| 编辑推荐: |
本文介绍了MySQL在InnoDB层所提供的并行加速技术的基本使用、效果、原理以及一些使用限制,部分查询、DDL支持了并行扫描、并行排序、并行构建B+树。希望对你的学习有帮助。
本文来自于微信公众号阿里技术,由火龙果软件Linda编辑、推荐。 |
|
01 前言
随着用户表上数据量的增加,一些SQL的执行时间会变得越来越长。比如一些需要全表扫描的查询SQL,数据扫描过程会耗费一定的时间,表越大时扫描时间越久。再比如一些创建二级索引、重建表的DDL操作,会扫描全表,并做排序操作,表越大时扫描和排序耗时都会比较久。
为提升SQL查询性能,MySQL社区于8.0.14推出了InnoDB并行扫描特性,可通过innodb_parallel_read_threads变量控制并行扫描聚簇索引的线程数量;于
8.0.27 支持并行创建索引,可通过innodb_ddl_threads控制创建二级索引的并行线程数量,加速索引创建过程。MySQL的并行当前仅限于InnoDB层对全表的一个并行。
本文以8.0.37代码为基准,对InnoDB层的这些并行技术做一些基本介绍、原理解析。
02 如何使用
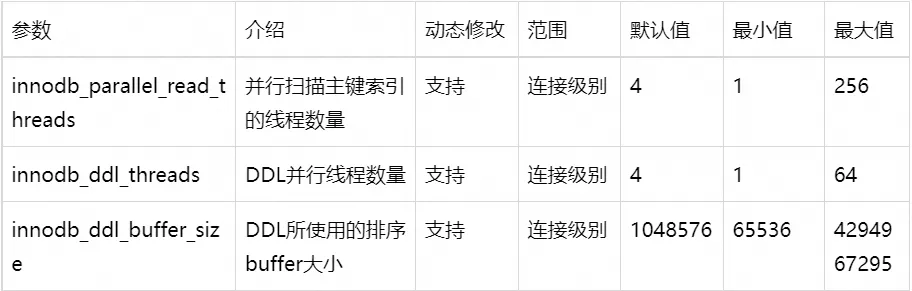
2.1 参数介绍
innodb_parallel_read_threads
该参数用于控制并行扫描主键索引的线程数量,当前仅支持并行扫描主键索引,不支持并行扫描二级索引。设置该参数大于1即可使用并行扫描。最大值为256,256也是所有用户连接的并行线程数量之和最大值,达到限制后,用户连接回退为单线程扫描。
innodb_ddl_threads
该参数用于控制创建二级索引期间并行排序的线程数量,以及重建表期间并行排序、并行构建B+树的线程数量。
innodb_ddl_buffer_size
DDL期间所使用的排序buffer总大小,内存排序由并行扫描线程完成,每个并行线程分配到的排序buffer大小为
innodb_ddl_buffer_size/innodb_parallel_read_threads,因此当增大innodb_parallel_read_threads大小时,也需要增加innodb_ddl_buffer_size大小。
共涉及三个参数,汇总如下表格。
2.2 哪些SQL支持并行
SELECT COUNT(*) FROM table1;
SELECT COUNT(*)语句支持对主键索引的并行扫描,不支持二级索引。
CHECK TABLE table1;
CHECK TABLE语句执行过程中会扫描两次主键索引,在第二次扫描主键索引时,支持并行扫描。
CREATE INDEX index1 ON table1 (col1); ALTER TABLE
table1 ADD INDEX index1 (col1);
CREATE INDEX时,在扫描主键索引、排序阶段支持并行,构建B+树阶段不支持并行。不支持虚拟列索引、全文索引、稀疏索引。
ALTER TABLE table1 ENGINE = INNODB; OPTIMIZE TABLE
table1; (下文简称重建表。optimize table = 重建表 + analyze table,在重建表阶段支持并行)。
重建表时,在排序阶段、构建二级索引阶段支持并行,在扫描主键索引时不支持并行。
以下表格总结了上述SQL的并行支持程度。部分需要全表扫描主键索引的查询SQL、创建二级索引(CREATE
INDEX)的DDL支持并行,需要注意的是这些SQL并不是所有阶段都支持并行。

03 并行查询
MySQL的并行查询由InnoDB层完成,实际是一个对B+树进行并行扫描的过程。
InnoDB层提供了一个索引扫描的接口row_scan_index_for_mysql,用于对索引做全纪录扫描。SELECT
COUNT(*)、CHECK TABLE共用该接口完成索引的并行扫描。
row_scan_index_for_mysql //
索引全纪录扫描
|-> row_mysql_parallel_select_count_star
// 并行count(*)
| |-> Parallel_reader
reader; // 创建reader
| |-> reader.add_scan(count_callback);
// 设置COUNT(*)专属的回调函数,做一些预分片
| |-> reader.run // 开始并行扫描
|
|-> parallel_check_table
// 并行CHECK TABLE
| |-> Parallel_reader
reader; // 创建reader
| |-> reader.add_scan(check_callback);
// 设置CHECK TABLE专属的回调函数,做一些预分片
| |-> reader.run // 开始并行扫描
|
创建二级索引的主键索引扫描阶段,也都会使用到并行扫描,其实现是一样的,但是扫描入口有所区别。
3.1 并行COUNT(*)
先以COUNT(*)为例,介绍下单线程扫描的步骤。
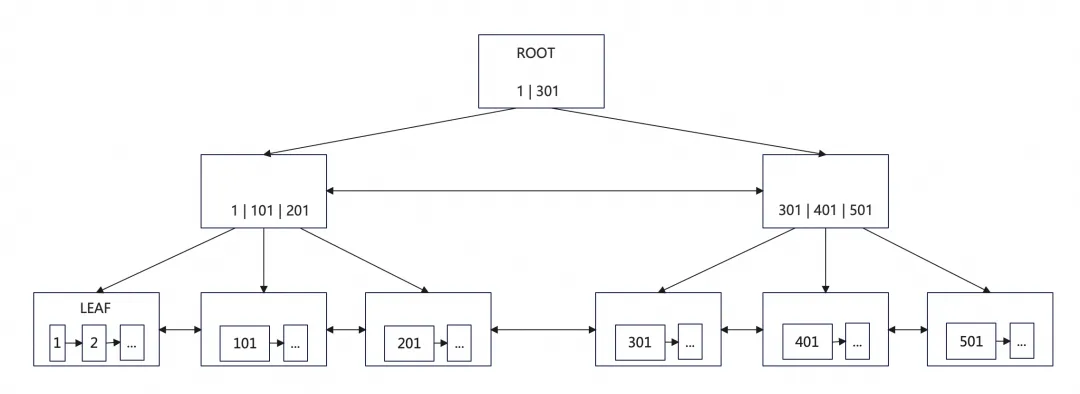
单线程如何扫描一棵B+树?让我们来简单回顾下B+树的组织结构。上图为一个3层B+树,第一层为根节点页,第三层为叶子结点。其特点为:
InnoDB是通过B+树组织数据,非叶子结点保存指针信息,叶子结点按序保存了所有的记录。
上下层之间通过单向指针连接。
同层级的页面之间通过双向链表连接。
页面内部的记录通过单向链表连接起来构成一个由小到大的有序链表。
从最左叶子结点的第一个记录开始,依次向后遍历B+树即可按序完成对B+树的全记录扫描。
在并行查询以前,单线程SELECT COUNT(*)全表在InnoDB层的基本执行过程为:
首先访问根节点最小记录(ID=1),然后根据该记录定位其最左的孩子结点,然后继续向下定位到叶子结点最小记录(ID=1)。
定位过程依次加INDEX S锁、ROOT PAGE S锁、NO LEAF PAGE S锁、LEAF
PAGE S锁,定位结束后放掉LEAF PAGE外的所有的S锁。
从B+树最小记录开始扫描到最大记录,扫描过程中对每个记录进行MVCC可见性判断,若可见则处理行记录。对于COUNT(*),则是对计数器加1。
扫描完B+树后将计数器结果返回给SERVER层。
上述扫描过程由 row_search_mvcc 函数完成最小记录定位,以及获取下一记录。在扫描过程中仅持有单个LEAF
PAGE的S锁,在页内每扫一条记录,都会对page加锁、解锁:
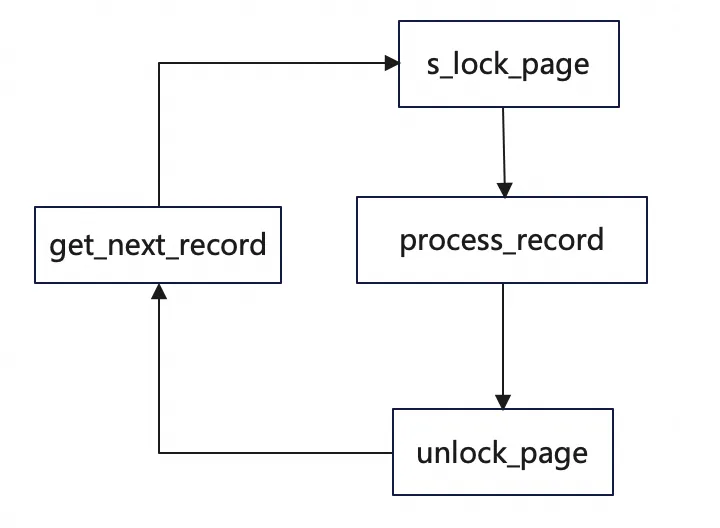
当一个页扫描完毕,就扫描下一个页,重复上述过程直到最后一条记录。
InnoDB提供了并行扫描特性来对上述过程进行加速,需要对B+树做全记录扫描时,即可使用上并行扫描技术。
并行扫描

一棵B+树由多个子树构成,并行扫描通过将B+树划分为多个子树来做并行,每个子树的扫描作为一个并行任务,交由多个线程来并行处理。具体流程为:
用户线程发起COUNT(*)语句,然后进入InnoDB层的并行扫描逻辑。
用户线程对B+树预分片(子树划分),并将分片放入任务队列。上图例中划分为了2个分片,每个分片由一个二元组构成,二元组记录了子树的起始记录和结束记录。这里用户线程先做较粗粒度的分片,减轻用户线程负担,后续交由work线程会做更细粒度的分片。
用户线程开启多个work线程,然后等待work线程结束(这里用户线程没有工作)。
work线程从任务队列中依次取出分片。
若分片粒度较大,那么由work线程将大分片再次划分为粒度更小的分片,并将分片放入队列。
work线程依次对每个分片执行扫描任务。
并行线程执行完后将结果汇总返回给SERVER层。
分片过程
每个分片(Range)可以表示一段逻辑连续的主键记录集合,其由两个Iter构成一个左闭右开的区间 [start,
end)。
struct RANGE {
Iter start;
Iter end;
}
|
每个Iter标记了一个记录的位置。
struct Iter {
...
const rec_t *m_rec{}; //
记录,标记分片的边界
btr_pcur_t *m_pcur{}; //
B+树游标,标记该记录的page no
...
}
|
并行扫描的关键在于如何分片以及分片过程如何对B+树加锁,需要尽可能保证分片均匀,确保分片边界是连续的、无交叉。
用户线程分片的策略为根据根节点子树数量预分片,比如根节点包含N个子树(N条记录)就分为N个分片。分片的过程是一个根据ROOT的结点指针完成对叶子结点行记录定位的过程,预分片过程如下:
1. INDEX加S锁;
2. ROOT PAGE加S锁,整个分片过程一直持有INDEX、ROOT的S锁,确保ROOT
PAGE的记录不被更改,不产生新的子树;
访问ROOT第一条记录;
根据该记录定位到叶子结点记录,对沿路PAGE加S锁;
根据叶子结点记录创建一个分片,作为该分片的起始位置,同时将该记录作为上一个分片的结束位置;
释放沿路PAGE的锁,ROOT、INDEX锁保留;
访问ROOT PAGE第二条记录。。。回到第2.a步重复上述过程。
3. ROOT PAGE记录遍历结束后释放ROOT、INDEX的S锁,完成预分片。
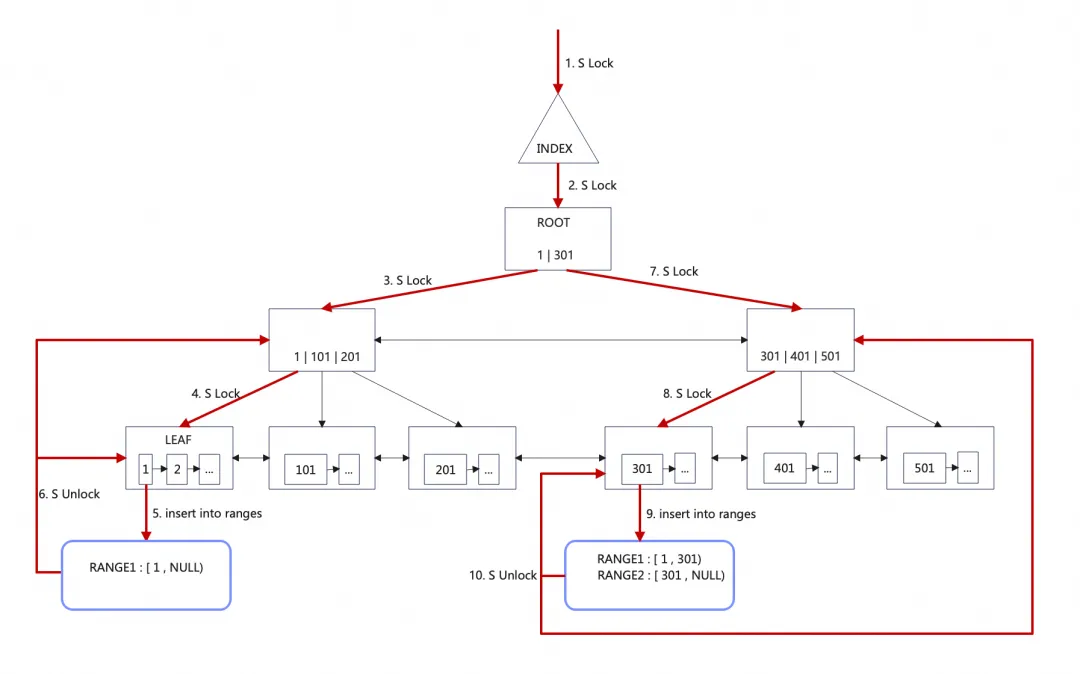
假设B+树比较平衡,那么预分片就可以将B+树划分得比较均匀。
为什么work线程还需要再次分片?work线程如何确定分片粒度较大需要再次划分呢?
并行扫描最初设计中存在分片粒度较大的问题,对于非常大的树,将导致并行线程利用率不足。假设并行扫描线程为4,有一棵B+树存在5棵子树,用户线程将其分为5个分片,那么前4棵子树可以并行扫描,有一个线程需要扫描两棵子树。假设每棵子树扫描耗时为1min,可以计算出并行扫描总耗时为2min。
解决办法为将BTREE划分为更小粒度的子树,提高并行线程的利用率,由用户线程预分片,work线程会对某些分片再次划分,由此便可以将上述例子中的扫描总耗时变为1分15秒(5min/4)。
优化后的分片策略为:
预分片:用户线程根据根节点子树数量预分片,同时对余量分片(分片数量对并行线程数取余)标记为需要再次划分。例如下图中有4个并行work线程,一棵B+树有5棵子树,用户线程预分为5个分片,那么会将第5个分片标记为需要再次划分的分片。然后将预分片依次放入队列,先放入的分片会先被work获取。
前4个分片会先被work取出来被并行执行。
某个work第一轮任务结束后争抢到第5个分片,发现该分片需要再次划分,那么对该子树向下再分为多个子树。
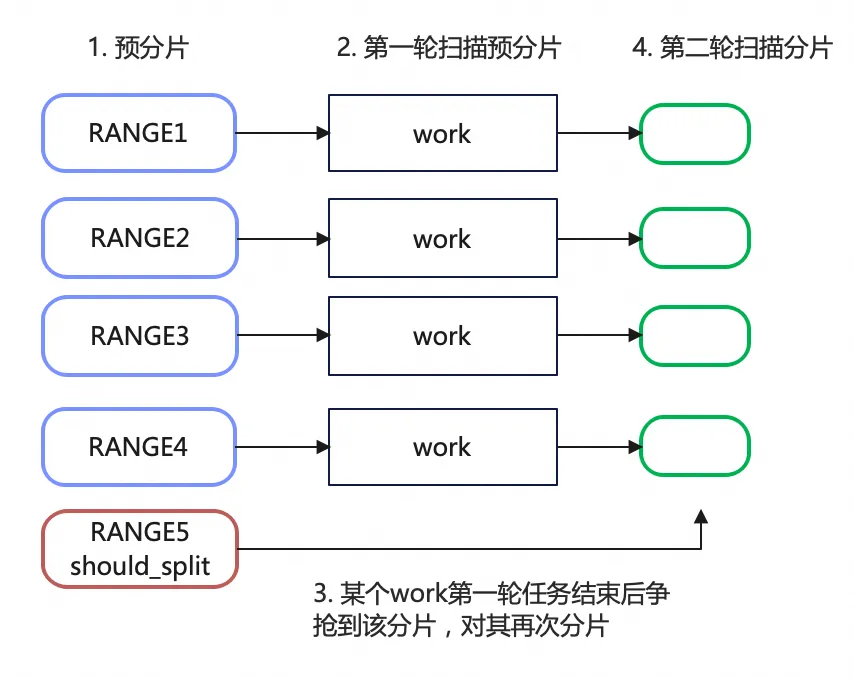
再次分片时,过程与ROOT PAGE分片过程、加锁逻辑基本一致,但由于前后两次分片期间放掉了INDEX、ROOT
PAGE的S锁,子树结构可能发生了变化。因此不能直接按分片的子树数量划分,需要按分片的RANGE来对其划分。
具体如下:
下图定位到叶子结点ID=301的记录,作为一个分界点。
获取SUB TREE ROOT的301后面的一个记录,定位到叶子结点,作为一个分界点。
依次类推,最后分为 301、401、501、null四个边界点。

二次分片后相当于分了两层,根节点划分一次,根节点的子树再分一次。这里最多分两次,由于B+树比较矮胖层级不会太高,分两次后已经能够将大表划分为比较多的子树了,能够提升并行线程利用率。
扫描过程
每个work对子树分片[start, end)的扫描过程与单线程扫描整棵B+树过程基本一致:
1. 恢复出start的游标所对应的叶子结点page;
对叶子结点乐观加S锁
乐观加锁失败则需要从ROOT重新定位到该记录,对叶子结点加S锁
2. 扫描页内记录,对每条记录做MVCC可见性判断,旧版本数据的构建;
3. 到达页面最大记录,获取next page,对next page加S锁;
4. 释放该page的S锁,对next page重复上述扫描过程,直到扫描到分片end。
每个在扫描过程中仅持有单个LEAF PAGE的S锁,对page加S锁后一次性处理完页内所有记录,再解锁,去处理下一个page。这一点比单线程扫描时页内对每个记录都要加锁、解锁的效率要高。
回调函数
parallel_work
|--> process one row
| |--> callback
| | |--> counter++
|
并行扫描设计了一套通用的接口,在并行扫描时通过回调函数对行记录做处理,每个work线程每扫描完一行记录都会调用一次回调函数。
对于COUNT(*)语句,回调函数内容为对线程级别的计数器执行加1操作。在并行扫描结束后,累加所有计数器即可获取结果。
并行效果
来看下COUNT(*)并行扫描的效果,使用一张包含4亿行记录的Sysbench表进行了测试,测试配置:
sysbench测试数据量4亿行的单表,大小约95GB。
innodb_buffer_pool_size=128GB (纯内存场景)。
cpu:Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz,
52核
os:4.19.91-013.ali4000.alios7.x86_64
磁盘:SSD
mysql:8.0.37
测试前预热多次将数据全部加载进buffer pool,测试过程buffer pool命中率100%。
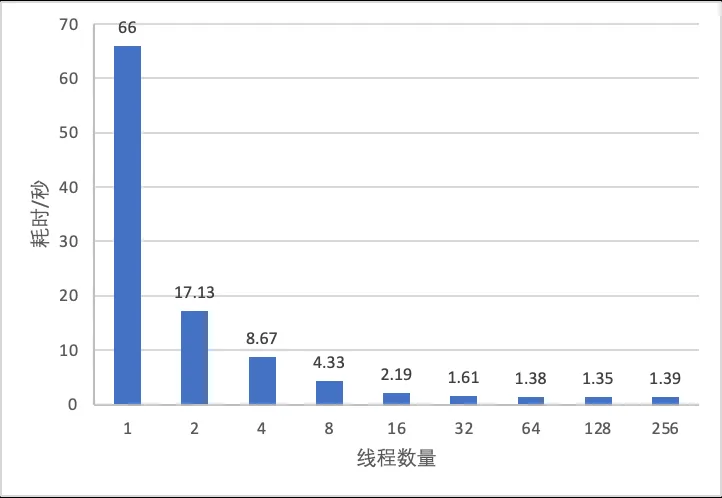
并行效果明显,线程数量在2-32之间增加时,每增加一倍,耗时下降一倍,呈线性下降趋势。
高并发下无线性趋势,仍然存在并发线程利用率问题。
线程数由1提高到2,时间变为原来的1/4,原因:线程数为1时,并不是使用单个work线程来扫描,而是回退为原有用户线程串行扫描逻辑,这里每扫描完一行,使用row_search_mvcc函数(1600行)来定位下一行,row_search_mvcc函数在这种场景效率较差,其中较多的变量定义、if条件判断都无需执行,并且加锁效率不高。并行work线程扫描定位下一行记录的操作只用了100行代码实现,且加锁效率高,效率会比row_search_mvcc高。
性能回退问题
官方8.0.14-8.0.36版本,COUNT(*)语句支持对主键索引的并行扫描,不支持二级索引的并行扫描及单线程扫描。即使优化器选择的索引为二级索引时,执行阶段InnoDB也会强制使用主键索引来并行扫描。这会导致性能回退:多线程扫描主键索引耗时可能大于单线程扫描二级索引。
为什么会带来性能回退?单线程扫主键、单线程扫二级索引时间复杂度都是o(n),如果是纯内存场景,对每行数据仅执行count++操作,不会发生性能回退。如下表所示。
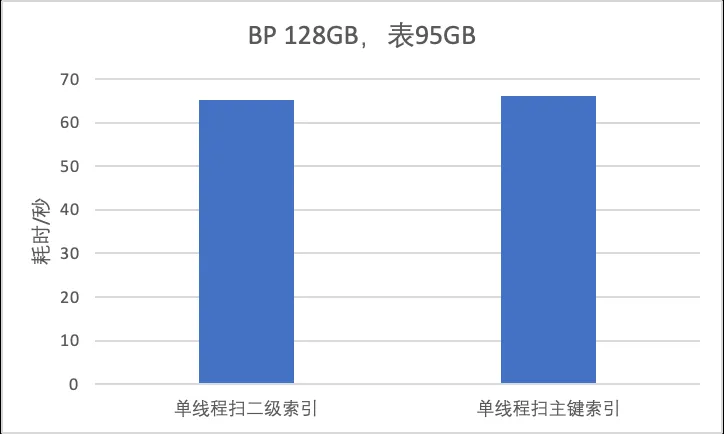
但是当buffer pool较小时,耗时主要消耗在将数据页读入buffer pool。由于主键索引比二级索引磁盘占用大很多,扫描主键的IO次数远高于扫描二级索引,于是多线程扫描主键索引不如单线程扫描二级快。当表主键索引越大时,性能影响会越严重。
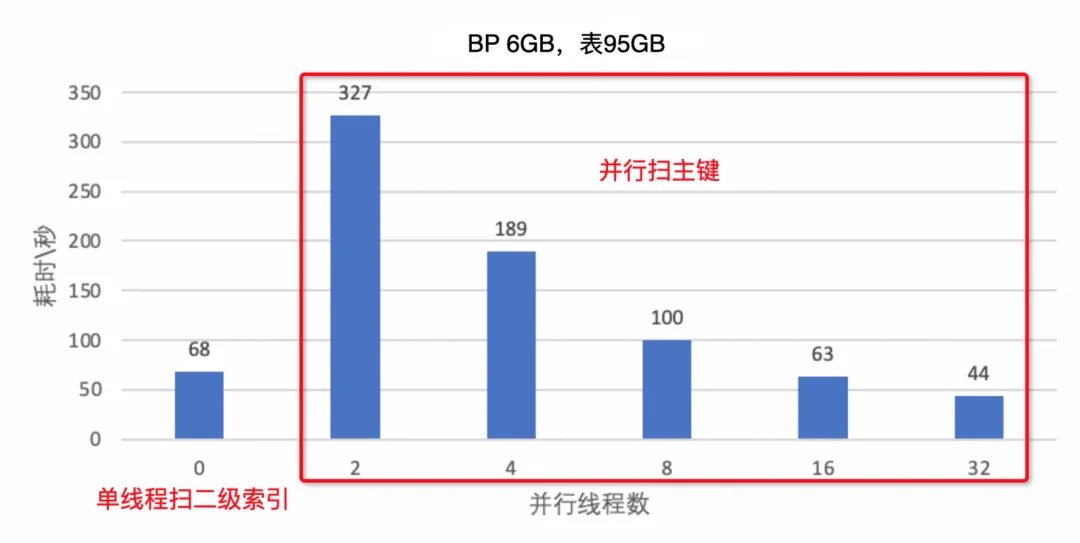
上表为buffer pool配置为6GB,使用95GB的sysbench表的测试结果。其中并行线程为16扫描主键索引才能超过单线程扫描二级索引的性能。当表主键索引越大时,性能影响会越严重。
AliSQL在8.0.25发现并修复了该问题,当指定innodb_parallel_read_threads为0时,退化为使用优化器选择的索引来进行扫描。
官方在8.0.37修复了该问题,不再强制主键索引来执行COUNT(*)语句,当优化器选择二级索引时,执行单线程扫描;当优化器选择主键索引时,执行并行扫描。release
note: "MySQL no longer ignores the Optimizer
hint to use a secondary index scan, which instead
forced a clustered (parallel) index scan."。
3.2 并行CHECK TABLE
简单介绍下InnoDB层CHECK TABLE语句执行过程。CHECK TABLE语句在InnoDB层执行时会遍历表的每一个索引,依次对每一个索引做如下检查:
1. 第一次扫描索引,主要验证B+树结构正确性, 从root层到leaf层逐层扫描:
从当前层级最左结点开始,依次遍历到最右结点;
检查页面一致性:一些FLAG检查、PAGE_MAX_TRX_ID检查、PAGE directory、RECORD验证等。这里会在页面内从页最小记录遍历到页最大记录;
检查结点指针指向正确性;
检查父节点指向正确性;
检查相邻页面之间记录的有序性:结点最大记录小于右结点的最小记录;
.....
2. 第二次扫描索引,是按行记录扫描,从B+树最小记录开始遍历到最大记录,依次比较相邻记录的大小是否符合预期。
这里第一次扫描索引为单线程扫描。在第二次扫描索引时,如果是主键索引,那么支持并行扫描,对于二级索引仍然是单线程扫描。
并行扫描
CHECK TABLE并行扫描与SELECT COUNT(*)实现一致,区别在于回调函数上。
COUNT*(*):work统计每个子树的count,结束后汇总。
CHECK TABLE:work比较每棵子树内部叶子结点记录的顺序性。这里没有检查子树之间顺序性,因为第一次扫描时做了页面之间顺序性的检查。
CHECK TABLE work线程在扫描子树时,每扫描完一行主键记录,会执行一次回调函数,回调函数逻辑为比较当前行与前一行的顺序性:
1. 若为分片最左记录,设置 pre_record = nullptr。
2. 若 pre_record 指针非空,比较 current_record 与 pre_record
大小是否符合预期。不符合预期则报错返回,符合预期则继续。
3. 设置 pre_record = current_record。
4. 返回成功。
并行效果
先来看下CHECK TABLE并行扫描的效果,使用一张包含4亿行记录的Sysbench表进行了测试,测试配置与COUNT(*)中的配置相同。sysbench原生表包含一个主键索引,一个二级索引,在CHECK
TABLE时会对每个索引做两次扫描。
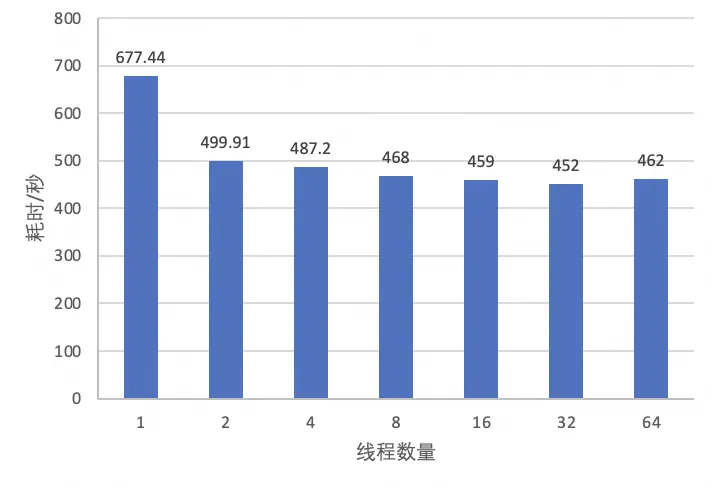
线程数由1提高到2,耗时下降明显,但这里的收益不是并行扫描带来的,原因和COUNT(*)中线程数1变为2的现象一致:原有单线程扫描效率较差。
线程数从2开始增加后,效果有所提升但不太明显,说明CHECK TABLE耗时的大头在第一次扫描上。
可优化点
看完CHECK TABLE的并行过程,可以发现有一些可以优化的地方。
1. 可以以索引为粒度并行。当前索引之间不支持并行CHECK,当二级索引数量较多时,会比较耗时,可以考虑增加一个以索引为粒度来并行CHECK的逻辑。
2. CHECK TABLE第一次扫描索引时,理论上也可以划分为多个子树,做并行CHECK。不过需要额外考虑两点:1
非叶子结点也需要扫描;2 子树边界结点的CHECK。
3. CHECK TABLE第一次扫描索引时,已经遍历了所有的记录,在遍历过程中就可以比较记录之间的顺序性了,并且相邻页面的顺序性也已经做了检查,第二次再来扫一次索引来比较全部记录顺序性似乎没有必要。
4. CHECK TABLE第二次扫描二级索引时是否可以支持并行。看起来似乎没必要支持,因为这里大头在于扫描主键索引上。
04 并行DDL
4.1 并行创建二级索引
先简要介绍下InnoDB层创建二级索引语句执行过程,可分为三个阶段:
1. 扫描:从最小记录到最大记录依次扫描聚簇索引,构建出二级索引行记录,然后将二级索引行记录做一些小的内存排序,内存满了就写入临时文件。
2. 排序:对临时文件进行排序。
3. 构建:将排序后的数据插入到二级索引树。
每个阶段并行的粒度、实现都有所不同:
1. 第1阶段可通过前文所述的并行扫描来加速,并行粒度为子树级别,通过 innodb_parallel_read_threads
参数可配置并行扫描线程数量。每个线程内存排序的buffer大小为innodb_ddl_buffer_size/innodb_parallel_read_threads。
2. 第2阶段可利用多线程来做并行排序,并行粒度为临时排序文件数量,通过 innodb_ddl_threads
参数来配置并行排序线程数量。
3. 第3阶段将排序后的数据构建为二级索引树的过程为单线程执行。
ddl::Context::build // 建二级索引、重建表入口
|-> ddl::Loader::build_all
| |-> scan_and_build_indexes // 重建表时有多个INDEX
| | |-> scan // CREATE INDEX时并行扫主键索引,重建表时单线程扫
| | | |-> Parallel_reader.add_scan(bulk_inserter)
// 每扫描一行的回调函数
| | | |-> Parallel_reader.run // 并行扫描
| | |-> load // 多线程排序、构建
| | | |-> mt_execute
| | | | |-> Loader::Task::operator()
| | | | | |-> Builder::merge_sort // 排序,Builder::State::SORT
| | | | | |
| | | | | |-> Builder::btree_build // 构建,Builder::State::BTREE_BUILD
|
并行扫描
并行扫描时,每个work线程会创建一个临时文件,一个排序buffer,work线程每扫描完一行主键记录,就会调用一次回调函数,回调函数所做的事情为:
1. 根据主键记录构建二级索引行记录
2. 将行记录写入线程级别的buffer
3. buffer没写满,则直接返回
4. buffer写满后对buffer内的记录使用归并排序算法做内存排序。排序结束后得到了一个有序list,将这个有序list写入临时文件。然后清空buffer。
写入第一个有序list到临时文件过程,一个有序list的大小为buffer大小:
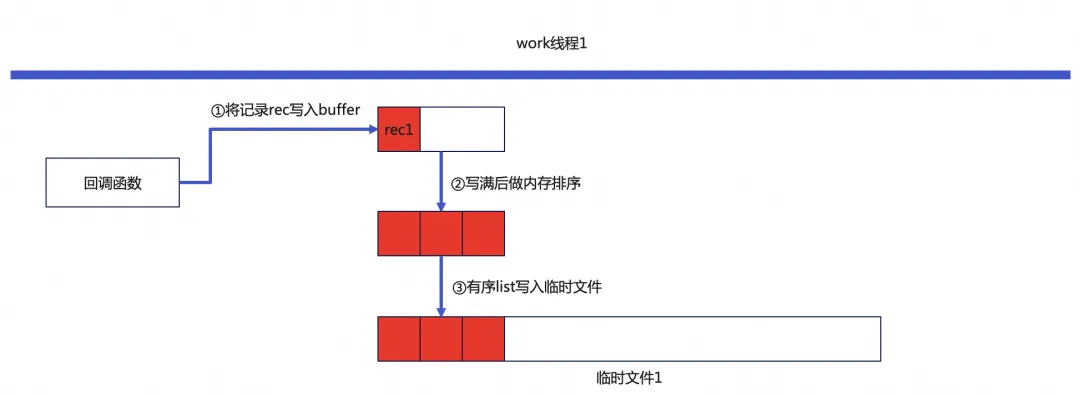
work线程1扫描完一个分片后,临时文件1上会有多个有序list:

work线程不停从队列中取出分片来做扫描,扫描过程中会将一个个有序list写入对应的临时文件。假设innodb_parallel_read_threads为3,那么有3个并行扫描线程,共3个临时文件,所有分片被并行扫描结束后,会得到3个局部有序的文件,每个文件由多个有序list构成:

小结
这里对并行扫描做一个小结,并行扫描work线程每扫描完一行主键记录,都会执行一次回调函数。通过对不同的上层SQL设计对应的回调函数以完成相应的并行任务。COUNT(*)全表、CHECK
TABLE、建立二级索引的并行扫描执行过程是一样的,并行扫描线程由innodb_parallel_read_threads参数控制,三者的主要区别在回调函数上,小结如下表。

理论上需要扫描B+树的过程都可以用这套并行接口来将其划分为多个子树来并行扫描,例如
除COUNT(*)外其他的聚合函数(sum、avg)
一些where 语句
范围查询 (start,end)
analyze table
并行排序
DDL的排序、构建都作为任务由work线程完成,work从任务队列取出任务来执行,通过任务状态确定是排序还是构建。
DDL_parallel_work
|-> Loader::Task::operator() // 执行任务
| |-> Builder::merge_sort // 排序,Builder::State::SORT
| |
| |-> Builder::btree_build // 构建,Builder::State::BTREE_BUILD
|
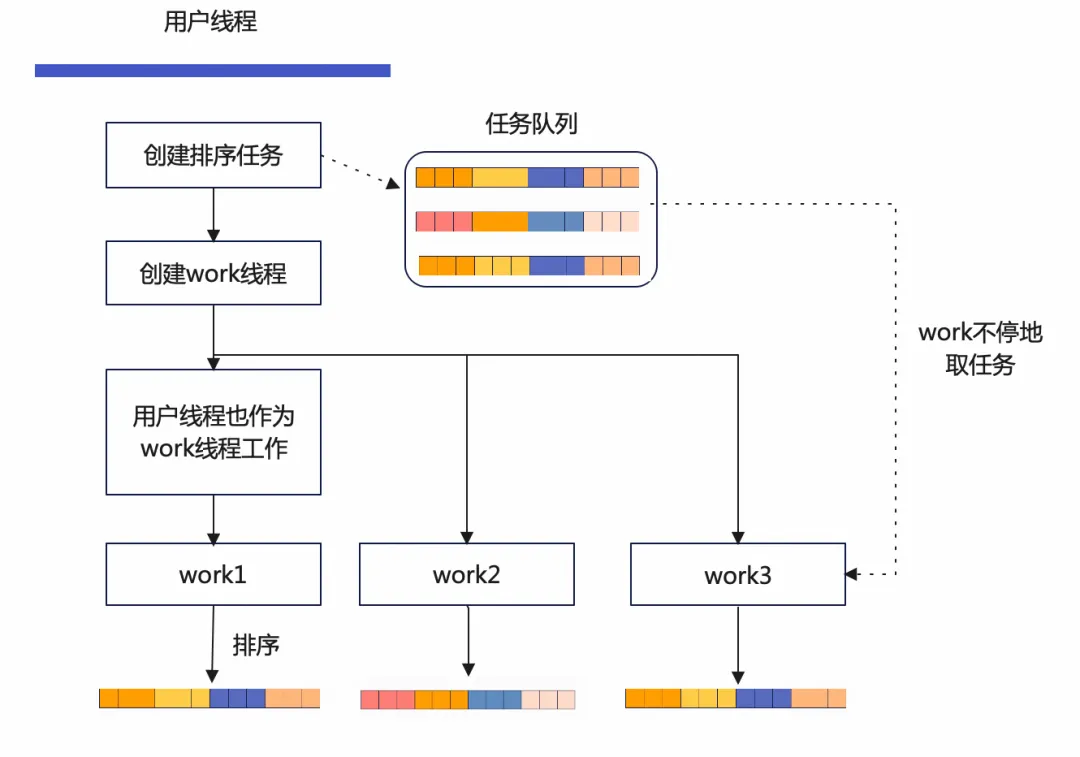
并行扫描结束后,得到了3个局部有序的临时文件,3个文件的集合构成一个二级索引的全部记录。用户线程会创建3个排序任务(实际上排序任务也可能由work线程创建,这里简化描述),将任务状态设置为Builder::State::SORT。
这里的并行粒度为临时文件级别,每个临时文件对应一个排序任务。用户线程创建work线程后作为work线程处理从队列中获取任务来执行。work线程会从队列中不停取出任务来执行。这一点与并行扫描有所区别,并行扫描中用户线程没有作为工作线程。
可以发现并行排序的任务数量由临时文件数量决定,而临时文件数量由并行扫描线程数决定,前文假设 innodb_parallel_read_threads
为3,这里即使设置innodb_ddl_threads为6,那么也只有3个任务,实际执行的DDL排序线程数量也为3。若设置innodb_ddl_threads为2,那么会有1个DDL线程处理两个临时文件。所以使用上建议设置innodb_parallel_read_threads
、innodb_ddl_threads两者为同一个值。
DDL线程文件排序过程使用归并排序算法,会创建一个新的临时文件辅助排序。假设临时文件1包含4个有序list,那么第一轮归并排序后得到包含两个有序的list的文件,两轮归并排序后便可以得到一个全局有序的临时文件:
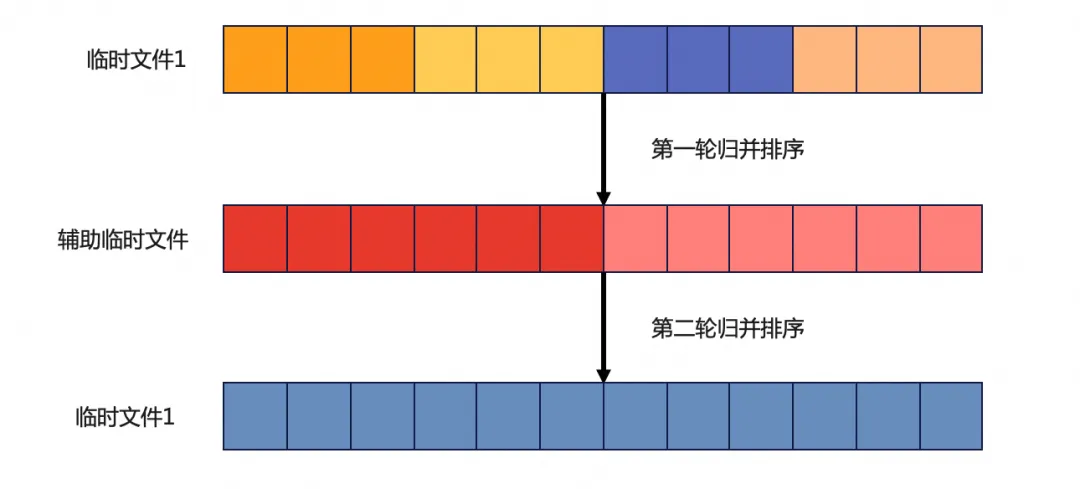
所有并行排序任务结束后,会得到3个有序的临时文件,不会再将这三个文件归并排序为一个文件:
单线程构建
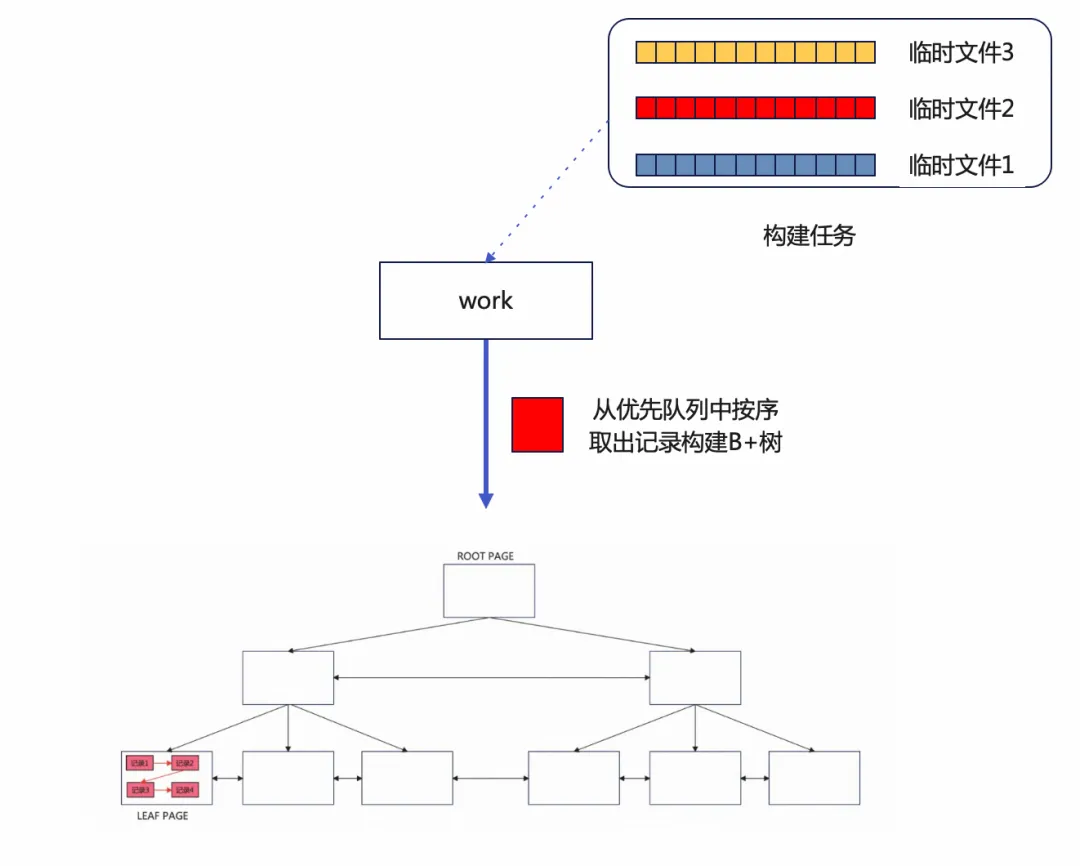
所有的DDL work线程完成并行排序后,会得到3个有序的临时文件,并没有将这3个临时文件归并排序为一个有序的文件。会将3个临时文件构造成一个优先队列,添加一个构建任务,设置任务状态为Builder::State::BTREE_BUILD。然后会由一个work线程执行该构建任务,会从优先队列中按序取出记录,逐行写入B+树,完成构建过程。具体构建过程本文不再叙述。
并行效果
看下并行建立索引的效果,使用一张包含4千万行(大小约9.5GB)记录的Sysbench表进行了测试其余配置与3.1节中的配置相同。测试SQL为给sysbench表的pad列添加二级索引:
create
index idx1 on sbtest1 (pad); |
为观察各阶段的并行效果,进行了几个对照实验。
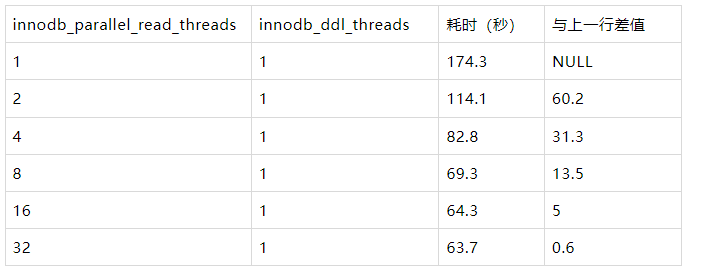
为分析第一阶段并行扫描效果,上表固定innodb_ddl_threads为1,innodb_ddl_buffer_size=4GB,将这个值设置得尽可能的大可以使得数据在内存全部完成排序,可以尽可能减少第二阶段文件排序的耗时,减少对第一阶段并行扫描的干扰。增加innodb_parallel_read_threads后:
耗时有所下降,说明第一阶段的并行扫描发挥了作用,并且二、三阶段耗时不是大头。
耗时没有随innodb_parallel_read_threads增加而线性下降,说明第二、第三阶段会消耗一部分时间,
每两次实验的耗时之差基本随innodb_parallel_read_threads增加而线性下降,说明第一阶段并行扫描效果符合预期。
与COUNT(*)、CHECK TABLE并行扫描不同的是,innodb_parallel_read_threads为1时,这里会采用单个并行work线程来扫描索引,所以不会出现COUNT(*)在单并发时的效率较差的问题。

为分析第二阶段并行排序效果,上表固定innodb_parallel_read_threads为1,innodb_ddl_buffer_size为32MB,增加innodb_ddl_threads后,可以发现DDL并行线程没有发挥作用,原因后文分解。
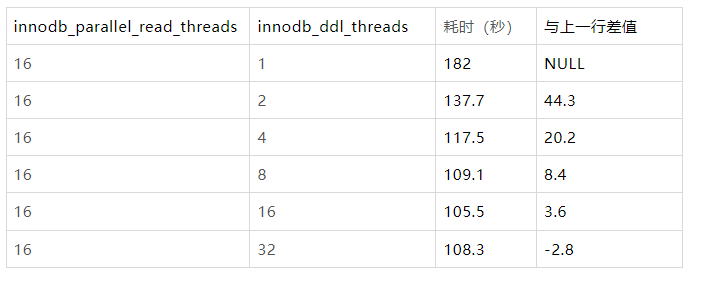
为进一步分析第二阶段并行排序效果,上表固定innodb_parallel_read_threads为16,使得第一阶段并行扫描耗时尽可能的小,减少对第二阶段的干扰。
innodb_ddl_buffer_size为32MB,每个并行线程分配得到的buffer size为32MB/16=2MB,buffer用于内存排序,设置比较小的buffer
size可以使得内存排序数量少,进而使得文件排序任务耗时变长,能更显著的观察到并行排序的提升效果(可模拟线上大表,创建二级索引时需要大量的文件排序场景)。然后逐渐增加innodb_ddl_threads。
每两次实验的耗时之差基本随innodb_ddl_threads增加而线性下降,说明第二阶段并行排序符合预期。
4.2 并行重建表
介绍下InnoDB重建表语句执行过程,可分为3个阶段:
1. 扫描:从主键B+树第一条记录开始依次遍历B+树,直到最后一条记录,跳过空洞记录。每扫描完一行做如下操作:
直接将主键记录按序写入新的主键索引B+树(主键是有序的,无需再次排序)
对于要重建的二级索引,构建二级索引行记录,将记录写入排序buffer,满了后再写临时文件
2. 排序:对二级索引临时文件进行排序;
3. 构建:将排序后的二级索引数据插入到二级索引树。
相比CREATE INDEX语句,多了1.a 构建主键B+树的操作,以及可能会创建多个二级索引。如果只重建一个二级索引,那么1.b、2、3这3步就是一个CREATE
INDEX操作。
重建表时每个阶段是否支持并行、并行的粒度都与并行创建二级索引有较大的区别。
重建表的一个重要作用是重建主键索引B+树,回收空洞,收缩表空间。主键B+树本身是有序的,也就没必要对其做并行排序,只需要从小到大串行的扫描主键索引,然后将主键行记录一行行的按序插入新的B+树中,就可以获得一棵紧凑的主键B+树。
这一过程看下来没必要对重建主键索引的过程做并行化,MySQL本身也是这么做的:重建表时扫描主键索引不支持并行,innodb_parallel_read_threads参数对重建表不生效。
由此带来的副作用是对于要重建的单个二级索引,在扫描阶段也无法并行写入多个临时文件了。并且在排序阶段,也无法对单个索引做并行排序。
但是,这里二级索引的排序、构建阶段仍然是支持并行的,只不过并行的粒度变成了索引级别。假设有4个二级索引要被重建,那么这里4个二级索引之间的排序、构建可由DDL并行线程来并行处理。
单线程扫描
重建表主键B+树的扫描过程由用户线程单线程完成,假设原表有1个主键索引,3个二级索引,那么扫描过程会为每个二级索引创建一个临时排序文件,总共为3个临时文件。每扫描完1行主键记录,会做如下操作:
将该主键记录插入新的主键B+树。
根据主键记录构建3个对应的二级索引行记录,分别写入3个临时文件。
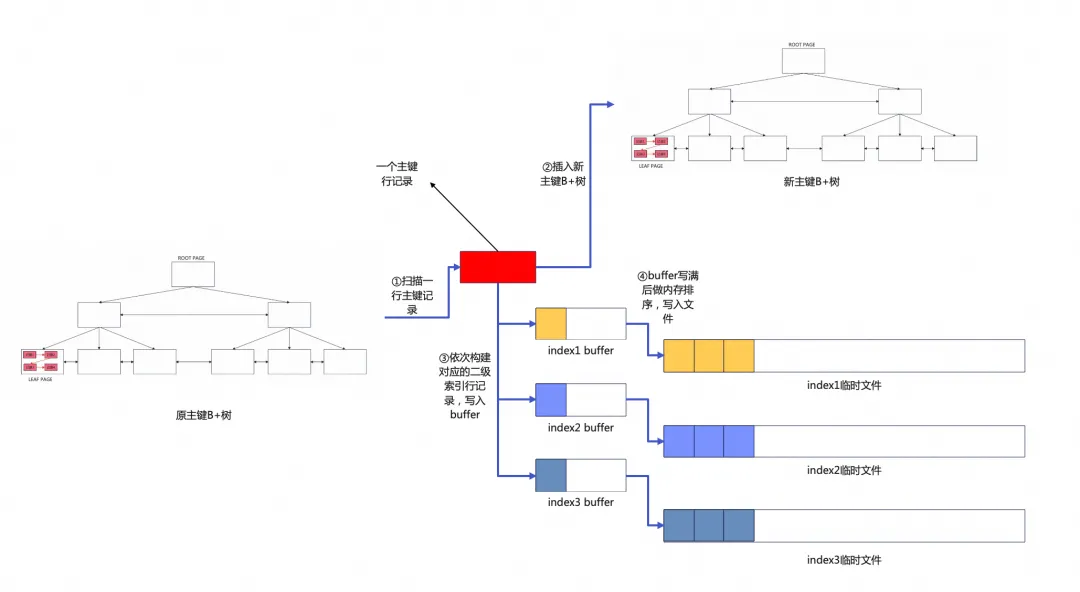
单线程扫描结束后,会得到1棵新的紧凑的主键B+树,3个局部有序的临时文件,每个临时文件对应于一个二级索引记录集合:
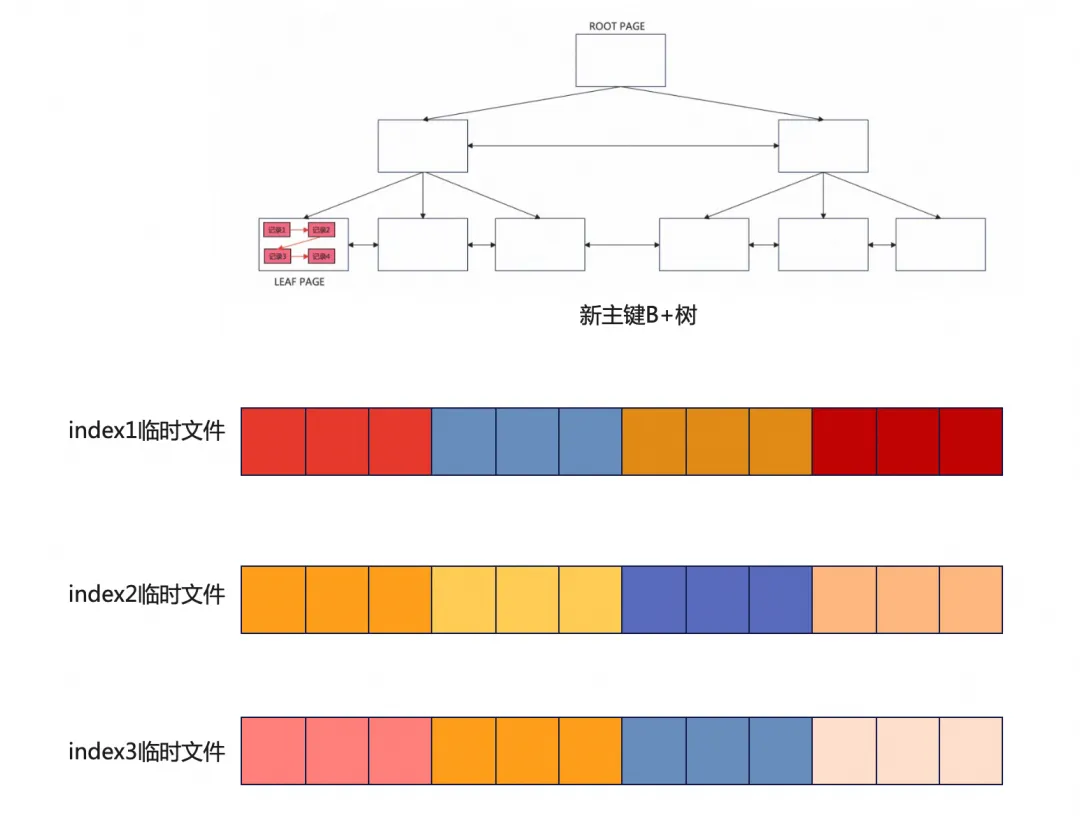
并行排序
重建表并行排序与CREATE INDEX并行排序实现相同,区别在于并行粒度不同。
前文说到创建二级索引时,其多线程排序并行任务数量由innodb_parallel_read_threads决定,会为单个索引创建innodb_parallel_read_threads个临时文件,在索引内部并行排序。重建表时使用单线程扫描,可以理解为innodb_parallel_read_threads为1。那么这里单个二级索引的临时文件只有一个,这种并行排序架构下二级索引内部是无法做并行排序的。
但是多个二级索引之间支持并行,也就是说这里并行的粒度为索引级别。这里的三个INDEX的临时文件会作为3个排序任务被添加到任务队列中,由work线程取出任务,完成对INDEX临时文件的排序。任务队列如下,每个任务对应一个INDEX,对应一个局部有序的临时文件。
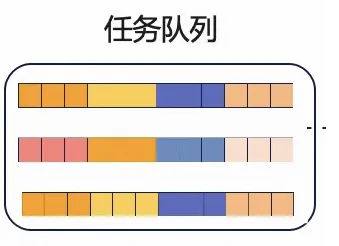
假设innodb_ddl_threads配置为3,那么会有3个线程并行,每个线程对应一个索引,对应一个临时文件。每个线程都会对临时文件做归并排序,归并排序结束后,得到3个文件,每个文件都按序记录了所对应的二级索引的全部记录。

并行构建
这里不再需要重新创建新的work线程,上一步创建的work线程不会退出,在这里仍然是从任务队列里取出任务来执行,只是任务由排序变为了构建。上一步每一个排序任务对应一个索引,每一个排序任务结束后都会自动添加一个构建任务,将任务状态设置为
Builder::State::BTREE_BUILD 并将其放入任务队列。这里添加了3个构建任务,每个构建任务对应一个索引的构建。
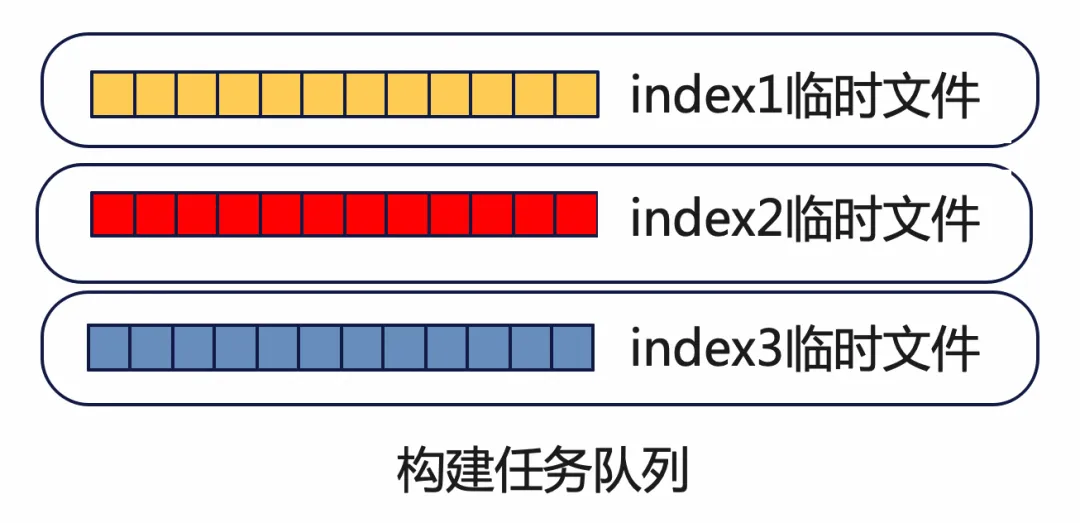
每个DDL线程负责扫描一个index的构建,按序读取行记录,逐行构建新的紧凑的二级索引B+树。最后重建表过程完成后,就得到了1棵新的紧凑的主键B+树,3棵新的紧凑的二级索引B+树。
小结
重建表并行构建、重建表并行排序、CREATE INDEX并行排序、CREATE INDEX单线程构建实现相同,区别在于并行粒度、并行任务不同。重建表并行构建与重建表并行排序都是以索引为粒度进行,线程数量由innodb_ddl_threads决定。总结如下表。

并行效果
来看下并行重建表的效果,使用一张包含4千万行(大小约9.5GB)记录的Sysbench表进行了测试,innodb_ddl_buffer_size=65536,
其余配置与3.1节中的配置相同。测试包含两种表:
1. sysbench原生表:包含1个主键索引+1个二级索引。
2. sysbench索引加二表:包含1个主键索引+3个二级索引,在sysbench原表基础上为pad、c列添加两个二级索引:
create index idx1 on sbtest1
(pad);
create index idx2 on sbtest1
(c);
|
测试SQL为重建表语句:
ALTER
TABLE sbtest1 ENGINE = INNODB; |

可以发现重建表时innodb_parallel_read_threads参数没有带来性能提升
innodb_ddl_threads对包含多个二级索引的重建表语句进行并行处理带来了性能提升,当二级索引数量越多时,并行度越高。
05 总结
本文介绍了MySQL在InnoDB层所提供的并行加速技术的基本使用、效果、原理以及一些使用限制,部分查询、DDL支持了并行扫描、并行排序、并行构建B+树,这些技术AliSQL已全部包含,欢迎用户使用。MySQL当前支持的并行语句还比较有限,期待社区在未来推出更多的并行语句支持,AliSQL团队也会在并行查询、DDL上新增特性,未来将支持并行扫描二级索引。以下为一些使用建议。
建议根据实例规格、负载情况设置合适的innodb_parallel_read_threads、innodb_ddl_threads、innodb_ddl_buffer_size参数;
并行扫描对COUNT(*)全表语句效果提升明显,可根据表大小设置合适的innodb_parallel_read_threads参数;
并行扫描对CHECK TABLE语句提升效果一般,CHECK TABLE时建议设置innodb_parallel_read_threads值为2;
对于创建二级索引的语句,并行扫描、并行排序均有明显的性能提升,建议设置innodb_parallel_read_threads、innodb_ddl_threads为相同的值,可根据表大小设置合适的值,当增加innodb_parallel_read_threads时,建议同时增加innodb_ddl_buffer_size;
对于重建表语句,并行带来的提升明显,支持以索引为并行粒度的文件排序、重建,可根据原表索引数量设置对应的innodb_ddl_threads值,innodb_parallel_read_threads参数无需设置,innodb_ddl_buffer_size可根据内存使用情况设置。 | 





 订阅
订阅