЁЂДцДЂЁЂЙмРэгыЗжЮіЮяСЊЭјЪБађЪ§ОнЕФШэМўЯЕЭГЁЃApache
IoTDB ВЩгУЧсСПЪНМмЙЙЃЌОпгаИпадФмКЭЗсИЛЕФЙІФмЃЌВЂгыApache HadoopЁЂSparkКЭFlinkЕШНјааСЫЩюЖШМЏГЩЃЌПЩвдТњзуЙЄвЕЮяСЊЭјСьгђЕФКЃСПЪ§ОнДцДЂЁЂИпЫйЪ§ОнЖСШЁКЭИДдгЪ§ОнЗжЮіашЧѓЁЃ
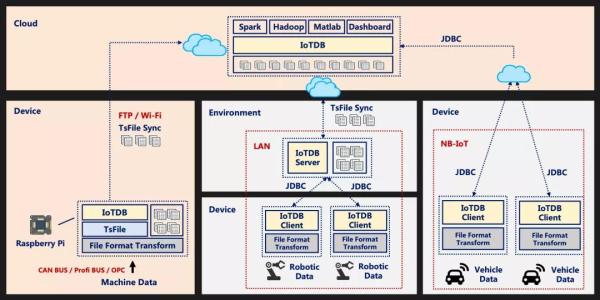
гІгУГЁОА
ИпЖЫЩшБИ
дкИпЖЫжЦдьвЕжаЃЌгаКмЖрЩшБИХфБИгаДЋИаЦїРДЪеМЏЙЄзїзДЬЌЪ§ОнЃЌР§ШчЦјЯѓеОЃЌЗчСІЮаТжЛњЪЧГЃМћЕФИпЖЫЩшБИЁЃетаЉЩшБИШчЙћжЇГжJavaЛђGo(е§дкПЊЗЂжа)ЃЌдђПЩвддЫааTsFileдкБОЕиДцДЂЪ§ОнЁЃЭЈЙ§етжжЗНЪНЃЌTsFileПЩвдЬсЙЉОпгаИпЭЬЭТЁЂИпбЙЫѕТЪКЭКСУыМЖВщбЏбгГйЕФЪ§ОнЙмРэЙІФмЁЃНсКЯTsFile-SyncЙЄОпЃЌПЩвдНЋTsFilesЭЌВНЕНЪ§ОнжааФЁЃ
БОЕиПижЦЦї
дкЙЄГЇЯжГЁЃЌLANЭјТчЯТгаЪ§ЪЎЬЈЩшБИЁЃIoTDBПЩвдАВзАдкЙЄГЇЕФБОЕиПижЦЦїЗўЮёЦїЩЯЃЌвдДгетаЉЩшБИНгЪеЪ§ОнЁЃАВзАгаIoTDBЕФБОЕиЗўЮёЦї(ЦеЭЈPCЛђЙЄзїеО)ПЩвдЪЙгУРрSQLДцДЂКЭВщбЏЪ§ОнЁЃДЫЭтЃЌЪЙгУTsFile-SyncЙЄОпЃЌПЩвдНЋБОЕиПижЦЦїЩЯЕФTsFileЮФМўДЋЪфЕНдЦЩЯАВзАгаIoTDBЪЕР§ЕФЪ§ОнжааФЁЃ
дЦЪ§ОнЙмРэ
дкИпЫйЭјТч(ГЕСЊЭјЕШ)ЕФГЁОАжаЃЌАВзАгаДЋИаЦїЕФЦћГЕПЩвдвдвЛЖЈЦЕТЪЪеМЏздЩэЕФМрЪгаХЯЂ(ааЪЛзДЬЌЕШ)ЁЃЭЈГЃЃЌетаЉЦћГЕЩшБИЕФгВМўХфжУгаЯоЃЌВЂЧвФбвдНјааИДдгЕФгІгУЁЃЧсСПМЖЕФIoTDB(IoTDBПЭЛЇЖЫ)гІдЫЖјЩњЁЃНшжњJDBC
API(ЛђMQTT)ЃЌЫќПЩвдЪЙгУеДјIoTЛђ4G/5GЗЂЫЭЪ§ОнЃЌДгЖјНЋЩшБИКЭдЦСЌНгдквЛЦ№ЁЃ
ДцДЂМмЙЙ
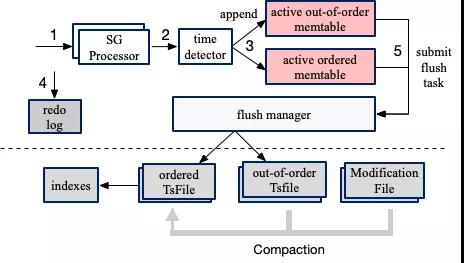
IoTDB ДцДЂв§ЧцЛљгк LSM Tree НсЙЙЩшМЦЃЌаДШыЕФЪ§ОнЯШМЧТМ WALЃЌдйаДЕНФкДц memtableЃЌдкКѓЬЈж№ВНЫЂЕНДХХЬ
TsFile;ДХХЬЩЯЕФ TsFile ЭЈЙ§вЛЖЈЕФЙцдђНјаа CompactionЃЌБЃжЄВщбЏаЇТЪЁЃ
ФЧУДЮвУЧОЭЯШДгLSM Tree ЫЕЦ№АЩЁЃ
LSM Tree
LSM Tree(Log Structured Merge Tree) ВЂВЛЯёB+ЪїЁЂКьКкЪївЛбљЪЧвЛПХбЯИёЕФЪїзДЪ§ОнНсЙЙЃЌЦфЪЕЫќЪЧвЛжжДцДЂНсЙЙЃЌФПЧАHBase,LevelDB,RocksDBетаЉNoSQLДцДЂЖМЪЧВЩгУЕФLSMЪїЁЃ
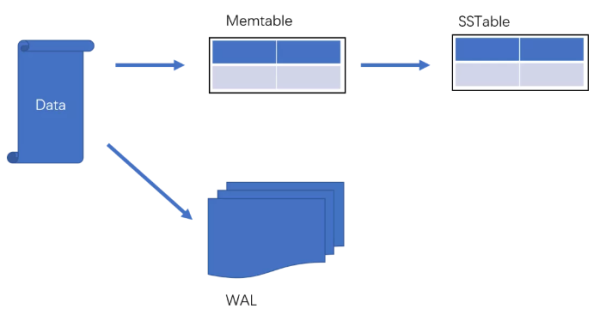
Mentable
MemTableЪЧдкФкДцжаЕФЪ§ОнНсЙЙЃЌгУгкБЃДцзюНќИќаТЕФЪ§ОнЃЌЛсАДееKeyгаађЕизщжЏетаЉЪ§ОнЃЌLSMЪїЖдгкОпЬхШчКЮзщжЏгаађЕизщжЏЪ§ОнВЂУЛгаУїШЗЕФЪ§ОнНсЙЙЖЈвхЃЌР§ШчHbaseЪЙЬјдОБэРДБЃжЄФкДцжаkeyЕФгаађЁЃ
вђЮЊЪ§ОнднЪББЃДцдкФкДцжаЃЌФкДцВЂВЛЪЧПЩППДцДЂЃЌШчЙћЖЯЕчЛсЖЊЪЇЪ§ОнЃЌвђДЫЭЈГЃЛсЭЈЙ§WAL(Write-ahead
loggingЃЌдЄаДЪНШежО)ЕФЗНЪНРДБЃжЄЪ§ОнЕФПЩППадЁЃ
SSTable(Sorted String Table)
гаађМќжЕЖдМЏКЯЃЌЪЧLSMЪїзщдкДХХЬжаЕФЪ§ОнНсЙЙЁЃЮЊСЫМгПьSSTableЕФЖСШЁЃЌПЩвдЭЈЙ§НЈСЂkeyЕФЫїв§вдМАВМТЁЙ§ТЫЦїРДМгПьkeyЕФВщевЁЃ
ЮвУЧдкаДШыЪ§ОнЪБЃЌЪзЯШНЋЖдЪ§ОнЕФаоИФдіСПБЃДцMemtableжаЃЌЭЌЪБЛсЬсНЛwal,ЕБMemtableДяЕНжИЖЈДѓаЁЯожЦжЎКѓХњСПАбЪ§ОнЫЂЕНДХХЬ(SSTable)жаЃЌДХХЬжаЪїЖЈЦкПЩвдзіmergeВйзїЃЌКЯВЂГЩвЛПУДѓЪїЃЌвдгХЛЏЖСадФмЁЃВЛЙ§ЖСШЁЕФЪБКђЩдЮЂТщЗГвЛаЉЃЌЖСШЁЪБПДетаЉЪ§ОндкФкДцжаЃЌШчЙћЮДФмУќжаФкДцЃЌдђашвЊЗУЮЪНЯЖрЕФДХХЬЮФМўЁЃМЋЖЫЕФЫЕЃЌЛљгкLSMЪїЪЕЯжЕФhbaseаДадФмБШmysqlИпСЫвЛИіЪ§СПМЖЃЌЖСадФмШДЕЭСЫвЛИіЪ§СПМЖЁЃ
злЩЯЫљЪіЃЌLSMЪїЛсНЋЪ§ОнЕФЫљгадіЁЂЩОЁЂИФЕШВйзїЃЌМЧТМЕНФкДцжаЃЌдйЫГађЫЂаТЕНДХХЬРяЃЌетОЭдьГЩСЫЦфгыB+ЪїзюДѓЕФВЛЭЌЃЌB+ЪїЛсжБНгдкЪ§ОнЕФЮЛжУИќаТЃЌЖјLSMЪїдђПЩФмзЗЕНЕНВЛЭЌЕФSSTableжаЃЌЕБШЛЃЌзюаТЕФФЧЬѕМЧТМВХЪЧзМШЗЕФЁЃетбљЩшМЦЕФЫфШЛДѓДѓЬсИпСЫаДадФмЃЌЕЋЭЌЪБвВЛсДјРДвЛаЉЮЪЬтЃК
1)ШпгрДцДЂЃЌЖдгкФГИіkeyЃЌЪЕМЪЩЯГ§СЫзюаТЕФФЧЬѕМЧТМЭтЃЌЦфЫћЕФМЧТМЖМЪЧШпгрЮогУЕФЃЌЕЋЪЧШдШЛеМгУСЫДцДЂПеМфЁЃвђДЫашвЊНјааCompactВйзї(КЯВЂЖрИіSSTable)РДЧхГ§ШпгрЕФМЧТМЁЃ2)ЖСШЁЪБашвЊДгзюаТЕФЕЙзХВщбЏЃЌжБЕНевЕНФГИіkeyЕФМЧТМЁЃзюЛЕЧщПіашвЊВщбЏЭъЫљгаЕФSSTableЃЌетРяПЩвдЭЈЙ§ЧАУцЬсЕНЕФЫїв§/ВМТЁЙ§ТЫЦїРДгХЛЏВщевЫйЖШЁЃ
бЙЫѕ(Compact)ВпТд
дке§ЪННщЩмбЙЫѕВпТдвдЧАЃЌЮвУЧгаБивЊЯШСЫНтвЛЯТет3ИіЛљДЁИХФюЃЌетвВЪЧвдЯТбЙЫѕВпТдашвЊШЈКтЕФЙиМќЃКЖСЗХДѓ(Read
Amplifier)ЁЂаДЗХДѓ(Write Amplifier)ЁЂПеМфЗХДѓ(Space Amplifier)
ЖСЗХДѓ(Read Amplifier):ЪЧжИЮвУЧвЊевЕНвЛИіЮвУЧЫљашЕФЪ§ОнЃЌашвЊНјааЖрЩйДЮДХХЬЕФЖСВйзїЁЃР§ШчЮвУЧГіУХЧАашвЊевдПГзЃЌФуПЩФмвЊУПИіЗПМфЃЌУПМўвТЗўПкДќЗвЛБщЁЃетВЂВЛгІИУЪЧвЛИіе§ГЃВйзїЁЃ
аДЗХДѓ(Write Amplifier):аДШыЪ§ОнЪБЪЕМЪаДШыЕФЪ§ОнСПДѓгкеце§ЕФЪ§ОнСПЁЃР§ШчдкLSMЪїжааДШыЪБПЩФмДЅЗЂCompactВйзїЃЌЕМжТЪЕМЪаДШыЕФЪ§ОнСПдЖДѓгкИУkeyЕФЪ§ОнСПЁЃ
ПеМфЗХДѓ(Space Amplifier):Ъ§ОнЪЕМЪеМгУЕФДХХЬПеМфБШЪ§ОнЕФеце§ДѓаЁИќЖрЁЃЩЯУцЬсЕНЕФШпгрДцДЂЃЌЖдгквЛИіkeyРДЫЕЃЌжЛгазюаТЕФФЧЬѕМЧТМЪЧгааЇЕФЃЌЖјжЎЧАЕФМЧТМЖМЪЧПЩвдБЛЧхРэЛиЪеЕФЁЃ
size-tiered ВпТд
size-tieredВпТдЯрЖдМђЕЅДжБЉЃЌЦфжїжМБЃжЄУПВуSSTableЕФДѓаЁЯрНќЃЌЭЌЪБЯожЦУПВуSSTableЕФЪ§СПЁЃШчЯТЭМЫљЪОЃЌУПВуЯожЦSSTableЮЊNЃЌЕБУПВуSSTableДяЕНNКѓЃЌдђДЅЗЂCompactВйзїКЯВЂетаЉSSTableЃЌВЂНЋКЯВЂКѓЕФНсЙћаДШыЕНЯТвЛВуГЩЮЊвЛИіИќДѓЕФsstableЁЃ
гЩДЫПЩвдПДГіЃЌЕБВуЪ§ДяЕНвЛЖЈЪ§СПЪБЃЌзюЕзВуЕФЕЅИіSSTableЕФДѓаЁЛсБфЕУЗЧГЃДѓЁЃВЂЧвsize-tieredВпТдЛсЕМжТПеМфЗХДѓБШНЯбЯжиЁЃМДЪЙЖдгкЭЌвЛВуЕФSSTableЃЌУПИіkeyЕФМЧТМЪЧПЩФмДцдкЖрЗнЕФЃЌжЛгаЕБИУВуЕФSSTableжДааcompactВйзїВХЛсЯћГ§етаЉkeyЕФШпгрМЧТМЁЃ
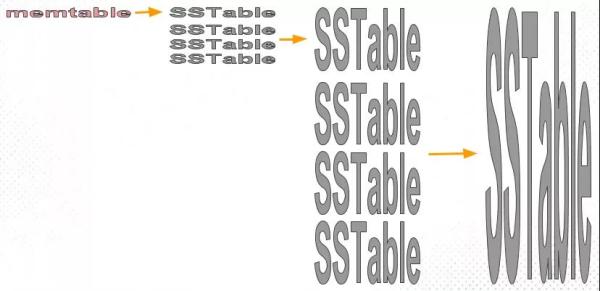
leveledВпТд
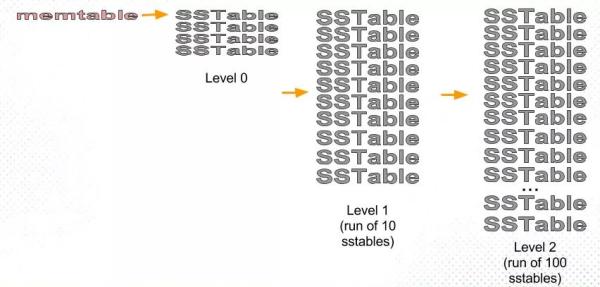
leveledВпТдвВЪЧВЩгУЗжВуЕФЫМЯыЃЌУПвЛВуЯожЦзмЮФМўЕФДѓаЁЁЃЕЋгыsize-tieredВпТдВЛЭЌЕФЪЧЃЌleveledЛсНЋУПвЛВуЧаЗжГЩЖрИіДѓаЁЯрНќЕФSSTableЁЃетаЉSSTableЪЧетвЛВуЪЧШЋОжгаађЕФЃЌетвтЮЖзХвЛИіkeyдкУПвЛВужСЖржЛга1ЬѕМЧТМЃЌВЛДцдкШпгрМЧТМЁЃВЂЧвУПВуЮЌГжЁАЮЈвЛвЛИіЁБ
RunЁЃЮвУЧРДСЫНтвЛЯТRunетИіLSMРяУцживЊЕФИХФюЃЌвдЯТеЊздWikiЃК
Each run contains data *sorted* by the index key.
A run can be represented on disk as a single file,
or alternatively as a collection of files with *non-overlapping*
key ranges.
runашвЊТњзуЪВУДЬѕМўФи?ЕквЛsortedЃЌЕкЖўnon-overlapping key ranges
ШчЯТЭМЫљЪОЃК
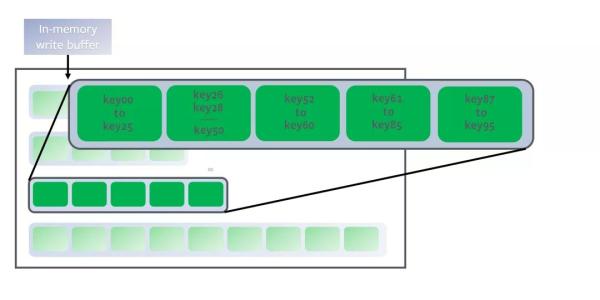
УПВуЕФДѓаЁЪЧЩЯвЛМЖЕФT(ЯТЭМЪЧ10) БЖЃЌВуЪ§дНИпЃЌdataдНЖрЕЋЪЧвВдНОЩ.УПВуЖМгаtarget
size
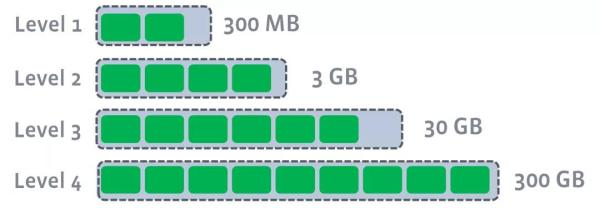
ећИіЕФЙ§ГЬПЩвдМђЛЏГЩЃКin memoryЕФtableаДТњСЫЃЌФЧУДОЭflushЕНЕквЛМЖЕФDisk SStableВЂЧвзіcompactionЃЌвЊЪЧЕквЛМЖгжТњСЫЃЌОЭгжПЊЪМflushЕНЕкЖўМЖзіcompactionЃЌвдДЫРрЭЦжБЕНmax
level, ЯТУцМИеХЭМУшЪіСЫећИіЙ§ГЬЁЃ
МйЩшШчЯТЭМЪЧЦ№ЪМзДЬЌ
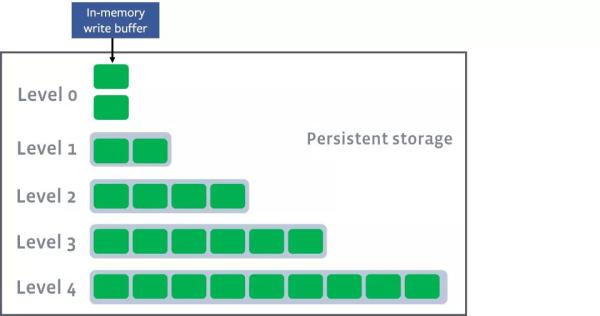
level0 гаЪ§ОнаДШыЃЌетИіЪБКђДЅЗЂlevel0ЕНlevel1ЕФcompact
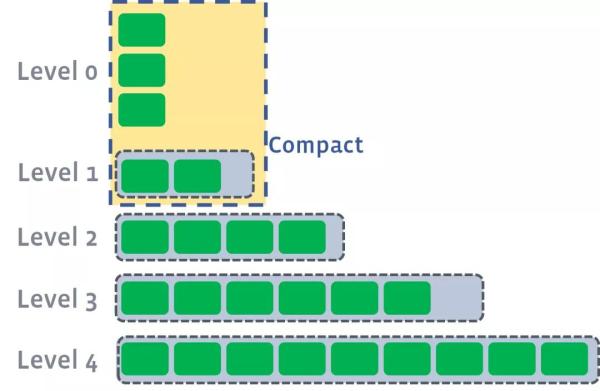
level1 ГЌГіЯожЦЃЌДЅЗЂlevel1ЕНlevel2compact
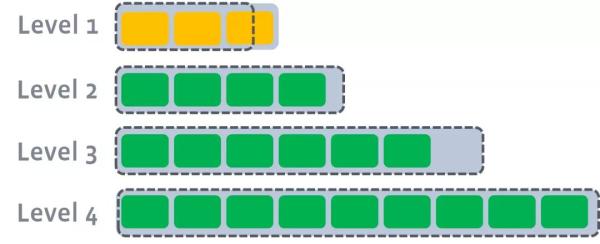
ДЫЪБЛсДгlevel1жабЁдёжСЩйвЛИіЮФМўЃЌШЛКѓАбЫќИњlevel2гаНЛМЏЕФВПЗж(ЗЧГЃЙиМќ)НјааКЯВЂЁЃЩњГЩЕФЮФМўЛсЗХдкlevel2
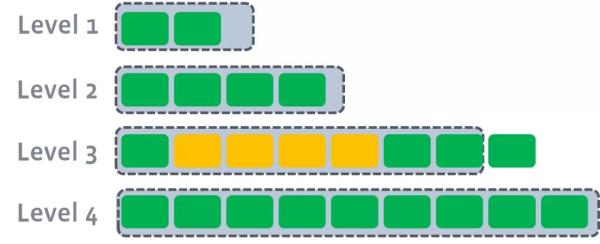
гЩгкlevel1ЕкЖўSSTableЕФkeyЕФЗЖЮЇИВИЧСЫlevel2жаЧАШ§ИіSSTableЃЌФЧУДОЭашвЊНЋlevel1жаЕкЖўИіSSTableгыlevel2жаЧАШ§ИіSSTableжДааCompactВйзїЁЃ
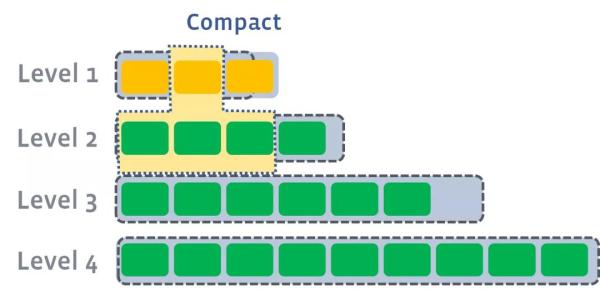
level2КЯВЂЭъГЩКѓЃЌШчЙћЦфГЌГіСЫlevel2уажЕЕФЯожЦЃЌФЧУДЛсДЅЗЂlevel2ЕНlevel3ЕФcompact
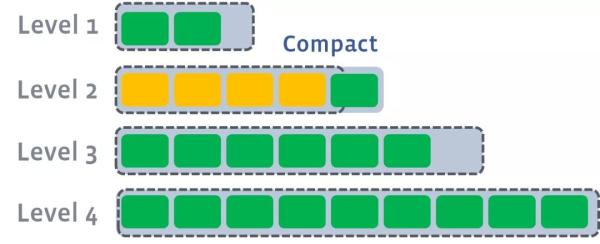
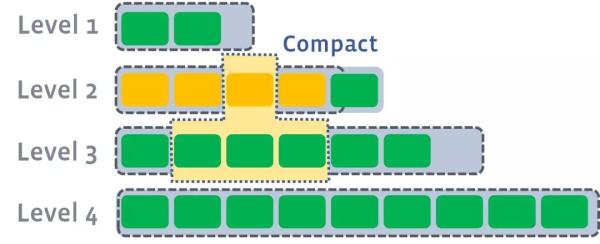
вдДЫРрЭЦЃЌЩЯвЛВуДяЕНуажЕвдКѓЃЌОЭГіДЅЗЂЕНЯТвЛВуЕФcompactВйзїЁЃ
жЕЕУвЛЬсЕФЪЧЃЌЮоТлЪЧЭЌМЖЛЙЪЧВЛЭЌМЖЃЌВЛжиЕўЕФkeyЃЌПЩвдВЂааНјааЁЃ
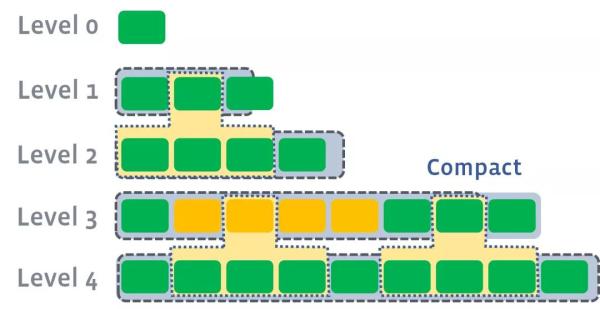
МђЕЅзмНсЃЌLevel compactionФПБъОЭЪЧЮЌГжУПИіlevelЖМБЃГжзЁone data sorted
runЃЌЫљвдУПИіlevelЖМПЩвдКЭЯТвЛИіlevelзіcompactionЃЌЭЌЪБКмгаПЩФмЛсБЛЩЯвЛИіlevelзіcompactionЁЃетбљзіКУДІОЭЪЧlevelжЎМфЕФcompactionПЩвдmultithreadРДзі(Г§СЫmemoryЕНlevel0)ЃЌЬсИпаЇТЪЁЃ
LSM Tree vs. B+ Tree vs. Hash
ЖдБШШ§жжв§ЧцЕФЪЕЯжЃК
hashДцДЂв§ЧцЃКЙўЯЃБэГжОУЛЏЕФЪЕЯжЃЌПЩвдПьЫйжЇГждіЩОИФВщЕШЫцЛњВйзїЃЌЧвЪБМфИДдгЖШЮЊo(1)ЃЌЕЋЪЧВЛжЇГжЫГађЖСШЁЩЈУшЃЌЖдгІЕФДцДЂЯЕЭГЮЊk-vДцДЂЯЕЭГЕФЪЕЯжЁЃ
bЪїДцДЂв§ЧцЪЧbЪїЕФГжОУЛЏЪЕЯжЃЌВЛНіжЇГжЕЅЬѕМЧТМЕФдіЩОИФВщВйзїЃЌЛЙжЇГжЫГађЩЈУшЃЌЖдгІЕФДцДЂЯЕЭГОЭЪЧmysqlЁЃ
lsmЪїДцДЂв§ЧцКЭbЪїДцДЂв§ЧцЃЌвЛбљжЇГжЃЌдіЩОИФВщЃЌвВжЇГжЫГађЩЈУшВйзїЁЃLSMЮўЩќСЫЖСадФмЃЌЬсИпаДадФмЁЃ
IotdbаДШыСїГЬ
ЯрЙиДњТы
org.apache.iotdb.db.engine.StorageEngine
ИКд№вЛИі IoTDB ЪЕР§ЕФаДШыКЭЗУЮЪЃЌЙмРэЫљгаЕФ StorageGroupProsessorЁЃ
org.apache.iotdb.db.engine .storagegroup.StorageGroupProcessor
ИКд№вЛИіДцДЂзщвЛИіЪБМфЗжЧјФкЕФЪ§ОнаДШыКЭЗУЮЪЁЃЙмРэЫљгаЗжЧјЕФTsFileProcessorЁЃ
org.apache.iotdb.db.engine .storagegroup.TsFileProcessor
ИКд№вЛИі TsFile ЮФМўЕФЪ§ОнаДШыКЭЗУЮЪЁЃ
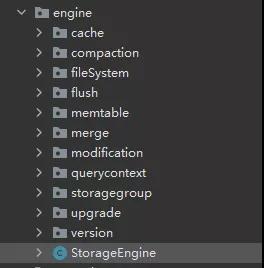
етЦЊЮФеТЃЌЮвУЧЯШНщЩмЕНетРя.
| 







