| БрМЭЦМі: |
БОЮФжївЊНщЩмзжНкЬјЖЏдк
Bucket ЗНУцЕФгХЛЏЁЃ
БОЮФРДздЮЂаХЙЋжкКХЙ§ЭљМЧвфДѓЪ§ОнЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ
|
|
БОЮФжївЊДгвдЯТЫФИіЗНУцНщЩмЃК
Spark SQL дкзжНкЬјЖЏЕФгІгУ
ЪВУДЪЧЗжЭА
Spark ЗжЭАЕФЯожЦ
зжНкЬјЖЏдкЗжЭАЗНУцЕФгХЛЏ

ЯТУцЪЧ Spark SQL дкзжНкЬјЖЏЕФгІгУЁЃ
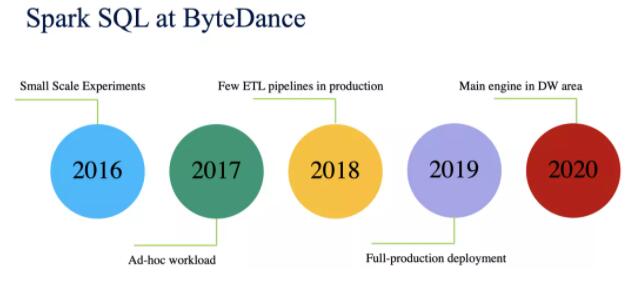
2016ФъжївЊЪЧаЁЙцФЃЕФВтЪдНзЖЮ
2017ФъгУгкДІРэ Ad-hoc ЙЄзїИКди
2018ФъдкЩњВњЛЗОГЯТДІРэЩйСПЕФ ETL ЙмЕРЙЄзїЃЛ
2019ФъдкЩњВњЛЗОГЯТШЋУцВПЪ№ЃЛ
2020ФъГЩЮЊ DW СьгђЕФжївЊМЦЫув§ЧцЁЃ
ЪВУДЪЧЗжЭА

ЩЯУцР§згеЙЪОСЫДДНЈЗжЭАБэЕФЗНЗЈЁЃжївЊЙиМќзжЪЧ clustered by (xxx) sorted
by (xxx) into N buckets
ШчЙћЮвУЧЭљЗжЭАБэРяУцВхШыЪ§ОнЃЌПЩвдШчЯТЪЙгУ
INSERT INTO order
SELECT order_id, user_id, product, amount
FROM order_staging
ПЩМћЃЌетИіКЭе§ГЃБэЕФЪЙгУВЂУЛгаЪВУДЧјБ№ЁЃ
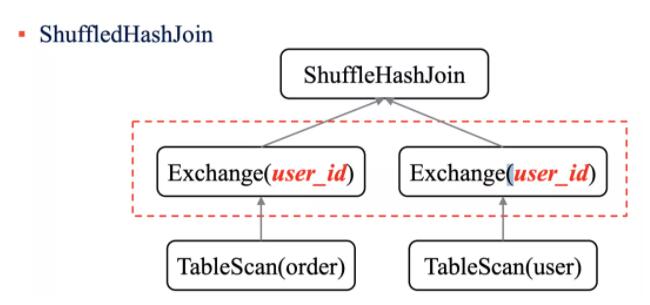
ШчЙћЮвУЧНјаавЛИі ShuffleHashJoin ЕФЪБКђЃЌЪзЯШашвЊНЋБэЕФЪ§ОнАДее on ЕФЬѕМўНјааЗжЧјЃЌШЛКѓВХЪЧНјаа
Join ВйзїЁЃ 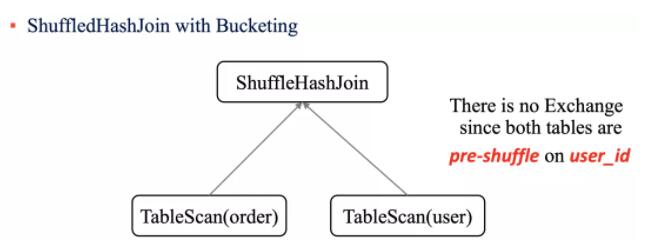
ЕЋЪЧШчЙћВЮгы Join ЕФБэвбОЪЕЯжЗжЭАСЫЃЌФЧУДдкжДаа ShuffleHashJoin ЕФЪБКђЪЁШЅ
Shuffle ЕФВйзїЁЃБШШчЩЯУцЕФР§згШчЙћЮвУЧЖд order КЭ user БэАДее user_id
зжЖЮНјааЗжЭАЃЌФЧУДдк ShuffleHashJoin ЕФЪБКђОЭВЛашвЊНјаа Exchange ВйзїСЫЁЃ
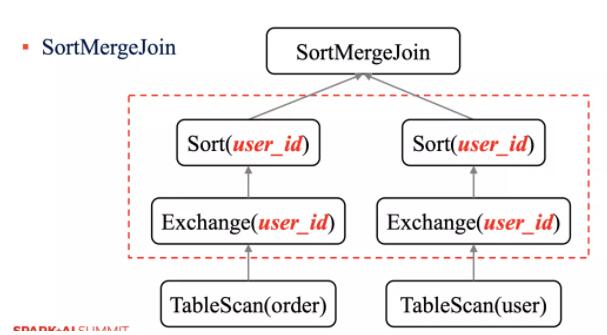
Ждгк SortMergeJoin ЃЌашвЊЖд on РяУцЕФЬѕМўзжЖЮНјаа Exchange ВйзїЃЌШЛКѓдйНјаа
Sort ВйзїЃЌзюКѓВХЪЧжДаа SortMergeJoinЃЈИќЖрЙигк Join ЕФВпТдПЩвдВЮМћЙ§ЭљМЧвфДѓЪ§ОнЕФЁЖУПИі
Spark ЙЄГЬЪІЖМгІИУжЊЕРЕФЮхжж Join ВпТдЁЗЮФеТЃЉЁЃ 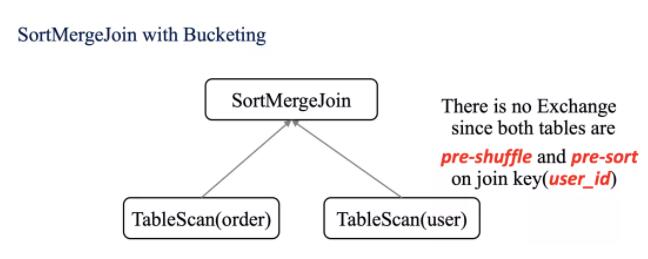
ШчЙћВЮгы Join ЕФБэвбОЗжЭАСЫЃЌФЧУДВЛашвЊОЭаа Exchange КЭ Sort ВйзїСЫЁЃ
Spark ЗжЭАЕФЯожЦ
аЁЮФМўЮЪЬт 
жДааЩЯУцЕФ SQLЃЌУПИі task зюЖрПЩФмВњЩњ 1024 ИіЮФМўЃЌЦфжа 1024 ЪЧЗжЭАЕФЪ§СПЁЃЫљвдШчЙћЮвУЧга
M Иі taskЃЌФЧУДзюЖрВњЩњЕФЮФМўИіЪ§ЮЊ M * 1024ЁЃБШШчЩЯУцЕФ attempt_20200519145628_0014_m_000014_0
ФПТМЯТВњЩњСЫ 988 ИіЮФМўЁЃ
НтОіаЁЮФМўЕФЮЪЬтПЩвдМгЩЯ DISTRIBUTE BY ЃЌШчЯТЃК
INSERT INTO order SELECT order_id, user_id, product,
amount
FROM order_staging
DISTRIBUTE BY user_id
ШчЙћ 1024 ЪЧ M ЕФБЖЪ§ЃЌФЧУДзюЖрЛсВњЩњ 1024 ИіЮФМўЃЌЦфжа M = spark.sql.shuffle.partitionsЃЛ
ШчЙћ M ЪЧ 1024 ЕФБЖЪ§ЃЌФЧУДзюЖрЛсВњЩњ M ИіЮФМўЃЌЦфжа M = spark.sql.shuffle.partitionsЁЃ
Spark ЗжЭАКЭЦфЫћ SQL в§ЧцВЛМцШн 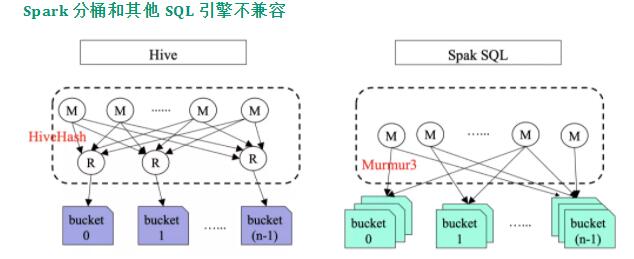
Spark ЕФЗжЭАКЭ Hive ЕФЗжЭАЪЧВЛМцШнЕФЃЌЭЌЪБКЭ Presto вВЪЧВЛМцШнЕФЃЛЕЋЪЧ Presto
гы Hive ЕФЗжЭАЪЧМцШнЕФЁЃ
Spark ЕФЗжЭАКЭ Hive ВЛМцШнжївЊдвђЪЧвдЯТдвђЕМжТЕФЃК
Hive дкЩњГЩЗжЭАЕФЪБКђЛсЖюЭтНјаавЛИі Reduce ВйзїЃЌвдБЃжЄЯрЭЌЗжЭАЕФЪ§ОнЖМДцДЂдквЛИіЮФМўжаЁЃЖј
Spark SQL дкаДЗжЭАЮФМўЪБВЛашвЊ Shuffle ВйзїЃЌетбљОЭЛсЕМжТУПИіЗжЭАзюЖрВњЩњ M ИіЮФМўЃЌетОЭЕМжТЩЯУцЫЕЕФаЁЮФМўЮЪЬтЃЛ
Spark ЗжЭАКЭ Hive ЗжЭАВЩгУВЛЭЌЕФ hash ЫуЗЈЁЃHive гУЕФЪЧ HiveHashЃЛЖј
Spark гУЕФЪЧ Murmur3ЃЌЫљвдЪ§ОнЕФЗжВМЪЧВЛвЛбљЕФЁЃ

вђЮЊ Spark КЭ Hive ЗжЭАВЛМцШнЃЌЫљвдЕБ Spark ЕФЗжЭАБэКЭ Hive ЕФЗжЭАБэНјаа
SortMergeJoin ЕФЪБКђЪЧашвЊНјаа Sort КЭ Exchange ВйзїЕФЁЃ
ЖюЭтЕФХХађВйзї
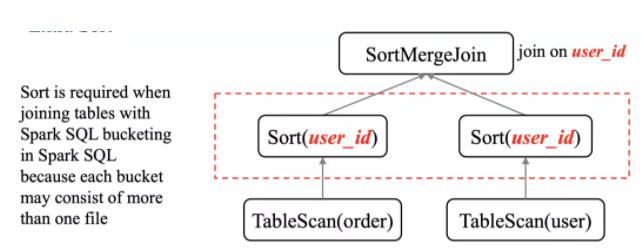
вђЮЊ Spark SQL БэжаЕФУПИіЗжЭАРяУцзюЩйАќКЌвЛИіЮФМўЃЌЫљвддкНјаа Join жЎЧАашвЊНјааЖюЭтЕФХХађВйзїЁЃ
ЗжЭАЪ§ВЛЖдЦы 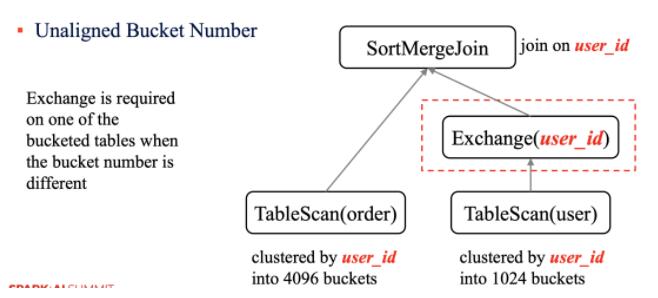
ШчЙћВЮгы Join ЕФБэЗжЭАЪ§ВЛвЛжТЃЌФЧУДЦфжавЛеХБэашвЊНјааЖюЭтЕФ Exchange ВйзїЁЃ
ВЮгы Join ЕФ key КЭЗжЭАСаВЛвЛбљашвЊЖюЭтВйзї
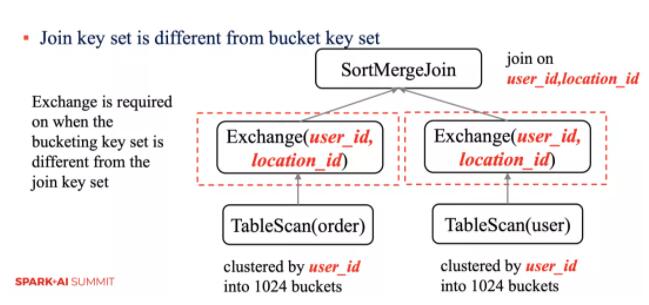
ЕБВЮгы Join ЕФ key КЭЗжЭАЕФСаВЛвЛбљЪБЃЌашвЊЖюЭтЕФ Exchange ВйзїЁЃ
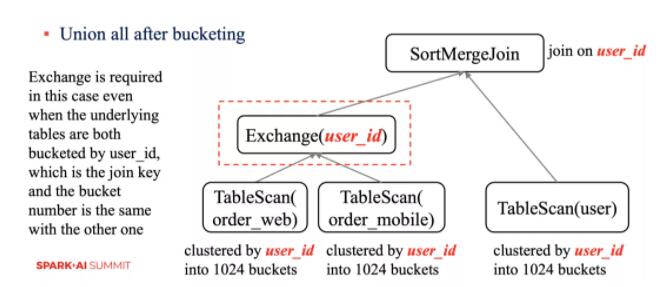
ЩЯУцЕФР§згОЁЙмВЮгы Join ЕФБэЖМЪЧЖд user_id зжЖЮНјааЗжЭАЃЌВЂЧвЗжЭАЪ§вЛбљЃЌЕЋЪЧЛЙЪЧашвЊЖюЭтЕФ
Exchange ВйзїЁЃ
зжНкЬјЖЏдкЗжЭАЗНУцЕФгХЛЏ
Spark ЗжЭАКЭ Hive ЗжЭАЖдЦы
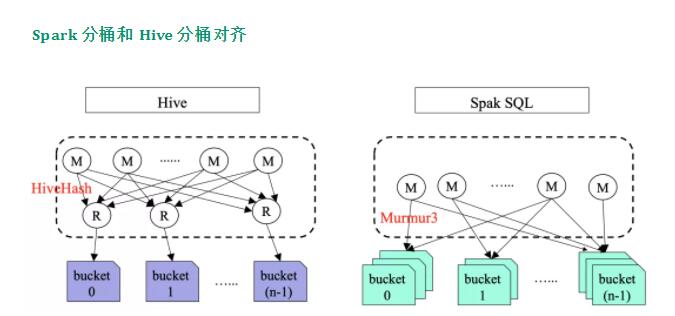
ЧАУцНщЩмСЫ Spark КЭ Hive ЗжЭАВЛМцШнЃЌЖдгкетЗНУцЃЌзжНкЬјЖЏНЋ Hive ЗжЭАБэКЭ Spark
ЗжЭАБэНјааСЫЖдЦыЃЌжївЊАќРЈЃК

Spark SQL аД Hive ЗжЭАБэЕФТпМКЭ Hive вЛжТЁЃ жиаДСЫ InsertIntoHiveTable#requiredOrdering
КЭ InsertIntoHiveTable#requiredDistributionЃЌВЂЧввВЪЙгУСЫ
HiveHash ЫуЗЈЁЃ

ЖдгкЖСЗНУцЃЌжиаДСЫ HiveTableScanExec#outputPartitioning КЭ
HiveTableScanExec#outputOrderingЃЌЪЙгУСЫ HiveHash ЫуЗЈЃЌВЂЧвЪЙгУСЫ
Hive ЕФЗжЭАдЊЪ§ОнЁЃ 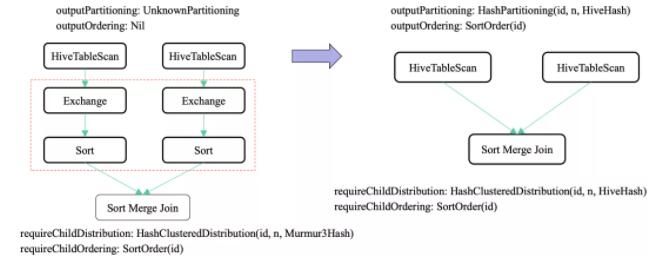
ЩЯУцЪЧ Spark ЖСШЁ Hive ЗжЭАБэИФНјЧАКЭИФНјКѓЕФЧјБ№ЁЃПЩвдПДЕНЃЌИФНјКѓЃЌoutputPartitioning
ЮЊ HashPartitioningЃЌВЂЧв outputOrdering ЮЊ SortOrderЃЌТњзуСЫ
requireChildDistribution ЮЊ HashClusteredDistributionЕФвЊЧѓвдМАrequireChildOrdering
ЮЊ SortOrderЃЌДгЖјдкНјаа SortMergeJoin ЕФЪБКђЪЁШЅСЫ Exchange КЭ
Sort ВйзїЁЃ
One to Mange Bucket Join
СэвЛИіИФНјЪЧ One to Merge Bucket JoinЃЌБШШчЯТУцР§зг A БэгаШ§ИіЗжЭАЃЌB
БэгаСљИіЗжЭАЁЃ
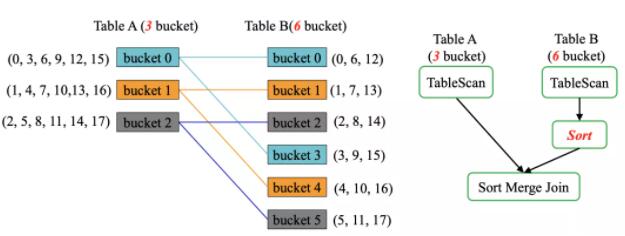
ШчЙћЮвУЧдк Spark ЖдЩЯУцСНеХБэНјаа Join ВйзїЃЌB БэашвЊЖюЭтЕФ Sort ВйзїЃЌвђЮЊЩЯУцСНеХБэЕФЗжЭАЪ§ВЛвЛбљЁЃЕЋЪЧдкзжНкЙЋЫОЃЌгЩгкЖдадФмЕФвЊЧѓЃЌашвЊБмУт
Sort ВйзїЁЃ
вЛжжЗНЗЈЪЧНЋ A БэЕФЗжЭА 0 КЭ B БэЕФЗжЭА 0 ЁЂЗжЭА 3 НјааЙиСЊЃЛНЋ A БэЕФЗжЭА 1 КЭ
B БэЕФЗжЭА 1 ЁЂЗжЭА 4 НјааЙиСЊЃЛНЋ A БэЕФЗжЭА 2 КЭ B БэЕФЗжЭА 2 ЁЂЗжЭА 5 НјааЙиСЊЁЃЮвУЧжЛашвЊНЋ
A БэИДжЦвЛЗнЃЌетбљ A БэвВТњзу 6 ИіЗжЭАЁЃНЋ A БэКЭ A БэНјаа Union ПЩвдВњЩњ ЕН
6 ИіЗжЭАЕФаТБэЃЌЕЋЪЧ Spark здДјЕФ Union ВйзїжЎКѓ outputPartitioning
КЭ outputOrdering НЋБЛЩОГ§ЃЌЫљвдзжНкздМКПЊЗЂГі bucket unionЃЌЪЙЕУ outputPartitioning
КЭ outputOrdering БЛБЃСєЃЌетбљОЭПЩвдЪЁШЅ Sort КЭ Exchange ВйзїЁЃ
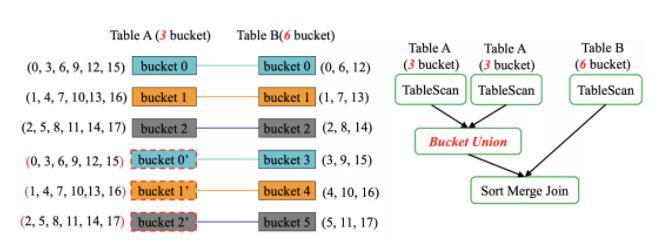
ВЛЙ§ЩЯУцЕФЗНУцдк B left join A ЁЂB left semi join AЁЂB anti
join AЁЂB inner join A ПЩвде§ГЃЙЄзїЃЌЕЋЪЧдк B right join AЁЂB
full outer join AЁЂB cross join A ЕФЪБКђНсЙћгажиИДЃЌвђЮЊ A БэЕФЪ§ОнБЛЩЈУшСЫСНДЮЁЃ 
ЮЊСЫНтОіетИіЮЪЬтЃЌдк TableScan КѓУцМгЩЯСЫ hash(10) % buckets = bucket
id ЕФЙ§ТЫЬѕМўЃЌБШШч bucket 0 НЋЛсАб 3ЁЂ9ЁЂ15 Й§ТЫЕєЃЌЭЈЙ§етжжАьЗЈНЋЛсЯћГ§жиИДЪ§ОнЁЃ 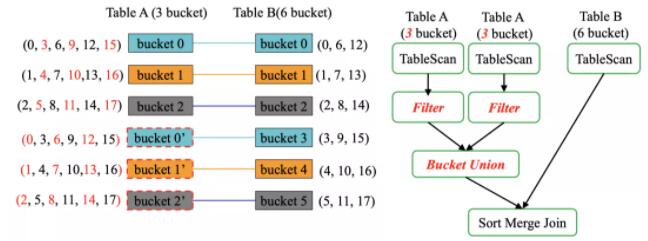
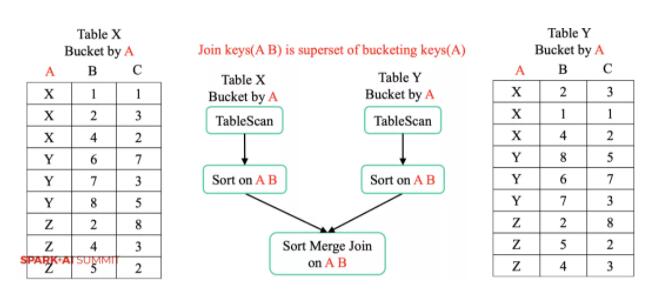
зжНкЕФСэЭтвЛИігХЛЏЪЧШчЙћ Join ЕФ Key ВЛНіНіЪЧЗжЭАЕФ KeyЃЌдЩњЕФ Spark ЛсВњЩњЖюЭтЕФ
Exchange КЭ Sort ВйзїЁЃ
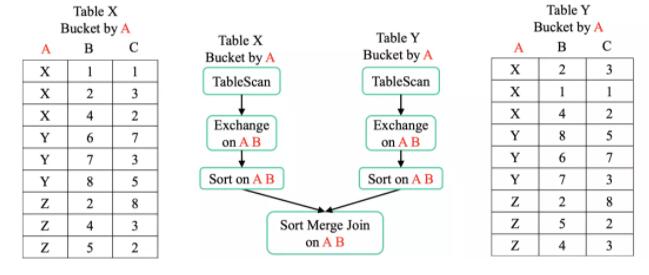
ЭЈЙ§гХЛЏКѓЃЌExchange НЋЯћГ§ЁЃ
| 







