| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫNebula
Graph МђНщгыМмЙЙЁЂЖрдЦМмЙЙЬєеНЁЂDBaaSМАKubeSphere ЖрМЏШКЙмРэЁЃ
БОЮФРДздKubeSphere жаЮФЩчЧјЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ
|
|
ЭМЪ§ОнПтЪЧвЛжжЪЙгУЭМНсЙЙНјаагявхВщбЏЕФЪ§ОнПтЃЌЫќЪЙгУНкЕуЁЂБпКЭЪєадРДБэЪОКЭДцДЂЪ§ОнЁЃЭМЪ§ОнПтЕФгІгУСьгђЗЧГЃЙуЗКЃЌдкЗДгІЪТЮяжЎМфСЊЯЕЕФМЦЫуЖМПЩвдЪЙгУЭМЪ§ОнПтРДНтОіЃЌГЃгУЕФСьгђШчЩчНЛСьгђРяЕФКУгбЭЦМіЁЂН№ШкСьгђРяЕФЗчПиЙмРэЁЂСуЪлСьгђРяЕФЩЬЦЗЪЕЪБЭЦМіЕШЕШЁЃ
Nebula Graph МђНщгыМмЙЙ
Nebula Graph ЪЧвЛИіИпадФмЁЂПЩЯпадРЉеЙЁЂПЊдДЕФЗжВМЪНЭМЪ§ОнПтЃЌЫќВЩгУДцДЂЁЂМЦЫуЗжРыЕФМмЙЙЃЌМЦЫуВуКЭДцДЂВуПЩвдИљОнИїздЕФЧщПіЕЏадРЉШнЁЂЫѕШнЃЌетОЭвтЮЖзХ
Nebula Graph ПЩвдзюДѓЛЏРћгУдЦдЩњММЪѕЪЕЯжЕЏадРЉеЙЁЂГЩБОПижЦЃЌФмЙЛШнФЩЧЇвкИіЖЅЕуКЭЭђвкЬѕБпЃЌВЂЬсЙЉКСУыМЖВщбЏбгЪБЕФЭМЪ§ОнПтНтОіЗНАИЁЃ
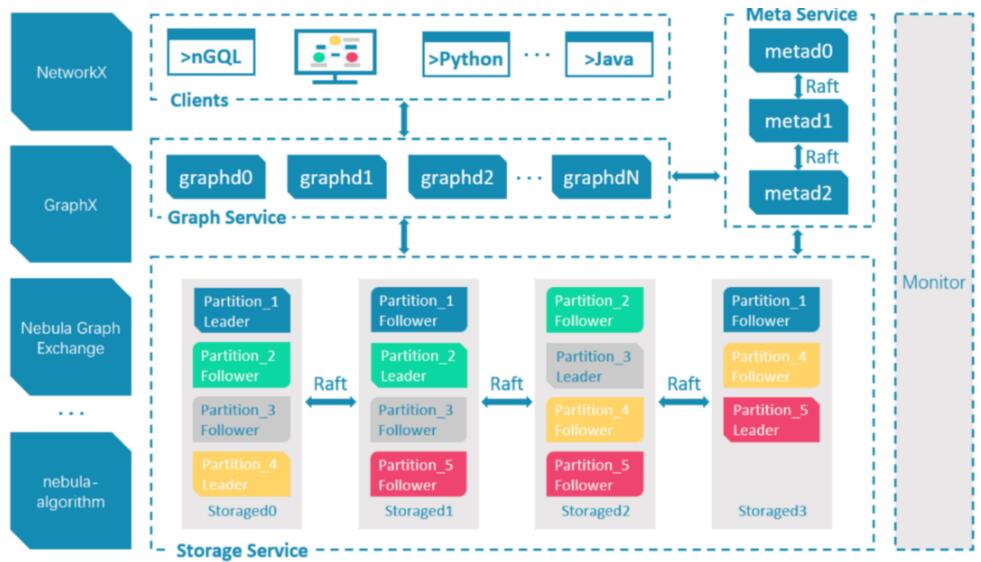
ЩЯЭМЫљЪОЮЊ Nebula Graph ЕФМмЙЙЃЌвЛИі Nebula МЏШКАќКЌШ§ИіКЫаФЗўЮёЃЌGraph
ServiceЁЂMeta Service КЭ Storage ServiceЁЃУПИіЗўЮёгЩШєИЩИіИББОзщГЩЃЌетаЉИББОЛсИљОнЕїЖШВпТдОљдШЕиЗжВМдкВПЪ№НкЕуЩЯЁЃ
Graph Service ЖдгІЕФНјГЬЪЧ nebula-graphdЃЌЫќгЩЮозДЬЌЮоЙиСЊЕФМЦЫуНкЕузщГЩЃЌМЦЫуНкЕужЎМфЛЅВЛЭЈаХЁЃGraph
Service ЕФжївЊЙІФмЃЌЪЧНтЮіПЭЛЇЖЫЗЂЫЭ nGQL ЮФБОЃЌЭЈЙ§ДЪЗЈНтЮіLexer КЭгяЗЈНтЮі Parser
ЩњГЩжДааМЦЛЎЃЌВЂЭЈЙ§гХЛЏКѓНЋжДааМЦЛЎНЛгЩжДаав§ЧцЃЌжДаав§ЧцЭЈЙ§ Meta Service ЛёШЁЭМЕуКЭБпЕФ
schemaЃЌВЂЭЈЙ§ДцДЂв§ЧцВуЛёШЁЕуКЭБпЕФЪ§ОнЁЃ
Meta Service ЖдгІЕФНјГЬЪЧ nebula-metad ЃЌЫќЛљгк Raft авщЪЕЯжЗжВМЪНМЏШКЃЌleader
гЩМЏШКжаЫљга Meta Service НкЕубЁГіЃЌШЛКѓЖдЭтЬсЙЉЗўЮёЃЌfollowers ДІгкД§УќзДЬЌВЂДг
leader ИДжЦИќаТЕФЪ§ОнЁЃвЛЕЉ leader НкЕу down ЕєЃЌЛсдйбЁОйЦфжавЛИі follower
ГЩЮЊаТЕФ leaderЁЃMeta Service ВЛНіИКд№ДцДЂКЭЬсЙЉЭМЪ§ОнЕФ meta аХЯЂЃЌШч SpaceЁЂSchemaЁЂPartitionЁЂTag
КЭ Edge ЕФЪєадЕФИїзжЖЮЕФРраЭЕШЃЌЛЙЭЌЪБИКд№жИЛгЪ§ОнЧЈвЦМА leader ЕФБфИќЕШдЫЮЌВйзїЁЃ
Storage Service ЖдгІЕФНјГЬЪЧ nebula-storagedЃЌВЩгУ shared-nothing
ЕФЗжВМЪНМмЙЙЩшМЦЃЌУПИіДцДЂНкЕуЖМгаЖрИіБОЕи KV ДцДЂЪЕР§зїЮЊЮяРэДцДЂЦфКЫаФЃЌNebula ВЩгУ Raft
РДБЃжЄетаЉKV ДцДЂжЎМфЕФвЛжТадЁЃФПЧАжЇГжЕФжївЊДцДЂв§ЧцЮЊ Rocksdb КЭ HBaseЁЃ
Nebula Graph ЬсЙЉC++ЁЂJavaЁЂGolangЁЂPythonЁЂRust ЕШЖржжгябдЕФПЭЛЇЖЫЃЌгыЗўЮёЦїжЎМфЕФЭЈаХЗНЪНЮЊ
RPCЃЌВЩгУЕФЭЈаХавщЮЊ Facebook-ThriftЁЃгУЛЇвВПЩЭЈЙ§ nebula-consoleЁЂnebula-studio
ЪЕЯжЖд Nebula Graph ВйзїЁЃ
ЖрдЦМмЙЙЬєеН
Nebula Graph ЕФдЦВњЦЗЖЈЮЛЪЧ DBaaS ЃЈDatabase-as-a-ServiceЃЉЦНЬЈЃЌвђДЫПЯЖЈвЊНшжњдЦдЩњММЪѕРДДяГЩетвЛФПБъЁЃЕНЕзИУШчКЮТфЕиФиЃПЪзЯШвЊУїШЗвЛЕуЃЌШЮКЮММЪѕЖМВЛЪЧвјЕЏЃЌжЛгаКЯЪЪЕФГЁОАЪЙгУКЯЪЪЕФММЪѕЁЃЫфШЛЮвУЧгЕгаКмЖрПЩЙЉЬєбЁЕФПЊдДВњЦЗРДДюНЈетИіЦНЬЈЃЌЕЋЪЧзюжеТфЪЕЕННЛИЖИјгУЛЇЕФВњЦЗЩЯЃЌЛЙгаКмЖрЬєеНЁЃ
етРяЮвСаОйСЫШ§ИіЗНУцЕФЬєеНЃК
вЕЮёЬєеН
ЖрИідЦГЇЩЬЕФзЪдДЪЪХфЃЌетРяашвЊЪЕЯжЭГвЛЕФзЪдДГщЯѓФЃаЭЃЌЭЌЪБЛЙвЊзіКУЙњМЪЛЏЃЌЙњМЪЛЏашвЊПМТЧЕигђЮФЛЏВювьЁЂЕБЕиЗЈТЩЗЈЙцВювьЁЂгУЛЇЯћЗбЯАЙпВювьЕШЖрИівЊЫиЃЌетаЉвЊЫиОіЖЈСЫашвЊдкЩшМЦФЃЪНЩЯШЅгКЯЕБЕигУЛЇЕФЪЙгУЯАЙпЃЌДгЖјЬсЩ§гУЛЇЬхбщЁЃ
адФмЬєеН
дкДѓЖрЪ§ЧщПіЯТЃЌЭЈЙ§ЭЌвЛдЦГЇЩЬЭјТчДЋЪфЕФЪ§ОнвЦЖЏЫйЖШБШБиаыЭЈЙ§ШЋЧђЛЅСЊЭјДгвЛИідЦГЇЩЬДЋЪфЕНСэвЛИідЦГЇЩЬЕФЪ§ОнвЦЖЏЫйЖШвЊПьЕУЖрЁЃетвтЮЖзХПчдЦжЎМфЕФЭјТчСЌНгПЩФмГЩЮЊЖрдЦЬхЯЕНсЙЙЕФбЯжиадФмЦПОБЁЃЪ§ОнЙТЕККмФбДђЦЦЃЌвђЮЊЦѓвЕЮоЗЈЧЈвЦИёЪНВЛЭЌЧвзЄСєдкВЛЭЌММЪѕжаЕФЪ§ОнЃЌШБЗІПЩЧЈвЦадЛсДјИјЖрдЦеНТдДјРДЧБдкЕФЗчЯеЁЃдкЕЅИідЦГЇЩЬжаЃЌЪЙгУдЦГЇЩЬЕФдЩњздЖЏРЉеЙЙЄОпХфжУЙЄзїИКдиЕФздЖЏРЉеЙЗЧГЃШнвзЃЌЕБгУЛЇЕФЙЄзїИКдиПчдНЖрИідЦГЇЩЬЪБЃЌздЖЏРЉеЙОЭЛсБфЕУМЌЪжЁЃ
дЫгЊЬєеН
ДѓЙцФЃЕФ Kubernetes МЏШКдЫгЊЪЧЗЧГЃгаЬєеНЕФЪТЧщЃЌТњзувЕЮёЕФПьЫйЗЂеЙКЭгУЛЇашЧѓвВЪЧЖдЭХЖгМЋДѓЕФПМбщЁЃЪзЯШЪЧзіЕНМЏШКЕФЙмРэБъзМЛЏЁЂПЩЪгЛЏЃЌЦфДЮШЋВПЕФдЫЮЌВйзїСїГЬЛЏЃЌеташвЊгавЛИіЩюШыСЫНтдЫЮЌЭДЕуЕФЙмРэЦНЬЈЃЌПЩвдНтОіЮвУЧДѓВПЗжЕФдЫЮЌашЧѓЁЃЪ§ОнАВШЋЩЯашвЊПМТЧдкУЛгаЪЪЕБЕФжЮРэКЭАВШЋПижЦЕФЧщПіЯТЃЌНЋЪ§ОнДгвЛИіЦНЬЈЧЈвЦЕНСэвЛИіЦНЬЈ(ЛђДгвЛИіЧјгђЧЈвЦЕНСэвЛИіЧјгђ)ЛсДјРДЪ§ОнАВШЋЗчЯеЁЃ
DBaaSЃЈDatabase-as-a-ServiceЃЉ
дЦдЩњММЪѕМђЕЅИХРЈОЭЪЧЮЊгУЛЇЬсЙЉвЛжжМђвзЕФЁЂУєНнЕФЁЂПЩЕЏадРЉеЙЕФЁЂПЩИДжЦЕФЗНЪНЃЌзюДѓЛЏЪЙгУдЦЩЯзЪдДЕФФмСІЁЃдЦдЩњММЪѕВЛЖЯбнНјвВЪЧЮЊСЫгУЛЇИќКУЕФзЈзЂгквЕЮёПЊЗЂЁЃДѓМвПЩвдПДЕНетИіН№зжЫўЃЌДг
IaaS ЕНзюЩЯУцЕФдЦдЩњгІгУВуЃЌВњЦЗаЮЬЌдНРДдНСщЛюЃЌМЦЫуЕЅдЊЕФСЃЖШдНРДдНЯИЃЌФЃПщЛЏГЬЖШЁЂздЖЏЛЏдЫЮЌГЬЖШЁЂЕЏадаЇТЪЁЂЙЪеЯЛжИДФмСІЖМЪЧдНРДдНИпЃЌетЫЕУїУПЭљЩЯзпвЛВуЃЌгІгУгыЕзВуЮяРэЛљДЁЩшЪЉНтёюОЭдНГЙЕзЃЌгУЛЇЕФЙизЂЕуВЛдйЪЧДггВМўЗўЮёЦїЕНвЕЮёЪЕЯжећИіСДЬѕЃЌЖјЪЧНіашвЊЙизЂгкЕБЯТвЕЮёБОЩэЁЃ
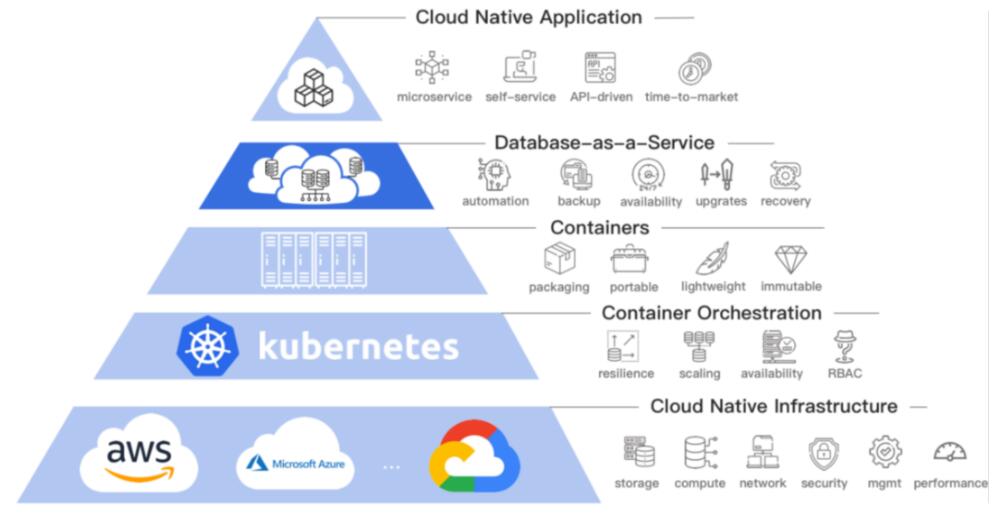
PaaS ЦНЬЈЕФШнЦїБрХХЯЕЭГЪЧ KubernetesЃЌздШЛЖјШЛЕиОЭФмЯыЕНЛљгк Kubernetes
ЙЙНЈетЬзЦНЬЈЃЌKubernetes ЬсЙЉСЫШнЦїдЫааЪБНгПкЃЌФуПЩвдбЁдёШЮвтвЛжжЪЕЯжетЬзНгПкЕФдЫааЪБРДЙЙНЈгІгУдЫааЕФЛљДЁЛЗОГЁЃвђДЫЃЌРћгУКУ
Kubernetes ЬсЙЉЕФФмСІЃЌОЭФмДяЕНЪТАыЙІБЖЕФаЇЙћЁЃKubernetes ЬсЙЉСЫДгУќСюаажеЖЫ
kubectl ЕНШнЦїдЫаавРРЕЕФДцДЂЁЂЭјТчЁЂМЦЫуЕФЖрИіРЉеЙЕуЃЌгУЛЇПЩвдИљОнвЕЮёГЁОАЪЕЯжвЛаЉздЖЈвхРЉеЙВхМўЖдНгЕН
kubernetes ЦНЬЈЃЌЖјВЛгУЕЃаФЧжШыадЁЃ
гУЛЇЪгЭМ
NebulaCloud ФПЧАЮЊгУЛЇЬсЙЉСНжжЗУЮЪЗНЪНЃЌвЛжжЪЧЭЈЙ§фЏРРЦїНјШы Studio ВйзїДАПкЃЌдкЪ§ОнЕМШыКѓПЩвдзіЭМЬНЫїЃЌnGQL
гяОфжДааЕШВйзїЃЌСэвЛжжЪЧЭЈЙ§ГЇЩЬЬсЙЉЕФ private-link ДђЭЈгУЛЇЕН NebulaCloud
жЎМфЕФЭјТчСЌНгЃЌгУЛЇПЩвдЭЈЙ§ nebula-console Лђеп nebula client жБСЌЕН
Nebula ЪЕР§ЁЃ
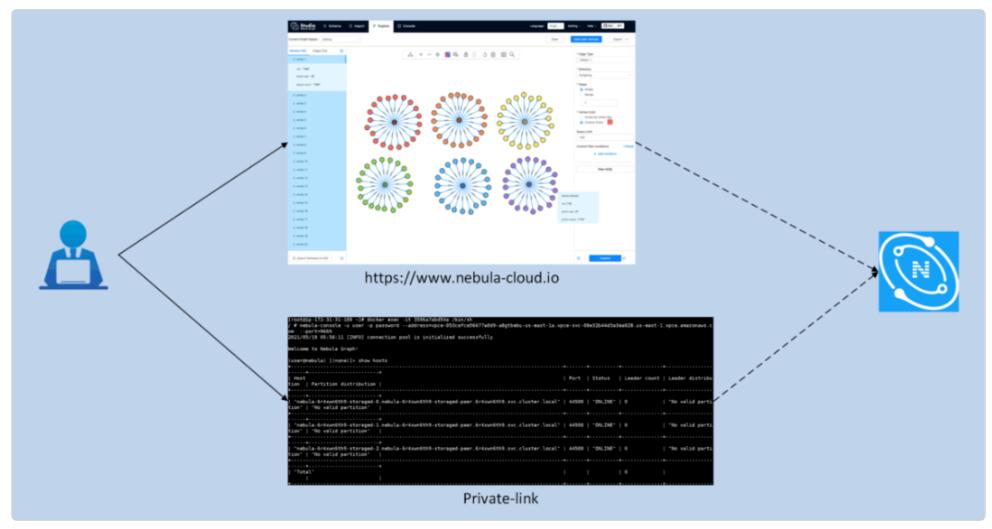
NebulaCloud МмЙЙ
ДгвЕЮёМмЙЙЩЯПДЃЌNebulaCloud ПЩвдЗжЮЊШ§ВуЃЌзюЕзВуЪЧзЪдДЪЪХфВуЃЌжївЊИКд№ЬсЙЉзЪдДВуУцЩЯЕФЪЪХфЃЌЬсЙЉЖдЖрдЦГЇЩЬЁЂЖрЕигђМЏШКЁЂЭЌЙЙЛђвьЙЙзЪдДГиЕФГщЯѓУшЪіЁЃдйЭљЩЯЪЧвЕЮёВугызЪдДВуЃЌвЕЮёВуКИЧЛљДЁЗўЮёЁЂЪЕР§ЙмРэЁЂзтЛЇЙмРэЁЂМЦЗбЙмРэЁЂЪ§ОнЕМШыЙмРэЕШвЕЮёФЃПщЃЛзЪдДВуИКд№ЬсЙЉ
Nebula МЏШКЕФдЫааЛЗОГЃЌдкЕїЖШВпТдЯТЬсЙЉзюМбЕФзЪдДХфжУЁЃзюЩЯВуЪЧЭјЙиВуЃЌЖдЭтЬсЙЉЗУЮЪЗўЮёЁЃ

NebulaCloud ФкВПСїГЬ
етРявд AWS ЮЊР§ВпТдЕиУшЪівЛИі Nebula МЏШКЕФДДНЈЙ§ГЬЁЃгУЛЇДДНЈЪЕР§ЧыЧѓЬсНЛКѓЃЌnebula-platform
ЗўЮёИљОнЪфШыЕФГЇЩЬЁЂЕигђЁЂЙцИёЕШВЮЪ§аХЯЂзізЪдДЕїЖШЃЌБШШчзЪдДГиЁЂИКдиОљКтЁЂАВШЋВпТдЕШХфжУЃЌШЛКѓЭЈЙ§
nebula-operator ЕФ api ЭъГЩЪЕР§ЕФДДНЈЃЌзюКѓХфжУ ALB ЙцдђЃЌЮЊгУЛЇЬсЙЉЗУЮЪЪЕР§ЕФШыПкЁЃ

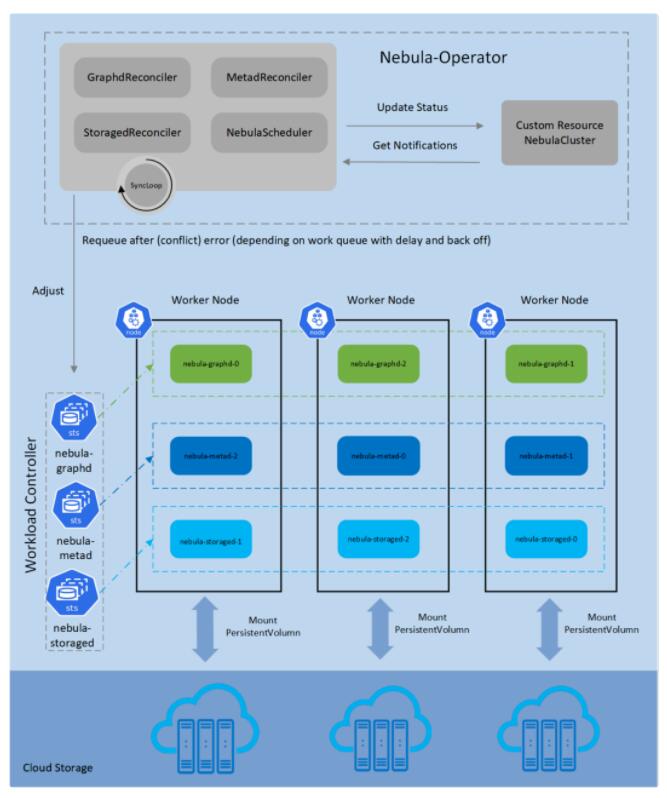
Nebula-Operator
дк Kubernetes жаЃЌЖЈвхвЛИіаТЖдЯѓПЩвдгаСНжжЗНЪНЃЌвЛИіЪЧ CustomResourceDefinition,
вЛИіЪЧ Aggregation ApiServerЃЌЦфжа CRD ЪЧФПЧАжїСїЕФзіЗЈЃЌnebula-operator
ОЭЪЧ CRD РДЪЕЯжЕФЁЃ
CRD+Custom Controller ОЭЪЧЕфаЭЕФ Operator ФЃЪНСЫЁЃЭЈЙ§Яђ Kubernetes
ЯЕЭГзЂВсКУЕФ CRDЃЌЮвУЧПЩвдЪЙгУ controller РДЙлВь Nebula МЏШКвдМАгыЫќЯрЙиСЊЕФзЪдДЖдЯѓзДЬЌЃЌШЛКѓАДееаДЕФаЕїТпМРДЧ§ЖЏ
Nebula МЏШКЯђЦкЭћзДЬЌзЊвЦЁЃетУДЪЕЯжПЩвдАб Nebula ЯрЙиЕФЙмРэЙЄзїЖМГСЕэЕН Operator
РяЃЌгУЛЇЪЙгУ NebulaGraph ЕФИДдгЖШНЕЕЭЃЌПЩвдЧсЫЩЭъГЩЕЏадРЉЫѕШнЁЂЙіЖЏЩ§МЖЕШКЫаФВйзїЁЃЮвУЧЛљгк
kubernetes ЕФ Restful API ЩњГЩСЫвЛЬзЙмРэ Nebula МЏШКЕФ APIЃЌетбљгУЛЇПЩвдФУзХ
API ОЭФмЪЕЯжЖдНгздМКЕФ PaaS ЦНЬЈЃЌДюНЈздМКЕФЭММЦЫуЦНЬЈЁЃ
nebula-operator ФПЧАЕФЙІФмЛЙдкВЛЖЯЭъЩЦжаЃЌЪЕР§ЕФЙіЖЏЩ§МЖашвЊ Nebula ЬсЙЉЕзВужЇГжЃЌдЄМЦНёФъЛсжЇГжЩЯЁЃ
KubeSphere ЖрМЏШКЙмРэ
ЦНЬЈЛЏЙмРэ
KubeSphere бмЩњздЧрдЦЙЋгадЦЕФВйзїУцАхЃЌГ§СЫМЬГабежЕЃЌЭЌЪБдкЙІФмЩЯвВЪЧЯрЕБЭъБИЁЃNebulaCloud
ашвЊЖдНгЕФжїСїдЦГЇЩЬЖМвбОжЇГжЩЯЃЌвђДЫвЛЬзЙмРэЦНЬЈОЭПЩвддЫЮЌЫљгаЕФ Kubernetes МЏШКЁЃЖрМЏШКЙмРэЪЧЮвУЧзюЮЊПДжиЕФЙІФмЕуЁЃ
ЮвУЧдкБОЕиЛЗОГВПЪ№СЫ Host МЏШКЃЌЦфгрЕФдЦЩЯЭаЙм Kubernetes МЏШКЭЈЙ§жБСЌНгШыЕФЗНЪНзїЮЊ
Member МЏШКЃЌетРяашвЊзЂвт ApiServer ЗУЮЪХфжУЗХЭЈЕЅИі IPЃЌБШШчБОЕиЛЗОГЕФГіПкЙЋЭј
IPЁЃ

СїГЬЛЏВйзї
ЮвУЧЪЙгУ IaC ЙЄОп pulumi ВПЪ№аТМЏШКЃЌдйЭЈЙ§здЖЏЛЏНХБОЙЄОпЩшжУД§ЙмРэМЏШК member
НЧЩЋЃЌШЋВПЙ§ГЬЮоашШЫЙЄВйзїЁЃМЏШКЕФДДНЈгЩЦНЬЈЕФИцОЏФЃПщРДДЅЗЂЃЌЕБЕЅМЏШКЕФзЪдДХфЖюДяЕНИцОЏЫЎЮЛКѓЃЌЛсздЖЏДЅЗЂЕЏадГівЛЬзаТЕФМЏШКЁЃ

здЖЏЛЏМрПи
KubeSphere ЬсЙЉСЫЗсИЛЕФФкжУИцОЏВпТдЃЌЭЌЪБЛЙжЇГжздЖЈвхИцОЏВпТдЃЌФкжУЕФИцОЏВпТдЛљБОПЩвдИВИЧШеГЃЫљашЕФМрПижИБъЁЃдкИцОЏЗНЪНЩЯвВгаЖржжбЁдёЃЌЮвУЧВЩгУСЫгЪМўгыЖЄЖЄЯрНсКЯЕФЗНЪНЃЌживЊНєМБЕФПЩвдЭЈЙ§ЖЄЖЄжБНгЖЄЕНжЕАрШЫдБЃЌЦеЭЈМЖБ№ЕФПЩвдзпгЪМўЗНЪНЁЃ
жЧФмЛЏдЫгЊ
KubeSphere ЬсЙЉСЫМЏШКЖрИіЮЌЖШЕФШЋОжеЙЪОЪгЭМЃЌФПЧАЙмРэЕФМЏШКЪ§СПЩйзуЙЛЪЙгУЁЃЮДРДЫцзХНгШы
member МЏШКЪ§СПЕФдіМгЃЌПЩвдЭЈЙ§дЫгЊЪ§ОнЕФЗжЮізізЪдДЕФОЋЯИЛЏЕїЖШКЭЙЪеЯдЄВтЃЌНјвЛВНЬсЧАЗЂЯжЗчЯеЃЌЬсЩ§дЫгЊЕФжЪСПЁЃ
ЦфЫћ
KubeSphere ЛЙгаКмЖрКУгУЕФХфЬзЙЄОпЃЌБШШчШежОВщбЏЁЂЪТМўВщбЏЁЂВйзїЩѓМЦШежОЕШЃЌетаЉЙЄОпдкОЋЯИЛЏдЫгЊЖМЪЧБиВЛПЩЩйЕФЁЃ
ЮвУЧФПЧАвбОНгШыСЫВтЪдЛЗОГМЏШКЃЌдкЩюЖШЪЙгУеЦЮе KubeSphere ЕФШЋУВКѓЛсГЂЪдНгШыЩњВњМЏШКЁЃ
ЮДРДЙцЛЎ
ЮвУЧНЋГфЗжЭкОђздЖЈвхИцОЏВпТдВЂМгвдРћгУЃЌЭЌЪБНсКЯ Nebula МЏШКздЩэЕФМрПижИБъДђдьМрПиШЋОАЭМЃЛИВИЧКЫаФжИБъЕФЖрМЖЁЂЖрЮЌЖШЕФИцОЏЛњжЦЃЌНЋЗчЯеЯћУ№дкдДЭЗЃЛЭъЩЦжмБпХфЬзЙЄОпЃЌЭЈЙ§жїЖЏЁЂБЛЖЏвдМАСїГЬЛЏЕШМѕЩйЮѓВйзїЗчЯеЃЛЦєгУ
DevOps ЙЄзїСїЃЌДђЭЈПЊЗЂЁЂВтЪдЁЂдЄЗЂЁЂЩњВњЛЗОГЃЌМѕЩйШЫСІНщШыЁЃ
| 







