| БрМЭЦМі: |
БОЮФжївЊЪ§ОнКўЦНЬЈМђНщЁЂЪ§ОнНЈЩшзМдђЁЂЕфаЭЪ§ОнгІгУГЁОАЁЂITШежОЪ§ОнЁЂЪ§ОнДцДЂЗНАИМАЪ§ОнЩшМЦЙцЗЖЕШЁЃ
БОЮФРДздЫбКќЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
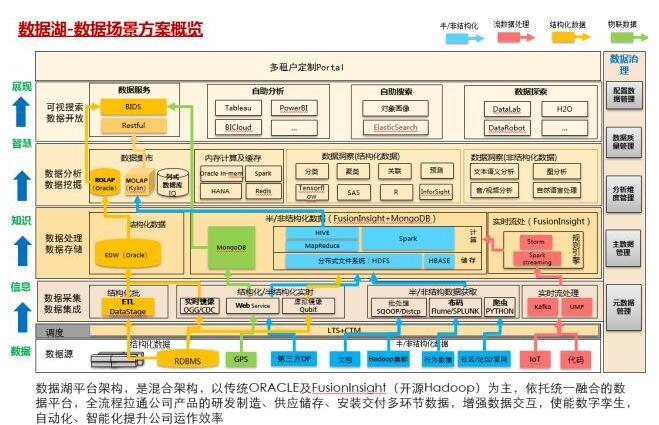
Ъ§ОнКўЦНЬЈМђНщ
Ъ§ОнКўЦНЬЈЪЧвЛЬзЛьКЯМмЙЙЃЌвдДЋЭГOracleгыЛЊЮЊFusionInsight HD&LibrAЮЊжїЃЌвРЭаЭГвЛШкКЯЕФЪ§ОнЦНЬЈЃЌШЋСїГЬРЭЈЙЋЫОВњЦЗЕФбаЗЂжЦдьЁЂЙЉгІДЂДцЁЂАВзАНЛИЖЖрЛЗНкЪ§ОнЃЌдіЧПЪ§ОнНЛЛЅЃЌЪЙФмЪ§зжТЯЩњЃЌздЖЏЛЏЁЂжЧФмЛЏЬсЩ§ЙЋЫОдЫзїаЇТЪЁЃ
ИУЦНЬЈЮЇШЦЪ§ОнЗжШчЯТШ§ДѓТпМФЃПщЃК

ЯЕЭГМмЙЙШчЯТЃК
Ъ§ОнНЈЩшзМдђ
Ъ§ОнНгШыддђ
вдгІгУЧ§ЖЏЮЊжїЃЌгХЯШНЈЩшИпМлжЕЪ§зжТЯЩњЯюФПЃЛ
ШыКўЪ§ОнБиаыгаЪ§ОнЙмРэВПШЯжЄЃЌЗЂВМЖдгІЪ§ОнзЪВњБъзМЃЌЦЅХфЖдгІЪ§Онд№ШЮШЫЃЛ
Ъ§ОнНЈФЃддђвддЪМЪ§ОнЁЂЧхЯДећКЯЪ§ОнЁЂШ§ЗЖЪННсЙЙЁЂЗўЮёЛЏПэБэж№МЖЯђЩЯЙцЗЖЃЛ
ећЬхЦНЬЈашЗћКЯИпПЩгУЁЂЦНааРЉШнддђЃЌЗћКЯвЕЮё3-5ФъЕФЪ§ОнЙцЛЎЁЃ
Ъ§ОнКўжИЕМЫМЯы
ДѓЪ§ОнжЛгаПЊЗХЩњЬЌВХПЩФмзюДѓЛЏЗЂЛгМлжЕЃЌЖЉЕЅВЛРЭЈЩњВњжЦдьЁЂНЛИЖбщЪеЃЌОЭФбвддЄЙРВњФмжмЦкЁЂгУЛЇЦкЭћЕШЃЌЮвУЧБиаыЪ§ОнПЊЗХЃЌВХФмЬсЙЉИќгХжЪЕФЪ§ОнЗўЮёЁЃ
ДѓЪ§ОнХђеЭбИУЭЬиБ№ЪЧIOTгІгУЕФЦеМАЃЌЬсЩ§Ъ§ОнОЋЖШВХФмЗЂЯжИќЖрЩњВњЮЪЬтЃЌAIЫуЗЈвВашвЊДѓЪ§ОнбЕСЗФЃаЭЃЌЮвУЧашвЊгЕБЇПЊдДЃЌГжајв§ШыЙЄвЕНчгХауЦНЬЈЬсЩ§здМКЁЃ
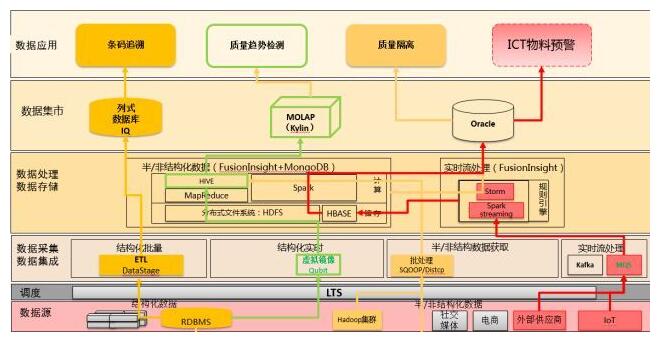
ЕфаЭЪ§ОнгІгУГЁОА
ЯТЭМАДгІгУГЁОАЃЌЖдЪ§ОнСїГЬЁЂДІРэЦНЬЈНјааЕФБъзЂЃК
ЃЈТЬЩЋЃЉНсЙЙЛЏЪ§ОнЭЈЙ§ХњДІРэЁЂащФтОЕЯёЕНHiveЪ§ОнЃЌдйЭЈЙ§KylinдЄДІРэНЋЪ§ОнДЂДцдкCubeжаЃЌЗтзАГЩRESTAPIЗўЮёЃЌЬсЙЉИпВЂЗЂбЧУыМЖВщбЏЗўЮёЃЌМрВтЮяСЯжЪСПЧщПіЃЛ
ЃЈКьЩЋЃЉIoTЪ§ОнЃЌЭЈЙ§sensorВЩМЏЩЯБЈЕНMQSЃЌзпstormЪЕЪБЗжМ№ЕНHBaseЃЌЭЈЙ§ЫуЗЈФЃаЭМгЙЄКѓНјааICTЮяСЯдЄОЏМрВтЃЛ
ЃЈЛЦЩЋЃЉЬѕТыЪ§ОнЭЈЙ§ETLloaderЕНIQСаЪНЪ§ОнКўЃЌОЙ§ЧхЯДМгЙЄКѓЃЌЬсЙЉЧЇвкЙцФЃЬѕТыЩЈУшВйзїЁЃ
IoTЪ§ОнгІгУ (Ъ§ОнГЁОАЃКSensorЪ§Он)
MQSЃЈUMPЃЉЃКИКд№ЛКДцЯћЯЂЪ§ОнЃЌЯћЯЂЖгСаЗўЮёЃЈMessage Queue ServiceЃЌМђГЦMQSЃЉЪЧеыЖдЛЊЮЊITГЁОАДђдьЕФзЈвЕЯћЯЂжаМфМўЃЌЪЧЦѓвЕМЖЛЅСЊЭјМмЙЙЕФКЫаФВњЦЗЃЌЛљгкИпПЩгУЗжВМЪНМЏШКММЪѕЃЌДюНЈСЫАќРЈЗЂВМЖЉдФЁЂЯћЯЂЙьМЃЁЂзЪдДЭГМЦЁЂМрПиБЈОЏЕШвЛЬзЭъећЕФЯћЯЂдЦЗўЮёЁЃжЇГжШЋЧђТЗгЩЁЂИєРыЭјТчЁЂдЦМфМЏГЩШ§ДѓвЕЮёГЁОАЁЃ
StormЃКhadoopЬхЯЕСїДІРэЦНЬЈ,ИКд№НЋMQSЪ§ОнНјааДІРэЗжЗЂЕНHiveЁЂHbaseЁЂOracleЕШЪ§ОнЦНЬЈДЂДцЁЃ
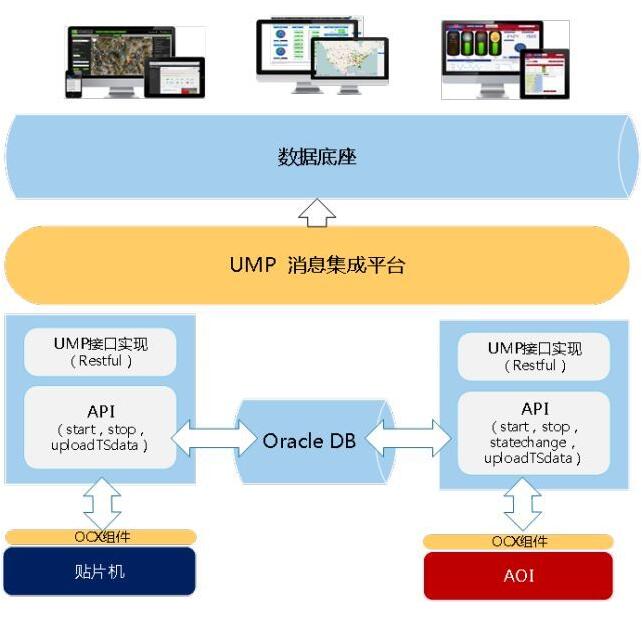
ITШежОЪ§Он
ЛёШЁITгІгУШчАьЙЋФкwebгІгУЁЂAPPгІгУЕШШежОЪ§ОнЃЌЭЈЙ§SDKЧЖШыЪЕЯжЪ§ОнЕФЪЕЪБВЩМЏЃЌЩЯБЈЕНkafkaЃЈРрЭЌгкMQSЕФЯћЯЂжаМфМўЃЉЃЌШЛКѓЭЈЙ§ХњДІРэЗНЪННјааШежОЗжЮіЁЂЗУЮЪадФмЕШЭГМЦЃЌЛђепзпFlinkНјааЪЕЪБМрВтМЦЫуЁЃ
SDжЪМьЭМЦЌЪ§Он(Ъ§ОнГЁОАЃКЗЧНсЙЙЛЏЪ§Он)
ЭЈЙ§webЧАЬЈЁЂЪ§ОнAPIЗўЮёЃЌНјааЭМЦЌЪ§ОнЕФЩЯДЋМАВщбЏЃЌЭМЦЌашвЊгаЮЈвЛIDзїЮЊБъЪОЃЌШЗБЃПЩМьЫїЁЃКЃСПЭМЦЌЪ§ОнвдIDЮЊrowkeyЃЌДЂДцгкHbaseЦНЬЈЃЌЬсЙЉПьЫйДЂДцМАВщбЏФмСІЁЃЪ§ОнзЪВњЩЯгавдЯТЗНУцЕФЙЙНЈЃК
ЭГвЛЫїв§УшЪіЗЧНсЙЙЪ§ОнЃЌЗНБуЪ§ОнМьЫїЗжЮіЁЃ
діМгЮЌЛЄМАИќаТЪБМфзїЮЊЖдЯѓУшЪізжЖЮ(ЭМЦЌРраЭЁЂЯёЫиДѓаЁЁЂГпДчЙцИё)ЁЃЗЧЖдЯѓЗНЪНМАЪ§зжЛЏЪєадБрФП(ШЋЮФЮФБОЁЂЭМЯёЁЂЩљвєЁЂгАЪгЁЂГЌУНЬхЕШаХЯЂ),здЖЈвхдЊЪ§ОнЁЃ
ВЛЭЌРраЭЕФЪ§ОнПЩвдаЮГЩСЫЙиСЊВЂДІРэЗЧНсЙЙЛЏЪ§ОнЁЃ
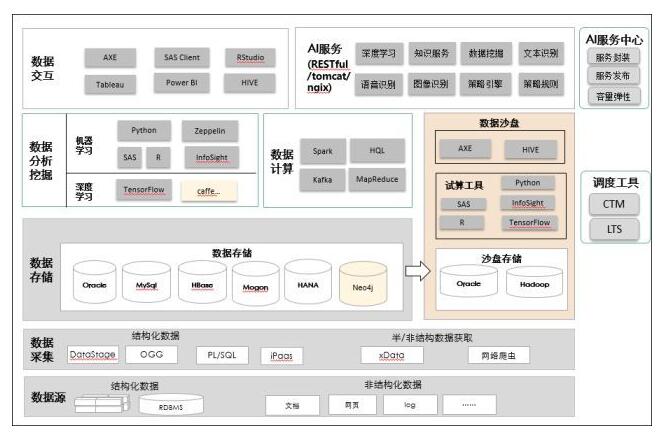
Ъ§ОнДцДЂЗНАИ
ФПЧАЪ§ОнКўДЂДцНщжЪвдFusionInsight HD&LibrAКЭOracleСНЬзЦНЬЈЮЊжїЃЌзмЬхНгШыддђЃК
ИпМлжЕМАИпШШЖШЪ§ОнЃЌвдFusionInsight HD&LibrAЛђOracleЮЊжїЃЌШчFINЪ§ОнЃЛ
ДДаТадЁЂЗЧНсЙЙЛЏЪ§ОнвдFusionInsight HDЦНЬЈЮЊжїЃЌШчЭМЦЌЁЂЪгЦЕЁЂЕиЭМЕШЪ§ОнЃЛ
ЬљдДНЈЩшЃЌШчдДЯЕЭГЮЊЙиЯЕаЭЪ§ОнПтНгШыOracleЃЌдДЯЕЭГЮЊHadoopдђЖдНгFusionInsight
HDЃЛ
СьгђМЖгХЯШНЈЩшддђЃЌШчITЁЂжЦдьЁЂбаЗЂДњТыЃЛ
ЮвУЧАДееЪ§ОнРраЭЁЂЪ§ОнЙцЗЖЁЂЪЪгУГЁОАНЈвщШчЯТЃК

Ъ§ОнЩшМЦЙцЗЖ
ШыКўЪ§ОнЃЌддђЩЯзїЮЊЩњВњЛЗОГЕФШЋСПОЕЯёЗНЪНДЂДцЃЌВПЗжЪ§ОнЩѕжСвдЪ§ОнКўзїЮЊЕквЛПЩаХдДЗЂВМЃЌГігквдЯТПМТЧЃК
Ъ§ОнКўЬхСПДѓЃЌФмРфШШБИЩњВњЪ§ОнЃЌПЩНЋБЃГжНЯГЄЪБМфЩњВњЛЗОГЪ§ОнЃЛ
OLAPЩЈУшЪ§ОнСПДѓЃЌЖрЪ§ГЁОАЛсШЋСПЩЈУшЪ§ОнЃЌетЖдOLTPЮЊжїЕФзївЕЯЕЭГЪЧВЛКЯЪЪЃЌЫљвдЮвУЧашвЊМЏжадкЪ§ОнКўжаНјааЪ§ОнЗжЮіЙЄзїЃЌКЭдЯЕЭГНтёюЁЃ
Ъ§ОнШыКўСїГЬ
МЦЫуЛњаХЯЂЛЏЯЕЭГжаЕФЪ§ОнЗжЮЊНсЙЙЛЏЪ§ОнКЭЗЧНсЙЙЛЏЪ§ОнЁЃЗЧНсЙЙЛЏЪ§ОнЦфИёЪНЗЧГЃЖрбљЃЌБъзМвВЪЧЖрбљадЕФЃЌЖјЧвдкММЪѕЩЯЗЧНсЙЙЛЏаХЯЂБШНсЙЙЛЏаХЯЂИќФбБъзМЛЏКЭРэНтЁЃЫљвдДцДЂЁЂМьЫїЁЂЗЂВМвдМАРћгУашвЊИќМгжЧФмЛЏЕФITММЪѕЃЌБШШчКЃСПДцДЂЁЂжЧФмМьЫїЁЂжЊЪЖЭкОђЁЂФкШнБЃЛЄЁЂаХЯЂЕФдіжЕПЊЗЂРћгУЕШЃЌЫљвдЮвУЧАДЪ§ОнРраЭЗжЮЊШчЯТСНДѓСїГЬЃК
НсЙЙЛЏЪ§Он
НсЙЙЛЏЪ§ОнвВГЦзїааЪ§ОнЃЌЪЧгЩЖўЮЌБэНсЙЙРДТпМБэДяКЭЪЕЯжЕФЪ§ОнЃЌбЯИёЕизёбЪ§ОнИёЪНгыГЄЖШЙцЗЖЃЌжївЊЭЈЙ§ЙиЯЕаЭЪ§ОнПтНјДцДЂКЭЙмРэЁЃ
ЗЧНсЙЙЛЏЪ§Он
ЗЧНсЙЙЛЏЪ§ОнЪЧЪ§ОнНсЙЙВЛЙцдђЛђВЛЭъећЃЌУЛгадЄЖЈвхЕФЪ§ОнФЃаЭЃЌВЛЗНБугУЪ§ОнПтЖўЮЌТпМБэРДБэЯжЕФЪ§ОнЁЃАќРЈЫљгаИёЪНЕФАьЙЋЮФЕЕЁЂЮФБОЁЂЭМЦЌЁЂXML,
HTMLЁЂИїРрБЈБэЁЂЭМЯёКЭвєЦЕ/ЪгЦЕаХЯЂЕШЕШЁЃжЇГжЗЧНсЙЙЛЏЪ§ОнЕФЪ§ОнПтВЩгУЖржЕзжЖЮЁЂСЫзжЖЮКЭБфГЄзжЖЮЛњжЦНјааЪ§ОнЯюЕФДДНЈКЭЙмРэЃЌЙуЗКгІгУгкШЋЮФМьЫїКЭИїжжЖрУНЬхаХЯЂДІРэСьгђЁЃ
НЈФЃБивЊвЊЧѓЃКЭГвЛЫїв§УшЪіЗЧНсЙЙЪ§ОнЃЌЗНБуЪ§ОнМьЫїЗжЮіЃЌПЩдіМгЮЌЛЄШЫдБМАИќаТЪБМфзїЮЊЖдЯѓУшЪізжЖЮЁЃ
ЗЧНсЙЙЛЏДЂДцЃЌЪЧЖдЖдЯѓЗНЪНМАЪ§зжЛЏЪєадБрФП,здЖЈвхдЊЪ§Он,ЙиСЊДѓСПЗЧНсЙЙЛЏвьЙЙЪ§ОнВЩгУЭГвЛЕФЮФМўдЊЪ§ОнЖдЪ§ОнНјааНЈФЃ,УПвЛИідЊЪ§ОнПЩвдзїЮЊИУЪ§ОнЕФвЛИіЮЌЖШ,Ыїв§в§ЧцЛсЖдЪ§ОнЕФУПИідЊЪ§ОнЪєадНјааЖрЮЌЫїв§,етбљВЛЭЌРраЭЕФЪ§ОнОЭПЩвдаЮГЩСЫЙиСЊВЂДІРэЗЧНсЙЙЛЏЪ§Он(ШЋЮФЮФБОЁЂЭМЯѓЁЂЩљвєЁЂгАЪгЁЂГЌУНЬхЕШаХЯЂ)ЁЃ
ДЂДцЦНЬЈЃКHBaseЁЂmongoDBЁЂHDFSЁЃ
діСПЗНЪНЃКжЇГжpushЁЂpullСНжжВпТдЃЌШчбЁдёHBaseДЂДцашПМТЧДЂДцЕФАцБОИіЪ§ЗНБувЕЮёВщПДРњЪЗАцБОЁЃ
ШчpushЗНЪНЃЌашвЕЮёЯШНЋЪ§ОнвдЯћЯЂЗНЪНЭЦЫЭMQSЃЈЯћЯЂжаМфМўЃЉЃЌЪ§ОнКўИКд№ЗжМ№ШыКўЃЛ
ШчpullЗНЪНЃЌгЩЪ§ОнКўжїЖЏВПЪ№agentЩЯБЈЁЂЛђепjdbcЕШЗНЪНШЅgetвЕЮёЪ§ОнЃЌЪЕЯжзщМќвдflumeЁЂХРГцЛђепЪ§ОнПтЧ§ЖЏЮЊжїЁЃ
| 







