| 编辑推荐: |
文章主要介绍了从一个事故中理解Redis(几乎)所有知识点。希望对你的学习有帮助。
本文来自于微信公众号阿里云开发者,由火龙果软件Linda编辑、推荐。 |
|
阿里妹导读
作者从一个事故中总结了Redis(几乎)所有的知识点,供大家学习。
简单回顾
事故回溯总结一句话:
(1)因为大KEY调用量,随着白天自然流量趋势增长而增长,最终在业务高峰最高点期占满带宽使用100%。
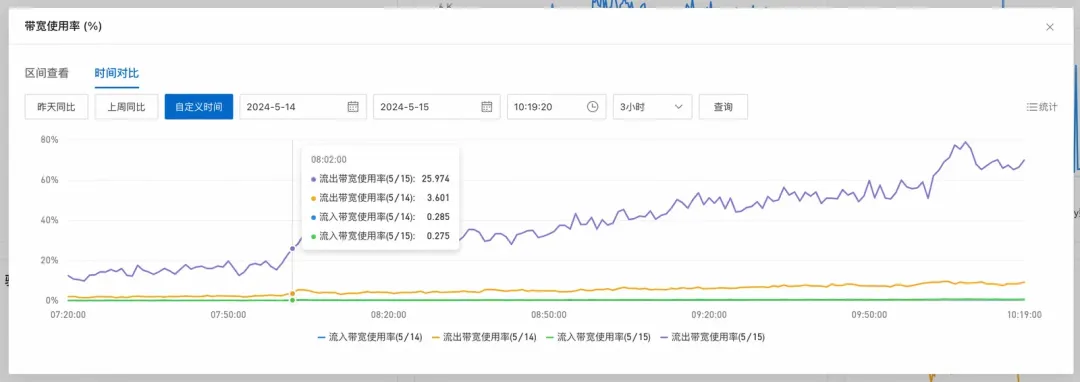
(2)从而引发redis的内存使用率,在5min之内从0%->100%。
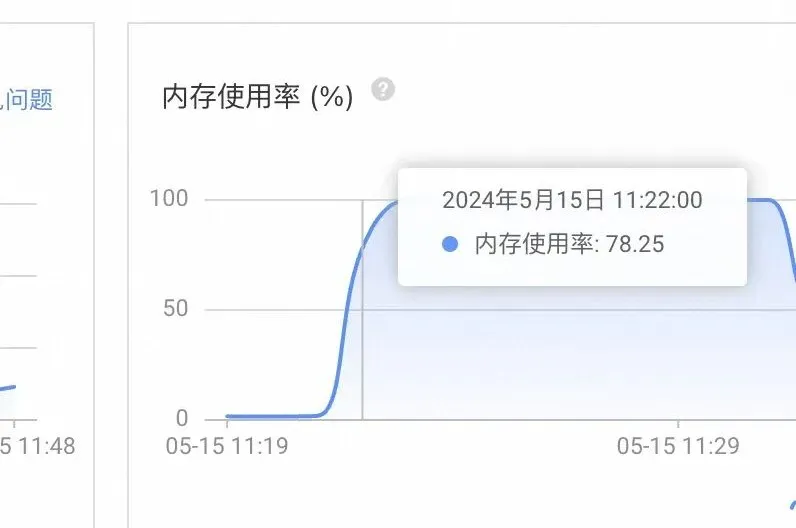
(3)最终全面GET SET timeout崩溃(11点22分02秒)。
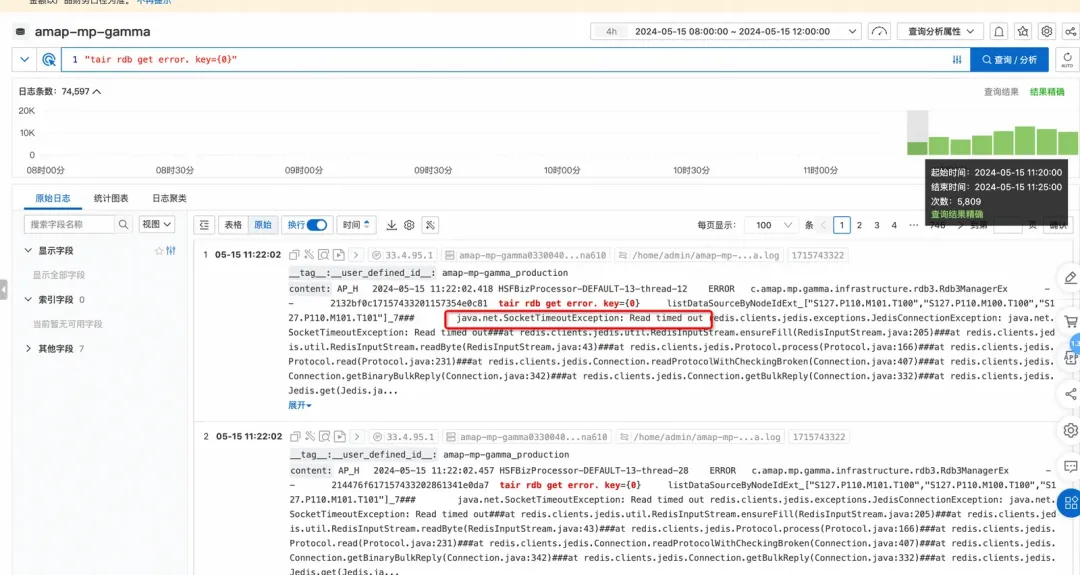
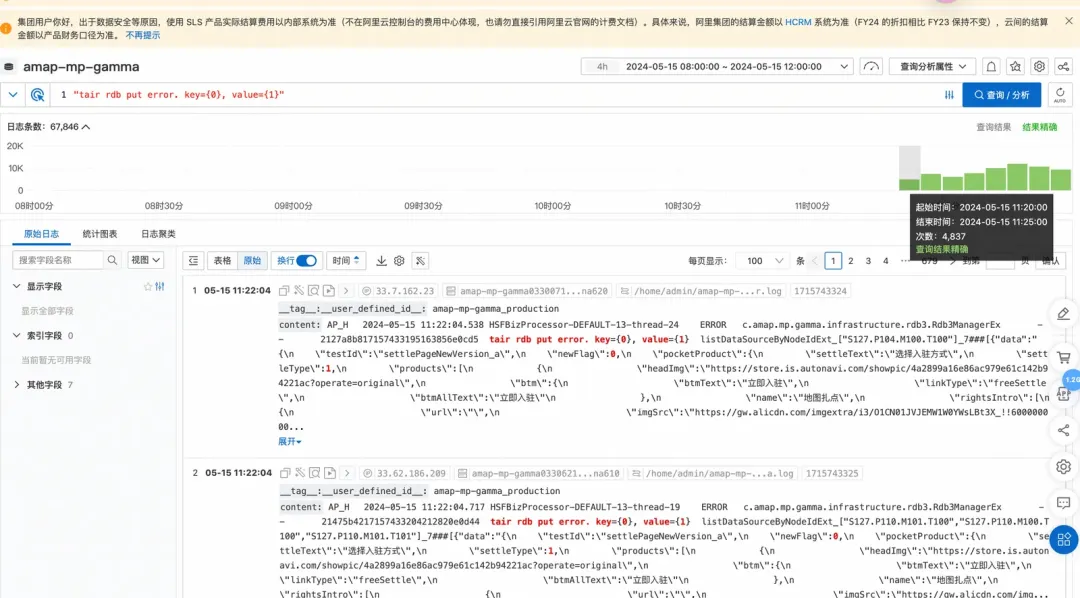
(4)最终导致页面返回timeout。
未解之谜
疑问点:内存使用率100% 就等同于redis不可用吗?
解答:正常使用情况下,不是。
redis有【缓存淘汰机制】,Redis 在内存使用率达到 100% 时不会直接崩溃。相反,它依赖内存淘汰策略来释放内存,确保系统的稳定性。

这个配置在哪里?
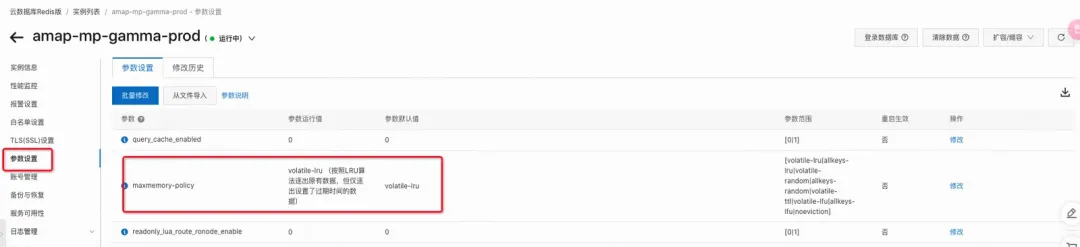
大部分同学都是不会主动去调整这里的参数的。
因此大概率默认的是:volatile-lru
行为: 使用 LRU(Least Recently Used,最近最少使用)算法驱逐键。volatile-lru
仅驱逐设有过期时间的键,allkeys-lru 则驱逐所有键。
适用场景: 缓存场景,不介意丢失一些数据。
确保你根据实际需求配置适当的内存淘汰策略,以便在内存达到上限时,系统能够稳定地处理新请求,而不会出现写操作失败的情况(只要不是noeviction)。
也就是说,照理SET GET都应该没啥问题才对(先不考虑其他复杂命令)。
尽管 Redis 本身不会轻易崩溃,但如果内存耗尽且没有淘汰策略或者淘汰策略未能生效,Redis
可能拒绝新的写操作,并返回错误:OOM command not allowed when used
memory > 'maxmemory'
如果系统的配置或者操作系统的内存管理不当,可能会导致 Redis 进程被操作系统杀死。
疑问点:但是事故现象就是:内存使用率100% 时,redis不可用,怎么解释?
猜测1:会是淘汰不及时导致的性能瓶颈吗?
也就是说:写入的速度>>淘汰的速度。
解答:如果是正常的业务写入,不可能!
redis纯内存,淘汰速度是非常快的;
这个业务特性,也并非高频写入;
这个redis实例其实里面存储的KEY很少,最终占了整个实例的内存使用率<5%。

不太符合正常使用下KEY不断增多,最终挤爆内存使用率的问题。
因此,初步结论:Redis 的崩溃一般不会是由于单纯写入速度超过淘汰速度引起的,尤其是使用了合理的内存淘汰策略时;如果写入速度非常高,而淘汰策略无法及时清除旧数据,Redis
可能会非常频繁地进行键的查找和淘汰操作,从而导致性能下降。
具体机制如下:
过期 key 的自动删除机制。它是 Redis 用来回收内存空间的常用机制,应用广泛,本身就会引起
Redis 操作阻塞,导致性能变慢,所以,你必须要知道该机制对性能的影响。
Redis 键值对的 key 可以设置过期时间。默认情况下,Redis 每 100 毫秒会删除一些过期
key,具体的算法如下:
1.采样:
ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP 个数的 key,并将其中过期的
key 全部删除;
2.如果超过 25% 的 key 过期了,则重复删除的过程,直到过期 key 的比例降至 25% 以下。
ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP 是 Redis 的一个参数,默认是
20,那么,一秒内基本有 200 个过期 key 会被删除。这一策略对清除过期 key、释放内存空间很有帮助。如果每秒钟删除
200 个过期 key,并不会对 Redis 造成太大影响。
但是,如果触发了上面这个算法的第二条,Redis 就会一直删除以释放内存空间。注意,删除操作是阻塞的(Redis
4.0 后可以用异步线程机制来减少阻塞影响)。所以,一旦该条件触发,Redis 的线程就会一直执行删除,这样一来,就没办法正常服务其他的键值操作了,就会进一步引起其他键值操作的延迟增加,Redis
就会变慢。
那么,算法的第二条是怎么被触发的呢?其中一个重要来源,就是频繁使用带有相同时间参数的 EXPIREAT
命令设置过期 key,这就会导致,在同一秒内有大量的 key 同时过期。
可以类比JVM频繁GC造成的性能影响。
猜测2:那就是写入太凶猛,且是【非正常业务写入】
那到底是什么导致了内存使用率激增呢??
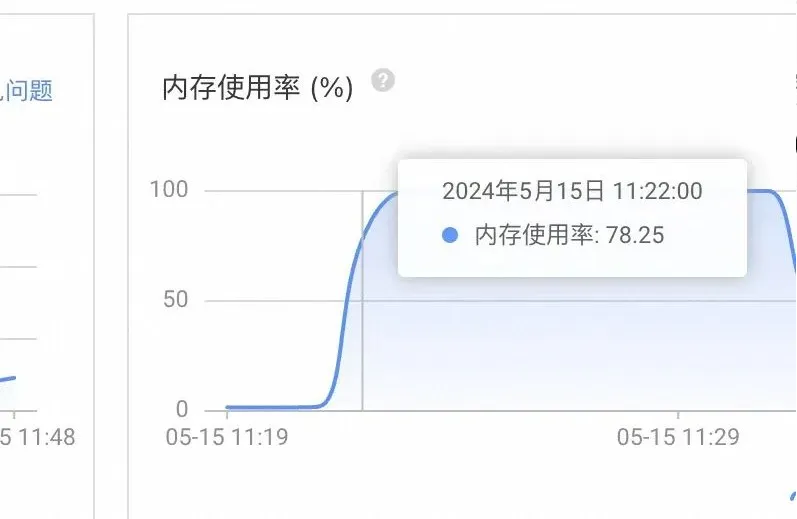

证据支撑
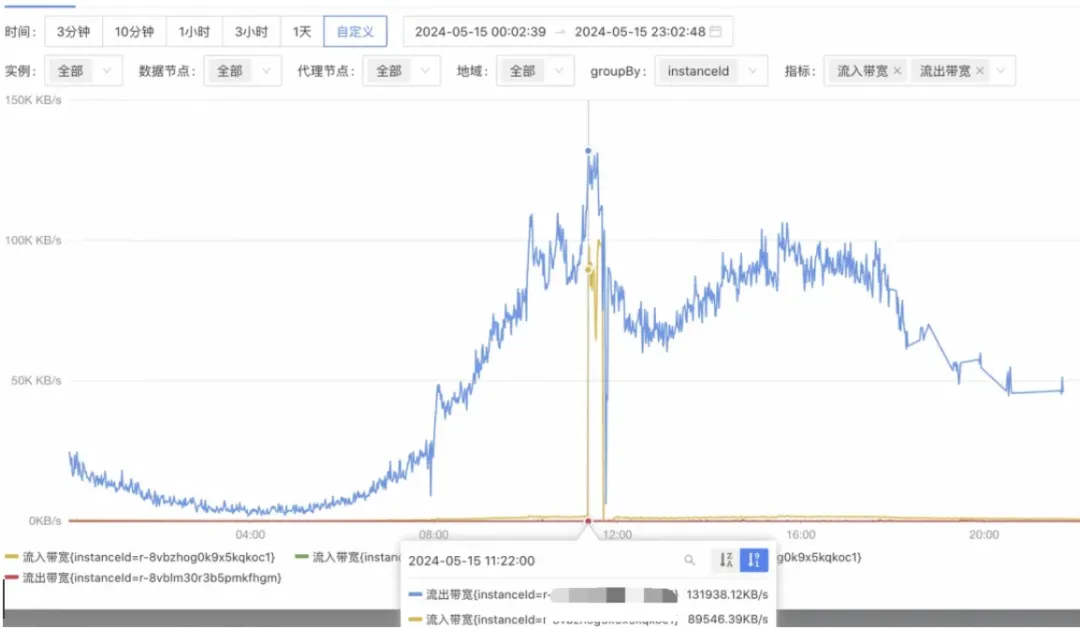
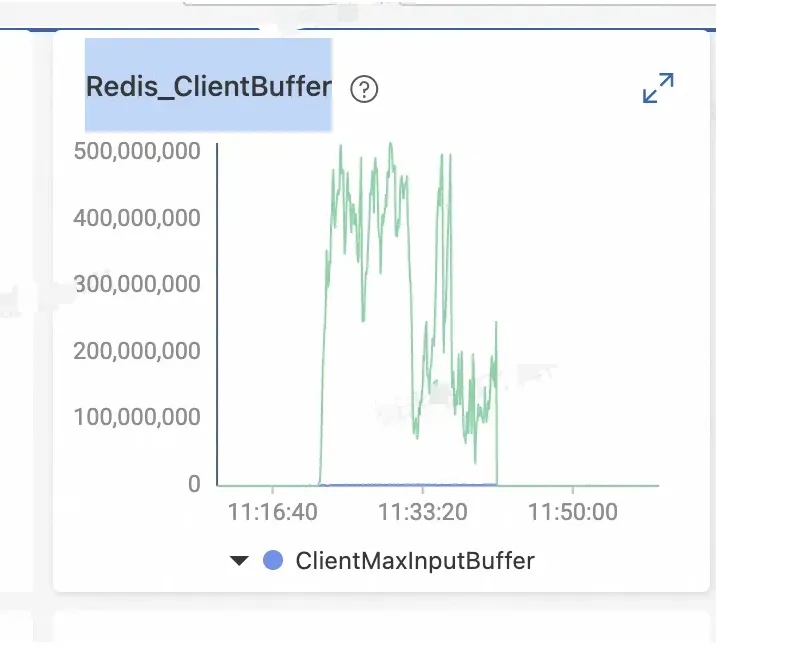
真相大白
果然是这样,说明内存是被【缓冲区】挤爆的。
知识点:Redis的内存占用组成
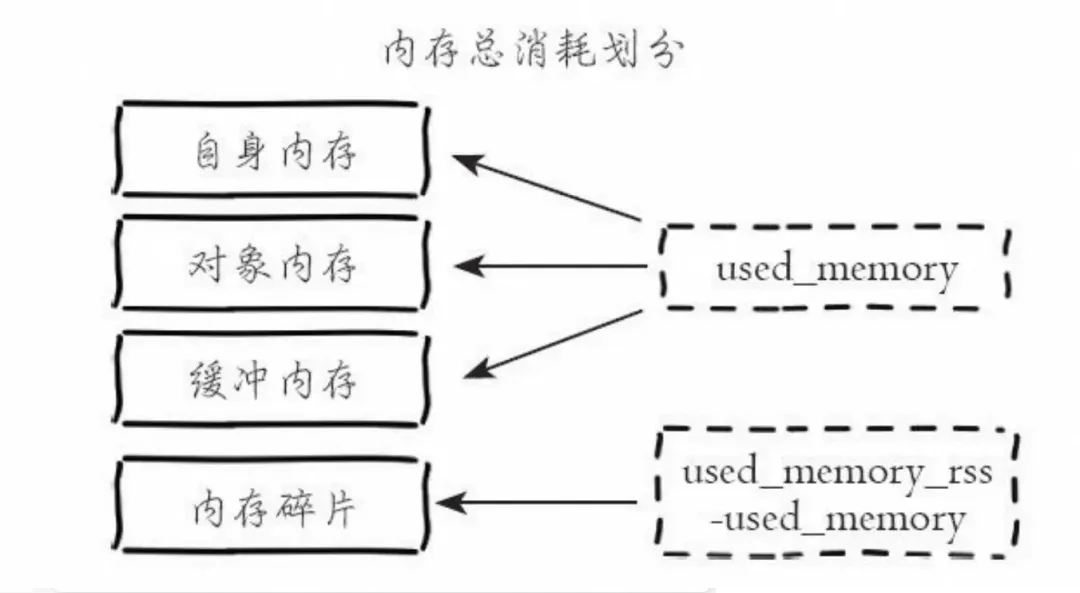
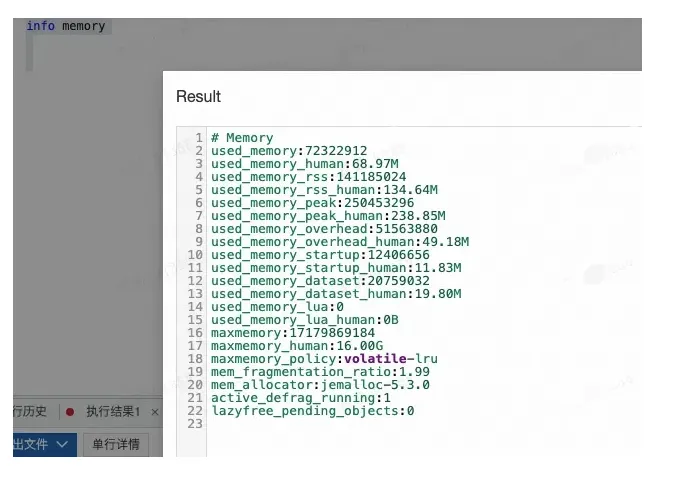
使用info memory进行分析(我随便模拟了一个缓冲区溢出的case,并非事故现场,因为当时不会)。
# Memory
used_memory:1072693248
used_memory_human:1023.99M
used_memory_rss:1090519040
used_memory_rss_human:1.02G
used_memory_peak:1072693248
used_memory_peak_human:1023.99M
used_memory_peak_perc:100.00%
used_memory_overhead:1048576000
used_memory_startup:1024000
used_memory_dataset:23929848
used_memory_dataset_perc:2.23%
allocator_allocated:1072693248
allocator_active:1090519040
allocator_resident:1090519040
total_system_memory:16777216000
total_system_memory_human:16.00G
used_memory_lua:37888
used_memory_lua_human:37.89K
used_memory_scripts:1024000
used_memory_scripts_human:1.00M
maxmemory:1073741824
maxmemory_human:1.00G
maxmemory_policy:noeviction
allocator_frag_ratio:1.02
allocator_frag_bytes:17825792
allocator_rss_ratio:1.00
allocator_rss_bytes:0
rss_overhead_ratio:1.00
rss_overhead_bytes:0
mem_fragmentation_ratio:1.02
mem_fragmentation_bytes:17825792
mem_not_counted_for_evict:0
mem_replication_backlog:0
mem_clients_slaves:0
mem_clients_normal:1048576000
mem_aof_buffer:0
mem_allocator:jemalloc-5.1.0
active_defrag_running:0
lazyfree_pending_objects:0
|
分析和解释
从上面的 INFO memory 输出中,我们可以看到一些关键信息,这些信息表明大部分内存被缓冲区占用殆尽:
1.内存使用情况:
used_memory: 1072693248 (1.02 GB)
maxmemory: 1073741824 (1.00 GB)
上面的输出表明,当前内存使用几乎达到了配置的最大内存限制,内存已接近耗尽。
2.缓冲区占用:
used_memory_overhead: 1048576000 (1.00 GB)
这个值表示 Redis 开销的内存,包括缓冲区、连接和其他元数据。在这种情况下,大部分 used_memory
(1.02 GB) 被 used_memory_overhead (1.00 GB) 占用,这意味着大部分内存都被缓冲区等开销占据。
3.数据集占用:
used_memory_dataset: 23929848 (23.93 MB)
used_memory_dataset_perc: 2.23%
这里显示,实际存储的数据只占了非常少的一部分内存(约 23.93 MB),而绝大部分内存被缓冲区占据。
4.客户端缓冲区:
mem_clients_normal: 1048576000 (1.00 GB)
这表明普通客户端连接占用了约 1.00 GB 内存,这通常意味着输出缓冲区可能已经接近或达到了设定的限制。
5.内存碎片:
allocator_frag_ratio: 1.02
mem_fragmentation_ratio: 1.02
碎片率不高,表明内存被合理使用但被缓冲区占用过多。
总结
从上面的例子可以看出,Redis 的内存几乎被缓冲区占用殆尽。以下是具体的结论:
当前内存使用 (used_memory) 已经接近最大内存限制 (maxmemory),即 1.02
GB 接近 1.00 GB 的限制。
内存开销 (used_memory_overhead) 很大,主要被客户端普通连接使用(可能是输出缓冲区),而实际的数据仅占用了很少的内存。
分配器和 RSS 碎片率 (allocator_frag_ratio 和 mem_fragmentation_ratio)
较低,表明碎片不是问题。
缓冲内存的理论最大值推导
为什么要有缓冲区
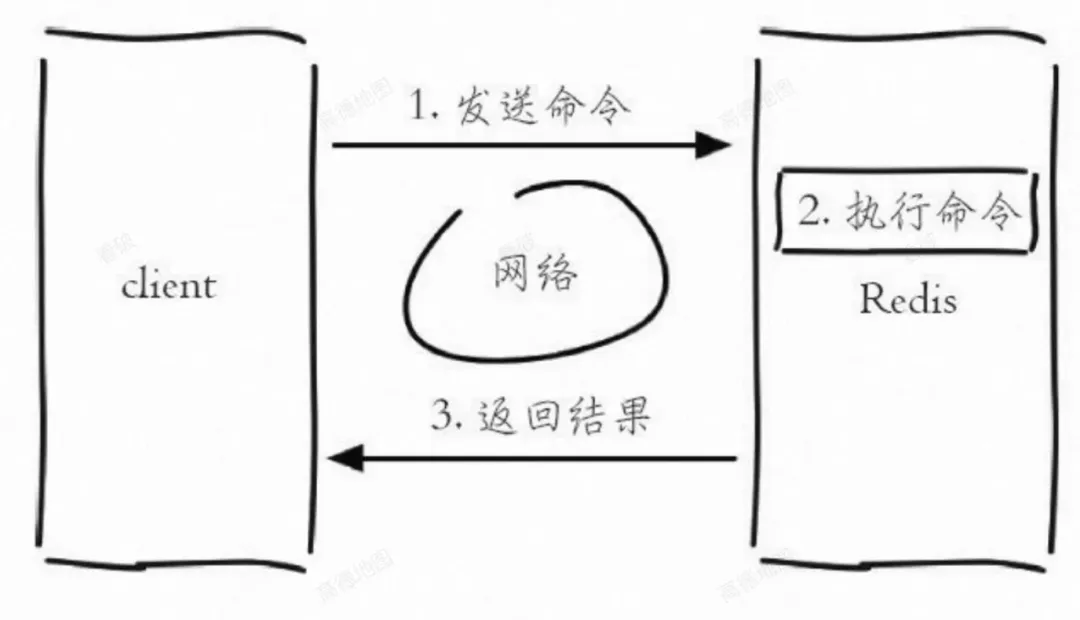
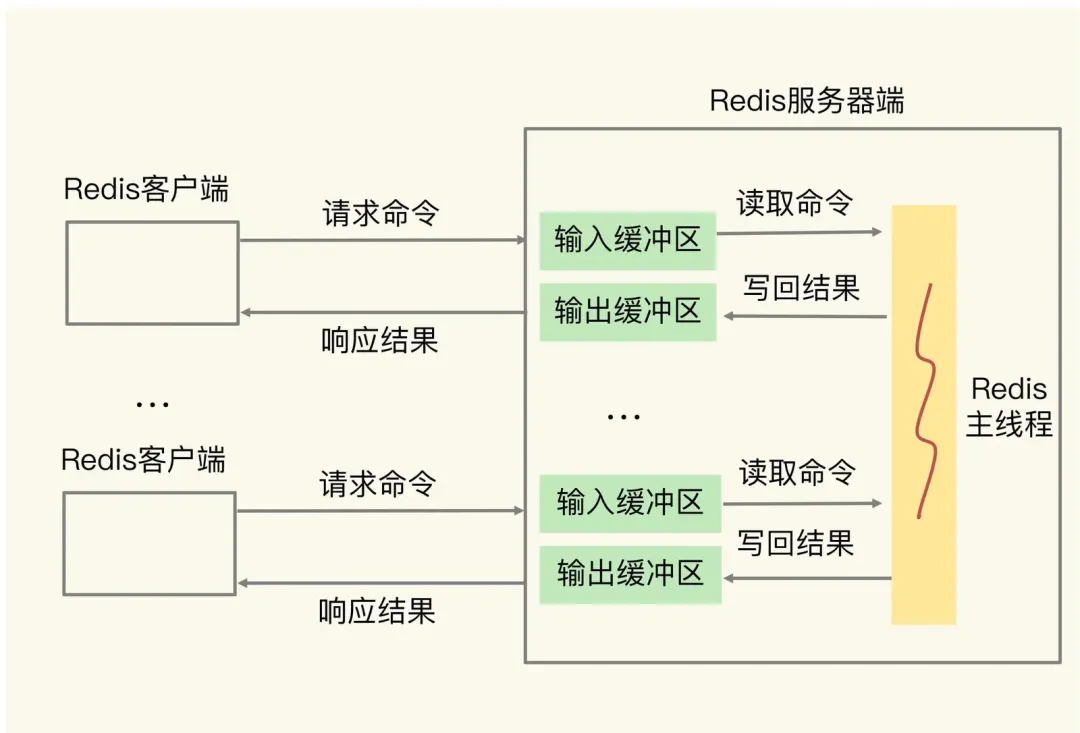
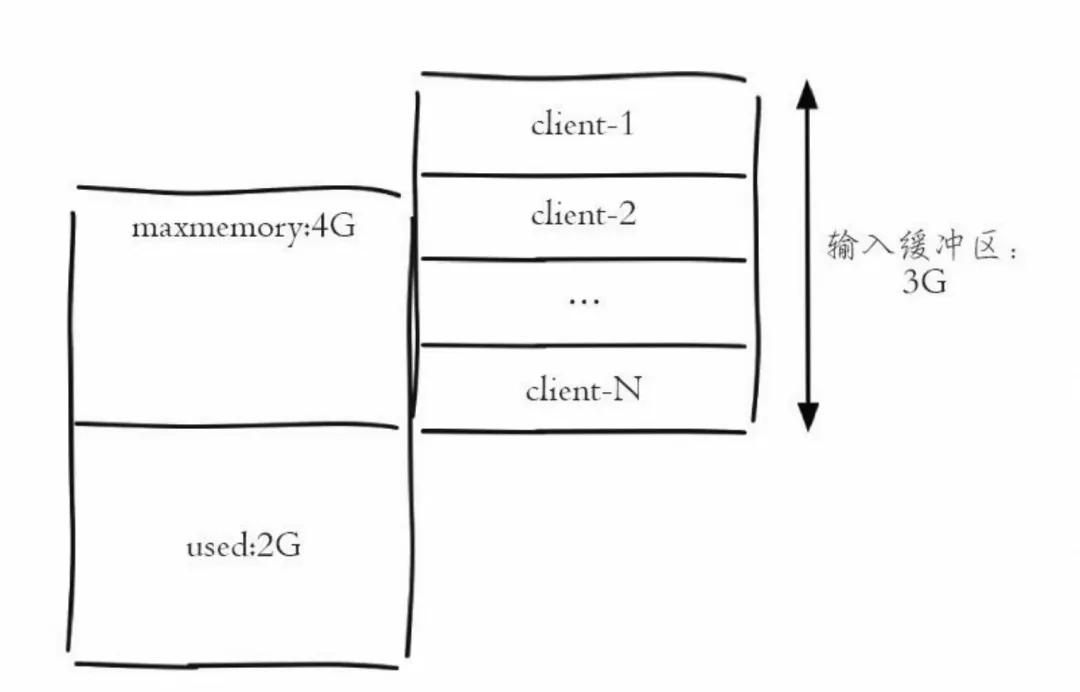
Redis工作原理-单客户端视角简单版:
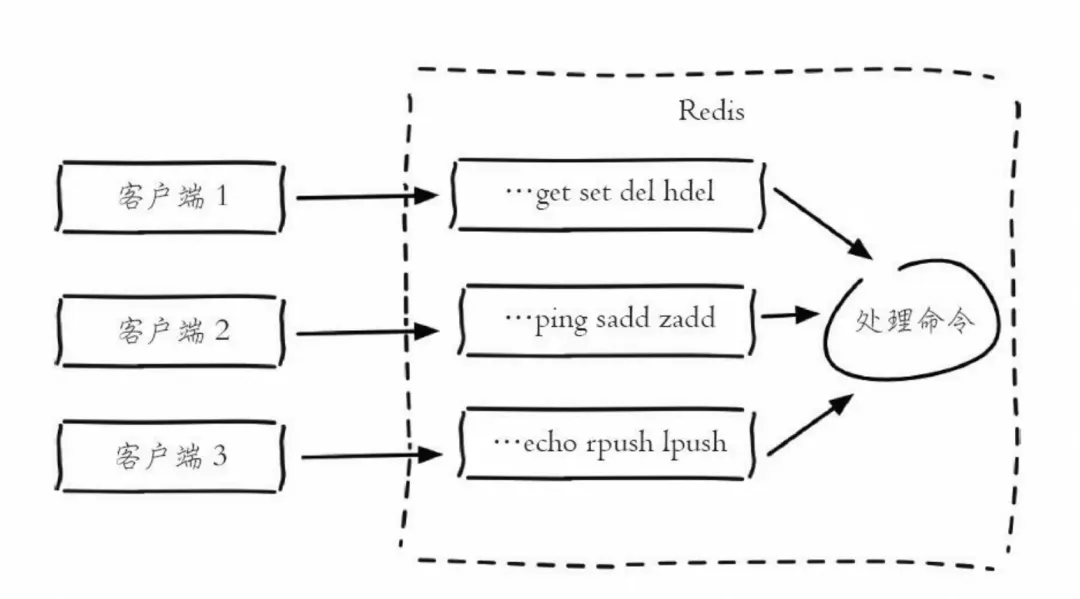
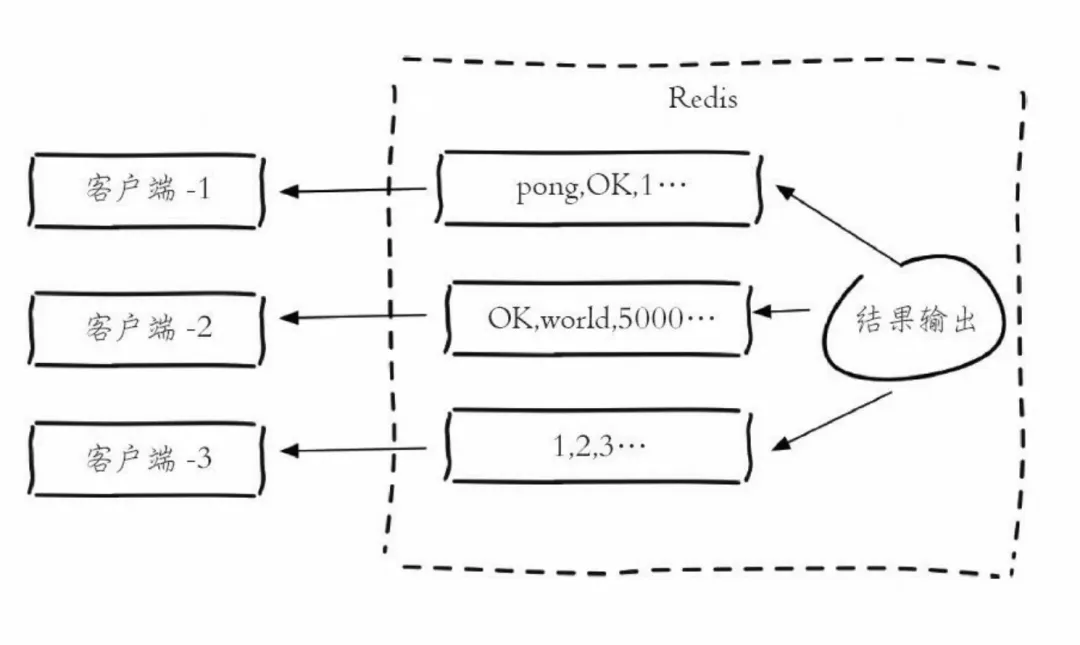
Redis工作原理-单客户端视角复杂版:
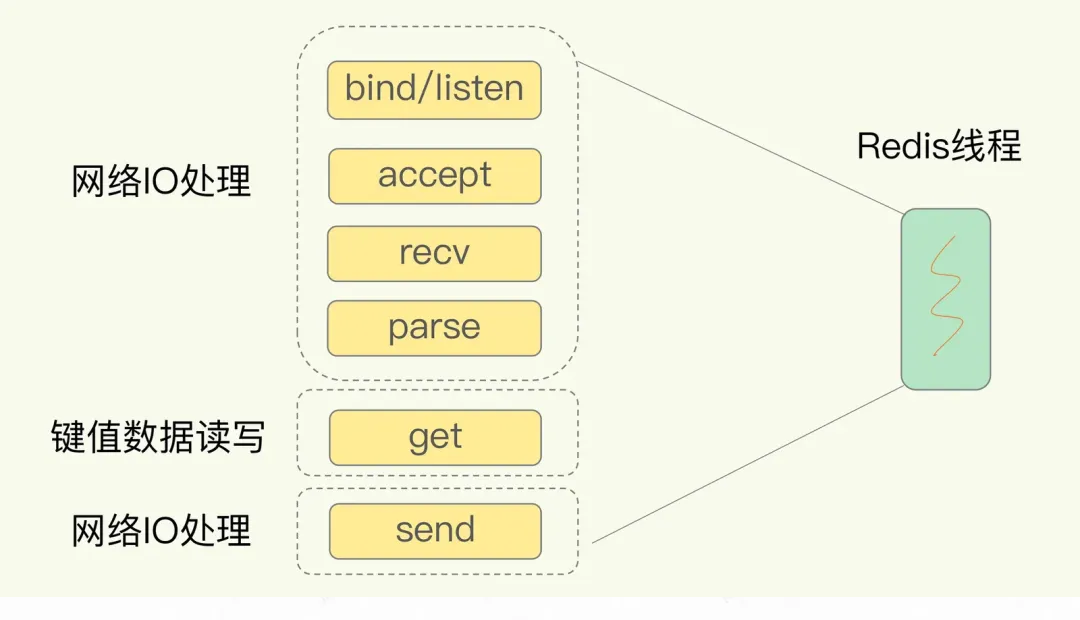
缓冲区的功能其实很简单,主要就是用一块内存空间来暂时存放命令数据,以免出现因为数据和命令的处理速度慢于发送速度而导致的数据丢失和性能问题。
因此,Redis工作原理-多客户端视角简单版(含缓冲区)。
输入缓冲区
定义
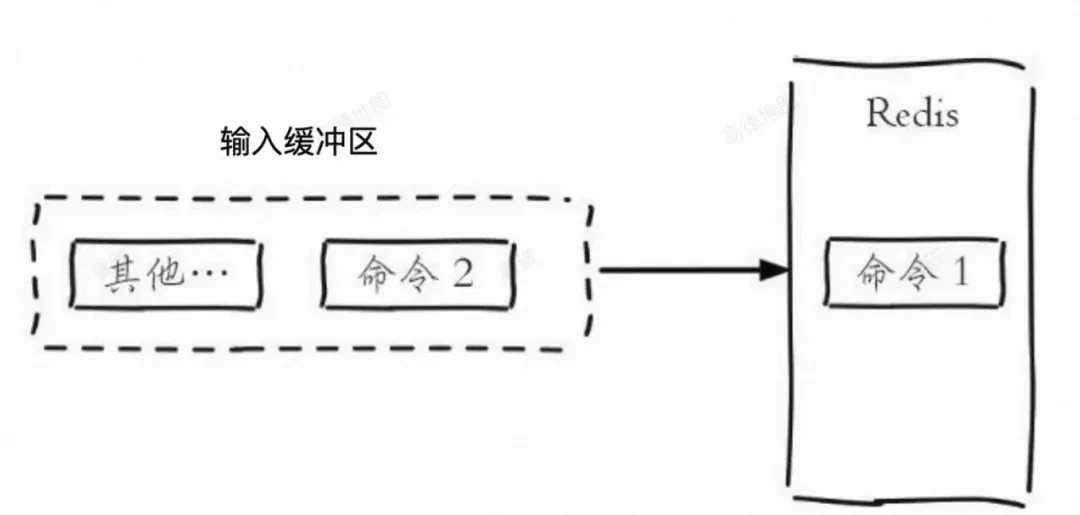
内存占用

输出缓冲区
定义
内存占用
Redis Server 的输出大小通常是不可控制的。存在bigkey的时候,就会产生体积庞大的返回数据。另外也有可能因为执行了太多命令,导致产生返回数据的速率超过了往客户端发送的速率,导致服务器堆积大量消息,从而导致输出缓冲区越来越大,占用过多内存,甚至导致系统崩溃。Redis
通过设置 client-output-buffer-limit来保护系统安全。

不出意外,默认是:32MB 8MB 60s
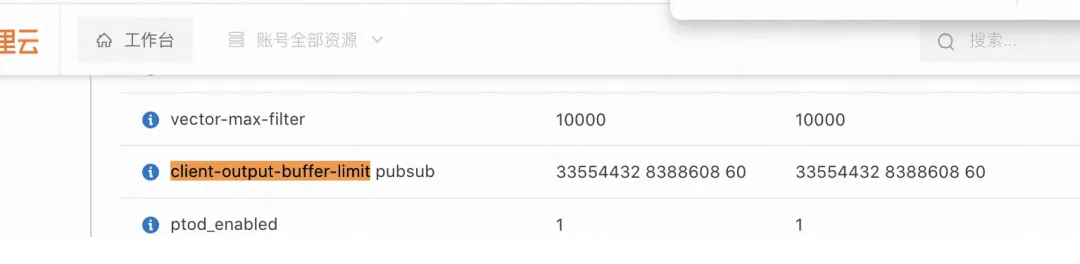
对于 Pub/Sub 连接:
硬限制:每个 Pub/Sub 客户端连接的输出缓冲区最大可以达到 32MB 。
连接池最大连接数:300 个连接,其中所有连接假设都在处理 Pub/Sub 消息且达到了最大缓冲区限制。
故理论上,最大输出缓冲区可以达到:
最大输出缓冲区占用=硬限制×连接池最大连接数最大输出缓冲区占用=硬限制×连接池最大连接数=32MB×300=9600MB=9.375GB
因此,在这种配置下,所有 Pub/Sub 连接的输出缓冲区理论上的最大占用内存为 9.375 GB。
因此,在client-output-buffer-limit是默认的情况下,最大占用内存为 9.375
GB。
所以,MAX(输出缓冲区+输入缓冲区)是否会造成内存使用率100%?
当然!
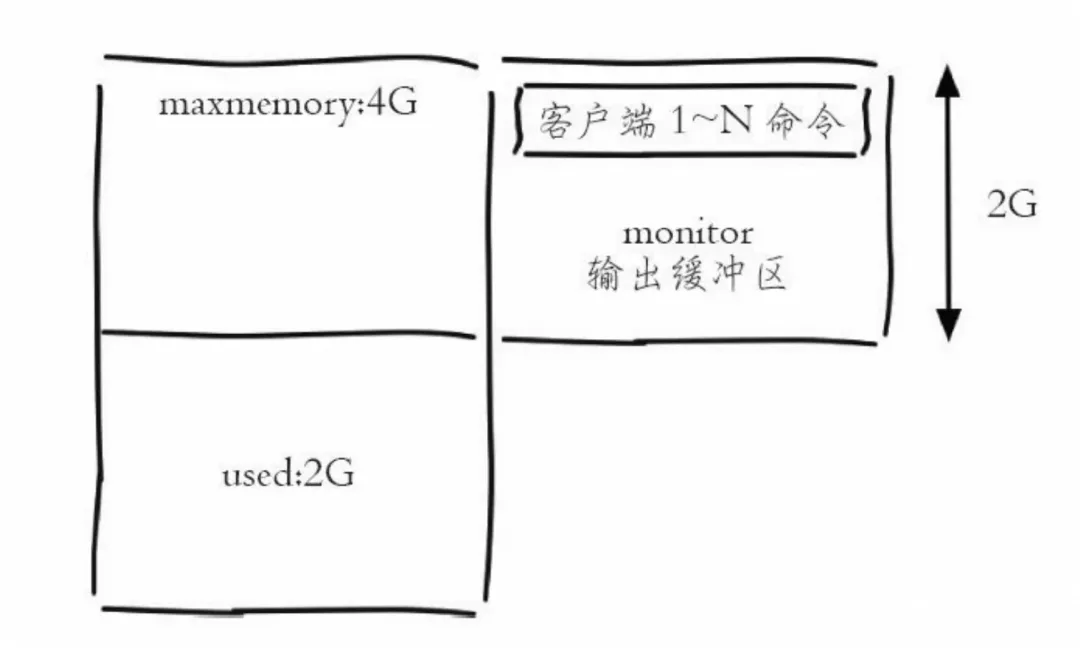
MAX(输出缓冲区+输入缓冲区)=10.375GB >> 一个实例的内存规格(在本case中,是2G)
最后的效果就是:
对象存储的部分因为是有过期时间的,过期了自然被清理了。
【缓冲内存】↑ (涌入)
【对象内存】↓ (定时清理)
并受MAX内存掣肘(上限)
最终的结局:Redis 的内存完全被缓冲区占据。
自然,每当有SET请求进来的时候,SET不进来——因为「内存淘汰策略」(maxmemory-policy)
淘汰的是【对象内存】,压根起不到作用!!!
结论:
Redis 的内存完全被缓冲区占据,实际上 Redis 将无法正常工作,包括数据存储(SET 操作)和数据读取(GET
操作)。
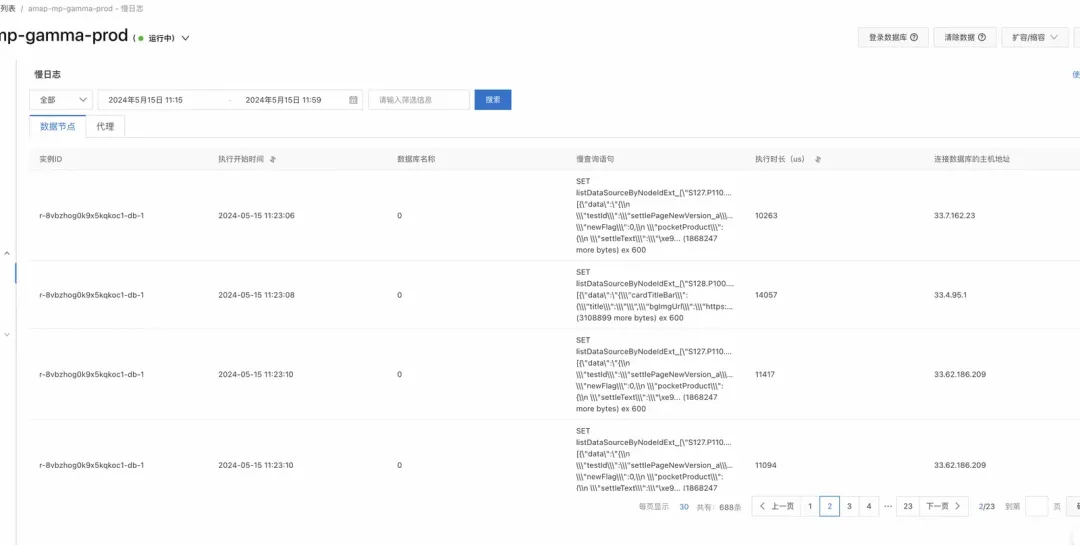
分析:为何缓冲区激增(Redis不可用的时间点11:22:02,之前都发生了什么)
知道了缓冲区挤爆Redis内存会导致Redis不工作之后,接下来就是分析为何当时出现了缓冲区激增并最终导致redis不可用。
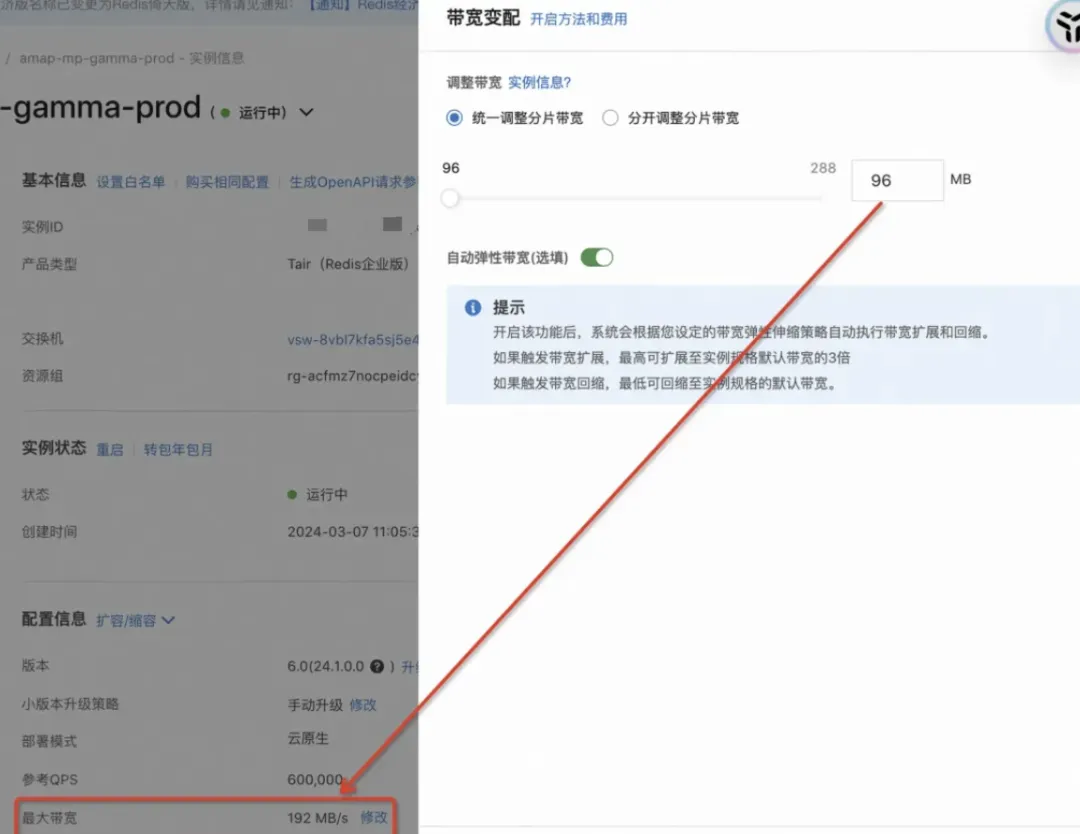
实例信息
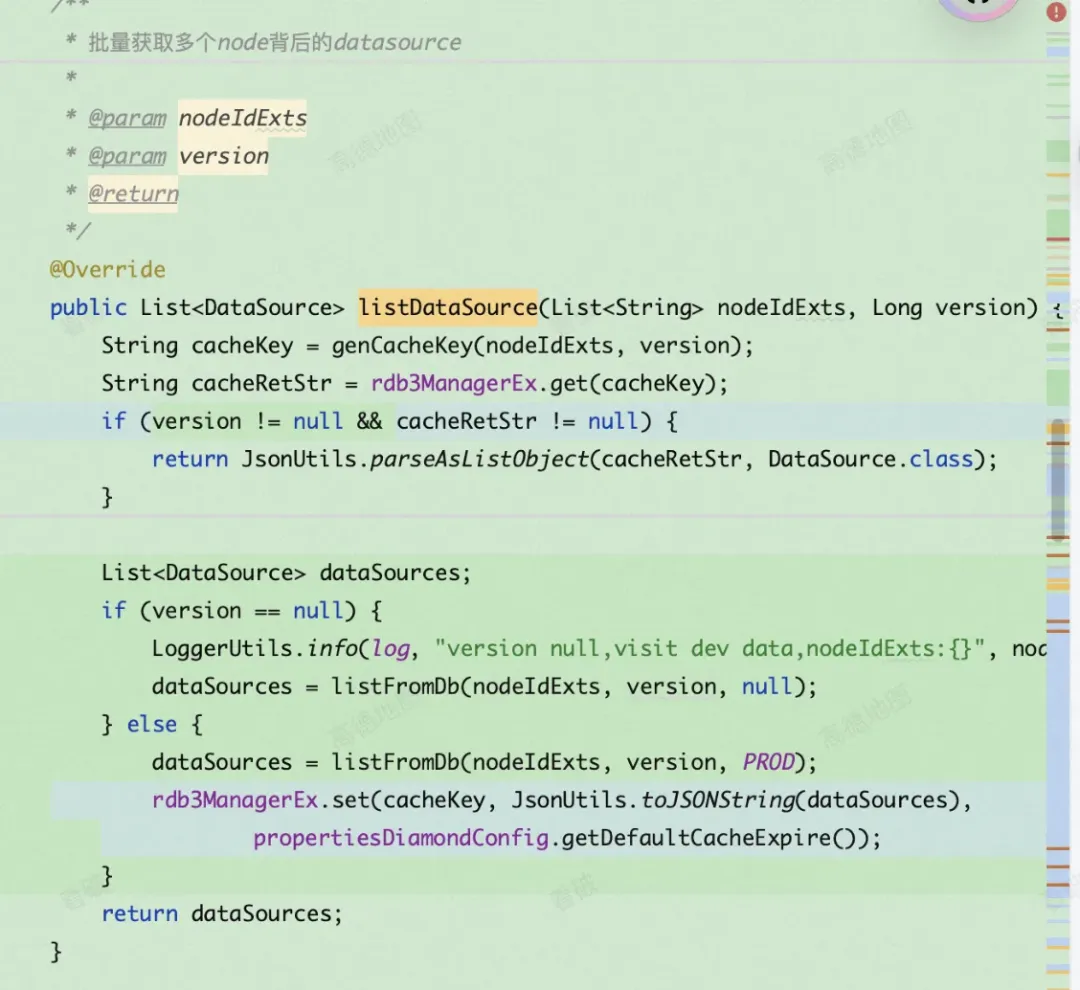
相关代码
案件还原
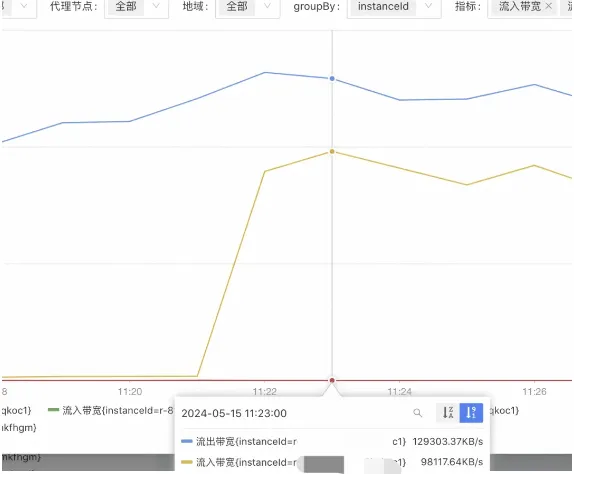
1.自然增长导致流出带宽不断变大直至96MB/s。
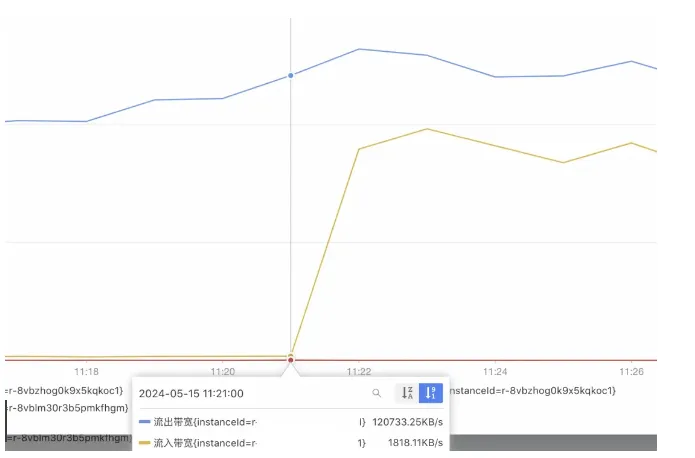
2.流出带宽超过96MB/s,输出缓冲区内存占用激增甚至溢出 (300setMaxTotal*10机器ip数量个客户端,之前推导过可以到9G)。
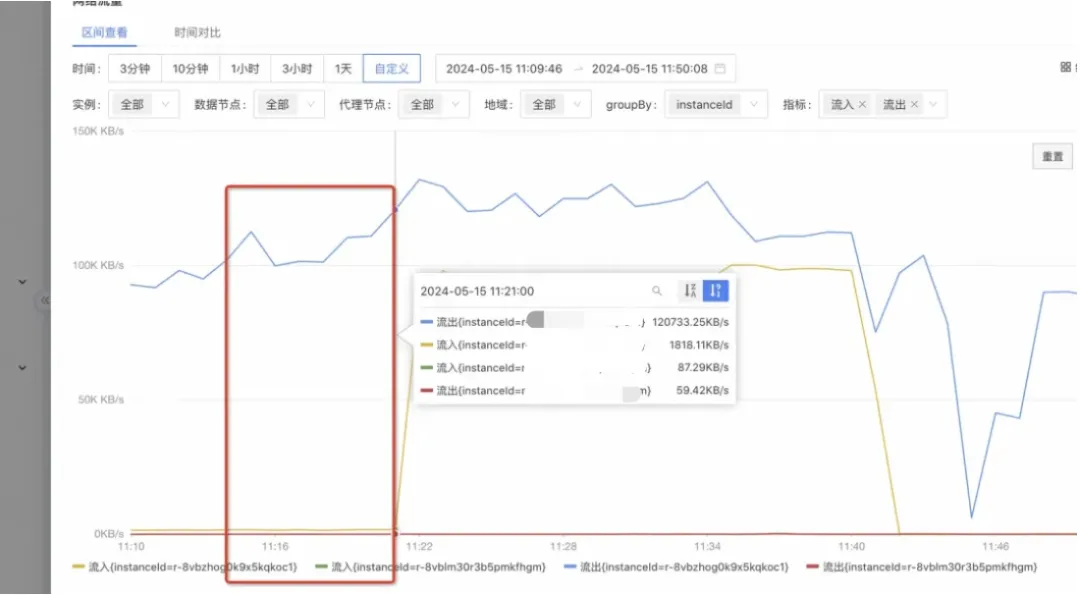
3.导致输出缓冲区爆了,redis客户端连接不得不关闭。
4.客户端连接关闭后,导致请求都走DB。
5.DB走完之后都会执行SET。
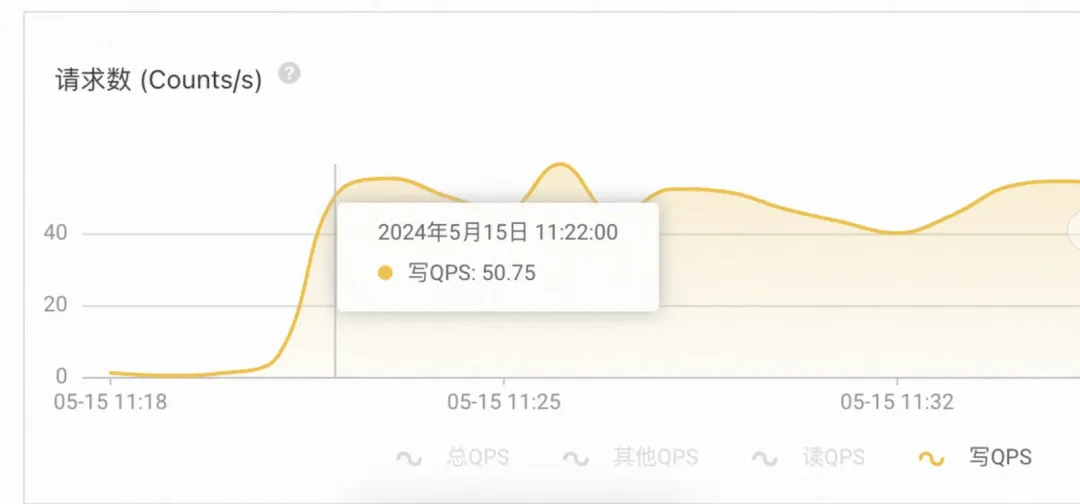
6.SET流量飙升,且因都是大KEY,导致流入带宽激增(别看写QPS只有50,但是如果每个写都是2MB,就可以做到瞬间占满流入带宽)。
7.Redis主线程模型,处理请求的速度过慢(大KEY),出现了间歇性阻塞,无法及时处理正常发送的请求,导致客户端发送的请求在输入缓冲区越积越多。
8.输入缓冲区内存随即激增。
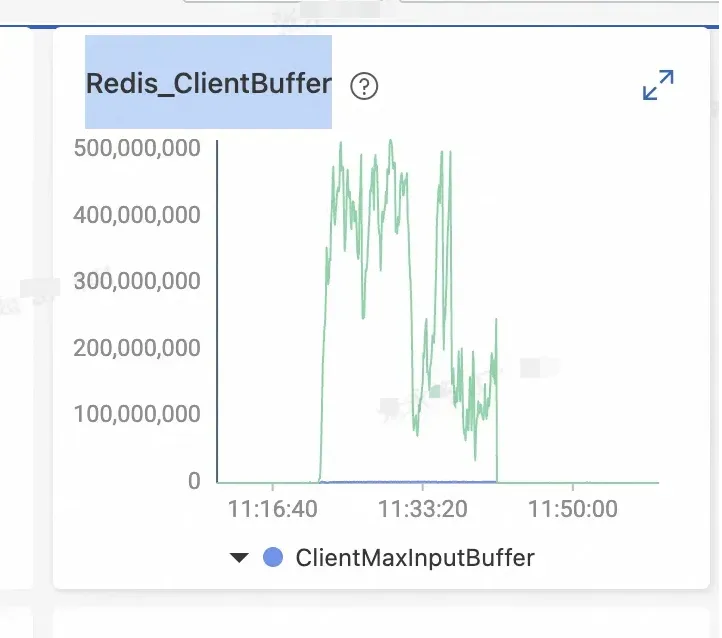
9.最终,redis内存被缓冲区内存(输入、输出)完全侵占。
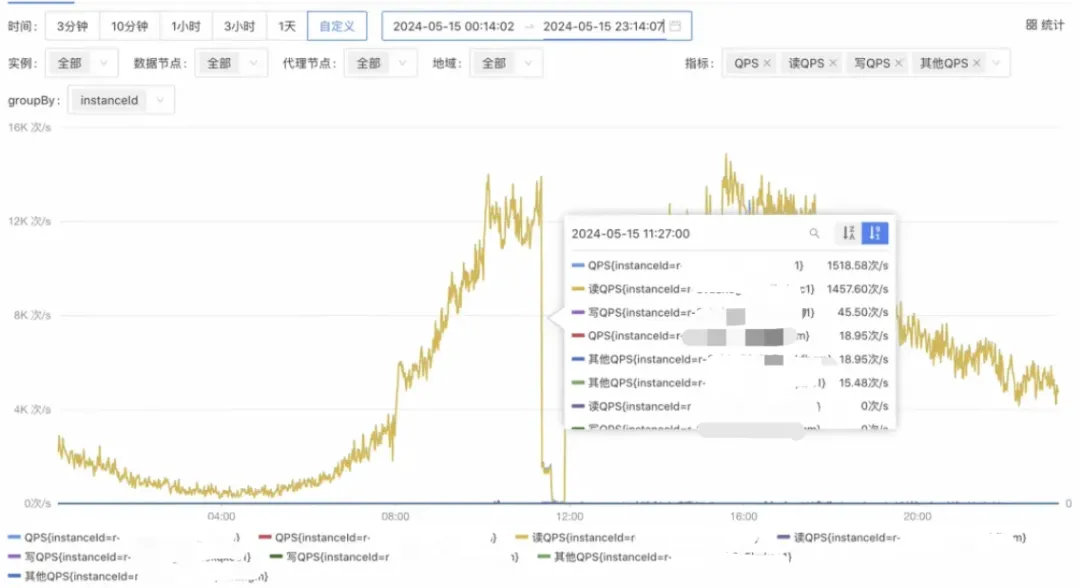
10.后续的SET GET命令甚至都进不了输入缓冲区,阻塞持续到客户端配置的SoTimeout时间;但是流入流出带宽依然占据并持续,总带宽到达了216MB/s
> 实例最大带宽192MB/s。
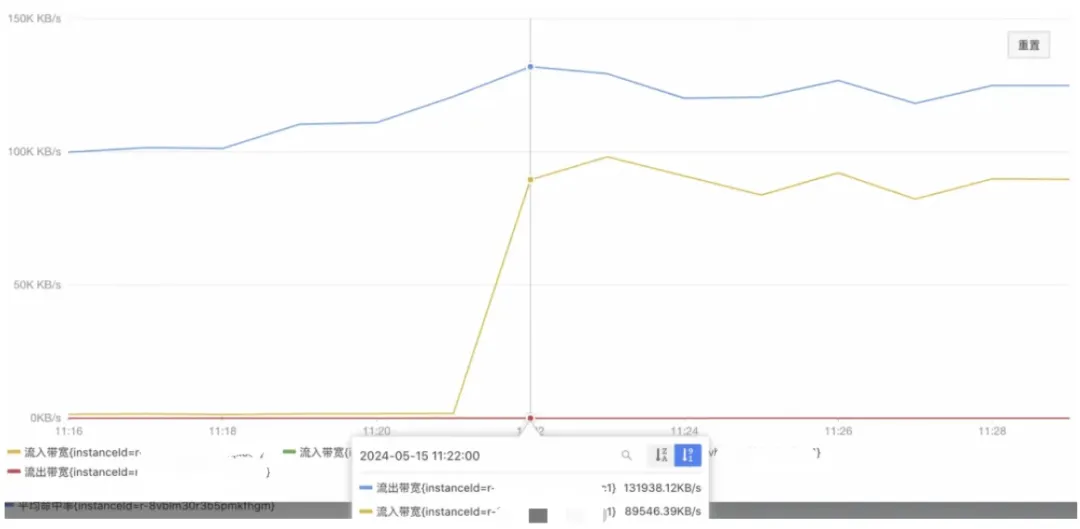
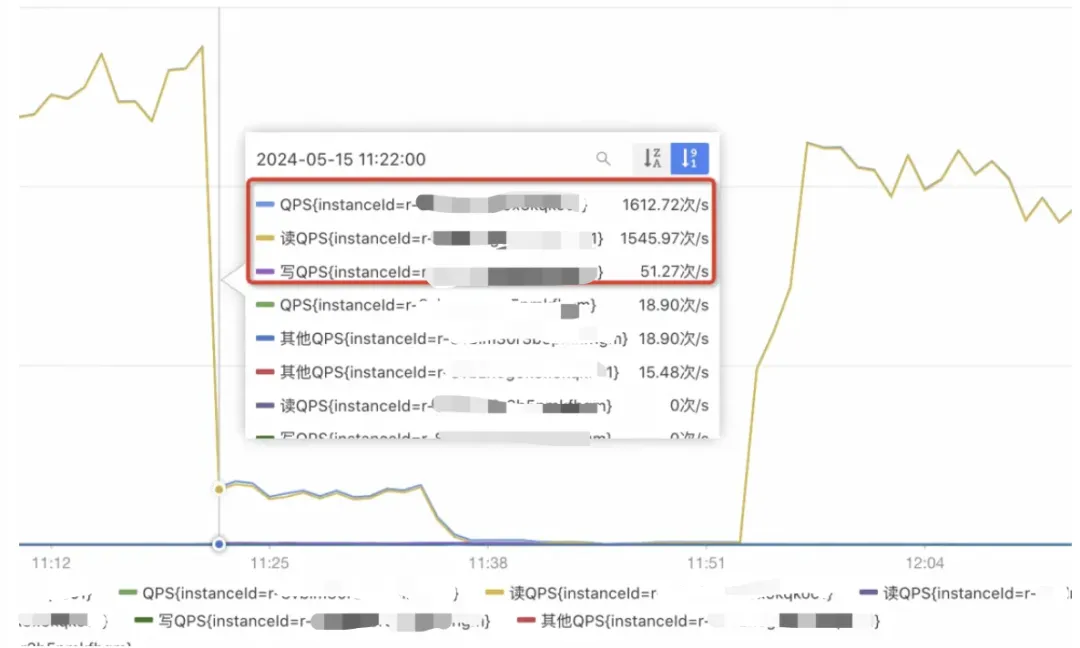
11.造成最终的不可用(后续的命令想进场,要依赖当前输入缓冲区里的命令被执行给你腾出来位置,但是还是那句话Redis主线程处理消化的速度,实在是太慢了;从图中,可以看到Redis的QPS骤降。
11:35分之后,我把redis降级了,全使用db来抗流量。
开发运维规范
可以看到Redis的性能是有边界的,不能盲目相信所谓的高性能。
真正理解性能须使用benchmark。

它也是有问题能造成他的性能瓶颈的。
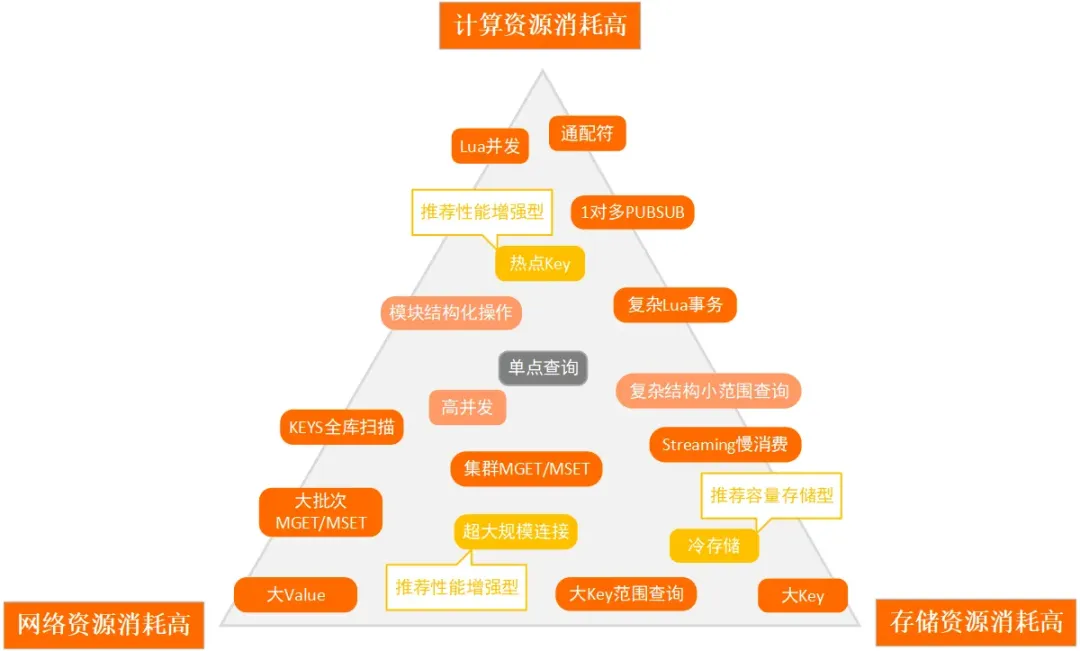

在上述的事故中,就占了【网络资源消耗高】【存储资源消耗高】两大问题
因此也到了本文的方法论环节:从业务部署、Key的设计、SDK、命令、运维管理等维度展示云数据库Redis开发运维规范:
业务部署规范:https://help.aliyun.com/zh/redis/use-cases/development-and-o-and-m-standards-for-apsaradb-for-redis
Key设计规范:https://help.aliyun.com/zh/redis/use-cases/development-and-o-and-m-standards-for-apsaradb-for-redis
SDK使用规范:https://help.aliyun.com/zh/redis/use-cases/development-and-o-and-m-standards-for-apsaradb-for-redis
命令使用规范:https://help.aliyun.com/zh/redis/use-cases/development-and-o-and-m-standards-for-apsaradb-for-redis
运维管理规范:https://help.aliyun.com/zh/redis/use-cases/development-and-o-and-m-standards-for-apsaradb-for-redis
业务部署规范
 
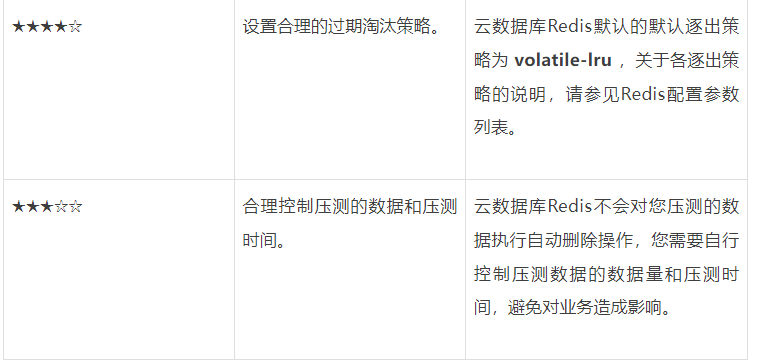
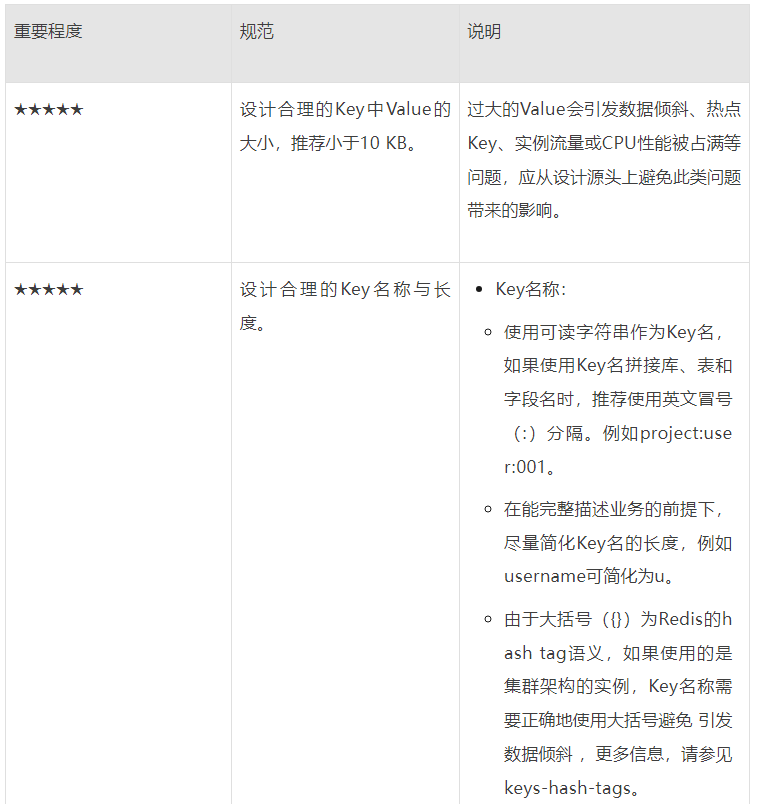
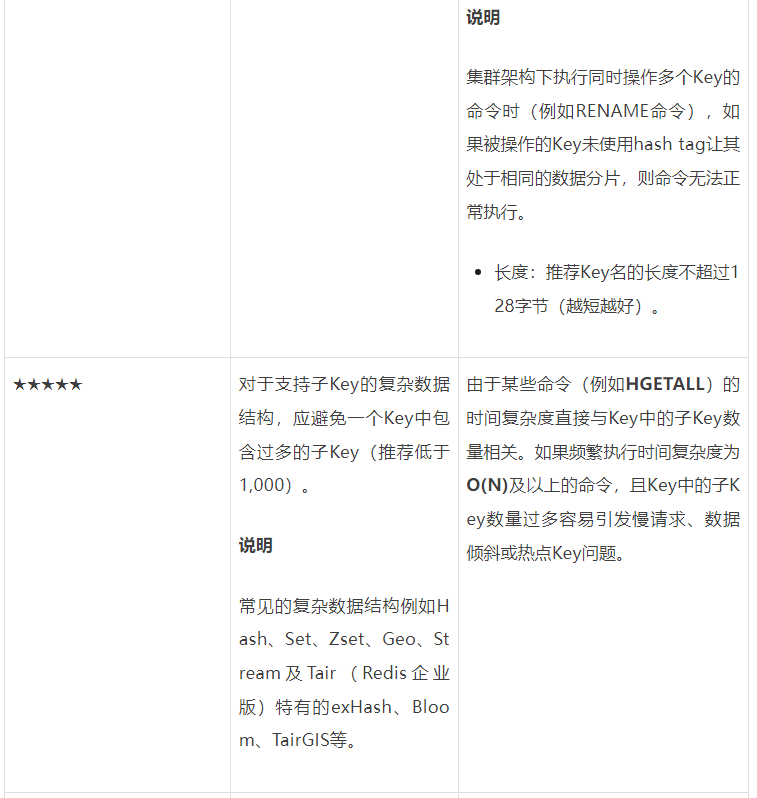
Key设计规范
SDK使用规范 
命令使用规范
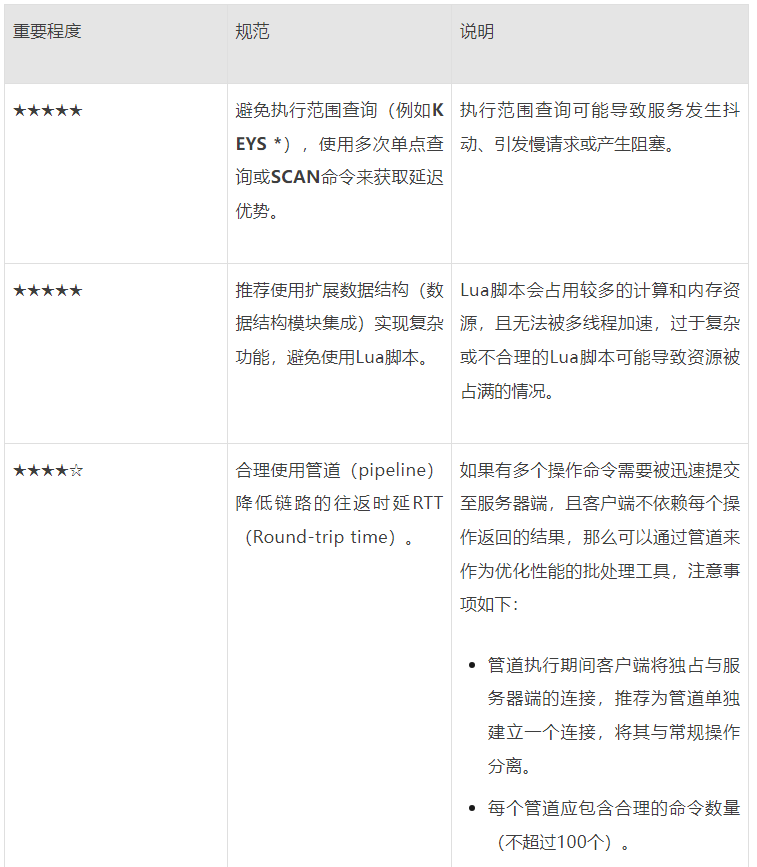
 
运维管理规范
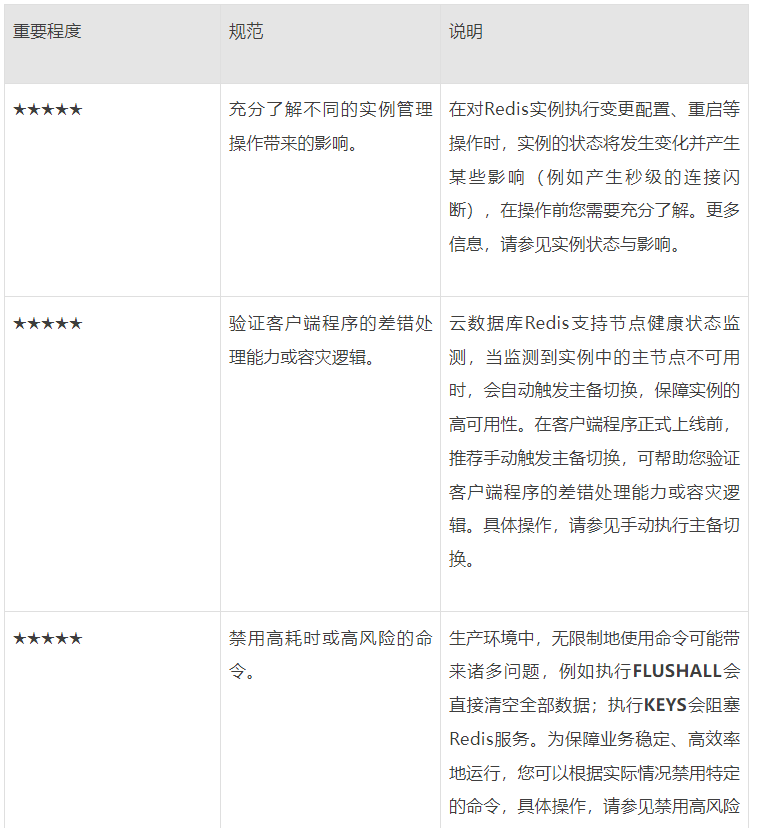
 
重点行动项
大KEY
大KEY其实并不是长度过长的KEY,而是存放了慢查询命令的KEY。
对于String类型,慢查询的本质在于value的大小。
对于其他类型,慢查询的本质在于集合的大小(时间复杂度带来)。
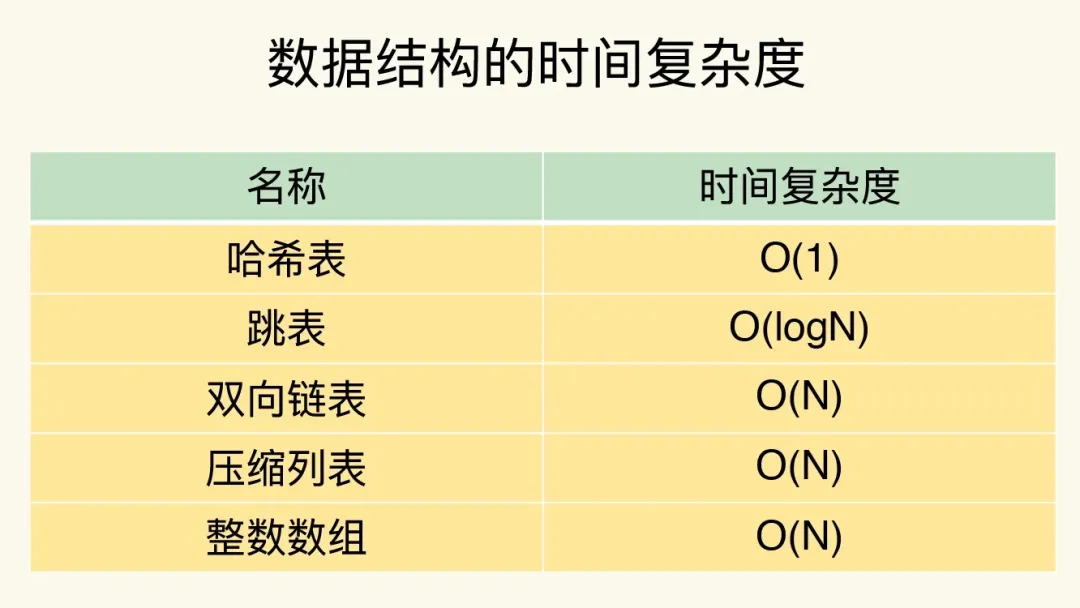
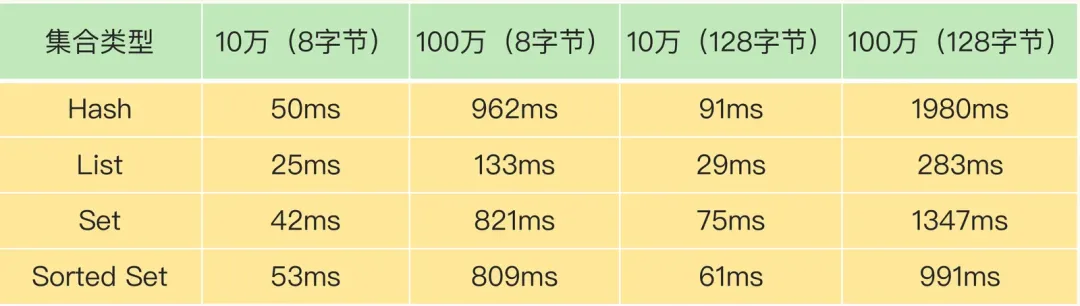
如何找到大key?
阿里云:发现并处理Redis的大Key和热Key。
如何解决大key?
其实就是一个字 "拆"。
1.对于字符串类型的key,我们通常要在业务层面将value的大小控制在10KB左右,如果value确实很大,可以考虑采用序列化算法和压缩算法来处理,推荐常用的几种序列化算法:Protostuff、Kryo或者Fst。
2.对于集合类型的key,我们通常要通过控制集合内元素数量来避免bigKey,通常的做法是将一个大的集合类型的key拆分成若干小集合类型的key来达到目的。
压测关注点
1.数据是否倾斜(不能只看聚合信息,要切换到分片上,看数据节点);
2.是否有大key、热key;
a.压测过程中关注(1)CloudDBA-实时TOP KEY统计(2)CloudDBA-慢请求;
b.压测后(1)CloudDBA-离线全量KEY分析(2)CloudDBA-诊断报告,做到分析报告时间覆盖压测时段;
3.CPU使用率、内存使用率、带宽使用率变化趋势(流入、流出都要看,最好看一个缓存周期);
4.如果可以,打开审计日志,看写入日志是否符合代码逻辑。
常用运维命令
出线上事故的时候,用于快速分析和保留现场。
CLIENT LIST
info memory
MEMORY USAGE
| 




